6.3. ツール
I/O サブシステムのパフォーマンス問題の診断に役立つツールは、数多くあります。vmstat は、システムパフォーマンスの概要を提供します。それに続くコラムは、I/O に最も関連するものです:
si (swap in)、so (swap out)、bi (block in)、 bo (block out)、wa (I/O wait time)。si と so は、スワップ領域がデータパーティションと同じデバイス上にある時、および全体のメモリプレッシャーの指標として便利です。si と bi は読み取り操作で、so と bo は書き込み操作です。各カテゴリーはキロバイトでレポートされます。wa はアイドル時間で、実行キューのどの部分がブロックされて I/O の完了を待っているかを示します。
vmstat でシステムを分析することで、I/O サブシステムがパフォーマンス問題の原因であるかどうかが分かります。
free、buff、cache のコラムも注目に値します。cache の値が bo の値とともに増えて、その後に cache が減少し free が増えていれば、システムはページキャッシュのライトバックと無効化を実行していることを示します。
vmstat がレポートする I/O 数は、全デバイスへの全 I/O の合計であることに注意してください。I/O サブシステムにパフォーマンスギャップがあるかもしれないと判断したら、iostat でより詳細に問題を調べることができます。これは、デバイスごとに I/O レポートティングを分類します。また、要求の平均サイズや 1 秒ごとの読み取りおよび書き込み数、進行中の I/O マージの量など、さらなる詳細情報を引き出すこともできます。
要求の平均サイズとキューの平均サイズ (
avgqu-sz) を使うと、ストレージのパフォーマンスを特徴付ける際に生成したグラフを使って、ストレージのパフォーマンスを予想することができます。ここでは一般化が適用されます。例えば、要求の平均サイズが 4KB でキューの平均サイズが 1 の場合、スループットが非常に高性能である可能性は低くなります。
パフォーマンス数が予想するパフォーマンスにマッピングされない場合、blktrace を使ってより粒度の細かい分析を実行できます。blktrace ユーティリティは、I/O サブシステムに費やされる時間についての詳細な情報を提供します。blktrace の出力はバイナリー追跡ファイルで、これは blkparse のような別のユーティリティで後処理することができます。
blkparse は blktrace の仲間のユーティリティです。トレースから raw 出力を読み取り、簡略なテキストバージョンを作成します。
以下は blktrace 出力の例です。
8,64 3 1 0.000000000 4162 Q RM 73992 + 8 [fs_mark]
8,64 3 0 0.000012707 0 m N cfq4162S / alloced
8,64 3 2 0.000013433 4162 G RM 73992 + 8 [fs_mark]
8,64 3 3 0.000015813 4162 P N [fs_mark]
8,64 3 4 0.000017347 4162 I R 73992 + 8 [fs_mark]
8,64 3 0 0.000018632 0 m N cfq4162S / insert_request
8,64 3 0 0.000019655 0 m N cfq4162S / add_to_rr
8,64 3 0 0.000021945 0 m N cfq4162S / idle=0
8,64 3 5 0.000023460 4162 U N [fs_mark] 1
8,64 3 0 0.000025761 0 m N cfq workload slice:300
8,64 3 0 0.000027137 0 m N cfq4162S / set_active wl_prio:0 wl_type:2
8,64 3 0 0.000028588 0 m N cfq4162S / fifo=(null)
8,64 3 0 0.000029468 0 m N cfq4162S / dispatch_insert
8,64 3 0 0.000031359 0 m N cfq4162S / dispatched a request
8,64 3 0 0.000032306 0 m N cfq4162S / activate rq, drv=1
8,64 3 6 0.000032735 4162 D R 73992 + 8 [fs_mark]
8,64 1 1 0.004276637 0 C R 73992 + 8 [0]
このように、出力は高密度で読みづらいものです。どのプロセスがデバイスに I/O 出力を発行しているかが分かり有用ですが、blkparse を使うと追加情報のサマリーが理解しやすい形式で提供されます。blkparse のサマリー情報は、出力の一番最後に印刷されます。
Total (sde):
Reads Queued: 19, 76KiB Writes Queued: 142,183, 568,732KiB
Read Dispatches: 19, 76KiB Write Dispatches: 25,440, 568,732KiB
Reads Requeued: 0 Writes Requeued: 125
Reads Completed: 19, 76KiB Writes Completed: 25,315, 568,732KiB
Read Merges: 0, 0KiB Write Merges: 116,868, 467,472KiB
IO unplugs: 20,087 Timer unplugs: 0
サマリーでは、平均 I/O 率とマージアクティビティが示され、読み取りワークロードと書き込みワークロードが比較されています。しかしほとんどの部分で、blkparse の出力はそれ自体を活用するには膨大すぎるものです。幸いにも、このデータを視覚化するのに役立つツールがいくつかあります。
btt は、I/O スタックの異なるエリアで I/O が費やした時間の分析を提供します。これらのエリアは以下のとおりです。
- Q — ブロック I/O がキュー待ち
- G — 要求を取得新たにキュー待ちとなったブロック I/O は既存要求とマージする候補ではないので、新たなブロック層要求が割り当てられます。
- M — ブロック I/O 既存の要求とマージされます。
- I — 要求がデバイスのキューに挿入されます。
- D — 要求がデバイスに発行されます。
- C — 要求がドライバーによって完了されます。
- P — ブロックデバイスキューが接続され、要求の集合を許可します。
- U — デバイスキューが除外され、要求の集合のデバイスへの発行を許可します。
btt は、以下のようにエリア間の移動に費やされた時間に加えて、各エリアで費やされた時間も分類します。
- Q2Q — ブロック層に送信された要求間の時間
- Q2G — ブロック I/O がキュー待ちになってから要求が割り当てられるまでの時間
- G2I — 要求が割り当てられてからデバイスのキューに挿入されるまでの時間
- Q2M — ブロック I/O がキュー待ちになってから既存の要求とマージされるまでの時間
- I2D — 要求がデバイスのキューに挿入されてから実際にデバイスに発行されるまでの時間
- M2D — ブロック I/O が既存の要求とマージしてから要求がデバイスに発行されるまでの時間
- D2C — デバイスによる要求のサービス時間
- Q2C — 要求がブロック層で費やした合計時間
上記の表からワークロードについて多くのことを導き出すことができます。例えば、Q2Q が Q2C よりもかなり大きいとすると、アプリケーションが I/O を間断なく発行していないことになります。つまり、パフォーマンス問題は I/O サブシステムに全く関係していない可能性があります。D2C が非常に高い場合は、デバイスが要求を実行するのに長い時間かかっていることになります。これが意味するのは、デバイスは単にオーバーロードとなっている (共有リソースだからという理由で) か、デバイスに送信されたワークロードが最適なものではないということです。Q2G が非常に高い場合は、同時にキュー待ちとなっている要求が多くあることを意味します。つまり、ストレージが I/O 負荷に対応できないことを示しています。
最後に、seekwatcher は blktrace バイナリーデータを消費し、論理ブロックアドレス (LBA) やスループット、1 秒あたりのシーク回数、1 秒あたりの I/O (IOPS) を含むプロットのセットを作成します。
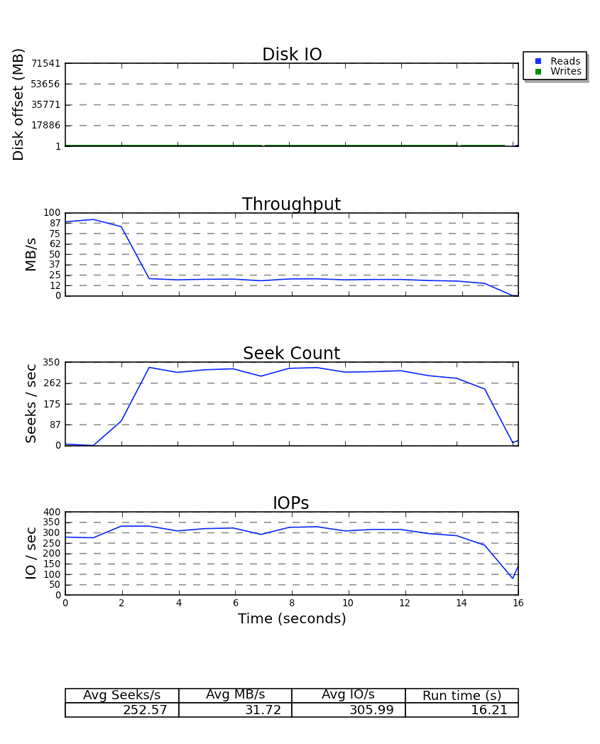
図6.2 seekwatcher の出力例
x 軸は全プロットの使用時間です。LBA プロットは、読み取りと書き込みで違う色になっています。スループットと 1 秒あたりのシーク回数のグラフの関係が興味深いものになっています。シーク回数に影響を受けやすいストレージでは、この 2 つのプロット間に逆の関係が存在します。IOPS グラフは、例えばデバイスから予想されるスループットが得られていないのに IOPS 制限に達している際などに便利なものです。