3.3. OpenShift Container Platform etcd 主机的建议实践
etcd 是一个分布式键值存储,OpenShift Container Platform 用于配置它。
| OpenShift Container Platform 版本 | etcd 版本 | 存储 schema 版本 |
| 3.3 及更早版本 | 2.x | v2 |
| 3.4 和 3.5 | 3.x | v2 |
| 3.6 | 3.x | v2(升级) |
| 3.6 | 3.x | v3(新安装) |
| 3.7 及更新的版本 | 3.x | v3 |
etcd 3.x 引入了重要的可伸缩性和性能改进,用于减少任意大小集群的 CPU、内存、网络和磁盘要求。etcd 3.x 还会实施后向兼容的存储 API,促进磁盘 etcd 数据库的两个步骤迁移。出于迁移目的,OpenShift Container Platform 3.5 中 etcd 3.x 使用的存储模式保留在 v2 模式中。自 OpenShift Container Platform 3.6 起,新安装使用存储模式 v3。从以前的 OpenShift Container Platform 版本升级不会自动将数据从 v2 迁移到 v3。您必须使用提供的 playbook,并遵循记录的流程来迁移数据。
etcd 版本 3 实现了向后兼容的存储 API,有助于对磁盘 etcd 数据库进行两步迁移。出于迁移目的,OpenShift Container Platform 3.5 中 etcd 3.x 使用的存储模式保留在 v2 模式中。自 OpenShift Container Platform 3.6 起,新安装使用存储模式 v3。作为升级到 OpenShift Container Platform 3.7 的过程的一部分,如果需要,您需要将 etcd 存储 API 升级到 v3。在版本 3.7 及更新的版本中,必须使用 v3 API。
除了更改 v3 的新安装模式外,OpenShift Container Platform 3.6 也会开始对所有 OpenShift Container Platform 类型进行 enforcing 仲裁读取。这是为了确保对 etcd 的查询不会返回过时的数据。在单节点 etcd 集群中,过时的数据不是问题。在高可用的 etcd 部署中,通常在生产集群中找到,仲裁读取确保有效的查询结果。在数据库术语中,仲裁读是 线性的 - 每个客户端都会看到集群的最新更新状态,所有客户端会看到相同的读写序列。有关性能改进的更多信息,请参阅 etcd 3.1 公告。
请注意,OpenShift Container Platform 使用 etcd 来存储 Kubernetes 本身所需的其他信息。例如,OpenShift Container Platform 在 etcd 中存储有关镜像、构建和其他组件的信息,如 OpenShift Container Platform 在 Kubernetes 之上添加的功能需要。最后,这意味着 etcd 主机性能和大小调整的信息将与 Kubernetes 和其他建议有所不同。红帽使用 OpenShift Container Platform 用例和参数测试 etcd 可扩展性和性能,以生成最准确的建议。
使用 cluster-loader 实用程序使用 300 个节点 OpenShift Container Platform 3.6 集群来量化性能。etcd 3.x(存储模式 v2)与 etcd 3.x(存储模式 v3)的比较,会在下面的图表中识别出清晰的信息。
在负载下显著降低存储 IOPS:
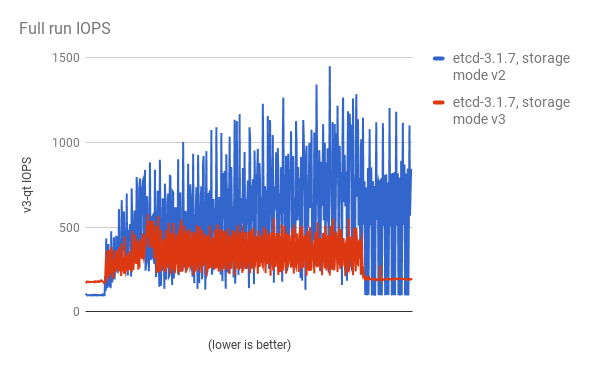
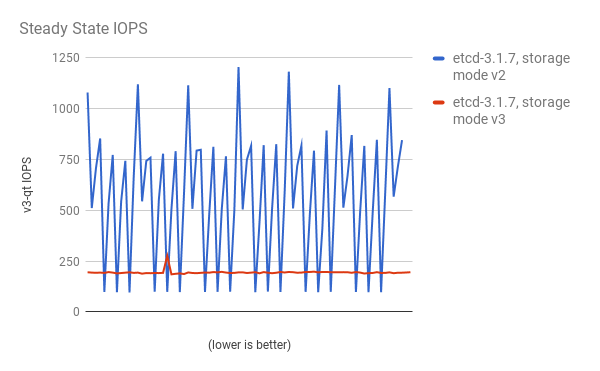
稳定状态的存储 IOPS 也显著降低:
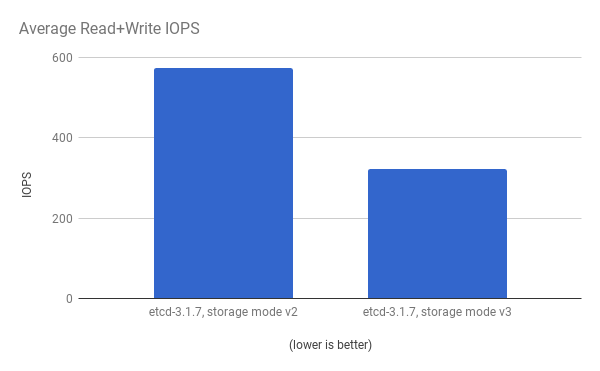
查看相同的 I/O 数据,在两个模式中绘制平均 IOPS:
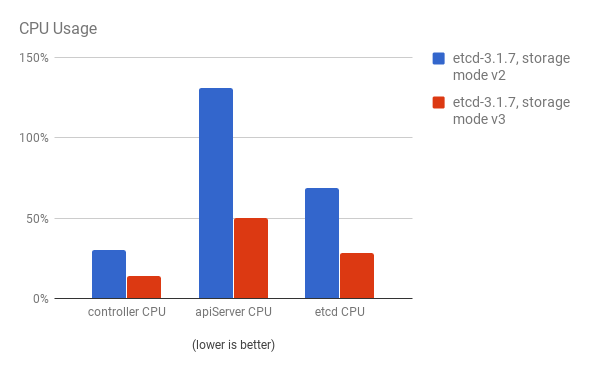
API 服务器(master)和 etcd 进程的 CPU 使用率会减少:
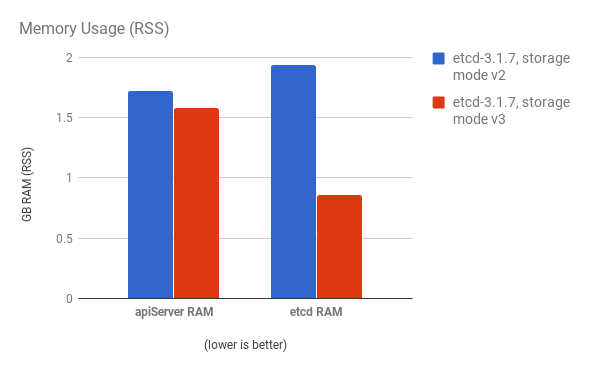
API 服务器(master)和 etcd 进程的内存使用率也会减少:
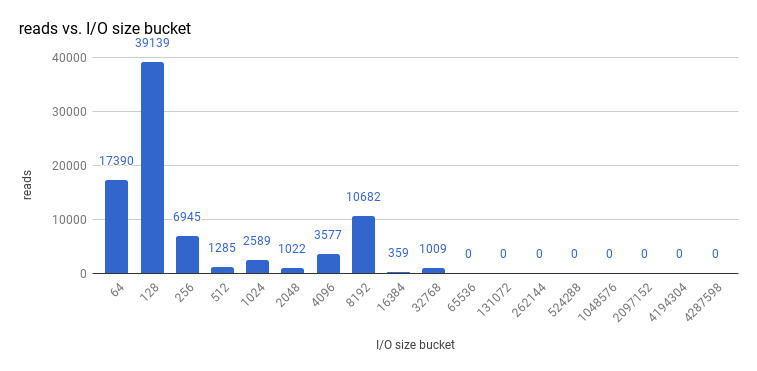
在 OpenShift Container Platform 下分析 etcd 后,etcd 通常会执行少量存储输入和输出。强烈建议您使用带有可快速处理较小读写操作的存储的 etcd。
查看 etcd 3.1 的 3 节点集群(使用存储 v3 模式和仲裁读取强制)执行的大小 I/O 操作,如下所示:
和写入:
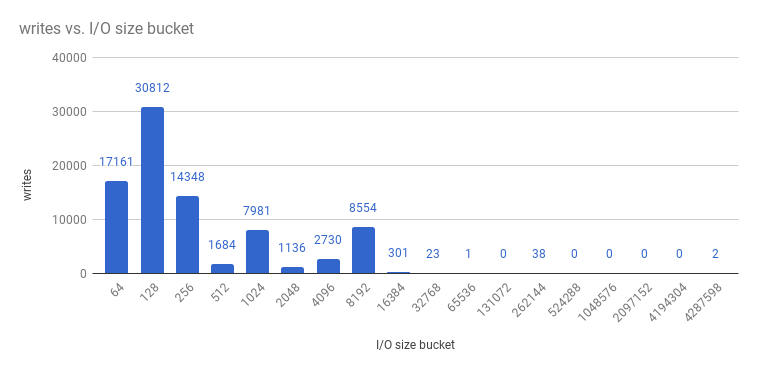
etcd 进程通常是内存密集型。Master/API 服务器进程是 CPU 密集型。这使得他们在一台虚拟机或虚拟机(VM)内合理地定位对。通过在同一个主机上定位或提供专用网络,以此优化 etcd 和 master 主机之间的通信。
3.3.1. 通过 OpenStack 使用 PCI 透传向 etcd 节点提供存储
要为 etcd 节点提供快速存储以便 etcd 在大规模稳定,使用 PCI 透传将非易失性内存表达(NVMe)设备直接传递给 etcd 节点。要使用 Red Hat OpenStack 11 或更高版本进行设置,请在存在 PCI 设备的 OpenStack 节点上完成以下内容。
- 确定在 BIOS 中启用了 Intel Vt-x。
-
启用 input-output 内存管理单元(IOMMU)。在 /etc/sysconfig/grub 文件中,将
intel_iommu=on iommu=pt添加到GRUB_CMDLINX_LINUX行的末尾(在括号内)。 运行以下命令重新生成 /etc/grub2.cfg :
$ grub2-mkconfig -o /etc/grub2.cfg- 重启系统:
在 /etc/nova.conf 中的控制器上:
[filter_scheduler] enabled_filters=RetryFilter,AvailabilityZoneFilter,RamFilter,DiskFilter,ComputeFilter,ComputeCapabilitiesFilter,ImagePropertiesFilter,ServerGroupAntiAffinityFilter,ServerGroupAffinityFilter,PciPassthroughFilter available_filters=nova.scheduler.filters.all_filters [pci] alias = { "vendor_id":"144d", "product_id":"a820", "device_type":"type-PCI", "name":"nvme" }-
在控制器上重启
nova-api和nova-scheduler。 在 /etc/nova/nova.conf 中的计算节点上:
[pci] passthrough_whitelist = { "address": "0000:06:00.0" } alias = { "vendor_id":"144d", "product_id":"a820", "device_type":"type-PCI", "name":"nvme" }要检索您想要透传的 NVMe 设备的
address、vendor_id和product_id值,请运行:# lspci -nn | grep devicename-
重启计算节点上的
nova-compute。 - 将您正在运行的 OpenStack 版本配置为使用 NVMe 并启动 etcd 节点。