1.2. Debezium アーキテクチャーの説明
Apache Kafka Connect を使用して Debezium をデプロイします。Kafka Connect は、以下を実装および操作するためのフレームワークおよびランタイムです。
- レコードを Kafka に送信する Debezium などのソースコネクター
- Kafka トピックから他のシステムにレコードを伝播する Sink コネクター
以下の図は、Debezium をベースとした Change Data Capture パイプラインのアーキテクチャーを示しています。
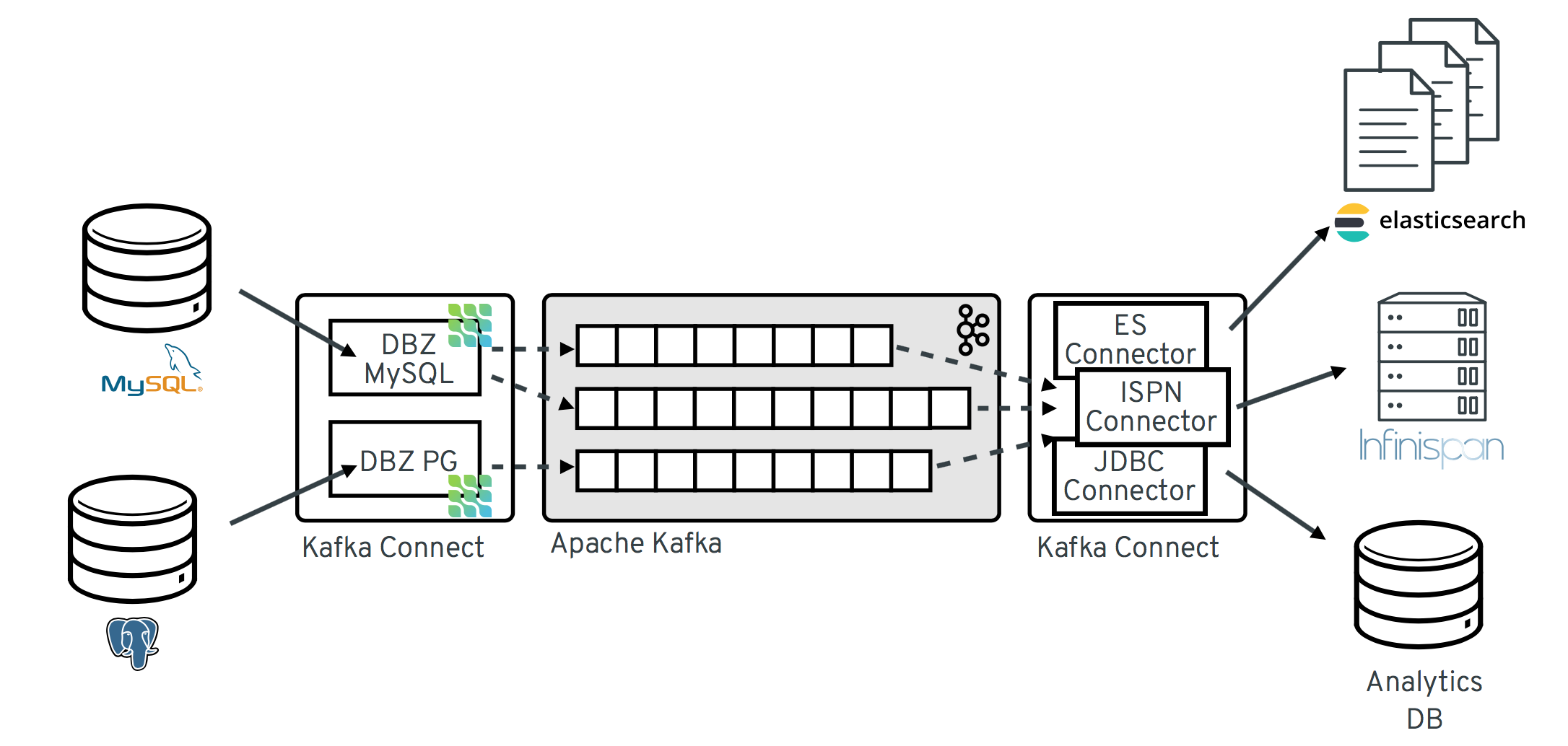
イメージにあるように、MySQL と PostgresSQL の Debezium コネクターは、この 2 種類のデータベースへの変更をキャプチャーするためにデプロイされます。各 Debezium コネクターは、そのソースデータベースへの接続を確立します。
-
MySQL コネクターは、
binlogへのアクセスにクライアントライブラリーを使用します。 - PostgreSQL コネクターは論理レプリケーションストリームから読み取ります。
Kafka Connect は、Kafka ブローカー以外の別のサービスとして動作します。
デフォルトでは、1 つのデータベースからの変更が、名前がテーブル名に対応する Kafka トピックに書き込まれます。必要な場合は、Debezium の トピックルーティング変換 を設定すると、宛先トピック名を調整できます。たとえば、以下を実行できます。
- テーブルの名前と名前が異なるトピックへレコードをルーティングする。
- 複数テーブルの変更イベントレコードを単一のトピックにストリーミングする。
変更イベントレコードが Apache Kafka に存在する場合、Kafka Connect エコシステムの異なるコネクターは、Elasticsearch、データウェアハウス、分析システムなどのその他のシステムおよびデータベースや、Infinispan などのキャッシュにレコードをストリーミングできます。選択した sink コネクターによっては、Debezium の 新しいレコード状態の抽出 (Record State Extraction) の変換を設定する必要がある場合があります。この Kafka Connect SMT は、Debezium の変更イベントから sink コネクターに after 構造を伝播します。これは、デフォルトで伝播される詳細な変更イベントレコードの代わりになります。