5.2. 运行由 Python 代码生成的数据科学项目
在上一节中,您使用 GUI 管道编辑器创建一个简单的管道。通常最好使用可以控制版本控制的代码创建管道,并与他人共享。kfp SDK 为创建管道提供了一个 Python API。SDK 作为 Python 软件包提供,您可以使用 pip install kfp 命令进行安装。使用这个软件包,您可以使用 Python 代码创建管道,然后将其编译为 YAML 格式。然后,您可以将 YAML 代码导入到 OpenShift AI。
本教程不会将您介绍如何使用 SDK。相反,它会为您提供查看和上传的文件。
另外,还可导航到
fraud-detection-notebooks项目的管道目录来查看 Jupyter 环境中提供的 Python 代码。它包含以下文件:-
7_get_data_train_upload.py是主管道代码。 -
get_data.py, training_model.py, 和upload.py是管道的三个组件。 build.sh是一个构建管道并创建 YAML 文件的脚本。为方便起见,
build.sh脚本的输出在7_get_data_train_upload.yaml文件中提供。7_get_data_train_upload.yaml输出文件位于顶级fraud-detection目录中。
-
-
右键点击
7_get_data_train_upload.yaml文件,然后点 Download。 将
7_get_data_train_upload.yaml文件上传到 OpenShift AI。在 OpenShift AI 仪表板中,导航到您的数据科学项目页面。点 Pipelines 选项卡,然后点 Import pipeline。
- 为 Pipeline 名称和 Pipeline 描述输入值。
点 Upload,然后从本地文件中选择
7_get_data_train_upload.yaml,以上传管道。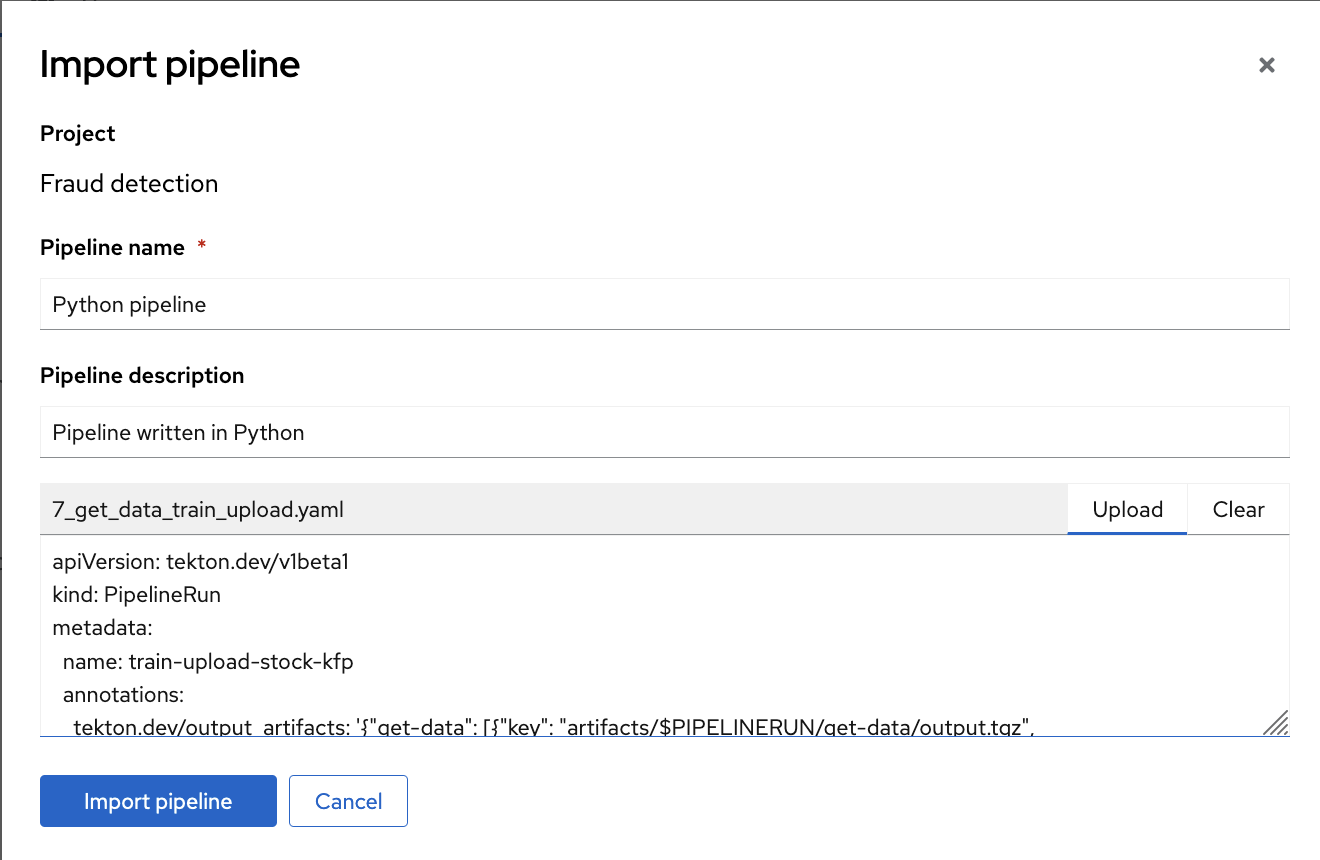
点 Import pipeline 导入并保存管道。
管道显示在管道列表中。
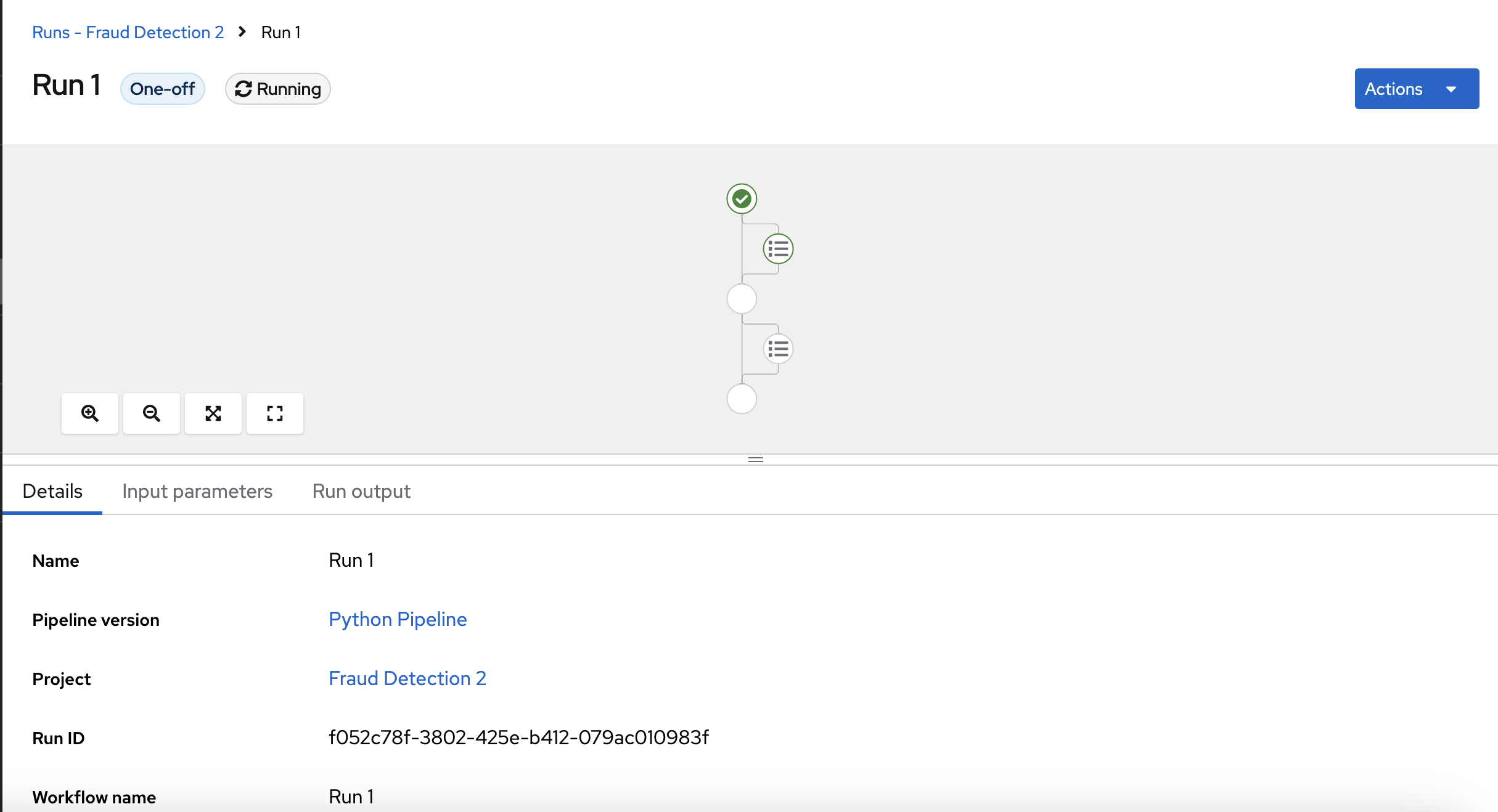
展开管道项目,点操作菜单(RCU),然后选择 View run。
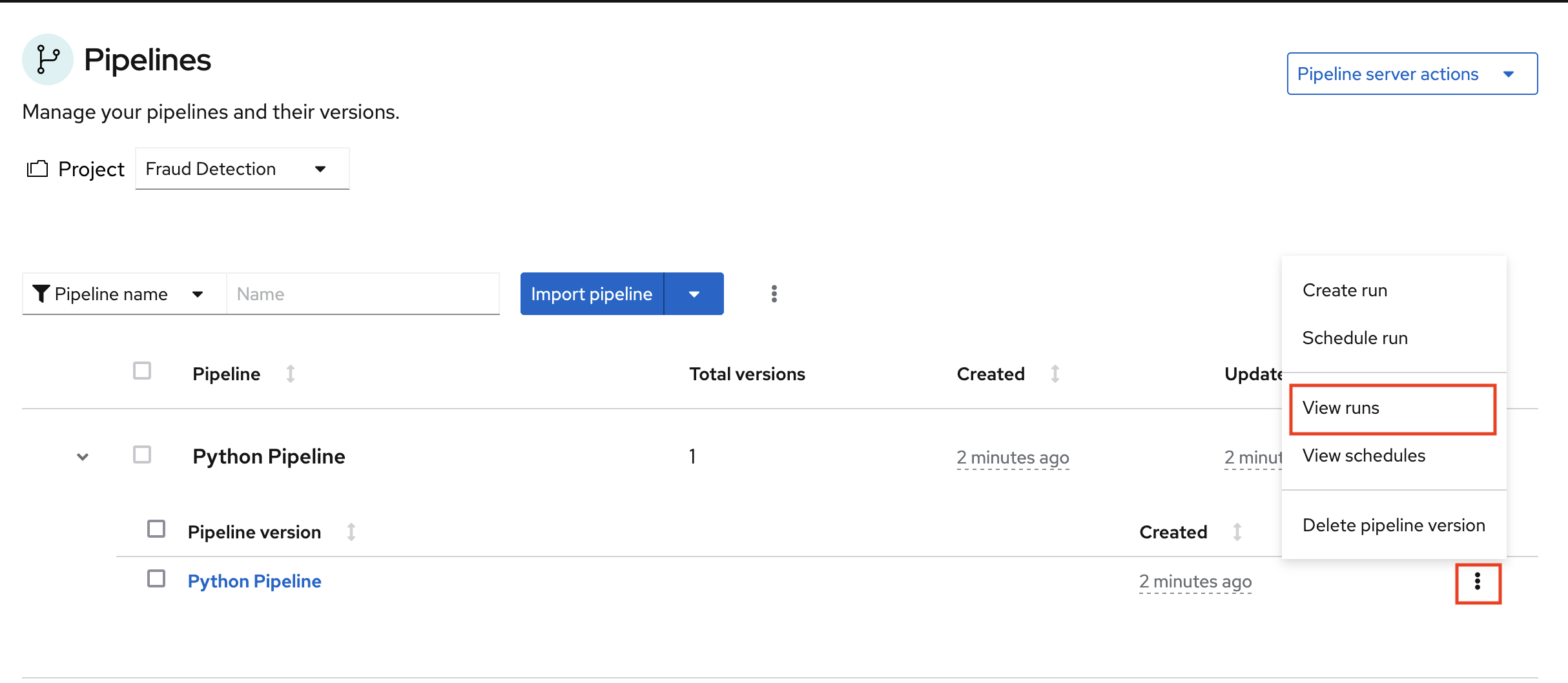
- 点 Create run。
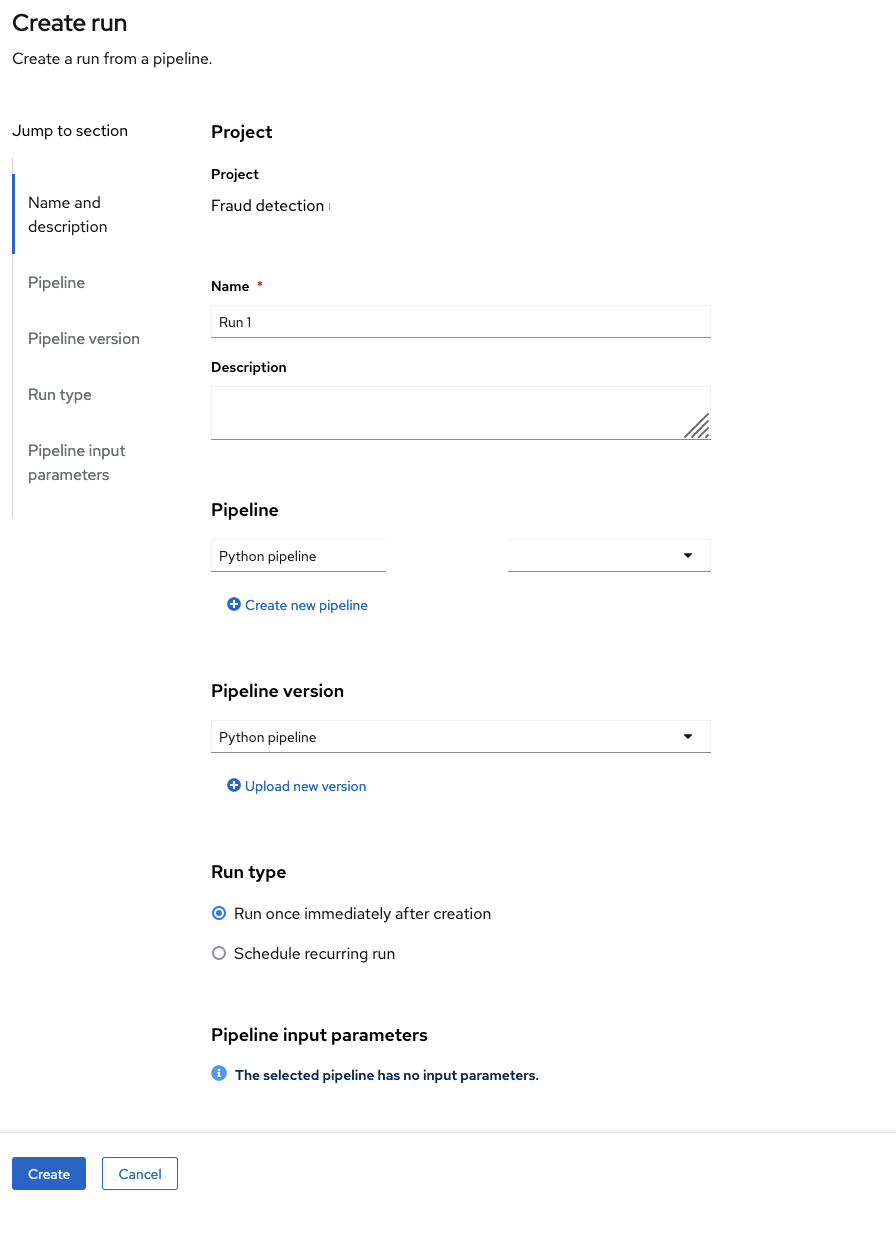
在 Create run 页面中,提供以下值:
-
对于 Name,键入任何名称,例如
Run 1。 对于 Pipeline,选择您上传的管道。
您可以将其他字段保留默认值。
-
对于 Name,键入任何名称,例如
单击 Create 以创建该运行。
新运行会立即启动。Details 页面显示在 OpenShift AI 中运行的 Python 中创建的管道。