Chapter 2. Understanding the Operator Lifecycle Manager (OLM)
2.1. Operator Lifecycle Manager workflow and architecture
This guide outlines the concepts and architecture of the Operator Lifecycle Manager (OLM) in OpenShift Container Platform.
2.1.1. Overview of the Operator Lifecycle Manager
In OpenShift Container Platform 4.2, the Operator Lifecycle Manager (OLM) helps users install, update, and manage the lifecycle of all Operators and their associated services running across their clusters. It is part of the Operator Framework, an open source toolkit designed to manage Kubernetes native applications (Operators) in an effective, automated, and scalable way.
Figure 2.1. Operator Lifecycle Manager workflow
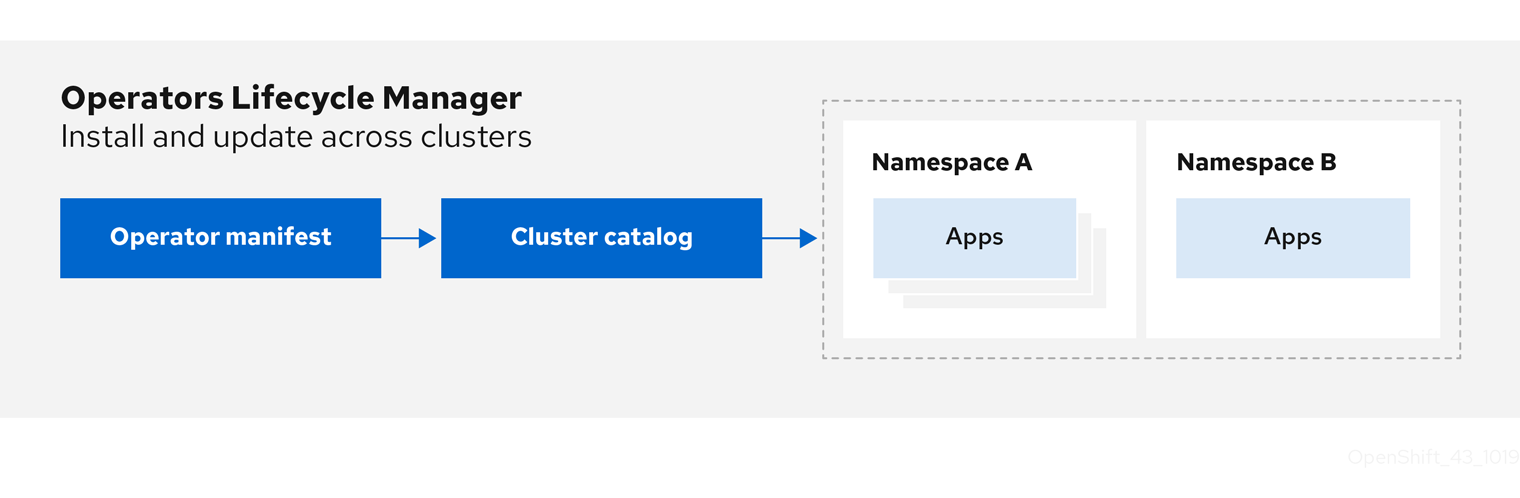
The OLM runs by default in OpenShift Container Platform 4.2, which aids cluster administrators in installing, upgrading, and granting access to Operators running on their cluster. The OpenShift Container Platform web console provides management screens for cluster administrators to install Operators, as well as grant specific projects access to use the catalog of Operators available on the cluster.
For developers, a self-service experience allows provisioning and configuring instances of databases, monitoring, and big data services without having to be subject matter experts, because the Operator has that knowledge baked into it.
2.1.2. ClusterServiceVersions (CSVs)
A ClusterServiceVersion (CSV) is a YAML manifest created from Operator metadata that assists the Operator Lifecycle Manager (OLM) in running the Operator in a cluster.
A CSV is the metadata that accompanies an Operator container image, used to populate user interfaces with information like its logo, description, and version. It is also a source of technical information needed to run the Operator, like the RBAC rules it requires and which Custom Resources (CRs) it manages or depends on.
A CSV is composed of:
- Metadata
Application metadata:
- Name, description, version (semver compliant), links, labels, icon, etc.
- Install strategy
Type: Deployment
- Set of service accounts and required permissions
- Set of Deployments.
- CRDs
- Type
- Owned: Managed by this service
- Required: Must exist in the cluster for this service to run
- Resources: A list of resources that the Operator interacts with
- Descriptors: Annotate CRD spec and status fields to provide semantic information
2.1.3. Operator installation and upgrade workflow in OLM
In the Operator Lifecycle Manager (OLM) ecosystem, the following resources are used to resolve Operator installations and upgrades:
- ClusterServiceVersion (CSV)
- CatalogSource
- Subscription
Operator metadata, defined in CSVs, can be stored in a collection called a CatalogSource. OLM uses CatalogSources, which use the Operator Registry API, to query for available Operators as well as upgrades for installed Operators.
Figure 2.2. CatalogSource overview
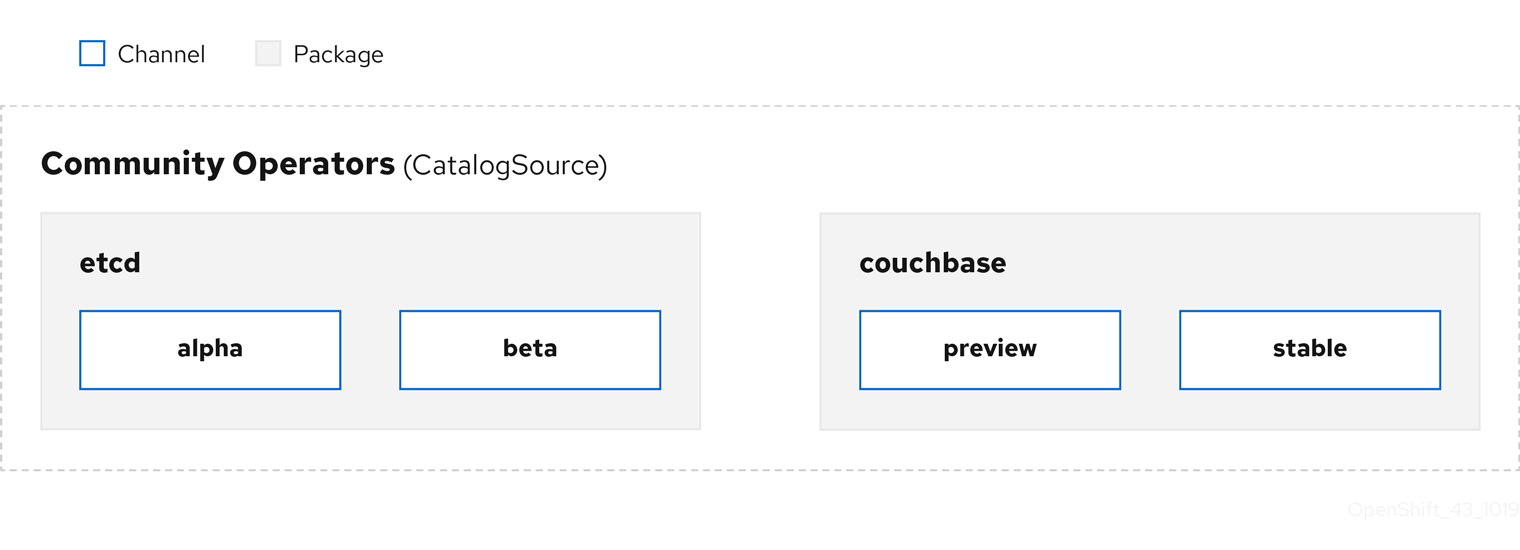
Within a CatalogSource, Operators are organized into packages and streams of updates called channels, which should be a familiar update pattern from OpenShift Container Platform or other software on a continuous release cycle like web browsers.
Figure 2.3. Packages and channels in a CatalogSource
A user indicates a particular package and channel in a particular CatalogSource in a Subscription, for example an etcd package and its alpha channel. If a Subscription is made to a package that has not yet been installed in the namespace, the latest Operator for that package is installed.
OLM deliberately avoids version comparisons, so the "latest" or "newest" Operator available from a given catalog
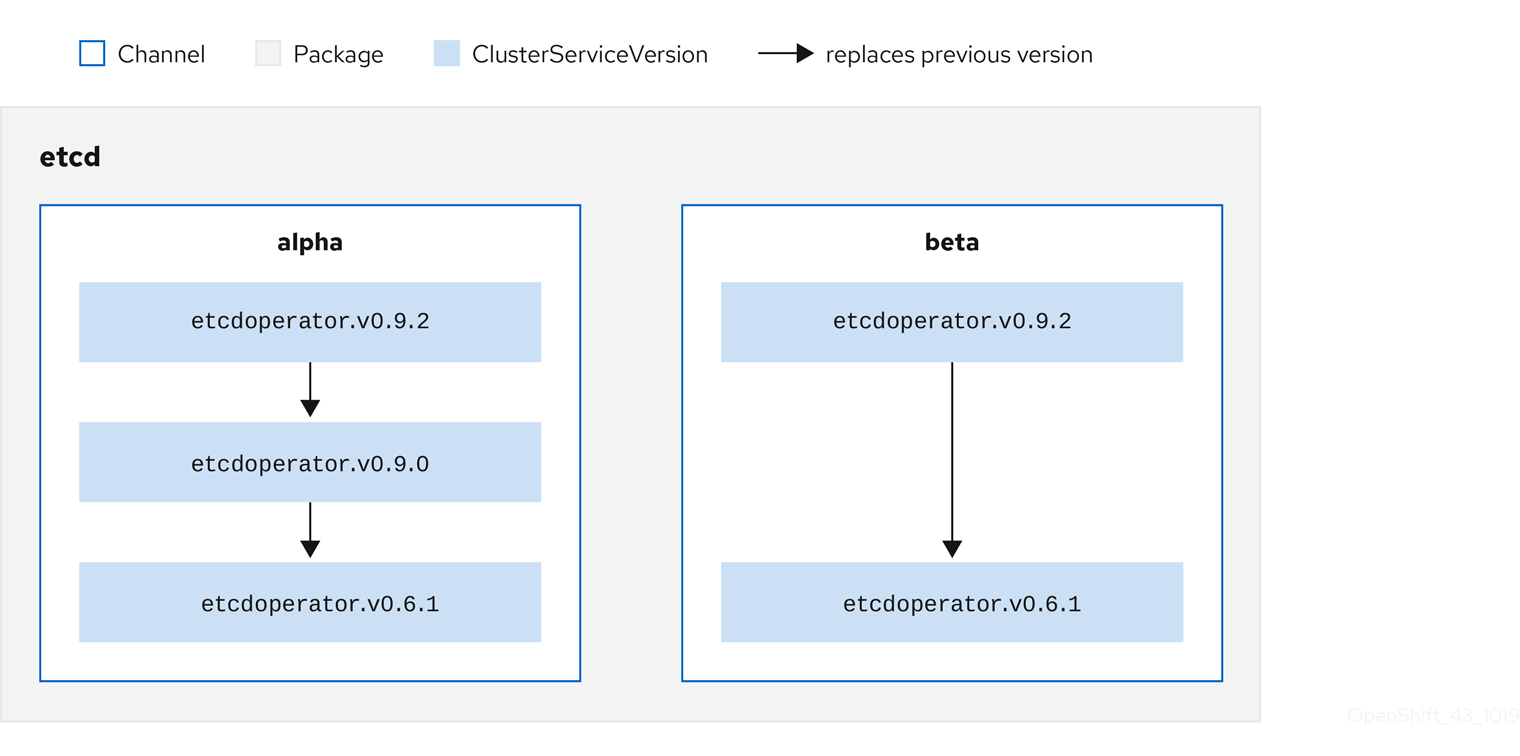
Each CSV has a replaces parameter that indicates which Operator it replaces. This builds a graph of CSVs that can be queried by OLM, and updates can be shared between channels. Channels can be thought of as entry points into the graph of updates:
Figure 2.4. OLM’s graph of available channel updates
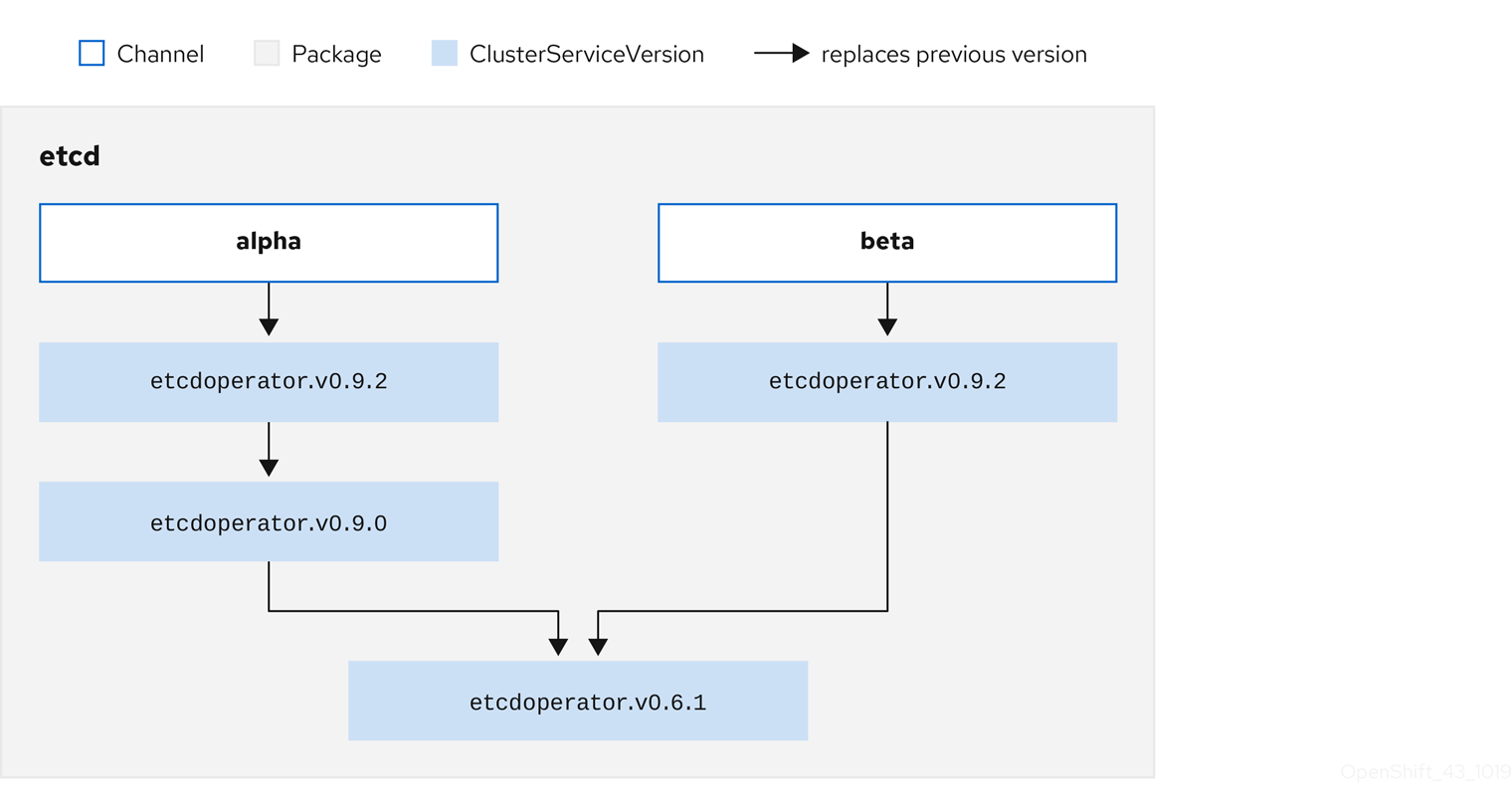
For example:
Channels in a package
packageName: example
channels:
- name: alpha
currentCSV: example.v0.1.2
- name: beta
currentCSV: example.v0.1.3
defaultChannel: alpha
For OLM to successfully query for updates, given a CatalogSource, package, channel, and CSV, a catalog must be able to return, unambiguously and deterministically, a single CSV that replaces the input CSV.
2.1.3.1. Example upgrade path
For an example upgrade scenario, consider an installed Operator corresponding to CSV version 0.1.1. OLM queries the CatalogSource and detects an upgrade in the subscribed channel with new CSV version 0.1.3 that replaces an older but not-installed CSV version 0.1.2, which in turn replaces the older and installed CSV version 0.1.1.
OLM walks back from the channel head to previous versions via the replaces field specified in the CSVs to determine the upgrade path 0.1.3 0.1.2 0.1.1; the direction of the arrow indicates that the former replaces the latter. OLM upgrades the Operator one version at the time until it reaches the channel head.
For this given scenario, OLM installs Operator version 0.1.2 to replace the existing Operator version 0.1.1. Then, it installs Operator version 0.1.3 to replace the previously installed Operator version 0.1.2. At this point, the installed operator version 0.1.3 matches the channel head and the upgrade is completed.
2.1.3.2. Skipping upgrades
OLM’s basic path for upgrades is:
- A CatalogSource is updated with one or more updates to an Operator.
- OLM traverses every version of the Operator until reaching the latest version the CatalogSource contains.
However, sometimes this is not a safe operation to perform. There will be cases where a published version of an Operator should never be installed on a cluster if it has not already, for example because a version introduces a serious vulnerability.
In those cases, OLM must consider two cluster states and provide an update graph that supports both:
- The "bad" intermediate Operator has been seen by the cluster and installed.
- The "bad" intermediate Operator has not yet been installed onto the cluster.
By shipping a new catalog and adding a skipped release, OLM is ensured that it can always get a single unique update regardless of the cluster state and whether it has seen the bad update yet.
For example:
CSV with skipped release
apiVersion: operators.coreos.com/v1alpha1
kind: ClusterServiceVersion
metadata:
name: etcdoperator.v0.9.2
namespace: placeholder
annotations:
spec:
displayName: etcd
description: Etcd Operator
replaces: etcdoperator.v0.9.0
skips:
- etcdoperator.v0.9.1Consider the following example Old CatalogSource and New CatalogSource:
Figure 2.5. Skipping updates
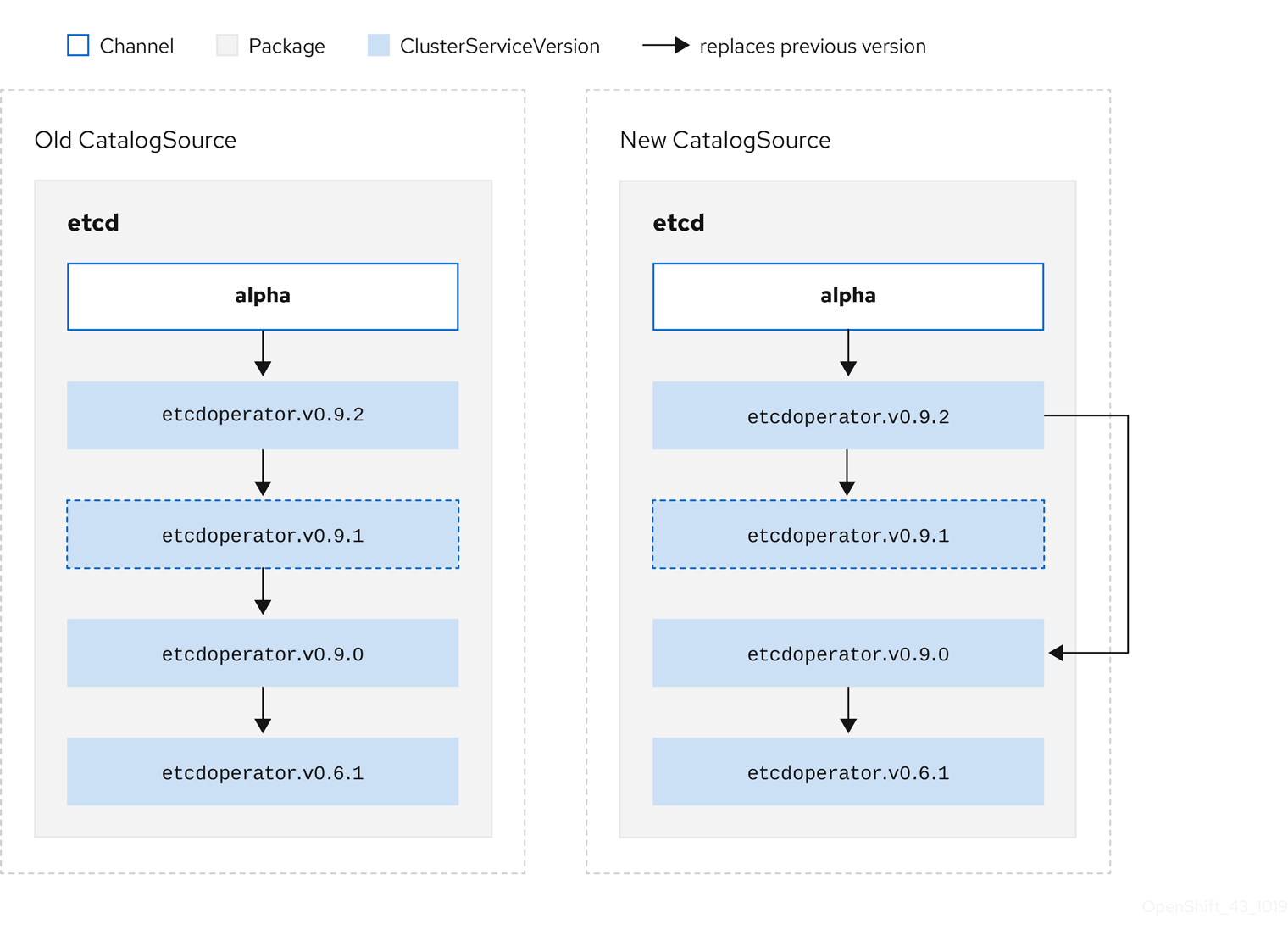
This graph maintains that:
- Any Operator found in Old CatalogSource has a single replacement in New CatalogSource.
- Any Operator found in New CatalogSource has a single replacement in New CatalogSource.
- If the bad update has not yet been installed, it will never be.
2.1.3.3. Replacing multiple Operators
Creating the New CatalogSource as described requires publishing CSVs that replace one Operator, but can skip several. This can be accomplished using the skipRange annotation:
olm.skipRange: <semver_range>
where <semver_range> has the version range format supported by the semver library.
When searching catalogs for updates, if the head of a channel has a skipRange annotation and the currently installed Operator has a version field that falls in the range, OLM updates to the latest entry in the channel.
The order of precedence is:
-
Channel head in the source specified by
sourceNameon the Subscription, if the other criteria for skipping are met. -
The next Operator that replaces the current one, in the source specified by
sourceName. - Channel head in another source that is visible to the Subscription, if the other criteria for skipping are met.
- The next Operator that replaces the current one in any source visible to the Subscription.
For example:
CSV with skipRange
apiVersion: operators.coreos.com/v1alpha1
kind: ClusterServiceVersion
metadata:
name: elasticsearch-operator.v4.1.2
namespace: <namespace>
annotations:
olm.skipRange: '>=4.1.0 <4.1.2'2.1.3.4. Z-stream support
A z-stream, or patch release, must replace all previous z-stream releases for the same minor version. OLM does not care about major, minor, or patch versions, it just needs to build the correct graph in a catalog.
In other words, OLM must be able to take a graph as in Old CatalogSource and, similar to before, generate a graph as in New CatalogSource:
Figure 2.6. Replacing several Operators
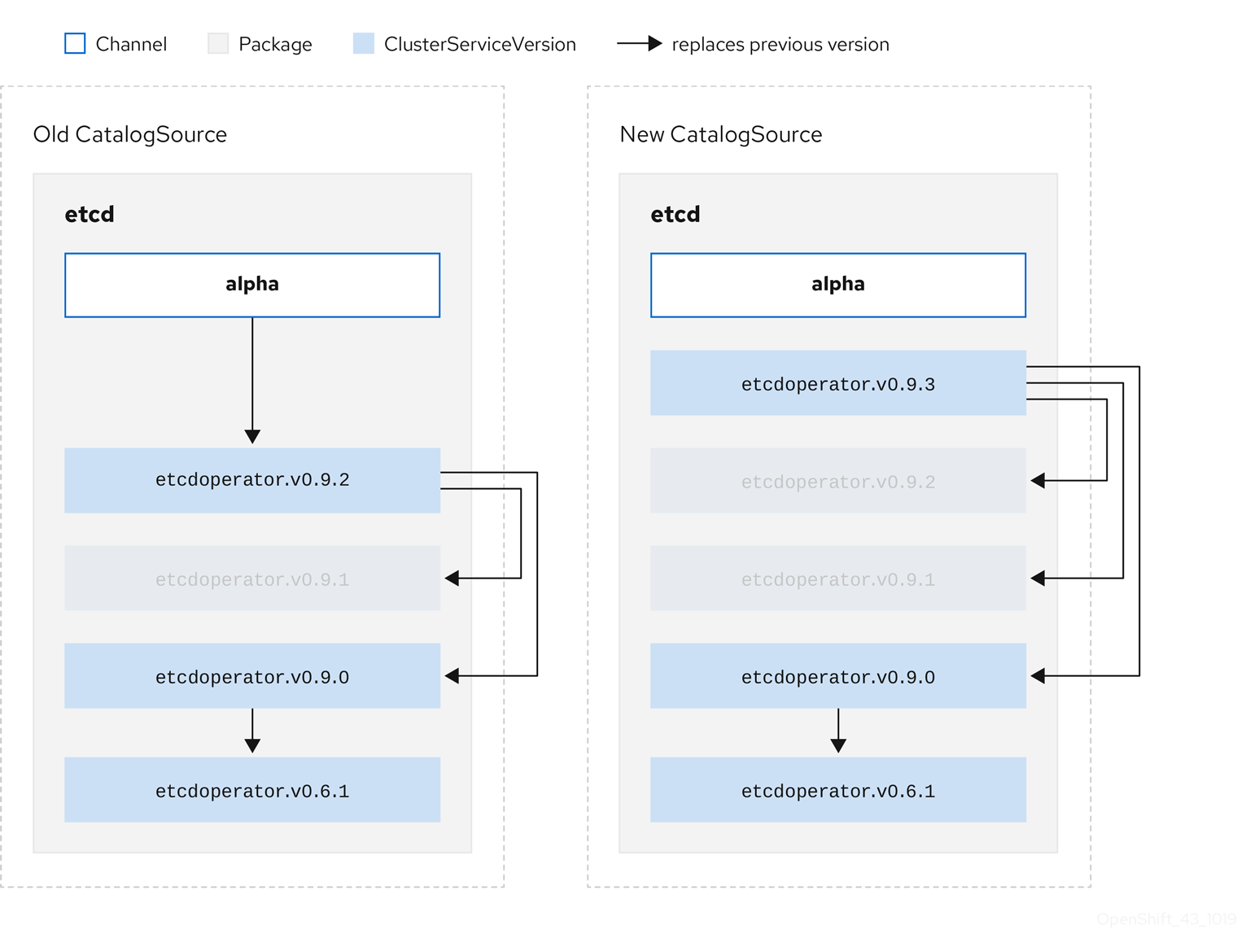
This graph maintains that:
- Any Operator found in Old CatalogSource has a single replacement in New CatalogSource.
- Any Operator found in New CatalogSource has a single replacement in New CatalogSource.
- Any z-stream release in Old CatalogSource will update to the latest z-stream release in New CatalogSource.
- Unavailable releases can be considered "virtual" graph nodes; their content does not need to exist, the registry just needs to respond as if the graph looks like this.
2.1.4. Operator Lifecycle Manager architecture
The Operator Lifecycle Manager is composed of two Operators: the OLM Operator and the Catalog Operator.
Each of these Operators is responsible for managing the Custom Resource Definitions (CRDs) that are the basis for the OLM framework:
| Resource | Short name | Owner | Description |
|---|---|---|---|
| ClusterServiceVersion |
| OLM | Application metadata: name, version, icon, required resources, installation, etc. |
| InstallPlan |
| Catalog | Calculated list of resources to be created in order to automatically install or upgrade a CSV. |
| CatalogSource |
| Catalog | A repository of CSVs, CRDs, and packages that define an application. |
| Subscription |
| Catalog | Used to keep CSVs up to date by tracking a channel in a package. |
| OperatorGroup |
| OLM | Used to group multiple namespaces and prepare them for use by an Operator. |
Each of these Operators is also responsible for creating resources:
| Resource | Owner |
|---|---|
| Deployments | OLM |
| ServiceAccounts | |
| (Cluster)Roles | |
| (Cluster)RoleBindings | |
| Custom Resource Definitions (CRDs) | Catalog |
| ClusterServiceVersions (CSVs) |
2.1.4.1. OLM Operator
The OLM Operator is responsible for deploying applications defined by CSV resources after the required resources specified in the CSV are present in the cluster.
The OLM Operator is not concerned with the creation of the required resources; users can choose to manually create these resources using the CLI, or users can choose to create these resources using the Catalog Operator. This separation of concern allows users incremental buy-in in terms of how much of the OLM framework they choose to leverage for their application.
While the OLM Operator is often configured to watch all namespaces, it can also be operated alongside other OLM Operators so long as they all manage separate namespaces.
OLM Operator workflow
Watches for ClusterServiceVersion (CSVs) in a namespace and checks that requirements are met. If so, runs the install strategy for the CSV.
NoteA CSV must be an active member of an OperatorGroup in order for the install strategy to be run.
2.1.4.2. Catalog Operator
The Catalog Operator is responsible for resolving and installing CSVs and the required resources they specify. It is also responsible for watching CatalogSources for updates to packages in channels and upgrading them (optionally automatically) to the latest available versions.
A user who wishes to track a package in a channel creates a Subscription resource configuring the desired package, channel, and the CatalogSource from which to pull updates. When updates are found, an appropriate InstallPlan is written into the namespace on behalf of the user.
Users can also create an InstallPlan resource directly, containing the names of the desired CSV and an approval strategy, and the Catalog Operator creates an execution plan for the creation of all of the required resources. After it is approved, the Catalog Operator creates all of the resources in an InstallPlan; this then independently satisfies the OLM Operator, which proceeds to install the CSVs.
Catalog Operator workflow
- Has a cache of CRDs and CSVs, indexed by name.
Watches for unresolved InstallPlans created by a user:
- Finds the CSV matching the name requested and adds it as a resolved resource.
- For each managed or required CRD, adds it as a resolved resource.
- For each required CRD, finds the CSV that manages it.
- Watches for resolved InstallPlans and creates all of the discovered resources for it (if approved by a user or automatically).
- Watches for CatalogSources and Subscriptions and creates InstallPlans based on them.
2.1.4.3. Catalog Registry
The Catalog Registry stores CSVs and CRDs for creation in a cluster and stores metadata about packages and channels.
A package manifest is an entry in the Catalog Registry that associates a package identity with sets of CSVs. Within a package, channels point to a particular CSV. Because CSVs explicitly reference the CSV that they replace, a package manifest provides the Catalog Operator all of the information that is required to update a CSV to the latest version in a channel, stepping through each intermediate version.
2.1.5. Exposed metrics
The Operator Lifecycle Manager (OLM) exposes certain OLM-specific resources for use by the Prometheus-based OpenShift Container Platform cluster monitoring stack.
| Name | Description |
|---|---|
|
| Number of CSVs successfully registered. |
|
| Number of InstallPlans. |
|
| Number of Subscriptions. |
|
| Monotonic count of CatalogSources. |
2.2. Operator Lifecycle Manager dependency resolution
This guide outlines dependency resolution and Custom Resource Definition (CRD) upgrade lifecycles within the Operator Lifecycle Manager (OLM) in OpenShift Container Platform.
2.2.1. About dependency resolution
OLM manages the dependency resolution and upgrade lifecycle of running Operators. In many ways, the problems OLM faces are similar to other operating system package managers like yum and rpm.
However, there is one constraint that similar systems do not generally have that OLM does: because Operators are always running, OLM attempts to ensure that you are never left with a set of Operators that do not work with each other.
This means that OLM must never:
- install a set of Operators that require APIs that cannot be provided, or
- update an Operator in a way that breaks another that depends upon it.
2.2.2. Custom Resource Definition (CRD) upgrades
OLM upgrades a Custom Resource Definition (CRD) immediately if it is owned by a singular Cluster Service Version (CSV). If a CRD is owned by multiple CSVs, then the CRD is upgraded when it has satisfied all of the following backward compatible conditions:
- All existing serving versions in the current CRD are present in the new CRD.
- All existing instances, or Custom Resources (CRs), that are associated with the serving versions of the CRD are valid when validated against the new CRD’s validation schema.
2.2.2.1. Adding a new CRD version
Procedure
To add a new version of a CRD:
Add a new entry in the CRD resource under the
versionssection.For example, if the current CRD has one version
v1alpha1and you want to add a new versionv1beta1and mark it as the new storage version:versions: - name: v1alpha1 served: true storage: false - name: v1beta11 served: true storage: true- 1
- Add a new entry for
v1beta1.
Ensure the referencing version of the CRD in your CSV’s
ownedsection is updated if the CSV intends to use the new version:customresourcedefinitions: owned: - name: cluster.example.com version: v1beta11 kind: cluster displayName: Cluster- 1
- Update the
version.
- Push the updated CRD and CSV to your bundle.
2.2.2.2. Deprecating or removing a CRD version
OLM does not allow a serving version of a CRD to be removed right away. Instead, a deprecated version of the CRD must be first disabled by setting the served field in the CRD to false. Then, the non-serving version can be removed on the subsequent CRD upgrade.
Procedure
To deprecate and remove a specific version of a CRD:
Mark the deprecated version as non-serving to indicate this version is no longer in use and may be removed in a subsequent upgrade. For example:
versions: - name: v1alpha1 served: false1 storage: true- 1
- Set to
false.
Switch the
storageversion to a serving version if the version to be deprecated is currently thestorageversion. For example:versions: - name: v1alpha1 served: false storage: false1 - name: v1beta1 served: true storage: true2 NoteIn order to remove a specific version that is or was the
storageversion from a CRD, that version must be removed from thestoredVersionin the CRD’s status. OLM will attempt to do this for you if it detects a stored version no longer exists in the new CRD.- Upgrade the CRD with the above changes.
In subsequent upgrade cycles, the non-serving version can be removed completely from the CRD. For example:
versions: - name: v1beta1 served: true storage: true-
Ensure the referencing version of the CRD in your CSV’s
ownedsection is updated accordingly if that version is removed from the CRD.
2.2.3. Example dependency resolution scenarios
In the following examples, a provider is an Operator which "owns" a CRD or APIService.
Example: Deprecating dependent APIs
A and B are APIs (e.g., CRDs):
- A’s provider depends on B.
- B’s provider has a Subscription.
- B’s provider updates to provide C but deprecates B.
This results in:
- B no longer has a provider.
- A no longer works.
This is a case OLM prevents with its upgrade strategy.
Example: Version deadlock
A and B are APIs:
- A’s provider requires B.
- B’s provider requires A.
- A’s provider updates to (provide A2, require B2) and deprecate A.
- B’s provider updates to (provide B2, require A2) and deprecate B.
If OLM attempts to update A without simultaneously updating B, or vice-versa, it is unable to progress to new versions of the Operators, even though a new compatible set can be found.
This is another case OLM prevents with its upgrade strategy.
2.3. OperatorGroups
This guide outlines the use of OperatorGroups with the Operator Lifecycle Manager (OLM) in OpenShift Container Platform.
2.3.1. About OperatorGroups
An OperatorGroup is an OLM resource that provides multitenant configuration to OLM-installed Operators. An OperatorGroup selects a set of target namespaces in which to generate required RBAC access for its member Operators.
The set of target namespaces is provided by a comma-delimited string stored in the ClusterServiceVersion’s (CSV) olm.targetNamespaces annotation. This annotation is applied to member Operator’s CSV instances and is projected into their deployments.
2.3.2. OperatorGroup membership
An Operator is considered a member of an OperatorGroup if the following conditions are true:
- The Operator’s CSV exists in the same namespace as the OperatorGroup.
- The Operator’s CSV’s InstallModes support the set of namespaces targeted by the OperatorGroup.
An InstallMode consists of an InstallModeType field and a boolean Supported field. A CSV’s spec can contain a set of InstallModes of four distinct InstallModeTypes:
| InstallModeType | Description |
|---|---|
|
| The Operator can be a member of an OperatorGroup that selects its own namespace. |
|
| The Operator can be a member of an OperatorGroup that selects one namespace. |
|
| The Operator can be a member of an OperatorGroup that selects more than one namespace. |
|
|
The Operator can be a member of an OperatorGroup that selects all namespaces (target namespace set is the empty string |
If a CSV’s spec omits an entry of InstallModeType, then that type is considered unsupported unless support can be inferred by an existing entry that implicitly supports it.
2.3.3. Target namespace selection
The set of namespaces for the OperatorGroup is specified using a label selector with the spec.selector field:
apiVersion: operators.coreos.com/v1
kind: OperatorGroup
metadata:
name: my-group
namespace: my-namespace
spec:
selector:
matchLabels:
cool.io/prod: "true"
You can also explicitly name the target namespaces using the spec.targetNamespaces field:
apiVersion: operators.coreos.com/v1
kind: OperatorGroup
metadata:
name: my-group
namespace: my-namespace
spec:
targetNamespaces:
- my-namespace
- my-other-namespace
- my-other-other-namespace
If both spec.targetNamespaces and spec.selector are defined, spec.selector is ignored.
Alternatively, you can omit both spec.selector and spec.targetNamespaces to specify a global OperatorGroup, which selects all namespaces:
apiVersion: operators.coreos.com/v1
kind: OperatorGroup
metadata:
name: my-group
namespace: my-namespace
The resolved set of selected namespaces is shown in an OperatorGroup’s status.namespaces field. A global OperatorGroup’s status.namespace contains the empty string (""), which signals to a consuming Operator that it should watch all namespaces.
2.3.4. OperatorGroup CSV annotations
Member CSVs of an OperatorGroup have the following annotations:
| Annotation | Description |
|---|---|
|
| Contains the name of the OperatorGroup. |
|
| Contains the namespace of the OperatorGroup. |
|
| Contains a comma-delimited string that lists the OperatorGroup’s target namespace selection. |
All annotations except olm.targetNamespaces are included with copied CSVs. Omitting the olm.targetNamespaces annotation on copied CSVs prevents the duplication of target namespaces between tenants.
2.3.5. Provided APIs annotation
Information about what GroupVersionKinds (GVKs) are provided by an OperatorGroup are shown in an olm.providedAPIs annotation. The annotation’s value is a string consisting of <kind>.<version>.<group> delimited with commas. The GVKs of CRDs and APIServices provided by all active member CSVs of an OperatorGroup are included.
Review the following example of an OperatorGroup with a single active member CSV that provides the PackageManifest resource:
apiVersion: operators.coreos.com/v1
kind: OperatorGroup
metadata:
annotations:
olm.providedAPIs: PackageManifest.v1alpha1.packages.apps.redhat.com
name: olm-operators
namespace: local
...
spec:
selector: {}
serviceAccount:
metadata:
creationTimestamp: null
targetNamespaces:
- local
status:
lastUpdated: 2019-02-19T16:18:28Z
namespaces:
- local2.3.6. Role-based access control
When an OperatorGroup is created, three ClusterRoles are generated. Each contains a single AggregationRule with a ClusterRoleSelector set to match a label, as shown below:
| ClusterRole | Label to match |
|---|---|
|
|
|
|
|
|
|
|
|
The following RBAC resources are generated when a CSV becomes an active member of an OperatorGroup, as long as the CSV is watching all namespaces with the AllNamespaces InstallMode and is not in a failed state with reason InterOperatorGroupOwnerConflict.
| ClusterRole | Settings |
|---|---|
|
|
Verbs on
Aggregation labels:
|
|
|
Verbs on
Aggregation labels:
|
|
|
Verbs on
Aggregation labels:
|
|
|
Verbs on
Aggregation labels:
|
| ClusterRole | Settings |
|---|---|
|
|
Verbs on
Aggregation labels:
|
|
|
Verbs on
Aggregation labels:
|
|
|
Verbs on
Aggregation labels:
|
Additional Roles and RoleBindings
-
If the CSV defines exactly one target namespace that contains
*, then a ClusterRole and corresponding ClusterRoleBinding are generated for each permission defined in the CSV’s permissions field. All resources generated are given theolm.owner: <csv_name>andolm.owner.namespace: <csv_namespace>labels. -
If the CSV does not define exactly one target namespace that contains
*, then all Roles and RoleBindings in the Operator namespace with theolm.owner: <csv_name>andolm.owner.namespace: <csv_namespace>labels are copied into the target namespace.
2.3.7. Copied CSVs
OLM creates copies of all active member CSVs of an OperatorGroup in each of that OperatorGroup’s target namespaces. The purpose of a copied CSV is to tell users of a target namespace that a specific Operator is configured to watch resources created there. Copied CSVs have a status reason Copied and are updated to match the status of their source CSV. The olm.targetNamespaces annotation is stripped from copied CSVs before they are created on the cluster. Omitting the target namespace selection avoids the duplication of target namespaces between tenants. Copied CSVs are deleted when their source CSV no longer exists or the OperatorGroup that their source CSV belongs to no longer targets the copied CSV’s namespace.
2.3.8. Static OperatorGroups
An OperatorGroup is static if its spec.staticProvidedAPIs field is set to true. As a result, OLM does not modify the OperatorGroup’s olm.providedAPIs annotation, which means that it can be set in advance. This is useful when a user wants to use an OperatorGroup to prevent resource contention in a set of namespaces but does not have active member CSVs that provide the APIs for those resources.
Below is an example of an OperatorGroup that protects Prometheus resources in all namespaces with the something.cool.io/cluster-monitoring: "true" annotation:
apiVersion: operators.coreos.com/v1
kind: OperatorGroup
metadata:
name: cluster-monitoring
namespace: cluster-monitoring
annotations:
olm.providedAPIs: Alertmanager.v1.monitoring.coreos.com,Prometheus.v1.monitoring.coreos.com,PrometheusRule.v1.monitoring.coreos.com,ServiceMonitor.v1.monitoring.coreos.com
spec:
staticProvidedAPIs: true
selector:
matchLabels:
something.cool.io/cluster-monitoring: "true"2.3.9. OperatorGroup intersection
Two OperatorGroups are said to have intersecting provided APIs if the intersection of their target namespace sets is not an empty set and the intersection of their provided API sets, defined by olm.providedAPIs annotations, is not an empty set.
A potential issue is that OperatorGroups with intersecting provided APIs can compete for the same resources in the set of intersecting namespaces.
When checking intersection rules, an OperatorGroup’s namespace is always included as part of its selected target namespaces.
Rules for intersection
Each time an active member CSV synchronizes, OLM queries the cluster for the set of intersecting provided APIs between the CSV’s OperatorGroup and all others. OLM then checks if that set is an empty set:
If
trueand the CSV’s provided APIs are a subset of the OperatorGroup’s:- Continue transitioning.
If
trueand the CSV’s provided APIs are not a subset of the OperatorGroup’s:If the OperatorGroup is static:
- Clean up any deployments that belong to the CSV.
-
Transition the CSV to a failed state with status reason
CannotModifyStaticOperatorGroupProvidedAPIs.
If the OperatorGroup is not static:
-
Replace the OperatorGroup’s
olm.providedAPIsannotation with the union of itself and the CSV’s provided APIs.
-
Replace the OperatorGroup’s
If
falseand the CSV’s provided APIs are not a subset of the OperatorGroup’s:- Clean up any deployments that belong to the CSV.
-
Transition the CSV to a failed state with status reason
InterOperatorGroupOwnerConflict.
If
falseand the CSV’s provided APIs are a subset of the OperatorGroup’s:If the OperatorGroup is static:
- Clean up any deployments that belong to the CSV.
-
Transition the CSV to a failed state with status reason
CannotModifyStaticOperatorGroupProvidedAPIs.
If the OperatorGroup is not static:
-
Replace the OperatorGroup’s
olm.providedAPIsannotation with the difference between itself and the CSV’s provided APIs.
-
Replace the OperatorGroup’s
Failure states caused by OperatorGroups are non-terminal.
The following actions are performed each time an OperatorGroup synchronizes:
- The set of provided APIs from active member CSVs is calculated from the cluster. Note that copied CSVs are ignored.
-
The cluster set is compared to
olm.providedAPIs, and ifolm.providedAPIscontains any extra APIs, then those APIs are pruned. - All CSVs that provide the same APIs across all namespaces are requeued. This notifies conflicting CSVs in intersecting groups that their conflict has possibly been resolved, either through resizing or through deletion of the conflicting CSV.
2.3.10. Troubleshooting OperatorGroups
Membership
-
If more than one OperatorGroup exists in a single namespace, any CSV created in that namespace will transition to a failure state with the reason
TooManyOperatorGroups. CSVs in a failed state for this reason will transition to pending once the number of OperatorGroups in their namespaces reaches one. -
If a CSV’s InstallModes do not support the target namespace selection of the OperatorGroup in its namespace, the CSV will transition to a failure state with the reason
UnsupportedOperatorGroup. CSVs in a failed state for this reason will transition to pending once either the OperatorGroup’s target namespace selection changes to a supported configuration, or the CSV’s InstallModes are modified to support the OperatorGroup’s target namespace selection.