8.5. Aggregator
概要
図8.5「Aggreagator パターン」 に示されている Aggregator パターンにより、関連するメッセージのバッチを単一のメッセージにまとめることができます。
図8.5 Aggreagator パターン

Aggregator の動作を制御するため、Apache Camel では以下のようにEnterprise Integration Patternsで説明されているプロパティーを指定できます。
- 相関式: 集約するメッセージを決定します。相関式は各受信メッセージに対して評価され、相関キー を生成します。同じ相関キーを持つ受信メッセージは、同じバッチにグループ化されます。たとえば、すべての 受信メッセージを 1 つのメッセージに集約する場合は、定数式を使用することができあす。
- 完了条件: メッセージのバッチが完了したかどうかを決定します。これは単純なサイズ制限として指定することもでき、より一般的には、バッチ完了を示すフラグを述語条件として指定することもできます。
- 集約アルゴリズム: 特定の相関キーを持つメッセージエクスチェンジを単一のメッセージエクスチェンジに統合します。
たとえば、毎秒 30,000 通のメッセージを受信する株式市場のデータシステムについて考えてみましょう。GUI ツールがこのような大規模の更新レートに対応できない場合は、メッセージフローをスロットルダウンした方がよい場合があります。単純に最新の気配値を選択して古い値を破棄することで、入力される株の気配値を集約することができます (一部の履歴をキャプチャーする場合は、delta 処理アルゴリズムを適用することができます)。
Aggregator はより多くの情報を含む ManagedAggregateProcessorMBean を使い、JMX へ登録されるようになりました。これにより、集約コントローラーを使い制御できるようになります。
Aggregator の仕組み
図8.6「Aggregator の実装」 は、A、B、C、D などの相関キーを持つエクスチェンジのストリームを使用して、Aggragator がどのように動作するか概要を示しています。
図8.6 Aggregator の実装
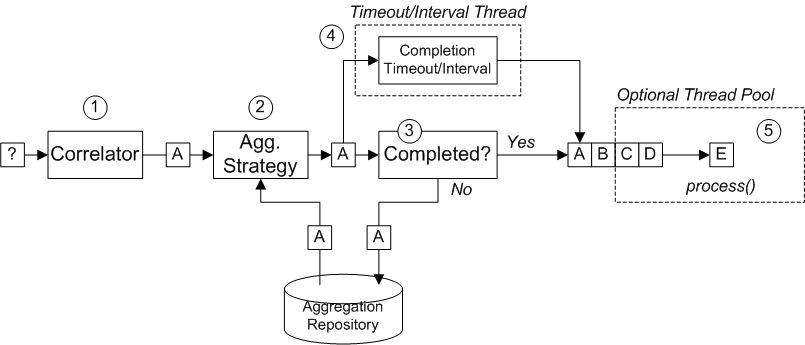
図8.6「Aggregator の実装」 に示されているエクスチェンジの受信ストリームは、以下のように処理されます。
- Correlator は、相関キーに基づいてエクスチェンジをソートします。各受信メッセージごとに相関式が評価され、相関キーを生成します。たとえば、図8.6「Aggregator の実装」 で示されているエクスチェンジでは、相関キーは A と評価されます。
集約ストラテジー は、同じ相関キーを持つエクスチェンジをマージします。新しいエクスチェンジ A が到達すると、Aggregator は集約リポジトリーで対応する 集約エクスチェンジ (A') を検索し、新しいエクスチェンジと結合します。
特定の集約サイクルが完了するまで、受信したエクスチェンジは、対応する集約エクスチェンジへ継続的に集約されます。集約サイクルは、完了メカニズムのいずれかによって終了されるまで継続されます。
注記Camel 2.16 から、新しい XSLT 集約ストラテジー により、2 つのメッセージを XSLT ファイルでマージできるようになりました。ツールボックスから
AggregationStrategies.xslt()ファイルにアクセスできます。Aggregator に完了述語が指定された場合、集約エクスチェンジをテストし、ルートの次のプロセッサーに送信する準備ができているかどうかを判断します。以下のように処理を続けます。
- 完了したら、集約エクスチェンジはルートの後半部分で処理されます。2 つの代替えモデルがあります。1 つは、同期 (デフォルト) で、呼び出しスレッドがブロックされます。2 つ目は 非同期 (並列処理が有効になっている場合) で、集約エクスチェンジはエクゼキュータースレッドプールに送信されます (図8.6「Aggregator の実装」 を参照)。
- 完了していない場合、集約エクスチェンジは集約リポジトリーに戻されます。
-
同期的な完了テストの他、
completionTimeoutオプションまたはcompletionIntervalオプションの いずれか を有効にすることで、非同期的な完了テストを有効にすることができます。これらの完了テストは別のスレッドで実行され、完了テストを満すたびに、対応するエクスチェンジが完了としてマークされ、ルートの後半部分によって処理されます (並列処理が有効かどうかによって、同期または非同期的に処理されます)。 - 並列処理が有効な場合、スレッドプールがルートの後半部分でエクスチェンジを処理します。デフォルトでは、このスレッドプールには 10 個のスレッドが含まれますが、プールをカスタマイズすることもできます (「スレッドオプション」)。
Java DSL の例
以下の例は、UseLatestAggregationStrategy 集計ストラテジーを使用して、同じ StockSymbol ヘッダー値を持つエクスチェンジを集約しています。指定された StockSymbol 値について、その相関キーを持つエクスチェンジを最後に受信してから 3 秒以上経過すると、集約されたエクスチェンジは完了とみなされ、mock エンドポイントに送信されます。
from("direct:start")
.aggregate(header("id"), new UseLatestAggregationStrategy())
.completionTimeout(3000)
.to("mock:aggregated");XML DSL の例
以下の例は、XML で同じルートを設定する方法を示しています。
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<aggregate strategyRef="aggregatorStrategy"
completionTimeout="3000">
<correlationExpression>
<simple>header.StockSymbol</simple>
</correlationExpression>
<to uri="mock:aggregated"/>
</aggregate>
</route>
</camelContext>
<bean id="aggregatorStrategy"
class="org.apache.camel.processor.aggregate.UseLatestAggregationStrategy"/>相関式の指定
Java DSL では、相関式は常に第 1 引数として aggregate() DSL コマンドに渡されます。ここでは、Simple 式言語の使用に制限はありません。XPath、XQuery、SQL などの式言語やスクリプト言語を使用して、相関式を指定することができます。
例えば、XPath 式を使用してエクスチェンジを相関させるには、以下の Java DSL ルートを使用します。
from("direct:start")
.aggregate(xpath("/stockQuote/@symbol"), new UseLatestAggregationStrategy())
.completionTimeout(3000)
.to("mock:aggregated");
特定の受信エクスチェンジで相関式を評価することができない場合、Aggregator はデフォルトで CamelExchangeException を出力します。ignoreInvalidCorrelationKeys オプションを設定することで、この例外を抑制できます。たとえば、Java DSL の場合は以下のようになります。
from(...).aggregate(...).ignoreInvalidCorrelationKeys()
XML DSL では、以下のように ignoreInvalidCorrelationKeys オプションを属性として設定できます。
<aggregate strategyRef="aggregatorStrategy"
ignoreInvalidCorrelationKeys="true"
...>
...
</aggregate>集約ストラテジーの指定
Java DSL では、集約ストラテジーを第 2 引数として aggregate() DSL コマンドに渡すか、aggregationStrategy() 句を使用して指定できます。たとえば、以下のように aggregationStrategy() 句を使用できます。
from("direct:start")
.aggregate(header("id"))
.aggregationStrategy(new UseLatestAggregationStrategy())
.completionTimeout(3000)
.to("mock:aggregated");
Apache Camel は、以下の基本的な集約ストラテジーを提供しています (各クラスは org.apache.camel.processor.aggregate Java パッケージ配下に属します)。
UseLatestAggregationStrategy- 指定された相関キーの最後のエクスチェンジを返し、このキーとの以前のエクスチェンジをすべて破棄します。たとえば、このストラテジーは、特定の株式シンボルの最新価格のみを確認する場合、証券取引所からのフィードをスロットリングするのに役立ちます。
UseOriginalAggregationStrategy-
指定された相関キーの最初のエクスチェンジを返し、このキーを持つそれ以降のすべてのエクスチェンジを破棄します。このストラテジーを使用する前に、
UseOriginalAggregationStrategy.setOriginal()を呼び出して、最初のエクスチェンジを設定する必要があります。 GroupedExchangeAggregationStrategy-
指定された相関キーの all のエクスチェンジをリストに連結し、
Exchange.GROUPED_EXCHANGEエクスチェンジプロパティーに保存します。「グループ化されたエクスチェンジ」を参照してください。
カスタム集約ストラテジーの実装
別の集計ストラテジーを適用する場合は、以下の集計ストラテジーのベースとなるインターフェースのいずれかを実装することができます。
org.apache.camel.processor.aggregate.AggregationStrategy- 基本的な Aggregation Strategy インターフェイス。
org.apache.camel.processor.aggregate.TimeoutAwareAggregationStrategy集約サイクルのタイムアウト時にお使いの実装で通知を受け取る場合は、このインターフェイスを実装します。
timeout通知メソッドには、以下の署名があります。void timeout(Exchange oldExchange, int index, int total, long timeout)org.apache.camel.processor.aggregate.CompletionAwareAggregationStrategy集約サイクルが正常に完了したときにお使いの実装で通知を受け取る場合は、このインターフェイスを実装します。通知メソッドには、以下の署名があります。
void onCompletion(Exchange exchange)
たとえば、以下のコードは、StringAggregationStrategy および ArrayListAggregationStrategy の 2 つの異なるカスタム集計ストラテジーを示しています。
//simply combines Exchange String body values using '' as a delimiter
class StringAggregationStrategy implements AggregationStrategy {
public Exchange aggregate(Exchange oldExchange, Exchange newExchange) {
if (oldExchange == null) {
return newExchange;
}
String oldBody = oldExchange.getIn().getBody(String.class);
String newBody = newExchange.getIn().getBody(String.class);
oldExchange.getIn().setBody(oldBody + "" + newBody);
return oldExchange;
}
}
//simply combines Exchange body values into an ArrayList<Object>
class ArrayListAggregationStrategy implements AggregationStrategy {
public Exchange aggregate(Exchange oldExchange, Exchange newExchange) {
Object newBody = newExchange.getIn().getBody();
ArrayList<Object> list = null;
if (oldExchange == null) {
list = new ArrayList<Object>();
list.add(newBody);
newExchange.getIn().setBody(list);
return newExchange;
} else {
list = oldExchange.getIn().getBody(ArrayList.class);
list.add(newBody);
return oldExchange;
}
}
}
Apache Camel 2.0 以降、AggregationStrategy.aggregate() コールバックメソッドも最初のエクスチェンジに対して呼び出されます。aggregate メソッドの最初の呼び出しでは、oldExchange パラメーターは null であり、newExchange パラメーターに最初の受信エクスチェンジが含まれます。
カスタムストラテジークラス ArrayListAggregationStrategy を使用してメッセージを集約するには、以下のようなルートを定義します。
from("direct:start")
.aggregate(header("StockSymbol"), new ArrayListAggregationStrategy())
.completionTimeout(3000)
.to("mock:result");以下のように、XML でカスタム集約ストラテジーを使用してルートを設定することもできます。
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<aggregate strategyRef="aggregatorStrategy"
completionTimeout="3000">
<correlationExpression>
<simple>header.StockSymbol</simple>
</correlationExpression>
<to uri="mock:aggregated"/>
</aggregate>
</route>
</camelContext>
<bean id="aggregatorStrategy" class="com.my_package_name.ArrayListAggregationStrategy"/>カスタム集約ストラテジーのライフサイクルの管理
カスタム集約ストラテジーを実装し、そのライフサイクルを、それを管理しているエンタープライズインテグレーションパターンのライフサイクルに合わせることができます。これは、集約ストラテジーが正常にシャットダウンできることを保証するのに役立ちます。
ライフサイクルをサポートする集約ストラテジーを実装するには、org.apache.camel.Service インターフェイスを実装し (AggregationStrategy インターフェイスに加えて)、start() および stop() ライフサイクルメソッドの実装を提供する必要があります。たとえば、以下のコード例は、ライフサイクルをサポートする集約ストラテジーの概要を示しています。
// Java
import org.apache.camel.processor.aggregate.AggregationStrategy;
import org.apache.camel.Service;
import java.lang.Exception;
...
class MyAggStrategyWithLifecycleControl
implements AggregationStrategy, Service {
public Exchange aggregate(Exchange oldExchange, Exchange newExchange) {
// Implementation not shown...
...
}
public void start() throws Exception {
// Actions to perform when the enclosing EIP starts up
...
}
public void stop() throws Exception {
// Actions to perform when the enclosing EIP is stopping
...
}
}エクスチェンジプロパティー
以下のプロパティーは、集約された各エクスチェンジ毎に設定されます。
| ヘッダー | 型 | 集約されたエクスチェンジ プロパティーに関する説明 |
|---|---|---|
|
|
| このエクスチェンジに集約されたエクスチェンジの合計数。 |
|
|
|
エクスチェンジの集約を完了するためのメカニズムを示します。使用できる値は、 |
以下のプロパティーは、SQL コンポーネント集約リポジトリーによって再配信されるエクスチェンジに設定されます (「永続集計リポジトリー」 を参照)。
| ヘッダー | 型 | 再配信されたエクスチェンジプロパティー に関する説明 |
|---|---|---|
|
|
|
現在の再配信試行のシーケンス番号 ( |
完了条件の指定
集約されたエクスチェンジが Aggregator から出て、ルート上の次のノードに遷移するタイミングを判断するので、少なくとも 1 つ の完了条件を指定する必要があります。以下の完了条件を指定できます。
completionPredicate-
各エクスチェンジが集約された後に述語を評価し、完全性を評価します。
trueの値は、集約エクスチェンジが完了したことを示します。または、このオプションを設定する代わりに、Predicateインターフェイスを実装するカスタムAggregationStrategyを定義することができます。この場合、完了述語としてAggregationStrategyが使用されます。 completionSize- 指定された数の受信エクスチェンジが集約された後、エクスチェンジの集約を完了します。
completionTimeout(
completionIntervalとは互換性がありません) 指定されたタイムアウト内に受信エクスチェンジが集約されない場合、エクスチェンジの集約を完了します。つまり、タイムアウトメカニズムは 各 相関キー値のタイムアウトを追跡します。特定のキー値を持つ最新のエクスチェンジを受け取ると、クロックがカウントを開始します。指定したタイムアウト値の間に同じキー値を持つ別のエクスチェンジが受信されない 場合、対応するエクスチェンジの集約は完了とマークされ、ルート上の次のノードに遷移します。
completionInterval(
completionTimeoutとは互換性がありません) 各時間間隔 (指定された長さ) が経過した後、未処理のエクスチェンジの集約を すべて 完了します。時間間隔は、各エクスチェンジの集約毎に調整されていません。このメカニズムは、すべての未処理のエクスチェンジに対し、集約の完了を強制します。したがって、場合によっては、このメカニズムは集約開始直後にエクスチェンジの集約を完了できます。
completionFromBatchConsumer- バッチコンシューマーメカニズムをサポートするコンシューマーエンドポイントと組み合わせて使用すると、この完了オプションは、コンシューマーエンドポイントから受信した情報に基づいて、現在のエクスチェンジのバッチが完了したタイミングを自動的に算出します。「バッチコンシューマー」 を参照してください。
forceCompletionOnStop- このオプションを有効にすると、現在のルートコンテキストが停止したときに、未処理のエクスチェンジの集約をすべて強制的に完了させます。
前述の完了条件は、completionTimeout および completionInterval のみ同時に有効にできませんが、任意に組み合わせることができます。条件を組み合わせて使用する場合、最初にトリガーされた完了条件が、有効な完了条件になるのが一般的です。
完了述語の指定
エクスチェンジの集約が完了するタイミングを決定する任意の述語式を指定できます。述語式を評価する方法は 2 つあります。
- 最新の集約されたエクスチェンジ - これがデフォルトの動作です。
-
最新の受信エクスチェンジ -
eagerCheckCompletionオプションを有効にすると、この動作が選択されます。
たとえば、ALERT メッセージを受信するたびに (最新の受信エクスチェンジの MsgType ヘッダーの値で示される)、株式相場のストリームを終了させたい場合は、以下のようなルートを定義できます。
from("direct:start")
.aggregate(
header("id"),
new UseLatestAggregationStrategy()
)
.completionPredicate(
header("MsgType").isEqualTo("ALERT")
)
.eagerCheckCompletion()
.to("mock:result");以下の例は、XML を使用して同じルートを設定する方法を示しています。
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<aggregate strategyRef="aggregatorStrategy"
eagerCheckCompletion="true">
<correlationExpression>
<simple>header.StockSymbol</simple>
</correlationExpression>
<completionPredicate>
<simple>$MsgType = 'ALERT'</simple>
</completionPredicate>
<to uri="mock:result"/>
</aggregate>
</route>
</camelContext>
<bean id="aggregatorStrategy"
class="org.apache.camel.processor.aggregate.UseLatestAggregationStrategy"/>動的な完了タイムアウトの指定
動的な完了タイムアウトを指定できます。この場合、タイムアウト値が受信エクスチェンジごとに再計算されます。たとえば、各受信エクスチェンジで timeout ヘッダーからタイムアウト値を設定するには、以下のようにルートを定義します。
from("direct:start")
.aggregate(header("StockSymbol"), new UseLatestAggregationStrategy())
.completionTimeout(header("timeout"))
.to("mock:aggregated");XML DSL で以下のように同じルートを設定できます。
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<aggregate strategyRef="aggregatorStrategy">
<correlationExpression>
<simple>header.StockSymbol</simple>
</correlationExpression>
<completionTimeout>
<header>timeout</header>
</completionTimeout>
<to uri="mock:aggregated"/>
</aggregate>
</route>
</camelContext>
<bean id="aggregatorStrategy"
class="org.apache.camel.processor.UseLatestAggregationStrategy"/>
固定のタイムアウト値を追加することもでき、動的なタイムアウト値が null または 0 であった場合、Apache Camel はこの固定値を使用するようにフォールバックします。
動的な完了サイズの指定
動的な完了サイズ を指定することが可能であり、受信エクスチェンジ毎に完了サイズは再計算されます。たとえば、各受信エクスチェンジの mySize ヘッダーから完了サイズを設定するには、以下のようにルートを定義します。
from("direct:start")
.aggregate(header("StockSymbol"), new UseLatestAggregationStrategy())
.completionSize(header("mySize"))
.to("mock:aggregated");Spring XML を使用した同じ例を以下に示します。
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<aggregate strategyRef="aggregatorStrategy">
<correlationExpression>
<simple>header.StockSymbol</simple>
</correlationExpression>
<completionSize>
<header>mySize</header>
</completionSize>
<to uri="mock:aggregated"/>
</aggregate>
</route>
</camelContext>
<bean id="aggregatorStrategy"
class="org.apache.camel.processor.UseLatestAggregationStrategy"/>
固定のサイズ値を追加することもできます。動的な値が null または 0 であった場合、Apache Camel はこの固定値を使用するようにフォールバックします。
集約ストラテジー内から単一グループを強制完了
カスタム AggregationStrategy クラスを実装した場合、AggregationStrategy.aggregate() メソッドから返されたエクスチェンジで Exchange.AGGREGATION_COMPLETE_CURRENT_GROUP エクスチェンジプロパティーを true に設定することで、現在のメッセージグループを強制的に完了させる機能があります。この機能は現在のグループに のみ 影響します。他のメッセージグループ (異なる相関 ID を持つ) は強制的に完了しません。この機能は、述語、サイズ、タイムアウトなど、その他の完了機能に対して上書きされます。
たとえば、以下のサンプル AggregationStrategy クラスは、メッセージのボディーサイズが 5 より大きい場合に現在のグループを完了します。
// Java
public final class MyCompletionStrategy implements AggregationStrategy {
@Override
public Exchange aggregate(Exchange oldExchange, Exchange newExchange) {
if (oldExchange == null) {
return newExchange;
}
String body = oldExchange.getIn().getBody(String.class) + "+"
+ newExchange.getIn().getBody(String.class);
oldExchange.getIn().setBody(body);
if (body.length() >= 5) {
oldExchange.setProperty(Exchange.AGGREGATION_COMPLETE_CURRENT_GROUP, true);
}
return oldExchange;
}
}特別なメッセージですべてのグループを強制完了
特別なヘッダーを持つメッセージをルートに送信することで、未処理のメッセージの集約を強制的に完了することができます。強制完了するために使用できる代替ヘッダー設定は 2 つあります。
Exchange.AGGREGATION_COMPLETE_ALL_GROUPS-
trueに設定して、現在の集約サイクルを強制的に完了させます。このメッセージはシグナルとして純粋に機能し、いかなる集約サイクルにも含まれません。このシグナルメッセージを処理した後、メッセージの内容は破棄されます。 Exchange.AGGREGATION_COMPLETE_ALL_GROUPS_INCLUSIVE-
trueに設定して、現在の集約サイクルを強制的に完了させます。このメッセージは現在の集計サイクルに 含まれます。
AggregateController の使用
org.apache.camel.processor.aggregate.AggregateController を使用すると、Java または JMX API を使用してランタイム時に集約を制御することができます。エクスチェンジのグループを強制的に完了したり、現在のランタイム統計情報をクエリーしたりするために使われます。
カスタムが設定されていない場合、Aggregator はデフォルト実装を提供します。これは、getAggregateController() メソッドを使用してアクセスできます。ただし、aggregateController を使用して、ルート内でコントローラーを簡単に設定することができます。
private AggregateController controller = new DefaultAggregateController();
from("direct:start")
.aggregate(header("id"), new MyAggregationStrategy()).completionSize(10).id("myAggregator")
.aggregateController(controller)
.to("mock:aggregated");
また、AggregateController の API を使用して、強制的に完了することもできます。例えば、キー foo を持つグループを完了するには、次のコマンドを実行します。
int groups = controller.forceCompletionOfGroup("foo");戻り値は完了したグループの数になります。すべてのグループを完了する API は以下のとおりです。
int groups = controller.forceCompletionOfAllGroups();一意な相関キーの強制
集約シナリオによっては、エクスチェンジのバッチごとに相関キーが一意であるという条件を強制する場合があります。つまり、特定の相関キーを持つエクスチェンジの集約が完了したら、その相関キーを持つエクスチェンジの集約がこれ以上続行されないようにします。たとえば、ルートの後半部分で一意の相関キーの値を持つエクスチェンジを処理することを想定している場合に、この条件を実施することができます。
完了条件の設定方法によっては、特定の相関キーで複数のエクスチェンジの集約が生成されるリスクがある可能性があります。たとえば、特定の相関キーを持つ すべての エクスチェンジを受信するまで待機する補完述語を定義することもできますが、完了タイムアウトも定義しており、そのキーを持つすべてのエクスチェンジが到着する前に発火してしまう可能性もあります。この場合、遅れて到着するエクスチェンジは、同じ相関キーの値を持つ 2 つ目 のエクスチェンジの集約になる可能性があります。
このようなシナリオでは、closeCorrelationKeyOnCompletion オプションを設定することで、以前の相関キー値と重複した集約エクスチェンジを抑制するように Aggregator を設定することができます。相関キー値の重複を抑制するためには、Aggregator が以前の相関キーの値をキャッシュに記録する必要があります。このキャッシュのサイズ (キャッシュされた相関キーの数) は、closeCorrelationKeyOnCompletion() DSL コマンドの引数として指定されます。無制限サイズのキャッシュを指定するには、ゼロまたは負の整数値を渡します。たとえば、10000 キー値のキャッシュサイズを指定するには、次のコマンドを実行します。
from("direct:start")
.aggregate(header("UniqueBatchID"), new MyConcatenateStrategy())
.completionSize(header("mySize"))
.closeCorrelationKeyOnCompletion(10000)
.to("mock:aggregated");
相関キー値が重複している状態でエクスチェンジの集約が完了すると、Aggregator は ClosedCorrelationKeyException 例外を出力します。
Simple 式を使用したストリームベースの処理
ストリーミングモードで tokenizeXML サブコマンドを使用して、Simple 言語式をトークンとして使うことができます。Simple 言語式を使用することで、動的トークンのサポートが可能になります。
たとえば、Java を使用してタグ person で区切られた名前のシーケンスを分割するには、tokenizeXML Bean および Simple 言語トークンを使用して、ファイルを name 要素に分割することができます。
public void testTokenizeXMLPairSimple() throws Exception {
Expression exp = TokenizeLanguage.tokenizeXML("${header.foo}", null);
<person> で区切られた名前の入力文字列を取得し、<person> をトークンに設定します。
exchange.getIn().setHeader("foo", "<person>");
exchange.getIn().setBody("<persons><person>James</person><person>Claus</person><person>Jonathan</person><person>Hadrian</person></persons>");入力から分割された名前をリストします。
List<?> names = exp.evaluate(exchange, List.class);
assertEquals(4, names.size());
assertEquals("<person>James</person>", names.get(0));
assertEquals("<person>Claus</person>", names.get(1));
assertEquals("<person>Jonathan</person>", names.get(2));
assertEquals("<person>Hadrian</person>", names.get(3));
}グループ化されたエクスチェンジ
送信バッチ内の集約されたすべてのエクスチェンジを、単一の org.apache.camel.impl.GroupedExchange ホルダークラスに統合できます。グループ化されたエクスチェンジを有効にするには、以下の Java DSL ルートに示されるように groupExchanges() オプションを指定します。
from("direct:start")
.aggregate(header("StockSymbol"))
.completionTimeout(3000)
.groupExchanges()
.to("mock:result");
mock:result に送信されるグループ化されたエクスチェンジには、メッセージボディーに集約されたエクスチェンジのリストが含まれます。以下のコードは、後続のプロセッサーがリスト形式でグループ化されたエクスチェンジのコンテンツにアクセスする方法を示しています。
// Java
List<Exchange> grouped = ex.getIn().getBody(List.class);エクスチェンジをグループ化する機能を有効にする場合、集約ストラテジーを設定するべきではありません (エクスチェンジのグループ化機能は、それ自体が集約ストラテジーになります)。
送信エクスチェンジのプロパティーからグループ化されたエクスチェンジにアクセスする従来の方法は現在非推奨となっており、今後のリリースで削除される予定です。
バッチコンシューマー
Aggregator は batch consumer パターンと連携して、バッチコンシューマーによって報告されるメッセージの総数を集約できます (バッチコンシューマーエンドポイントは受信エクスチェンジで CamelBatchSize、CamelBatchIndex、および CamelBatchComplete プロパティーを設定します)。たとえば、File コンシューマーエンドポイントで見つかったすべてのファイルを集約するには、以下のようなルートを使用することができます。
from("file://inbox")
.aggregate(xpath("//order/@customerId"), new AggregateCustomerOrderStrategy())
.completionFromBatchConsumer()
.to("bean:processOrder");現在、バッチコンシューマー機能をサポートしているエンドポイントは File、FTP、Mail、iBatis、および JPA です。
永続集計リポジトリー
デフォルトの Aggregator はインメモリーのみの AggregationRepository を使用します。保留中の集約されたエクスチェンジを永続的に保存する場合は、SQL Component を永続集計リポジトリーとして使用できます。SQL コンポーネントには JdbcAggregationRepository が含まれており、集約されたメッセージをオンザフライで永続化し、メッセージを失うことがないようにします。
エクスチェンジが正常に処理された場合、リポジトリーで confirm メソッドが呼び出されると、完了とマークされます。つまり、同じエクスチェンジが再度失敗すると、成功するまで再試行さることを意味します。
camel-sql への依存関係の追加
SQL コンポーネントを使用するには、プロジェクトに camel-sql への依存関係を含める必要があります。たとえば、Maven pom.xml ファイルを使用している場合は、以下を追記します。
<dependency>
<groupId>org.apache.camel</groupId>
<artifactId>camel-sql</artifactId>
<version>x.x.x</version>
<!-- use the same version as your Camel core version -->
</dependency>集約データベーステーブルの作成
永続化のために、集約テーブルと完成テーブルをそれぞれデータベースに作成する必要があります。たとえば、以下のクエリーは my_aggregation_repo という名前のデータベーステーブルを作成します。
CREATE TABLE my_aggregation_repo (
id varchar(255) NOT NULL,
exchange blob NOT NULL,
constraint aggregation_pk PRIMARY KEY (id)
);
CREATE TABLE my_aggregation_repo_completed (
id varchar(255) NOT NULL,
exchange blob NOT NULL,
constraint aggregation_completed_pk PRIMARY KEY (id)
);
}集約リポジトリーの設定
フレームワーク XML ファイル (Spring または Blueprint など) で集約リポジトリーを設定する必要があります。
<bean id="my_repo"
class="org.apache.camel.processor.aggregate.jdbc.JdbcAggregationRepository">
<property name="repositoryName" value="my_aggregation_repo"/>
<property name="transactionManager" ref="my_tx_manager"/>
<property name="dataSource" ref="my_data_source"/>
...
</bean>
repositoryName、transactionManager、および dataSource プロパティーが必要です。永続集約リポジトリーの設定オプションの詳細は、Apache Camel コンポーネントリファレンスガイド の SQL コンポーネント を参照してください。
スレッドオプション
図8.6「Aggregator の実装」 にあるように、Aggregator はルートの後半部分から切り離されており、ルートの後半部分へ送信されたエクスチェンジは、専用のスレッドプールによって処理されます。デフォルトでは、このプールには 1 つのスレッドのみがあります。複数のスレッドを持つプールを指定する場合は、以下のように parallelProcessing オプションを有効にします。
from("direct:start")
.aggregate(header("id"), new UseLatestAggregationStrategy())
.completionTimeout(3000)
.parallelProcessing()
.to("mock:aggregated");デフォルトでは、ワーカースレッドが 10 個あるプールが作成されます。
作成したスレッドプールをより詳細に制御する場合は、executorService オプションを使用してカスタム java.util.concurrent.ExecutorService インスタンスを指定します (この場合は、parallelProcessing オプションを有効化する必要はありません)。
List への集約
一般的な集約シナリオでは、一連の受信メッセージボディーを List オブジェクトに集約します。このシナリオを容易にするため、Apache Camel は AbstractListAggregationStrategy 抽象クラスを提供しています。このクラスを手早く拡張して、こういったシチュエーションに応じた集約ストラテジーを作成できます。T 型の受信メッセージボディーは、List<T> 型のメッセージボディーを持つ完了済みエクスチェンジへと集約されます。
たとえば、一連の Integer メッセージボディーを List<Integer> オブジェクトに集約するには、以下のように定義された集約ストラテジーを使用することができます。
import org.apache.camel.processor.aggregate.AbstractListAggregationStrategy;
...
/**
* Strategy to aggregate integers into a List<Integer>.
*/
public final class MyListOfNumbersStrategy extends AbstractListAggregationStrategy<Integer> {
@Override
public Integer getValue(Exchange exchange) {
// the message body contains a number, so just return that as-is
return exchange.getIn().getBody(Integer.class);
}
}Aggregator のオプション
Aggregator は以下のオプションをサポートします。
| オプション | デフォルト | 説明 |
|---|---|---|
|
|
集約に使用する相関キーを評価するために必須な式。同じ相関キーを持つエクスチェンジが集約されます。相関キーを評価できない場合、例外が発生します。 | |
|
|
既存のすでにマージされたエクスチェンジと受信エクスチェンジを マージ するために使用される必須の | |
|
|
レジストリーで | |
|
|
集約の完了前に、既に集約されたメッセージの数。このオプションは、固定値を設定することも、動的にサイズを評価する式を使用することもできます。式は | |
|
|
集約されたエクスチェンジが完了するまで非アクティブになる時間 (ミリ秒単位) 。このオプションは、固定値として設定することも、動的にタイムアウトを評価する式を使用することもできます。式は | |
|
| Aggregator が現在すべてのエクスチェンジを集約し完了するまでに繰り返される期間 (ミリ秒単位)。Camel には、期間ごとにトリガーされるバックグラウンドタスクがあります。このオプションは completionTimeout と併用できません。使用できるのはどちらか 1 つだけです。 | |
|
|
集約されたエクスチェンジの完了時にシグナルを送る述語 ( | |
|
|
|
このオプションは、エクスチェンジがバッチコンシューマーから送信される場合に使用します。有効にすると、「Aggregator」 は、 |
|
|
|
新しい受信エクスチェンジを受け取ったときに、常に完了を確認するかどうか。このオプションは、エクスチェンジが渡される挙動が変わるため、 |
|
|
|
|
|
|
|
この機能を有効にすると、Camel は集約されたすべてのエクスチェンジを 1 つの |
|
|
| 評価できない相関キーを無視するかどうか。デフォルトでは Camel は例外を出力しますが、このオプションを有効にして状況を無視することもできます。 |
|
|
遅い エクスチェンジを受け入れるべきかどうか。これを有効にすると、相関キーがすでに完了している場合に、同じ相関キーを持つ新しいエクスチェンジを拒否することができます。その後、Camel は | |
|
|
| Camel 2.5: タイムアウトによって完了したエクスチェンジが破棄されるべきかどうか。有効にした場合、タイムアウトが発生すると集約されたメッセージは送信 されず、破棄されます。 |
|
|
現在実行中 (inflight) の集約されたエクスチェンジを追跡する | |
|
|
レジストリーで | |
|
|
| 集約が完了すると、Aggregator から送信されます。このオプションは、Camel が並列実行用に複数のスレッドを持つスレッドプールを使用するかどうかを指定します。カスタムスレッドプールが指定されていない場合、Camel は 10 個のスレッドを持つデフォルトプールを作成します。 |
|
|
| |
|
|
レジストリーで | |
|
|
| |
|
|
レジストリーで | |
|
| Aggregator を停止する場合、このオプションを使用すると、集約リポジトリーから保留中のエクスチェンジをすべて完了することができます。 | |
|
|
| 楽観的ロックを有効にします。このロックは、集約リポジトリーと組み合わせて使用できます。 |
|
| 楽観的ロックのための Retry ポリシーを設定します。 |