このコンテンツは選択した言語では利用できません。
5.9. Creating Dispersed Volumes
Dispersed volumes are based on erasure coding. Erasure coding (EC) is a method of data protection in which data is broken into fragments, expanded and encoded with redundant data pieces and stored across a set of different locations. This allows the recovery of the data stored on one or more bricks in case of failure. The number of bricks that can fail without losing data is configured by setting the redundancy count.
Dispersed volume requires less storage space when compared to a replicated volume. It is equivalent to a replicated pool of size two, but requires 1.5 TB instead of 2 TB to store 1 TB of data when the redundancy level is set to 2. In a dispersed volume, each brick stores some portions of data and parity or redundancy. The dispersed volume sustains the loss of data based on the redundancy level.
Important
Dispersed volume configuration is supported only on JBOD storage. For more information, see Section 20.1.2, “JBOD”.
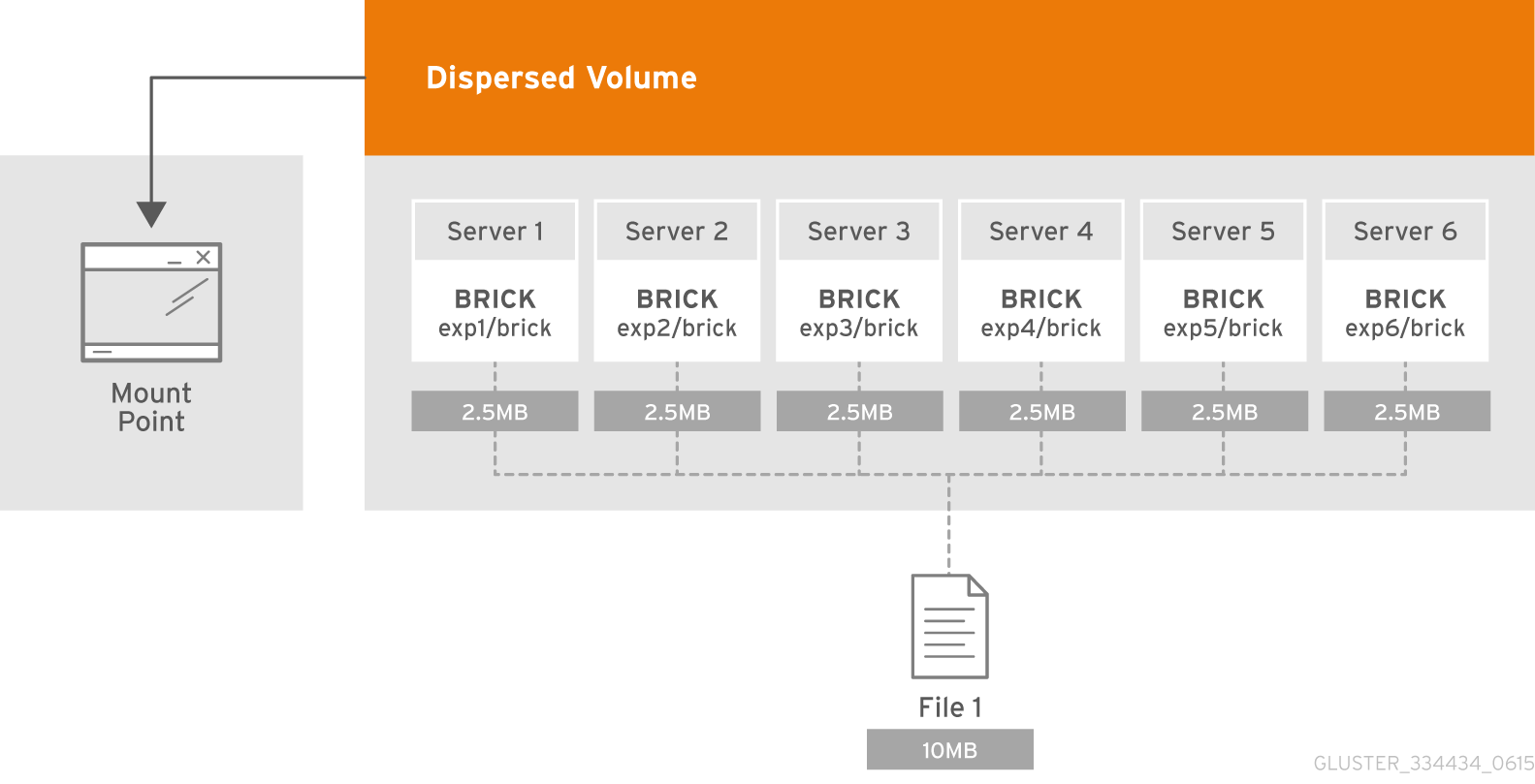
Figure 5.7. Illustration of a Dispersed Volume
The data protection offered by erasure coding can be represented in simple form by the following equation:
n = k + m. Here n is the total number of bricks, we would require any k bricks out of n bricks for recovery. In other words, we can tolerate failure up to any m bricks. With this release, the following configurations are supported:
- 6 bricks with redundancy level 2 (4 + 2)
- 10 bricks with redundancy level 2 (8 + 2)
- 11 bricks with redundancy level 3 (8 + 3)
- 12 bricks with redundancy level 4 (8 + 4)
- 20 bricks with redundancy level 4 (16 + 4)
For optimal fault tolerance, create each brick on a separate server. Creating multiple bricks on a single server is supported, but the more bricks there are on a single server, the greater the risk to availability and consistency when that single server becomes unavailable.
Use
gluster volume create to create different types of volumes, and gluster volume info to verify successful volume creation.
Prerequisites
- Create a trusted storage pool as described in Section 4.1, “Adding Servers to the Trusted Storage Pool”.
- Understand how to start and stop volumes, as described in Section 5.11, “Starting Volumes”.
Important
Red Hat recommends you to review the Dispersed Volume configuration recommendations explained in Section 5.9, “Creating Dispersed Volumes” before creating the Dispersed volume.
To Create a dispersed volume
- Run the
gluster volume createcommand to create the dispersed volume.The syntax is# gluster volume create NEW-VOLNAME [disperse-data COUNT] [redundancy COUNT] [transport tcp | rdma | tcp,rdma] NEW-BRICK...The number of bricks required to create a disperse volume is the sum ofdisperse-data countandredundancy count.Thedisperse-datacountoption specifies the number of bricks that is part of the dispersed volume, excluding the count of the redundant bricks. For example, if the total number of bricks is 6 andredundancy-countis specified as 2, then the disperse-data count is 4 (6 - 2 = 4). If thedisperse-data countoption is not specified, and only theredundancy countoption is specified, then thedisperse-data countis computed automatically by deducting the redundancy count from the specified total number of bricks.Redundancy determines how many bricks can be lost without interrupting the operation of the volume. Ifredundancy countis not specified, based on the configuration it is computed automatically to the optimal value and a warning message is displayed.The default value for transport istcp. Other options can be passed such asauth.alloworauth.reject. See Section 5.3, “About Encrypted Disk” for a full list of parameters.Example 5.11. Dispersed Volume with Six Storage Servers
# gluster volume create test-volume disperse-data 4 redundancy 2 transport tcp server1:/rhgs1/brick1 server2:/rhgs2/brick2 server3:/rhgs3/brick3 server4:/rhgs4/brick4 server5:/rhgs5/brick5 server6:/rhgs6/brick6 Creation of test-volume has been successful Please start the volume to access data. - Run
# gluster volume start VOLNAMEto start the volume.# gluster volume start test-volume Starting test-volume has been successfulImportant
Theopen-behindvolume option is enabled by default. If you are accessing the dispersed volume using the SMB protocol, you must disable theopen-behindvolume option to avoid performance bottleneck on large file workload. Run the following command to disableopen-behindvolume option:# gluster volume set VOLNAME open-behind offFor information onopen-behindvolume option, see Section 11.1, “Configuring Volume Options” - Run
gluster volume infocommand to optionally display the volume information.