第 5 章 实现管道
5.1. 使用数据科学项目管道自动化工作流
在本教程的前面部分中,您使用笔记本来培训和保存您的模型。另外,您可以使用 Red Hat OpenShift AI 管道自动化这些任务。管道提供了一种方式来自动执行多个笔记本和 Python 代码。通过使用管道,您可以按时间表执行长期培训作业或重新排列模型,而无需在笔记本中手动运行它们。
在本节中,您可以使用 GUI 管道编辑器创建一个简单的管道。管道使用您在前面的小节中使用的笔记本来培训模型,然后将其保存到 S3 存储中。
您完成的管道应当类似于 6 Train Save.pipeline 文件中的值。
要探索管道编辑器,请完成以下步骤以创建自己的管道。或者,您可以跳过以下步骤,并运行 6 Train Save.pipeline 文件。
5.1.1. 创建管道
打开工作台的 JupyterLab 环境。如果启动程序不可见,点 + 打开它。
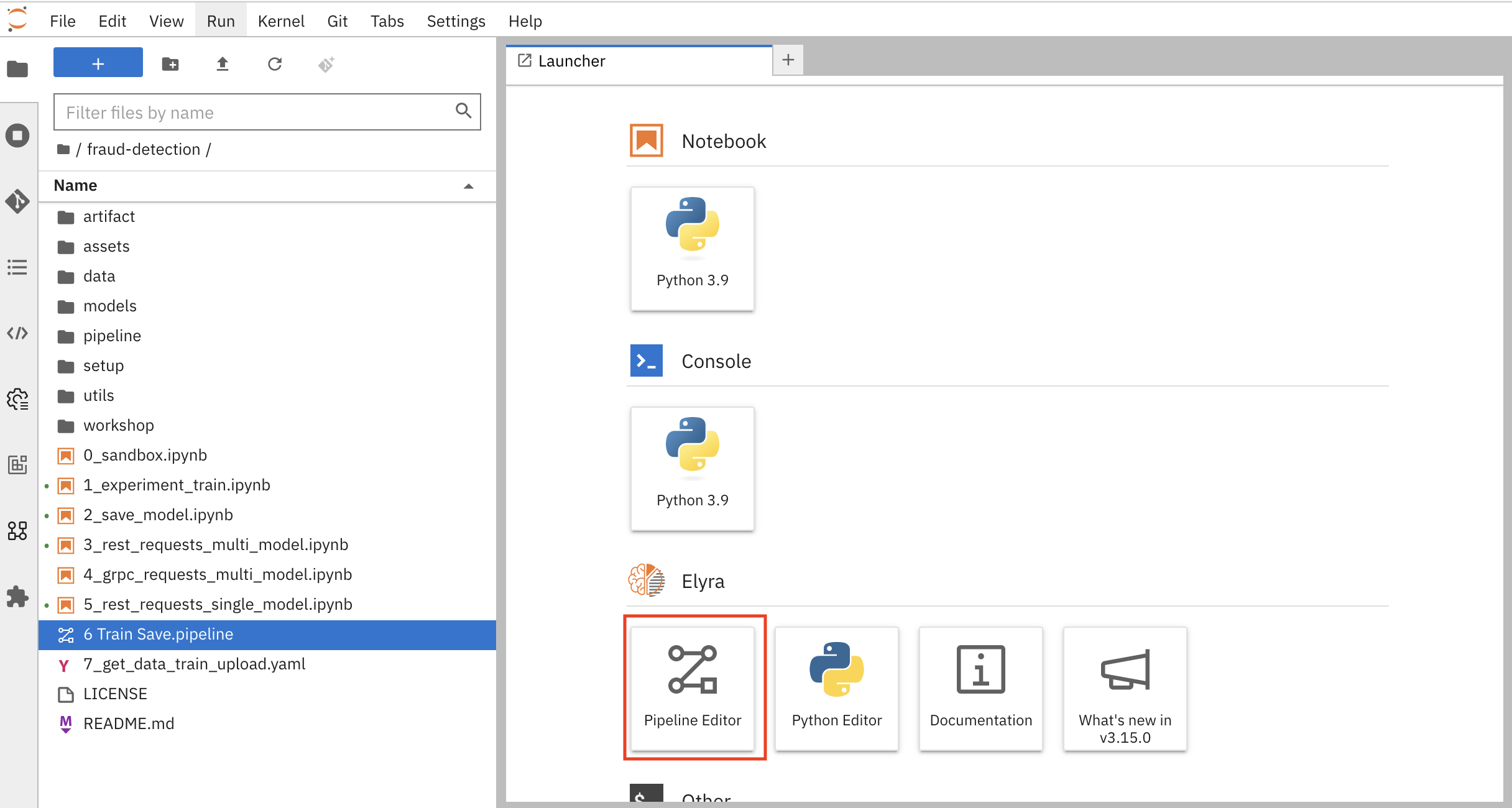
点 Pipeline Editor。

您已创建了一个空白管道!
在运行笔记本或 Python 代码时,设置默认的运行时镜像。
在管道编辑器中,点 Open Panel。

选择 Pipeline Properties 选项卡。
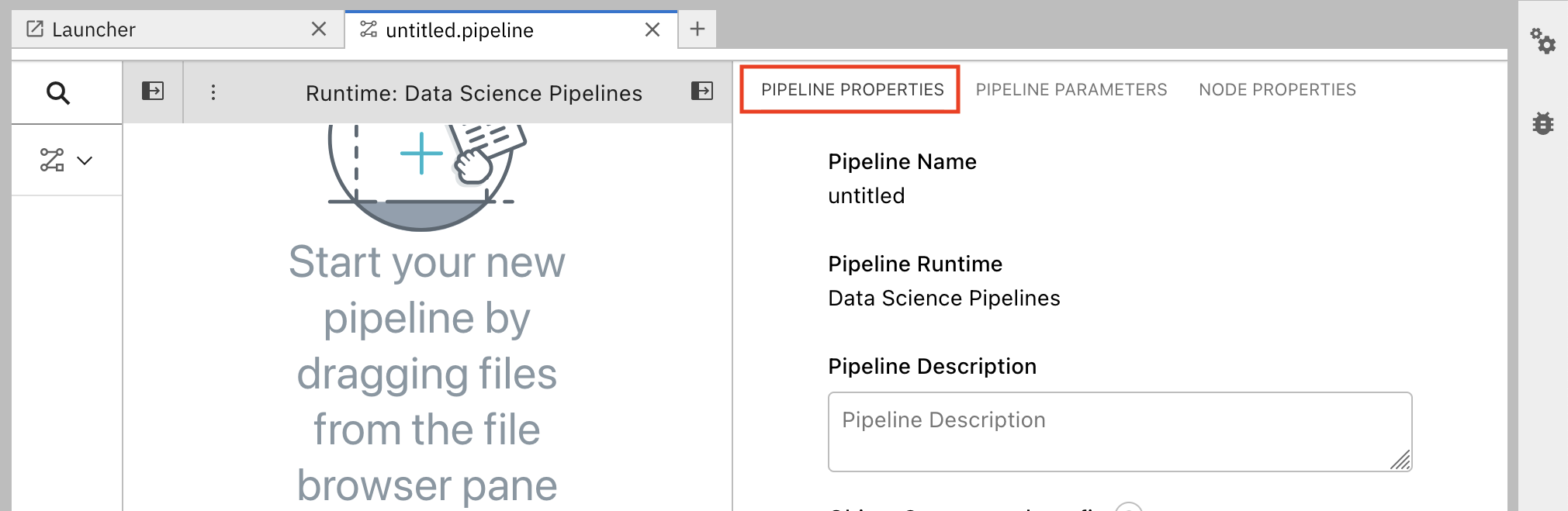
在 Pipeline Properties 面板中,向下滚动到 Generic Node Defaults 和 Runtime Image。
使用 Cuda 和 Python 3.9 (UBI 9)将值设为 Tensorflow。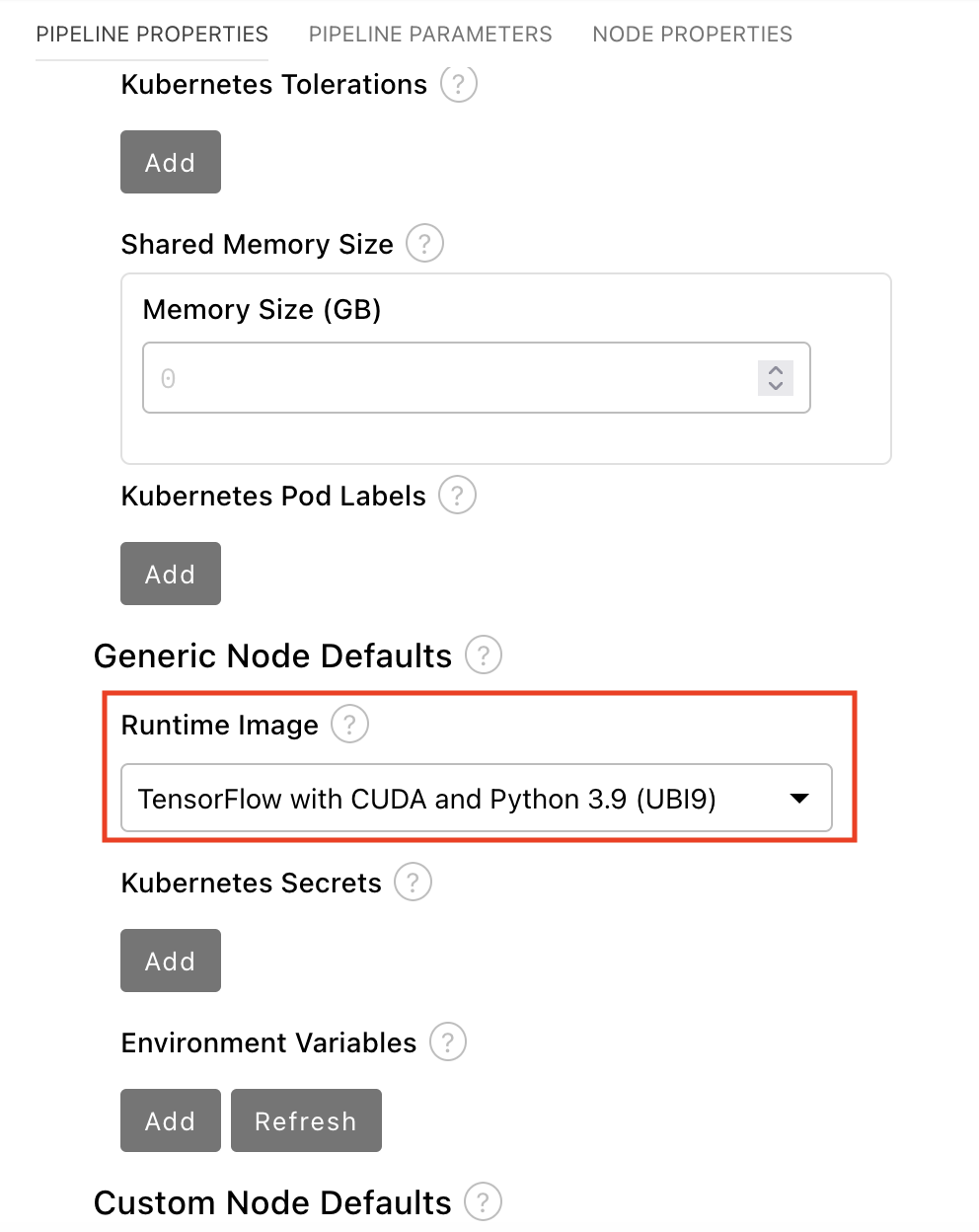
- 保存管道。
5.1.2. 在管道中添加节点
在管道中添加一些步骤或节点。您的两个节点将使用 1_experiment_train.ipynb 和 2_save_model.ipynb 笔记本。
在 file-browser 面板中,将
1_experiment_train.ipynb和2_save_model.ipynb笔记本拖到管道 canvas。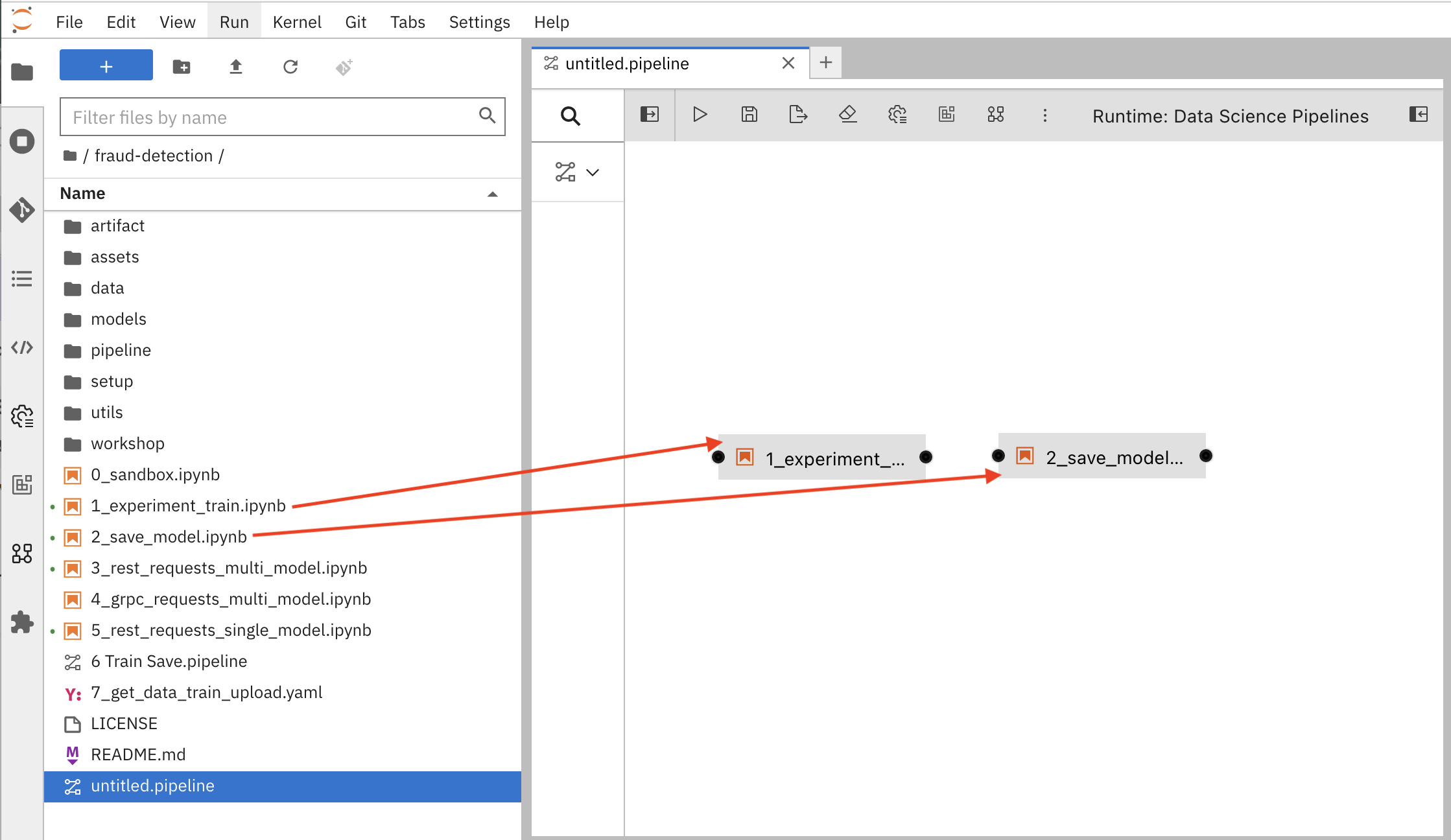
单击
1_experiment_train.ipynb的输出端口,并将连接行拖到2_save_model.ipynb的输入端口。
- 保存管道。
5.1.3. 将培训文件指定为依赖项
设置节点属性,将培训文件指定为依赖项。
注:如果您没有设置此文件依赖项,则该文件在运行时不会包含在节点中,并且培训作业失败时不会包含该文件。
单击
1_experiment_train.ipynb节点。
- 在 Properties 面板中,点 Node Properties 选项卡。
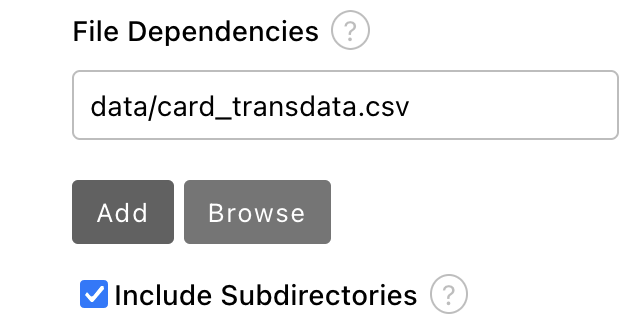
向下滚动到 File Dependencies 部分,然后单击 Add。
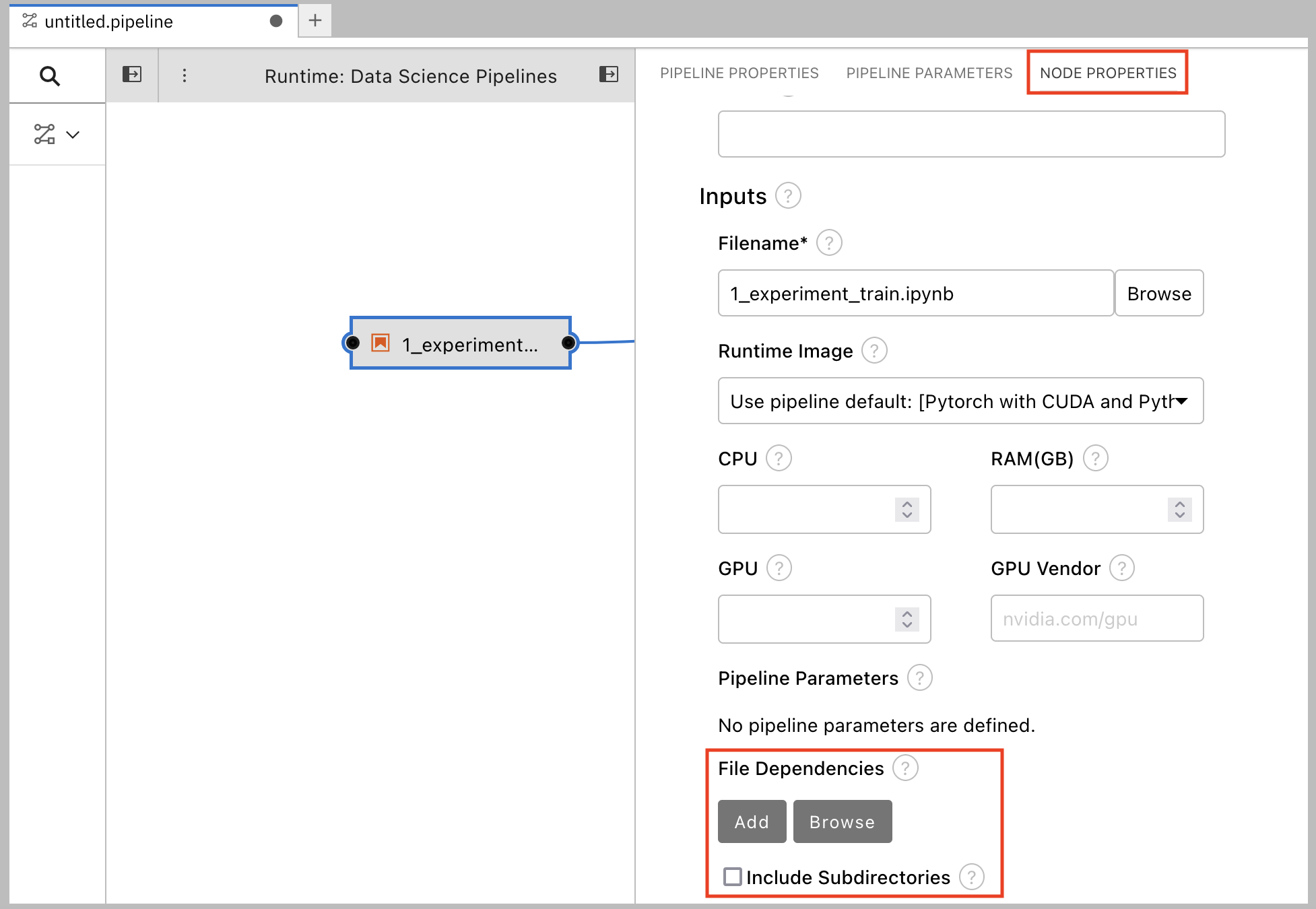
-
将值设为
data/card_transdata.csv,其中包含要为您的模型进行培训的数据。 选择 Include Subdirectories 选项,然后单击 Add。
- 保存管道。
5.1.4. 创建并存储 ONNX 格式的输出文件
在节点 1 中,笔记本会创建 models/fraud/1/model.onnx 文件。在节点 2 中,笔记本将该文件上传到 S3 存储桶。您必须将 model /fraud/1/model.onnx 文件设置为两个节点的输出文件。
- 选择节点 1,然后选择 Node Properties 选项卡。
- 向下滚动到 Output Files 部分,然后单击 Add。
将值设为
models/fraud/1/model.onnx,然后单击 Add。
- 对节点 2 重复步骤 1-3。
- 保存管道。
5.1.5. 配置到 S3 存储桶的数据连接
在节点 2 中,笔记本将模型上传到 S3 存储桶。
您必须使用您通过本教程 的数据连接 部分设置的 My Storage 数据连接创建的 secret 设置 S3 存储桶密钥。
您可以在管道节点中使用此 secret,而无需在管道代码中保存信息。这很重要,例如,如果要将管道保存到没有 secret 密钥 - 到源控制中。
secret 名为 aws-connection-my-storage。
如果您命名了 My Storage 以外的数据连接内容,您可以通过在 Data Connections 选项卡中将鼠标悬停在资源信息图标上来获取 OpenShift AI 仪表板中的 secret 名称。
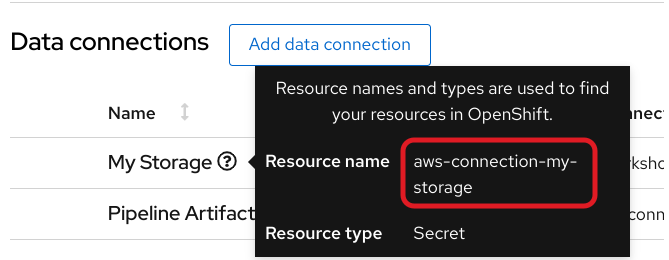
aws-connection-my-storage secret 包括以下字段:
-
AWS_ACCESS_KEY_ID -
AWS_DEFAULT_REGION -
AWS_S3_BUCKET -
AWS_S3_ENDPOINT -
AWS_SECRET_ACCESS_KEY
您必须为每个这些字段设置 secret 名称和密钥。
流程
删除任何预先填充的环境变量。
选择节点 2,然后选择 Node Properties 选项卡。
在 Additional Properties 下,请注意预填充了一些环境变量。管道编辑器从笔记本代码中推断出您需要它们。
由于您不想在管道中保存值,因此请删除所有这些环境变量。
为每个预先填充的环境变量点 Remove。
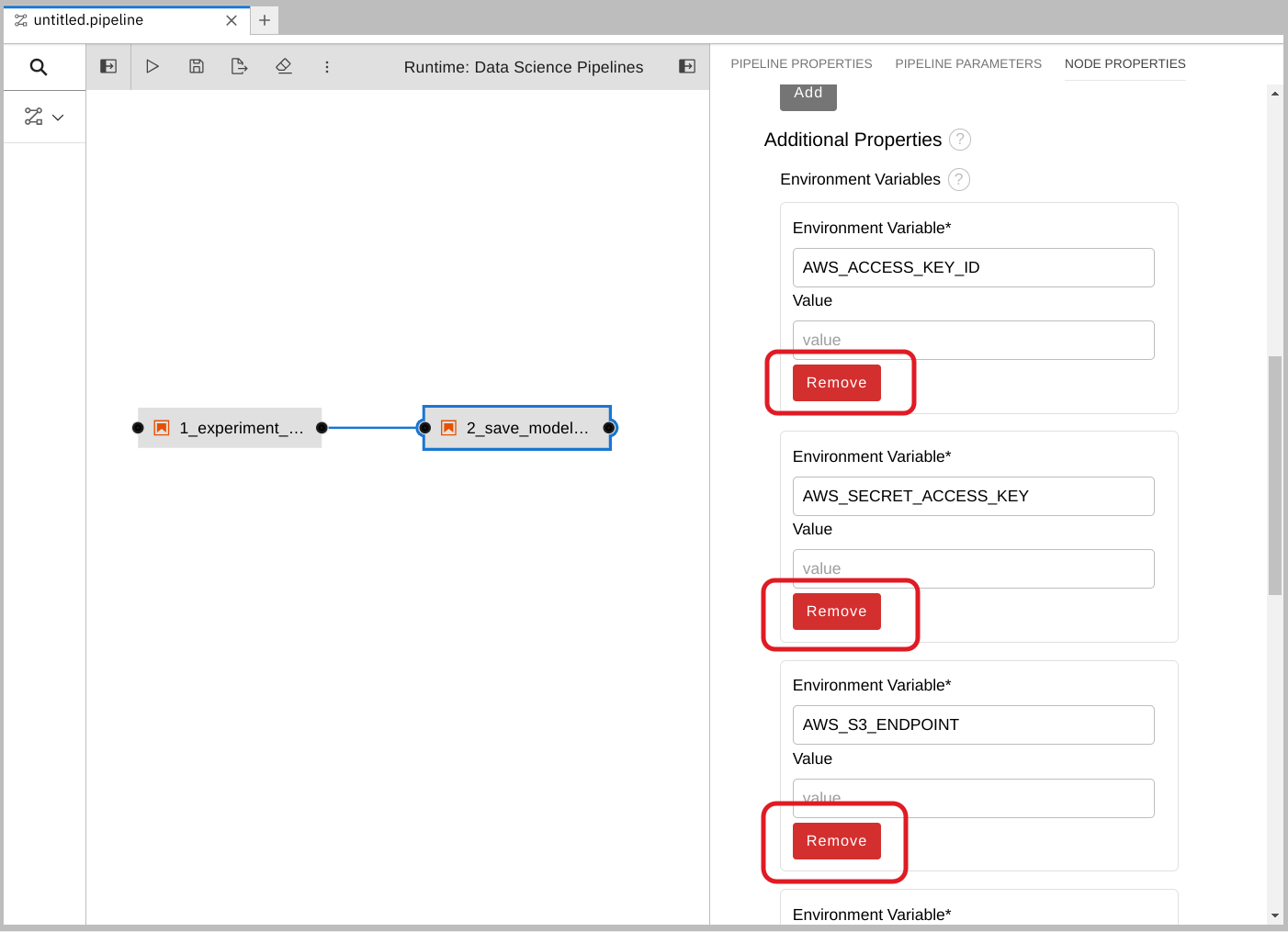
使用 Kubernetes secret 添加 S3 存储桶和密钥。
在 Kubernetes Secrets 下,单击 Add。
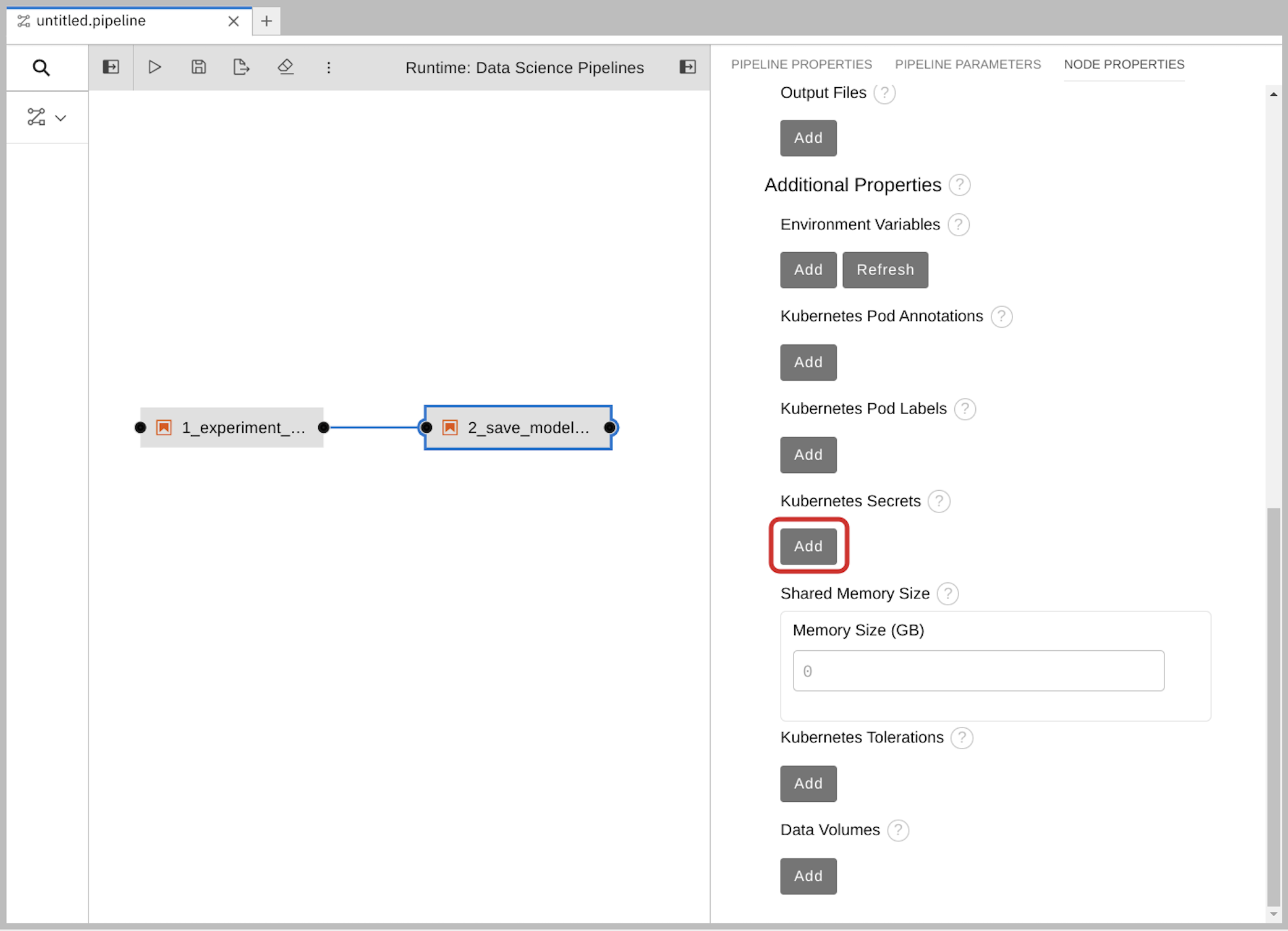
输入以下值,然后单击 Add。
-
环境变量 :
AWS_ACCESS_KEY_ID -
Secret Name:
aws-connection-my-storage Secret Key:
AWS_ACCESS_KEY_ID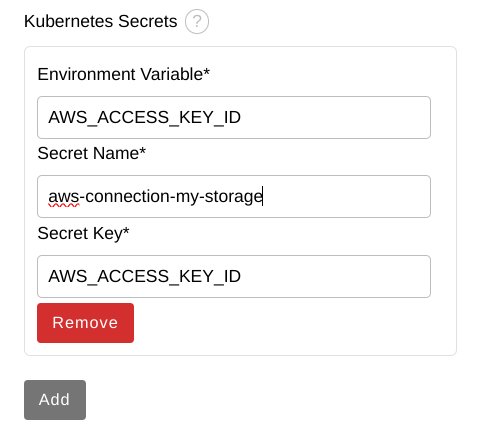
-
环境变量 :
对这些 Kubernetes secret 的每个组重复步骤 2a 和 2b :
环境变量 :
AWS_SECRET_ACCESS_KEY-
Secret Name:
aws-connection-my-storage -
Secret Key:
AWS_SECRET_ACCESS_KEY
-
Secret Name:
环境变量 :
AWS_S3_ENDPOINT-
Secret Name:
aws-connection-my-storage -
Secret Key:
AWS_S3_ENDPOINT
-
Secret Name:
环境变量 :
AWS_DEFAULT_REGION-
Secret Name:
aws-connection-my-storage -
Secret Key:
AWS_DEFAULT_REGION
-
Secret Name:
环境变量 :
AWS_S3_BUCKET-
Secret Name:
aws-connection-my-storage -
Secret Key:
AWS_S3_BUCKET
-
Secret Name:
-
保存并 重命名
.pipeline文件。
5.1.6. 运行 Pipeline
在集群中上传管道并运行它。您可以直接从管道编辑器完成此操作。您可以将自己的新创建的管道用于此或 6 个 Train Save.pipeline。
流程
单击管道编辑器工具栏中的 play 按钮。

- 为管道输入一个名称。
-
验证 Runtime Configuration: 是否已设置为
Data Science Pipeline。 点击 确定。
注意如果
Data Science Pipeline没有作为运行时配置提供,则可能会在管道服务器可用前创建笔记本。您可以在数据科学项目中创建管道服务器后重启笔记本。返回您的数据科学项目并扩展新创建的管道。
点 View run,然后查看管道运行正在进行中。
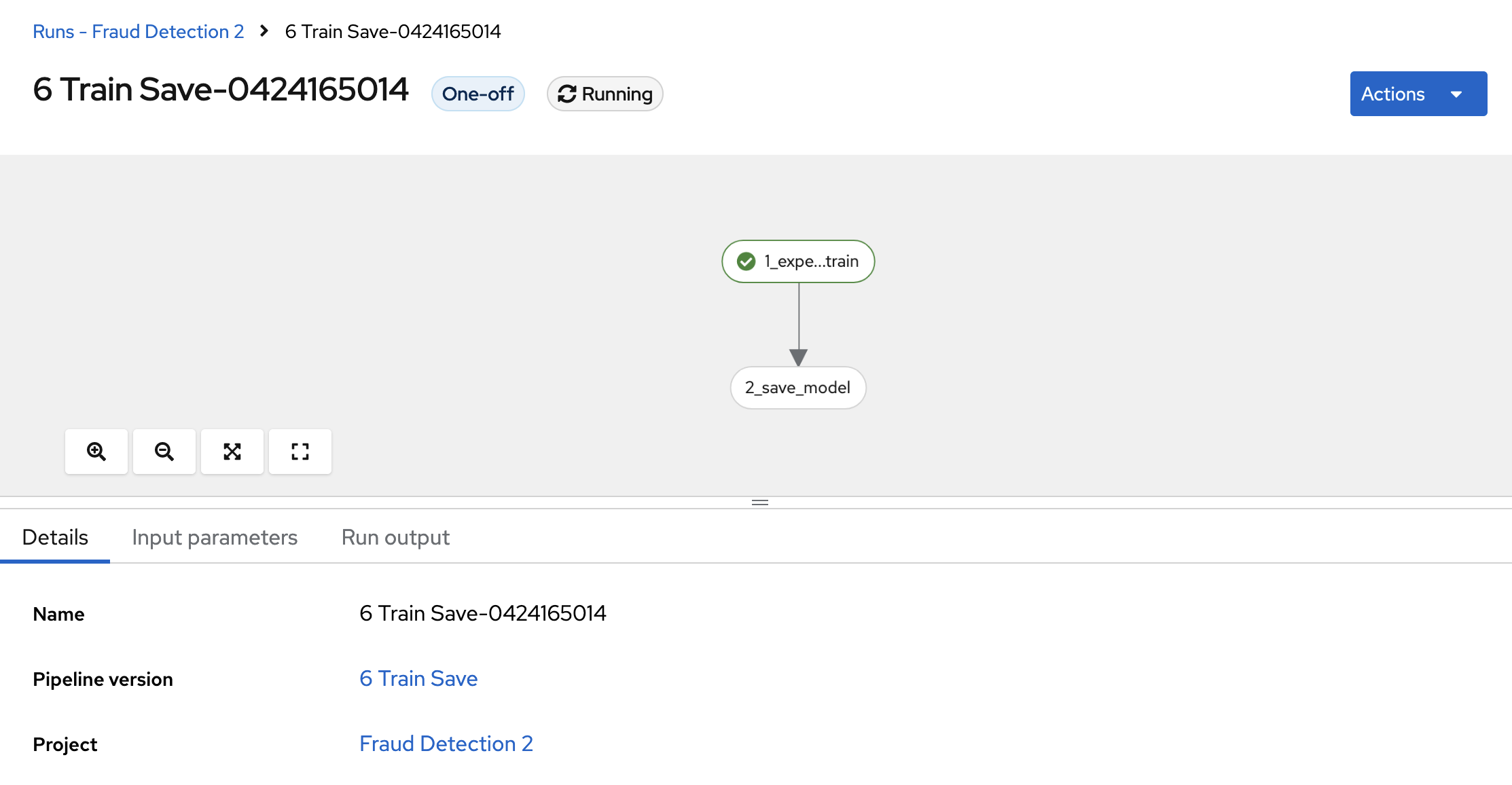
结果应该是 S3 存储桶中的 models/fraud/1/model.onnx 文件,就像 为部署准备模型 部分一样。
后续步骤