2.2. 集群更新如何工作
以下小节详细介绍了 OpenShift Container Platform (OCP) 更新过程的每个主要方面。有关更新如何工作的一般信息,请参阅 OpenShift 更新简介。
2.2.1. Cluster Version Operator
Cluster Version Operator (CVO) 是编配并协助 OpenShift Container Platform 更新过程的主要组件。在安装和标准集群操作过程中,CVO 会持续将受管集群 Operator 的清单与集群资源中的清单进行比较,并协调差异以确保这些资源的实际状态与所需状态匹配。
2.2.1.1. ClusterVersion 对象
Cluster Version Operator (CVO) 监控的资源之一是 ClusterVersion 资源。
管理员和 OpenShift 组件可以通过 ClusterVersion 对象与 CVO 通信或交互。所需的 CVO 状态通过 ClusterVersion 对象声明,当前 CVO 状态反映在对象的状态中。
不要直接修改 ClusterVersion 对象。反之,使用 oc CLI 或 Web 控制台等接口来声明您的更新目标。
CVO 持续将集群与 ClusterVersion 资源的 spec 属性中声明的目标状态进行协调。当所需的发行版本与实际发行版本不同时,协调会更新集群。
更新可用性数据
ClusterVersion 资源还包含集群可用的更新信息。这包括可用更新,但不推荐因为应用到集群的已知风险而不推荐。这些更新称为条件更新。要了解 CVO 如何在 ClusterVersion 资源中维护此信息,请参阅"更新可用性评估"部分。
您可以使用以下命令检查所有可用更新:
$ oc adm upgrade --include-not-recommended注意额外的
--include-not-recommended参数包括可用的更新,但不推荐因为应用到集群的已知风险而不建议这样做。输出示例
Cluster version is 4.10.22 Upstream is unset, so the cluster will use an appropriate default. Channel: fast-4.11 (available channels: candidate-4.10, candidate-4.11, eus-4.10, fast-4.10, fast-4.11, stable-4.10) Recommended updates: VERSION IMAGE 4.10.26 quay.io/openshift-release-dev/ocp-release@sha256:e1fa1f513068082d97d78be643c369398b0e6820afab708d26acda2262940954 4.10.25 quay.io/openshift-release-dev/ocp-release@sha256:ed84fb3fbe026b3bbb4a2637ddd874452ac49c6ead1e15675f257e28664879cc 4.10.24 quay.io/openshift-release-dev/ocp-release@sha256:aab51636460b5a9757b736a29bc92ada6e6e6282e46b06e6fd483063d590d62a 4.10.23 quay.io/openshift-release-dev/ocp-release@sha256:e40e49d722cb36a95fa1c03002942b967ccbd7d68de10e003f0baa69abad457b Supported but not recommended updates: Version: 4.11.0 Image: quay.io/openshift-release-dev/ocp-release@sha256:300bce8246cf880e792e106607925de0a404484637627edf5f517375517d54a4 Recommended: False Reason: RPMOSTreeTimeout Message: Nodes with substantial numbers of containers and CPU contention may not reconcile machine configuration https://bugzilla.redhat.com/show_bug.cgi?id=2111817#c22oc adm upgrade命令查询ClusterVersion资源以获取可用更新的信息,并以人类可读格式显示它。直接检查 CVO 创建的底层可用性数据的一种方法是,使用以下命令查询
ClusterVersion资源:$ oc get clusterversion version -o json | jq '.status.availableUpdates'输出示例
[ { "channels": [ "candidate-4.11", "candidate-4.12", "fast-4.11", "fast-4.12" ], "image": "quay.io/openshift-release-dev/ocp-release@sha256:400267c7f4e61c6bfa0a59571467e8bd85c9188e442cbd820cc8263809be3775", "url": "https://access.redhat.com/errata/RHBA-2023:3213", "version": "4.11.41" }, ... ]类似的命令可用于检查条件更新:
$ oc get clusterversion version -o json | jq '.status.conditionalUpdates'输出示例
[ { "conditions": [ { "lastTransitionTime": "2023-05-30T16:28:59Z", "message": "The 4.11.36 release only resolves an installation issue https://issues.redhat.com//browse/OCPBUGS-11663 , which does not affect already running clusters. 4.11.36 does not include fixes delivered in recent 4.11.z releases and therefore upgrading from these versions would cause fixed bugs to reappear. Red Hat does not recommend upgrading clusters to 4.11.36 version for this reason. https://access.redhat.com/solutions/7007136", "reason": "PatchesOlderRelease", "status": "False", "type": "Recommended" } ], "release": { "channels": [...], "image": "quay.io/openshift-release-dev/ocp-release@sha256:8c04176b771a62abd801fcda3e952633566c8b5ff177b93592e8e8d2d1f8471d", "url": "https://access.redhat.com/errata/RHBA-2023:1733", "version": "4.11.36" }, "risks": [...] }, ... ]
2.2.1.2. 更新可用性的评估
Cluster Version Operator (CVO) 会定期查询 OpenShift Update Service (OSUS),以获取与更新可能相关的最新数据。这个数据基于集群的订阅频道。然后,CVO 将有关更新建议的信息保存到它的 ClusterVersion 资源的 availableUpdates或r conditionalUpdates 字段中。
CVO 定期检查条件更新以更新风险。这些风险通过 OSUS 提供的数据传递,其中包含可能会影响到该版本的集群更新的已知问题的每个版本的信息。大多数风险仅限于具有特定特征的集群,如在特定云平台中部署的特定大小或集群的集群。
CVO 根据每个条件更新的条件风险信息持续评估其集群特征。如果 CVO 发现集群与条件匹配,CVO 会将此信息存储在 ClusterVersion 资源的 conditionalUpdates 字段中。如果 CVO 发现集群与更新的风险不匹配,或者没有与更新相关的风险,它会将目标版本存储在 ClusterVersion 资源的 availableUpdates 字段中。
用户界面,Web 控制台或 OpenShift CLI (oc),在管理员的部分标题中显示此信息。每个支持但不推荐的更新建议都包含有关风险的进一步资源的链接,以便管理员可以就更新做出明智的决定。
2.2.2. 发行镜像
发行镜像是特定 OpenShift Container Platform (OCP) 版本的交付机制。它包含发行版本元数据、与发行版本匹配的 Cluster Version Operator (CVO) 二进制文件、部署单个 OpenShift 集群 Operator 所需的每个清单,以及对组成此 OpenShift 版本的所有容器镜像的 SHA 摘要版本引用列表。
您可以运行以下命令来检查特定发行镜像的内容:
$ oc adm release extract <release image>输出示例
$ oc adm release extract quay.io/openshift-release-dev/ocp-release:4.12.6-x86_64
Extracted release payload from digest sha256:800d1e39d145664975a3bb7cbc6e674fbf78e3c45b5dde9ff2c5a11a8690c87b created at 2023-03-01T12:46:29Z
$ ls
0000_03_authorization-openshift_01_rolebindingrestriction.crd.yaml
0000_03_config-operator_01_proxy.crd.yaml
0000_03_marketplace-operator_01_operatorhub.crd.yaml
0000_03_marketplace-operator_02_operatorhub.cr.yaml
0000_03_quota-openshift_01_clusterresourcequota.crd.yaml
...
0000_90_service-ca-operator_02_prometheusrolebinding.yaml
0000_90_service-ca-operator_03_servicemonitor.yaml
0000_99_machine-api-operator_00_tombstones.yaml
image-references
release-metadata2.2.3. 更新过程工作流
以下步骤代表了 OpenShift Container Platform (OCP) 更新过程的详细工作流:
-
目标版本存储在
ClusterVersion资源的spec.desiredUpdate.version字段中,该字段可通过 Web 控制台或 CLI 进行管理。 -
Cluster Version Operator (CVO) 检测到
ClusterVersion资源中的desiredUpdate与当前集群版本不同。使用 OpenShift Update Service 中的图形数据,CVO 将所需的集群版本解析为发行镜像的 pull spec。 - CVO 验证发行镜像的完整性和真实性。红帽通过使用镜像 SHA 摘要作为唯一和不可变发行镜像标识符,发布有关在预定义位置发布的发行镜像的加密签名的声明。CVO 使用内置公钥列表来验证与检查的发行镜像匹配的声明是否存在和签名。
-
CVO 在
openshift-cluster-version命名空间中创建一个名为version-$version-$hash的作业。此作业使用执行发行镜像的容器,因此集群通过容器运行时下载镜像。然后,作业会将清单和元数据从发行镜像提取到 CVO 访问的共享卷。 - CVO 验证提取的清单和元数据。
- CVO 检查一些 preconditions,以确保集群中没有检测到有问题的条件。某些条件可能会阻止更新进行。这些条件可以由 CVO 本身决定,或由单个集群 Operator 报告,用于检测 Operator 认为更新问题的一些集群详情。
-
CVO 以
status.desired记录接受的发行版本,并创建一个有关新更新的status.history条目。 - CVO 开始协调来自发行镜像的清单。集群 Operator 在称为 Runlevels 的独立阶段更新,CVO 确保 Runlevel 中的所有 Operator 在进入下一级别前完成更新。
- CVO 本身的清单会在进程早期应用。应用 CVO 部署时,当前的 CVO pod 会停止,并使用新版本启动的 CVO pod。新的 CVO 继续协调剩余的清单。
-
更新会进行,直到整个 control plane 更新至新版本。单个集群 Operator 可能会在集群域中执行更新任务,但它们通过
Progressing=True条件报告其状态。 - Machine Config Operator (MCO) 清单应用到进程末尾。然后,更新的 MCO 开始更新每个节点的系统配置和操作系统。每个节点可能会在开始重新接受工作负载前排空、更新和重启。
在 control plane 更新完成后,集群会报告(在更新所有节点之前)。更新后,CVO 维护所有集群资源以匹配发行镜像中交付的状态。
2.2.4. 了解更新期间如何应用清单
因为它们之间的依赖项,发行镜像中提供的一些清单必须按特定顺序应用。例如,必须在匹配的自定义资源前创建 CustomResourceDefinition 资源。另外,还需要更新单个集群 Operator 的逻辑顺序,以便最大程度降低集群中的中断。Cluster Version Operator (CVO) 通过运行级别 (runlevel) 的概念来实施这个逻辑顺序。
这些依赖项在发行镜像中清单的文件名中编码:
0000_<runlevel>_<component>_<manifest-name>.yaml例如:
0000_03_config-operator_01_proxy.crd.yamlCVO 在内部为清单构建依赖项图,其中 CVO 遵循以下规则:
- 在更新过程中,在较高运行级别的清单之前会应用较低运行级别的清单。
- 在一个运行级别中,可以并行应用不同组件的清单。
- 在一个运行级别中,单个组件的清单以字典顺序应用。
然后,CVO 按照生成的依赖项图应用清单。
对于某些资源类型,CVO 在应用清单后监控资源,并将其视为仅在资源达到稳定状态后成功更新。实现此状态可能需要一些时间。对于 ClusterOperator 资源,这尤其如此,而 CVO 会等待集群 Operator 更新其自身,然后更新其 ClusterOperator 状态。
CVO 在进入下一个运行级别前等待到 Runlevel 中的所有集群 Operator 满足以下条件:
-
集群 Operator 有一个
Available=True条件。 -
集群 Operator 有一个
Degraded=False条件。
- 集群 Operator 声明它们已在 ClusterOperator 资源中实现所需的版本。
有些操作可能需要大量时间来完成。CVO 等待操作完成,以确保后续运行级别可以安全继续。初始协调新发行版本的清单预计需要 60 到 120 分钟。请参阅了解 OpenShift Container Platform 更新持续时间以了解更多有关影响更新持续时间的信息。
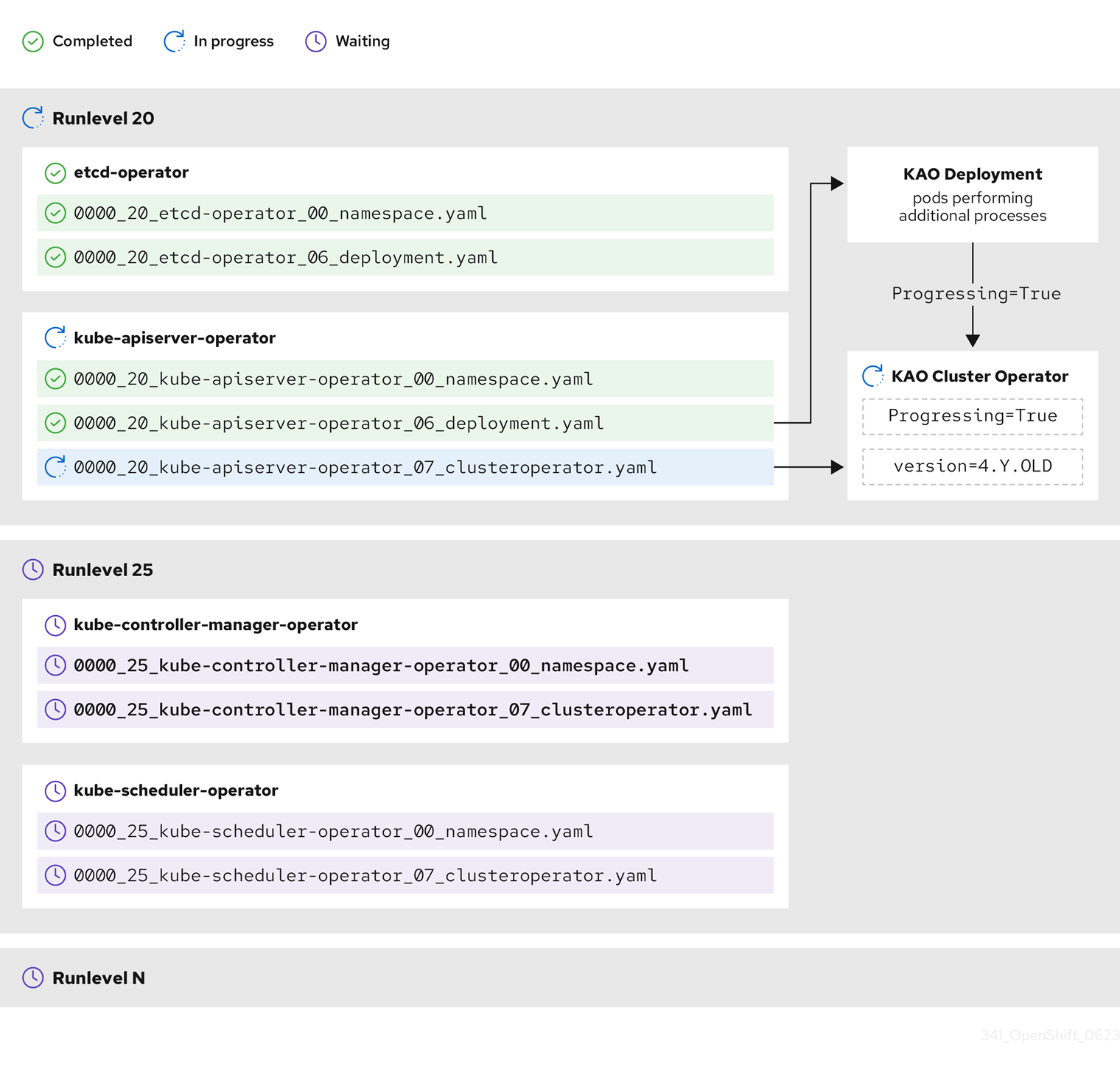
在上例中,CVO 会等待所有工作在 Runlevel 20 中完成。CVO 将所有清单应用到 Runlevel 中的 Operator,但 kube-apiserver-operator ClusterOperator 在部署了新版本后执行一些操作。kube-apiserver-operator ClusterOperator 通过 Progressing=True 条件声明此进度,且没有在 status.versions 中声明新版本作为协调。CVO 等待 ClusterOperator 报告可接受的状态,然后在 Runlevel 25 开始协调清单。
2.2.5. 了解 Machine Config Operator 如何更新节点
Machine Config Operator (MCO) 将新机器配置应用到每个 control plane 节点和计算节点。在机器配置更新过程中,control plane 节点和计算节点被组织到自己的机器配置池中,其中机器池会并行更新。.spec.maxUnavailable 参数(默认值为 1)决定机器配置池中可以同时处理更新过程中的节点数。
当机器配置更新过程启动时,MCO 会检查池中当前不可用的节点数量。如果不可用的节点小于 .spec.maxUnavailable 的值,MCO 会在池中对可用节点启动以下操作序列:
cordon 和 drain 节点
注意当节点被封锁时,工作负载无法调度到其中。
- 更新节点的系统配置和操作系统 (OS)
- 重新引导节点
- 取消协调节点
一个节点无法处理这个过程,直到它被取消封锁,且工作负载可以再次调度到其中。MCO 开始更新节点,直到不可用节点的数量等于 .spec.maxUnavailable 的值。
当节点完成其更新并变为可用时,机器配置池中不可用的节点数量会重新小于 .spec.maxUnavailable。如果需要更新剩余的节点,MCO 会在节点上启动更新过程,直到再次达到 .spec.maxUnavailable 限制为止。此过程会重复,直到每个 control plane 节点和计算节点已更新。
以下示例工作流描述了这个过程在 5 个节点的机器配置池中如何发生,其中 .spec.maxUnavailable 为 3,所有节点最初可用:
- MCO 会处理节点 1、2 和 3,并开始排空它们。
- 节点 2 完成排空、重启并再次可用。MCO 对节点 4 进行 cordons,并开始排空节点。
- 节点 1 完成排空、重新引导并再次可用。MCO 对节点 5 进行 cordons,并开始排空节点。
- 节点 3 完成排空、重启并再次可用。
- 节点 5 完成排空、重启并再次可用。
- 节点 4 完成排空、重启并再次可用。
因为每个节点的更新过程独立于其他节点,所以上例中的一些节点会完全完成它们的更新顺序,由 MCO 封锁。
您可以运行以下命令来检查机器配置更新的状态:
$ oc get mcp输出示例
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE
master rendered-master-acd1358917e9f98cbdb599aea622d78b True False False 3 3 3 0 22h
worker rendered-worker-1d871ac76e1951d32b2fe92369879826 False True False 2 1 1 0 22h