Chapter 67. Configuring and managing logical volumes
67.1. Overview of logical volume management
Logical Volume Manager (LVM) creates a layer of abstraction over physical storage, which helps you to create logical storage volumes. This offers more flexibility compared to direct physical storage usage.
In addition, the hardware storage configuration is hidden from the software so you can resize and move it without stopping applications or unmounting file systems. This can reduce operational costs.
67.1.1. LVM architecture
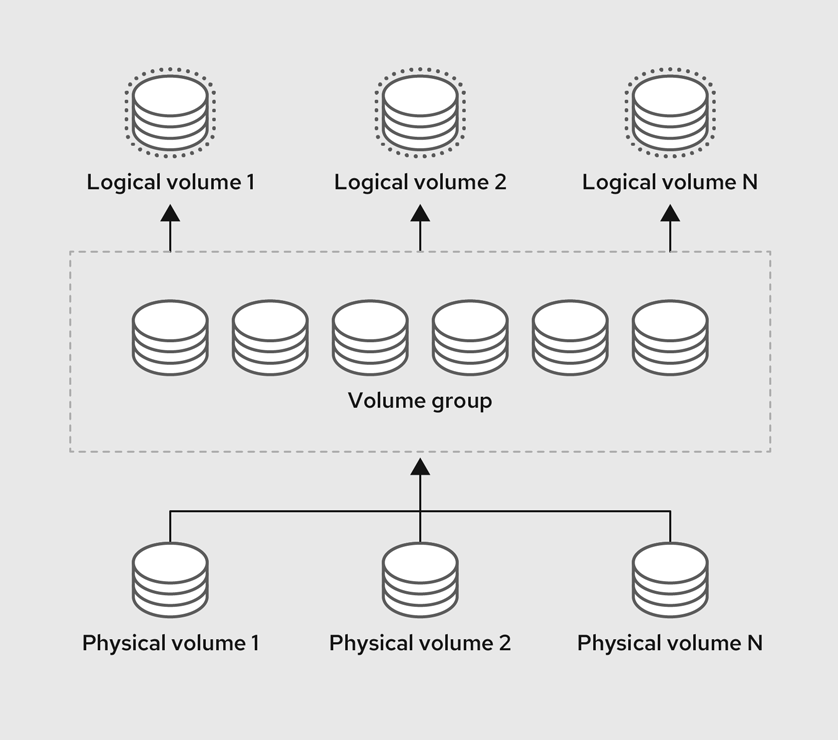
The following are the components of LVM:
- Physical volume
- A physical volume (PV) is a partition or whole disk designated for LVM use. For more information, see Managing LVM physical volumes.
- Volume group
- A volume group (VG) is a collection of physical volumes (PVs), which creates a pool of disk space out of which you can allocate logical volumes. For more information, see Managing LVM volume groups.
- Logical volume
- A logical volume represents a usable storage device. For more information, see Basic logical volume management and Advanced logical volume management.
The following diagram illustrates the components of LVM:
Figure 67.1. LVM logical volume components
67.1.2. Advantages of LVM
Logical volumes provide the following advantages over using physical storage directly:
- Flexible capacity
- When using logical volumes, you can aggregate devices and partitions into a single logical volume. With this functionality, file systems can extend across multiple devices as though they were a single, large one.
- Convenient device naming
- Logical storage volumes can be managed with user-defined and custom names.
- Resizeable storage volumes
- You can extend logical volumes or reduce logical volumes in size with simple software commands, without reformatting and repartitioning the underlying devices. For more information, see Resizing logical volumes.
- Online data relocation
To deploy newer, faster, or more resilient storage subsystems, you can move data while your system is active using the
pvmovecommand. Data can be rearranged on disks while the disks are in use. For example, you can empty a hot-swappable disk before removing it.For more information on how to migrate the data, see the
pvmoveman page and Removing physical volumes from a volume group.- Striped Volumes
- You can create a logical volume that stripes data across two or more devices. This can dramatically increase throughput. For more information, see Creating a striped logical volume.
- RAID volumes
- Logical volumes provide a convenient way to configure RAID for your data. This provides protection against device failure and improves performance. For more information, see Configuring RAID logical volumes.
- Volume snapshots
- You can take snapshots, which is a point-in-time copy of logical volumes for consistent backups or to test the effect of changes without affecting the real data. For more information, see Managing logical volume snapshots.
- Thin volumes
- Logical volumes can be thin-provisioned. This allows you to create logical volumes that are larger than the available physical space. For more information, see Creating a thin logical volume.
- Caching
- Caching uses fast devices, like SSDs, to cache data from logical volumes, boosting performance. For more information, see Caching logical volumes.
67.2. Managing LVM physical volumes
A physical volume (PV) is a physical storage device or a partition on a storage device that LVM uses.
During the initialization process, an LVM disk label and metadata are written to the device, which allows LVM to track and manage it as part of the logical volume management scheme.
You cannot increase the size of the metadata after the initialization. If you need larger metadata, you must set the appropriate size during the initialization process.
When initialization process is complete, you can allocate the PV to a volume group (VG). You can divide this VG into logical volumes (LVs), which are the virtual block devices that operating systems and applications can use for storage.
To ensure optimal performance, partition the whole disk as a single PV for LVM use.
67.2.1. Creating an LVM physical volume
You can use the pvcreate command to initialize a physical volume LVM usage.
Prerequisites
- Administrative access.
-
The
lvm2package is installed.
Procedure
Identify the storage device you want to use as a physical volume. To list all available storage devices, use:
$ lsblkCreate an LVM physical volume:
# pvcreate /dev/sdbReplace /dev/sdb with the name of the device you want to initialize as a physical volume.
Verification steps
Display the created physical volume:
# pvs PV VG Fmt Attr PSize PFree /dev/sdb lvm2 a-- 28.87g 13.87g
67.2.2. Removing LVM physical volumes
You can use the pvremove command to remove a physical volume for LVM usage.
Prerequisites
- Administrative access.
Procedure
List the physical volumes to identify the device you want to remove:
# pvs PV VG Fmt Attr PSize PFree /dev/sdb1 lvm2 --- 28.87g 28.87gRemove the physical volume:
# pvremove /dev/sdb1Replace /dev/sdb1 with the name of the device associated with the physical volume.
If your physical volume is part of the volume group, you need to remove it from the volume group first.
If you volume group contains more that one physical volume, use the
vgreducecommand:# vgreduce VolumeGroupName /dev/sdb1Replace VolumeGroupName with the name of the volume group. Replace /dev/sdb1 with the name of the device.
If your volume group contains only one physical volume, use
vgremovecommand:# vgremove VolumeGroupNameReplace VolumeGroupName with the name of the volume group.
Verification
Verify the physical volume is removed:
# pvs
67.2.3. Creating logical volumes in the web console
Logical volumes act as physical drives. You can use the RHEL 8 web console to create LVM logical volumes in a volume group.
Prerequisites
- You have installed the RHEL 8 web console.
- You have enabled the cockpit service.
Your user account is allowed to log in to the web console.
For instructions, see Installing and enabling the web console.
-
The
cockpit-storagedpackage is installed on your system. - The volume group is created.
Procedure
Log in to the RHEL 8 web console.
For details, see Logging in to the web console.
- Click Storage.
- In the Storage table, click the volume group in which you want to create logical volumes.
- On the Logical volume group page, scroll to the LVM2 logical volumes section and click .
- In the Name field, enter a name for the new logical volume. Do not include spaces in the name.
In the drop-down menu, select Block device for filesystems.
This configuration enables you to create a logical volume with the maximum volume size which is equal to the sum of the capacities of all drives included in the volume group.

Define the size of the logical volume. Consider:
- How much space the system using this logical volume will need.
- How many logical volumes you want to create.
You do not have to use the whole space. If necessary, you can grow the logical volume later.

Click .
The logical volume is created. To use the logical volume you must format and mount the volume.
Verification
On the Logical volume page, scroll to the LVM2 logical volumes section and verify whether the new logical volume is listed.

67.2.4. Formatting logical volumes in the web console
Logical volumes act as physical drives. To use them, you must format them with a file system.
Formatting logical volumes erases all data on the volume.
The file system you select determines the configuration parameters you can use for logical volumes. For example, the XFS file system does not support shrinking volumes.
Prerequisites
- You have installed the RHEL 8 web console.
- You have enabled the cockpit service.
Your user account is allowed to log in to the web console.
For instructions, see Installing and enabling the web console.
-
The
cockpit-storagedpackage is installed on your system. - The logical volume created.
- You have root access privileges to the system.
Procedure
Log in to the RHEL 8 web console.
For details, see Logging in to the web console.
- Click .
- In the Storage table, click the volume group in the logical volumes is created.
- On the Logical volume group page, scroll to the LVM2 logical volumes section.
- Click the menu button, , next to the volume group you want to format.
From the drop-down menu, select .
- In the Name field, enter a name for the file system.
In the Mount Point field, add the mount path.

In the drop-down menu, select a file system:
XFS file system supports large logical volumes, switching physical drives online without outage, and growing an existing file system. Leave this file system selected if you do not have a different strong preference.
XFS does not support reducing the size of a volume formatted with an XFS file system
ext4 file system supports:
- Logical volumes
- Switching physical drives online without an outage
- Growing a file system
- Shrinking a file system
Select the Overwrite existing data with zeros checkbox if you want the RHEL web console to rewrite the whole disk with zeros. This option is slower because the program has to go through the whole disk, but it is more secure. Use this option if the disk includes any data and you need to overwrite it.
If you do not select the Overwrite existing data with zeros checkbox, the RHEL web console rewrites only the disk header. This increases the speed of formatting.
From the drop-down menu, select the type of encryption if you want to enable it on the logical volume.
You can select a version with either the LUKS1 (Linux Unified Key Setup) or LUKS2 encryption, which allows you to encrypt the volume with a passphrase.
- In the drop-down menu, select when you want the logical volume to mount after the system boots.
- Select the required Mount options.
Format the logical volume:
- If you want to format the volume and immediately mount it, click .
If you want to format the volume without mounting it, click .
Formatting can take several minutes depending on the volume size and which formatting options are selected.
Verification
On the Logical volume group page, scroll to the LVM2 logical volumes section and click the logical volume to check the details and additional options.

- If you selected the option, click the menu button at the end of the line of the logical volume, and select to use the logical volume.
67.2.5. Resizing logical volumes in the web console
You can extend or reduce logical volumes in the RHEL 8 web console. The example procedure demonstrates how to grow and shrink the size of a logical volume without taking the volume offline.
You cannot reduce volumes that contains GFS2 or XFS filesystem.
Prerequisites
- You have installed the RHEL 8 web console.
- You have enabled the cockpit service.
Your user account is allowed to log in to the web console.
For instructions, see Installing and enabling the web console.
-
The
cockpit-storagedpackage is installed on your system. - An existing logical volume containing a file system that supports resizing logical volumes.
Procedure
- Log in to the RHEL web console.
- Click .
- In the Storage table, click the volume group in the logical volumes is created.
On the Logical volume group page, scroll to the LVM2 logical volumes section and click the menu button, , next to volume group you want to resize.
From the menu, select Grow or Shrink to resize the volume:
Growing the Volume:
- Select to increase the size of the volume.
In the Grow logical volume dialog box, adjust the size of the logical volume.

Click .
LVM grows the logical volume without causing a system outage.
Shrinking the Volume:
- Select to reduce the size of the volume.
In the Shrink logical volume dialog box, adjust the size of the logical volume.

Click .
LVM shrinks the logical volume without causing a system outage.
67.3. Managing LVM volume groups
You can create and use volume groups (VGs) to manage and resize multiple physical volumes (PVs) combined into a single storage entity.
Extents are the smallest units of space that you can allocate in LVM. Physical extents (PE) and logical extents (LE) has the default size of 4 MiB that you can configure. All extents have the same size.
When you create a logical volume (LV) within a VG, LVM allocates physical extents on the PVs. The logical extents within the LV correspond one-to-one with physical extents in the VG. You do not need to specify the PEs to create LVs. LVM will locate the available PEs and piece them together to create a LV of the requested size.
Within a VG, you can create multiple LVs, each acting like a traditional partition but with the ability to span across physical volumes and resize dynamically. VGs can manage the allocation of disk space automatically.
67.3.1. Creating an LVM volume group
You can use the vgcreate command to create a volume group (VG). You can adjust the extent size for very large or very small volumes to optimize performance and storage efficiency. You can specify the extent size when creating a VG. To change the extent size you must re-create the volume group.
Prerequisites
- Administrative access.
-
The
lvm2package is installed. - One or more physical volumes are created. For more information about creating physical volumes, see Creating LVM physical volume.
Procedure
List and identify the PV that you want to include in the VG:
# pvsCreate a VG:
# vgcreate VolumeGroupName PhysicalVolumeName1 PhysicalVolumeName2Replace VolumeGroupName with the name of the volume group that you want to create. Replace PhysicalVolumeName with the name of the PV.
To specify the extent size when creating a VG, use the
-s ExtentSizeoption. Replace ExtentSize with the size of the extent. If you provide no size suffix, the command defaults to MB.
Verification
Verify that the VG is created:
# vgs VG #PV #LV #SN Attr VSize VFree VolumeGroupName 1 0 0 wz--n- 28.87g 28.87g
67.3.2. Creating volume groups in the web console
Create volume groups from one or more physical drives or other storage devices.
Logical volumes are created from volume groups. Each volume group can include multiple logical volumes.
Prerequisites
- You have installed the RHEL 8 web console.
- You have enabled the cockpit service.
Your user account is allowed to log in to the web console.
For instructions, see Installing and enabling the web console.
-
The
cockpit-storagedpackage is installed on your system. - Physical drives or other types of storage devices from which you want to create volume groups.
Procedure
Log in to the RHEL 8 web console.
For details, see Logging in to the web console.
- Click .
- In the Storage table, click the menu button.
From the drop-down menu, select Create LVM2 volume group.

- In the Name field, enter a name for the volume group. The name must not include spaces.
Select the drives you want to combine to create the volume group.

The RHEL web console displays only unused block devices. If you do not see your device in the list, make sure that it is not being used by your system, or format it to be empty and unused. Used devices include, for example:
- Devices formatted with a file system
- Physical volumes in another volume group
- Physical volumes being a member of another software RAID device
Click .
The volume group is created.
Verification
- On the Storage page, check whether the new volume group is listed in the Storage table.
67.3.3. Renaming an LVM volume group
You can use the vgrename command to rename a volume group (VG).
Prerequisites
- Administrative access.
-
The
lvm2package is installed. - One or more physical volumes are created. For more information about creating physical volumes, see Creating LVM physical volume.
- The volume group is created. For more information about creating volume groups, see Section 67.3.1, “Creating an LVM volume group”.
Procedure
List and identify the VG that you want to rename:
# vgsRename the VG:
# vgrename OldVolumeGroupName NewVolumeGroupNameReplace OldVolumeGroupName with the name of the VG. Replace NewVolumeGroupName with the new name for the VG.
Verification
Verify that the VG has a new name:
# vgs VG #PV #LV #SN Attr VSize VFree NewVolumeGroupName 1 0 0 wz--n- 28.87g 28.87g
67.3.4. Extending an LVM volume group
You can use the vgextend command to add physical volumes (PVs) to a volume group (VG).
Prerequisites
- Administrative access.
-
The
lvm2package is installed. - One or more physical volumes are created. For more information about creating physical volumes, see Creating LVM physical volume.
- The volume group is created. For more information about creating volume groups, see Section 67.3.1, “Creating an LVM volume group”.
Procedure
List and identify the VG that you want to extend:
# vgsList and identify the PVs that you want to add to the VG:
# pvsExtend the VG:
# vgextend VolumeGroupName PhysicalVolumeNameReplace VolumeGroupName with the name of the VG. Replace PhysicalVolumeName with the name of the PV.
Verification
Verify that the VG now includes the new PV:
# pvs PV VG Fmt Attr PSize PFree /dev/sda VolumeGroupName lvm2 a-- 28.87g 28.87g /dev/sdd VolumeGroupName lvm2 a-- 1.88g 1.88g
67.3.5. Combining LVM volume groups
You can combine two existing volume groups (VGs) with the vgmerge command. The source volume will be merged into the destination volume.
Prerequisites
- Administrative access.
-
The
lvm2package is installed. - One or more physical volumes are created. For more information about creating physical volumes, see Creating LVM physical volume.
- Two or more volume group are created. For more information about creating volume groups, see Section 67.3.1, “Creating an LVM volume group”.
Procedure
List and identify the VG that you want to merge:
# vgs VG #PV #LV #SN Attr VSize VFree VolumeGroupName1 1 0 0 wz--n- 28.87g 28.87g VolumeGroupName2 1 0 0 wz--n- 1.88g 1.88gMerge the source VG into the destination VG:
# vgmerge VolumeGroupName2 VolumeGroupName1Replace VolumeGroupName2 with the name of the source VG. Replace VolumeGroupName1 with the name of the destination VG.
Verification
Verify that the VG now includes the new PV:
# vgs VG #PV #LV #SN Attr VSize VFree VolumeGroupName1 2 0 0 wz--n- 30.75g 30.75g
67.3.6. Removing physical volumes from a volume group
To remove unused physical volumes (PVs) from a volume group (VG), use the vgreduce command. The vgreduce command shrinks a volume group’s capacity by removing one or more empty physical volumes. This frees those physical volumes to be used in different volume groups or to be removed from the system.
Procedure
If the physical volume is still being used, migrate the data to another physical volume from the same volume group:
# pvmove /dev/vdb3 /dev/vdb3: Moved: 2.0% ... /dev/vdb3: Moved: 79.2% ... /dev/vdb3: Moved: 100.0%If there are not enough free extents on the other physical volumes in the existing volume group:
Create a new physical volume from /dev/vdb4:
# pvcreate /dev/vdb4 Physical volume "/dev/vdb4" successfully createdAdd the newly created physical volume to the volume group:
# vgextend VolumeGroupName /dev/vdb4 Volume group "VolumeGroupName" successfully extendedMove the data from /dev/vdb3 to /dev/vdb4:
# pvmove /dev/vdb3 /dev/vdb4 /dev/vdb3: Moved: 33.33% /dev/vdb3: Moved: 100.00%
Remove the physical volume /dev/vdb3 from the volume group:
# vgreduce VolumeGroupName /dev/vdb3 Removed "/dev/vdb3" from volume group "VolumeGroupName"
Verification
Verify that the /dev/vdb3 physical volume is removed from the VolumeGroupName volume group:
# pvs PV VG Fmt Attr PSize PFree Used /dev/vdb1 VolumeGroupName lvm2 a-- 1020.00m 0 1020.00m /dev/vdb2 VolumeGroupName lvm2 a-- 1020.00m 0 1020.00m /dev/vdb3 lvm2 a-- 1020.00m 1008.00m 12.00m
67.3.7. Splitting a LVM volume group
If there is enough unused space on the physical volumes, a new volume group can be created without adding new disks.
In the initial setup, the volume group VolumeGroupName1 consists of /dev/vdb1, /dev/vdb2, and /dev/vdb3. After completing this procedure, the volume group VolumeGroupName1 will consist of /dev/vdb1 and /dev/vdb2, and the second volume group, VolumeGroupName2, will consist of /dev/vdb3.
Prerequisites
-
You have sufficient space in the volume group. Use the
vgscancommand to determine how much free space is currently available in the volume group. -
Depending on the free capacity in the existing physical volume, move all the used physical extents to other physical volume using the
pvmovecommand. For more information, see Removing physical volumes from a volume group.
Procedure
Split the existing volume group VolumeGroupName1 to the new volume group VolumeGroupName2:
# vgsplit VolumeGroupName1 VolumeGroupName2 /dev/vdb3 Volume group "VolumeGroupName2" successfully split from "VolumeGroupName1"NoteIf you have created a logical volume using the existing volume group, use the following command to deactivate the logical volume:
# lvchange -a n /dev/VolumeGroupName1/LogicalVolumeNameView the attributes of the two volume groups:
# vgs VG #PV #LV #SN Attr VSize VFree VolumeGroupName1 2 1 0 wz--n- 34.30G 10.80G VolumeGroupName2 1 0 0 wz--n- 17.15G 17.15G
Verification
Verify that the newly created volume group VolumeGroupName2 consists of /dev/vdb3 physical volume:
# pvs PV VG Fmt Attr PSize PFree Used /dev/vdb1 VolumeGroupName1 lvm2 a-- 1020.00m 0 1020.00m /dev/vdb2 VolumeGroupName1 lvm2 a-- 1020.00m 0 1020.00m /dev/vdb3 VolumeGroupName2 lvm2 a-- 1020.00m 1008.00m 12.00m
67.3.8. Moving a volume group to another system
You can move an entire LVM volume group (VG) to another system using the following commands:
vgexport- Use this command on an existing system to make an inactive VG inaccessible to the system. Once the VG is inaccessible, you can detach its physical volumes (PV).
vgimport- Use this command on the other system to make the VG, which was inactive in the old system, accessible in the new system.
Prerequisites
- No users are accessing files on the active volumes in the volume group that you are moving.
Procedure
Unmount the LogicalVolumeName logical volume:
# umount /dev/mnt/LogicalVolumeNameDeactivate all logical volumes in the volume group, which prevents any further activity on the volume group:
# vgchange -an VolumeGroupName vgchange -- volume group "VolumeGroupName" successfully deactivatedExport the volume group to prevent it from being accessed by the system from which you are removing it:
# vgexport VolumeGroupName vgexport -- volume group "VolumeGroupName" successfully exportedView the exported volume group:
# pvscan PV /dev/sda1 is in exported VG VolumeGroupName [17.15 GB / 7.15 GB free] PV /dev/sdc1 is in exported VG VolumeGroupName [17.15 GB / 15.15 GB free] PV /dev/sdd1 is in exported VG VolumeGroupName [17.15 GB / 15.15 GB free] ...- Shut down your system and unplug the disks that make up the volume group and connect them to the new system.
Plug the disks into the new system and import the volume group to make it accessible to the new system:
# vgimport VolumeGroupNameNoteYou can use the
--forceargument of thevgimportcommand to import volume groups that are missing physical volumes and subsequently run thevgreduce --removemissingcommand.Activate the volume group:
# vgchange -ay VolumeGroupNameMount the file system to make it available for use:
# mkdir -p /mnt/VolumeGroupName/users # mount /dev/VolumeGroupName/users /mnt/VolumeGroupName/users
Additional resources
-
vgimport(8),vgexport(8), andvgchange(8)man pages on your system
67.3.9. Removing LVM volume groups
You can remove an existing volume group using the vgremove command. Only volume groups that do not contain logical volumes can be removed.
Prerequisites
- Administrative access.
Procedure
Ensure the volume group does not contain logical volumes:
# vgs -o vg_name,lv_count VolumeGroupName VG #LV VolumeGroupName 0Replace VolumeGroupName with the name of the volume group.
Remove the volume group:
# vgremove VolumeGroupNameReplace VolumeGroupName with the name of the volume group.
67.3.10. Removing LVM volume groups in a cluster environment
In a cluster environment, LVM uses the lockspace <qualifier> to coordinate access to volume groups shared among multiple machines. You must stop the lockspace before removing a volume group to make sure no other node is trying to access or modify it during the removal process.
Prerequisites
- Administrative access.
- The volume group contains no logical volumes.
Procedure
Ensure the volume group does not contain logical volumes:
# vgs -o vg_name,lv_count VolumeGroupName VG #LV VolumeGroupName 0Replace VolumeGroupName with the name of the volume group.
Stop the
lockspaceon all nodes except the node where you are removing the volume group:# vgchange --lockstop VolumeGroupNameReplace VolumeGroupName with the name of the volume group and wait for the lock to stop.
Remove the volume group:
# vgremove VolumeGroupNameReplace VolumeGroupName with the name of the volume group.
67.4. Managing LVM logical volumes
A logical volume is a virtual, block storage device that a file system, database, or application can use. To create an LVM logical volume, the physical volumes (PVs) are combined into a volume group (VG). This creates a pool of disk space out of which LVM logical volumes (LVs) can be allocated.
67.4.1. Overview of logical volume features
With the Logical Volume Manager (LVM), you can manage disk storage in a flexible and efficient way that traditional partitioning schemes cannot offer. Below is a summary of key LVM features that are used for storage management and optimization.
- Concatenation
- Concatenation involves combining space from one or more physical volumes into a singular logical volume, effectively merging the physical storage.
- Striping
- Striping optimizes data I/O efficiency by distributing data across multiple physical volumes. This method enhances performance for sequential reads and writes by allowing parallel I/O operations.
- RAID
- LVM supports RAID levels 0, 1, 4, 5, 6, and 10. When you create a RAID logical volume, LVM creates a metadata subvolume that is one extent in size for every data or parity subvolume in the array.
- Thin provisioning
- Thin provisioning enables the creation of logical volumes that are larger than the available physical storage. With thin provisioning, the system dynamically allocates storage based on actual usage instead of allocating a predetermined amount upfront.
- Snapshots
- With LVM snapshots, you can create point-in-time copies of logical volumes. A snapshot starts empty. As changes occur on the original logical volume, the snapshot captures the pre-change states through copy-on-write (CoW), growing only with changes to preserve the state of the original logical volume.
- Caching
- LVM supports the use of fast block devices, such as SSD drives as write-back or write-through caches for larger slower block devices. Users can create cache logical volumes to improve the performance of their existing logical volumes or create new cache logical volumes composed of a small and fast device coupled with a large and slow device.
67.4.2. Managing logical volume snapshots
A snapshot is a logical volume (LV) that mirrors the content of another LV at a specific point in time.
67.4.2.1. Understanding logical volume snapshots
When you create a snapshot, you are creating a new LV that serves as a point-in-time copy of another LV. Initially, the snapshot LV contains no actual data. Instead, it references the data blocks of the original LV at the moment of snapshot creation.
It is important to regularly monitor the snapshot’s storage usage. If a snapshot reaches 100% of its allocated space, it will become invalid.
It is essential to extend the snapshot before it gets completely filled. This can be done manually by using the lvextend command or automatically via the /etc/lvm/lvm.conf file.
- Thick LV snapshots
- When data on the original LV changes, the copy-on-write (CoW) system copies the original, unchanged data to the snapshot before the change is made. This way, the snapshot grows in size only as changes occur, storing the state of the original volume at the time of the snapshot’s creation. Thick snapshots are a type of LV that requires you to allocate some amount of storage space upfront. This amount can later be extended or reduced, however, you should consider what type of changes you intend to make to the original LV. This helps you to avoid either wasting resources by allocating too much space or needing to frequently increase the snapshot size if you allocate too little.
- Thin LV snapshots
Thin snapshots are a type of LV created from an existing thin provisioned LV. Thin snapshots do not require allocating extra space upfront. Initially, both the original LV and its snapshot share the same data blocks. When changes are made to the original LV, it writes new data to different blocks, while the snapshot continues to reference the original blocks, preserving a point-in-time view of the LV’s data at the snapshot creation.
Thin provisioning is a method of optimizing and managing storage efficiently by allocating disk space on an as-needed basis. This means that you can create multiple LVs without needing to allocate a large amount of storage upfront for each LV. The storage is shared among all LVs in a thin pool, making it a more efficient use of resources. A thin pool allocates space on-demand to its LVs.
- Choosing between thick and thin LV snapshots
- The choice between thick or thin LV snapshots is directly determined by the type of LV you are taking a snapshot of. If your original LV is a thick LV, your snapshots will be thick. If your original LV is thin, your snapshots will be thin.
67.4.2.2. Managing thick logical volume snapshots
When you create a thick LV snapshot, it is important to consider the storage requirements and the intended lifespan of your snapshot. You need to allocate enough storage for it based on the expected changes to the original volume. The snapshot must have a sufficient size to capture changes during its intended lifespan, but it cannot exceed the size of the original LV. If you expect a low rate of change, a smaller snapshot size of 10%-15% might be sufficient. For LVs with a high rate of change, you might need to allocate 30% or more.
It is essential to extend the snapshot before it gets completely filled. If a snapshot reaches 100% of its allocated space, it becomes invalid. You can monitor the snapshot capacity with the lvs -o lv_name,data_percent,origin command.
67.4.2.2.1. Creating thick logical volume snapshots
You can create a thick LV snapshot with the lvcreate command.
Prerequisites
- Administrative access.
- You have created a physical volume. For more information, see Creating LVM physical volume.
- You have created a volume group. For more information, see Creating LVM volume group.
- You have created a logical volume. For more information, see Creating logical volumes.
Procedure
Identify the LV of which you want to create a snapshot:
# lvs -o vg_name,lv_name,lv_size VG LV LSize VolumeGroupName LogicalVolumeName 10.00gThe size of the snapshot cannot exceed the size of the LV.
Create a thick LV snapshot:
# lvcreate --snapshot --size SnapshotSize --name SnapshotName VolumeGroupName/LogicalVolumeNameReplace SnapshotSize with the size you want to allocate for the snapshot (e.g. 10G). Replace SnapshotName with the name you want to give to the snapshot logical volume. Replace VolumeGroupName with the name of the volume group that contains the original logical volume. Replace LogicalVolumeName with the name of the logical volume that you want to create a snapshot of.
Verification
Verify that the snapshot is created:
# lvs -o lv_name,origin LV Origin LogicalVolumeName SnapshotName LogicalVolumeName
67.4.2.2.2. Manually extending logical volume snapshots
If a snapshot reaches 100% of its allocated space, it becomes invalid. It is essential to extend the snapshot before it gets completely filled. This can be done manually by using the lvextend command.
Prerequisites
- Administrative access.
Procedure
List the names of volume groups, logical volumes, source volumes for snapshots, their usage percentages, and sizes:
# lvs -o vg_name,lv_name,origin,data_percent,lv_size VG LV Origin Data% LSize VolumeGroupName LogicalVolumeName 10.00g VolumeGroupName SnapshotName LogicalVolumeName 82.00 5.00gExtend the thick-provisioned snapshot:
# lvextend --size +AdditionalSize VolumeGroupName/SnapshotNameReplace AdditionalSize with how much space to add to the snapshot (for example, +1G). Replace VolumeGroupName with the name of the volume group. Replace SnapshotName with the name of the snapshot.
Verification
Verify that the LV is extended:
# lvs -o vg_name,lv_name,origin,data_percent,lv_size VG LV Origin Data% LSize VolumeGroupName LogicalVolumeName 10.00g VolumeGroupName SnapshotName LogicalVolumeName 68.33 6.00g
67.4.2.2.3. Automatically extending thick logical volume snapshots
If a snapshot reaches 100% of its allocated space, it becomes invalid. It is essential to extend the snapshot before it gets completely filled. This can be done automatically.
Prerequisites
- Administrative access.
Procedure
-
As the
rootuser, open the/etc/lvm/lvm.conffile in an editor of your choice. Uncomment the
snapshot_autoextend_thresholdandsnapshot_autoextend_percentlines and set each parameter to a required value:snapshot_autoextend_threshold = 70 snapshot_autoextend_percent = 20snapshot_autoextend_thresholddetermines the percentage at which LVM starts to auto-extend the snapshot. For example, setting the parameter to 70 means that LVM will try to extend the snapshot when it reaches 70% capacity.snapshot_autoextend_percentspecifies by what percentage the snapshot should be extended when it reaches the threshold. For example, setting the parameter to 20 means the snapshot will be increased by 20% of its current size.- Save the changes and exit the editor.
Restart the
lvm2-monitor:# systemctl restart lvm2-monitor
67.4.2.2.4. Merging thick logical volume snapshots
You can merge thick LV snapshot into the original logical volume from which the snapshot was created. The process of merging means that the original LV is reverted to the state it was in when the snapshot was created. Once the merge is complete, the snapshot is removed.
The merge between the original and snapshot LV is postponed if either is active. It only proceeds once the LVs are reactivated and not in use.
Prerequisites
- Administrative access.
Procedure
List the LVs, their volume groups, and their paths:
# lvs -o lv_name,vg_name,lv_path LV VG Path LogicalVolumeName VolumeGroupName /dev/VolumeGroupName/LogicalVolumeName SnapshotName VolumeGroupName /dev/VolumeGroupName/SnapshotNameCheck where the LVs are mounted:
# findmnt -o SOURCE,TARGET /dev/VolumeGroupName/LogicalVolumeName # findmnt -o SOURCE,TARGET /dev/VolumeGroupName/SnapshotNameReplace /dev/VolumeGroupName/LogicalVolumeName with the path to your logical volume. Replace /dev/VolumeGroupName/SnapshotName with the path to your snapshot.
Unmount the LVs:
# umount /LogicalVolume/MountPoint # umount /Snapshot/MountPointReplace /LogicalVolume/MountPoint with the mounting point for your logical volume. Replace /Snapshot/MountPoint with the mounting point for your snapshot.
Deactivate the LVs:
# lvchange --activate n VolumeGroupName/LogicalVolumeName # lvchange --activate n VolumeGroupName/SnapshotNameReplace VolumeGroupName with the name of the volume group. Replace LogicalVolumeName with the name of the logical volume. Replace SnapshotName with the name of your snapshot.
Merge the thick LV snapshot into the origin:
# lvconvert --merge SnapshotNameReplace SnapshotName with the name of the snapshot.
Activate the LV:
# lvchange --activate y VolumeGroupName/LogicalVolumeNameReplace VolumeGroupName with the name of the volume group. Replace LogicalVolumeName with the name of the logical volume.
Mount the LV:
# umount /LogicalVolume/MountPointReplace /LogicalVolume/MountPoint with the mounting point for your logical volume.
Verification
Verify that the snapshot is removed:
# lvs -o lv_name
67.4.2.3. Managing thin logical volume snapshots
Thin provisioning is appropriate where storage efficiency is a priority. Storage space dynamic allocation reduces initial storage costs and maximizes the use of available storage resources. In environments with dynamic workloads or where storage grows over time, thin provisioning allows for flexibility. It enables the storage system to adapt to changing needs without requiring large upfront allocations of the storage space. With dynamic allocation, over-provisioning is possible, where the total size of all LVs can exceed the physical size of the thin pool, under the assumption that not all space will be utilized at the same time.
67.4.2.3.1. Creating thin logical volume snapshots
You can create a thin LV snapshot with the lvcreate command. When creating a thin LV snapshot, avoid specifying the snapshot size. Including a size parameter results in the creation of a thick snapshot instead.
Prerequisites
- Administrative access.
- You have created a physical volume. For more information, see Creating LVM physical volume.
- You have created a volume group. For more information, see Creating LVM volume group.
- You have created a logical volume. For more information, see Creating logical volumes.
Procedure
Identify the LV of which you want to create a snapshot:
# lvs -o lv_name,vg_name,pool_lv,lv_size LV VG Pool LSize PoolName VolumeGroupName 152.00m ThinVolumeName VolumeGroupName PoolName 100.00mCreate a thin LV snapshot:
# lvcreate --snapshot --name SnapshotName VolumeGroupName/ThinVolumeNameReplace SnapshotName with the name you want to give to the snapshot logical volume. Replace VolumeGroupName with the name of the volume group that contains the original logical volume. Replace ThinVolumeName with the name of the thin logical volume that you want to create a snapshot of.
Verification
Verify that the snapshot is created:
# lvs -o lv_name,origin LV Origin PoolName SnapshotName ThinVolumeName ThinVolumeName
67.4.2.3.2. Merging thin logical volume snapshots
You can merge thin LV snapshot into the original logical volume from which the snapshot was created. The process of merging means that the original LV is reverted to the state it was in when the snapshot was created. Once the merge is complete, the snapshot is removed.
Prerequisites
- Administrative access.
Procedure
List the LVs, their volume groups, and their paths:
# lvs -o lv_name,vg_name,lv_path LV VG Path ThinPoolName VolumeGroupName ThinSnapshotName VolumeGroupName /dev/VolumeGroupName/ThinSnapshotName ThinVolumeName VolumeGroupName /dev/VolumeGroupName/ThinVolumeNameCheck where the original LV is mounted:
# findmnt -o SOURCE,TARGET /dev/VolumeGroupName/ThinVolumeNameReplace VolumeGroupName/ThinVolumeName with the path to your logical volume.
Unmount the LV:
# umount /ThinLogicalVolume/MountPointReplace /ThinLogicalVolume/MountPoint with the mounting point for your logical volume. Replace /ThinSnapshot/MountPoint with the mounting point for your snapshot.
Deactivate the LV:
# lvchange --activate n VolumeGroupName/ThinLogicalVolumeNameReplace VolumeGroupName with the name of the volume group. Replace ThinLogicalVolumeName with the name of the logical volume.
Merge the thin LV snapshot into the origin:
# lvconvert --mergethin VolumeGroupName/ThinSnapshotNameReplace VolumeGroupName with the name of the volume group. Replace ThinSnapshotName with the name of the snapshot.
Mount the LV:
# umount /ThinLogicalVolume/MountPointReplace /ThinLogicalVolume/MountPoint with the mounting point for your logical volume.
Verification
Verify that the original LV is merged:
# lvs -o lv_name
67.4.3. Creating a RAID0 striped logical volume
A RAID0 logical volume spreads logical volume data across multiple data subvolumes in units of stripe size. The following procedure creates an LVM RAID0 logical volume called mylv that stripes data across the disks.
Prerequisites
- You have created three or more physical volumes. For more information about creating physical volumes, see Creating LVM physical volume.
- You have created the volume group. For more information, see Creating LVM volume group.
Procedure
Create a RAID0 logical volume from the existing volume group. The following command creates the RAID0 volume mylv from the volume group myvg, which is 2G in size, with three stripes and a stripe size of 4kB:
# lvcreate --type raid0 -L 2G --stripes 3 --stripesize 4 -n mylv my_vg Rounding size 2.00 GiB (512 extents) up to stripe boundary size 2.00 GiB(513 extents). Logical volume "mylv" created.Create a file system on the RAID0 logical volume. The following command creates an ext4 file system on the logical volume:
# mkfs.ext4 /dev/my_vg/mylvMount the logical volume and report the file system disk space usage:
# mount /dev/my_vg/mylv /mnt # df Filesystem 1K-blocks Used Available Use% Mounted on /dev/mapper/my_vg-mylv 2002684 6168 1875072 1% /mnt
Verification
View the created RAID0 stripped logical volume:
# lvs -a -o +devices,segtype my_vg LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert Devices Type mylv my_vg rwi-a-r--- 2.00g mylv_rimage_0(0),mylv_rimage_1(0),mylv_rimage_2(0) raid0 [mylv_rimage_0] my_vg iwi-aor--- 684.00m /dev/sdf1(0) linear [mylv_rimage_1] my_vg iwi-aor--- 684.00m /dev/sdg1(0) linear [mylv_rimage_2] my_vg iwi-aor--- 684.00m /dev/sdh1(0) linear
67.4.4. Removing a disk from a logical volume
This procedure describes how to remove a disk from an existing logical volume, either to replace the disk or to use the disk as part of a different volume.
In order to remove a disk, you must first move the extents on the LVM physical volume to a different disk or set of disks.
Procedure
View the used and free space of physical volumes when using the LV:
# pvs -o+pv_used PV VG Fmt Attr PSize PFree Used /dev/vdb1 myvg lvm2 a-- 1020.00m 0 1020.00m /dev/vdb2 myvg lvm2 a-- 1020.00m 0 1020.00m /dev/vdb3 myvg lvm2 a-- 1020.00m 1008.00m 12.00mMove the data to other physical volume:
If there are enough free extents on the other physical volumes in the existing volume group, use the following command to move the data:
# pvmove /dev/vdb3 /dev/vdb3: Moved: 2.0% ... /dev/vdb3: Moved: 79.2% ... /dev/vdb3: Moved: 100.0%If there are no enough free extents on the other physical volumes in the existing volume group, use the following commands to add a new physical volume, extend the volume group using the newly created physical volume, and move the data to this physical volume:
# pvcreate /dev/vdb4 Physical volume "/dev/vdb4" successfully created # vgextend myvg /dev/vdb4 Volume group "myvg" successfully extended # pvmove /dev/vdb3 /dev/vdb4 /dev/vdb3: Moved: 33.33% /dev/vdb3: Moved: 100.00%
Remove the physical volume:
# vgreduce myvg /dev/vdb3 Removed "/dev/vdb3" from volume group "myvg"If a logical volume contains a physical volume that fails, you cannot use that logical volume. To remove missing physical volumes from a volume group, you can use the
--removemissingparameter of thevgreducecommand, if there are no logical volumes that are allocated on the missing physical volumes:# vgreduce --removemissing myvg
67.4.5. Changing physical drives in volume groups using the web console
You can change the drive in a volume group using the RHEL 8 web console.
Prerequisites
- A new physical drive for replacing the old or broken one.
- The configuration expects that physical drives are organized in a volume group.
67.4.5.1. Adding physical drives to volume groups in the web console
You can add a new physical drive or other type of volume to the existing logical volume by using the RHEL 8 web console.
Prerequisites
- You have installed the RHEL 8 web console.
- You have enabled the cockpit service.
Your user account is allowed to log in to the web console.
For instructions, see Installing and enabling the web console.
-
The
cockpit-storagedpackage is installed on your system. - A volume group must be created.
- A new drive connected to the machine.
Procedure
Log in to the RHEL 8 web console.
For details, see Logging in to the web console.
- Click Storage.
- In the Storage table, click the volume group to which you want to add physical drives.
- On the LVM2 volume group page, click .
- In the Add Disks dialog box, select the preferred drives and click .
Verification
- On the LVM2 volume group page, check the Physical volumes section to verify whether the new physical drives are available in the volume group.
67.4.5.2. Removing physical drives from volume groups in the web console
If a logical volume includes multiple physical drives, you can remove one of the physical drives online.
The system moves automatically all data from the drive to be removed to other drives during the removal process. Notice that it can take some time.
The web console also verifies, if there is enough space for removing the physical drive.
Prerequisites
- You have installed the RHEL 8 web console.
- You have enabled the cockpit service.
Your user account is allowed to log in to the web console.
For instructions, see Installing and enabling the web console.
-
The
cockpit-storagedpackage is installed on your system. - A volume group with more than one physical drive connected.
Procedure
- Log in to the RHEL 8 web console.
- Click Storage.
- In the Storage table, click the volume group to which you want to add physical drives.
- On the LVM2 volume group page, scroll to the Physical volumes section.
- Click the menu button, , next to the physical volume you want to remove.
From the drop-down menu, select .
The RHEL 8 web console verifies whether the logical volume has enough free space to removing the disk. If there is no free space to transfer the data, you cannot remove the disk and you must first add another disk to increase the capacity of the volume group. For details, see Adding physical drives to logical volumes in the web console.
67.4.6. Removing logical volumes
You can remove an existing logical volume, including snapshots, using the lvremove command.
Prerequisites
- Administrative access.
Procedure
List the logical volumes and their paths:
# lvs -o lv_name,lv_path LV Path LogicalVolumeName /dev/VolumeGroupName/LogicalVolumeNameCheck where the logical volume is mounted:
# findmnt -o SOURCE,TARGET /dev/VolumeGroupName/LogicalVolumeName SOURCE TARGET /dev/mapper/VolumeGroupName-LogicalVolumeName /MountPointReplace /dev/VolumeGroupName/LogicalVolumeName with the path to your logical volume.
Unmount the logical volume:
# umount /MountPointReplace /MountPoint with the mounting point for your logical volume.
Remove the logical volume:
# lvremove VolumeGroupName/LogicalVolumeNameReplace VolumeGroupName/LogicalVolumeName with the path to your logical volume.
67.4.7. Managing LVM logical volumes by using RHEL system roles
Use the storage role to perform the following tasks:
- Create an LVM logical volume in a volume group consisting of multiple disks.
- Create an ext4 file system with a given label on the logical volume.
- Persistently mount the ext4 file system.
Prerequisites
-
An Ansible playbook including the
storagerole
67.4.7.1. Creating or resizing a logical volume by using the storage RHEL system role
Use the storage role to perform the following tasks:
- To create an LVM logical volume in a volume group consisting of many disks
- To resize an existing file system on LVM
- To express an LVM volume size in percentage of the pool’s total size
If the volume group does not exist, the role creates it. If a logical volume exists in the volume group, it is resized if the size does not match what is specified in the playbook.
If you are reducing a logical volume, to prevent data loss you must ensure that the file system on that logical volume is not using the space in the logical volume that is being reduced.
Prerequisites
- You have prepared the control node and the managed nodes
- You are logged in to the control node as a user who can run playbooks on the managed nodes.
-
The account you use to connect to the managed nodes has
sudopermissions on them.
Procedure
Create a playbook file, for example
~/playbook.yml, with the following content:--- - name: Manage local storage hosts: managed-node-01.example.com tasks: - name: Create logical volume ansible.builtin.include_role: name: redhat.rhel_system_roles.storage vars: storage_pools: - name: myvg disks: - sda - sdb - sdc volumes: - name: mylv size: 2G fs_type: ext4 mount_point: /mnt/dataThe settings specified in the example playbook include the following:
size: <size>- You must specify the size by using units (for example, GiB) or percentage (for example, 60%).
For details about all variables used in the playbook, see the
/usr/share/ansible/roles/rhel-system-roles.storage/README.mdfile on the control node.Validate the playbook syntax:
$ ansible-playbook --syntax-check ~/playbook.ymlNote that this command only validates the syntax and does not protect against a wrong but valid configuration.
Run the playbook:
$ ansible-playbook ~/playbook.yml
Verification
Verify that specified volume has been created or resized to the requested size:
# ansible managed-node-01.example.com -m command -a 'lvs myvg'
67.4.8. Resizing an existing file system on LVM by using the storage RHEL system role
You can use the storage RHEL system role to resize an LVM logical volume with a file system.
If the logical volume you are reducing has a file system, to prevent data loss you must ensure that the file system is not using the space in the logical volume that is being reduced.
Prerequisites
- You have prepared the control node and the managed nodes
- You are logged in to the control node as a user who can run playbooks on the managed nodes.
-
The account you use to connect to the managed nodes has
sudopermissions on them.
Procedure
Create a playbook file, for example
~/playbook.yml, with the following content:--- - name: Manage local storage hosts: managed-node-01.example.com tasks: - name: Resize LVM logical volume with file system ansible.builtin.include_role: name: redhat.rhel_system_roles.storage vars: storage_pools: - name: myvg disks: - /dev/sda - /dev/sdb - /dev/sdc volumes: - name: mylv1 size: 10 GiB fs_type: ext4 mount_point: /opt/mount1 - name: mylv2 size: 50 GiB fs_type: ext4 mount_point: /opt/mount2This playbook resizes the following existing file systems:
-
The Ext4 file system on the
mylv1volume, which is mounted at/opt/mount1, resizes to 10 GiB. -
The Ext4 file system on the
mylv2volume, which is mounted at/opt/mount2, resizes to 50 GiB.
For details about all variables used in the playbook, see the
/usr/share/ansible/roles/rhel-system-roles.storage/README.mdfile on the control node.-
The Ext4 file system on the
Validate the playbook syntax:
$ ansible-playbook --syntax-check ~/playbook.ymlNote that this command only validates the syntax and does not protect against a wrong but valid configuration.
Run the playbook:
$ ansible-playbook ~/playbook.yml
Verification
Verify that the logical volume has been resized to the requested size:
# ansible managed-node-01.example.com -m command -a 'lvs myvg'Verify file system size using file system tools. For example, for ext4, calculate the file system size by multiplying block count and block size reported by dumpe2fs tool:
# ansible managed-node-01.example.com -m command -a 'dumpe2fs -h /dev/myvg/mylv | grep -E "Block count|Block size"'
67.5. Modifying the size of a logical volume
After you have created a logical volume, you can modify the size of the volume.
67.5.1. Extending a striped logical volume
You can extend a striped logical volume (LV) by using the lvextend command with the required size.
Prerequisites
- You have enough free space on the underlying physical volumes (PVs) that make up the volume group (VG) to support the stripe.
Procedure
Optional: Display your volume group:
# vgs VG #PV #LV #SN Attr VSize VFree myvg 2 1 0 wz--n- 271.31G 271.31GOptional: Create a stripe using the entire amount of space in the volume group:
# lvcreate -n stripe1 -L 271.31G -i 2 myvg Using default stripesize 64.00 KB Rounding up size to full physical extent 271.31 GiBOptional: Extend the myvg volume group by adding new physical volumes:
# vgextend myvg /dev/sdc1 Volume group "myvg" successfully extendedRepeat this step to add sufficient physical volumes depending on your stripe type and the amount of space used. For example, for a two-way stripe that uses up the entire volume group, you need to add at least two physical volumes.
Extend the striped logical volume stripe1 that is a part of the myvg VG:
# lvextend myvg/stripe1 -L 542G Using stripesize of last segment 64.00 KB Extending logical volume stripe1 to 542.00 GB Logical volume stripe1 successfully resizedYou can also extend the stripe1 logical volume to fill all of the unallocated space in the myvg volume group:
# lvextend -l+100%FREE myvg/stripe1 Size of logical volume myvg/stripe1 changed from 1020.00 MiB (255 extents) to <2.00 GiB (511 extents). Logical volume myvg/stripe1 successfully resized.
Verification
Verify the new size of the extended striped LV:
# lvs LV VG Attr LSize Pool Origin Data% Move Log Copy% Convert stripe1 myvg wi-ao---- 542.00 GB
67.6. Customizing the LVM report
LVM provides a wide range of configuration and command line options to produce customized reports. You can sort the output, specify units, use selection criteria, and update the lvm.conf file to customize the LVM report.
67.6.1. Controlling the format of the LVM display
When you use the pvs, lvs, or vgs command without additional options, you see the default set of fields displayed in the default sort order. The default fields for the pvs command include the following information sorted by the name of physical volumes:
# pvs
PV VG Fmt Attr PSize PFree
/dev/vdb1 VolumeGroupName lvm2 a-- 17.14G 17.14G
/dev/vdb2 VolumeGroupName lvm2 a-- 17.14G 17.09G
/dev/vdb3 VolumeGroupName lvm2 a-- 17.14G 17.14GPV- Physical volume name.
VG- Volume group name.
Fmt-
Metadata format of the physical volume:
lvm2orlvm1. Attr- Status of the physical volume: (a) - allocatable or (x) - exported.
PSize- Size of the physical volume.
PFree- Free space remaining on the physical volume.
Displaying custom fields
To display a different set of fields than the default, use the -o option. The following example displays only the name, size and free space of the physical volumes:
# pvs -o pv_name,pv_size,pv_free
PV PSize PFree
/dev/vdb1 17.14G 17.14G
/dev/vdb2 17.14G 17.09G
/dev/vdb3 17.14G 17.14GSorting the LVM display
To sort the results by specific criteria, use the -O option. The following example sorts the entries by the free space of their physical volumes in ascending order:
# pvs -o pv_name,pv_size,pv_free -O pv_free
PV PSize PFree
/dev/vdb2 17.14G 17.09G
/dev/vdb1 17.14G 17.14G
/dev/vdb3 17.14G 17.14G
To sort the results by descending order, use the -O option along with the - character:
# pvs -o pv_name,pv_size,pv_free -O -pv_free
PV PSize PFree
/dev/vdb1 17.14G 17.14G
/dev/vdb3 17.14G 17.14G
/dev/vdb2 17.14G 17.09G67.6.2. Specifying the units for an LVM display
You can view the size of the LVM devices in base 2 or base 10 units by specifying the --units argument of an LVM display command. See the following table for all arguments:
| Units type | Description | Available options | Default |
|---|---|---|---|
| Base 2 units | Units are displayed in powers of 2 (multiples of 1024). |
|
|
| Base 10 units | Units are displayed in multiples of 1000. |
| N/A |
| Custom units |
Combination of a quantity with a base 2 or base 10 unit. For example, to display the results in 4 mebibytes, use | N/A | N/A |
If you do not specify a value for the units, human-readable format (
r) is used by default. The followingvgscommand displays the size of VGs in human-readable format. The most suitable unit is used and the rounding indicator<shows that the actual size is an approximation and it is less than 931 gibibytes.# vgs myvg VG #PV #LV #SN Attr VSize VFree myvg 1 1 0 wz-n <931.00g <930.00gThe following
pvscommand displays the output in base 2 gibibyte units for the/dev/vdbphysical volume:# pvs --units g /dev/vdb PV VG Fmt Attr PSize PFree /dev/vdb myvg lvm2 a-- 931.00g 930.00gThe following
pvscommand displays the output in base 10 gigabyte units for the/dev/vdbphysical volume:# pvs --units G /dev/vdb PV VG Fmt Attr PSize PFree /dev/vdb myvg lvm2 a-- 999.65G 998.58GThe following
pvscommand displays the output in 512-byte sectors:# pvs --units s PV VG Fmt Attr PSize PFree /dev/vdb myvg lvm2 a-- 1952440320S 1950343168SYou can specify custom units for an LVM display command. The following example displays the output of the
pvscommand in units of 4 mebibytes:# pvs --units 4m PV VG Fmt Attr PSize PFree /dev/vdb myvg lvm2 a-- 238335.00U 238079.00U
67.6.3. Customizing the LVM configuration file
You can customize your LVM configuration according to your specific storage and system requirements by editing the lvm.conf file. For example, you can edit the lvm.conf file to modify filter settings, configure volume group auto activation, manage a thin pool, or automatically extend a snapshot.
Procedure
-
Open the
lvm.conffile in an editor of your choice. Customize the
lvm.conffile by uncommenting and modifying the setting for which you want to modify the default display values.To customize what fields you see in the
lvsoutput, uncomment thelvs_colsparameter and modify it:lvs_cols="lv_name,vg_name,lv_attr"To hide empty fields for the
pvs,vgs, andlvscommands, uncomment thecompact_output=1setting:compact_output = 1To set gigabytes as the default unit for the
pvs,vgs, andlvscommands, replace theunits = "r"setting withunits = "G":units = "G"
Ensure that the corresponding section of the
lvm.conffile is uncommented. For example, to modify thelvs_colsparameter, thereportsection must be uncommented:report { ... }
Verification
View the changed values after modifying the
lvm.conffile:# lvmconfig --typeconfig diff
67.6.4. Defining LVM selection criteria
Selection criteria are a set of statements in the form of <field> <operator> <value>, which use comparison operators to define values for specific fields. Objects that match the selection criteria are then processed or displayed. Objects can be physical volumes (PVs), volume groups (VGs), or logical volumes (LVs). Statements are combined by logical and grouping operators.
To define selection criteria use the -S or --select option followed by one or multiple statements.
The -S option works by describing the objects to process, rather than naming each object. This is helpful when processing many objects and it would be difficult to find and name each object separately or when searching objects that have a complex set of characteristics. The -S option can also be used as a shortcut to avoid typing many names.
To see full sets of fields and possible operators, use the lvs -S help command. Replace lvs with any reporting or processing command to see the details of that command:
-
Reporting commands include
pvs,vgs,lvs,pvdisplay,vgdisplay,lvdisplay, anddmsetup info -c. -
Processing commands include
pvchange,vgchange,lvchange,vgimport,vgexport,vgremove, andlvremove.
Examples of selection criteria using the pvs commands
The following example of the
pvscommand displays only physical volumes with a name that contains the stringnvme:# pvs -S name=~nvme PV Fmt Attr PSize PFree /dev/nvme2n1 lvm2 --- 1.00g 1.00gThe following example of the
pvscommand displays only physical devices in themyvgvolume group:# pvs -S vg_name=myvg PV VG Fmt Attr PSize PFree /dev/vdb1 myvg lvm2 a-- 1020.00m 396.00m /dev/vdb2 myvg lvm2 a-- 1020.00m 896.00m
Examples of selection criteria using the lvs commands
The following example of the
lvscommand displays only logical volumes with a size greater than 100m but less than 200m:# lvs -S 'size > 100m && size < 200m' LV VG Attr LSize Cpy%Sync rr myvg rwi-a-r--- 120.00m 100.00The following example of the
lvscommand displays only logical volumes with a name that containslvoland any number between 0 and 2:# lvs -S name=~lvol[02] LV VG Attr LSize lvol0 myvg -wi-a----- 100.00m lvol2 myvg -wi------- 100.00mThe following example of the
lvscommand displays only logical volumes with araid1segment type:# lvs -S segtype=raid1 LV VG Attr LSize Cpy%Sync rr myvg rwi-a-r--- 120.00m 100.00
Advanced examples
You can combine selection criteria with other options.
The following example of the
lvchangecommand adds a specific tagmytagto only active logical volumes:# lvchange --addtag mytag -S active=1 Logical volume myvg/mylv changed. Logical volume myvg/lvol0 changed. Logical volume myvg/lvol1 changed. Logical volume myvg/rr changed.The following example of the
lvscommand displays all logical volumes whose name does not match_pmspareand changes the default headers to custom ones:# lvs -a -o lv_name,vg_name,attr,size,pool_lv,origin,role -S 'name!~_pmspare' LV VG Attr LSize Pool Origin Role thin1 example Vwi-a-tz-- 2.00g tp public,origin,thinorigin thin1s example Vwi---tz-- 2.00g tp thin1 public,snapshot,thinsnapshot thin2 example Vwi-a-tz-- 3.00g tp public tp example twi-aotz-- 1.00g private [tp_tdata] example Twi-ao---- 1.00g private,thin,pool,data [tp_tmeta] example ewi-ao---- 4.00m private,thin,pool,metadataThe following example of the
lvchangecommand flags a logical volume withrole=thinsnapshotandorigin=thin1to be skipped during normal activation commands:# lvchange --setactivationskip n -S 'role=thinsnapshot && origin=thin1' Logical volume myvg/thin1s changed.The following example of the
lvscommand displays only logical volumes that match all three conditions:-
Name contains
_tmeta. -
Role is
metadata. - Size is less or equal to 4m.
# lvs -a -S 'name=~_tmeta && role=metadata && size <= 4m' LV VG Attr LSize [tp_tmeta] myvg ewi-ao---- 4.00m-
Name contains
Additional resources
-
lvmreport(7)man page on your system
67.7. Configuring RAID logical volumes
You can create and manage Redundant Array of Independent Disks (RAID) volumes by using logical volume manager (LVM). LVM supports RAID levels 0, 1, 4, 5, 6, and 10. An LVM RAID volume has the following characteristics:
- LVM creates and manages RAID logical volumes that leverage the Multiple Devices (MD) kernel drivers.
- You can temporarily split RAID1 images from the array and merge them back into the array later.
- LVM RAID volumes support snapshots.
- RAID logical volumes are not cluster-aware. Although you can create and activate RAID logical volumes exclusively on one machine, you cannot activate them simultaneously on more than one machine.
-
When you create a RAID logical volume (LV), LVM creates a metadata subvolume that is one extent in size for every data or parity subvolume in the array. For example, creating a 2-way RAID1 array results in two metadata subvolumes (
lv_rmeta_0andlv_rmeta_1) and two data subvolumes (lv_rimage_0andlv_rimage_1). - Adding integrity to a RAID LV reduces or prevents soft corruption.
67.7.1. RAID levels and linear support
The following are the supported configurations by RAID, including levels 0, 1, 4, 5, 6, 10, and linear:
- Level 0
RAID level 0, often called striping, is a performance-oriented striped data mapping technique. This means the data being written to the array is broken down into stripes and written across the member disks of the array, allowing high I/O performance at low inherent cost but provides no redundancy.
RAID level 0 implementations only stripe the data across the member devices up to the size of the smallest device in the array. This means that if you have multiple devices with slightly different sizes, each device gets treated as though it was the same size as the smallest drive. Therefore, the common storage capacity of a level 0 array is the total capacity of all disks. If the member disks have a different size, then the RAID0 uses all the space of those disks using the available zones.
- Level 1
RAID level 1, or mirroring, provides redundancy by writing identical data to each member disk of the array, leaving a mirrored copy on each disk. Mirroring remains popular due to its simplicity and high level of data availability. Level 1 operates with two or more disks, and provides very good data reliability and improves performance for read-intensive applications but at relatively high costs.
RAID level 1 is costly because you write the same information to all of the disks in the array, which provides data reliability, but in a much less space-efficient manner than parity based RAID levels such as level 5. However, this space inefficiency comes with a performance benefit, which is parity-based RAID levels that consume considerably more CPU power in order to generate the parity while RAID level 1 simply writes the same data more than once to the multiple RAID members with very little CPU overhead. As such, RAID level 1 can outperform the parity-based RAID levels on machines where software RAID is employed and CPU resources on the machine are consistently taxed with operations other than RAID activities.
The storage capacity of the level 1 array is equal to the capacity of the smallest mirrored hard disk in a hardware RAID or the smallest mirrored partition in a software RAID. Level 1 redundancy is the highest possible among all RAID types, with the array being able to operate with only a single disk present.
- Level 4
Level 4 uses parity concentrated on a single disk drive to protect data. Parity information is calculated based on the content of the rest of the member disks in the array. This information can then be used to reconstruct data when one disk in the array fails. The reconstructed data can then be used to satisfy I/O requests to the failed disk before it is replaced and to repopulate the failed disk after it has been replaced.
Since the dedicated parity disk represents an inherent bottleneck on all write transactions to the RAID array, level 4 is seldom used without accompanying technologies such as write-back caching. Or it is used in specific circumstances where the system administrator is intentionally designing the software RAID device with this bottleneck in mind such as an array that has little to no write transactions once the array is populated with data. RAID level 4 is so rarely used that it is not available as an option in Anaconda. However, it could be created manually by the user if needed.
The storage capacity of hardware RAID level 4 is equal to the capacity of the smallest member partition multiplied by the number of partitions minus one. The performance of a RAID level 4 array is always asymmetrical, which means reads outperform writes. This is because write operations consume extra CPU resources and main memory bandwidth when generating parity, and then also consume extra bus bandwidth when writing the actual data to disks because you are not only writing the data, but also the parity. Read operations need only read the data and not the parity unless the array is in a degraded state. As a result, read operations generate less traffic to the drives and across the buses of the computer for the same amount of data transfer under normal operating conditions.
- Level 5
This is the most common type of RAID. By distributing parity across all the member disk drives of an array, RAID level 5 eliminates the write bottleneck inherent in level 4. The only performance bottleneck is the parity calculation process itself. Modern CPUs can calculate parity very fast. However, if you have a large number of disks in a RAID 5 array such that the combined aggregate data transfer speed across all devices is high enough, parity calculation can be a bottleneck.
Level 5 has asymmetrical performance, and reads substantially outperforming writes. The storage capacity of RAID level 5 is calculated the same way as with level 4.
- Level 6
This is a common level of RAID when data redundancy and preservation, and not performance, are the paramount concerns, but where the space inefficiency of level 1 is not acceptable. Level 6 uses a complex parity scheme to be able to recover from the loss of any two drives in the array. This complex parity scheme creates a significantly higher CPU burden on software RAID devices and also imposes an increased burden during write transactions. As such, level 6 is considerably more asymmetrical in performance than levels 4 and 5.
The total capacity of a RAID level 6 array is calculated similarly to RAID level 5 and 4, except that you must subtract two devices instead of one from the device count for the extra parity storage space.
- Level 10
This RAID level attempts to combine the performance advantages of level 0 with the redundancy of level 1. It also reduces some of the space wasted in level 1 arrays with more than two devices. With level 10, it is possible, for example, to create a 3-drive array configured to store only two copies of each piece of data, which then allows the overall array size to be 1.5 times the size of the smallest devices instead of only equal to the smallest device, similar to a 3-device, level 1 array. This avoids CPU process usage to calculate parity similar to RAID level 6, but it is less space efficient.
The creation of RAID level 10 is not supported during installation. It is possible to create one manually after installation.
- Linear RAID
Linear RAID is a grouping of drives to create a larger virtual drive.
In linear RAID, the chunks are allocated sequentially from one member drive, going to the next drive only when the first is completely filled. This grouping provides no performance benefit, as it is unlikely that any I/O operations split between member drives. Linear RAID also offers no redundancy and decreases reliability. If any one member drive fails, the entire array cannot be used and data can be lost. The capacity is the total of all member disks.
67.7.2. LVM RAID segment types
To create a RAID logical volume, you can specify a RAID type by using the --type argument of the lvcreate command. For most users, specifying one of the five available primary types, which are raid1, raid4, raid5, raid6, and raid10, should be sufficient.
The following table describes the possible RAID segment types.
| Segment type | Description |
|---|---|
|
|
RAID1 mirroring. This is the default value for the |
|
| RAID4 dedicated parity disk. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| Striping. RAID0 spreads logical volume data across multiple data subvolumes in units of stripe size. This is used to increase performance. Logical volume data is lost if any of the data subvolumes fail. |
67.7.3. Parameters for creating a RAID0
You can create a RAID0 striped logical volume using the lvcreate --type raid0[meta] --stripes _Stripes --stripesize StripeSize VolumeGroup [PhysicalVolumePath] command.
The following table describes different parameters, which you can use while creating a RAID0 striped logical volume.
| Parameter | Description |
|---|---|
|
|
Specifying |
|
| Specifies the number of devices to spread the logical volume across. |
|
| Specifies the size of each stripe in kilobytes. This is the amount of data that is written to one device before moving to the next device. |
|
| Specifies the volume group to use. |
|
| Specifies the devices to use. If this is not specified, LVM will choose the number of devices specified by the Stripes option, one for each stripe. |
67.7.4. Creating RAID logical volumes
You can create RAID1 arrays with multiple numbers of copies, according to the value you specify for the -m argument. Similarly, you can specify the number of stripes for a RAID 0, 4, 5, 6, and 10 logical volume with the -i argument. You can also specify the stripe size with the -I argument. The following procedure describes different ways to create different types of RAID logical volume.
Procedure
Create a 2-way RAID. The following command creates a 2-way RAID1 array, named my_lv, in the volume group my_vg, that is 1G in size:
# lvcreate --type raid1 -m 1 -L 1G -n my_lv my_vg Logical volume "my_lv" created.Create a RAID5 array with stripes. The following command creates a RAID5 array with three stripes and one implicit parity drive, named my_lv, in the volume group my_vg, that is 1G in size. Note that you can specify the number of stripes similar to an LVM striped volume. The correct number of parity drives is added automatically.
# lvcreate --type raid5 -i 3 -L 1G -n my_lv my_vgCreate a RAID6 array with stripes. The following command creates a RAID6 array with three 3 stripes and two implicit parity drives, named my_lv, in the volume group my_vg, that is 1G one gigabyte in size:
# lvcreate --type raid6 -i 3 -L 1G -n my_lv my_vg
Verification
Display the LVM device my_vg/my_lv, which is a 2-way RAID1 array:
# lvs -a -o name,copy_percent,devices my_vg LV Copy% Devices my_lv 6.25 my_lv_rimage_0(0),my_lv_rimage_1(0) [my_lv_rimage_0] /dev/sde1(0) [my_lv_rimage_1] /dev/sdf1(1) [my_lv_rmeta_0] /dev/sde1(256) [my_lv_rmeta_1] /dev/sdf1(0)
67.7.5. Configuring an LVM pool with RAID by using the storage RHEL system role
With the storage system role, you can configure an LVM pool with RAID on RHEL by using Red Hat Ansible Automation Platform. You can set up an Ansible playbook with the available parameters to configure an LVM pool with RAID.
Prerequisites
- You have prepared the control node and the managed nodes
- You are logged in to the control node as a user who can run playbooks on the managed nodes.
-
The account you use to connect to the managed nodes has
sudopermissions on them.
Procedure
Create a playbook file, for example
~/playbook.yml, with the following content:--- - name: Manage local storage hosts: managed-node-01.example.com tasks: - name: Configure LVM pool with RAID ansible.builtin.include_role: name: redhat.rhel_system_roles.storage vars: storage_safe_mode: false storage_pools: - name: my_pool type: lvm disks: [sdh, sdi] raid_level: raid1 volumes: - name: my_volume size: "1 GiB" mount_point: "/mnt/app/shared" fs_type: xfs state: presentFor details about all variables used in the playbook, see the
/usr/share/ansible/roles/rhel-system-roles.storage/README.mdfile on the control node.Validate the playbook syntax:
$ ansible-playbook --syntax-check ~/playbook.ymlNote that this command only validates the syntax and does not protect against a wrong but valid configuration.
Run the playbook:
$ ansible-playbook ~/playbook.yml
Verification
Verify that your pool is on RAID:
# ansible managed-node-01.example.com -m command -a 'lsblk'
67.7.6. Creating a RAID0 striped logical volume
A RAID0 logical volume spreads logical volume data across multiple data subvolumes in units of stripe size. The following procedure creates an LVM RAID0 logical volume called mylv that stripes data across the disks.
Prerequisites
- You have created three or more physical volumes. For more information about creating physical volumes, see Creating LVM physical volume.
- You have created the volume group. For more information, see Creating LVM volume group.
Procedure
Create a RAID0 logical volume from the existing volume group. The following command creates the RAID0 volume mylv from the volume group myvg, which is 2G in size, with three stripes and a stripe size of 4kB:
# lvcreate --type raid0 -L 2G --stripes 3 --stripesize 4 -n mylv my_vg Rounding size 2.00 GiB (512 extents) up to stripe boundary size 2.00 GiB(513 extents). Logical volume "mylv" created.Create a file system on the RAID0 logical volume. The following command creates an ext4 file system on the logical volume:
# mkfs.ext4 /dev/my_vg/mylvMount the logical volume and report the file system disk space usage:
# mount /dev/my_vg/mylv /mnt # df Filesystem 1K-blocks Used Available Use% Mounted on /dev/mapper/my_vg-mylv 2002684 6168 1875072 1% /mnt
Verification
View the created RAID0 stripped logical volume:
# lvs -a -o +devices,segtype my_vg LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert Devices Type mylv my_vg rwi-a-r--- 2.00g mylv_rimage_0(0),mylv_rimage_1(0),mylv_rimage_2(0) raid0 [mylv_rimage_0] my_vg iwi-aor--- 684.00m /dev/sdf1(0) linear [mylv_rimage_1] my_vg iwi-aor--- 684.00m /dev/sdg1(0) linear [mylv_rimage_2] my_vg iwi-aor--- 684.00m /dev/sdh1(0) linear
67.7.7. Configuring a stripe size for RAID LVM volumes by using the storage RHEL system role
With the storage system role, you can configure a stripe size for RAID LVM volumes on RHEL by using Red Hat Ansible Automation Platform. You can set up an Ansible playbook with the available parameters to configure an LVM pool with RAID.
Prerequisites
- You have prepared the control node and the managed nodes
- You are logged in to the control node as a user who can run playbooks on the managed nodes.
-
The account you use to connect to the managed nodes has
sudopermissions on them.
Procedure
Create a playbook file, for example
~/playbook.yml, with the following content:--- - name: Manage local storage hosts: managed-node-01.example.com tasks: - name: Configure stripe size for RAID LVM volumes ansible.builtin.include_role: name: redhat.rhel_system_roles.storage vars: storage_safe_mode: false storage_pools: - name: my_pool type: lvm disks: [sdh, sdi] volumes: - name: my_volume size: "1 GiB" mount_point: "/mnt/app/shared" fs_type: xfs raid_level: raid0 raid_stripe_size: "256 KiB" state: presentFor details about all variables used in the playbook, see the
/usr/share/ansible/roles/rhel-system-roles.storage/README.mdfile on the control node.Validate the playbook syntax:
$ ansible-playbook --syntax-check ~/playbook.ymlNote that this command only validates the syntax and does not protect against a wrong but valid configuration.
Run the playbook:
$ ansible-playbook ~/playbook.yml
Verification
Verify that stripe size is set to the required size:
# ansible managed-node-01.example.com -m command -a 'lvs -o+stripesize /dev/my_pool/my_volume'
67.7.8. Soft data corruption
Soft corruption in data storage implies that the data retrieved from a storage device is different from the data written to that device. The corrupted data can exist indefinitely on storage devices. You might not discover this corrupted data until you retrieve and attempt to use this data.
Depending on the type of configuration, a Redundant Array of Independent Disks (RAID) logical volume(LV) prevents data loss when a device fails. If a device consisting of a RAID array fails, the data can be recovered from other devices that are part of that RAID LV. However, a RAID configuration does not ensure the integrity of the data itself. Soft corruption, silent corruption, soft errors, and silent errors are terms that describe data that has become corrupted, even if the system design and software continues to function as expected.
When creating a new RAID LV with DM integrity or adding integrity to an existing RAID LV, consider the following points:
- The integrity metadata requires additional storage space. For each RAID image, every 500MB data requires 4MB of additional storage space because of the checksums that get added to the data.
- While some RAID configurations are impacted more than others, adding DM integrity impacts performance due to latency when accessing the data. A RAID1 configuration typically offers better performance than RAID5 or its variants.
- The RAID integrity block size also impacts performance. Configuring a larger RAID integrity block size offers better performance. However, a smaller RAID integrity block size offers greater backward compatibility.
-
There are two integrity modes available:
bitmaporjournal. Thebitmapintegrity mode typically offers better performance thanjournalmode.
If you experience performance issues, either use RAID1 with integrity or test the performance of a particular RAID configuration to ensure that it meets your requirements.
67.7.9. Creating a RAID logical volume with DM integrity
When you create a RAID LV with device mapper (DM) integrity or add integrity to an existing RAID logical volume (LV), it mitigates the risk of losing data due to soft corruption. Wait for the integrity synchronization and the RAID metadata to complete before using the LV. Otherwise, the background initialization might impact the LV’s performance.
Device mapper (DM) integrity is used with RAID levels 1, 4, 5, 6, and 10 to mitigate or prevent data loss due to soft corruption. The RAID layer ensures that a non-corrupted copy of the data can fix the soft corruption errors.
Procedure
Create a RAID LV with DM integrity. The following example creates a new RAID LV with integrity named test-lv in the my_vg volume group, with a usable size of 256M and RAID level 1:
# lvcreate --type raid1 --raidintegrity y -L 256M -n test-lv my_vg Creating integrity metadata LV test-lv_rimage_0_imeta with size 8.00 MiB. Logical volume "test-lv_rimage_0_imeta" created. Creating integrity metadata LV test-lv_rimage_1_imeta with size 8.00 MiB. Logical volume "test-lv_rimage_1_imeta" created. Logical volume "test-lv" created.NoteTo add DM integrity to an existing RAID LV, use the following command:
# lvconvert --raidintegrity y my_vg/test-lvAdding integrity to a RAID LV limits the number of operations that you can perform on that RAID LV.
Optional: Remove the integrity before performing certain operations.
# lvconvert --raidintegrity n my_vg/test-lv Logical volume my_vg/test-lv has removed integrity.
Verification
View information about the added DM integrity:
View information about the test-lv RAID LV that was created in the my_vg volume group:
# lvs -a my_vg LV VG Attr LSize Origin Cpy%Sync test-lv my_vg rwi-a-r--- 256.00m 2.10 [test-lv_rimage_0] my_vg gwi-aor--- 256.00m [test-lv_rimage_0_iorig] 93.75 [test-lv_rimage_0_imeta] my_vg ewi-ao---- 8.00m [test-lv_rimage_0_iorig] my_vg -wi-ao---- 256.00m [test-lv_rimage_1] my_vg gwi-aor--- 256.00m [test-lv_rimage_1_iorig] 85.94 [...]The following describes different options from this output:
gattribute-
It is the list of attributes under the Attr column indicates that the RAID image is using integrity. The integrity stores the checksums in the
_imetaRAID LV. Cpy%Synccolumn- It indicates the synchronization progress for both the top level RAID LV and for each RAID image.
- RAID image
-
It is is indicated in the LV column by
raid_image_N. LVcolumn- It ensures that the synchronization progress displays 100% for the top level RAID LV and for each RAID image.
Display the type for each RAID LV:
# lvs -a my-vg -o+segtype LV VG Attr LSize Origin Cpy%Sync Type test-lv my_vg rwi-a-r--- 256.00m 87.96 raid1 [test-lv_rimage_0] my_vg gwi-aor--- 256.00m [test-lv_rimage_0_iorig] 100.00 integrity [test-lv_rimage_0_imeta] my_vg ewi-ao---- 8.00m linear [test-lv_rimage_0_iorig] my_vg -wi-ao---- 256.00m linear [test-lv_rimage_1] my_vg gwi-aor--- 256.00m [test-lv_rimage_1_iorig] 100.00 integrity [...]There is an incremental counter that counts the number of mismatches detected on each RAID image. View the data mismatches detected by integrity from
rimage_0under my_vg/test-lv:# lvs -o+integritymismatches my_vg/test-lv_rimage_0 LV VG Attr LSize Origin Cpy%Sync IntegMismatches [test-lv_rimage_0] my_vg gwi-aor--- 256.00m [test-lv_rimage_0_iorig] 100.00 0In this example, the integrity has not detected any data mismatches and thus the
IntegMismatchescounter shows zero (0).View the data integrity information in the
/var/log/messageslog files, as shown in the following examples:Example 67.1. Example of dm-integrity mismatches from the kernel message logs
device-mapper: integrity: dm-12: Checksum failed at sector 0x24e7
Example 67.2. Example of dm-integrity data corrections from the kernel message logs
md/raid1:mdX: read error corrected (8 sectors at 9448 on dm-16)
67.7.10. Converting a RAID logical volume to another RAID level
LVM supports RAID takeover, which means converting a RAID logical volume from one RAID level to another, for example, from RAID 5 to RAID 6. You can change the RAID level to increase or decrease resilience to device failures.
Procedure
Create a RAID logical volume:
# lvcreate --type raid5 -i 3 -L 500M -n my_lv my_vg Using default stripesize 64.00 KiB. Rounding size 500.00 MiB (125 extents) up to stripe boundary size 504.00 MiB (126 extents). Logical volume "my_lv" created.View the RAID logical volume:
# lvs -a -o +devices,segtype LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert Devices Type my_lv my_vg rwi-a-r--- 504.00m 100.00 my_lv_rimage_0(0),my_lv_rimage_1(0),my_lv_rimage_2(0),my_lv_rimage_3(0) raid5 [my_lv_rimage_0] my_vg iwi-aor--- 168.00m /dev/sda(1) linearConvert the RAID logical volume to another RAID level:
# lvconvert --type raid6 my_vg/my_lv Using default stripesize 64.00 KiB. Replaced LV type raid6 (same as raid6_zr) with possible type raid6_ls_6. Repeat this command to convert to raid6 after an interim conversion has finished. Are you sure you want to convert raid5 LV my_vg/my_lv to raid6_ls_6 type? [y/n]: y Logical volume my_vg/my_lv successfully converted.Optional: If this command prompts to repeat the conversion, run:
# lvconvert --type raid6 my_vg/my_lv
Verification
View the RAID logical volume with the converted RAID level:
# lvs -a -o +devices,segtype LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert Devices Type my_lv my_vg rwi-a-r--- 504.00m 100.00 my_lv_rimage_0(0),my_lv_rimage_1(0),my_lv_rimage_2(0),my_lv_rimage_3(0),my_lv_rimage_4(0) raid6 [my_lv_rimage_0] my_vg iwi-aor--- 172.00m /dev/sda(1) linear
67.7.11. Converting a linear device to a RAID logical volume
You can convert an existing linear logical volume to a RAID logical volume. To perform this operation, use the --type argument of the lvconvert command.
RAID logical volumes are composed of metadata and data subvolume pairs. When you convert a linear device to a RAID1 array, it creates a new metadata subvolume and associates it with the original logical volume on one of the same physical volumes that the linear volume is on. The additional images are added in a metadata/data subvolume pair. If the metadata image that pairs with the original logical volume cannot be placed on the same physical volume, the lvconvert fails.
Procedure
View the logical volume device that needs to be converted:
# lvs -a -o name,copy_percent,devices my_vg LV Copy% Devices my_lv /dev/sde1(0)Convert the linear logical volume to a RAID device. The following command converts the linear logical volume my_lv in volume group __my_vg, to a 2-way RAID1 array:
# lvconvert --type raid1 -m 1 my_vg/my_lv Are you sure you want to convert linear LV my_vg/my_lv to raid1 with 2 images enhancing resilience? [y/n]: y Logical volume my_vg/my_lv successfully converted.
Verification
Ensure if the logical volume is converted to a RAID device:
# lvs -a -o name,copy_percent,devices my_vg LV Copy% Devices my_lv 6.25 my_lv_rimage_0(0),my_lv_rimage_1(0) [my_lv_rimage_0] /dev/sde1(0) [my_lv_rimage_1] /dev/sdf1(1) [my_lv_rmeta_0] /dev/sde1(256) [my_lv_rmeta_1] /dev/sdf1(0)
67.7.12. Converting an LVM RAID1 logical volume to an LVM linear logical volume
You can convert an existing RAID1 LVM logical volume to an LVM linear logical volume. To perform this operation, use the lvconvert command and specify the -m0 argument. This removes all the RAID data subvolumes and all the RAID metadata subvolumes that make up the RAID array, leaving the top-level RAID1 image as the linear logical volume.
Procedure
Display an existing LVM RAID1 logical volume:
# lvs -a -o name,copy_percent,devices my_vg LV Copy% Devices my_lv 100.00 my_lv_rimage_0(0),my_lv_rimage_1(0) [my_lv_rimage_0] /dev/sde1(1) [my_lv_rimage_1] /dev/sdf1(1) [my_lv_rmeta_0] /dev/sde1(0) [my_lv_rmeta_1] /dev/sdf1(0)Convert an existing RAID1 LVM logical volume to an LVM linear logical volume. The following command converts the LVM RAID1 logical volume my_vg/my_lv to an LVM linear device:
# lvconvert -m0 my_vg/my_lv Are you sure you want to convert raid1 LV my_vg/my_lv to type linear losing all resilience? [y/n]: y Logical volume my_vg/my_lv successfully converted.When you convert an LVM RAID1 logical volume to an LVM linear volume, you can also specify which physical volumes to remove. In the following example, the
lvconvertcommand specifies that you want to remove /dev/sde1, leaving /dev/sdf1 as the physical volume that makes up the linear device:# lvconvert -m0 my_vg/my_lv /dev/sde1
Verification
Verify if the RAID1 logical volume was converted to an LVM linear device:
# lvs -a -o name,copy_percent,devices my_vg LV Copy% Devices my_lv /dev/sdf1(1)
67.7.13. Converting a mirrored LVM device to a RAID1 logical volume
You can convert an existing mirrored LVM device with a segment type mirror to a RAID1 LVM device. To perform this operation, use the lvconvert command with the --type raid1 argument. This renames the mirror subvolumes named mimage to RAID subvolumes named rimage.
In addition, it also removes the mirror log and creates metadata subvolumes named rmeta for the data subvolumes on the same physical volumes as the corresponding data subvolumes.
Procedure
View the layout of a mirrored logical volume my_vg/my_lv:
# lvs -a -o name,copy_percent,devices my_vg LV Copy% Devices my_lv 15.20 my_lv_mimage_0(0),my_lv_mimage_1(0) [my_lv_mimage_0] /dev/sde1(0) [my_lv_mimage_1] /dev/sdf1(0) [my_lv_mlog] /dev/sdd1(0)Convert the mirrored logical volume my_vg/my_lv to a RAID1 logical volume:
# lvconvert --type raid1 my_vg/my_lv Are you sure you want to convert mirror LV my_vg/my_lv to raid1 type? [y/n]: y Logical volume my_vg/my_lv successfully converted.
Verification
Verify if the mirrored logical volume is converted to a RAID1 logical volume:
# lvs -a -o name,copy_percent,devices my_vg LV Copy% Devices my_lv 100.00 my_lv_rimage_0(0),my_lv_rimage_1(0) [my_lv_rimage_0] /dev/sde1(0) [my_lv_rimage_1] /dev/sdf1(0) [my_lv_rmeta_0] /dev/sde1(125) [my_lv_rmeta_1] /dev/sdf1(125)
67.7.14. Changing the number of images in an existing RAID1 device
You can change the number of images in an existing RAID1 array, similar to the way you can change the number of images in the implementation of LVM mirroring.
When you add images to a RAID1 logical volume with the lvconvert command, you can perform the following operations:
- specify the total number of images for the resulting device,
- how many images to add to the device, and
- can optionally specify on which physical volumes the new metadata/data image pairs reside.
Procedure
Display the LVM device my_vg/my_lv, which is a 2-way RAID1 array:
# lvs -a -o name,copy_percent,devices my_vg LV Copy% Devices my_lv 6.25 my_lv_rimage_0(0),my_lv_rimage_1(0) [my_lv_rimage_0] /dev/sde1(0) [my_lv_rimage_1] /dev/sdf1(1) [my_lv_rmeta_0] /dev/sde1(256) [my_lv_rmeta_1] /dev/sdf1(0)Metadata subvolumes named
rmetaalways exist on the same physical devices as their data subvolume counterpartsrimage. The metadata/data subvolume pairs will not be created on the same physical volumes as those from another metadata/data subvolume pair in the RAID array unless you specify--allocanywhere.Convert the 2-way RAID1 logical volume my_vg/my_lv to a 3-way RAID1 logical volume:
# lvconvert -m 2 my_vg/my_lv Are you sure you want to convert raid1 LV my_vg/my_lv to 3 images enhancing resilience? [y/n]: y Logical volume my_vg/my_lv successfully converted.The following are a few examples of changing the number of images in an existing RAID1 device:
You can also specify which physical volumes to use while adding an image to RAID. The following command converts the 2-way RAID1 logical volume my_vg/my_lv to a 3-way RAID1 logical volume by specifying the physical volume /dev/sdd1 to use for the array:
# lvconvert -m 2 my_vg/my_lv /dev/sdd1Convert the 3-way RAID1 logical volume into a 2-way RAID1 logical volume:
# lvconvert -m1 my_vg/my_lv Are you sure you want to convert raid1 LV my_vg/my_lv to 2 images reducing resilience? [y/n]: y Logical volume my_vg/my_lv successfully converted.Convert the 3-way RAID1 logical volume into a 2-way RAID1 logical volume by specifying the physical volume /dev/sde1, which contains the image to remove:
# lvconvert -m1 my_vg/my_lv /dev/sde1Additionally, when you remove an image and its associated metadata subvolume volume, any higher-numbered images will be shifted down to fill the slot. Removing
lv_rimage_1from a 3-way RAID1 array that consists oflv_rimage_0,lv_rimage_1, andlv_rimage_2results in a RAID1 array that consists oflv_rimage_0andlv_rimage_1. The subvolumelv_rimage_2will be renamed and take over the empty slot, becominglv_rimage_1.
Verification
View the RAID1 device after changing the number of images in an existing RAID1 device:
# lvs -a -o name,copy_percent,devices my_vg LV Cpy%Sync Devices my_lv 100.00 my_lv_rimage_0(0),my_lv_rimage_1(0),my_lv_rimage_2(0) [my_lv_rimage_0] /dev/sdd1(1) [my_lv_rimage_1] /dev/sde1(1) [my_lv_rimage_2] /dev/sdf1(1) [my_lv_rmeta_0] /dev/sdd1(0) [my_lv_rmeta_1] /dev/sde1(0) [my_lv_rmeta_2] /dev/sdf1(0)
67.7.15. Splitting off a RAID image as a separate logical volume
You can split off an image of a RAID logical volume to form a new logical volume. When you are removing a RAID image from an existing RAID1 logical volume or removing a RAID data subvolume and its associated metadata subvolume from the middle of the device, any higher numbered images will be shifted down to fill the slot. The index numbers on the logical volumes that make up a RAID array will thus be an unbroken sequence of integers.
You cannot split off a RAID image if the RAID1 array is not yet in sync.
Procedure
Display the LVM device my_vg/my_lv, which is a 2-way RAID1 array:
# lvs -a -o name,copy_percent,devices my_vg LV Copy% Devices my_lv 12.00 my_lv_rimage_0(0),my_lv_rimage_1(0) [my_lv_rimage_0] /dev/sde1(1) [my_lv_rimage_1] /dev/sdf1(1) [my_lv_rmeta_0] /dev/sde1(0) [my_lv_rmeta_1] /dev/sdf1(0)Split the RAID image into a separate logical volume:
The following example splits a 2-way RAID1 logical volume, my_lv, into two linear logical volumes, my_lv and new:
# lvconvert --splitmirror 1 -n new my_vg/my_lv Are you sure you want to split raid1 LV my_vg/my_lv losing all resilience? [y/n]: yThe following example splits a 3-way RAID1 logical volume, my_lv, into a 2-way RAID1 logical volume, my_lv, and a linear logical volume, new:
# lvconvert --splitmirror 1 -n new my_vg/my_lv
Verification
View the logical volume after you split off an image of a RAID logical volume:
# lvs -a -o name,copy_percent,devices my_vg LV Copy% Devices my_lv /dev/sde1(1) new /dev/sdf1(1)
67.7.16. Splitting and merging a RAID Image
You can temporarily split off an image of a RAID1 array for read-only use while tracking any changes by using the --trackchanges argument with the --splitmirrors argument of the lvconvert command. Using this feature, you can merge the image into an array at a later time while resyncing only those portions of the array that have changed since the image was split.
When you split off a RAID image with the --trackchanges argument, you can specify which image to split but you cannot change the name of the volume being split. In addition, the resulting volumes have the following constraints:
- The new volume you create is read-only.
- You cannot resize the new volume.
- You cannot rename the remaining array.
- You cannot resize the remaining array.
- You can activate the new volume and the remaining array independently.
You can merge an image that was split off. When you merge the image, only the portions of the array that have changed since the image was split are resynced.
Procedure
Create a RAID logical volume:
# lvcreate --type raid1 -m 2 -L 1G -n my_lv my_vg Logical volume "my_lv" createdOptional: View the created RAID logical volume:
# lvs -a -o name,copy_percent,devices my_vg LV Copy% Devices my_lv 100.00 my_lv_rimage_0(0),my_lv_rimage_1(0),my_lv_rimage_2(0) [my_lv_rimage_0] /dev/sdb1(1) [my_lv_rimage_1] /dev/sdc1(1) [my_lv_rimage_2] /dev/sdd1(1) [my_lv_rmeta_0] /dev/sdb1(0) [my_lv_rmeta_1] /dev/sdc1(0) [my_lv_rmeta_2] /dev/sdd1(0)Split an image from the created RAID logical volume and track the changes to the remaining array:
# lvconvert --splitmirrors 1 --trackchanges my_vg/my_lv my_lv_rimage_2 split from my_lv for read-only purposes. Use 'lvconvert --merge my_vg/my_lv_rimage_2' to merge back into my_lvOptional: View the logical volume after splitting the image:
# lvs -a -o name,copy_percent,devices my_vg LV Copy% Devices my_lv 100.00 my_lv_rimage_0(0),my_lv_rimage_1(0) [my_lv_rimage_0] /dev/sdc1(1) [my_lv_rimage_1] /dev/sdd1(1) [my_lv_rmeta_0] /dev/sdc1(0) [my_lv_rmeta_1] /dev/sdd1(0)Merge the volume back into the array:
# lvconvert --merge my_vg/my_lv_rimage_1 my_vg/my_lv_rimage_1 successfully merged back into my_vg/my_lv
Verification
View the merged logical volume:
# lvs -a -o name,copy_percent,devices my_vg LV Copy% Devices my_lv 100.00 my_lv_rimage_0(0),my_lv_rimage_1(0) [my_lv_rimage_0] /dev/sdc1(1) [my_lv_rimage_1] /dev/sdd1(1) [my_lv_rmeta_0] /dev/sdc1(0) [my_lv_rmeta_1] /dev/sdd1(0)
67.7.17. Setting the RAID fault policy to allocate
You can set the raid_fault_policy field to the allocate parameter in the /etc/lvm/lvm.conf file. With this preference, the system attempts to replace the failed device with a spare device from the volume group. If there is no spare device, the system log includes this information.
Procedure
View the RAID logical volume:
# lvs -a -o name,copy_percent,devices my_vg LV Copy% Devices my_lv 100.00 my_lv_rimage_0(0),my_lv_rimage_1(0),my_lv_rimage_2(0) [my_lv_rimage_0] /dev/sdb1(1) [my_lv_rimage_1] /dev/sdc1(1) [my_lv_rimage_2] /dev/sdd1(1) [my_lv_rmeta_0] /dev/sdb1(0) [my_lv_rmeta_1] /dev/sdc1(0) [my_lv_rmeta_2] /dev/sdd1(0)View the RAID logical volume if the /dev/sdb device fails:
# lvs --all --options name,copy_percent,devices my_vg /dev/sdb: open failed: No such device or address Couldn't find device with uuid A4kRl2-vIzA-uyCb-cci7-bOod-H5tX-IzH4Ee. WARNING: Couldn't find all devices for LV my_vg/my_lv_rimage_1 while checking used and assumed devices. WARNING: Couldn't find all devices for LV my_vg/my_lv_rmeta_1 while checking used and assumed devices. LV Copy% Devices my_lv 100.00 my_lv_rimage_0(0),my_lv_rimage_1(0),my_lv_rimage_2(0) [my_lv_rimage_0] [unknown](1) [my_lv_rimage_1] /dev/sdc1(1) [...]You can also view the system log for the error messages if the /dev/sdb device fails.
Set the
raid_fault_policyfield toallocatein thelvm.conffile:# vi /etc/lvm/lvm.conf raid_fault_policy = "allocate"NoteIf you set
raid_fault_policytoallocatebut there are no spare devices, the allocation fails, leaving the logical volume as it is. If the allocation fails, you can fix and replace the failed device by using thelvconvert --repaircommand. For more information, see Replacing a failed RAID device in a logical volume.
Verification
Verify if the failed device is now replaced with a new device from the volume group:
# lvs -a -o name,copy_percent,devices my_vg Couldn't find device with uuid 3lugiV-3eSP-AFAR-sdrP-H20O-wM2M-qdMANy. LV Copy% Devices lv 100.00 lv_rimage_0(0),lv_rimage_1(0),lv_rimage_2(0) [lv_rimage_0] /dev/sdh1(1) [lv_rimage_1] /dev/sdc1(1) [lv_rimage_2] /dev/sdd1(1) [lv_rmeta_0] /dev/sdh1(0) [lv_rmeta_1] /dev/sdc1(0) [lv_rmeta_2] /dev/sdd1(0)NoteEven though the failed device is now replaced, the display still indicates that LVM could not find the failed device because the device is not yet removed from the volume group. You can remove the failed device from the volume group by executing the
vgreduce --removemissing my_vgcommand.
67.7.18. Setting the RAID fault policy to warn
You can set the raid_fault_policy field to the warn parameter in the lvm.conf file. With this preference, the system adds a warning to the system log that indicates a failed device. Based on the warning, you can determine the further steps.
By default, the value of the raid_fault_policy field is warn in lvm.conf.
Procedure
View the RAID logical volume:
# lvs -a -o name,copy_percent,devices my_vg LV Copy% Devices my_lv 100.00 my_lv_rimage_0(0),my_lv_rimage_1(0),my_lv_rimage_2(0) [my_lv_rimage_0] /dev/sdb1(1) [my_lv_rimage_1] /dev/sdc1(1) [my_lv_rimage_2] /dev/sdd1(1) [my_lv_rmeta_0] /dev/sdb1(0) [my_lv_rmeta_1] /dev/sdc1(0) [my_lv_rmeta_2] /dev/sdd1(0)Set the raid_fault_policy field to warn in the lvm.conf file:
# vi /etc/lvm/lvm.conf # This configuration option has an automatic default value. raid_fault_policy = "warn"View the system log to display error messages if the /dev/sdb device fails:
# grep lvm /var/log/messages Apr 14 18:48:59 virt-506 kernel: sd 25:0:0:0: rejecting I/O to offline device Apr 14 18:48:59 virt-506 kernel: I/O error, dev sdb, sector 8200 op 0x1:(WRITE) flags 0x20800 phys_seg 0 prio class 2 [...] Apr 14 18:48:59 virt-506 dmeventd[91060]: WARNING: VG my_vg is missing PV 9R2TVV-bwfn-Bdyj-Gucu-1p4F-qJ2Q-82kCAF (last written to /dev/sdb). Apr 14 18:48:59 virt-506 dmeventd[91060]: WARNING: Couldn't find device with uuid 9R2TVV-bwfn-Bdyj-Gucu-1p4F-qJ2Q-82kCAF. Apr 14 18:48:59 virt-506 dmeventd[91060]: Use 'lvconvert --repair my_vg/ly_lv' to replace failed device.If the /dev/sdb device fails, the system log displays error messages. In this case, however, LVM will not automatically attempt to repair the RAID device by replacing one of the images. Instead, if the device has failed you can replace the device with the
--repairargument of thelvconvertcommand. For more information, see Replacing a failed RAID device in a logical volume.
67.7.19. Replacing a working RAID device
You can replace a working RAID device in a logical volume by using the --replace argument of the lvconvert command.
In the case of RAID device failure, the following commands do not work.
Prerequisites
- The RAID device has not failed.
Procedure
Create a RAID1 array:
# lvcreate --type raid1 -m 2 -L 1G -n my_lv my_vg Logical volume "my_lv" createdExamine the created RAID1 array:
# lvs -a -o name,copy_percent,devices my_vg LV Copy% Devices my_lv 100.00 my_lv_rimage_0(0),my_lv_rimage_1(0),my_lv_rimage_2(0) [my_lv_rimage_0] /dev/sdb1(1) [my_lv_rimage_1] /dev/sdb2(1) [my_lv_rimage_2] /dev/sdc1(1) [my_lv_rmeta_0] /dev/sdb1(0) [my_lv_rmeta_1] /dev/sdb2(0) [my_lv_rmeta_2] /dev/sdc1(0)Replace the RAID device with any of the following methods depending on your requirements:
Replace a RAID1 device by specifying the physical volume that you want to replace:
# lvconvert --replace /dev/sdb2 my_vg/my_lvReplace a RAID1 device by specifying the physical volume to use for the replacement:
# lvconvert --replace /dev/sdb1 my_vg/my_lv /dev/sdd1Replace multiple RAID devices at a time by specifying multiple replace arguments:
# lvconvert --replace /dev/sdb1 --replace /dev/sdc1 my_vg/my_lv
Verification
Examine the RAID1 array after specifying the physical volume that you wanted to replace:
# lvs -a -o name,copy_percent,devices my_vg LV Copy% Devices my_lv 37.50 my_lv_rimage_0(0),my_lv_rimage_1(0),my_lv_rimage_2(0) [my_lv_rimage_0] /dev/sdb1(1) [my_lv_rimage_1] /dev/sdc2(1) [my_lv_rimage_2] /dev/sdc1(1) [my_lv_rmeta_0] /dev/sdb1(0) [my_lv_rmeta_1] /dev/sdc2(0) [my_lv_rmeta_2] /dev/sdc1(0)Examine the RAID1 array after specifying the physical volume to use for the replacement:
# lvs -a -o name,copy_percent,devices my_vg LV Copy% Devices my_lv 28.00 my_lv_rimage_0(0),my_lv_rimage_1(0) [my_lv_rimage_0] /dev/sda1(1) [my_lv_rimage_1] /dev/sdd1(1) [my_lv_rmeta_0] /dev/sda1(0) [my_lv_rmeta_1] /dev/sdd1(0)Examine the RAID1 array after replacing multiple RAID devices at a time:
# lvs -a -o name,copy_percent,devices my_vg LV Copy% Devices my_lv 60.00 my_lv_rimage_0(0),my_lv_rimage_1(0),my_lv_rimage_2(0) [my_lv_rimage_0] /dev/sda1(1) [my_lv_rimage_1] /dev/sdd1(1) [my_lv_rimage_2] /dev/sde1(1) [my_lv_rmeta_0] /dev/sda1(0) [my_lv_rmeta_1] /dev/sdd1(0) [my_lv_rmeta_2] /dev/sde1(0)
67.7.20. Replacing a failed RAID device in a logical volume
RAID is not similar to traditional LVM mirroring. In case of LVM mirroring, remove the failed devices. Otherwise, the mirrored logical volume would hang while RAID arrays continue running with failed devices. For RAID levels other than RAID1, removing a device would mean converting to a lower RAID level, for example, from RAID6 to RAID5, or from RAID4 or RAID5 to RAID0.
Instead of removing a failed device and allocating a replacement, with LVM, you can replace a failed device that serves as a physical volume in a RAID logical volume by using the --repair argument of the lvconvert command.
Prerequisites
The volume group includes a physical volume that provides enough free capacity to replace the failed device.
If no physical volume with enough free extents is available on the volume group, add a new, sufficiently large physical volume by using the
vgextendutility.
Procedure
View the RAID logical volume:
# lvs --all --options name,copy_percent,devices my_vg LV Cpy%Sync Devices my_lv 100.00 my_lv_rimage_0(0),my_lv_rimage_1(0),my_lv_rimage_2(0) [my_lv_rimage_0] /dev/sde1(1) [my_lv_rimage_1] /dev/sdc1(1) [my_lv_rimage_2] /dev/sdd1(1) [my_lv_rmeta_0] /dev/sde1(0) [my_lv_rmeta_1] /dev/sdc1(0) [my_lv_rmeta_2] /dev/sdd1(0)View the RAID logical volume after the /dev/sdc device fails:
# lvs --all --options name,copy_percent,devices my_vg /dev/sdc: open failed: No such device or address Couldn't find device with uuid A4kRl2-vIzA-uyCb-cci7-bOod-H5tX-IzH4Ee. WARNING: Couldn't find all devices for LV my_vg/my_lv_rimage_1 while checking used and assumed devices. WARNING: Couldn't find all devices for LV my_vg/my_lv_rmeta_1 while checking used and assumed devices. LV Cpy%Sync Devices my_lv 100.00 my_lv_rimage_0(0),my_lv_rimage_1(0),my_lv_rimage_2(0) [my_lv_rimage_0] /dev/sde1(1) [my_lv_rimage_1] [unknown](1) [my_lv_rimage_2] /dev/sdd1(1) [my_lv_rmeta_0] /dev/sde1(0) [my_lv_rmeta_1] [unknown](0) [my_lv_rmeta_2] /dev/sdd1(0)Replace the failed device:
# lvconvert --repair my_vg/my_lv /dev/sdc: open failed: No such device or address Couldn't find device with uuid A4kRl2-vIzA-uyCb-cci7-bOod-H5tX-IzH4Ee. WARNING: Couldn't find all devices for LV my_vg/my_lv_rimage_1 while checking used and assumed devices. WARNING: Couldn't find all devices for LV my_vg/my_lv_rmeta_1 while checking used and assumed devices. Attempt to replace failed RAID images (requires full device resync)? [y/n]: y Faulty devices in my_vg/my_lv successfully replaced.Optional: Manually specify the physical volume that replaces the failed device:
# lvconvert --repair my_vg/my_lv replacement_pvExamine the logical volume with the replacement:
# lvs --all --options name,copy_percent,devices my_vg /dev/sdc: open failed: No such device or address /dev/sdc1: open failed: No such device or address Couldn't find device with uuid A4kRl2-vIzA-uyCb-cci7-bOod-H5tX-IzH4Ee. LV Cpy%Sync Devices my_lv 43.79 my_lv_rimage_0(0),my_lv_rimage_1(0),my_lv_rimage_2(0) [my_lv_rimage_0] /dev/sde1(1) [my_lv_rimage_1] /dev/sdb1(1) [my_lv_rimage_2] /dev/sdd1(1) [my_lv_rmeta_0] /dev/sde1(0) [my_lv_rmeta_1] /dev/sdb1(0) [my_lv_rmeta_2] /dev/sdd1(0)Until you remove the failed device from the volume group, LVM utilities still indicate that LVM cannot find the failed device.
Remove the failed device from the volume group:
# vgreduce --removemissing my_vg
Verification
View the available physical volumes after removing the failed device:
# pvscan PV /dev/sde1 VG rhel_virt-506 lvm2 [<7.00 GiB / 0 free] PV /dev/sdb1 VG my_vg lvm2 [<60.00 GiB / 59.50 GiB free] PV /dev/sdd1 VG my_vg lvm2 [<60.00 GiB / 59.50 GiB free] PV /dev/sdd1 VG my_vg lvm2 [<60.00 GiB / 59.50 GiB free]Examine the logical volume after the replacing the failed device:
# lvs --all --options name,copy_percent,devices my_vg my_lv_rimage_0(0),my_lv_rimage_1(0),my_lv_rimage_2(0) [my_lv_rimage_0] /dev/sde1(1) [my_lv_rimage_1] /dev/sdb1(1) [my_lv_rimage_2] /dev/sdd1(1) [my_lv_rmeta_0] /dev/sde1(0) [my_lv_rmeta_1] /dev/sdb1(0) [my_lv_rmeta_2] /dev/sdd1(0)
67.7.21. Checking data coherency in a RAID logical volume
LVM provides scrubbing support for RAID logical volumes. RAID scrubbing is the process of reading all the data and parity blocks in an array and checking to see whether they are coherent. The lvchange --syncaction repair command initiates a background synchronization action on the array.
Procedure
Optional: Control the rate at which a RAID logical volume is initialized by setting any one of the following options:
-
--maxrecoveryrate Rate[bBsSkKmMgG]sets the maximum recovery rate for a RAID logical volume so that it will not expel nominal I/O operations. --minrecoveryrate Rate[bBsSkKmMgG]sets the minimum recovery rate for a RAID logical volume to ensure that I/O for sync operations achieves a minimum throughput, even when heavy nominal I/O is present# lvchange --maxrecoveryrate 4K my_vg/my_lv Logical volume _my_vg/my_lv_changed.Replace 4K with the recovery rate value, which is an amount per second for each device in the array. If you provide no suffix, the options assume kiB per second per device.
# lvchange --syncaction repair my_vg/my_lvWhen you perform a RAID scrubbing operation, the background I/O required by the
syncactions can crowd out other I/O to LVM devices, such as updates to volume group metadata. This might cause the other LVM operations to slow down.NoteYou can also use these maximum and minimum I/O rate while creating a RAID device. For example,
lvcreate --type raid10 -i 2 -m 1 -L 10G --maxrecoveryrate 128 -n my_lv my_vgcreates a 2-way RAID10 array my_lv, which is in the volume group my_vg with 3 stripes that is 10G in size with a maximum recovery rate of 128 kiB/sec/device.
-
Display the number of discrepancies in the array, without repairing them:
# lvchange --syncaction check my_vg/my_lvThis command initiates a background synchronization action on the array.
-
Optional: View the
var/log/syslogfile for the kernel messages. Correct the discrepancies in the array:
# lvchange --syncaction repair my_vg/my_lvThis command repairs or replaces failed devices in a RAID logical volume. You can view the
var/log/syslogfile for the kernel messages after executing this command.
Verification
Display information about the scrubbing operation:
# lvs -o +raid_sync_action,raid_mismatch_count my_vg/my_lv LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert SyncAction Mismatches my_lv my_vg rwi-a-r--- 500.00m 100.00 idle 0
67.7.22. I/O Operations on a RAID1 logical volume
You can control the I/O operations for a device in a RAID1 logical volume by using the --writemostly and --writebehind parameters of the lvchange command. The following is the format for using these parameters:
--[raid]writemostly PhysicalVolume[:{t|y|n}]Marks a device in a RAID1 logical volume as
write-mostlyand avoids all read actions to these drives unless necessary. Setting this parameter keeps the number of I/O operations to the drive to a minimum.Use the
lvchange --writemostly /dev/sdb my_vg/my_lvcommand to set this parameter.You can set the
writemostlyattribute in the following ways::y-
By default, the value of the
writemostlyattribute is yes for the specified physical volume in the logical volume. :n-
To remove the
writemostlyflag, append:nto the physical volume. :tTo toggle the value of the
writemostlyattribute, specify the--writemostlyargument.You can use this argument more than one time in a single command, for example,
lvchange --writemostly /dev/sdd1:n --writemostly /dev/sdb1:t --writemostly /dev/sdc1:y my_vg/my_lv. With this, it is possible to toggle thewritemostlyattributes for all the physical volumes in a logical volume at once.
--[raid]writebehind IOCountSpecifies the maximum number of pending writes marked as
writemostly. These are the number of write operations applicable to devices in a RAID1 logical volume. After the value of this parameter exceeds, all write actions to the constituent devices complete synchronously before the RAID array notifies for completion of all write actions.You can set this parameter by using the
lvchange --writebehind 100 my_vg/my_lvcommand. Setting thewritemostlyattribute’s value to zero clears the preference. With this setting, the system chooses the value arbitrarily.
67.7.23. Reshaping a RAID volume
RAID reshaping means changing attributes of a RAID logical volume without changing the RAID level. Some attributes that you can change include RAID layout, stripe size, and number of stripes.
Procedure
Create a RAID logical volume:
# lvcreate --type raid5 -i 2 -L 500M -n my_lv my_vg Using default stripesize 64.00 KiB. Rounding size 500.00 MiB (125 extents) up to stripe boundary size 504.00 MiB (126 extents). Logical volume "my_lv" created.View the RAID logical volume:
# lvs -a -o +devices LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert Devices my_lv my_vg rwi-a-r--- 504.00m 100.00 my_lv_rimage_0(0),my_lv_rimage_1(0),my_lv_rimage_2(0) [my_lv_rimage_0] my_vg iwi-aor--- 252.00m /dev/sda(1) [my_lv_rimage_1] my_vg iwi-aor--- 252.00m /dev/sdb(1) [my_lv_rimage_2] my_vg iwi-aor--- 252.00m /dev/sdc(1) [my_lv_rmeta_0] my_vg ewi-aor--- 4.00m /dev/sda(0) [my_lv_rmeta_1] my_vg ewi-aor--- 4.00m /dev/sdb(0) [my_lv_rmeta_2] my_vg ewi-aor--- 4.00m /dev/sdc(0)Optional: View the
stripesimages andstripesizeof the RAID logical volume:# lvs -o stripes my_vg/my_lv #Str 3# lvs -o stripesize my_vg/my_lv Stripe 64.00kModify the attributes of the RAID logical volume by using the following ways depending on your requirement:
Modify the
stripesimages of the RAID logical volume:# lvconvert --stripes 3 my_vg/my_lv Using default stripesize 64.00 KiB. WARNING: Adding stripes to active logical volume my_vg/my_lv will grow it from 126 to 189 extents! Run "lvresize -l126 my_vg/my_lv" to shrink it or use the additional capacity. Are you sure you want to add 1 images to raid5 LV my_vg/my_lv? [y/n]: y Logical volume my_vg/my_lv successfully converted.Modify the
stripesizeof the RAID logical volume:# lvconvert --stripesize 128k my_vg/my_lv Converting stripesize 64.00 KiB of raid5 LV my_vg/my_lv to 128.00 KiB. Are you sure you want to convert raid5 LV my_vg/my_lv? [y/n]: y Logical volume my_vg/my_lv successfully converted.Modify the
maxrecoveryrateandminrecoveryrateattributes:# lvchange --maxrecoveryrate 4M my_vg/my_lv Logical volume my_vg/my_lv changed.# lvchange --minrecoveryrate 1M my_vg/my_lv Logical volume my_vg/my_lv changed.Modify the
syncactionattribute:# lvchange --syncaction check my_vg/my_lvModify the
writemostlyandwritebehindattributes:# lvchange --writemostly /dev/sdb my_vg/my_lv Logical volume my_vg/my_lv changed.# lvchange --writebehind 100 my_vg/my_lv Logical volume my_vg/my_lv changed.
Verification
View the
stripesimages andstripesizeof the RAID logical volume:# lvs -o stripes my_vg/my_lv #Str 4# lvs -o stripesize my_vg/my_lv Stripe 128.00kView the RAID logical volume after modifying the
maxrecoveryrateattribute:# lvs -a -o +raid_max_recovery_rate LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert MaxSync my_lv my_vg rwi-a-r--- 10.00g 100.00 4096 [my_lv_rimage_0] my_vg iwi-aor--- 10.00g [...]View the RAID logical volume after modifying the
minrecoveryrateattribute:# lvs -a -o +raid_min_recovery_rate LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert MinSync my_lv my_vg rwi-a-r--- 10.00g 100.00 1024 [my_lv_rimage_0] my_vg iwi-aor--- 10.00g [...]View the RAID logical volume after modifying the
syncactionattribute:# lvs -a LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert my_lv my_vg rwi-a-r--- 10.00g 2.66 [my_lv_rimage_0] my_vg iwi-aor--- 10.00g [...]
67.7.24. Changing the region size on a RAID logical volume
When you create a RAID logical volume, the raid_region_size parameter from the /etc/lvm/lvm.conf file represents the region size for the RAID logical volume. After you created a RAID logical volume, you can change the region size of the volume. This parameter defines the granularity to keep track of the dirty or clean state. Dirty bits in the bitmap define the work set to synchronize after a dirty shutdown of a RAID volume, for example, a system failure.
If you set raid_region_size to a higher value, it reduces the size of bitmap as well as the congestion. But it impacts the write operation during resynchronizing the region because writes to RAID are postponed until synchronizing the region finishes.
Procedure
Create a RAID logical volume:
# lvcreate --type raid1 -m 1 -L 10G test Logical volume "lvol0" created.View the RAID logical volume:
# lvs -a -o +devices,region_size LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert Devices Region lvol0 test rwi-a-r--- 10.00g 100.00 lvol0_rimage_0(0),lvol0_rimage_1(0) 2.00m [lvol0_rimage_0] test iwi-aor--- 10.00g /dev/sde1(1) 0 [lvol0_rimage_1] test iwi-aor--- 10.00g /dev/sdf1(1) 0 [lvol0_rmeta_0] test ewi-aor--- 4.00m /dev/sde1(0) 0 [lvol0_rmeta_1] test ewi-aor--- 4.00mThe Region column indicates the raid_region_size parameter’s value.
Optional: View the
raid_region_sizeparameter’s value:# cat /etc/lvm/lvm.conf | grep raid_region_size # Configuration option activation/raid_region_size. # raid_region_size = 2048Change the region size of a RAID logical volume:
# lvconvert -R 4096K my_vg/my_lv Do you really want to change the region_size 512.00 KiB of LV my_vg/my_lv to 4.00 MiB? [y/n]: y Changed region size on RAID LV my_vg/my_lv to 4.00 MiB.Resynchronize the RAID logical volume:
# lvchange --resync my_vg/my_lv Do you really want to deactivate logical volume my_vg/my_lv to resync it? [y/n]: y
Verification
View the RAID logical volume:
# lvs -a -o +devices,region_size LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert Devices Region lvol0 test rwi-a-r--- 10.00g 6.25 lvol0_rimage_0(0),lvol0_rimage_1(0) 4.00m [lvol0_rimage_0] test iwi-aor--- 10.00g /dev/sde1(1) 0 [lvol0_rimage_1] test iwi-aor--- 10.00g /dev/sdf1(1) 0 [lvol0_rmeta_0] test ewi-aor--- 4.00m /dev/sde1(0) 0The Region column indicates the changed value of the
raid_region_sizeparameter.View the
raid_region_sizeparameter’s value in thelvm.conffile:# cat /etc/lvm/lvm.conf | grep raid_region_size # Configuration option activation/raid_region_size. # raid_region_size = 4096
67.8. Snapshot of logical volumes
Using the LVM snapshot feature, you can create virtual images of a volume, for example, /dev/sda, at a particular instant without causing a service interruption.
67.8.1. Overview of snapshot volumes
When you modify the original volume (the origin) after you take a snapshot, the snapshot feature makes a copy of the modified data area as it was prior to the change so that it can reconstruct the state of the volume. When you create a snapshot, full read and write access to the origin stays possible.
Since a snapshot copies only the data areas that change after the snapshot is created, the snapshot feature requires a minimal amount of storage. For example, with a rarely updated origin, 3-5 % of the origin’s capacity is sufficient to maintain the snapshot. It does not provide a substitute for a backup procedure. Snapshot copies are virtual copies and are not an actual media backup.
The size of the snapshot controls the amount of space set aside for storing the changes to the origin volume. For example, if you create a snapshot and then completely overwrite the origin, the snapshot should be at least as big as the origin volume to hold the changes. You should regularly monitor the size of the snapshot. For example, a short-lived snapshot of a read-mostly volume, such as /usr, would need less space than a long-lived snapshot of a volume because it contains many writes, such as /home.
If a snapshot is full, the snapshot becomes invalid because it can no longer track changes on the origin volume. But you can configure LVM to automatically extend a snapshot whenever its usage exceeds the snapshot_autoextend_threshold value to avoid snapshot becoming invalid. Snapshots are fully resizable and you can perform the following operations:
- If you have the storage capacity, you can increase the size of the snapshot volume to prevent it from getting dropped.
- If the snapshot volume is larger than you need, you can reduce the size of the volume to free up space that is needed by other logical volumes.
The snapshot volume provide the following benefits:
- Most typically, you take a snapshot when you need to perform a backup on a logical volume without halting the live system that is continuously updating the data.
-
You can execute the
fsckcommand on a snapshot file system to check the file system integrity and determine if the original file system requires file system repair. - Since the snapshot is read/write, you can test applications against production data by taking a snapshot and running tests against the snapshot without touching the real data.
- You can create LVM volumes for use with Red Hat Virtualization. You can use LVM snapshots to create snapshots of virtual guest images. These snapshots can provide a convenient way to modify existing guests or create new guests with minimal additional storage.
67.8.2. Creating a Copy-On-Write snapshot
Upon creation, Copy-on-Write (COW) snapshots do not contain any data. Instead, it references the data blocks of the original volume at the moment of snapshot creation. When data on the original volume changes, the COW system copies the original, unchanged data to the snapshot before the change is made. This way, the snapshot grows in size only as changes occur, storing the state of the original volume at the time of the snapshot’s creation. COW snapshots are efficient for short-term backups and situations with minimal data changes, offering a space-saving method to capture and revert to a specific point in time. When you create a COW snapshot, allocate enough storage for it based on the expected changes to the original volume.
Before creating a snapshot, it is important to consider the storage requirements and the intended lifespan of your snapshot. The size of the snapshot should be sufficient to capture changes during its intended lifespan, but it cannot exceed the size of the original LV. If you expect a low rate of change, a smaller snapshot size of 10%-15% might be sufficient. For LVs with a high rate of change, you might need to allocate 30% or more.
It is important to regularly monitor the snapshot’s storage usage. If a snapshot reaches 100% of its allocated space, it will become invalid. You can display the information about the snapshot with the lvs command.
It is essential to extend the snapshot before it gets completely filled. This can be done manually by using the lvextend command. Alternatively, you can set up automatic extension by setting snapshot_autoextend_threshold and snapshot_autoextend_percent parameters in the /etc/lvm/lvm.conf file. This configuration allows dmeventd to automatically extend the snapshot when its usage reaches a defined threshold.
The COW snapshot allows you to access a read-only version of the file system as it was at the time the snapshot was taken. This enables backups or data analysis without interrupting the ongoing operations on the original file system. While the snapshot is mounted and being used, the original logical volume and its file system can continue to be updated and used normally.
The following procedure outlines how to create a logical volume named origin from the volume group vg001 and then create a snapshot of it named snap.
Prerequisites
- Administrative access.
- You have created a volume group. For more information, see Creating LVM volume group.
Procedure
Create a logical volume named origin from the volume group vg001:
# lvcreate -L 1G -n origin vg001Create a snapshot named snap of /dev/vg001/origin LV that is 100 MB in size:
# lvcreate --size 100M --name snap --snapshot /dev/vg001/originDisplay the origin volume and the current percentage of the snapshot volume being used:
# lvs -a -o +devices LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert Devices origin vg001 owi-a-s--- 1.00g /dev/sde1(0) snap vg001 swi-a-s--- 100.00m origin 0.00 /dev/sde1(256)
67.8.3. Merging snapshot to its original volume
Use the lvconvert command with the --merge option to merge a snapshot into its original (the origin) volume. You can perform a system rollback if you have lost data or files, or otherwise you have to restore your system to a previous state. After you merge the snapshot volume, the resulting logical volume has the origin volume’s name, minor number, and UUID. While the merge is in progress, reads or writes to the origin appear as they were directed to the snapshot being merged. When the merge finishes, the merged snapshot is removed.
If both the origin and snapshot volume are not open and active, the merge starts immediately. Otherwise, the merge starts after either the origin or snapshot are activated and both are closed. You can merge a snapshot into an origin that cannot be closed, for example a root file system, after the origin volume is activated.
Procedure
Merge the snapshot volume. The following command merges snapshot volume vg001/snap into its origin:
# lvconvert --merge vg001/snap Merging of volume vg001/snap started. vg001/origin: Merged: 100.00%View the origin volume:
# lvs -a -o +devices LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert Devices origin vg001 owi-a-s--- 1.00g /dev/sde1(0)
67.8.4. Creating LVM snapshots using the snapshot RHEL System Role
With the new snapshot RHEL system role, you can now create LVM snapshots. This system role also checks if there is sufficient space for the created snapshots and no conflict with its name by setting the snapshot_lvm_action parameter to check. To mount the created snapshot, set snapshot_lvm_action to mount.
In the following example, the nouuid option is set and only required when working with the XFS file system. XFS does not support mounting multiple file systems at the same time with the same UUID.
Prerequisites
- You have prepared the control node and the managed nodes
- You are logged in to the control node as a user who can run playbooks on the managed nodes.
-
The account you use to connect to the managed nodes has
sudopermissions on them.
Procedure
Create a playbook file, for example
~/playbook.yml, with the following content:--- - name: Run the snapshot system role hosts: managed-node-01.example.com vars: snapshot_lvm_set: name: snapset1 volumes: - name: data1 snapshot vg: data_vg lv: data1 percent_space_required: 25 mountpoint: /data1_snapshot options: nouuid mountpoint_create: true - name: data2 snapshot vg: data_vg lv: data2 percent_space_required: 25 mountpoint: /data2_snapshot options: nouuid mountpoint_create: true tasks: - name: Create a snapshot set ansible.builtin.include_role: name: redhat.rhel_system_roles.snapshot vars: snapshot_lvm_action: snapshot - name: Verify the set of snapshots for the LVs ansible.builtin.include_role: name: redhat.rhel_system_roles.snapshot vars: snapshot_lvm_action: check snapshot_lvm_verify_only: true - name: Mount the snapshot set ansible.builtin.include_role: name: redhat.rhel_system_roles.snapshot vars: snapshot_lvm_action: mountHere, the
snapshot_lvm_setparameter describes specific logical volumes (LV) from the same volume group (VG). You can also specify LVs from different VGs while setting this parameter.Validate the playbook syntax:
$ ansible-playbook --syntax-check ~/playbook.ymlNote that this command only validates the syntax and does not protect against a wrong but valid configuration.
Run the playbook:
$ ansible-playbook ~/playbook.yml
Verification
On the managed node, view the created snapshots:
# lvs LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert data1 data_vg owi-a-s--- 1.00g data1_snapset1 data_vg swi-a-s--- 208.00m data1 0.00 data2 data_vg owi-a-s--- 1.00g data2_snapset1 data_vg swi-a-s--- 208.00m data2 0.00On the managed node, verify if the mount operation was successful by checking the existence of /data1_snapshot and /data2_snapshot:
# ls -al /data1_snapshot # ls -al /data2_snapshot
67.8.5. Unmounting LVM snapshots using the snapshot RHEL System Role
You can unmount a specific snapshot or all snapshots by setting the snapshot_lvm_action parameter to umount.
Prerequisites
- You have prepared the control node and the managed nodes
- You are logged in to the control node as a user who can run playbooks on the managed nodes.
-
The account you use to connect to the managed nodes has
sudopermissions on them. - You have created snapshots using the name <_snapset1_> for the set of snapshots.
-
You have mounted the snapshots by setting
snapshot_lvm_actiontomountor otherwise mounted them manually.
Procedure
Create a playbook file, for example
~/playbook.yml, with the following content:Unmount a specific LVM snapshot:
--- - name: Unmount the snapshot specified by the snapset hosts: managed-node-01.example.com vars: snapshot_lvm_snapset_name: snapset1 snapshot_lvm_action: umount snapshot_lvm_vg: data_vg snapshot_lvm_lv: data2 snapshot_lvm_mountpoint: /data2_snapshot roles: - rhel-system-roles.snapshotHere, the
snapshot_lvm_lvparameter describes a specific logical volume (LV) and thesnapshot_lvm_vgparameter describes a specific volume group (VG).Unmount a set of LVM snapshots:
--- - name: Unmount a set of snapshots hosts: managed-node-01.example.com vars: snapshot_lvm_action: umount snapshot_lvm_set: name: snapset1 volumes: - name: data1 snapshot vg: data_vg lv: data1 mountpoint: /data1_snapshot - name: data2 snapshot vg: data_vg lv: data2 mountpoint: /data2_snapshot roles: - rhel-system-roles.snapshotHere, the
snapshot_lvm_setparameter describes specific LVs from the same VG. You can also specify LVs from different VGs while setting this parameter.
Validate the playbook syntax:
$ ansible-playbook --syntax-check ~/playbook.ymlNote that this command only validates the syntax and does not protect against a wrong but valid configuration.
Run the playbook:
$ ansible-playbook ~/playbook.yml
67.8.6. Extending LVM snapshots using the snapshot RHEL System Role
With the new snapshot RHEL system role, you can now extend LVM snapshots by setting the snapshot_lvm_action parameter to extend. You can set the snapshot_lvm_percent_space_required parameter to the required space that should be allocated to the snapshot after extending it.
Prerequisites
- You have prepared the control node and the managed nodes
- You are logged in to the control node as a user who can run playbooks on the managed nodes.
-
The account you use to connect to the managed nodes has
sudopermissions on them. - You have created snapshots for the given volume groups and logical volumes.
Procedure
Create a playbook file, for example
~/playbook.yml, with the following content:Extend all LVM snapshots by specifying the value for the
percent_space_requiredparameter:--- - name: Extend all snapshots hosts: managed-node-01.example.com vars: snapshot_lvm_action: extend snapshot_lvm_set: name: snapset1 volumes: - name: data1 snapshot vg: data_vg lv: data1 percent_space_required: 40 - name: data2 snapshot vg: data_vg lv: data2 percent_space_required: 40 roles: - rhel-system-roles.snapshotHere, the
snapshot_lvm_setparameter describes specific LVs from the same VG. You can also specify LVs from different VGs while setting this parameter.Extend a LVM snapshot set by setting
percent_space_requiredto different value for each VG and LV pair in a set:--- - name: Extend the snapshot hosts: managed-node-01.example.com vars: snapshot_extend_set: name: snapset1 volumes: - name: data1 snapshot vg: data_vg lv: data1 percent_space_required: 30 - name: data2 snapshot vg: data_vg lv: data2 percent_space_required: 40 tasks: - name: Extend data1 to 30% and data2 to 40% vars: snapshot_lvm_set: "{{ snapshot_extend_set }}" snapshot_lvm_action: extend ansible.builtin.include_role: name: redhat.rhel_system_roles.snapshot
Validate the playbook syntax:
$ ansible-playbook --syntax-check ~/playbook.ymlNote that this command only validates the syntax and does not protect against a wrong but valid configuration.
Run the playbook:
$ ansible-playbook ~/playbook.yml
Verification
On the managed node, view the extended snapshot by 30%:
# lvs LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert data1 data_vg owi-a-s--- 1.00g data1_snapset1 data_vg swi-a-s--- 308.00m data1 0.00 data2 data_vg owi-a-s--- 1.00g data2_snapset1 data_vg1 swi-a-s--- 408.00m data2 0.00
67.8.7. Reverting LVM snapshots using the snapshot RHEL System Role
With the new snapshot RHEL system role, you can now revert LVM snapshots to its original volume by setting the snapshot_lvm_action parameter to revert.
If both the logical volume and snapshot volume are not open and active, the revert operation starts immediately. Otherwise, it starts either after the origin or snapshot are activated and both are closed.
Prerequisites
- You have prepared the control node and the managed nodes
- You are logged in to the control node as a user who can run playbooks on the managed nodes.
-
The account you use to connect to the managed nodes has
sudopermissions on them. - You have created snapshots for the given volume groups and logical volumes by using <_snapset1_> as the snapset name.
Procedure
Create a playbook file, for example
~/playbook.yml, with the following content:Revert a specific LVM snapshot to its original volume:
--- - name: Revert a snapshot to its original volume hosts: managed-node-01.example.com vars: snapshot_lvm_snapset_name: snapset1 snapshot_lvm_action: revert snapshot_lvm_vg: data_vg snapshot_lvm_lv: data2 roles: - rhel-system-roles.snapshotHere, the
snapshot_lvm_lvparameter describes a specific logical volume (LV) and thesnapshot_lvm_vgparameter describes a specific volume group (VG).Revert a set of LVM snapshots to its original volume:
--- - name: Revert a set of snapshot hosts: managed-node-01.example.com vars: snapshot_lvm_action: revert snapshot_lvm_set: name: snapset1 volumes: - name: data1 snapshot vg: data_vg lv: data1 - name: data2 snapshot vg: data_vg lv: data2 roles: - rhel-system-roles.snapshotHere, the
snapshot_lvm_setparameter describes specific LVs from the same VG. You can also specify LVs from different VGs while setting this parameter.NoteThe
revertoperation might take some time to complete.
Validate the playbook syntax:
$ ansible-playbook --syntax-check ~/playbook.ymlNote that this command only validates the syntax and does not protect against a wrong but valid configuration.
Run the playbook:
$ ansible-playbook ~/playbook.ymlReboot the host, or deactivate and reactivate the logical volume using the following steps:
$ umount /data1; umount /data2 $ lvchange -an data_vg/data1 data_vg/data2 $ lvchange -ay data_vg/data1 data_vg/data2 $ mount /data1; mount /data2
Verification
On the managed node, view the reverted snapshots:
# lvs LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert data1 data_vg -wi-a----- 1.00g data2 data_vg -wi-a----- 1.00g
67.8.8. Removing LVM snapshots using the snapshot RHEL System Role
With the new snapshot RHEL system role, you can now remove all LVM snapshots by specifying the prefix or pattern of the snapshot, and by setting the snapshot_lvm_action parameter to remove.
Prerequisites
- You have prepared the control node and the managed nodes
- You are logged in to the control node as a user who can run playbooks on the managed nodes.
-
The account you use to connect to the managed nodes has
sudopermissions on them. - You have created the specified snapshots by using <_snapset1_> as the snapset name.
Procedure
Create a playbook file, for example
~/playbook.yml, with the following content:Remove a specific LVM snapshot:
--- - name: Remove a snapshot hosts: managed-node-01.example.com vars: snapshot_lvm_snapset_name: snapset1 snapshot_lvm_action: remove snapshot_lvm_vg: data_vg roles: - rhel-system-roles.snapshotHere, the
snapshot_lvm_vgparameter describes a specific logical volume (LV) from the volume group (VG).Remove a set of LVM snapshots:
--- - name: Remove a set of snapshots hosts: managed-node-01.example.com vars: snapshot_lvm_action: remove snapshot_lvm_set: name: snapset1 volumes: - name: data1 snapshot vg: data_vg lv: data1 - name: data2 snapshot vg: data_vg lv: data2 roles: - rhel-system-roles.snapshotHere, the
snapshot_lvm_setparameter describes specific LVs from the same VG. You can also specify LVs from different VGs while setting this parameter.
Validate the playbook syntax:
$ ansible-playbook --syntax-check ~/playbook.ymlNote that this command only validates the syntax and does not protect against a wrong but valid configuration.
Run the playbook:
$ ansible-playbook ~/playbook.yml
67.9. Creating and managing thin-provisioned volumes (thin volumes)
Red Hat Enterprise Linux supports thin-provisioned snapshot volumes and logical volumes:
- Using thin-provisioned logical volumes, you can create logical volumes that are larger than the available physical storage.
- Using thin-provisioned snapshot volumes, you can store more virtual devices on the same data volume.
67.9.1. Overview of thin provisioning
Many modern storage stacks now provide the ability to choose between thick provisioning and thin provisioning:
- Thick provisioning provides the traditional behavior of block storage where blocks are allocated regardless of their actual usage.
- Thin provisioning grants the ability to provision a larger pool of block storage that may be larger in size than the physical device storing the data, resulting in over-provisioning. Over-provisioning is possible because individual blocks are not allocated until they are actually used. If you have multiple thin-provisioned devices that share the same pool, then these devices can be over-provisioned.
By using thin provisioning, you can over-commit the physical storage, and instead can manage a pool of free space known as a thin pool. You can allocate this thin pool to an arbitrary number of devices when needed by applications. You can expand the thin pool dynamically when needed for cost-effective allocation of storage space.
For example, if ten users each request a 100GB file system for their application, then you can create what appears to be a 100GB file system for each user but which is backed by less actual storage that is used only when needed.
When using thin provisioning, it is important that you monitor the storage pool and add more capacity as the available physical space runs out.
The following are a few advantages of using thin-provisioned devices:
- You can create logical volumes that are larger than the available physical storage.
- You can have more virtual devices to be stored on the same data volume.
- You can create file systems that can grow logically and automatically to support the data requirements and the unused blocks are returned to the pool for use by any file system in the pool
The following are the potential drawbacks of using thin-provisioned devices:
- Thin-provisioned volumes have an inherent risk of running out of available physical storage. If you have over-provisioned your underlying storage, it could possibly result in an outage due to the lack of available physical storage. For example, if you create 10T of thinly provisioned storage with only 1T physical storage for backing, the volumes will become unavailable or unwritable after the 1T is exhausted.
-
If volumes are not sending discards to the layers after thin-provisioned devices, then the accounting for usage will not be accurate. For example, placing a file system without the
-o discard mountoption and not runningfstrimperiodically on top of thin-provisioned devices will never unallocate previously used storage. In such cases, you end up using the full provisioned amount over time even if you are not really using it. - You must monitor the logical and physical usage so as to not run out of available physical space.
- Copy on Write (CoW) operation can be slower on file systems with snapshots.
- Data blocks can be intermixed between multiple file systems leading to random access limitations of the underlying storage even when it does not appear that way to the end user.
67.9.2. Creating thinly-provisioned logical volumes
Using thin-provisioned logical volumes, you can create logical volumes that are larger than the available physical storage. Creating a thinly provisioned set of volumes allows the system to allocate what you use instead of allocating the full amount of storage that is requested.
Using the -T or --thin option of the lvcreate command, you can create either a thin pool or a thin volume. You can also use the -T option of the lvcreate command to create both a thin pool and a thin volume at the same time with a single command. This procedure describes how to create and grow thinly-provisioned logical volumes.
Prerequisites
- You have created a volume group. For more information, see Creating LVM volume group.
Procedure
Create a thin pool:
# lvcreate -L 100M -T vg001/mythinpool Thin pool volume with chunk size 64.00 KiB can address at most 15.81 TiB of data. Logical volume "mythinpool" created.Note that since you are creating a pool of physical space, you must specify the size of the pool. The
-Toption of thelvcreatecommand does not take an argument; it determines what type of device is to be created from the other options that are added with the command. You can also create thin pool using additional parameters as shown in the following examples:You can also create a thin pool using the
--thinpoolparameter of thelvcreatecommand. Unlike the-Toption, the--thinpoolparameter requires that you specify the name of the thin pool logical volume you are creating. The following example uses the--thinpoolparameter to create a thin pool named mythinpool in the volume group vg001 that is 100M in size:# lvcreate -L 100M --thinpool mythinpool vg001 Thin pool volume with chunk size 64.00 KiB can address at most 15.81 TiB of data. Logical volume "mythinpool" created.As striping is supported for pool creation, you can use the
-iand-Ioptions to create stripes. The following command creates a 100M thin pool named as thinpool in volume group vg001 with two 64 kB stripes and a chunk size of 256 kB. It also creates a 1T thin volume named vg001/thinvolume.NoteEnsure that there are two physical volumes with sufficient free space in the volume group or you cannot create the thin pool.
# lvcreate -i 2 -I 64 -c 256 -L 100M -T vg001/thinpool -V 1T --name thinvolume
Create a thin volume:
# lvcreate -V 1G -T vg001/mythinpool -n thinvolume WARNING: Sum of all thin volume sizes (1.00 GiB) exceeds the size of thin pool vg001/mythinpool (100.00 MiB). WARNING: You have not turned on protection against thin pools running out of space. WARNING: Set activation/thin_pool_autoextend_threshold below 100 to trigger automatic extension of thin pools before they get full. Logical volume "thinvolume" created.In this case, you are specifying virtual size for the volume that is greater than the pool that contains it. You can also create thin volumes using additional parameters as shown in the following examples:
To create both a thin volume and a thin pool, use the
-Toption of thelvcreatecommand and specify both the size and virtual size argument:# lvcreate -L 100M -T vg001/mythinpool -V 1G -n thinvolume Thin pool volume with chunk size 64.00 KiB can address at most 15.81 TiB of data. WARNING: Sum of all thin volume sizes (1.00 GiB) exceeds the size of thin pool vg001/mythinpool (100.00 MiB). WARNING: You have not turned on protection against thin pools running out of space. WARNING: Set activation/thin_pool_autoextend_threshold below 100 to trigger automatic extension of thin pools before they get full. Logical volume "thinvolume" created.To use the remaining free space to create a thin volume and thin pool, use the
100%FREEoption:# lvcreate -V 1G -l 100%FREE -T vg001/mythinpool -n thinvolume Thin pool volume with chunk size 64.00 KiB can address at most <15.88 TiB of data. Logical volume "thinvolume" created.To convert an existing logical volume to a thin pool volume, use the
--thinpoolparameter of thelvconvertcommand. You must also use the--poolmetadataparameter in conjunction with the--thinpoolparameter to convert an existing logical volume to a thin pool volume’s metadata volume.The following example converts the existing logical volume lv1 in volume group vg001 to a thin pool volume and converts the existing logical volume lv2 in volume group vg001 to the metadata volume for that thin pool volume:
# lvconvert --thinpool vg001/lv1 --poolmetadata vg001/lv2 Converted vg001/lv1 to thin pool.NoteConverting a logical volume to a thin pool volume or a thin pool metadata volume destroys the content of the logical volume, as
lvconvertdoes not preserve the content of the devices but instead overwrites the content.By default, the
lvcreatecommand approximately sets the size of the thin pool metadata logical volume by using the following formula:Pool_LV_size / Pool_LV_chunk_size * 64If you have large numbers of snapshots or if you have have small chunk sizes for your thin pool and therefore expect significant growth of the size of the thin pool at a later time, you may need to increase the default value of the thin pool’s metadata volume using the
--poolmetadatasizeparameter of thelvcreatecommand. The supported value for the thin pool’s metadata logical volume is in the range between 2MiB and 16GiB.The following example illustrates how to increase the default value of the thin pools’ metadata volume:
# lvcreate -V 1G -l 100%FREE -T vg001/mythinpool --poolmetadatasize 16M -n thinvolume Thin pool volume with chunk size 64.00 KiB can address at most 15.81 TiB of data. Logical volume "thinvolume" created.
View the created thin pool and thin volume:
# lvs -a -o +devices LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert Devices [lvol0_pmspare] vg001 ewi------- 4.00m /dev/sda(0) mythinpool vg001 twi-aotz-- 100.00m 0.00 10.94 mythinpool_tdata(0) [mythinpool_tdata] vg001 Twi-ao---- 100.00m /dev/sda(1) [mythinpool_tmeta] vg001 ewi-ao---- 4.00m /dev/sda(26) thinvolume vg001 Vwi-a-tz-- 1.00g mythinpool 0.00Optional: Extend the size of a thin pool with the
lvextendcommand. You cannot, however, reduce the size of a thin pool.NoteThis command fails if you use
-l 100%FREEargument while creating a thin pool and thin volume.The following command resizes an existing thin pool that is 100M in size by extending it another 100M:
# lvextend -L+100M vg001/mythinpool Size of logical volume vg001/mythinpool_tdata changed from 100.00 MiB (25 extents) to 200.00 MiB (50 extents). WARNING: Sum of all thin volume sizes (1.00 GiB) exceeds the size of thin pool vg001/mythinpool (200.00 MiB). WARNING: You have not turned on protection against thin pools running out of space. WARNING: Set activation/thin_pool_autoextend_threshold below 100 to trigger automatic extension of thin pools before they get full. Logical volume vg001/mythinpool successfully resized# lvs -a -o +devices LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert Devices [lvol0_pmspare] vg001 ewi------- 4.00m /dev/sda(0) mythinpool vg001 twi-aotz-- 200.00m 0.00 10.94 mythinpool_tdata(0) [mythinpool_tdata] vg001 Twi-ao---- 200.00m /dev/sda(1) [mythinpool_tdata] vg001 Twi-ao---- 200.00m /dev/sda(27) [mythinpool_tmeta] vg001 ewi-ao---- 4.00m /dev/sda(26) thinvolume vg001 Vwi-a-tz-- 1.00g mythinpool 0.00Optional: To rename the thin pool and thin volume, use the following command:
# lvrename vg001/mythinpool vg001/mythinpool1 Renamed "mythinpool" to "mythinpool1" in volume group "vg001" # lvrename vg001/thinvolume vg001/thinvolume1 Renamed "thinvolume" to "thinvolume1" in volume group "vg001"View the thin pool and thin volume after renaming:
# lvs LV VG Attr LSize Pool Origin Data% Move Log Copy% Convert mythinpool1 vg001 twi-a-tz 100.00m 0.00 thinvolume1 vg001 Vwi-a-tz 1.00g mythinpool1 0.00Optional: To remove the thin pool, use the following command:
# lvremove -f vg001/mythinpool1 Logical volume "thinvolume1" successfully removed. Logical volume "mythinpool1" successfully removed.
67.9.3. Creating pools for thinly provisioned volumes in the web console
Create a pool for thinly-provisioned volumes.
Prerequisites
- You have installed the RHEL 8 web console.
- You have enabled the cockpit service.
Your user account is allowed to log in to the web console.
For instructions, see Installing and enabling the web console.
-
The
cockpit-storagedpackage is installed on your system. - A volume group is created.
Procedure
Log in to the RHEL 8 web console.
For details, see Logging in to the web console.
- Click Storage.
- In the Storage table, click the volume group in which you want to create thin volumes.
- On the Logical volume group page, scroll to the LVM2 logical volumes section and click .
- In the Name field, enter a name for the new logical volume. Do not include spaces in the name.
In the drop-down menu, select Pool for thinly provisioned volumes.
This configuration enables you to create a logical volume with the maximum volume size which is equal to the sum of the capacities of all drives included in the volume group.
Define the size of the logical volume. Consider:
- How much space the system using this logical volume needs.
- How many logical volumes you want to create.
You do not have to use the whole space. If necessary, you can grow the logical volume later.
Click .
The pool for thin volumes is created and you can now add thin volumes to the pool.
67.9.4. Creating thinly provisioned logical volumes in the web console
You can use the web console to create a thin-provisioned logical volume in the pool. The pool can include multiple thin volumes and each thin volume can be as large as the pool for thin volumes itself.
Using thin volumes requires regular checkup of the actual free physical space of the logical volume.
Prerequisites
- You have installed the RHEL 8 web console.
- You have enabled the cockpit service.
Your user account is allowed to log in to the web console.
For instructions, see Installing and enabling the web console.
-
The
cockpit-storagedpackage is installed on your system. - A pool for thin volumes created.
Procedure
Log in to the RHEL 8 web console.
For details, see Logging in to the web console.
- Click Storage.
- In the Storage table, click the menu button volume group in which you want to create thin volumes.
- On the Logical volume group page, scroll to the LVM2 logical volumes section and click the pool in which you want to create the thin logical volumes.
- On the Pool for thinly provisioned LVM2 logical volumes page, scroll to the Thinly provisioned LVM2 logical volumes section and click Create new thinly provisioned logical volume.
- In the Create thin volume dialog box, enter a name for the thin volume. Do not use spaces in the name.
- Define the size of the thin volume.
Click Create.
The thin logical volume is created. You must format the volume before you can use it.
67.9.5. Overview of chunk size
A chunk is the largest unit of physical disk dedicated to snapshot storage.
Use the following criteria for using the chunk size:
- A smaller chunk size requires more metadata and hinders performance, but provides better space utilization with snapshots.
- A bigger chunk size requires less metadata manipulation, but makes the snapshot less space efficient.
Be default, lvm2 starts with a 64KiB chunk size and estimates good metadata size for such chunk size. The minimal metadata size lvm2 can create and use is 2 MiB. If the metadata size needs to be larger than 128 MiB it begins to increase the chunk size, so the metadata size stays compact. However, this may result in some big chunk size values, which are less space efficient for snapshot usage. In such cases, a smaller chunk size and bigger metadata size is a better option.
To specify the chunk size according to your requirement, use the -c or --chunksize parameter to overrule lvm2 estimated chunk size. Be aware that you cannot change the chunk size once the thinpool is created.
If the volume data size is in the range of TiB, use ~15.8GiB as the metadata size, which is the maximum supported size, and set the chunk size according to your requirement. But, note that it is not possible to increase the metadata size if you need to extend the volume’s data size and have a small chunk size.
Using the inappropriate combination of chunk size and metadata size may result in potentially problematic situation, when user runs out of space in metadata or they may not further grow their thin-pool size because of limited maximum addressable thin-pool data size.
67.9.6. Thinly-provisioned snapshot volumes
Red Hat Enterprise Linux supports thinly-provisioned snapshot volumes. A snapshot of a thin logical volume also creates a thin logical volume (LV). A thin snapshot volume has the same characteristics as any other thin volume. You can independently activate the volume, extend the volume, rename the volume, remove the volume, and even snapshot the volume.
Similarly to all LVM snapshot volumes, and all thin volumes, thin snapshot volumes are not supported across the nodes in a cluster. The snapshot volume must be exclusively activated on only one cluster node.
Traditional snapshots must allocate new space for each snapshot created, where data is preserved as changes are made to the origin. But thin-provisioning snapshots share the same space with the origin. Snapshots of thin LVs are efficient because the data blocks common to a thin LV and any of its snapshots are shared. You can create snapshots of thin LVs or from the other thin snapshots. Blocks common to recursive snapshots are also shared in the thin pool.
Thin snapshot volumes provide the following benefits:
- Increasing the number of snapshots of the origin has a negligible impact on performance.
- A thin snapshot volume can reduce disk usage because only the new data is written and is not copied to each snapshot.
- There is no need to simultaneously activate the thin snapshot volume with the origin, which is a requirement of traditional snapshots.
- When restoring an origin from a snapshot, it is not required to merge the thin snapshot. You can remove the origin and instead use the snapshot. Traditional snapshots have a separate volume where they store changes that must be copied back, that is, merged to the origin to reset it.
- There is a significantly higher limit on the number of allowed snapshots as compared to the traditional snapshots.
Although there are many advantages for using thin snapshot volumes, there are some use cases for which the traditional LVM snapshot volume feature might be more appropriate to your needs. You can use traditional snapshots with all types of volumes. However, to use thin-snapshots requires you to use thin-provisioning.
You cannot limit the size of a thin snapshot volume; the snapshot uses all of the space in the thin pool, if necessary. In general, you should consider the specific requirements of your site when deciding which snapshot format to use.
By default, a thin snapshot volume is skipped during normal activation commands.
67.9.7. Creating thinly-provisioned snapshot volumes
Using thin-provisioned snapshot volumes, you can have more virtual devices stored on the same data volume.
When creating a thin snapshot volume, do not specify the size of the volume. If you specify a size parameter, the snapshot that will be created will not be a thin snapshot volume and will not use the thin pool for storing data. For example, the command lvcreate -s vg/thinvolume -L10M will not create a thin snapshot, even though the origin volume is a thin volume.
Thin snapshots can be created for thinly-provisioned origin volumes, or for origin volumes that are not thinly-provisioned. The following procedure describes different ways to create a thinly-provisioned snapshot volume.
Prerequisites
- You have created a thinly-provisioned logical volume. For more information, see Overview of thin provisioning.
Procedure
Create a thinly-provisioned snapshot volume. The following command creates a thinly-provisioned snapshot volume named as mysnapshot1 of the thinly-provisioned logical volume vg001/thinvolume:
# lvcreate -s --name mysnapshot1 vg001/thinvolume Logical volume "mysnapshot1" created# lvs LV VG Attr LSize Pool Origin Data% Move Log Copy% Convert mysnapshot1 vg001 Vwi-a-tz 1.00g mythinpool thinvolume 0.00 mythinpool vg001 twi-a-tz 100.00m 0.00 thinvolume vg001 Vwi-a-tz 1.00g mythinpool 0.00NoteWhen using thin provisioning, it is important that the storage administrator monitor the storage pool and add more capacity if it starts to become full. For information about extending the size of a thin volume, see Creating thinly-provisioned logical volumes .
You can also create a thinly-provisioned snapshot of a non-thinly-provisioned logical volume. Since the non-thinly-provisioned logical volume is not contained within a thin pool, it is referred to as an external origin. External origin volumes can be used and shared by many thinly-provisioned snapshot volumes, even from different thin pools. The external origin must be inactive and read-only at the time the thinly-provisioned snapshot is created.
The following example creates a thin snapshot volume of the read-only, inactive logical volume named origin_volume. The thin snapshot volume is named mythinsnap. The logical volume origin_volume then becomes the thin external origin for the thin snapshot volume mythinsnap in volume group vg001 that uses the existing thin pool vg001/pool. The origin volume must be in the same volume group as the snapshot volume. Do not specify the volume group when specifying the origin logical volume.
# lvcreate -s --thinpool vg001/pool origin_volume --name mythinsnapYou can create a second thinly-provisioned snapshot volume of the first snapshot volume by executing the following command.
# lvcreate -s vg001/mysnapshot1 --name mysnapshot2 Logical volume "mysnapshot2" created.To create a third thinly-provisioned snapshot volume, use the following command:
# lvcreate -s vg001/mysnapshot2 --name mysnapshot3 Logical volume "mysnapshot3" created.
Verification
Display a list of all ancestors and descendants of a thin snapshot logical volume:
$ lvs -o name,lv_ancestors,lv_descendants vg001 LV Ancestors Descendants mysnapshot2 mysnapshot1,thinvolume mysnapshot3 mysnapshot1 thinvolume mysnapshot2,mysnapshot3 mysnapshot3 mysnapshot2,mysnapshot1,thinvolume mythinpool thinvolume mysnapshot1,mysnapshot2,mysnapshot3Here,
- thinvolume is an origin volume in volume group vg001.
- mysnapshot1 is a snapshot of thinvolume
- mysnapshot2 is a snapshot of mysnapshot1
mysnapshot3 is a snapshot of mysnapshot2
NoteThe
lv_ancestorsandlv_descendantsfields display existing dependencies. However, they do not track removed entries which can break a dependency chain if the entry was removed from the middle of the chain.
67.9.8. Creating thinly-provisioned snapshot volumes with the web console
You can create snapshots of thin logical volumes in the RHEL web console to backup changes recorded on the disk from the last snapshot.
Prerequisites
- You have installed the RHEL 8 web console.
- You have enabled the cockpit service.
Your user account is allowed to log in to the web console.
For instructions, see Installing and enabling the web console.
-
The
cockpit-storagedpackage is installed on your system. - A thin-provisioned volume is created.
Procedure
- Log in to the RHEL 8 web console.
- Click Storage.
- In the Storage table, click the volume group in which you want to create thin volumes.
- On the Logical volume group page, scroll to the LVM2 logical volumes section and click the pool in which you want to create the thin logical volumes.
- On the Pool for thinly provisioned LVM2 logical volumes page, scroll to the Thinly provisioned LVM2 logical volumes section and click the menu button, , next to the logical volume.
From the drop-down menu, select Create snapshot.

In the Name field, enter a snapshot name.

- Click .
- On the Pool for thinly provisioned LVM2 logical volumes page, scroll to the Thinly provisioned LVM2 logical volumes section and click the menu button, , next to the newly created snapshot.
From the drop-down menu, select Activate to activate the volume.

67.10. Enabling caching to improve logical volume performance
You can add caching to an LVM logical volume to improve performance. LVM then caches I/O operations to the logical volume using a fast device, such as an SSD.
The following procedures create a special LV from the fast device, and attach this special LV to the original LV to improve the performance.
67.10.1. Caching methods in LVM
LVM provides the following kinds of caching. Each one is suitable for different kinds of I/O patterns on the logical volume.
dm-cacheThis method speeds up access to frequently used data by caching it on the faster volume. The method caches both read and write operations.
The
dm-cachemethod creates logical volumes of the typecache.dm-writecacheThis method caches only write operations. The faster volume stores the write operations and then migrates them to the slower disk in the background. The faster volume is usually an SSD or a persistent memory (PMEM) disk.
The
dm-writecachemethod creates logical volumes of the typewritecache.
67.10.2. LVM caching components
LVM provides support for adding a cache to LVM logical volumes. LVM caching uses the following LVM logical volume types:
- Main LV
- The larger, slower, and original volume.
- Cache pool LV
-
A composite LV that you can use for caching data from the main LV. It has two sub-LVs: data for holding cache data and metadata for managing the cache data. You can configure specific disks for data and metadata. You can use the cache pool only with
dm-cache. - Cachevol LV
-
A linear LV that you can use for caching data from the main LV. You cannot configure separate disks for data and metadata.
cachevolcan be only used with eitherdm-cacheordm-writecache.
All of these associated LVs must be in the same volume group.
You can combine a main logical volume (LV) with a faster, usually smaller, LV that holds the cached data. The fast LV is created from fast block devices, such as SSD drives. When you enable caching for a logical volume, LVM renames and hides the original volumes, and presents a new logical volume that is composed of the original logical volumes. The composition of the new logical volume depends on the caching method and whether you are using the cachevol or cachepool option.
The cachevol and cachepool options expose different levels of control over the placement of the caching components:
-
With the
cachevoloption, the faster device stores both the cached copies of data blocks and the metadata for managing the cache. With the
cachepooloption, separate devices can store the cached copies of data blocks and the metadata for managing the cache.The
dm-writecachemethod is not compatible withcachepool.
In all configurations, LVM exposes a single resulting device, which groups together all the caching components. The resulting device has the same name as the original slow logical volume.
67.10.3. Enabling dm-cache caching for a logical volume
This procedure enables caching of commonly used data on a logical volume using the dm-cache method.
Prerequisites
-
A slow logical volume that you want to speed up using
dm-cacheexists on your system. - The volume group that contains the slow logical volume also contains an unused physical volume on a fast block device.
Procedure
Create a
cachevolvolume on the fast device:# lvcreate --size cachevol-size --name <fastvol> <vg> </dev/fast-pv>Replace the following values:
cachevol-size-
The size of the
cachevolvolume, such as5G fastvol-
A name for the
cachevolvolume vg- The volume group name
/dev/fast-pvThe path to the fast block device, such as
/dev/sdfExample 67.3. Creating a
cachevolvolume# lvcreate --size 5G --name fastvol vg /dev/sdf Logical volume "fastvol" created.
Attach the
cachevolvolume to the main logical volume to begin caching:# lvconvert --type cache --cachevol <fastvol> <vg/main-lv>Replace the following values:
fastvol-
The name of the
cachevolvolume vg- The volume group name
main-lvThe name of the slow logical volume
Example 67.4. Attaching the
cachevolvolume to the main LV# lvconvert --type cache --cachevol fastvol vg/main-lv Erase all existing data on vg/fastvol? [y/n]: y Logical volume vg/main-lv is now cached.
Verification
Verify if the newly created logical volume has
dm-cacheenabled:# lvs --all --options +devices <vg> LV Pool Type Devices main-lv [fastvol_cvol] cache main-lv_corig(0) [fastvol_cvol] linear /dev/fast-pv [main-lv_corig] linear /dev/slow-pv
67.10.4. Enabling dm-cache caching with a cachepool for a logical volume
This procedure enables you to create the cache data and the cache metadata logical volumes individually and then combine the volumes into a cache pool.
Prerequisites
-
A slow logical volume that you want to speed up using
dm-cacheexists on your system. - The volume group that contains the slow logical volume also contains an unused physical volume on a fast block device.
Procedure
Create a
cachepoolvolume on the fast device:# lvcreate --type cache-pool --size <cachepool-size> --name <fastpool> <vg /dev/fast>Replace the following values:
cachepool-size-
The size of the
cachepool, such as5G fastpool-
A name for the
cachepoolvolume vg- The volume group name
/dev/fastThe path to the fast block device, such as
/dev/sdf1NoteYou can use
--poolmetadataoption to specify the location of the pool metadata when creating the cache-pool.Example 67.5. Creating a
cachepoolvolume# lvcreate --type cache-pool --size 5G --name fastpool vg /dev/sde Logical volume "fastpool" created.
Attach the
cachepoolto the main logical volume to begin caching:# lvconvert --type cache --cachepool <fastpool> <vg/main>Replace the following values:
fastpool-
The name of the
cachepoolvolume vg- The volume group name
mainThe name of the slow logical volume
Example 67.6. Attaching the
cachepoolto the main LV# lvconvert --type cache --cachepool fastpool vg/main Do you want wipe existing metadata of cache pool vg/fastpool? [y/n]: y Logical volume vg/main is now cached.
Verification
Examine the newly created devicevolume with the
cache-pooltype:# lvs --all --options +devices <vg> LV Pool Type Devices [fastpool_cpool] cache-pool fastpool_pool_cdata(0) [fastpool_cpool_cdata] linear /dev/sdf1(4) [fastpool_cpool_cmeta] linear /dev/sdf1(2) [lvol0_pmspare] linear /dev/sdf1(0) main [fastpoool_cpool] cache main_corig(0) [main_corig] linear /dev/sdf1(O)
67.10.5. Enabling dm-writecache caching for a logical volume
This procedure enables caching of write I/O operations to a logical volume using the dm-writecache method.
Prerequisites
-
A slow logical volume that you want to speed up using
dm-writecacheexists on your system. - The volume group that contains the slow logical volume also contains an unused physical volume on a fast block device.
- If the slow logical volume is active, deactivate it.
Procedure
If the slow logical volume is active, deactivate it:
# lvchange --activate n <vg>/<main-lv>Replace the following values:
vg- The volume group name
main-lv- The name of the slow logical volume
Create a deactivated
cachevolvolume on the fast device:# lvcreate --activate n --size <cachevol-size> --name <fastvol> <vg> </dev/fast-pv>Replace the following values:
cachevol-size-
The size of the
cachevolvolume, such as5G fastvol-
A name for the
cachevolvolume vg- The volume group name
/dev/fast-pvThe path to the fast block device, such as
/dev/sdfExample 67.7. Creating a deactivated
cachevolvolume# lvcreate --activate n --size 5G --name fastvol vg /dev/sdf WARNING: Logical volume vg/fastvol not zeroed. Logical volume "fastvol" created.
Attach the
cachevolvolume to the main logical volume to begin caching:# lvconvert --type writecache --cachevol <fastvol> <vg/main-lv>Replace the following values:
fastvol-
The name of the
cachevolvolume vg- The volume group name
main-lvThe name of the slow logical volume
Example 67.8. Attaching the
cachevolvolume to the main LV# lvconvert --type writecache --cachevol fastvol vg/main-lv Erase all existing data on vg/fastvol? [y/n]?: y Using writecache block size 4096 for unknown file system block size, logical block size 512, physical block size 512. WARNING: unable to detect a file system block size on vg/main-lv WARNING: using a writecache block size larger than the file system block size may corrupt the file system. Use writecache block size 4096? [y/n]: y Logical volume vg/main-lv now has writecache.
Activate the resulting logical volume:
# lvchange --activate y <vg/main-lv>Replace the following values:
vg- The volume group name
main-lv- The name of the slow logical volume
Verification
Examine the newly created devices:
# lvs --all --options +devices vg LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert Devices main-lv vg Cwi-a-C--- 500.00m [fastvol_cvol] [main-lv_wcorig] 0.00 main-lv_wcorig(0) [fastvol_cvol] vg Cwi-aoC--- 252.00m /dev/sdc1(0) [main-lv_wcorig] vg owi-aoC--- 500.00m /dev/sdb1(0)
67.10.6. Disabling caching for a logical volume
This procedure disables dm-cache or dm-writecache caching that is currently enabled on a logical volume.
Prerequisites
- Caching is enabled on a logical volume.
Procedure
Deactivate the logical volume:
# lvchange --activate n <vg>/<main-lv>Replace vg with the volume group name, and main-lv with the name of the logical volume where caching is enabled.
Detach the
cachevolorcachepoolvolume:# lvconvert --splitcache <vg>/<main-lv>Replace the following values:
Replace vg with the volume group name, and main-lv with the name of the logical volume where caching is enabled.
Example 67.9. Detaching the
cachevolorcachepoolvolume# lvconvert --splitcache vg/main-lv Detaching writecache already clean. Logical volume vg/main-lv writecache has been detached.
Verification
Check that the logical volumes are no longer attached together:
# lvs --all --options +devices <vg> LV Attr Type Devices fastvol -wi------- linear /dev/fast-pv main-lv -wi------- linear /dev/slow-pv
67.11. Logical volume activation
By default, when you create a logical volume, it is in an active state. A logical volume that is an active state can be used through a block device. An activated logical volume is accessible and is subject to change.
There are various circumstances, where you need to make an individual logical volume inactive and therefore unknown to the kernel. You can activate or deactivate individual logical volume with the -a option of the lvchange command.
The following is the format to deactivate an individual logical volume:
# lvchange -an vg/lvThe following is the format to activate an individual logical volume:
# lvchange -ay vg/lv
You can activate or deactivate all of the logical volumes in a volume group with the -a option of the vgchange command. This is the equivalent of running the lvchange -a command on each individual logical volume in the volume group.
The following is the format to deactivate all of the logical volumes in a volume group:
# vgchange -an vgThe following is the format to activate all of the logical volumes in a volume group:
# vgchange -ay vg
During manual activation, the systemd automatically mounts LVM volumes with the corresponding mount point from the /etc/fstab file unless the systemd-mount unit is masked.
67.11.1. Controlling autoactivation of logical volumes and volume groups
Autoactivation of a logical volume refers to the event-based automatic activation of a logical volume during system startup. As devices become available on the system (device online events), systemd/udev runs the lvm2-pvscan service for each device. This service runs the pvscan --cache -aay device command, which reads the named device. If the device belongs to a volume group, the pvscan command will check if all of the physical volumes for that volume group are present on the system. If so, the command will activate logical volumes in that volume group.
You can set the autoactivation property on a VG or LV. When the autoactivation property is disabled, the VG or LV will not be activated by a command doing autoactivation, such as vgchange, lvchange, or pvscan using -aay option. If autoactivation is disabled on a VG, no LVs will be autoactivated in that VG, and the autoactivation property has no effect. If autoactivation is enabled on a VG, autoactivation can be disabled for individual LVs.
Procedure
You can update the autoactivation settings in one of the following ways:
Control autoactivation of a VG using the command line:
# vgchange --setautoactivation <y|n>Control autoactivation of a LV using the command line:
# lvchange --setautoactivation <y|n>Control autoactivation of a LV in the
/etc/lvm/lvm.confconfiguration file using one of the following configuration options:global/event_activationWhen
event_activationis disabled,systemd/udevwill autoactivate logical volume only on whichever physical volumes are present during system startup. If all physical volumes have not appeared yet, then some logical volumes may not be autoactivated.activation/auto_activation_volume_listSetting
auto_activation_volume_listto an empty list disables autoactivation entirely. Settingauto_activation_volume_listto specific logical volumes and volume groups limits autoactivation to those logical volumes.
67.11.2. Controlling logical volume activation
You can control the activation of logical volume in the following ways:
-
Through the
activation/volume_listsetting in the/etc/lvm/conffile. This allows you to specify which logical volumes are activated. For information about using this option, see the/etc/lvm/lvm.confconfiguration file. - By means of the activation skip flag for a logical volume. When this flag is set for a logical volume, the volume is skipped during normal activation commands.
Alternatively, you can use the --setactivationskip y|n option with the lvcreate or the lvchange commands to enable or disable the activation skip flag.
Procedure
You can set the activation skip flag on a logical volume in the following ways:
To determine whether the activation skip flag is set for a logical volume run the
lvscommand, which displays thekattribute as in the following example:# lvs vg/thin1s1 LV VG Attr LSize Pool Origin thin1s1 vg Vwi---tz-k 1.00t pool0 thin1You can activate a logical volume with the
kattribute set by using the-Kor--ignoreactivationskipoption in addition to the standard-ayor--activate yoption.By default, thin snapshot volumes are flagged for activation skip when they are created. You can control the default activation skip setting on new thin snapshot volumes with the
auto_set_activation_skipsetting in the/etc/lvm/lvm.conffile.The following command activates a thin snapshot logical volume that has the activation skip flag set:
# lvchange -ay -K VG/SnapLVThe following command creates a thin snapshot without the activation skip flag:
# lvcreate -n SnapLV -kn -s vg/ThinLV --thinpool vg/ThinPoolLVThe following command removes the activation skip flag from a snapshot logical volume:
# lvchange -kn VG/SnapLV
Verification
Verify if a thin snapshot without the activation skip flag has been created:
# lvs -a -o +devices,segtype LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert Devices Type SnapLV vg Vwi-a-tz-- 100.00m ThinPoolLV ThinLV 0.00 thin ThinLV vg Vwi-a-tz-- 100.00m ThinPoolLV 0.00 thin ThinPoolLV vg twi-aotz-- 100.00m 0.00 10.94 ThinPoolLV_tdata(0) thin-pool [ThinPoolLV_tdata] vg Twi-ao---- 100.00m /dev/sdc1(1) linear [ThinPoolLV_tmeta] vg ewi-ao---- 4.00m /dev/sdd1(0) linear [lvol0_pmspare] vg ewi------- 4.00m /dev/sdc1(0) linear
67.11.3. Activating shared logical volumes
You can control logical volume activation of a shared logical volume with the -a option of the lvchange and vgchange commands, as follows:
| Command | Activation |
|---|---|
|
| Activate the shared logical volume in exclusive mode, allowing only a single host to activate the logical volume. If the activation fails, as would happen if the logical volume is active on another host, an error is reported. |
|
| Activate the shared logical volume in shared mode, allowing multiple hosts to activate the logical volume concurrently. If the activation fails, as would happen if the logical volume is active exclusively on another host, an error is reported. If the logical type prohibits shared access, such as a snapshot, the command will report an error and fail. Logical volume types that cannot be used concurrently from multiple hosts include thin, cache, raid, and snapshot. |
|
| Deactivate the logical volume. |
67.11.4. Activating a logical volume with missing devices
You can control whether LVs that are missing devices can be activated by using the lvchange command with the --activationmode partial|degraded|complete option. The values are described below:
| Activation Mode | Meaning |
|---|---|
| complete | Allows only logical volumes with no missing physical volumes to be activated. This is the most restrictive mode. |
| degraded | Allows RAID logical volumes with missing physical volumes to be activated. |
| partial | Allows any logical volume with missing physical volumes to be activated. This option should be used for recovery or repair only. |
The default value of activationmode is determined by the activationmode setting in the /etc/lvm/lvm.conf file. It is used if no command line option is given.
67.12. Limiting LVM device visibility and usage
You can limit the devices that are visible and usable to Logical Volume Manager (LVM) by controlling the devices that LVM can scan.
To adjust the configuration of LVM device scanning, edit the LVM device filter settings in the /etc/lvm/lvm.conf file. The filters in the lvm.conf file consist of a series of simple regular expressions. The system applies these expressions to each device name in the /dev directory to decide whether to accept or reject each detected block device.
67.12.1. Persistent identifiers for LVM filtering
Traditional Linux device names, such as /dev/sda, are subject to changes during system modifications and reboots. Persistent Naming Attributes (PNAs) like World Wide Identifier (WWID), Universally Unique Identifier (UUID), and path names are based on unique characteristics of the storage devices and are resilient to changes in hardware configurations. This makes them more stable and predictable across system reboots.
Implementation of persistent device identifiers in LVM filtering enhances the stability and reliability of LVM configurations. It also reduces the risk of system boot failures associated with the dynamic nature of device names.
67.12.2. The LVM device filter
The Logical Volume Manager (LVM) device filter is a list of device name patterns. You can use it to specify a set of mandatory criteria by which the system can evaluate devices and consider them as valid for use with LVM. The LVM device filter enables you control over which devices LVM uses. This can help to prevent accidental data loss or unauthorized access to storage devices.
67.12.2.1. LVM device filter pattern characteristics
The patterns of LVM device filter are in the form of regular expression. A regular expression delimits with a character and precedes with either a for acceptance, or r for rejection. The first regular expression in the list that matches a device determines if LVM accepts or rejects (ignores) a specific device. Then, LVM looks for the initial regular expression in the list that matches the path of a device. LVM uses this regular expression to determine whether the device should be approved with an a outcome or rejected with an r outcome.
If a single device has multiple path names, LVM accesses these path names according to their order of listing. Before any r pattern, if at least one path name matches an a pattern, LVM approves the device. However, if all path names are consistent with an r pattern before an a pattern is found, the device is rejected.
Path names that do not match the pattern do not affect the approval status of the device. If no path names correspond to a pattern for a device, LVM still approves the device.
For each device on the system, the udev rules generate multiple symlinks. Directories contain symlinks, such as /dev/disk/by-id/, /dev/disk/by-uuid/, /dev/disk/by-path/ to ensure that each device on the system is accessible through multiple path names.
To reject a device in the filter, all of the path names associated with that particular device must match the corresponding reject r expressions. However, identifying all possible path names to reject can be challenging. This is why it is better to create filters that specifically accept certain paths and reject all others, using a series of specific a expressions followed by a single r|.*| expression that rejects everything else.
While defining a specific device in the filter, use a symlink name for that device instead of the kernel name. The kernel name for a device can change, such as /dev/sda while certain symlink names do not change such as /dev/disk/by-id/wwn-*.
The default device filter accepts all devices connected to the system. An ideal user configured device filter accepts one or more patterns and rejects everything else. For example, the pattern list ending with r|.*|.
You can find the LVM devices filter configuration in the devices/filter and devices/global_filter configuration fields in the lvm.conf file. The devices/filter and devices/global_filter configuration fields are equivalent.
67.12.2.2. Examples of LVM device filter configurations
The following examples display the filter configurations to control the devices that LVM scans and uses later. To configure the device filter in the lvm.conf file, see
You might encounter duplicate Physical Volume (PV) warnings when dealing with copied or cloned PVs. You can set up filters to resolve this. See the example filter configurations in Example LVM device filters that prevent duplicate PV warnings.
To scan all the devices, enter:
filter = [ "a|.*|" ]To remove the
cdromdevice to avoid delays if the drive contains no media, enter:filter = [ "r|^/dev/cdrom$|" ]To add all loop devices and remove all other devices, enter:
filter = [ "a|loop|", "r|.*|" ]To add all loop and SCSI devices and remove all other block devices, enter:
filter = [ "a|loop|", "a|/dev/sd.*|", "r|.*|" ]To add only partition 8 on the first SCSI drive and remove all other block devices, enter:
filter = [ "a|^/dev/sda8$|", "r|.*|" ]To add all partitions from a specific device identified by WWID along with all multipath devices, enter:
filter = [ "a|/dev/disk/by-id/<disk-id>.|", "a|/dev/mapper/mpath.|", "r|.*|" ]The command also removes any other block devices.
67.12.2.3. Applying an LVM device filter configuration
You can control which devices LVM scans by setting up filters in the lvm.conf configuration file.
Prerequisites
- You have prepared the device filter pattern that you want to use.
Procedure
Use the following command to test the device filter pattern, without actually modifying the
/etc/lvm/lvm.conffile. The following includes an example filter configuration.# lvs --config 'devices{ filter = [ "a|/dev/emcpower.|", "r|.|" ] }'Add the device filter pattern in the configuration section
devicesof the/etc/lvm/lvm.conffile:filter = [ "a|/dev/emcpower.*|", "r|*.|" ]Scan only necessary devices on reboot:
# dracut --force --verboseThis command rebuilds the
initramfsfile system so that LVM scans only the necessary devices at the time of reboot.
67.13. Controlling LVM allocation
By default, a volume group uses the normal allocation policy. This allocates physical extents according to common-sense rules such as not placing parallel stripes on the same physical volume. You can specify a different allocation policy (contiguous, anywhere, or cling) by using the --alloc argument of the vgcreate command. In general, allocation policies other than normal are required only in special cases where you need to specify unusual or nonstandard extent allocation.
67.13.1. Allocating extents from specified devices
You can restrict the allocation from specific devices by using the device arguments at the end of the command line with the lvcreate and the lvconvert commands. You can specify the actual extent ranges for each device for more control. The command only allocates extents for the new logical volume (LV) by using the specified physical volume (PV) as arguments. It takes available extents from each PV until they run out and then takes extents from the next PV listed. If there is not enough space on all the listed PVs for the requested LV size, then command fails. Note that the command only allocates from the named PVs. Raid LVs use sequential PVs for separate raid images or separate stripes. If the PVs are not large enough for an entire raid image, then the resulting device use is not entirely predictable.
Procedure
Create a volume group (VG):
# vgcreate <vg_name> <PV> ...Where:
-
<vg_name>is the name of the VG. -
<PV>are the PVs.
-
You can allocate PV to create different volume types, such as linear or raid:
Allocate extents to create a linear volume:
# lvcreate -n <lv_name> -L <lv_size> <vg_name> [ <PV> ... ]Where:
-
<lv_name>is the name of the LV. -
<lv_size>is the size of the LV. Default unit is megabytes. -
<vg_name>is the name of the VG. [ <PV …> ]are the PVs.You can specify one of the PVs, all of them, or none on the command line:
If you specify one PV, extents for that LV will be allocated from it.
NoteIf the PV does not have sufficient free extents for the entire LV, then the
lvcreatefails.- If you specify two PVs, extents for that LV will be allocated from one of them, or a combination of both.
If you do not specify any PV, extents will be allocated from one of the PVs in the VG, or any combination of all PVs in the VG.
NoteIn these cases, LVM might not use all of the named or available PVs. If the first PV has sufficient free extents for the entire LV, then the other PV will probably not be used. However, if the first PV does not have a set allocation size of free extents, then LV might be allocated partly from the first PV and partly from the second PV.
Example 67.10. Allocating extents from one PV
In this example,
lv1extents will be allocated fromsda.# lvcreate -n lv1 -L1G vg /dev/sdaExample 67.11. Allocating extents from two PVs
In this example,
lv2extents will be allocated from eithersda, orsdb, or a combination of both.# lvcreate -n lv2 L1G vg /dev/sda /dev/sdbExample 67.12. Allocating extents without specifying PV
In this example,
lv3extents will be allocated from one of the PVs in the VG, or any combination of all PVs in the VG.# lvcreate -n lv3 -L1G vgor
-
Allocate extents to create a raid volume:
# lvcreate --type <segment_type> -m <mirror_images> -n <lv_name> -L <lv_size> <vg_name> [ <PV> ... ]Where:
-
<segment_type>is the specified segment type (for exampleraid5,mirror,snapshot). -
<mirror_images>creates araid1or a mirrored LV with the specified number of images. For example,-m 1would result in araid1LV with two images. -
<lv_name>is the name of the LV. -
<lv_size>is the size of the LV. Default unit is megabytes. -
<vg_name>is the name of the VG. <[PV …]>are the PVs.The first raid image will be allocated from the first PV, the second raid image from the second PV, and so on.
Example 67.13. Allocating raid images from two PVs
In this example,
lv4first raid image will be allocated fromsdaand second image will be allocated fromsdb.# lvcreate --type raid1 -m 1 -n lv4 -L1G vg /dev/sda /dev/sdbExample 67.14. Allocating raid images from three PVs
In this example,
lv5first raid image will be allocated fromsda, second image will be allocated fromsdb, and third image will be allocated fromsdc.# lvcreate --type raid1 -m 2 -n lv5 -L1G vg /dev/sda /dev/sdb /dev/sdc
-
67.13.2. LVM allocation policies
When an LVM operation must allocate physical extents for one or more logical volumes (LVs), the allocation proceeds as follows:
- The complete set of unallocated physical extents in the volume group is generated for consideration. If you supply any ranges of physical extents at the end of the command line, only unallocated physical extents within those ranges on the specified physical volumes (PVs) are considered.
-
Each allocation policy is tried in turn, starting with the strictest policy (
contiguous) and ending with the allocation policy specified using the--allocoption or set as the default for the particular LV or volume group (VG). For each policy, working from the lowest-numbered logical extent of the empty LV space that needs to be filled, as much space as possible is allocated, according to the restrictions imposed by the allocation policy. If more space is needed, LVM moves on to the next policy.
The allocation policy restrictions are as follows:
The
contiguouspolicy requires that the physical location of any logical extent is adjacent to the physical location of the immediately preceding logical extent, with the exception of the first logical extent of a LV.When a LV is striped or mirrored, the
contiguousallocation restriction is applied independently to each stripe or raid image that needs space.-
The
clingallocation policy requires that the PV used for any logical extent be added to an existing LV that is already in use by at least one logical extent earlier in that LV. -
An allocation policy of
normalwill not choose a physical extent that shares the same PV as a logical extent already allocated to a parallel LV (that is, a different stripe or raid image) at the same offset within that parallel LV. -
If there are sufficient free extents to satisfy an allocation request but a
normalallocation policy would not use them, theanywhereallocation policy will, even if that reduces performance by placing two stripes on the same PV.
You can change the allocation policy by using the vgchange command.
Future updates can bring code changes in layout behavior according to the defined allocation policies. For example, if you supply on the command line two empty physical volumes that have an identical number of free physical extents available for allocation, LVM currently considers using each of them in the order they are listed; there is no guarantee that future releases will maintain that property. If you need a specific layout for a particular LV, build it up through a sequence of lvcreate and lvconvert steps such that the allocation policies applied to each step leave LVM no discretion over the layout.
67.13.3. Preventing allocation on a physical volume
You can prevent allocation of physical extents on the free space of one or more physical volumes with the pvchange command. This might be necessary if there are disk errors, or if you will be removing the physical volume.
Procedure
Use the following command to disallow the allocation of physical extents on
device_name:# pvchange -x n /dev/sdk1You can also allow allocation where it had previously been disallowed by using the
-xyarguments of thepvchangecommand.
67.14. Troubleshooting LVM
You can use Logical Volume Manager (LVM) tools to troubleshoot a variety of issues in LVM volumes and groups.
67.14.1. Gathering diagnostic data on LVM
If an LVM command is not working as expected, you can gather diagnostics in the following ways.
Procedure
Use the following methods to gather different kinds of diagnostic data:
-
Add the
-vargument to any LVM command to increase the verbosity level of the command output. Verbosity can be further increased by adding additionalv’s. A maximum of four suchv’sis allowed, for example,-vvvv. -
In the
logsection of the/etc/lvm/lvm.confconfiguration file, increase the value of theleveloption. This causes LVM to provide more details in the system log. If the problem is related to the logical volume activation, enable LVM to log messages during the activation:
-
Set the
activation = 1option in thelogsection of the/etc/lvm/lvm.confconfiguration file. -
Execute the LVM command with the
-vvvvoption. - Examine the command output.
Reset the
activationoption to0.If you do not reset the option to
0, the system might become unresponsive during low memory situations.
-
Set the
Display an information dump for diagnostic purposes:
# lvmdumpDisplay additional system information:
# lvs -v# pvs --all# dmsetup info --columns-
Examine the last backup of the LVM metadata in the
/etc/lvm/backup/directory and archived versions in the/etc/lvm/archive/directory. Check the current configuration information:
# lvmconfig-
Check the
/run/lvm/hintscache file for a record of which devices have physical volumes on them.
-
Add the
67.14.2. Displaying information about failed LVM devices
Troubleshooting information about a failed Logical Volume Manager (LVM) volume can help you determine the reason of the failure. You can check the following examples of the most common LVM volume failures.
Example 67.15. Failed volume groups
In this example, one of the devices that made up the volume group myvg failed. The volume group usability then depends on the type of failure. For example, the volume group is still usable if RAID volumes are also involved. You can also see information about the failed device.
# vgs --options +devices
/dev/vdb1: open failed: No such device or address
/dev/vdb1: open failed: No such device or address
WARNING: Couldn't find device with uuid 42B7bu-YCMp-CEVD-CmKH-2rk6-fiO9-z1lf4s.
WARNING: VG myvg is missing PV 42B7bu-YCMp-CEVD-CmKH-2rk6-fiO9-z1lf4s (last written to /dev/sdb1).
WARNING: Couldn't find all devices for LV myvg/mylv while checking used and assumed devices.
VG #PV #LV #SN Attr VSize VFree Devices
myvg 2 2 0 wz-pn- <3.64t <3.60t [unknown](0)
myvg 2 2 0 wz-pn- <3.64t <3.60t [unknown](5120),/dev/vdb1(0)Example 67.16. Failed logical volume
In this example, one of the devices failed. This can be a reason for the logical volume in the volume group to fail. The command output shows the failed logical volumes.
# lvs --all --options +devices
/dev/vdb1: open failed: No such device or address
/dev/vdb1: open failed: No such device or address
WARNING: Couldn't find device with uuid 42B7bu-YCMp-CEVD-CmKH-2rk6-fiO9-z1lf4s.
WARNING: VG myvg is missing PV 42B7bu-YCMp-CEVD-CmKH-2rk6-fiO9-z1lf4s (last written to /dev/sdb1).
WARNING: Couldn't find all devices for LV myvg/mylv while checking used and assumed devices.
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert Devices
mylv myvg -wi-a---p- 20.00g [unknown](0) [unknown](5120),/dev/sdc1(0)Example 67.17. Failed image of a RAID logical volume
The following examples show the command output from the pvs and lvs utilities when an image of a RAID logical volume has failed. The logical volume is still usable.
# pvs
Error reading device /dev/sdc1 at 0 length 4.
Error reading device /dev/sdc1 at 4096 length 4.
Couldn't find device with uuid b2J8oD-vdjw-tGCA-ema3-iXob-Jc6M-TC07Rn.
WARNING: Couldn't find all devices for LV myvg/my_raid1_rimage_1 while checking used and assumed devices.
WARNING: Couldn't find all devices for LV myvg/my_raid1_rmeta_1 while checking used and assumed devices.
PV VG Fmt Attr PSize PFree
/dev/sda2 rhel_bp-01 lvm2 a-- <464.76g 4.00m
/dev/sdb1 myvg lvm2 a-- <836.69g 736.68g
/dev/sdd1 myvg lvm2 a-- <836.69g <836.69g
/dev/sde1 myvg lvm2 a-- <836.69g <836.69g
[unknown] myvg lvm2 a-m <836.69g 736.68g# lvs -a --options name,vgname,attr,size,devices myvg
Couldn't find device with uuid b2J8oD-vdjw-tGCA-ema3-iXob-Jc6M-TC07Rn.
WARNING: Couldn't find all devices for LV myvg/my_raid1_rimage_1 while checking used and assumed devices.
WARNING: Couldn't find all devices for LV myvg/my_raid1_rmeta_1 while checking used and assumed devices.
LV VG Attr LSize Devices
my_raid1 myvg rwi-a-r-p- 100.00g my_raid1_rimage_0(0),my_raid1_rimage_1(0)
[my_raid1_rimage_0] myvg iwi-aor--- 100.00g /dev/sdb1(1)
[my_raid1_rimage_1] myvg Iwi-aor-p- 100.00g [unknown](1)
[my_raid1_rmeta_0] myvg ewi-aor--- 4.00m /dev/sdb1(0)
[my_raid1_rmeta_1] myvg ewi-aor-p- 4.00m [unknown](0)67.14.3. Removing lost LVM physical volumes from a volume group
If a physical volume fails, you can activate the remaining physical volumes in the volume group and remove all the logical volumes that used that physical volume from the volume group.
Procedure
Activate the remaining physical volumes in the volume group:
# vgchange --activate y --partial myvgCheck which logical volumes will be removed:
# vgreduce --removemissing --test myvgRemove all the logical volumes that used the lost physical volume from the volume group:
# vgreduce --removemissing --force myvgOptional: If you accidentally removed logical volumes that you wanted to keep, you can reverse the
vgreduceoperation:# vgcfgrestore myvgWarningIf you remove a thin pool, LVM cannot reverse the operation.
67.14.4. Finding the metadata of a missing LVM physical volume
If the volume group’s metadata area of a physical volume is accidentally overwritten or otherwise destroyed, you get an error message indicating that the metadata area is incorrect, or that the system was unable to find a physical volume with a particular UUID.
This procedure finds the latest archived metadata of a physical volume that is missing or corrupted.
Procedure
Find the archived metadata file of the volume group that contains the physical volume. The archived metadata files are located at the
/etc/lvm/archive/volume-group-name_backup-number.vgpath:# cat /etc/lvm/archive/myvg_00000-1248998876.vgReplace 00000-1248998876 with the backup-number. Select the last known valid metadata file, which has the highest number for the volume group.
Find the UUID of the physical volume. Use one of the following methods.
List the logical volumes:
# lvs --all --options +devices Couldn't find device with uuid 'FmGRh3-zhok-iVI8-7qTD-S5BI-MAEN-NYM5Sk'.-
Examine the archived metadata file. Find the UUID as the value labeled
id =in thephysical_volumessection of the volume group configuration. Deactivate the volume group using the
--partialoption:# vgchange --activate n --partial myvg PARTIAL MODE. Incomplete logical volumes will be processed. WARNING: Couldn't find device with uuid 42B7bu-YCMp-CEVD-CmKH-2rk6-fiO9-z1lf4s. WARNING: VG myvg is missing PV 42B7bu-YCMp-CEVD-CmKH-2rk6-fiO9-z1lf4s (last written to /dev/vdb1). 0 logical volume(s) in volume group "myvg" now active
67.14.5. Restoring metadata on an LVM physical volume
This procedure restores metadata on a physical volume that is either corrupted or replaced with a new device. You might be able to recover the data from the physical volume by rewriting the metadata area on the physical volume.
Do not attempt this procedure on a working LVM logical volume. You will lose your data if you specify the incorrect UUID.
Prerequisites
- You have identified the metadata of the missing physical volume. For details, see Finding the metadata of a missing LVM physical volume.
Procedure
Restore the metadata on the physical volume:
# pvcreate --uuid physical-volume-uuid \ --restorefile /etc/lvm/archive/volume-group-name_backup-number.vg \ block-deviceNoteThe command overwrites only the LVM metadata areas and does not affect the existing data areas.
Example 67.18. Restoring a physical volume on /dev/vdb1
The following example labels the
/dev/vdb1device as a physical volume with the following properties:-
The UUID of
FmGRh3-zhok-iVI8-7qTD-S5BI-MAEN-NYM5Sk The metadata information contained in
VG_00050.vg, which is the most recent good archived metadata for the volume group# pvcreate --uuid "FmGRh3-zhok-iVI8-7qTD-S5BI-MAEN-NYM5Sk" \ --restorefile /etc/lvm/archive/VG_00050.vg \ /dev/vdb1 ... Physical volume "/dev/vdb1" successfully created
-
The UUID of
Restore the metadata of the volume group:
# vgcfgrestore myvg Restored volume group myvgDisplay the logical volumes on the volume group:
# lvs --all --options +devices myvgThe logical volumes are currently inactive. For example:
LV VG Attr LSize Origin Snap% Move Log Copy% Devices mylv myvg -wi--- 300.00G /dev/vdb1 (0),/dev/vdb1(0) mylv myvg -wi--- 300.00G /dev/vdb1 (34728),/dev/vdb1(0)If the segment type of the logical volumes is RAID, resynchronize the logical volumes:
# lvchange --resync myvg/mylvActivate the logical volumes:
# lvchange --activate y myvg/mylv-
If the on-disk LVM metadata takes at least as much space as what overrode it, this procedure can recover the physical volume. If what overrode the metadata went past the metadata area, the data on the volume may have been affected. You might be able to use the
fsckcommand to recover that data.
Verification
Display the active logical volumes:
# lvs --all --options +devices LV VG Attr LSize Origin Snap% Move Log Copy% Devices mylv myvg -wi--- 300.00G /dev/vdb1 (0),/dev/vdb1(0) mylv myvg -wi--- 300.00G /dev/vdb1 (34728),/dev/vdb1(0)
67.14.6. Rounding errors in LVM output
LVM commands that report the space usage in volume groups round the reported number to 2 decimal places to provide human-readable output. This includes the vgdisplay and vgs utilities.
As a result of the rounding, the reported value of free space might be larger than what the physical extents on the volume group provide. If you attempt to create a logical volume the size of the reported free space, you might get the following error:
Insufficient free extentsTo work around the error, you must examine the number of free physical extents on the volume group, which is the accurate value of free space. You can then use the number of extents to create the logical volume successfully.
67.14.7. Preventing the rounding error when creating an LVM volume
When creating an LVM logical volume, you can specify the number of logical extents of the logical volume to avoid rounding error.
Procedure
Find the number of free physical extents in the volume group:
# vgdisplay myvgExample 67.19. Free extents in a volume group
For example, the following volume group has 8780 free physical extents:
--- Volume group --- VG Name myvg System ID Format lvm2 Metadata Areas 4 Metadata Sequence No 6 VG Access read/write [...] Free PE / Size 8780 / 34.30 GBCreate the logical volume. Enter the volume size in extents rather than bytes.
Example 67.20. Creating a logical volume by specifying the number of extents
# lvcreate --extents 8780 --name mylv myvgExample 67.21. Creating a logical volume to occupy all the remaining space
Alternatively, you can extend the logical volume to use a percentage of the remaining free space in the volume group. For example:
# lvcreate --extents 100%FREE --name mylv myvg
Verification
Check the number of extents that the volume group now uses:
# vgs --options +vg_free_count,vg_extent_count VG #PV #LV #SN Attr VSize VFree Free #Ext myvg 2 1 0 wz--n- 34.30G 0 0 8780
67.14.8. LVM metadata and their location on disk
LVM headers and metadata areas are available in different offsets and sizes.
The default LVM disk header:
-
Is found in
label_headerandpv_headerstructures. - Is in the second 512-byte sector of the disk. Note that if a non-default location was specified when creating the physical volume (PV), the header can also be in the first or third sector.
The standard LVM metadata area:
- Begins 4096 bytes from the start of the disk.
- Ends 1 MiB from the start of the disk.
-
Begins with a 512 byte sector containing the
mda_headerstructure.
A metadata text area begins after the mda_header sector and goes to the end of the metadata area. LVM VG metadata text is written in a circular fashion into the metadata text area. The mda_header points to the location of the latest VG metadata within the text area.
You can print LVM headers from a disk by using the # pvck --dump headers /dev/sda command. This command prints label_header, pv_header, mda_header, and the location of metadata text if found. Bad fields are printed with the CHECK prefix.
The LVM metadata area offset will match the page size of the machine that created the PV, so the metadata area can also begin 8K, 16K or 64K from the start of the disk.
Larger or smaller metadata areas can be specified when creating the PV, in which case the metadata area may end at locations other than 1 MiB. The pv_header specifies the size of the metadata area.
When creating a PV, a second metadata area can be optionally enabled at the end of the disk. The pv_header contains the locations of the metadata areas.
67.14.9. Extracting VG metadata from a disk
Choose one of the following procedures to extract VG metadata from a disk, depending on your situation. For information about how to save extracted metadata, see Saving extracted metadata to a file.
For repair, you can use backup files in /etc/lvm/backup/ without extracting metadata from disk.
Procedure
Print current metadata text as referenced from valid
mda_header:# pvck --dump metadata <disk>Example 67.22. Metadata text from valid
mda_header# pvck --dump metadata /dev/sdb metadata text at 172032 crc Oxc627522f # vgname test segno 59 --- <raw metadata from disk> ---Print the locations of all metadata copies found in the metadata area, based on finding a valid
mda_header:# pvck --dump metadata_all <disk>Example 67.23. Locations of metadata copies in the metadata area
# pvck --dump metadata_all /dev/sdb metadata at 4608 length 815 crc 29fcd7ab vg test seqno 1 id FaCsSz-1ZZn-mTO4-Xl4i-zb6G-BYat-u53Fxv metadata at 5632 length 1144 crc 50ea61c3 vg test seqno 2 id FaCsSz-1ZZn-mTO4-Xl4i-zb6G-BYat-u53Fxv metadata at 7168 length 1450 crc 5652ea55 vg test seqno 3 id FaCsSz-1ZZn-mTO4-Xl4i-zb6G-BYat-u53FxvSearch for all copies of metadata in the metadata area without using an
mda_header, for example, if headers are missing or damaged:# pvck --dump metadata_search <disk>Example 67.24. Copies of metadata in the metadata area without using an
mda_header# pvck --dump metadata_search /dev/sdb Searching for metadata at offset 4096 size 1044480 metadata at 4608 length 815 crc 29fcd7ab vg test seqno 1 id FaCsSz-1ZZn-mTO4-Xl4i-zb6G-BYat-u53Fxv metadata at 5632 length 1144 crc 50ea61c3 vg test seqno 2 id FaCsSz-1ZZn-mTO4-Xl4i-zb6G-BYat-u53Fxv metadata at 7168 length 1450 crc 5652ea55 vg test seqno 3 id FaCsSz-1ZZn-mTO4-Xl4i-zb6G-BYat-u53FxvInclude the
-voption in thedumpcommand to show the description from each copy of metadata:# pvck --dump metadata -v <disk>Example 67.25. Showing description from each copy of metadata
# pvck --dump metadata -v /dev/sdb metadata text at 199680 crc 0x628cf243 # vgname my_vg seqno 40 --- my_vg { id = "dmEbPi-gsgx-VbvS-Uaia-HczM-iu32-Rb7iOf" seqno = 40 format = "lvm2" status = ["RESIZEABLE", "READ", "WRITE"] flags = [] extent_size = 8192 max_lv = 0 max_pv = 0 metadata_copies = 0 physical_volumes { pv0 { id = "8gn0is-Hj8p-njgs-NM19-wuL9-mcB3-kUDiOQ" device = "/dev/sda" device_id_type = "sys_wwid" device_id = "naa.6001405e635dbaab125476d88030a196" status = ["ALLOCATABLE"] flags = [] dev_size = 125829120 pe_start = 8192 pe_count = 15359 } pv1 { id = "E9qChJ-5ElL-HVEp-rc7d-U5Fg-fHxL-2QLyID" device = "/dev/sdb" device_id_type = "sys_wwid" device_id = "naa.6001405f3f9396fddcd4012a50029a90" status = ["ALLOCATABLE"] flags = [] dev_size = 125829120 pe_start = 8192 pe_count = 15359 }
This file can be used for repair. The first metadata area is used by default for dump metadata. If the disk has a second metadata area at the end of the disk, you can use the --settings "mda_num=2" option to use the second metadata area for dump metadata instead.
67.14.10. Saving extracted metadata to a file
If you need to use dumped metadata for repair, it is required to save extracted metadata to a file with the -f option and the --setings option.
Procedure
-
If
-f <filename>is added to--dump metadata, the raw metadata is written to the named file. You can use this file for repair. -
If
-f <filename>is added to--dump metadata_allor--dump metadata_search, then raw metadata from all locations is written to the named file. To save one instance of metadata text from
--dump metadata_all|metadata_searchadd--settings "metadata_offset=<offset>"where<offset>is from the listing output "metadata at <offset>".Example 67.26. Output of the command
# pvck --dump metadata_search --settings metadata_offset=5632 -f meta.txt /dev/sdb Searching for metadata at offset 4096 size 1044480 metadata at 5632 length 1144 crc 50ea61c3 vg test seqno 2 id FaCsSz-1ZZn-mTO4-Xl4i-zb6G-BYat-u53Fxv # head -2 meta.txt test { id = "FaCsSz-1ZZn-mTO4-Xl4i-zb6G-BYat-u53Fxv"
67.14.11. Repairing a disk with damaged LVM headers and metadata using the pvcreate and the vgcfgrestore commands
You can restore metadata and headers on a physical volume that is either corrupted or replaced with a new device. You might be able to recover the data from the physical volume by rewriting the metadata area on the physical volume.
These instructions should be used with extreme caution, and only if you are familiar with the implications of each command, the current layout of the volumes, the layout that you need to achieve, and the contents of the backup metadata file. These commands have the potential to corrupt data, and as such, it is recommended that you contact Red Hat Global Support Services for assistance in troubleshooting.
Prerequisites
- You have identified the metadata of the missing physical volume. For details, see Finding the metadata of a missing LVM physical volume.
Procedure
Collect the following information needed for the
pvcreateandvgcfgrestorecommands. You can collect the information about your disk and UUID by running the# pvs -o+uuidcommand.-
metadata-file is the path to the most recent metadata backup file for the VG, for example,
/etc/lvm/backup/<vg-name> - vg-name is the name of the VG that has the damaged or missing PV.
-
UUID of the PV that was damaged on this device is the value taken from the output of the
# pvs -i+uuidcommand. -
disk is the name of the disk where the PV is supposed to be, for example,
/dev/sdb. Be certain this is the correct disk, or seek help, otherwise following these steps may lead to data loss.
-
metadata-file is the path to the most recent metadata backup file for the VG, for example,
Recreate LVM headers on the disk:
# pvcreate --restorefile <metadata-file> --uuid <UUID> <disk>Optionally, verify that the headers are valid:
# pvck --dump headers <disk>Restore the VG metadata on the disk:
# vgcfgrestore --file <metadata-file> <vg-name>Optionally, verify the metadata is restored:
# pvck --dump metadata <disk>
If there is no metadata backup file for the VG, you can get one by using the procedure in Saving extracted metadata to a file.
Verification
To verify that the new physical volume is intact and the volume group is functioning correctly, check the output of the following command:
# vgs
67.14.12. Repairing a disk with damaged LVM headers and metadata using the pvck command
This is an alternative to the Repairing a disk with damaged LVM headers and metadata using the pvcreate and the vgcfgrestore commands. There may be cases where the pvcreate and the vgcfgrestore commands do not work. This method is more targeted at the damaged disk.
This method uses a metadata input file that was extracted by pvck --dump, or a backup file from /etc/lvm/backup. When possible, use metadata saved by pvck --dump from another PV in the same VG, or from a second metadata area on the PV. For more information, see Saving extracted metadata to a file.
Procedure
Repair the headers and metadata on the disk:
# pvck --repair -f <metadata-file> <disk>where
-
<metadata-file> is a file containing the most recent metadata for the VG. This can be
/etc/lvm/backup/vg-name, or it can be a file containing raw metadata text from thepvck --dump metadata_searchcommand output. -
<disk> is the name of the disk where the PV is supposed to be, for example,
/dev/sdb. To prevent data loss, verify that is the correct disk. If you are not certain the disk is correct, contact Red Hat Support.
-
<metadata-file> is a file containing the most recent metadata for the VG. This can be
If the metadata file is a backup file, the pvck --repair should be run on each PV that holds metadata in VG. If the metadata file is raw metadata that has been extracted from another PV, the pvck --repair needs to be run only on the damaged PV.
Verification
To check that the new physical volume is intact and the volume group is functioning correctly, check outputs of the following commands:
# vgs <vgname># pvs <pvname># lvs <lvname>
67.14.13. Troubleshooting LVM RAID
You can troubleshoot various issues in LVM RAID devices to correct data errors, recover devices, or replace failed devices.
67.14.13.1. Checking data coherency in a RAID logical volume
LVM provides scrubbing support for RAID logical volumes. RAID scrubbing is the process of reading all the data and parity blocks in an array and checking to see whether they are coherent. The lvchange --syncaction repair command initiates a background synchronization action on the array.
Procedure
Optional: Control the rate at which a RAID logical volume is initialized by setting any one of the following options:
-
--maxrecoveryrate Rate[bBsSkKmMgG]sets the maximum recovery rate for a RAID logical volume so that it will not expel nominal I/O operations. --minrecoveryrate Rate[bBsSkKmMgG]sets the minimum recovery rate for a RAID logical volume to ensure that I/O for sync operations achieves a minimum throughput, even when heavy nominal I/O is present# lvchange --maxrecoveryrate 4K my_vg/my_lv Logical volume _my_vg/my_lv_changed.Replace 4K with the recovery rate value, which is an amount per second for each device in the array. If you provide no suffix, the options assume kiB per second per device.
# lvchange --syncaction repair my_vg/my_lvWhen you perform a RAID scrubbing operation, the background I/O required by the
syncactions can crowd out other I/O to LVM devices, such as updates to volume group metadata. This might cause the other LVM operations to slow down.NoteYou can also use these maximum and minimum I/O rate while creating a RAID device. For example,
lvcreate --type raid10 -i 2 -m 1 -L 10G --maxrecoveryrate 128 -n my_lv my_vgcreates a 2-way RAID10 array my_lv, which is in the volume group my_vg with 3 stripes that is 10G in size with a maximum recovery rate of 128 kiB/sec/device.
-
Display the number of discrepancies in the array, without repairing them:
# lvchange --syncaction check my_vg/my_lvThis command initiates a background synchronization action on the array.
-
Optional: View the
var/log/syslogfile for the kernel messages. Correct the discrepancies in the array:
# lvchange --syncaction repair my_vg/my_lvThis command repairs or replaces failed devices in a RAID logical volume. You can view the
var/log/syslogfile for the kernel messages after executing this command.
Verification
Display information about the scrubbing operation:
# lvs -o +raid_sync_action,raid_mismatch_count my_vg/my_lv LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert SyncAction Mismatches my_lv my_vg rwi-a-r--- 500.00m 100.00 idle 0
67.14.13.2. Replacing a failed RAID device in a logical volume
RAID is not similar to traditional LVM mirroring. In case of LVM mirroring, remove the failed devices. Otherwise, the mirrored logical volume would hang while RAID arrays continue running with failed devices. For RAID levels other than RAID1, removing a device would mean converting to a lower RAID level, for example, from RAID6 to RAID5, or from RAID4 or RAID5 to RAID0.
Instead of removing a failed device and allocating a replacement, with LVM, you can replace a failed device that serves as a physical volume in a RAID logical volume by using the --repair argument of the lvconvert command.
Prerequisites
The volume group includes a physical volume that provides enough free capacity to replace the failed device.
If no physical volume with enough free extents is available on the volume group, add a new, sufficiently large physical volume by using the
vgextendutility.
Procedure
View the RAID logical volume:
# lvs --all --options name,copy_percent,devices my_vg LV Cpy%Sync Devices my_lv 100.00 my_lv_rimage_0(0),my_lv_rimage_1(0),my_lv_rimage_2(0) [my_lv_rimage_0] /dev/sde1(1) [my_lv_rimage_1] /dev/sdc1(1) [my_lv_rimage_2] /dev/sdd1(1) [my_lv_rmeta_0] /dev/sde1(0) [my_lv_rmeta_1] /dev/sdc1(0) [my_lv_rmeta_2] /dev/sdd1(0)View the RAID logical volume after the /dev/sdc device fails:
# lvs --all --options name,copy_percent,devices my_vg /dev/sdc: open failed: No such device or address Couldn't find device with uuid A4kRl2-vIzA-uyCb-cci7-bOod-H5tX-IzH4Ee. WARNING: Couldn't find all devices for LV my_vg/my_lv_rimage_1 while checking used and assumed devices. WARNING: Couldn't find all devices for LV my_vg/my_lv_rmeta_1 while checking used and assumed devices. LV Cpy%Sync Devices my_lv 100.00 my_lv_rimage_0(0),my_lv_rimage_1(0),my_lv_rimage_2(0) [my_lv_rimage_0] /dev/sde1(1) [my_lv_rimage_1] [unknown](1) [my_lv_rimage_2] /dev/sdd1(1) [my_lv_rmeta_0] /dev/sde1(0) [my_lv_rmeta_1] [unknown](0) [my_lv_rmeta_2] /dev/sdd1(0)Replace the failed device:
# lvconvert --repair my_vg/my_lv /dev/sdc: open failed: No such device or address Couldn't find device with uuid A4kRl2-vIzA-uyCb-cci7-bOod-H5tX-IzH4Ee. WARNING: Couldn't find all devices for LV my_vg/my_lv_rimage_1 while checking used and assumed devices. WARNING: Couldn't find all devices for LV my_vg/my_lv_rmeta_1 while checking used and assumed devices. Attempt to replace failed RAID images (requires full device resync)? [y/n]: y Faulty devices in my_vg/my_lv successfully replaced.Optional: Manually specify the physical volume that replaces the failed device:
# lvconvert --repair my_vg/my_lv replacement_pvExamine the logical volume with the replacement:
# lvs --all --options name,copy_percent,devices my_vg /dev/sdc: open failed: No such device or address /dev/sdc1: open failed: No such device or address Couldn't find device with uuid A4kRl2-vIzA-uyCb-cci7-bOod-H5tX-IzH4Ee. LV Cpy%Sync Devices my_lv 43.79 my_lv_rimage_0(0),my_lv_rimage_1(0),my_lv_rimage_2(0) [my_lv_rimage_0] /dev/sde1(1) [my_lv_rimage_1] /dev/sdb1(1) [my_lv_rimage_2] /dev/sdd1(1) [my_lv_rmeta_0] /dev/sde1(0) [my_lv_rmeta_1] /dev/sdb1(0) [my_lv_rmeta_2] /dev/sdd1(0)Until you remove the failed device from the volume group, LVM utilities still indicate that LVM cannot find the failed device.
Remove the failed device from the volume group:
# vgreduce --removemissing my_vg
Verification
View the available physical volumes after removing the failed device:
# pvscan PV /dev/sde1 VG rhel_virt-506 lvm2 [<7.00 GiB / 0 free] PV /dev/sdb1 VG my_vg lvm2 [<60.00 GiB / 59.50 GiB free] PV /dev/sdd1 VG my_vg lvm2 [<60.00 GiB / 59.50 GiB free] PV /dev/sdd1 VG my_vg lvm2 [<60.00 GiB / 59.50 GiB free]Examine the logical volume after the replacing the failed device:
# lvs --all --options name,copy_percent,devices my_vg my_lv_rimage_0(0),my_lv_rimage_1(0),my_lv_rimage_2(0) [my_lv_rimage_0] /dev/sde1(1) [my_lv_rimage_1] /dev/sdb1(1) [my_lv_rimage_2] /dev/sdd1(1) [my_lv_rmeta_0] /dev/sde1(0) [my_lv_rmeta_1] /dev/sdb1(0) [my_lv_rmeta_2] /dev/sdd1(0)
67.14.14. Troubleshooting duplicate physical volume warnings for multipathed LVM devices
When using LVM with multipathed storage, LVM commands that list a volume group or logical volume might display messages such as the following:
Found duplicate PV GDjTZf7Y03GJHjteqOwrye2dcSCjdaUi: using /dev/dm-5 not /dev/sdd
Found duplicate PV GDjTZf7Y03GJHjteqOwrye2dcSCjdaUi: using /dev/emcpowerb not /dev/sde
Found duplicate PV GDjTZf7Y03GJHjteqOwrye2dcSCjdaUi: using /dev/sddlmab not /dev/sdfYou can troubleshoot these warnings to understand why LVM displays them, or to hide the warnings.
67.14.14.1. Root cause of duplicate PV warnings
When a multipath software such as Device Mapper Multipath (DM Multipath), EMC PowerPath, or Hitachi Dynamic Link Manager (HDLM) manages storage devices on the system, each path to a particular logical unit (LUN) is registered as a different SCSI device.
The multipath software then creates a new device that maps to those individual paths. Because each LUN has multiple device nodes in the /dev directory that point to the same underlying data, all the device nodes contain the same LVM metadata.
| Multipath software | SCSI paths to a LUN | Multipath device mapping to paths |
|---|---|---|
| DM Multipath |
|
|
| EMC PowerPath |
| |
| HDLM |
|
As a result of the multiple device nodes, LVM tools find the same metadata multiple times and report them as duplicates.
67.14.14.2. Cases of duplicate PV warnings
LVM displays the duplicate PV warnings in either of the following cases:
- Single paths to the same device
The two devices displayed in the output are both single paths to the same device.
The following example shows a duplicate PV warning in which the duplicate devices are both single paths to the same device.
Found duplicate PV GDjTZf7Y03GJHjteqOwrye2dcSCjdaUi: using /dev/sdd not /dev/sdfIf you list the current DM Multipath topology using the
multipath -llcommand, you can find both/dev/sddand/dev/sdfunder the same multipath map.These duplicate messages are only warnings and do not mean that the LVM operation has failed. Rather, they are alerting you that LVM uses only one of the devices as a physical volume and ignores the others.
If the messages indicate that LVM chooses the incorrect device or if the warnings are disruptive to users, you can apply a filter. The filter configures LVM to search only the necessary devices for physical volumes, and to leave out any underlying paths to multipath devices. As a result, the warnings no longer appear.
- Multipath maps
The two devices displayed in the output are both multipath maps.
The following examples show a duplicate PV warning for two devices that are both multipath maps. The duplicate physical volumes are located on two different devices rather than on two different paths to the same device.
Found duplicate PV GDjTZf7Y03GJHjteqOwrye2dcSCjdaUi: using /dev/mapper/mpatha not /dev/mapper/mpathc Found duplicate PV GDjTZf7Y03GJHjteqOwrye2dcSCjdaUi: using /dev/emcpowera not /dev/emcpowerhThis situation is more serious than duplicate warnings for devices that are both single paths to the same device. These warnings often mean that the machine is accessing devices that it should not access: for example, LUN clones or mirrors.
Unless you clearly know which devices you should remove from the machine, this situation might be unrecoverable. Red Hat recommends that you contact Red Hat Technical Support to address this issue.
67.14.14.3. Example LVM device filters that prevent duplicate PV warnings
The following examples show LVM device filters that avoid the duplicate physical volume warnings that are caused by multiple storage paths to a single logical unit (LUN).
You can configure the filter for logical volume manager (LVM) to check metadata for all devices. Metadata includes local hard disk drive with the root volume group on it and any multipath devices. By rejecting the underlying paths to a multipath device (such as /dev/sdb, /dev/sdd), you can avoid these duplicate PV warnings, because LVM finds each unique metadata area once on the multipath device itself.
To accept the second partition on the first hard disk drive and any device mapper (DM) Multipath devices and reject everything else, enter:
filter = [ "a|/dev/sda2$|", "a|/dev/mapper/mpath.*|", "r|.*|" ]To accept all HP SmartArray controllers and any EMC PowerPath devices, enter:
filter = [ "a|/dev/cciss/.*|", "a|/dev/emcpower.*|", "r|.*|" ]To accept any partitions on the first IDE drive and any multipath devices, enter:
filter = [ "a|/dev/hda.*|", "a|/dev/mapper/mpath.*|", "r|.*|" ]