Chapter 5. Using build strategies
The following sections define the primary supported build strategies, and how to use them.
5.1. Docker build
The Docker build strategy invokes the docker build command, and it expects a repository with a Dockerfile and all required artifacts in it to produce a runnable image.
5.1.1. Replacing Dockerfile FROM image
You can replace the FROM instruction of the Dockerfile with the from of the BuildConfig. If the Dockerfile uses multi-stage builds, the image in the last FROM instruction will be replaced.
Procedure
To replace the FROM instruction of the Dockerfile with the from of the BuildConfig.
strategy:
dockerStrategy:
from:
kind: "ImageStreamTag"
name: "debian:latest"5.1.2. Using Dockerfile path
By default, Docker builds use a Dockerfile (named Dockerfile) located at the root of the context specified in the BuildConfig.spec.source.contextDir field.
The dockerfilePath field allows the build to use a different path to locate your Dockerfile, relative to the BuildConfig.spec.source.contextDir field. It can be a different file name than the default Dockerfile (for example, MyDockerfile), or a path to a Dockerfile in a subdirectory (for example, dockerfiles/app1/Dockerfile).
Procedure
To use the dockerfilePath field for the build to use a different path to locate your Dockerfile, set:
strategy:
dockerStrategy:
dockerfilePath: dockerfiles/app1/Dockerfile5.1.3. Using Docker environment variables
To make environment variables available to the Docker build process and resulting image, you can add environment variables to the dockerStrategy definition of the BuildConfig.
The environment variables defined there are inserted as a single ENV Dockerfile instruction right after the FROM instruction, so that it can be referenced later on within the Dockerfile.
Procedure
The variables are defined during build and stay in the output image, therefore they will be present in any container that runs that image as well.
For example, defining a custom HTTP proxy to be used during build and runtime:
dockerStrategy:
...
env:
- name: "HTTP_PROXY"
value: "http://myproxy.net:5187/"Cluster administrators can also configure global build settings using Ansible.
You can also manage environment variables defined in the BuildConfig with the oc set env command.
5.1.4. Adding Docker build arguments
You can set Docker build arguments using the BuildArgs array. The build arguments will be passed to Docker when a build is started.
Procedure
To set Docker build arguments, add entries to the BuildArgs array, which is located in the dockerStrategy definition of the BuildConfig. For example:
dockerStrategy:
...
buildArgs:
- name: "foo"
value: "bar"5.2. Source-to-Image (S2I) build
Source-to-Image (S2I) is a tool for building reproducible, Docker-formatted container images. It produces ready-to-run images by injecting application source into a container image and assembling a new image. The new image incorporates the base image (the builder) and built source and is ready to use with the buildah run command. S2I supports incremental builds, which re-use previously downloaded dependencies, previously built artifacts, etc.
The advantages of S2I include the following:
| Image flexibility |
S2I scripts can be written to inject application code into almost any existing Docker-formatted container image, taking advantage of the existing ecosystem. Note that, currently, S2I relies on |
| Speed | With S2I, the assemble process can perform a large number of complex operations without creating a new layer at each step, resulting in a fast process. In addition, S2I scripts can be written to re-use artifacts stored in a previous version of the application image, rather than having to download or build them each time the build is run. |
| Patchability | S2I allows you to rebuild the application consistently if an underlying image needs a patch due to a security issue. |
| Operational efficiency | By restricting build operations instead of allowing arbitrary actions, as a Dockerfile would allow, the PaaS operator can avoid accidental or intentional abuses of the build system. |
| Operational security | Building an arbitrary Dockerfile exposes the host system to root privilege escalation. This can be exploited by a malicious user because the entire Docker build process is run as a user with Docker privileges. S2I restricts the operations performed as a root user and can run the scripts as a non-root user. |
| User efficiency |
S2I prevents developers from performing arbitrary |
| Ecosystem | S2I encourages a shared ecosystem of images where you can leverage best practices for your applications. |
| Reproducibility | Produced images can include all inputs including specific versions of build tools and dependencies. This ensures that the image can be reproduced precisely. |
5.2.1. Performing Source-to-Image (S2I) incremental builds
S2I can perform incremental builds, which means it reuses artifacts from previously-built images.
Procedure
To create an incremental build, create a BuildConfig with the following modification to the strategy definition:
strategy:
sourceStrategy:
from:
kind: "ImageStreamTag"
name: "incremental-image:latest"
incremental: true - 1
- Specify an image that supports incremental builds. Consult the documentation of the builder image to determine if it supports this behavior.
- 2
- This flag controls whether an incremental build is attempted. If the builder image does not support incremental builds, the build will still succeed, but you will get a log message stating the incremental build was not successful because of a missing save-artifacts script.
Additional resources
- See S2I Requirements for information on how to create a builder image supporting incremental builds.
5.2.2. Overriding Source-to-Image (S2I) builder image scripts
You can override the assemble, run, and save-artifacts S2I scripts provided by the builder image.
Procedure
To override the assemble, run, and save-artifacts S2I scripts provided by the builder image, either:
- Provide an assemble, run, or save-artifacts script in the .s2i/bin directory of your application source repository, or
- Provide a URL of a directory containing the scripts as part of the strategy definition. For example:
strategy:
sourceStrategy:
from:
kind: "ImageStreamTag"
name: "builder-image:latest"
scripts: "http://somehost.com/scripts_directory" - 1
- This path will have run, assemble, and save-artifacts appended to it. If any or all scripts are found they will be used in place of the same named script(s) provided in the image.
Files located at the scripts URL take precedence over files located in .s2i/bin of the source repository.
5.2.3. Source-to-Image (S2I) environment variables
There are two ways to make environment variables available to the source build process and resulting image. Environment files and BuildConfig environment values. Variables provided will be present during the build process and in the output image.
5.2.3.1. Using Source-to-Image (S2I) environment files
Source build enables you to set environment values (one per line) inside your application, by specifying them in a .s2i/environment file in the source repository. The environment variables specified in this file are present during the build process and in the output image.
If you provide a .s2i/environment file in your source repository, S2I reads this file during the build. This allows customization of the build behavior as the assemble script may use these variables.
Procedure
For example, to disable assets compilation for your Rails application during the build:
-
Add
DISABLE_ASSET_COMPILATION=truein the .s2i/environment file.
In addition to builds, the specified environment variables are also available in the running application itself. For example, to cause the Rails application to start in development mode instead of production:
-
Add
RAILS_ENV=developmentto the .s2i/environment file.
Additional resources
- The complete list of supported environment variables is available in the using images section for each image.
5.2.3.2. Using Source-to-Image (S2I) BuildConfig environment
You can add environment variables to the sourceStrategy definition of the BuildConfig. The environment variables defined there are visible during the assemble script execution and will be defined in the output image, making them also available to the run script and application code.
Procedure
- For example, to disable assets compilation for your Rails application:
sourceStrategy:
...
env:
- name: "DISABLE_ASSET_COMPILATION"
value: "true"Additional resources
- The Build environment section provides more advanced instructions.
-
You can also manage environment variables defined in the
BuildConfigwith theoc set envcommand.
5.2.4. Ignoring Source-to-Image (S2I) source files
Source to image supports a .s2iignore file, which contains a list of file patterns that should be ignored. Files in the build working directory, as provided by the various input sources, that match a pattern found in the .s2iignore file will not be made available to the assemble script.
For more details on the format of the .s2iignore file, see the source-to-image documentation.
5.2.5. Creating images from source code with s2i
Source-to-Image (S2I) is a framework that makes it easy to write images that take application source code as an input and produce a new image that runs the assembled application as output.
The main advantage of using S2I for building reproducible container images is the ease of use for developers. As a builder image author, you must understand two basic concepts in order for your images to provide the best possible S2I performance: the build process and S2I scripts.
5.2.5.1. Understanding the S2I build process
The build process consists of the following three fundamental elements, which are combined into a final container image:
- sources
- S2I scripts
- builder image
During the build process, S2I must place sources and scripts inside the builder image. To do so, S2I creates a tar file that contains the sources and scripts, then streams that file into the builder image. Before executing the assemble script, S2I un-tars that file and places its contents into the location specified by the io.openshift.s2i.destination label from the builder image, with the default location being the /tmp directory.
For this process to happen, your image must supply the tar archiving utility (the tar command available in $PATH) and the command line interpreter (the /bin/sh command); this allows your image to use the fastest possible build path. If the tar or /bin/sh command is not available, the s2i build process is forced to automatically perform an additional container build to put both the sources and the scripts inside the image, and only then run the usual build.
See the following diagram for the basic S2I build workflow:
Figure 5.1. Build Workflow
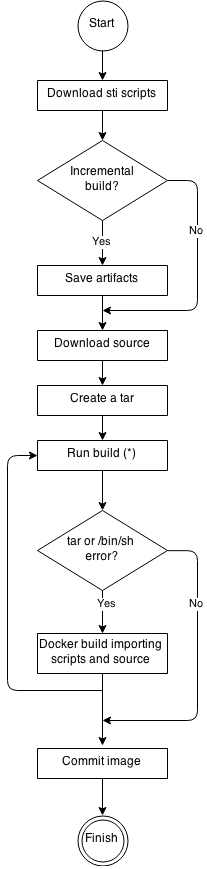
Run build’s responsibility is to un-tar the sources, scripts and artifacts (if such exist) and invoke the assemble script. If this is the second run (after catching tar or /bin/sh not found error) it is responsible only for invoking assemble script, since both scripts and sources are already there.
5.2.5.2. Writing S2I scripts
You can write S2I scripts in any programming language, as long as the scripts are executable inside the builder image. S2I supports multiple options providing assemble/run/save-artifacts scripts. All of these locations are checked on each build in the following order:
- A script specified in the BuildConfig
-
A script found in the application source
.s2i/bindirectory -
A script found at the default image URL (
io.openshift.s2i.scripts-urllabel)
Both the io.openshift.s2i.scripts-url label specified in the image and the script specified in a BuildConfig can take one of the following forms:
-
image:///path_to_scripts_dir- absolute path inside the image to a directory where the S2I scripts are located -
file:///path_to_scripts_dir- relative or absolute path to a directory on the host where the S2I scripts are located -
http(s)://path_to_scripts_dir- URL to a directory where the S2I scripts are located
| Script | Description |
|---|---|
| assemble (required) | The assemble script builds the application artifacts from a source and places them into appropriate directories inside the image. The workflow for this script is:
|
| run (required) | The run script executes your application. |
| save-artifacts (optional) | The save-artifacts script gathers all dependencies that can speed up the build processes that follow. For example:
These dependencies are gathered into a tar file and streamed to the standard output. |
| usage (optional) | The usage script allows you to inform the user how to properly use your image. |
| test/run (optional) | The test/run script allows you to create a simple process to check if the image is working correctly. The proposed flow of that process is:
Note The suggested location to put the test application built by your test/run script is the test/test-app directory in your image repository. See the S2I documentation for more information. |
5.2.5.2.1. Example S2I Scripts
The following example S2I scripts are written in Bash. Each example assumes its tar contents are unpacked into the /tmp/s2i directory.
Example 5.1. assemble script:
#!/bin/bash
# restore build artifacts
if [ "$(ls /tmp/s2i/artifacts/ 2>/dev/null)" ]; then
mv /tmp/s2i/artifacts/* $HOME/.
fi
# move the application source
mv /tmp/s2i/src $HOME/src
# build application artifacts
pushd ${HOME}
make all
# install the artifacts
make install
popdExample 5.2. run script:
#!/bin/bash
# run the application
/opt/application/run.shExample 5.3. save-artifacts script:
#!/bin/bash
pushd ${HOME}
if [ -d deps ]; then
# all deps contents to tar stream
tar cf - deps
fi
popdExample 5.4. usage script:
#!/bin/bash
# inform the user how to use the image
cat <<EOF
This is a S2I sample builder image, to use it, install
https://github.com/openshift/source-to-image
EOF5.3. Custom build
The Custom build strategy allows developers to define a specific builder image responsible for the entire build process. Using your own builder image allows you to customize your build process.
A Custom builder image is a plain Docker-formatted container image embedded with build process logic, for example for building RPMs or base images.
Custom builds run with a very high level of privilege and are not available to users by default. Only users who can be trusted with cluster administration permissions should be granted access to run custom builds.
5.3.1. Using FROM image for custom builds
You can use the customStrategy.from section to indicate the image to use for the custom build
Procedure
To set the customStrategy.from section:
strategy:
customStrategy:
from:
kind: "DockerImage"
name: "openshift/sti-image-builder"5.3.2. Using secrets in custom builds
In addition to secrets for source and images that can be added to all build types, custom strategies allow adding an arbitrary list of secrets to the builder pod.
Procedure
To mount each secret at a specific location:
strategy:
customStrategy:
secrets:
- secretSource:
name: "secret1"
mountPath: "/tmp/secret1"
- secretSource:
name: "secret2"
mountPath: "/tmp/secret2"5.3.3. Using environment variables for custom builds
To make environment variables available to the Custom build process, you can add environment variables to the customStrategy definition of the BuildConfig.
The environment variables defined there are passed to the pod that runs the custom build.
Procedure
To define a custom HTTP proxy to be used during build:
customStrategy:
...
env:
- name: "HTTP_PROXY"
value: "http://myproxy.net:5187/"Cluster administrators can also configure global build settings using Ansible.
You can also manage environment variables defined in the BuildConfig with the oc set env command.
5.3.4. Using custom builder images
By allowing you to define a specific builder image responsible for the entire build process, OpenShift Container Platform’s Custom build strategy was designed to fill a gap created with the increased popularity of creating container images. When there is a requirement for a build to still produce individual artifacts (packages, JARs, WARs, installable ZIPs, and base images, for example), a Custom builder image using the Custom build strategy is the perfect match to fill that gap.
A Custom builder image is a plain container image embedded with build process logic, for example for building RPMs or base container images.
Additionally, the Custom builder allows implementing any extended build process, for example a CI/CD flow that runs unit or integration tests.
To fully leverage the benefits of the Custom build strategy, you must understand how to create a Custom builder image that will be capable of building desired objects.
5.3.4.1. Custom builder image
Upon invocation, a custom builder image will receive the following environment variables with the information needed to proceed with the build:
| Variable Name | Description |
|---|---|
|
|
The entire serialized JSON of the |
|
| The URL of a Git repository with source to be built. |
|
|
Uses the same value as |
|
| Specifies the subdirectory of the Git repository to be used when building. Only present if defined. |
|
| The Git reference to be built. |
|
| The version of the OpenShift Container Platform master that created this build object. |
|
| The container image registry to push the image to. |
|
| The container image tag name for the image being built. |
|
|
The path to the container registry credentials for running a |
5.3.4.2. Custom builder workflow
Although custom builder image authors have great flexibility in defining the build process, your builder image must still adhere to the following required steps necessary for seamlessly running a build inside of OpenShift Container Platform:
-
The
Buildobject definition contains all the necessary information about input parameters for the build. - Run the build process.
- If your build produces an image, push it to the build’s output location if it is defined. Other output locations can be passed with environment variables.
5.4. Pipeline build
The Pipeline build strategy allows developers to define a Jenkins pipeline for execution by the Jenkins pipeline plugin. The build can be started, monitored, and managed by OpenShift Container Platform in the same way as any other build type.
Pipeline workflows are defined in a Jenkinsfile, either embedded directly in the build configuration, or supplied in a Git repository and referenced by the build configuration.
5.4.1. Understanding OpenShift Container Platform pipelines
Pipelines give you control over building, deploying, and promoting your applications on OpenShift Container Platform. Using a combination of the Jenkins Pipeline Build Strategy, Jenkinsfiles, and the OpenShift Container Platform Domain Specific Language (DSL) (provided by the Jenkins Client Plug-in), you can create advanced build, test, deploy, and promote pipelines for any scenario.
OpenShift Container Platform Jenkins Sync Plugin
The OpenShift Container Platform Jenkins Sync Plugin keeps BuildConfig and Build objects in sync with Jenkins Jobs and Builds, and provides the following:
- Dynamic job/run creation in Jenkins.
- Dynamic creation of slave pod templates from ImageStreams, ImageStreamTags, or ConfigMaps.
- Injecting of environment variables.
- Pipeline visualization in the OpenShift web console.
- Integration with the Jenkins git plugin, which passes commit information from
- Synchronizing secrets into Jenkins credential entries OpenShift builds to the Jenkins git plugin.
OpenShift Container Platform Jenkins Client Plugin
The OpenShift Container Platform Jenkins Client Plugin is a Jenkins plugin which aims to provide a readable, concise, comprehensive, and fluent Jenkins Pipeline syntax for rich interactions with an OpenShift Container Platform API Server. The plugin leverages the OpenShift command line tool (oc) which must be available on the nodes executing the script.
The Jenkins Client Plug-in must be installed on your Jenkins master so the OpenShift Container Platform DSL will be available to use within the JenkinsFile for your application. This plug-in is installed and enabled by default when using the OpenShift Container Platform Jenkins image.
For OpenShift Container Platform Pipelines within your project, you will must use the Jenkins Pipeline Build Strategy. This strategy defaults to using a jenkinsfile at the root of your source repository, but also provides the following configuration options:
-
An inline
jenkinsfilefield within yourBuildConfig. -
A
jenkinsfilePathfield within yourBuildConfigthat references the location of thejenkinsfileto use relative to the sourcecontextDir.
The optional jenkinsfilePath field specifies the name of the file to use, relative to the source contextDir. If contextDir is omitted, it defaults to the root of the repository. If jenkinsfilePath is omitted, it defaults to jenkinsfile.
5.4.2. Providing the Jenkinsfile for pipeline builds
The jenkinsfile uses the standard groovy language syntax to allow fine grained control over the configuration, build, and deployment of your application.
You can supply the jenkinsfile in one of the following ways:
- A file located within your source code repository.
-
Embedded as part of your build configuration using the
jenkinsfilefield.
When using the first option, the jenkinsfile must be included in your applications source code repository at one of the following locations:
-
A file named
jenkinsfileat the root of your repository. -
A file named
jenkinsfileat the root of the sourcecontextDirof your repository. -
A file name specified via the
jenkinsfilePathfield of theJenkinsPipelineStrategysection of your BuildConfig, which is relative to the sourcecontextDirif supplied, otherwise it defaults to the root of the repository.
The jenkinsfile is executed on the Jenkins slave pod, which must have the OpenShift Client binaries available if you intend to use the OpenShift DSL.
Procedure
To provide the Jenkinsfile, you can either:
- Embed the Jenkinsfile in the build configuration.
- Include in the build configuration a reference to the Git repository that contains the Jenkinsfile.
Embedded Definition
kind: "BuildConfig"
apiVersion: "v1"
metadata:
name: "sample-pipeline"
spec:
strategy:
jenkinsPipelineStrategy:
jenkinsfile: |-
node('agent') {
stage 'build'
openshiftBuild(buildConfig: 'ruby-sample-build', showBuildLogs: 'true')
stage 'deploy'
openshiftDeploy(deploymentConfig: 'frontend')
}Reference to Git Repository
kind: "BuildConfig"
apiVersion: "v1"
metadata:
name: "sample-pipeline"
spec:
source:
git:
uri: "https://github.com/openshift/ruby-hello-world"
strategy:
jenkinsPipelineStrategy:
jenkinsfilePath: some/repo/dir/filename - 1
- The optional
jenkinsfilePathfield specifies the name of the file to use, relative to the sourcecontextDir. IfcontextDiris omitted, it defaults to the root of the repository. IfjenkinsfilePathis omitted, it defaults to Jenkinsfile.
5.4.3. Using environment variables for pipeline builds
To make environment variables available to the Pipeline build process, you can add environment variables to the jenkinsPipelineStrategy definition of the BuildConfig.
Once defined, the environment variables will be set as parameters for any Jenkins job associated with the BuildConfig
Procedure
To define environment variables to be used during build:
jenkinsPipelineStrategy:
...
env:
- name: "FOO"
value: "BAR"
You can also manage environment variables defined in the BuildConfig with the oc set env command.
5.4.3.1. Mapping between BuildConfig environment variables and Jenkins job parameters
When a Jenkins job is created or updated based on changes to a Pipeline strategy BuildConfig, any environment variables in the BuildConfig are mapped to Jenkins job parameters definitions, where the default values for the Jenkins job parameters definitions are the current values of the associated environment variables.
After the Jenkins job’s initial creation, you can still add additional parameters to the job from the Jenkins console. The parameter names differ from the names of the environment variables in the BuildConfig. The parameters are honored when builds are started for those Jenkins jobs.
How you start builds for the Jenkins job dictates how the parameters are set.
-
If you start with
oc start-build, the values of the environment variables in theBuildConfigare the parameters set for the corresponding job instance. Any changes you make to the parameters' default values from the Jenkins console are ignored. TheBuildConfigvalues take precedence. If you start with
oc start-build -e, the values for the environment variables specified in the-eoption take precedence.-
If you specify an environment variable not listed in the
BuildConfig, they will be added as a Jenkins job parameter definitions. -
Any changes you make from the Jenkins console to the parameters corresponding to the environment variables are ignored. The
BuildConfigand what you specify withoc start-build -etakes precedence.
-
If you specify an environment variable not listed in the
- If you start the Jenkins job with the Jenkins console, then you can control the setting of the parameters with the Jenkins console as part of starting a build for the job.
It is recommended that you specify in the BuildConfig all possible environment variables to be associated with job parameters. Doing so reduces disk I/O and improves performance during Jenkins processing.
5.4.4. Pipeline build tutorial
This example demonstrates how to create an OpenShift Pipeline that will build, deploy, and verify a Node.js/MongoDB application using the nodejs-mongodb.json template.
Procedure
Create the Jenkins master:
$ oc project <project_name>1 $ oc new-app jenkins-ephemeral2 Create a file named nodejs-sample-pipeline.yaml with the following content:
NoteThis creates a
BuildConfigthat employs the Jenkins pipeline strategy to build, deploy, and scale theNode.js/MongoDBexample application.kind: "BuildConfig" apiVersion: "v1" metadata: name: "nodejs-sample-pipeline" spec: strategy: jenkinsPipelineStrategy: jenkinsfile: <pipeline content from below> type: JenkinsPipelineOnce you create a
BuildConfigwith ajenkinsPipelineStrategy, tell the pipeline what to do by using an inlinejenkinsfile:NoteThis example does not set up a Git repository for the application.
The following
jenkinsfilecontent is written in Groovy using the OpenShift DSL. For this example, include inline content in theBuildConfigusing the YAML Literal Style, though including ajenkinsfilein your source repository is the preferred method.def templatePath = 'https://raw.githubusercontent.com/openshift/nodejs-ex/master/openshift/templates/nodejs-mongodb.json'1 def templateName = 'nodejs-mongodb-example'2 pipeline { agent { node { label 'nodejs'3 } } options { timeout(time: 20, unit: 'MINUTES')4 } stages { stage('preamble') { steps { script { openshift.withCluster() { openshift.withProject() { echo "Using project: ${openshift.project()}" } } } } } stage('cleanup') { steps { script { openshift.withCluster() { openshift.withProject() { openshift.selector("all", [ template : templateName ]).delete()5 if (openshift.selector("secrets", templateName).exists()) {6 openshift.selector("secrets", templateName).delete() } } } } } } stage('create') { steps { script { openshift.withCluster() { openshift.withProject() { openshift.newApp(templatePath)7 } } } } } stage('build') { steps { script { openshift.withCluster() { openshift.withProject() { def builds = openshift.selector("bc", templateName).related('builds') timeout(5) {8 builds.untilEach(1) { return (it.object().status.phase == "Complete") } } } } } } } stage('deploy') { steps { script { openshift.withCluster() { openshift.withProject() { def rm = openshift.selector("dc", templateName).rollout() timeout(5) {9 openshift.selector("dc", templateName).related('pods').untilEach(1) { return (it.object().status.phase == "Running") } } } } } } } stage('tag') { steps { script { openshift.withCluster() { openshift.withProject() { openshift.tag("${templateName}:latest", "${templateName}-staging:latest")10 } } } } } } }- 1
- Path of the template to use.
- 2
- Name of the template that will be created.
- 3
- Spin up a
node.jsslave pod on which to run this build. - 4
- Set a timeout of 20 minutes for this pipeline.
- 5
- Delete everything with this template label.
- 6
- Delete any secrets with this template label.
- 7
- Create a new application from the
templatePath. - 8
- Wait up to five minutes for the build to complete.
- 9
- Wait up to five minutes for the deployment to complete.
- 10
- If everything else succeeded, tag the
$ {templateName}:latestimage as$ {templateName}-staging:latest. A pipelineBuildConfigfor the staging environment can watch for the$ {templateName}-staging:latestimage to change and then deploy it to the staging environment.
NoteThe previous example was written using the declarative pipeline style, but the older scripted pipeline style is also supported.
Create the Pipeline
BuildConfigin your OpenShift cluster:$ oc create -f nodejs-sample-pipeline.yamlIf you do not want to create your own file, you can use the sample from the Origin repository by running:
$ oc create -f https://raw.githubusercontent.com/openshift/origin/master/examples/jenkins/pipeline/nodejs-sample-pipeline.yaml
Start the Pipeline:
$ oc start-build nodejs-sample-pipelineNoteAlternatively, you can start your pipeline with the OpenShift Web Console by navigating to the Builds
Pipeline section and clicking Start Pipeline, or by visiting the Jenkins Console, navigating to the Pipeline that you created, and clicking Build Now. Once the pipeline is started, you should see the following actions performed within your project:
- A job instance is created on the Jenkins server.
- A slave pod is launched, if your pipeline requires one.
The pipeline runs on the slave pod, or the master if no slave is required.
-
Any previously created resources with the
template=nodejs-mongodb-examplelabel will be deleted. -
A new application, and all of its associated resources, will be created from the
nodejs-mongodb-exampletemplate. A build will be started using the
nodejs-mongodb-exampleBuildConfig.- The pipeline will wait until the build has completed to trigger the next stage.
A deployment will be started using the
nodejs-mongodb-exampledeployment configuration.- The pipeline will wait until the deployment has completed to trigger the next stage.
-
If the build and deploy are successful, the
nodejs-mongodb-example:latestimage will be tagged asnodejs-mongodb-example:stage.
-
Any previously created resources with the
The slave pod is deleted, if one was required for the pipeline.
NoteThe best way to visualize the pipeline execution is by viewing it in the OpenShift Web Console. You can view your pipelines by logging in to the web console and navigating to Builds
Pipelines.
5.5. Adding secrets with web console
You can add a secret to your build configuration so that it can access a private repository.
Procedure
To add a secret to your build configuration so that it can access a private repository:
- Create a new OpenShift Container Platform project.
- Create a secret that contains credentials for accessing a private source code repository.
- Create a build configuration.
-
On the build configuration editor page or in the
create app from builder imagepage of the web console, set the Source Secret. - Click the Save button.
5.6. Enabling pulling and pushing
You can enable pulling to a private registry by setting the Pull Secret and pushing by setting the Push Secret in the build configuration.
Procedure
To enable pulling to a private registry:
-
Set the
Pull Secretin the build configuration.
To enable pushing:
-
Set the
Push Secretin the build configuration.