Chapter 9. Knative Serving
9.1. Using kn to complete Knative Serving tasks
The Knative kn CLI extends the functionality of the oc or kubectl CLI tools to integrate interaction with Knative components on OpenShift Container Platform. kn allows developers to deploy and manage applications without editing YAML files directly.
9.1.1. Basic workflow using kn
The following basic workflow deploys a simple hello service that reads the environment variable RESPONSE and prints its output.
You can use this guide as a reference to perform create, read, update, and delete (CRUD) operations on a service.
Procedure
Create a service in the
defaultnamespace from an image:$ kn service create hello --image docker.io/openshift/hello-openshift --env RESPONSE="Hello Serverless!"Example output
Creating service 'hello' in namespace 'default': 0.085s The Route is still working to reflect the latest desired specification. 0.101s Configuration "hello" is waiting for a Revision to become ready. 11.590s ... 11.650s Ingress has not yet been reconciled. 11.726s Ready to serve. Service 'hello' created with latest revision 'hello-gsdks-1' and URL: http://hello-default.apps-crc.testingList the service:
$ kn service listExample output
NAME URL LATEST AGE CONDITIONS READY REASON hello http://hello-default.apps-crc.testing hello-gsdks-1 8m35s 3 OK / 3 TrueCheck if the service is working by using the
curlservice endpoint command:$ curl http://hello-default.apps-crc.testingExample output
Hello Serverless!Update the service:
$ kn service update hello --env RESPONSE="Hello OpenShift!"Example output
Updating Service 'hello' in namespace 'default': 10.136s Traffic is not yet migrated to the latest revision. 10.175s Ingress has not yet been reconciled. 10.348s Ready to serve. Service 'hello' updated with latest revision 'hello-dghll-2' and URL: http://hello-default.apps-crc.testingThe service’s environment variable
RESPONSEis now set to "Hello OpenShift!".Describe the service.
$ kn service describe helloExample output
Name: hello Namespace: default Age: 13m URL: http://hello-default.apps-crc.testing Revisions: 100% @latest (hello-dghll-2) [2] (1m) Image: docker.io/openshift/hello-openshift (pinned to 5ea96b) Conditions: OK TYPE AGE REASON ++ Ready 1m ++ ConfigurationsReady 1m ++ RoutesReady 1mDelete the service:
$ kn service delete helloExample output
Service 'hello' successfully deleted in namespace 'default'.Verify that the
helloservice is deleted by attempting to list it:$ kn service list helloExample output
No services found.
9.1.2. Autoscaling workflow using kn
You can access autoscaling capabilities by using kn to modify Knative services without editing YAML files directly.
Use the service create and service update commands with the appropriate flags to configure the autoscaling behavior.
| Flag | Description |
|---|---|
|
| Hard limit of concurrent requests to be processed by a single replica. |
|
|
Recommendation for when to scale up based on the concurrent number of incoming requests. Defaults to |
|
| Maximum number of replicas. |
|
| Minimum number of replicas. |
9.1.3. Traffic splitting using kn
You can use kn to control which revisions get routed traffic on your Knative service.
Knative service supports traffic mapping, which is the mapping of revisions of the service to an allocated portion of traffic. It offers the option to create unique URLs for particular revisions and has the ability to assign traffic to the latest revision.
With every update to the configuration of the service, a new revision is created with the service route pointing all the traffic to the latest ready revision by default. You can change this behavior by defining which revision gets a portion of the traffic.
Procedure
Use the
kn service updatecommand with the--trafficflag to update the traffic.For example, to route 10% of traffic to a new revision before putting all traffic on:
$ kn service update svc --traffic @latest=10 --traffic svc-vwxyz=90--traffic RevisionName=Percentuses the following syntax:-
The
--trafficflag requires two values separated by separated by an equals sign (=). -
The
RevisionNamestring refers to the name of the revision. -
Percentinteger denotes the traffic portion assigned to the revision. -
Use identifier
@latestfor the RevisionName to refer to the latest ready revision of the service. You can use this identifier only once with the--trafficflag. -
If the
service updatecommand updates the configuration values for the service along with traffic flags, the@latestreference points to the created revision to which the updates are applied. -
--trafficflag can be specified multiple times and is valid only if the sum of thePercentvalues in all flags totals 100.
-
The
9.1.3.1. Assigning tag revisions
A tag in a traffic block of a service creates a custom URL, which points to a referenced revision. A user can define a unique tag for an available revision of a service which creates a custom URL by using the format http(s)://TAG-SERVICE.DOMAIN.
A given tag must be unique to its traffic block of the service. kn supports assigning and unassigning custom tags for revisions of services as part of the kn service update command.
If you have assigned a tag to a particular revision, a user can reference the revision by its tag in the --traffic flag as --traffic Tag=Percent.
Procedure
Assign tag revisions by updating the service:
$ kn service update svc --tag @latest=candidate --tag svc-vwxyz=current--tag RevisionName=Taguses the following syntax:-
--tagflag requires two values separated by a=. -
RevisionNamestring refers to name of theRevision. -
Tagstring denotes the custom tag to be given for this Revision. -
Use the identifier
@latestfor theRevisionNameto refer to the latest ready revision of the service. You can use this identifier only once with the--tagflag. -
If the
service updatecommand is updating the configuration values for the service, along with tag flags, the@latestreference points to the created revision after applying the update. -
--tagflag can be specified multiple times. -
--tagflag may assign different tags to the same revision.
-
9.1.3.2. Unassigning tag revisions
Tags assigned to revisions in a traffic block can be unassigned. Unassigning tags removes the custom URLs.
If a revision is untagged and it is assigned 0% of the traffic, it is removed from the traffic block entirely.
Procedure
Unassign tags for revisions using the
kn service updatecommand:$ kn service update svc --untag candidate--untag Taguses the following syntax:-
The
--untagflag requires one value. -
The
tagstring denotes the unique tag in the traffic block of the service which needs to be unassigned. This also removes the respective custom URL. -
The
--untagflag can be specified multiple times.
-
The
9.1.3.3. Traffic flag operation precedence
All traffic-related flags can be specified using a single kn service update command. kn defines the precedence of these flags. The order of the flags specified when using the command is not taken into account.
The precedence of the flags as they are evaluated by kn are:
-
--untag: All the referenced revisions with this flag are removed from the traffic block. -
--tag: Revisions are tagged as specified in the traffic block. -
--traffic: The referenced revisions are assigned a portion of the traffic split.
9.1.3.4. Traffic splitting flags
kn supports traffic operations on the traffic block of a service as part of the kn service update command.
The following table displays a summary of traffic splitting flags, value formats, and the operation the flag performs. The Repetition column denotes whether repeating the particular value of flag is allowed in a kn service update command.
| Flag | Value(s) | Operation | Repetition |
|---|---|---|---|
|
|
|
Gives | Yes |
|
|
|
Gives | Yes |
|
|
|
Gives | No |
|
|
|
Gives | Yes |
|
|
|
Gives | No |
|
|
|
Removes | Yes |
9.2. Configuring Knative Serving autoscaling
OpenShift Serverless provides capabilities for automatic pod scaling, including scaling inactive pods to zero, by enabling the Knative Serving autoscaling system in an OpenShift Container Platform cluster. To enable autoscaling for Knative Serving, you must configure concurrency and scale bounds in the revision template.
Any limits or targets set in the revision template are measured against a single instance of your application. For example, setting the target annotation to 50 will configure the autoscaler to scale the application so that each instance of it will handle 50 requests at a time.
9.2.1. Configuring concurrent requests for Knative Serving autoscaling
You can specify the number of concurrent requests that should be handled by each instance of an application (revision container) by adding the target annotation or the containerConcurrency field in the revision template.
Here is an example of target being used in a revision template:
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: myapp
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/target: 50
spec:
containers:
- image: myimage
Here is an example of containerConcurrency being used in a revision template:
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: myapp
spec:
template:
metadata:
annotations:
spec:
containerConcurrency: 100
containers:
- image: myimage
Adding a value for both target and containerConcurrency will target the target number of concurrent requests, but impose a hard limit of the containerConcurrency number of requests. For example, if the target value is 50 and the containerConcurrency value is 100, the targeted number of requests will be 50, but the hard limit will be 100.
If the containerConcurrency value is less than the target value, the target value will be tuned down, since there is no need to target more requests than the number that can actually be handled.
containerConcurrency should only be used if there is a clear need to limit how many requests reach the application at a given time. Using containerConcurrency is only advised if the application needs to have an enforced constraint of concurrency.
9.2.1.1. Configuring concurrent requests using the target annotation
The default target for the number of concurrent requests is 100, but you can override this value by adding or modifying the autoscaling.knative.dev/target annotation value in the revision template.
Here is an example of how this annotation is used in the revision template to set the target to 50.
autoscaling.knative.dev/target: 509.2.1.2. Configuring concurrent requests using the containerConcurrency field
containerConcurrency sets a hard limit on the number of concurrent requests handled.
containerConcurrency: 0 | 1 | 2-N- 0
- allows unlimited concurrent requests.
- 1
- guarantees that only one request is handled at a time by a given instance of the revision container.
- 2 or more
- will limit request concurrency to that value.
If there is no target annotation, autoscaling is configured as if target is equal to the value of containerConcurrency.
9.2.2. Configuring scale bounds Knative Serving autoscaling
The minScale and maxScale annotations can be used to configure the minimum and maximum number of pods that can serve applications. These annotations can be used to prevent cold starts or to help control computing costs.
- minScale
-
If the
minScaleannotation is not set, pods scale to zero, or to 1 ifenable-scale-to-zeroisfalsein theConfigMap. - maxScale
-
If the
maxScaleannotation is not set, there is no upper limit for the number of pods that can be created.
minScale and maxScale can be configured as follows in the revision template:
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/minScale: "2"
autoscaling.knative.dev/maxScale: "10"
Using these annotations in the revision template will propagate this configuration to PodAutoscaler objects.
These annotations apply for the full lifetime of a revision. Even when a revision is not referenced by any route, the minimal pod count specified by minScale is still provided. Keep in mind that non-routeable revisions may be garbage collected, which allows Knative to reclaim the resources.
9.3. Cluster logging with OpenShift Serverless
9.3.1. Cluster logging
OpenShift Container Platform cluster administrators can deploy cluster logging using a few CLI commands and the OpenShift Container Platform web console to install the Elasticsearch Operator and Cluster Logging Operator. When the operators are installed, create a ClusterLogging custom resource (CR) to schedule cluster logging pods and other resources necessary to support cluster logging. The operators are responsible for deploying, upgrading, and maintaining cluster logging.
You can configure cluster logging by modifying the ClusterLogging custom resource (CR), named instance. The CR defines a complete cluster logging deployment that includes all the components of the logging stack to collect, store and visualize logs. The Cluster Logging Operator watches the ClusterLogging Custom Resource and adjusts the logging deployment accordingly.
Administrators and application developers can view the logs of the projects for which they have view access.
9.3.2. About deploying and configuring cluster logging
OpenShift Container Platform cluster logging is designed to be used with the default configuration, which is tuned for small to medium sized OpenShift Container Platform clusters.
The installation instructions that follow include a sample ClusterLogging custom resource (CR), which you can use to create a cluster logging instance and configure your cluster logging deployment.
If you want to use the default cluster logging install, you can use the sample CR directly.
If you want to customize your deployment, make changes to the sample CR as needed. The following describes the configurations you can make when installing your cluster logging instance or modify after installation. See the Configuring sections for more information on working with each component, including modifications you can make outside of the ClusterLogging custom resource.
9.3.2.1. Configuring and Tuning Cluster Logging
You can configure your cluster logging environment by modifying the ClusterLogging custom resource deployed in the openshift-logging project.
You can modify any of the following components upon install or after install:
- Memory and CPU
-
You can adjust both the CPU and memory limits for each component by modifying the
resourcesblock with valid memory and CPU values:
spec:
logStore:
elasticsearch:
resources:
limits:
cpu:
memory: 16Gi
requests:
cpu: 500m
memory: 16Gi
type: "elasticsearch"
collection:
logs:
fluentd:
resources:
limits:
cpu:
memory:
requests:
cpu:
memory:
type: "fluentd"
visualization:
kibana:
resources:
limits:
cpu:
memory:
requests:
cpu:
memory:
type: kibana
curation:
curator:
resources:
limits:
memory: 200Mi
requests:
cpu: 200m
memory: 200Mi
type: "curator"- Elasticsearch storage
-
You can configure a persistent storage class and size for the Elasticsearch cluster using the
storageClassnameandsizeparameters. The Cluster Logging Operator creates aPersistentVolumeClaimfor each data node in the Elasticsearch cluster based on these parameters.
spec:
logStore:
type: "elasticsearch"
elasticsearch:
nodeCount: 3
storage:
storageClassName: "gp2"
size: "200G"
This example specifies each data node in the cluster will be bound to a PersistentVolumeClaim that requests "200G" of "gp2" storage. Each primary shard will be backed by a single replica.
Omitting the storage block results in a deployment that includes ephemeral storage only.
spec:
logStore:
type: "elasticsearch"
elasticsearch:
nodeCount: 3
storage: {}- Elasticsearch replication policy
You can set the policy that defines how Elasticsearch shards are replicated across data nodes in the cluster:
-
FullRedundancy. The shards for each index are fully replicated to every data node. -
MultipleRedundancy. The shards for each index are spread over half of the data nodes. -
SingleRedundancy. A single copy of each shard. Logs are always available and recoverable as long as at least two data nodes exist. -
ZeroRedundancy. No copies of any shards. Logs may be unavailable (or lost) in the event a node is down or fails.
-
- Curator schedule
- You specify the schedule for Curator in the cron format.
spec:
curation:
type: "curator"
resources:
curator:
schedule: "30 3 * * *"9.3.2.2. Sample modified ClusterLogging custom resource
The following is an example of a ClusterLogging custom resource modified using the options previously described.
Sample modified ClusterLogging custom resource
apiVersion: "logging.openshift.io/v1"
kind: "ClusterLogging"
metadata:
name: "instance"
namespace: "openshift-logging"
spec:
managementState: "Managed"
logStore:
type: "elasticsearch"
elasticsearch:
nodeCount: 3
resources:
limits:
memory: 32Gi
requests:
cpu: 3
memory: 32Gi
storage: {}
redundancyPolicy: "SingleRedundancy"
visualization:
type: "kibana"
kibana:
resources:
limits:
memory: 1Gi
requests:
cpu: 500m
memory: 1Gi
replicas: 1
curation:
type: "curator"
curator:
resources:
limits:
memory: 200Mi
requests:
cpu: 200m
memory: 200Mi
schedule: "*/5 * * * *"
collection:
logs:
type: "fluentd"
fluentd:
resources:
limits:
memory: 1Gi
requests:
cpu: 200m
memory: 1Gi9.3.3. Using cluster logging to find logs for Knative Serving components
Procedure
To open the Kibana UI, the visualization tool for Elasticsearch, use the following command to get the Kibana route:
$ oc -n openshift-logging get route kibana- Use the route’s URL to navigate to the Kibana dashboard and log in.
- Ensure the index is set to .all. If the index is not set to .all, only the OpenShift Container Platform system logs are listed.
You can filter the logs by using the
knative-servingnamespace. Enterkubernetes.namespace_name:knative-servingin the search box to filter results.NoteKnative Serving uses structured logging by default. You can enable parsing of these logs by customizing the cluster logging Fluentd settings. This enables filtering at the log level to quickly identify issues.
9.3.4. Using cluster logging to find logs for services deployed with Knative Serving
With OpenShift Container Platform cluster logging, the logs that your applications write to the console are collected in Elasticsearch. The following procedure outlines how to apply these capabilities to applications deployed by using Knative Serving.
Procedure
Find the Kibana URL:
$ oc -n cluster-logging get route kibana- Enter the URL in your browser to open the Kibana UI.
- Ensure the index is set to .all. If the index is not set to .all, only the OpenShift Container Platform system logs are listed.
Filter the logs by using the Kubernetes namespace your service is deployed in. Add a filter to identify the service itself:
kubernetes.namespace_name:default AND kubernetes.labels.serving_knative_dev\/service:{SERVICE_NAME}.NoteYou can also filter by using
/configurationor/revision.You can narrow your search by using
kubernetes.container_name:<user-container>to only display the logs generated by your application. Otherwise, you will see logs from the queue-proxy.NoteUse JSON-based structured logging in your application to allow for the quick filtering of these logs in production environments.
9.4. Splitting traffic between revisions
9.4.1. Splitting traffic between revisions using the Developer perspective
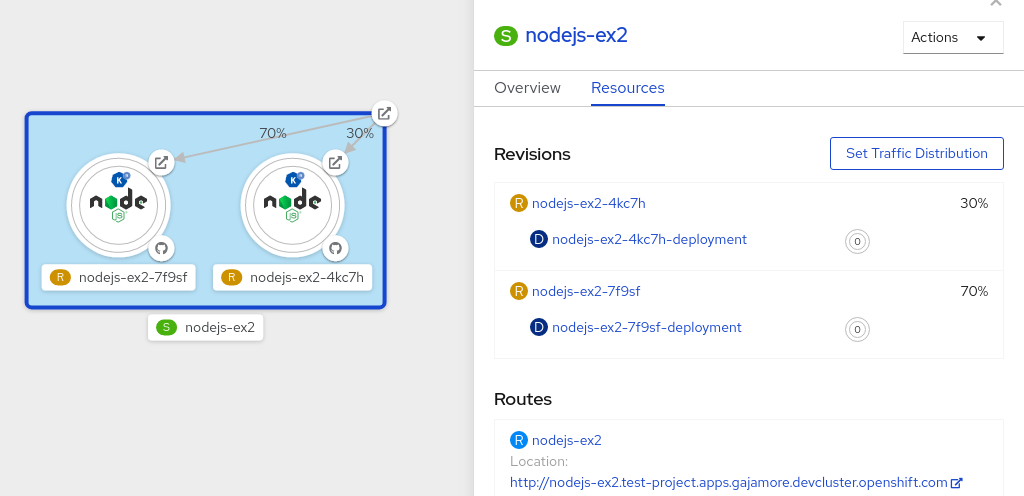
After you create a serverless application, the serverless application is displayed in the Topology view of the Developer perspective. The application revision is represented by the node and the serverless resource service is indicated by a quadrilateral around the node.
Any new change in the code or the service configuration triggers a revision, a snapshot of the code at a given time. For a service, you can manage the traffic between the revisions of the service by splitting and routing it to the different revisions as required.
Procedure
To split traffic between multiple revisions of an application in the Topology view:
- Click the serverless resource service, indicated by the quadrilateral, to see its overview in the side panel.
Click the Resources tab, to see a list of Revisions and Routes for the service.
Figure 9.1. Serverless application
- Click the service, indicated by the S icon at the top of the side panel, to see an overview of the service details.
-
Click the YAML tab and modify the service configuration in the YAML editor, and click Save. For example, change the
timeoutsecondsfrom 300 to 301 . This change in the configuration triggers a new revision. In the Topology view, the latest revision is displayed and the Resources tab for the service now displays the two revisions. In the Resources tab, click the button to see the traffic distribution dialog box:
- Add the split traffic percentage portion for the two revisions in the Splits field.
- Add tags to create custom URLs for the two revisions.
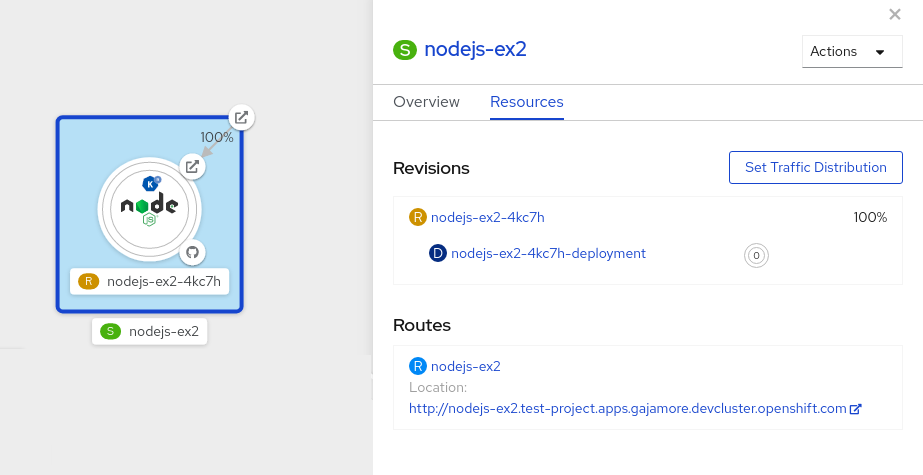
Click Save to see two nodes representing the two revisions in the Topology view.
Figure 9.2. Serverless application revisions