Chapter 2. Application life cycle management
2.1. Creating applications using the Developer perspective
The Developer perspective in the web console provides you the following options from the +Add view to create applications and associated services and deploy them on OpenShift Container Platform:
- From Git: Use this option to import an existing codebase in a Git repository to create, build, and deploy an application on OpenShift Container Platform.
- Container Image: Use existing images from an image stream or registry to deploy it on to OpenShift Container Platform.
- From Catalog: Explore the Developer Catalog to select the required applications, services, or source to image builders and add it to your project.
- From Dockerfile: Import a dockerfile from your Git repository to build and deploy an application.
- YAML: Use the editor to add YAML or JSON definitions to create and modify resources.
- Database: See the Developer Catalog to select the required database service and add it to your application.
Serverless options in the Developer perspective are displayed only if the OpenShift Serverless Operator is installed in your cluster.
2.1.1. Prerequisites
To create applications using the Developer perspective ensure that:
- You have logged in to the web console.
- You are in the Developer perspective.
- You have the appropriate roles and permissions in a project to create applications and other workloads in OpenShift Container Platform.
To create serverless applications, in addition to the preceeding prerequisites, ensure that:
2.1.2. Importing a codebase from Git to create an application
The following procedure walks you through the Import from Git option in the Developer perspective to create an application.
Create, build, and deploy an application on OpenShift Container Platform using an existing codebase in GitHub as follows:
Procedure
- In the +Add view, click From Git to see the Import from git form.
-
In the Git section, enter the Git repository URL for the codebase you want to use to create an application. For example, enter the URL of this sample Node.js application
https://github.com/sclorg/nodejs-ex. The URL is then validated. Optional: You can click Show Advanced Git Options to add details such as:
- Git Reference to point to code in a specific branch, tag, or commit to be used to build the application.
- Context Dir to specify the subdirectory for the application source code you want to use to build the application.
- Source Secret to create a Secret Name with credentials for pulling your source code from a private repository.
-
In the Builder section, after the URL is validated, an appropriate builder image is detected, indicated by a star, and automatically selected. For the
https://github.com/sclorg/nodejs-exGit URL, the Node.js builder image is selected by default. If required, you can change the version using the Builder Image Version drop-down list. In the General section:
-
In the Application field, enter a unique name for the application grouping, for example,
myapp. Ensure that the application name is unique in a namespace. The Name field to identify the resources created for this application is automatically populated based on the Git repository URL.
NoteThe resource name must be unique in a namespace. Modify the resource name if you get an error.
-
In the Application field, enter a unique name for the application grouping, for example,
In the Resources section, select:
- Deployment, to create an application in plain Kubernetes style.
- Deployment Config, to create an OpenShift style application.
- Knative Service, to create a microservice.
NoteThe Knative Service option is displayed in the Import from git form only if the Serverless Operator is installed in your cluster. For further details refer to documentation on installing OpenShift Serverless.
- In the Advanced Options section, the Create a route to the application is selected by default so that you can access your application using a publicly available URL. You can clear the check box if you do not want to expose your application on a public route.
Optional: You can use the following advanced options to further customize your application:
- Routing
Click the Routing link to:
- Customize the hostname for the route.
- Specify the path the router watches.
- Select the target port for the traffic from the drop-down list.
Secure your route by selecting the Secure Route check box. Select the required TLS termination type and set a policy for insecure traffic from the respective drop-down lists.
For serverless applications, the Knative Service manages all the routing options above. However, you can customize the target port for traffic, if required. If the target port is not specified, the default port of
8080is used.
- Build and Deployment Configuration
- Click the Build Configuration and Deployment Configuration links to see the respective configuration options. Some of the options are selected by default; you can customize them further by adding the necessary triggers and environment variables. For serverless applications, the Deployment Configuration option is not displayed as the Knative configuration resource maintains the desired state for your deployment instead of a DeploymentConfig.
- Scaling
Click the Scaling link to define the number of pods or instances of the application you want to deploy initially.
For serverless applications, you can:
- Set the upper and lower limit for the number of pods that can be set by the autoscaler. If the lower limit is not specified, it defaults to zero.
- Define the soft limit for the required number of concurrent requests per instance of the application at a given time. It is the recommended configuration for autoscaling. If not specified, it takes the value specified in the cluster configuration.
- Define the hard limit for the number of concurrent requests allowed per instance of the application at a given time. This is configured in the revision template. If not specified, it defaults to the value specified in the cluster configuration.
- Resource Limit
- Click the Resource Limit link to set the amount of CPU and Memory resources a container is guaranteed or allowed to use when running.
- Labels
- Click the Labels link to add custom labels to your application.
- Click Create to create the application and see its build status in the Topology view.
2.2. Creating applications from installed Operators
Operators are a method of packaging, deploying, and managing a Kubernetes application. You can create applications on OpenShift Container Platform using Operators that have been installed by a cluster administrator.
This guide walks developers through an example of creating applications from an installed Operator using the OpenShift Container Platform web console.
Additional resources
- See the Operators guide for more on how Operators work and how the Operator Lifecycle Manager is integrated in OpenShift Container Platform.
2.2.1. Creating an etcd cluster using an Operator
This procedure walks through creating a new etcd cluster using the etcd Operator, managed by the Operator Lifecycle Manager (OLM).
Prerequisites
- Access to an OpenShift Container Platform 4.4 cluster.
- The etcd Operator already installed cluster-wide by an administrator.
Procedure
- Create a new project in the OpenShift Container Platform web console for this procedure. This example uses a project called my-etcd.
Navigate to the Operators
Installed Operators page. The Operators that have been installed to the cluster by the cluster administrator and are available for use are shown here as a list of ClusterServiceVersions (CSVs). CSVs are used to launch and manage the software provided by the Operator. TipYou can get this list from the CLI using:
$ oc get csvOn the Installed Operators page, click Copied, and then click the etcd Operator to view more details and available actions:
Figure 2.1. etcd Operator overview
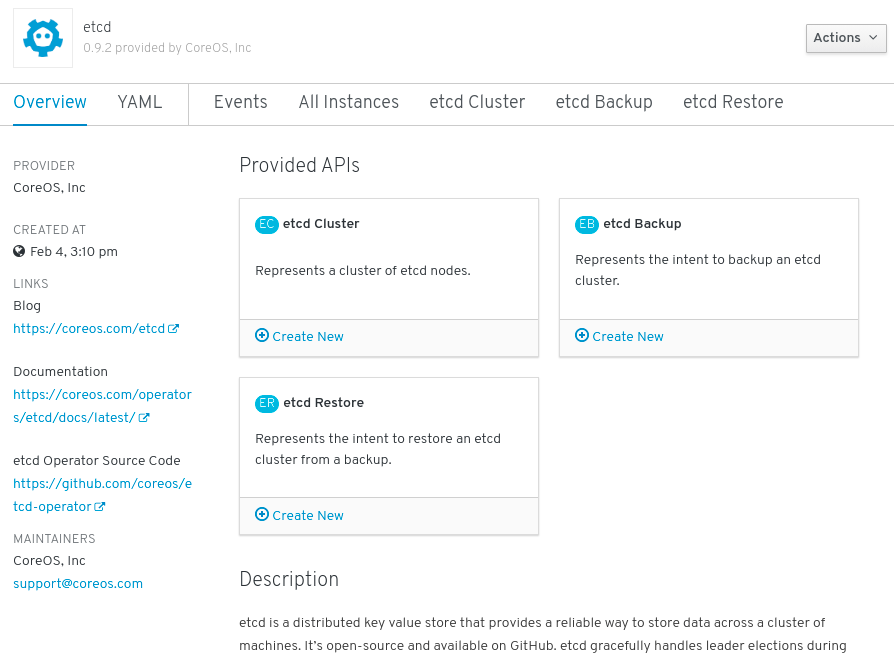
As shown under Provided APIs, this Operator makes available three new resource types, including one for an etcd Cluster (the
EtcdClusterresource). These objects work similar to the built-in native Kubernetes ones, such asDeploymentsorReplicaSets, but contain logic specific to managing etcd.Create a new etcd cluster:
- In the etcd Cluster API box, click Create New.
-
The next screen allows you to make any modifications to the minimal starting template of an
EtcdClusterobject, such as the size of the cluster. For now, click Create to finalize. This triggers the Operator to start up the pods, services, and other components of the new etcd cluster.
Click the Resources tab to see that your project now contains a number of resources created and configured automatically by the Operator.
Figure 2.2. etcd Operator resources
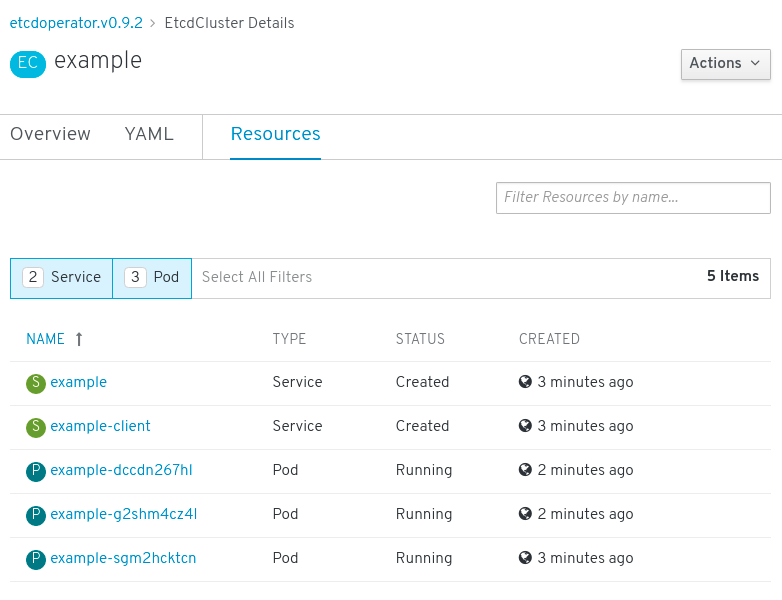
Verify that a Kubernetes service has been created that allows you to access the database from other pods in your project.
All users with the
editrole in a given project can create, manage, and delete application instances (an etcd cluster, in this example) managed by Operators that have already been created in the project, in a self-service manner, just like a cloud service. If you want to enable additional users with this ability, project administrators can add the role using the following command:$ oc policy add-role-to-user edit <user> -n <target_project>
You now have an etcd cluster that will react to failures and rebalance data as Pods become unhealthy or are migrated between nodes in the cluster. Most importantly, cluster administrators or developers with proper access can now easily use the database with their applications.
2.3. Creating applications using the CLI
You can create an OpenShift Container Platform application from components that include source or binary code, images, and templates by using the OpenShift Container Platform CLI.
The set of objects created by new-app depends on the artifacts passed as input: source repositories, images, or templates.
2.3.1. Creating an application from source code
With the new-app command you can create applications from source code in a local or remote Git repository.
The new-app command creates a build configuration, which itself creates a new application image from your source code. The new-app command typically also creates a DeploymentConfig object to deploy the new image, and a service to provide load-balanced access to the deployment running your image.
OpenShift Container Platform automatically detects whether the pipeline or source build strategy should be used, and in the case of source builds, detects an appropriate language builder image.
2.3.1.1. Local
To create an application from a Git repository in a local directory:
$ oc new-app /<path to source code>
If you use a local Git repository, the repository must have a remote named origin that points to a URL that is accessible by the OpenShift Container Platform cluster. If there is no recognized remote, running the new-app command will create a binary build.
2.3.1.2. Remote
To create an application from a remote Git repository:
$ oc new-app https://github.com/sclorg/cakephp-exTo create an application from a private remote Git repository:
$ oc new-app https://github.com/youruser/yourprivaterepo --source-secret=yoursecret
If you use a private remote Git repository, you can use the --source-secret flag to specify an existing source clone secret that will get injected into your build config to access the repository.
You can use a subdirectory of your source code repository by specifying a --context-dir flag. To create an application from a remote Git repository and a context subdirectory:
$ oc new-app https://github.com/sclorg/s2i-ruby-container.git \
--context-dir=2.0/test/puma-test-app
Also, when specifying a remote URL, you can specify a Git branch to use by appending #<branch_name> to the end of the URL:
$ oc new-app https://github.com/openshift/ruby-hello-world.git#beta42.3.1.3. Build strategy detection
If a Jenkins file exists in the root or specified context directory of the source repository when creating a new application, OpenShift Container Platform generates a pipeline build strategy. Otherwise, it generates a source build strategy.
Override the build strategy by setting the --strategy flag to either pipeline or source.
$ oc new-app /home/user/code/myapp --strategy=docker
The oc command requires that files containing build sources are available in a remote Git repository. For all source builds, you must use git remote -v.
2.3.1.4. Language detection
If you use the source build strategy, new-app attempts to determine the language builder to use by the presence of certain files in the root or specified context directory of the repository:
| Language | Files |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
After a language is detected, new-app searches the OpenShift Container Platform server for image stream tags that have a supports annotation matching the detected language, or an image stream that matches the name of the detected language. If a match is not found, new-app searches the Docker Hub registry for an image that matches the detected language based on name.
You can override the image the builder uses for a particular source repository by specifying the image, either an image stream or container specification, and the repository with a ~ as a separator. Note that if this is done, build strategy detection and language detection are not carried out.
For example, to use the myproject/my-ruby imagestream with the source in a remote repository:
$ oc new-app myproject/my-ruby~https://github.com/openshift/ruby-hello-world.git
To use the openshift/ruby-20-centos7:latest container image stream with the source in a local repository:
$ oc new-app openshift/ruby-20-centos7:latest~/home/user/code/my-ruby-app
Language detection requires the Git client to be locally installed so that your repository can be cloned and inspected. If Git is not available, you can avoid the language detection step by specifying the builder image to use with your repository with the <image>~<repository> syntax.
The -i <image> <repository> invocation requires that new-app attempt to clone repository in order to determine what type of artifact it is, so this will fail if Git is not available.
The -i <image> --code <repository> invocation requires new-app clone repository in order to determine whether image should be used as a builder for the source code, or deployed separately, as in the case of a database image.
2.3.2. Creating an application from an image
You can deploy an application from an existing image. Images can come from image streams in the OpenShift Container Platform server, images in a specific registry, or images in the local Docker server.
The new-app command attempts to determine the type of image specified in the arguments passed to it. However, you can explicitly tell new-app whether the image is a container image using the --docker-image argument or an image stream using the -i|--image-stream argument.
If you specify an image from your local Docker repository, you must ensure that the same image is available to the OpenShift Container Platform cluster nodes.
2.3.2.1. Docker Hub MySQL image
Create an application from the Docker Hub MySQL image, for example:
$ oc new-app mysql2.3.2.2. Image in a private registry
Create an application using an image in a private registry, specify the full container image specification:
$ oc new-app myregistry:5000/example/myimage2.3.2.3. Existing image stream and optional image stream tag
Create an application from an existing image stream and optional image stream tag:
$ oc new-app my-stream:v12.3.3. Creating an application from a template
You can create an application from a previously stored template or from a template file, by specifying the name of the template as an argument. For example, you can store a sample application template and use it to create an application.
Create an application from a stored template, for example:
$ oc create -f examples/sample-app/application-template-stibuild.json
$ oc new-app ruby-helloworld-sample
To directly use a template in your local file system, without first storing it in OpenShift Container Platform, use the -f|--file argument. For example:
$ oc new-app -f examples/sample-app/application-template-stibuild.json2.3.3.1. Template parameters
When creating an application based on a template, use the -p|--param argument to set parameter values that are defined by the template:
$ oc new-app ruby-helloworld-sample \
-p ADMIN_USERNAME=admin -p ADMIN_PASSWORD=mypassword
You can store your parameters in a file, then use that file with --param-file when instantiating a template. If you want to read the parameters from standard input, use --param-file=-:
$ cat helloworld.params
ADMIN_USERNAME=admin
ADMIN_PASSWORD=mypassword
$ oc new-app ruby-helloworld-sample --param-file=helloworld.params
$ cat helloworld.params | oc new-app ruby-helloworld-sample --param-file=-2.3.4. Modifying application creation
The new-app command generates OpenShift Container Platform objects that build, deploy, and run the application that is created. Normally, these objects are created in the current project and assigned names that are derived from the input source repositories or the input images. However, with new-app you can modify this behavior.
| Object | Description |
|---|---|
|
|
A |
|
|
For the |
|
|
A |
|
|
The |
| Other | Other objects can be generated when instantiating templates, according to the template. |
2.3.4.1. Specifying environment variables
When generating applications from a template, source, or an image, you can use the -e|--env argument to pass environment variables to the application container at run time:
$ oc new-app openshift/postgresql-92-centos7 \
-e POSTGRESQL_USER=user \
-e POSTGRESQL_DATABASE=db \
-e POSTGRESQL_PASSWORD=password
The variables can also be read from file using the --env-file argument:
$ cat postgresql.env
POSTGRESQL_USER=user
POSTGRESQL_DATABASE=db
POSTGRESQL_PASSWORD=password
$ oc new-app openshift/postgresql-92-centos7 --env-file=postgresql.env
Additionally, environment variables can be given on standard input by using --env-file=-:
$ cat postgresql.env | oc new-app openshift/postgresql-92-centos7 --env-file=-
Any BuildConfig objects created as part of new-app processing are not updated with environment variables passed with the -e|--env or --env-file argument.
2.3.4.2. Specifying build environment variables
When generating applications from a template, source, or an image, you can use the --build-env argument to pass environment variables to the build container at run time:
$ oc new-app openshift/ruby-23-centos7 \
--build-env HTTP_PROXY=http://myproxy.net:1337/ \
--build-env GEM_HOME=~/.gem
The variables can also be read from a file using the --build-env-file argument:
$ cat ruby.env
HTTP_PROXY=http://myproxy.net:1337/
GEM_HOME=~/.gem
$ oc new-app openshift/ruby-23-centos7 --build-env-file=ruby.env
Additionally, environment variables can be given on standard input by using --build-env-file=-:
$ cat ruby.env | oc new-app openshift/ruby-23-centos7 --build-env-file=-2.3.4.3. Specifying labels
When generating applications from source, images, or templates, you can use the -l|--label argument to add labels to the created objects. Labels make it easy to collectively select, configure, and delete objects associated with the application.
$ oc new-app https://github.com/openshift/ruby-hello-world -l name=hello-world2.3.4.4. Viewing the output without creation
To see a dry-run of running the new-app command, you can use the -o|--output argument with a yaml or json value. You can then use the output to preview the objects that are created or redirect it to a file that you can edit. After you are satisfied, you can use oc create to create the OpenShift Container Platform objects.
To output new-app artifacts to a file, edit them, then create them:
$ oc new-app https://github.com/openshift/ruby-hello-world \
-o yaml > myapp.yaml
$ vi myapp.yaml
$ oc create -f myapp.yaml2.3.4.5. Creating objects with different names
Objects created by new-app are normally named after the source repository, or the image used to generate them. You can set the name of the objects produced by adding a --name flag to the command:
$ oc new-app https://github.com/openshift/ruby-hello-world --name=myapp2.3.4.6. Creating objects in a different project
Normally, new-app creates objects in the current project. However, you can create objects in a different project by using the -n|--namespace argument:
$ oc new-app https://github.com/openshift/ruby-hello-world -n myproject2.3.4.7. Creating multiple objects
The new-app command allows creating multiple applications specifying multiple parameters to new-app. Labels specified in the command line apply to all objects created by the single command. Environment variables apply to all components created from source or images.
To create an application from a source repository and a Docker Hub image:
$ oc new-app https://github.com/openshift/ruby-hello-world mysql
If a source code repository and a builder image are specified as separate arguments, new-app uses the builder image as the builder for the source code repository. If this is not the intent, specify the required builder image for the source using the ~ separator.
2.3.4.8. Grouping images and source in a single pod
The new-app command allows deploying multiple images together in a single pod. In order to specify which images to group together, use the + separator. The --group command line argument can also be used to specify the images that should be grouped together. To group the image built from a source repository with other images, specify its builder image in the group:
$ oc new-app ruby+mysqlTo deploy an image built from source and an external image together:
$ oc new-app \
ruby~https://github.com/openshift/ruby-hello-world \
mysql \
--group=ruby+mysql2.3.4.9. Searching for images, templates, and other inputs
To search for images, templates, and other inputs for the oc new-app command, add the --search and --list flags. For example, to find all of the images or templates that include PHP:
$ oc new-app --search php2.4. Viewing application composition using the Topology view
The Topology view in the Developer perspective of the web console provides a visual representation of all the applications within a project, their build status, and the components and services associated with them.
2.4.1. Prerequisites
To view your applications in the Topology view and interact with them, ensure that:
- You have logged in to the web console.
- You are in the Developer perspective.
- You have the appropriate roles and permissions in a project to create applications and other workloads in OpenShift Container Platform.
- You have created and deployed an application on OpenShift Container Platform using the Developer perspective.
2.4.2. Viewing the topology of your application
You can navigate to the Topology view using the left navigation panel in the Developer perspective. After you create an application, you are directed automatically to the Topology view where you can see the status of the application pods, quickly access the application on a public URL, access the source code to modify it, and see the status of your last build. You can zoom in and out to see more details for a particular application.
A serverless application is visually indicated with the Knative symbol (
 ).
).
Serverless applications take some time to load and display on the Topology view. When you create a serverless application, it first creates a service resource and then a revision. After that it is deployed and displayed on the Topology view. If it is the only workload, you might be redirected to the Add page. Once the revision is deployed, the serverless application is displayed on the Topology view.
The status or phase of the Pod is indicated by different colors and tooltips as Running (
 ), Not Ready (
), Not Ready (
 ), Warning(
), Warning(
 ), Failed(
), Failed(
 ), Pending(
), Pending(
 ), Succeeded(
), Succeeded(
 ), Terminating(
), Terminating(
 ), or Unknown(
), or Unknown(
 ). For more information about pod status, see the Kubernetes documentation.
). For more information about pod status, see the Kubernetes documentation.
After you create an application and an image is deployed, the status is shown as Pending. After the application is built, it is displayed as Running.
Figure 2.3. Application topology
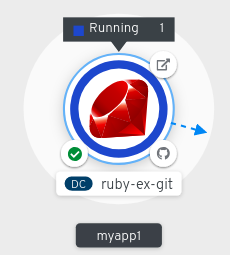
The application resource name is appended with indicators for the different types of resource objects as follows:
-
DC:
DeploymentConfig -
D:
Deployment -
SS:
StatefulSet -
DS:
DaemonSet
2.4.3. Interacting with the application and the components
The Topology view in the Developer perspective of the web console provides the following options to interact with the application and the components:
-
Click Open URL (
 ) to see your application exposed by the route on a public URL.
) to see your application exposed by the route on a public URL.
Click Edit Source code to access your source code and modify it.
NoteThis feature is available only when you create applications using the From Git, From Catalog, and the From Dockerfile options.
-
Hover your cursor over the lower left icon on the Pod to see the name of the latest build and its status. The status of the application build is indicated as New (
 ), Pending (
), Pending (
 ), Running (
), Running (
 ), Completed (
), Completed (
 ), Failed (
), Failed (
 ), and Canceled (
), and Canceled (
 ).
).
- Use the Shortcuts menu listed on the upper-right of the screen to navigate components in the Topology view.
- Use the List View icon to see a list of all your applications and use the Topology View icon to switch back to the Topology view.
2.4.4. Scaling application pods and checking builds and routes
The Topology view provides the details of the deployed components in the Overview panel. You can use the Overview and Resources tabs to scale the application pods, check build status, services, and routes as follows:
Click on the component node to see the Overview panel to the right. Use the Overview tab to:
- Scale your pods using the up and down arrows to increase or decrease the number of instances of the application manually. For serverless applications, the pods are automatically scaled down to zero when idle and scaled up depending on the channel traffic.
- Check the Labels, Annotations, and Status of the application.
Click the Resources tab to:
- See the list of all the pods, view their status, access logs, and click on the pod to see the pod details.
- See the builds, their status, access logs, and start a new build if needed.
- See the services and routes used by the component.
For serverless applications, the Resources tab provides information on the revision, routes, and the configurations used for that component.
2.4.5. Grouping multiple components within an application
You can use the Add page to add multiple components or services to your project and use the Topology page to group applications and resources within an application group. The following procedure adds a MongoDB database service to an existing application with a Node.js component.
Prerequisites
- Ensure that you have created and deployed a Node.js application on OpenShift Container Platform using the Developer perspective.
Procedure
Create and deploy the MongoDB service to your project as follows:
- In the Developer perspective, navigate to the Add view and select the Database option to see the Developer Catalog, which has multiple options that you can add as components or services to your application.
- Click on the MongoDB option to see the details for the service.
- Click Instantiate Template to see an automatically populated template with details for the MongoDB service, and click Create to create the service.
- On the left navigation panel, click Topology to see the MongoDB service deployed in your project.
- To add the MongoDB service to the existing application group, select the mongodb pod and drag it to the application; the MongoDB service is added to the existing application group.
Dragging a component and adding it to an application group automatically adds the required labels to the component. Click on the MongoDB service node to see the label
app.kubernetes.io/part-of=myappadded to the Labels section in the Overview Panel.Figure 2.4. Application grouping
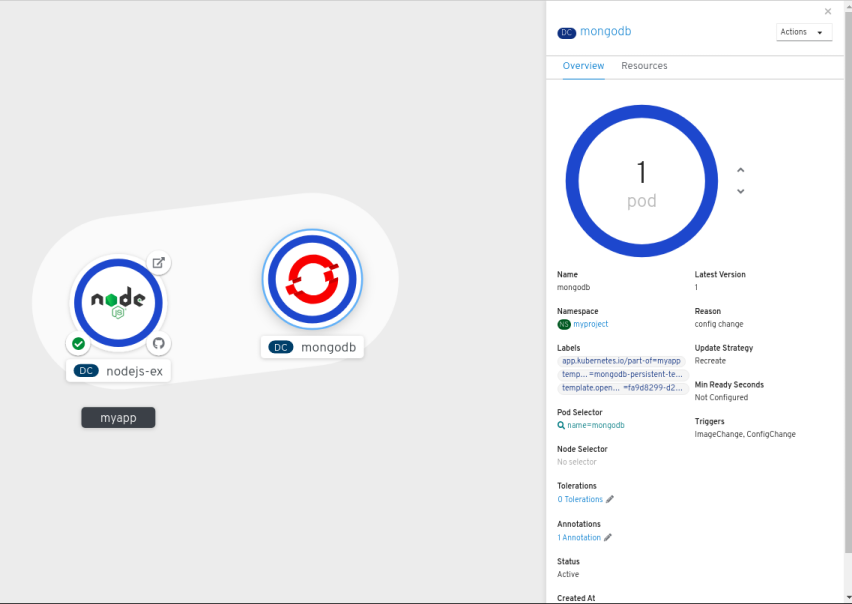
Alternatively, you can also add the component to an application as follows:
- To add the MongoDB service to your application, click on the mongodb pod to see the Overview panel to the right.
- Click the Actions drop-down menu on the upper right of the panel and select Edit Application Grouping.
- In the Edit Application Grouping dialog box, click the Select an Application drop-down list, and select the appropriate application group.
- Click Save to see the MongoDB service added to the application group.
You can remove a component from an application group by selecting the component and using Shift+ drag to drag it out of the application group.
2.4.6. Connecting components within an application and across applications
In addition to grouping multiple components within an application, you can also use the Topology view to connect components with each other. You can either use a binding connector or a visual one to connect components.
A binding connection between the components can be established only if the target node is an Operator-backed service. This is indicated by the Create a binding connector tool-tip which appears when you drag an arrow to such a target node. When an application is connected to a service using a binding connector a service binding request is created. Then, the Service Binding Operator controller uses an intermediate secret to inject the necessary binding data into the application deployment as environment variables. After the request is successful, the application is redeployed establishing an interaction between the connected components.
A visual connector establishes only a visual connection between the components, depicting an intent to connect. No interaction between the components is established. If the target node is not an Operator-backed service the Create a visual connector tool-tip is displayed when you drag an arrow to a target node.
2.4.6.1. Creating a visual connection between components
You can depict an intent to connect application components using the visual connector.
This procedure walks through an example of creating a visual connection between a MongoDB service and a Node.js application.
Prerequisites
- Ensure that you have created and deployed a Node.js application using the Developer perspective.
- Ensure that you have created and deployed a MongoDB service using the Developer perspective.
Procedure
Hover over the MongoDB service to see a dangling arrow on the node.
Figure 2.5. Connector

- Click and drag the arrow towards the Node.js component to connect the MongoDB service with it.
Click on the MongoDB service to see the Overview Panel. In the Annotations section, click the edit icon to see the Key =
app.openshift.io/connects-toand Value =nodejs-exannotation added to the service.
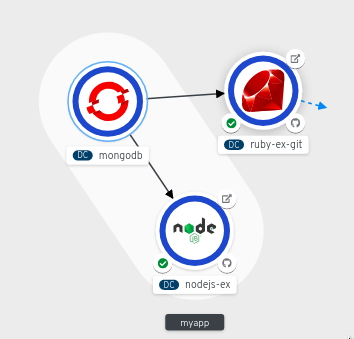
Similarly you can create other applications and components and establish connections between them.
Figure 2.6. Connecting multiple applications
2.4.6.2. Creating a binding connection between components
Service Binding is a Technology Preview feature only. Technology Preview features are not supported with Red Hat production service level agreements (SLAs) and might not be functionally complete. Red Hat does not recommend using them in production. These features provide early access to upcoming product features, enabling customers to test functionality and provide feedback during the development process.
For more information about the support scope of Red Hat Technology Preview features, see https://access.redhat.com/support/offerings/techpreview/.
Currently, a few specific Operators like the etcd and the PostgresSQL Database Operator’s service instances are bindable.
You can establish a binding connection with Operator-backed components.
This procedure walks through an example of creating a binding connection between a PostgreSQL Database service and a Node.js application. To create a binding connection with a service that is backed by the PostgreSQL Database Operator, you must first add the Red Hat-provided PostgreSQL Database Operator to the OperatorHub using a backing Operator source, and then install the Operator.
Prerequisite
- Ensure that you have created and deployed a Node.js application using the Developer perspective.
- Ensure that you have installed the Service Binding Operator from OperatorHub.
Procedure
Create a backing Operator source that adds the PostgresSQL Operator provided by Red Hat to the OperatorHub. A backing Operator source exposes the binding information in secrets, config maps, status, and spec attributes.
- In the Add view, click the YAML option to see the Import YAML screen.
Add the following YAML file to apply the Operator source:
apiVersion: operators.coreos.com/v1 kind: OperatorSource metadata: name: db-operators namespace: openshift-marketplace spec: type: appregistry endpoint: https://quay.io/cnr registryNamespace: pmacik- Click Create to create the Operator source in your cluster.
Install the Red Hat-provided PostgreSQL Database Operator:
-
In the Administrator perspective of the console, navigate to Operators
OperatorHub. - In the Database category, select the PostgreSQL Database Operator and install it.
-
In the Administrator perspective of the console, navigate to Operators
Create a database (DB) instance for the application:
- Switch to the Developer perspective and ensure that you are in the appropriate project.
- In the Add view, click the YAML option to see the Import YAML screen.
Add the service instance YAML in the editor and click Create to deploy the service. Following is an example of what the service YAML will look like:
apiVersion: postgresql.baiju.dev/v1alpha1 kind: Database metadata: name: db-demo namespace: test-project spec: image: docker.io/postgres imageName: postgres dbName: db-demoA DB instance is now deployed in the Topology view.
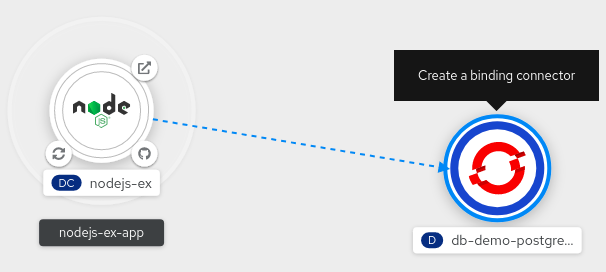
- In the Topology view, hover over the Node.js component to see a dangling arrow on the node.
Click and drag the arrow towards the db-demo-postgresql service to make a binding connection with the Node.js application. A service binding request is created and the Service Binding Operator controller injects the DB connection information into the application deployment as environment variables. After the request is successful, the application is redeployed and the connection is established.
Figure 2.7. Binding connector
2.4.7. Labels and annotations used for the Topology view
The Topology view uses the following labels and annotations:
- Icon displayed in the node
-
Icons in the node are defined by looking for matching icons using the
app.openshift.io/runtimelabel, followed by theapp.kubernetes.io/namelabel. This matching is done using a predefined set of icons. - Link to the source code editor or the source
-
The
app.openshift.io/vcs-uriannotation is used to create links to the source code editor. - Node Connector
-
The
app.openshift.io/connects-toannotation is used to connect the nodes. - App grouping
-
The
app.kubernetes.io/part-of=<appname>label is used to group the applications, services, and components.
For detailed information on the labels and annotations OpenShift Container Platform applications must use, see Guidelines for labels and annotations for OpenShift applications.
2.5. Editing applications
You can edit the configuration and the source code of the application you create using the Topology view.
2.5.1. Prerequisites
- You have logged in to the web console and have switched to the Developer perspective.
- You have the appropriate roles and permissions in a project to create and modify applications in OpenShift Container Platform.
- You have created and deployed an application on OpenShift Container Platform using the Developer perspective.
2.5.2. Editing the source code of an application using the Developer perspective
You can use the Topology view in the Developer perspective to edit the source code of your application.
Procedure
In the Topology view, click the Edit Source code icon, displayed at the bottom-right of the deployed application, to access your source code and modify it.
NoteThis feature is available only when you create applications using the From Git, From Catalog, and the From Dockerfile options.
If the Eclipse Che Operator is installed in your cluster, a Che workspace (
 ) is created and you are directed to the workspace to edit your source code. If it is not installed, you will be directed to the Git repository (
) is created and you are directed to the workspace to edit your source code. If it is not installed, you will be directed to the Git repository (
 ) your source code is hosted in.
) your source code is hosted in.
2.5.3. Editing the application configuration using the Developer perspective
You can use the Topology view in the Developer perspective to edit the configuration of your application.
Currently, only configurations of applications created by using the From Git, Container Image, From Catalog, or From Dockerfile options in the Add workflow of the Developer perspective can be edited. Configurations of applications created by using the CLI or the YAML option from the Add workflow cannot be edited.
Prerequisites
Ensure that you have created an application using the From Git, Container Image, From Catalog, or From Dockerfile options in the Add workflow.
Procedure
After you have created an application and it is displayed in the Topology view, right-click the application to see the edit options available.
Figure 2.8. Edit application

- Click Edit application-name to see the Add workflow you used to create the application. The form is pre-populated with the values you had added while creating the application.
Edit the necessary values for the application.
NoteYou cannot edit the Name field in the General section, the CI/CD pipelines, or the Create a route to the application field in the Advanced Options section.
Click Save to restart the build and deploy a new image.
Figure 2.9. Edit and redeploy application

2.6. Working with Helm charts using the Developer perspective
2.6.1. Understanding Helm
Helm is a command-line interface (CLI) tool that simplifies deployment of applications and services to OpenShift Container Platform clusters. Helm uses a packaging format called charts. A Helm chart is a collection of files that describes OpenShift Container Platform resources. A running instance of the chart in a cluster is called a release. A new release is created every time a chart is installed on the cluster.
2.6.1.1. Key features
Helm provides the ability to:
- Search through a large collection of charts stored in the chart repository.
- Modify existing charts.
- Create your own charts with OpenShift Container Platform or Kubernetes resources.
- Package and share your applications as charts.
You can use the Developer perspective in the web console to create Helm releases.
2.6.2. Installing Helm charts
You can use the Developer perspective to create Helm releases from the Helm charts provided in the Developer Catalog.
Prerequisites
- You have logged in to the web console and have switched to the Developer perspective.
Procedure
- In the Developer perspective, navigate to the Add view and select the From Catalog option to see the Developer Catalog.
In the filters listed on the left, under Type, select the Helm Charts filter to see the available Helm charts.
Figure 2.10. Helm charts in developer catalog
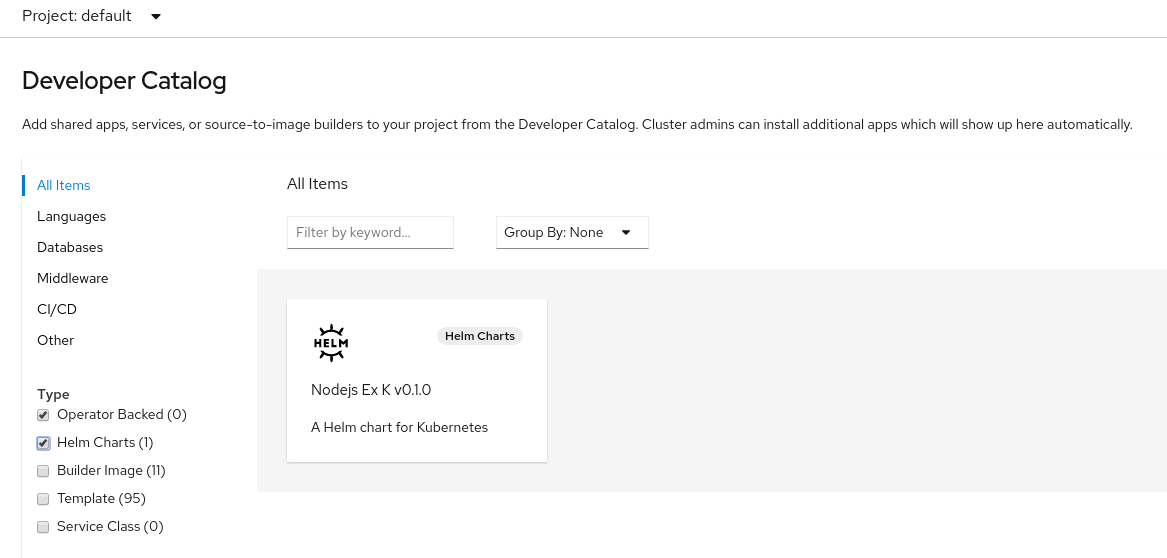
- Select the Node.js chart to see the description of the chart and click Install Helm Chart.
In the Install Helm Chart page:
- Enter a unique name for the release in the Release Name field.
- Optionally, in the YAML editor, modify the YAML file.
Click Install to create a Helm release. The release is displayed in the Topology view.
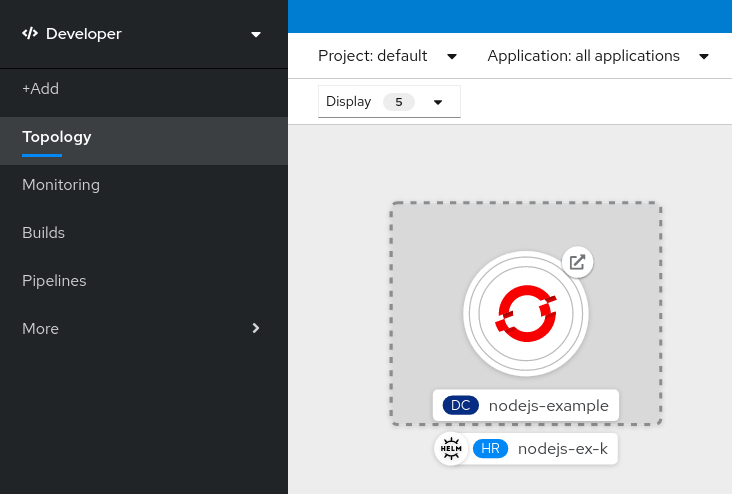
- In the left panel of the Developer perspective, click More > Helm to see the list of all the Helm releases in the namespace.
- Click on a listed Helm release to see the details and resources for that release.
2.7. Deleting applications
You can delete applications created in your project.
2.7.1. Deleting applications using the Developer perspective
You can delete an application and all of its associated components using the Topology view in the Developer perspective:
- Click the application you want to delete to see the side panel with the resource details of the application.
- Click the Actions drop-down menu displayed on the upper right of the panel, and select Delete Application to see a confirmation dialog box.
- Enter the name of the application and click Delete to delete it.
You can also right-click the application you want to delete and click Delete Application to delete it.