第15章 高可用性の実装
次のいずれかの方法を使用して、AMQ Broker の高可用性ソリューションを実装できます。
クラスター内のブローカーをプライマリーバックアップグループにまとめます。
プライマリーバックアップグループでは、プライマリーブローカーをバックアップブローカーに関連付けます。プライマリーブローカーはクライアントの要求に応えます。一方、バックアップブローカーはパッシブモードで待機します。プライマリーブローカーに障害が発生した場合、バックアップブローカーがプライマリーブローカーに代わってアクティブなブローカーになります。AMQ Broker には、プライマリーバックアップグループ内でフェイルオーバーを設定するためのさまざまなストラテジー (HA ポリシー) が用意されています。
クラスター化されていないブローカーでリーダー/フォロワー構成を作成します。
リーダー/フォロワー構成では、クラスター化されていないブローカーが共有メッセージストア (JDBC データベースまたはジャーナルファイル) を使用します。2 つのブローカーが、メッセージストアへのロックを取得するために、ピアとして競合します。ロックを取得したブローカーは、リーダーブローカーとなり、クライアントの要求に応えます。ロックを取得できなかったブローカーは、フォロワーになります。フォロワーはパッシブブローカーであり、現在のリーダーが利用不可になった場合にアクティブブローカーになるために、継続的にロックの取得を試みます。
プライマリーバックアップグループでは、1 つのブローカーをプライマリーとして設定し、もう 1 つをバックアップとして設定します。リーダー/フォロワー構成では、両方のブローカーに同じ設定を指定します。
15.1. 高可用性を実現するためのプライマリーバックアップグループの設定
プライマリーバックアップグループ内でフェイルオーバーを設定するには、HA ポリシー と呼ばれるさまざまなストラテジーを利用できます。
15.1.1. 高可用性ポリシー
高可用性 (HA) ポリシーは、プライマリー/バックアップグループでのフェイルオーバーの発生方法を定義します。AMQ Broker には、以下のようにさまざまな HA ポリシーが用意されています。
- 共有ストア (推奨)
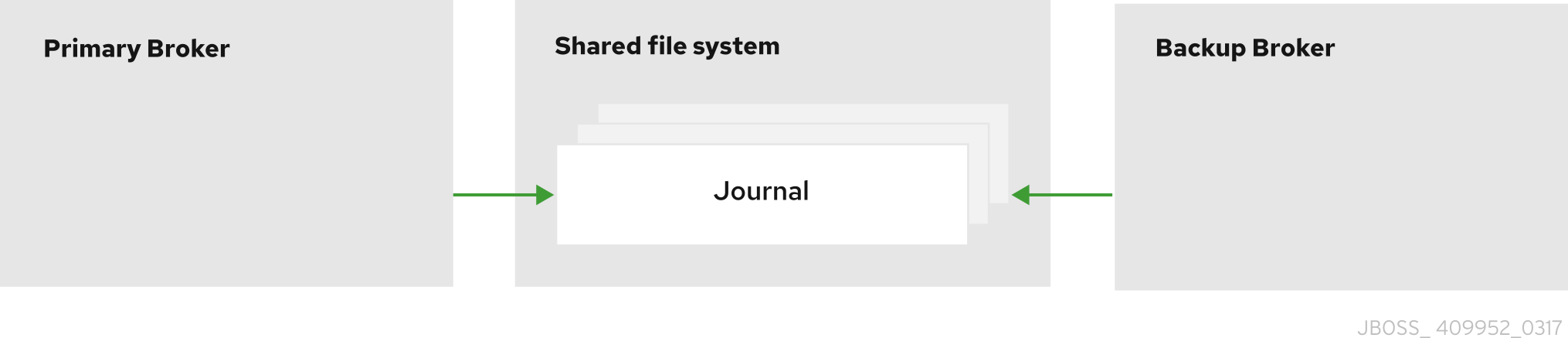
プライマリーおよびバックアップブローカーは、メッセージングデータを共有ファイルシステム上の共通ディレクトリー (通常は Storage Area Network (SAN) または Network File System (NFS) サーバー) に保存します。また、JDBC ベースの永続を設定している場合は、ブローカーデータを指定されたデータベースに保存することもできます。共有ストアでは、プライマリーブローカーに障害が発生した場合、バックアップブローカーが共有ストアからメッセージデータをロードし、アクティブブローカーとして引き継ぎます。
ほとんどの場合、レプリケーションではなく共有ストアを使用することが推奨されます。共有ストアはネットワーク経由でデータを複製しないため、通常はレプリケーションよりもパフォーマンスが向上します。共有ストアは、プライマリーブローカーとそのバックアップが同時にアクティブになるネットワーク分離 (「スプリットブレイン」とも呼ばれる) の問題も回避します。
図15.1 共有ストア高可用性
ブローカーをリーダー/フォロワー構成で設定することにより、共有ストアを使用した別の高可用性ソリューションを実装できます。リーダー/フォロワー構成では、ブローカーはクラスター化されず、ピアとして競合して、アクティブになってクライアントの要求に対応するブローカーと、アクティブなブローカーが利用できなくなるまでパッシブ状態を維持するブローカーを決定します。詳細は、「高可用性を実現するためのリーダー/フォロワーブローカーの設定」 を参照してください。
- レプリケーション
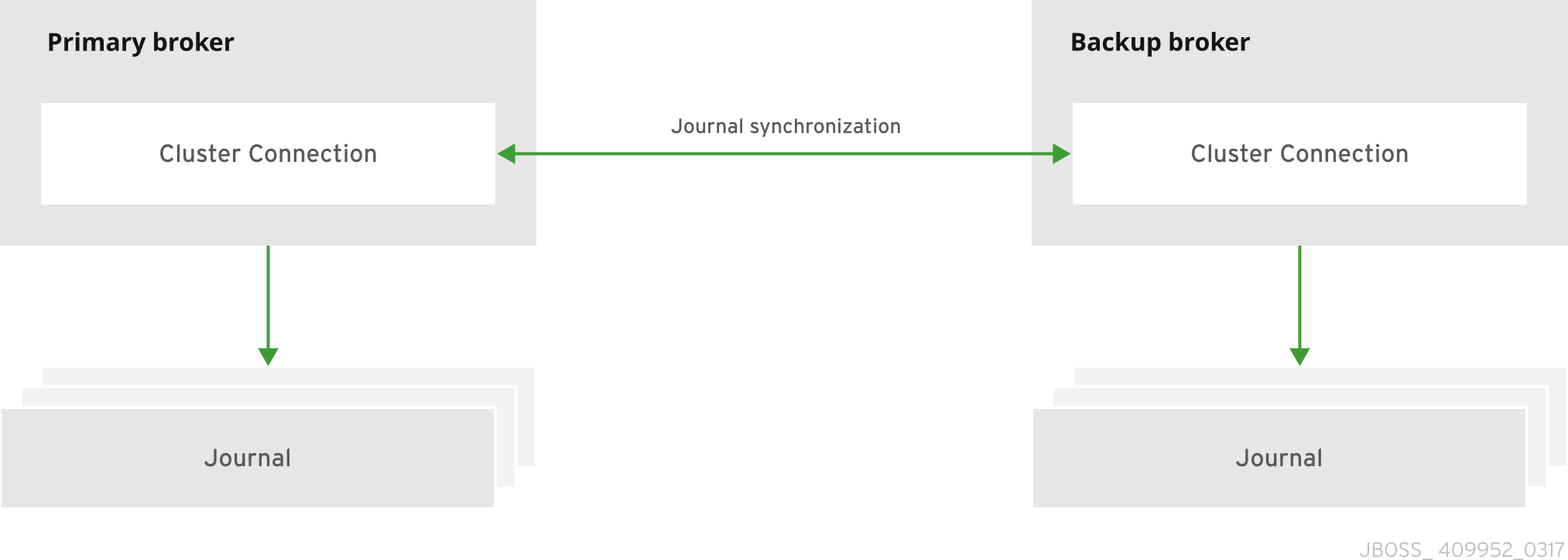
プライマリーおよびバックアップブローカーは、そのメッセージングデータをネットワーク経由で継続的に同期します。プライマリーブローカーに障害が発生した場合、バックアップブローカーが同期されたデータをロードし、アクティブブローカーとして引き継ぎます。
プライマリーブローカーとバックアップブローカー間のデータ同期により、プライマリーブローカーに障害が発生してもメッセージングデータが失われないようにします。プライマリーブローカーとバックアップブローカーが最初に結合すると、プライマリーブローカーは既存のデータをすべてネットワーク経由でバックアップブローカーにレプリケートします。この初期フェーズが完了すると、プライマリーブローカーは受信した永続データをバックアップブローカーにレプリケートします。つまり、プライマリーブローカーがネットワークから切断された場合、バックアップブローカーには、その時点までにプライマリーブローカーが受信したすべての永続データが含まれます。
レプリケーションはネットワーク経由でデータを同期するため、ネットワーク障害が発生すると、プライマリーブローカーとそのバックアップが同時にアクティブになるネットワーク分離が発生する可能性があります。
図15.2 レプリケーションの高可用性
- プライマリーのみ (限定的な HA)
プライマリーブローカーが正常に停止されると、そのメッセージとトランザクション状態を別のアクティブなブローカーにコピーしてからシャットダウンします。その後、クライアントは他のブローカーに再接続し、メッセージの送受信を続行します。
図15.3 プライマリーのみの高可用性

関連情報
- プライマリー/バックアップグループのブローカー間で共有される永続メッセージデータの詳細は、「ジャーナルでのメッセージデータの永続化」 を参照してください。
15.1.2. レプリケーションポリシーの制限
レプリケーションを使用して高可用性を提供する場合、プライマリーブローカーとバックアップブローカーの両方が同時にアクティブになるリスクが存在します。これは「スプリットブレイン」と呼ばれます。
プライマリーブローカーとそのバックアップの接続が失われた場合、スプリットブレインが発生する可能性があります。この場合、プライマリーブローカーとそのバックアップの両方を同時にアクティブ化できます。この状況では、ブローカー間でメッセージレプリケーションがないため、各ブローカーはクライアントとプロセスメッセージに、他のメッセージを認識せずに提供します。この場合、各ブローカーは完全に異なるジャーナルを持ちます。この状況からの復元は非常に困難であり、場合によっては不可能です。
- スプリットブレインの可能性を 排除 するには、共有ストア HA ポリシーを使用します。
レプリケーション HA ポリシーを使用する場合は、次の手順を実行して、スプリットブレインが発生するリスクを軽減してください。
ブローカーが ZooKeeper Coordination Service を使用してブローカーを調整するようにする場合は、少なくとも 3 つのノードに ZooKeeper をデプロイします。ブローカーが 1 つの ZooKeeper ノードへの接続を失った場合、少なくとも 3 つのノードを使用することで、プライマリー/バックアップブローカーペアでレプリケーションの中断が発生したときに、ノードの過半数をブローカー調整のために使用できるようになります。
クラスター内の他の使用可能なブローカーを使用してクォーラム投票を提供する埋め込みブローカー調整を使用する場合、3 つ以上のプライマリー/バックアップペア を使用することで、スプリットブレインが発生する可能性を減らすことができます (なくすことはできません)。3 つ以上のプライマリーバックアップペアを使用すると、プライマリーバックアップブローカーペアでレプリケーションの中断が発生した場合に行われるクォーラム投票で、過半数の結果を得られるようになります。
レプリケーション HA ポリシーを使用する場合の追加に関する考慮事項は以下のとおりです。
- プライマリーブローカーに障害が発生し、バックアップブローカーがアクティブになると、新しいバックアップブローカーがアクティブブローカーにアタッチされるか、元のプライマリーブローカーへのフェイルバックが発生するまで、それ以上のレプリケーションは実行されません。
- プライマリー/バックアップグループ内のバックアップブローカーに障害が発生した場合、プライマリーブローカーが引き続きメッセージを提供します。ただし、メッセージは別のブローカーがバックアップとして追加されるか、元のバックアップブローカーが再起動されるまで複製されません。その間、メッセージはプライマリーブローカーにのみ保存されます。
- ブローカーが埋め込みブローカー調整を使用し、プライマリー/バックアップのペアの両方のブローカーがシャットダウンされた場合、メッセージの損失を回避するために、最初に最も最近アクティブだったブローカーを再起動する必要があります。最後にアクティブだったブローカーがバックアップブローカーだった場合は、これが最初に再起動できるように、このブローカーをプライマリーブローカーとして手動で再設定する必要があります。
15.1.4. レプリケーション高可用性の設定
レプリケーション高可用性 (HA) ポリシーを使用して HA をブローカークラスターに実装できます。レプリケーションでは、永続データがプライマリーブローカーとバックアップブローカー間で同期されます。プライマリーブローカーに障害が発生した場合、メッセージデータはバックアップブローカーに同期され、障害が発生したプライマリーブローカーを引き継ぎます。
共有ファイルシステムがない場合は、共有ストアの代わりにレプリケーションを使用する必要があります。ただし、レプリケーションを行うと、プライマリーブローカーとそのバックアップが同時にアクティブになるシナリオが発生する可能性があります。
プライマリーブローカーとバックアップブローカーはネットワーク経由でメッセージングデータを同期する必要があるため、レプリケーションによってパフォーマンスのオーバーヘッドが追加されます。この同期プロセスでは、ジャーナル操作がブロックされますが、クライアントはブロックされません。データの同期のためにジャーナル操作がブロックできる最大時間を設定できます。
プライマリー/バックアップブローカーペア間のレプリケーション接続が中断された場合、ブローカーには、プライマリーブローカーがまだアクティブであるかどうか、または使用できず、バックアップブローカへのフェイルオーバーが必要かどうかを判断するための調整方法が必要です。この調整を行うために、次のいずれかの調整方法を使用するようにブローカーを設定できます。
- Apache ZooKeeper 調整サービス。
- クラスター内の他のブローカーを使用してクォーラム投票を提供する組み込み型のブローカー調整。
15.1.4.1. 調整方法の選択
Red Hat では、Apache ZooKeeper 調整サービスを使用してブローカーのアクティブ化を調整することを推奨します。調整方法を選択するときは、両方の調整方法間のインフラストラクチャー要件とデータ整合性の管理の違いを理解することが役立ちます。
インフラストラクチャーの要件
- ZooKeeper 調整サービスを使用する場合は、単一のプライマリー/バックアップブローカーペアで操作できます。ただし、ブローカーが 1 つのノードへの接続を失った場合でも機能し続けることができるように、ブローカーを少なくとも 3 つの Apache ZooKeeper ノードに接続する必要があります。ブローカーに調整サービスを提供するために、他のアプリケーションで使用されている既存の ZooKeeper ノードを共有できます。Apache ZooKeeper の設定の詳細は、Apache ZooKeeper のドキュメントを参照してください。
- クラスター内の他の使用可能なブローカーを使用してクォーラム投票を提供する埋め込みブローカー調整を使用する場合は、3 つ以上のプライマリー/バックアップブローカーペアが必要です。3 つ以上のプライマリー/バックアップペアを使用することで、プライマリー/バックアップのブローカーのペアでレプリケーションが中断された場合に発生するクォーラム投票で、過半数の結果を得られるようになります。
データの整合性
- Apache ZooKeeper 調整サービスを使用する場合、ZooKeeper は各ブローカー上のデータのバージョンを追跡するため、ブローカーがレプリケーションの目的でプライマリーブローカーとして設定されているか、バックアップブローカーとして設定されているかに関係なく、最新のジャーナルデータを持つブローカーだけがアクティブになります。バージョンの追跡により、ブローカーが期限切れのジャーナルでアクティブ化され、クライアントへのサービスを開始する可能性がなくなります。
- 組み込みブローカー調整を使用する場合、各ブローカーのデータのバージョンを追跡して、最新のジャーナルを持つブローカーだけがアクティブになるようにするメカニズムは存在しません。したがって、古いジャーナルを持つブローカーがアクティブになり、クライアントへのサービスを開始する可能性があり、これによりジャーナルに相違が生じます。
15.1.4.2. レプリケーションの中断後にブローカーが調整する方法
このセクションでは、レプリケーション接続が中断された後、両方の調整方法がどのように機能するかを説明します。
ZooKeeper 調整サービスの使用
ZooKeeper 調整サービスを使用してレプリケーションの中断を管理する場合、両方のブローカーが複数の Apache ZooKeeper ノードに接続されている必要があります。
- アクティブブローカーが ZooKeeper ノードの大部分との接続を失った場合はいつでも、、「スプリットブレイン」が発生するリスクを回避するためにシャットダウンします。
- いつでも、バックアップブローカーが ZooKeeper ノードの大部分への接続を失った場合、レプリケーションデータの受信を停止し、ZooKeeper ノードの大部分に接続できるようになるまで待機してから、バックアップブローカーとして再び機能します。過半数の ZooKeeper ノードへの接続が復元されると、バックアップブローカーは ZooKeeper を使用して、データを破棄してレプリケート元のアクティブブローカーを検索する必要があるかどうか、または現在のデータを使用してアクティブブローカーになることができるかどうかを判断します。
ZooKeeper は、以下の制御メカニズムを使用してフェイルオーバープロセスを管理します。
- 一度に 1 つのアクティブなブローカーのみが所有できる共有リースロック。
- ブローカーデータの最新バージョンを追跡する起動シーケンスカウンター。各ブローカーは、NodeID とともに、サーバーロックファイルに保存されているローカルカウンター内のジャーナルデータのバージョンを追跡します。また、アクティブブローカーは、ZooKeeper の調整されたアクティベーションシーケンスカウンターでもそのバージョンを共有します。
アクティブブローカーとバックアップブローカー間のレプリケーション接続が失われた場合、アクティブブローカーは、最新のデータがあることをアドバタイズするために、ローカルアクティベーションシーケンスカウンター値と ZooKeeper 上の調整されたアクティベーションシーケンスカウンター値の両方を 1 増やします。バックアップブローカーのデータは古くなったと見なされ、レプリケーション接続が復元されて最新のデータが同期されるまで、ブローカーはアクティブブローカーになることはできません。
レプリケーション接続が失われた後、バックアップブローカーは、ZooKeeper ロックがアクティブブローカーによって所有されているかどうか、および ZooKeeper 上の調整されたアクティベーションシーケンスカウンターがローカルカウンター値と一致しているかどうかを確認します。
- ロックがアクティブブローカーによって所有されている場合、バックアップブローカーは、レプリケーション接続が失われたときに、ZooKeeper 上のアクティベーションシーケンスカウンターがアクティブブローカーによって更新されたことを検出します。これは、アクティブブローカーが実行中であるため、バックアップブローカーがフェイルオーバーを試行しないことを示します。
- ロックがアクティブブローカーによって所有されていない場合、アクティブブローカーは動作していません。バックアップブローカーのアクティベーションシーケンスカウンターの値が、ZooKeeper の調整されたアクティベーションシーケンスカウンターの値と同じである場合、バックアップブローカーに最新のデータがあることを示し、バックアップブローカーはフェイルオーバーします。
- ロックがアクティブブローカーによって所有されていないが、バックアップブローカーのアクティベーションシーケンスカウンターの値が ZooKeeper のカウンター値より小さい場合、バックアップブローカーのデータは最新ではなく、バックアップブローカーはフェイルオーバーできません。
組み込みブローカー調整の使用
プライマリー/バックアップブローカーのペアが組み込みブローカー調整を使用してレプリケーションの中断を調整する場合、次の 2 種類のクォーラム投票を開始できます。
| 投票タイプ | 説明 | イニシエーター | 必要な設定 | 参加者 | 投票の結果に基づくアクション |
|---|---|---|---|---|---|
| パッシブ投票 | パッシブブローカーがアクティブブローカーへのレプリケーション接続を失った場合、パッシブブローカーはこの投票の結果に基づいて起動するかどうかを決定します。 | パッシブブローカー | なし。パッシブブローカーがレプリケーションパートナーとの接続を失うと、パッシブ投票が自動的に行われます。 ただし、これらのパラメーターにカスタム値を指定することにより、パッシブ投票のプロパティーを制御できます。
| クラスター内の他のアクティブなブローカー | パッシブブローカーは、レプリケーションパートナーが利用できなくなったことを示すクラスター内の他のアクティブブローカーから過半数 (つまり クォーラム) の投票を受け取ると起動します。 |
| アクティブ投票 | アクティブブローカーがレプリケーションパートナーへの接続を失った場合、アクティブブローカーはこの投票に基づいて実行を継続するかどうかを決定します。 | アクティブブローカー |
投票は、アクティブなブローカー (フェイルオーバーしたバックアップとして設定されたブローカーなど) がレプリケーションパートナーとの接続を失い、 | クラスター内の他のアクティブなブローカー | クラー内の他のアクティブなブローカーから、クラスター接続が引き続き有効であることを示す過半数の投票を 受け取れなかった 場合、アクティブブローカーはシャットダウンします。 |
以下は、ブローカークラスターの設定がクォーラム投票の動作にどのように影響するかについて留意すべき重要な事項になります。
- クォーラム評価を成功させるには、クラスターのサイズで、過半数の結果が得られる必要があります。したがって、クラスターには 少なくとも 3 つ のプライマリー/バックアップブローカーのペアが必要です。
- クラスターに追加するプライマリー/バックアップブローカーのペアの数が増えるほど、クラスターの全体的なフォールトトレランスが向上します。たとえば、プライマリー/バックアップのペアが 3 つあるとします。プライマリー/バックアップペアが完全に失われた場合、残りの 2 つのプライマリー/バックアップペアは、その後のクォーラム投票で過半数の結果を達成できません。この状況は、クラスター内でさらにレプリケーションが中断されると、プライマリーブローカーがシャットダウンし、バックアップブローカーが起動できなくなる可能性があることを意味します。例えば 5 組のブローカペアでクラスターを設定することで、クラスターでは少なくとも 2 つの障害が発生することができますが、それでもクォーラム投票で過半数の結果を得ることができます。
- クラスター内のプライマリー/バックアップブローカーのペアの数を意図的に 減らす 場合、以前に設定された多数決のしきい値は自動的に減少しません。この間、レプリケーション接続が失われたためにトリガーされたクォーラムの評価は成功せず、クラスターがスプリットブレインに対してより脆弱になります。クラスターでクォーラム投票の過半数しきい値を再計算するには、まずクラスターから削除するプライマリー/バックアップのペアをシャットダウンします。次に、クラスター内の残りのプライマリー/バックアップのペアを再起動します。残りのブローカーがすべて再起動すると、クラスターはクォーラム評価しきい値を再計算します。
15.1.4.3. ZooKeeper 調整サービスを使用したブローカークラスターのレプリケーションの設定
Apache ZooKeeper 調整サービスを使用するペアの両方のブローカーには、同じレプリケーション設定を指定する必要があります。次にブローカーは調整して、どのブローカーがアクティブブローカーで、どのブローカーがパッシブバックアップブローカーであるかを決定します。
前提条件
- 少なくとも 3 つの Apache ZooKeeper ノード。1 つのノードへの接続が失われた場合でもブローカーが動作を継続できるようにします。
- ブローカーマシンは同様のハードウェア仕様を持っています。つまり、任意の時点でマシンがアクティブブローカーを実行し、どのマシンがバックアップブローカーを実行するかを優先する必要はありません。
- ZooKeeper には、一時停止時間が ZooKeeper サーバーのティック時間よりも大幅に短くなるように十分なリソースが必要です。ブローカーの予想される負荷に応じて、ブローカーと ZooKeeper ノードが同じノードを共有できるかどうかを慎重に検討してください。詳細は、https://zookeeper.apache.org/ を参照してください。
手順
-
ペアの両方のブローカーの
<broker_instance_dir>/etc/broker.xml設定ファイルを開きます。 ペアの両方のブローカーに同じレプリケーション設定を設定します。以下に例を示します。
<configuration> <core> ... <ha-policy> <replication> <primary> <coordination-id>production-001</coordination-id> <manager> <properties> <property key="connect-string" value="192.168.1.10:6666,192.168.2.10:6667,192.168.3.10:6668"/> </properties> </manager> </primary> </replication> </ha-policy> ... </core> </configuration>プライマリー- レプリケーションタイプをプライマリーとして設定し、ブローカー調整の結果に応じてどちらのブローカーもプライマリーブローカーになれることを示します。
Coordination-id-
両方のブローカーに共通の文字列値を指定します。同じ
Coordination-id文字列を持つブローカーは、アクティベーションをともに調整します。調整プロセス中、両方のブローカーはCoordination-id文字列をノード ID として使用し、ZooKeeper でロックを取得しようとします。ロックを取得し、最新のデータを持つ最初のブローカーはアクティブブローカーとして起動し、他のブローカーはパッシブバックアップになります。 propertiesZooKeeper ノードの接続の詳細を提供するキーと値のペアのセットを指定できる
property要素を指定します。Expand 表15.2 ZooKeeper の接続の詳細 キー 値 connect-string
ZooKeeper ノードの IP アドレスとポート番号のコンマ区切りのリストを指定します。たとえば、
value="192.168.1.10:6666,192.168.2.10:6667,192.168.3.10:6668"です。session-ms
ZooKeeper ノードの大部分への接続が失われた後、ブローカーがシャットダウンするまでの待機時間。デフォルト値は
18000ミリ秒です。有効な値は、ZooKeeper サーバーのティック時間の 2 倍から 20 倍までの間です。注記ZooKeeper のハートビートが確実に機能するためには、ガベージコレクションのための ZooKeeper の一時停止時間を
session-msプロパティー値の 0.33 未満にする必要があります。一時停止時間をこの制限よりも短くすることができない場合は、各ブローカーのsession-msプロパティー値を増やし、より遅いフェイルオーバーを受け入れます。重要ブローカーレプリケーションパートナーは、2 秒ごとに自動的に "ping" パケットを交換し、パートナーブローカーが利用可能であることを確認します。バックアップブローカーがアクティブブローカーから応答を受信しない場合、バックアップはブローカーの接続の Time-to-live (TTL) が期限切れになるまで応答を待ちます。デフォルトの connection-ttl は
60000ミリ秒です。これは、バックアップブローカが 60 秒後にフェイルオーバーを試みることを意味します。フェイルオーバーを高速化するために、connection-ttl 値をsession-msプロパティー値と同様の値に設定することを推奨します。新しい connection-ttl を設定するには、connection-ttl-overrideプロパティーを設定します。namespace (オプション)
ブローカーが他のアプリケーションと ZooKeeper ノードを共有する場合、ブローカーに調整サービスを提供するファイルを格納する ZooKeeper namespace を作成することができます。両方のブローカーに同じ namespace を指定する必要があります。
ブローカーの追加の HA プロパティーを設定します。
これらの追加の HA プロパティーには、最も一般的なユースケースに適したデフォルト値があります。そのため、デフォルト動作が必要ない場合のみこのプロパティーを設定する必要があります。詳細は、付録F 追加のレプリケーションの高可用性設定要素 を参照してください。
- ステップ 1 - 3 を繰り返して、クラスター内の各追加ブローカーペアを設定します。
関連情報
- HA のためにレプリケーションを使用するブローカークラスターの例は、HA の例 を参照してください。
- ノード ID の詳細は、Understanding node IDs を参照してください。
15.1.4.4. 組み込みのブローカー調整を使用したレプリケーションの高可用性のためのブローカークラスターの設定
組み込みブローカー調整を使用したレプリケーションでは、「スプリットブレイン」のリスクを軽減する (排除はしない) ために、3 つ以上のプライマリーバックアップペアが必要です。
以下の手順では、6 つのブローカークラスターにレプリケーションの高可用性 (HA) を設定する方法を説明します。このトポロジーでは、6 つのブローカーが 3 つのプライマリー/バックアップブローカーのペアにグループ化されます。3 つのプライマリーブローカーのそれぞれが専用のバックアップブローカーとペアになります。
前提条件
6 つ以上のブローカーを持つブローカークラスターが必要です。
6 つのブローカーは、3 つのプライマリー/バックアップペアに設定されます。ブローカーのクラスターへの追加に関する詳細は、14章ブローカークラスターの設定 を参照してください。
手順
クラスター内のブローカーをプライマリー/バックアップグループにグループ化します。
ほとんどの場合、プライマリー/バックアップグループは、プライマリーブローカーとバックアップブローカーの 2 つのブローカーで構成される必要があります。クラスター内にブローカーが 6 つある場合は、プライマリー/バックアップグループが 3 つ必要です。
1 つのプライマリーブローカーと 1 つのバックアップブローカーで構成される最初のプライマリー/バックアップグループを作成します。
-
プライマリーブローカーの
<broker_instance_dir>/etc/broker.xml設定ファイルを開きます。 プライマリーブローカーを、HA ポリシーのレプリケーションを使用するように設定します。
<configuration> <core> ... <ha-policy> <replication> <primary> <check-for-active-server>true</check-for-active-server> <group-name>my-group-1</group-name> <vote-on-replication-failure>true</vote-on-replication-failure> ... </primary> </replication> </ha-policy> ... </core> </configuration>check-for-active-serverプライマリーブローカーが失敗すると、このプロパティーは、再起動時にクライアントがフェイルバックするかどうかを制御します。
このプロパティーを
trueに設定すると、以前のフェイルオーバー後にプライマリーブローカーが再起動すると、同じノード ID を持つクラスター内の別のブローカーを検索します。プライマリーブローカーが同じノード ID を持つ別のブローカーを見つけた場合、これは、プライマリーブローカーの障害時にバックアップブローカーが正常に起動したことを示しています。この場合、プライマリーブローカーはデータをバックアップブローカーと同期します。その後、プライマリーブローカーはバックアップブローカーにシャットダウンを要求します。以下に示すように、バックアップブローカーがフェイルバック用に設定されている場合、シャットダウンします。続いて、プライマリーブローカーはアクティブなロールを再開し、クライアントはこれに再接続します。警告プライマリーブローカーで
check-for-active-serverをtrueに設定しないと、以前のフェイルオーバー後にプライマリーブローカーを再起動したときに、メッセージ処理が重複する可能性があります。具体的には、このプロパティーをfalseに設定してプライマリーブローカーを再起動すると、プライマリーブローカーはバックアップブローカーとデータを同期しません。この場合、プライマリーブローカーはバックアップブローカーがすでに処理した同じメッセージを処理し、重複が発生する可能性があります。group-name- このプライマリー/バックアップグループの名前 (オプション)。プライマリー/バックアップグループを形成するには、プライマリーブローカーとバックアップブローカーを同じグループ名で設定する必要があります。group-name を指定しない場合、バックアップブローカーは任意のプライマリーブローカーとレプリケーションを行うことができます。
vote-on-replication-failureこのプロパティーは、レプリケーション接続が中断された場合にプライマリーブローカーが プライマリー投票 と呼ばれるクォーラム投票を開始するかどうかを制御します。
プライマリー投票は、プライマリーブローカーが、中断されたレプリケーション接続の原因が自分自身かそのパートナーかを判断する方法です。投票の結果に基づいて、プライマリーブローカーは稼働を継続するか、シャットダウンするかが決定されます。
重要クォーラム評価を成功させるには、クラスターのサイズで、過半数の結果が得られる必要があります。したがって、レプリケーション HA ポリシーを使用する場合は、クラスターに 少なくとも 3 つ のプライマリー/バックアップブローカーペアが必要です。
クラスターに設定するブローカーのペアが多いほど、クラスターの全体的なフォールトトレランスが向上します。たとえば、プライマリー/バックアップブローカーのペアが 3 つあるとします。完全なプライマリー/バックアップペアへの接続が失われた場合、残りの 2 つのプライマリー/バックアップペアはクォーラム投票で過半数の結果を達成できなくなります。この状況は、その後のレプリケーションの中断によりプライマリーブローカーがシャットダウンし、バックアップブローカーが起動できなくなる可能性があることを意味します。例えば 5 組のブローカペアでクラスターを設定することで、クラスターでは少なくとも 2 つの障害が発生することができますが、それでもクォーラム投票で過半数の結果を得ることができます。
プライマリーブローカーの追加の HA プロパティーを設定します。
これらの追加の HA プロパティーには、最も一般的なユースケースに適したデフォルト値があります。そのため、デフォルト動作が必要ない場合のみこのプロパティーを設定する必要があります。詳細は、付録F 追加のレプリケーションの高可用性設定要素 を参照してください。
-
バックアップブローカーの
<broker_instance_dir> /etc/broker.xml設定ファイルを開きます。 HA ポリシーのレプリケーションを使用するようにバックアップブローカーを設定します。
<configuration> <core> ... <ha-policy> <replication> <backup> <allow-failback>true</allow-failback> <group-name>my-group-1</group-name> <vote-on-replication-failure>true</vote-on-replication-failure> ... </backup> </replication> </ha-policy> ... </core> </configuration>allow-failbackフェイルオーバーが発生し、バックアップブローカーがプライマリーブローカーを引き継いだ場合、このプロパティーは、バックアップブローカーが再起動してクラスターに再接続したときに、元のプライマリーブローカにフェイルバックするかどうかを制御します。
注記フェイルバックは、プライマリー/バックアップのペア (1 つのプライマリーブローカーと 1 つのバックアップブローカーのペア) を対象としています。プライマリーブローカーに複数のバックアップが設定されている場合、フェイルバックは発生しません。代わりに、フェイルオーバーイベントが発生すると、バックアップブローカーはアクティブになり、次のバックアップがバックアップになります。プライマリーブローカーがオンラインに戻ったとき、現在アクティブなブローカーにはすでにバックアップがあるため、フェイルバックを開始することはできません。
group-name- このプライマリー/バックアップグループの名前 (オプション)。プライマリー/バックアップグループを形成するには、プライマリーブローカーとバックアップブローカーを同じグループ名で設定する必要があります。group-name を指定しない場合、バックアップブローカーは任意のプライマリーブローカーとレプリケーションを行うことができます。
vote-on-replication-failureこのプロパティーは、レプリケーション接続が中断された場合に、アクティブになったバックアップブローカーが プライマリー投票 と呼ばれるクォーラム投票を開始できるかどうかを制御します。
プライマリー投票は、プライマリーブローカーが、中断されたレプリケーション接続の原因が自分自身かそのパートナーかを判断する方法です。投票の結果に基づいて、プライマリーブローカーは稼働を継続するか、シャットダウンするかが決定されます。
( 任意設定 ) バックアップブローカーが開始するクォーラム票のプロパティーを設定します。
<configuration> <core> ... <ha-policy> <replication> <backup> ... <vote-retries>12</vote-retries> <vote-retry-wait>5000</vote-retry-wait> ... </backup> </replication> </ha-policy> ... </core> </configuration>vote-retries- このプロパティーは、バックアップブローカーの起動を可能にする大部分の結果を受信するために、バックアップブローカーがクォーラム評価を再試行する回数を制御します。
vote-retry-wait- このプロパティーは、バックアップブローカーがクォーラム評価の再試行ごとに待機する期間 ( ミリ秒単位 ) を制御します。
バックアップブローカーの追加の HA プロパティーを設定します。
これらの追加の HA プロパティーには、最も一般的なユースケースに適したデフォルト値があります。そのため、デフォルト動作が必要ない場合のみこのプロパティーを設定する必要があります。詳細は、付録F 追加のレプリケーションの高可用性設定要素 を参照してください。
-
プライマリーブローカーの
クラスター内の追加のプライマリー/バックアップグループごとにステップ 2 を繰り返します。
クラスター内にブローカーが 6 つある場合は、この手順をさらに 2 回繰り返します (残りのプライマリー/バックアップグループごとに 1 回ずつ)。
関連情報
- HA のためにレプリケーションを使用するブローカークラスターの例は、HA の例 を参照してください。
- ノード ID の詳細は、Understanding node IDs を参照してください。
15.1.5. プライマリーのみで限定的な高可用性を設定する
プライマリーのみの HA ポリシーを使用すると、メッセージを失うことなくクラスター内のブローカーをシャットダウンできます。プライマリーのみの場合、アクティブなブローカーが正常に停止されると、そのメッセージとトランザクション状態が別のアクティブなブローカーにコピーされてからシャットダウンされます。その後、クライアントは他のブローカーに再接続し、メッセージの送受信を続行します。
プライマリーのみの HA ポリシーは、ブローカーが正常に停止された場合にのみケースを処理します。予期しないブローカーの失敗を処理しません。
プライマリーのみの HA では、メッセージの損失は阻止されますが、メッセージの順序は維持されない可能性があります。プライマリーのみの HA で設定されたブローカーが停止すると、そのメッセージは別のブローカーのキューの最後に追加されます。
ブローカーがスケールダウンする準備時に、接続が切断される前に、新しいブローカーがメッセージを処理する準備ができていることを通知する前に、メッセージをクライアントに送信します。ただし、クライアントは、初期ブローカーがスケールダウンされた後にのみ新しいブローカーに再接続する必要があります。これにより、キューやトランザクションなどの状態が、クライアントが再接続する際に他のブローカーで利用可能になります。通常の再接続設定はクライアントが再接続する際に適用されるため、スケールダウンに必要な時間を処理するのに十分な時間を設定する必要があります。
この手順では、クラスター内の各ブローカーをスケールダウンするように設定する方法を説明します。この手順を完了すると、ブローカーが正常に停止されるたびに、メッセージとトランザクションの状態がクラスター内の別のブローカーにコピーされます。
手順
-
最初のブローカーの
<broker_instance_dir> /etc/broker.xml設定ファイルを開きます。 プライマリーのみの HA ポリシーを使用するようにブローカーを設定します。
<configuration> <core> ... <ha-policy> <primary-only> </primary-only> </ha-policy> ... </core> </configuration>ブローカークラスターをスケールダウンする方法を設定します。
このブローカーがスケールダウンするブローカーのブローカーまたはグループを指定します。
Expand 表15.3 ブローカークラスターをスケールダウンする方法 スケールダウン 実行内容 クラスター内の特定のブローカー
スケールダウンするブローカーのコネクターを指定します。
<primary-only> <scale-down> <connectors> <connector-ref>broker1-connector</connector-ref> </connectors> </scale-down> </primary-only>クラスター内のすべてのブローカー
ブローカークラスターの検出グループを指定します。
<primary-only> <scale-down> <discovery-group-ref discovery-group-name="my-discovery-group"/> </scale-down> </primary-only>特定のブローカーグループのブローカー
ブローカーグループを指定します。
<primary-only> <scale-down> <group-name>my-group-name</group-name> </scale-down> </primary-only>- クラスター内の残りのブローカーごとに、この手順を繰り返します。
関連情報
-
プライマリーのみを使用してクラスターをスケールダウンするブローカークラスターの例は、
scale-downexample を参照してください。
15.1.6. コロケーションバックアップを使用した高可用性の設定
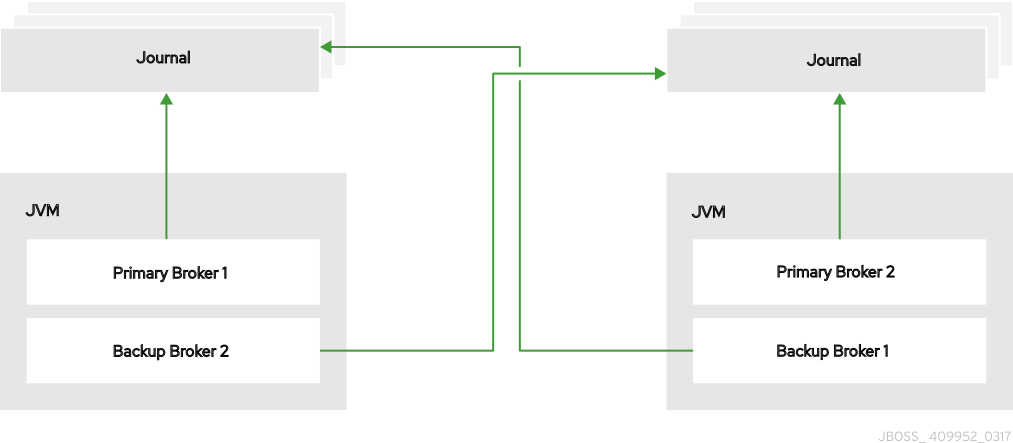
プライマリー/バックアップグループを設定する代わりに、バックアップブローカーを別のプライマリーブローカーと同じ JVM に配置できます。この設定では、各プライマリーブローカーが別のプライマリブローカーに対して、その JVM 内にバックアップブローカーを作成して起動するよう要求するように設定されています。
図15.4 プライマリーブローカーとバックアップブローカーのコロケーション
コロケーションは、共有ストアまたはレプリケーションのいずれかを高可用性 (HA) ポリシーとして使用できます。新しいバックアップブローカーは、それを作成したプライマリーブローカーから設定を継承します。バックアップの名前は、colocated_backup_n に設定されます。n は、プライマリーブローカーが作成したバックアップの数です。
さらに、バックアップブローカーは、それを作成したプライマリーブローカーからコネクターとアクセプターの設定を継承します。デフォルトでは、ポートオフセット 100 がそれぞれに適用されます。たとえば、プライマリーブローカーにポート 61616 のアクセプターがある場合、最初に作成されたバックアップブローカーはポート 61716 を使用し、2 番目のバックアップはポート 61816 を使用する、というようになります。
ジャーナル、大きなメッセージ、ページングのディレクトリーは、選択した HA ポリシーに従って設定されます。共有ストアを選択する場合、要求ブローカーはターゲットブローカーに対し、使用するディレクトリーを通知します。レプリケーションが選択されている場合、ディレクトリーは作成ブローカーから継承され、新しいバックアップの名前が追加されます。
この手順では、共有のストア HA を使用するようにクラスター内の各ブローカーを設定し、バックアップを作成してクラスター内の別のブローカーと共存させるよう要求します。
手順
-
最初のブローカーの
<broker_instance_dir> /etc/broker.xml設定ファイルを開きます。 HA ポリシーとコロケーションを使用するようにブローカーを設定します。
この例では、ブローカーは共有ストア HA およびコロケーションで設定されます。
<configuration> <core> ... <ha-policy> <shared-store> <colocated> <request-backup>true</request-backup> <max-backups>1</max-backups> <backup-request-retries>-1</backup-request-retries> <backup-request-retry-interval>5000</backup-request-retry-interval/> <backup-port-offset>150</backup-port-offset> <excludes> <connector-ref>remote-connector</connector-ref> </excludes> <primary> <failover-on-shutdown>true</failover-on-shutdown> </primary> <backup> <failover-on-shutdown>true</failover-on-shutdown> <allow-failback>true</allow-failback> <restart-backup>true</restart-backup> </backup> </colocated> </shared-store> </ha-policy> ... </core> </configuration>request-backup-
このプロパティーを
trueに設定すると、このブローカーはクラスター内の別のプライマリーブローカーによって作成されるバックアップブローカーを要求します。 max-backups-
このブローカーが作成できるバックアップブローカーの数。このプロパティーを
0に設定すると、このブローカーはクラスターの他のブローカーからのバックアップ要求を受け入れません。 backup-request-retries-
このブローカーがバックアップブローカーの作成を要求する回数。デフォルトは、無制限を意味する
-1です。 backup-request-retry-interval-
バックアップブローカーを作成する要求を再試行する前にブローカーが待機する時間 ( ミリ秒単位 )。デフォルトは
5000(5 秒) です。 backup-port-offset-
新しいバックアップブローカーにアクセプターおよびコネクターに使用するポートオフセット。このブローカーがクラスター内の別のブローカーのバックアップを作成する要求を受信すると、この量によってポートオフセットでバックアップブローカーが作成されます。デフォルトは
100です。 excludes( オプション )-
バックアップポートのオフセットからコネクターを除外します。バックアップポートのオフセットから除外する必要のある外部ブローカーのコネクターを設定している場合は、コネクターごとに
<connector-ref>を追加します。 プライマリー- このブローカーの共有ストアまたはレプリケーションフェイルオーバーの設定。
backup- このブローカーのバックアップの共有ストアまたはレプリケーションのフェイルオーバー設定。
- クラスター内の残りのブローカーごとに、この手順を繰り返します。
関連情報
- コロケーションバックアップを使用するブローカークラスターの例は、HA の例 を参照してください。