第 3 章 Performing blue-green cluster upgrades
This topic serves as an alternative approach for node host upgrades to the in-place upgrade method.
The blue-green deployment upgrade method follows a similar flow to the in-place method: masters and etcd servers are still upgraded first, however a parallel environment is created for new node hosts instead of upgrading them in-place.
This method allows administrators to switch traffic from the old set of node hosts (e.g., the blue deployment) to the new set (e.g., the green deployment) after the new deployment has been verified. If a problem is detected, it is also then easy to rollback to the old deployment quickly.
While blue-green is a proven and valid strategy for deploying just about any software, there are always trade-offs. Not all environments have the same uptime requirements or the resources to properly perform blue-green deployments.
In an OpenShift Container Platform environment, the most suitable candidate for blue-green deployments are the node hosts. All user processes run on these systems and even critical pieces of OpenShift Container Platform infrastructure are self-hosted on these resources. Uptime is most important for these workloads and the additional complexity of blue-green deployments can be justified.
The exact implementation of this approach varies based on your requirements. Often the main challenge is having the excess capacity to facilitate such an approach.
图 3.1. Blue-green deployment
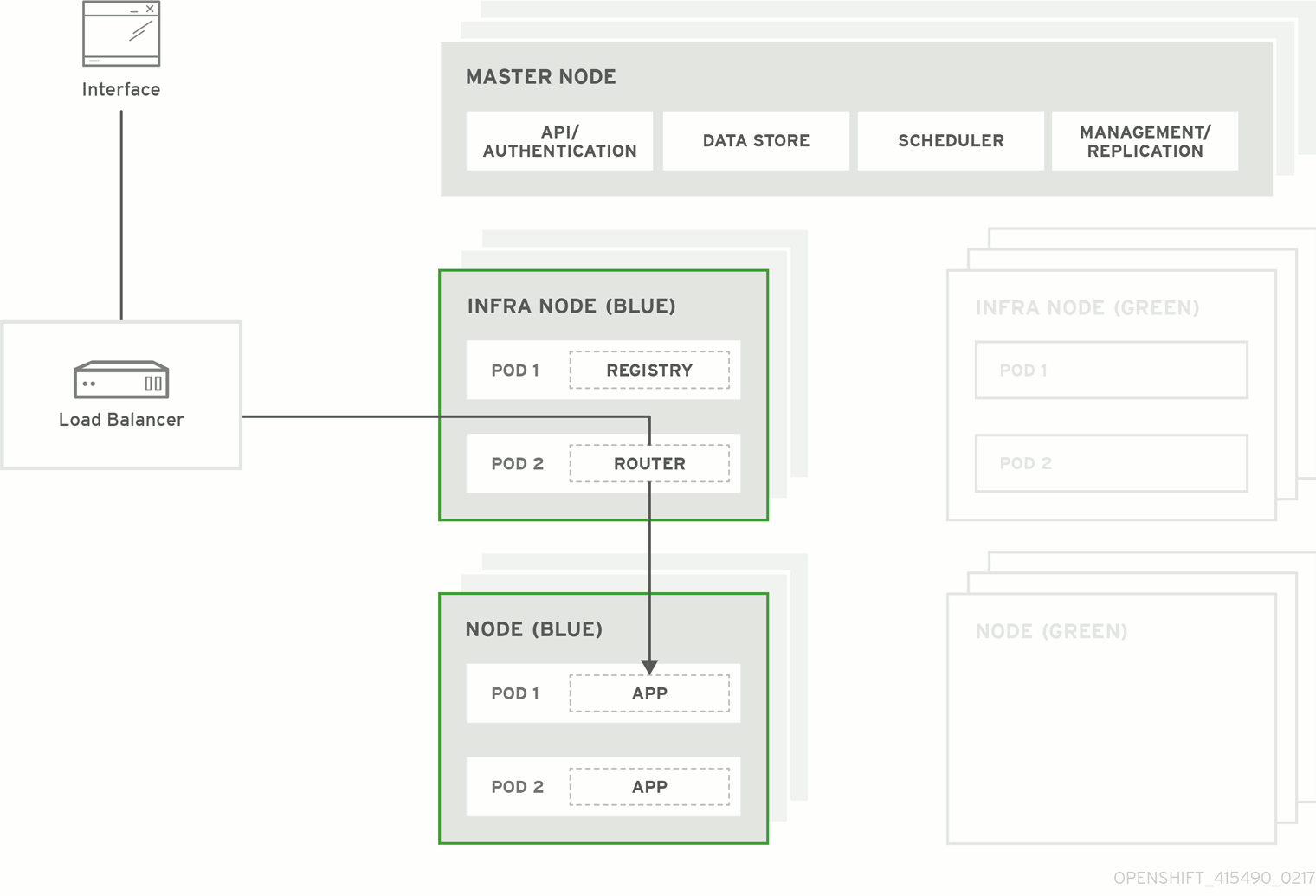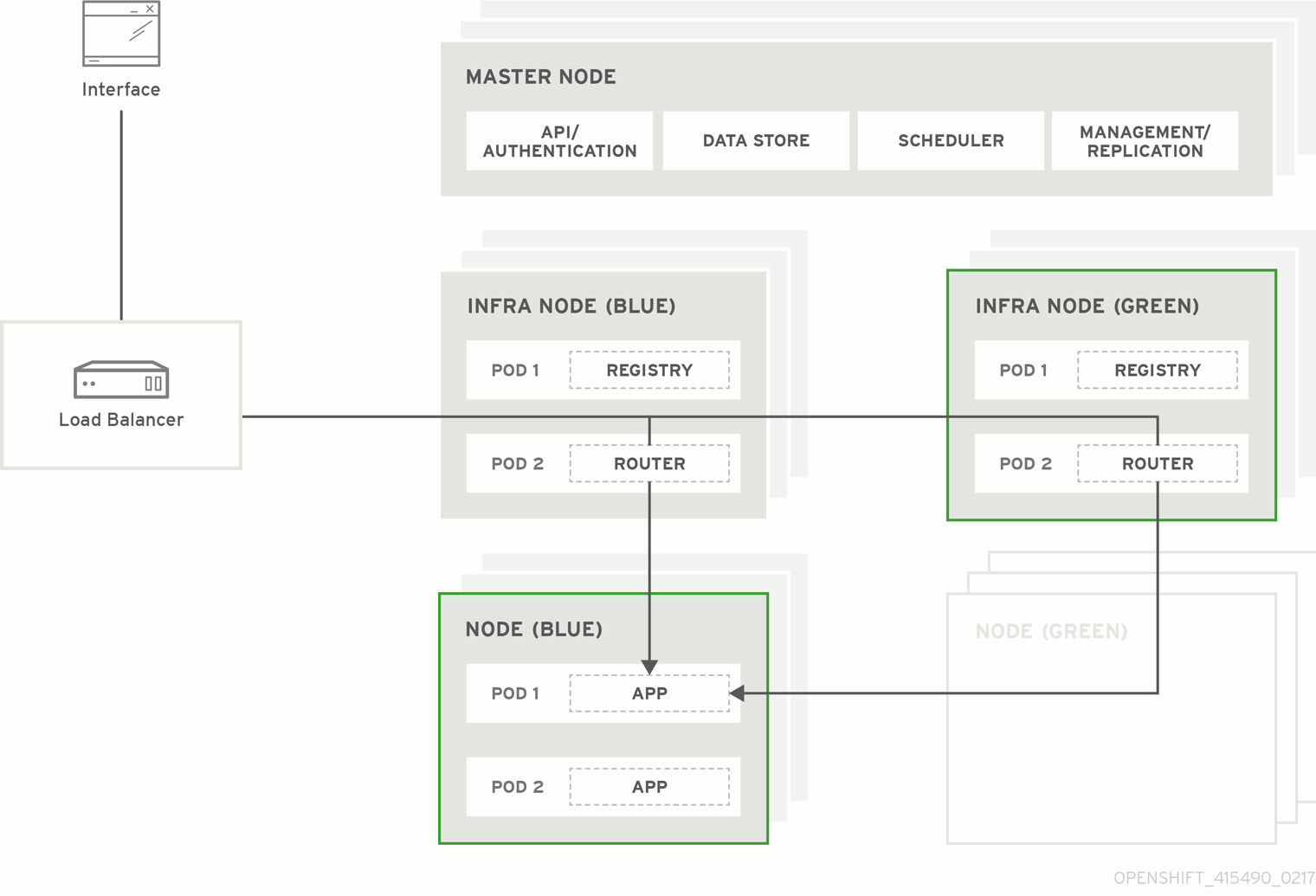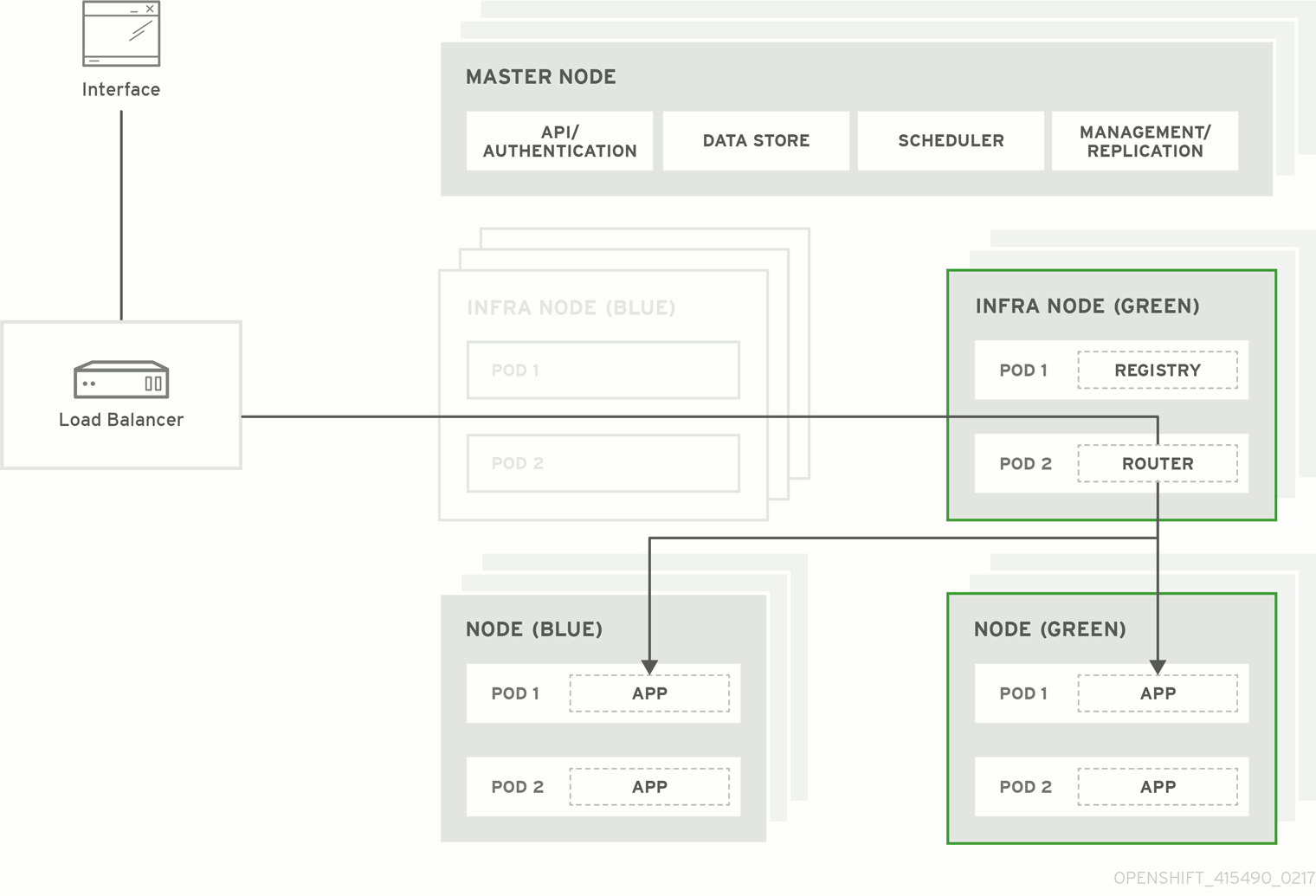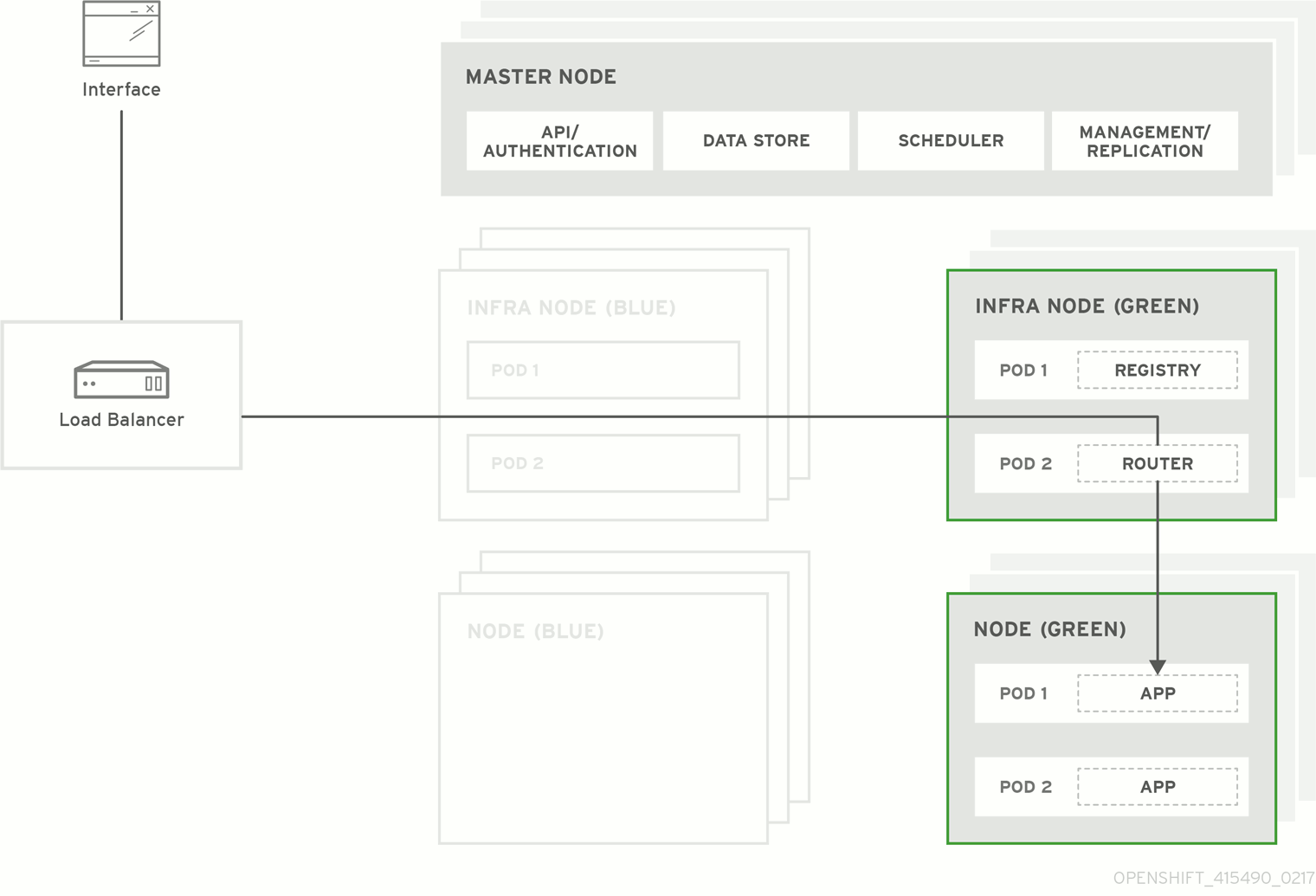
3.1. Preparing for a blue-green upgrade
After you have upgraded your master and etcd hosts using method described for In-place Upgrades, use the following sections to prepare your environment for a blue-green upgrade of the remaining node hosts.
3.1.1. Sharing software entitlements
Administrators must temporarily share the Red Hat software entitlements between the blue-green deployments or provide access to the installation content by means of a system such as Red Hat Satellite. This can be accomplished by sharing the consumer ID from the previous node host:
On each old node host that will be upgraded, note its
system identityvalue, which is the consumer ID:# subscription-manager identity | grep system system identity: 6699375b-06db-48c4-941e-689efd6ce3aa
On each new RHEL 7 or RHEL Atomic Host 7 system that will replace an old node host, register using the respective consumer ID from the previous step:
# subscription-manager register --consumerid=6699375b-06db-48c4-941e-689efd6ce3aa
3.1.2. Labeling blue nodes
You must ensure that your current node hosts in production are labeled either blue or green. In this example, the current production environment is blue, and the new environment is green.
Get the current list of node names known to the cluster:
$ oc get nodes
Label all non-master node hosts (compute nodes) and dedicated infrastructure nodes in your current production environment with
color=blue:$ oc label node --selector=node-role.kubernetes.io/compute=true color=blue $ oc label node --selector=node-role.kubernetes.io/infra=true color=blue
In the previous command, the
--selectorflag is used to match a subset of the cluster using the relevant node labels, and all matches are labeled withcolor=blue.
3.1.3. Creating and labeling green nodes
Create the green environment by adding an equal number of new node hosts to the existing cluster:
Add the new node hosts using the procedure as described in Adding Hosts to an Existing Cluster. When updating your inventory file with the
[new_nodes]group in that procedure, ensure these variables are set:-
In order to delay workload scheduling until the nodes are deemed healthy, which you verify in later steps, set the
openshift_schedulable=falsevariable for each new node host to ensure they are unschedulable initially.
-
In order to delay workload scheduling until the nodes are deemed healthy, which you verify in later steps, set the
After the new nodes deploy, apply the
color=greenlabel to each new node:$ oc label node <node_name> color=green
3.1.4. Verifying green nodes
Verify that your new green nodes are in a healthy state:
Verify that new nodes are detected in the cluster and are in Ready,SchedulingDisabled state:
$ oc get nodes NAME STATUS ROLES AGE node4.example.com Ready,SchedulingDisabled compute 1d
Verify that the green nodes have proper labels:
$ oc get nodes --show-labels NAME STATUS ROLES AGE LABELS node4.example.com Ready,SchedulingDisabled compute 1d beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,color=green,kubernetes.io/hostname=m01.example.com,node-role.kubernetes.io/compute=true
Perform a diagnostic check for the cluster:
$ oc adm diagnostics [Note] Determining if client configuration exists for client/cluster diagnostics Info: Successfully read a client config file at '/root/.kube/config' Info: Using context for cluster-admin access: 'default/m01-example-com:8443/system:admin' [Note] Performing systemd discovery [Note] Running diagnostic: ConfigContexts[default/m01-example-com:8443/system:admin] Description: Validate client config context is complete and has connectivity ... [Note] Running diagnostic: CheckExternalNetwork Description: Check that external network is accessible within a pod [Note] Running diagnostic: CheckNodeNetwork Description: Check that pods in the cluster can access its own node. [Note] Running diagnostic: CheckPodNetwork Description: Check pod to pod communication in the cluster. In case of ovs-subnet network plugin, all pods should be able to communicate with each other and in case of multitenant network plugin, pods in non-global projects should be isolated and pods in global projects should be able to access any pod in the cluster and vice versa. [Note] Running diagnostic: CheckServiceNetwork Description: Check pod to service communication in the cluster. In case of ovs-subnet network plugin, all pods should be able to communicate with all services and in case of multitenant network plugin, services in non-global projects should be isolated and pods in global projects should be able to access any service in the cluster. ...