このコンテンツは選択した言語では利用できません。
5.8. Creating Arbitrated Replicated Volumes
Advantages of arbitrated replicated volumes
- Better consistency
- When an arbiter is configured, arbitration logic uses client-side quorum in auto mode to prevent file operations that would lead to split-brain conditions.
- Less disk space required
- Because an arbiter brick only stores file names and metadata, an arbiter brick can be much smaller than the other bricks in the volume.
- Fewer nodes required
- The node that contains the arbiter brick of one volume can be configured with the data brick of another volume. This "chaining" configuration allows you to use fewer nodes to fulfill your overall storage requirements.
- Easy migration from deprecated two-way replicated volumes
- Red Hat Gluster Storage can convert a two-way replicated volume without arbiter bricks into an arbitrated replicated volume. See Section 5.8.5, “Converting to an arbitrated volume” for details.
Limitations of arbitrated replicated volumes
- Arbitrated replicated volumes provide better data consistency than a two-way replicated volume that does not have arbiter bricks. However, because arbitrated replicated volumes store only metadata, they provide the same level of availability as a two-way replicated volume that does not have arbiter bricks. To achieve high-availability, you need to use a three-way replicated volume instead of an arbitrated replicated volume.
- Tiering is not compatible with arbitrated replicated volumes.
- Arbitrated volumes can only be configured in sets of three bricks at a time. Red Hat Gluster Storage can convert an existing two-way replicated volume without arbiter bricks into an arbitrated replicated volume by adding an arbiter brick to that volume. See Section 5.8.5, “Converting to an arbitrated volume” for details.
5.8.1. Arbitrated volume requirements
5.8.1.1. System requirements for nodes hosting arbiter bricks
| Configuration type | Min CPU | Min RAM | NIC | Arbiter Brick Size | Max Latency |
|---|---|---|---|---|---|
| Dedicated arbiter | 64-bit quad-core processor with 2 sockets | 8 GB[a] | Match to other nodes in the storage pool | 1 TB to 4 TB[b] | 5 ms[c] |
| Chained arbiter | Match to other nodes in the storage pool | 1 TB to 4 TB[d] | 5 ms[e] | ||
[a]
More RAM may be necessary depending on the combined capacity of the number of arbiter bricks on the node.
[b]
Arbiter and data bricks can be configured on the same device provided that the data and arbiter bricks belong to different replica sets. See Section 5.8.1.2, “Arbiter capacity requirements” for further details on sizing arbiter volumes.
[c]
This is the maximum round trip latency requirement between all nodes irrespective of Aribiter node. See KCS#413623 to know how to determine latency between nodes.
[d]
Multiple bricks can be created on a single RAIDed physical device. Please refer the following product documentation: Section 20.2, “Brick Configuration”
[e]
This is the maximum round trip latency requirement between all nodes irrespective of Aribiter node. See KCS#413623 to know how to determine latency between nodes.
| |||||
- minimum 4 vCPUs
- minimum 16 GB RAM
- 1 TB to 4 TB of virtual disk space
- maximum 5 ms latency
5.8.1.2. Arbiter capacity requirements
minimum arbiter brick size = 4 KB * ( size in KB of largest data brick in volume or replica set / average file size in KB)minimum arbiter brick size = 4 KB * ( 1 TB / 2 GB )
= 4 KB * ( 1000000000 KB / 2000000 KB )
= 4 KB * 500 KB
= 2000 KB
= 2 MBminimum arbiter brick size = 4 KB * ( size in KB of largest data brick in volume or replica set / shard block size in KB )5.8.2. Arbitration logic
| Volume state | Arbitration behavior |
|---|---|
| All bricks available | All file operations permitted. |
| Arbiter and 1 data brick available |
If the arbiter does not agree with the available data node, write operations fail with ENOTCONN (since the brick that is correct is not available). Other file operations are permitted.
If the arbiter's metadata agrees with the available data node, all file operations are permitted.
|
| Arbiter down, data bricks available | All file operations are permitted. The arbiter's records are healed when it becomes available. |
| Only one brick available |
If the available brick is a data brick, client quorum is not met, and the volume enters an EROFS state.
If the available brick is the arbiter, all file operations fail with ENOTCONN.
|
5.8.3. Creating an arbitrated replicated volume
# gluster volume create VOLNAME replica 3 arbiter 1 HOST1:DATA_BRICK1 HOST2:DATA_BRICK2 HOST3:ARBITER_BRICK3Note
# gluster volume create testvol replica 3 arbiter 1 \
server1:/bricks/brick server2:/bricks/brick server3:/bricks/arbiter_brick \
server4:/bricks/brick server5:/bricks/brick server6:/bricks/arbiter_brick# gluster volume info testvol
Volume Name: testvol
Type: Distributed-Replicate
Volume ID: ed9fa4d5-37f1-49bb-83c3-925e90fab1bc
Status: Created
Snapshot Count: 0
Number of Bricks: 2 x (2 + 1) = 6
Transport-type: tcp
Bricks:
Brick1: server1:/bricks/brick
Brick2: server2:/bricks/brick
Brick3: server3:/bricks/arbiter_brick (arbiter)
Brick1: server4:/bricks/brick
Brick2: server5:/bricks/brick
Brick3: server6:/bricks/arbiter_brick (arbiter)
Options Reconfigured:
transport.address-family: inet
performance.readdir-ahead: on
nfs.disable: on
5.8.4. Creating multiple arbitrated replicated volumes across fewer total nodes
- Chain multiple arbitrated replicated volumes together, by placing the arbiter brick for one volume on the same node as a data brick for another volume. Chaining is useful for write-heavy workloads when file size is closer to metadata file size (that is, from 32–128 KiB). This avoids all metadata I/O going through a single disk.In arbitrated distributed-replicated volumes, you can also place an arbiter brick on the same node as another replica sub-volume's data brick, since these do not share the same data.
- Place the arbiter bricks from multiple volumes on a single dedicated node. A dedicated arbiter node is suited to write-heavy workloads with larger files, and read-heavy workloads.
Example 5.9. Example of a dedicated configuration
# gluster volume create firstvol replica 3 arbiter 1 server1:/bricks/brick server2:/bricks/brick server3:/bricks/arbiter_brick
# gluster volume create secondvol replica 3 arbiter 1 server4:/bricks/data_brick server5:/bricks/brick server3:/bricks/brick
Example 5.10. Example of a chained configuration
# gluster volume create arbrepvol replica 3 arbiter 1 server1:/bricks/brick1 server2:/bricks/brick1 server3:/bricks/arbiter_brick1 server2:/bricks/brick2 server3:/bricks/brick2 server4:/bricks/arbiter_brick2 server3:/bricks/brick3 server4:/bricks/brick3 server5:/bricks/arbiter_brick3 server4:/bricks/brick4 server5:/bricks/brick4 server6:/bricks/arbiter_brick4 server5:/bricks/brick5 server6:/bricks/brick5 server1:/bricks/arbiter_brick5 server6:/bricks/brick6 server1:/bricks/brick6 server2:/bricks/arbiter_brick6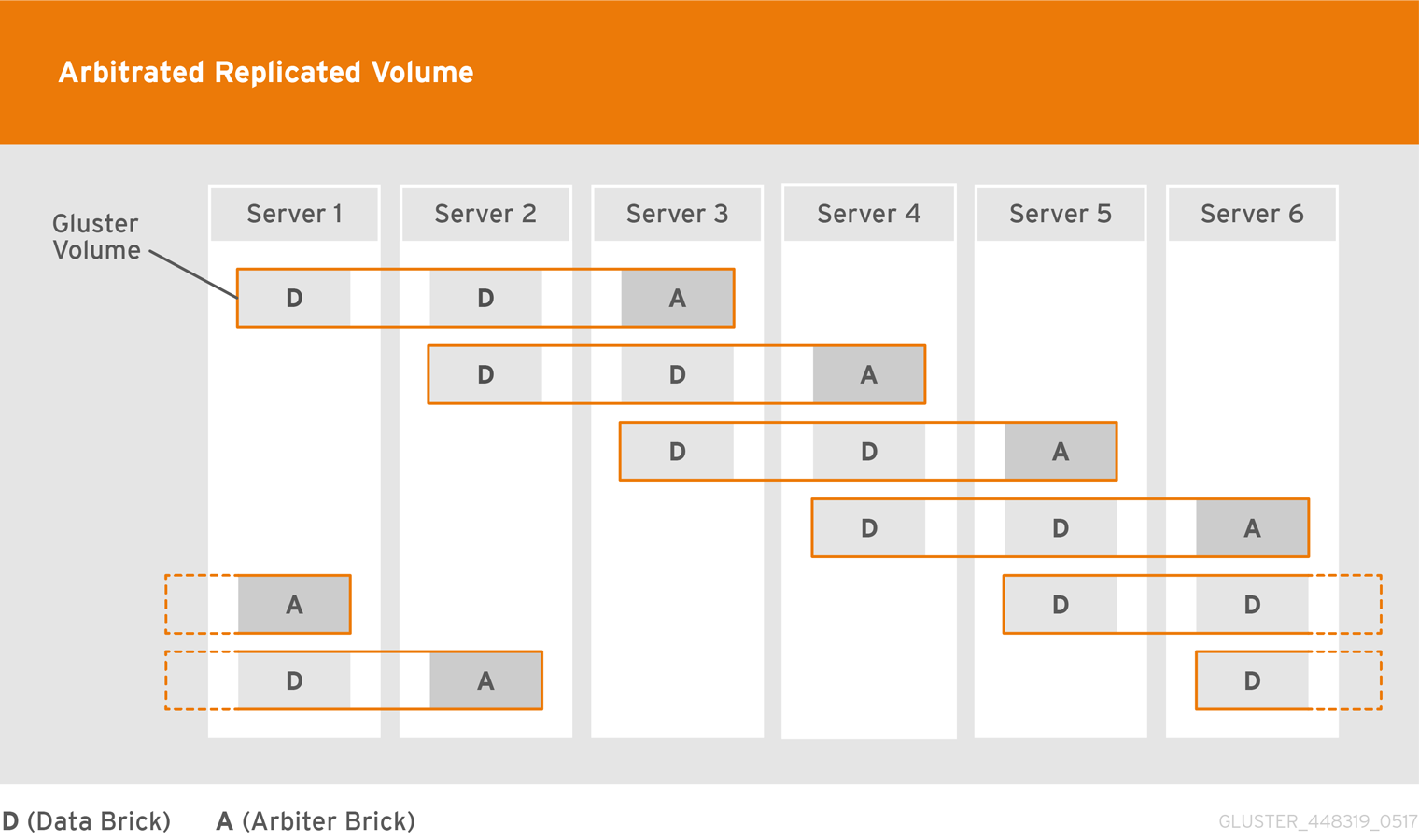
5.8.5. Converting to an arbitrated volume
Procedure 5.1. Converting a replica 2 volume to an arbitrated volume
Warning
Verify that healing is not in progress
# gluster volume heal VOLNAME infoWait until pending heal entries is0before proceeding.Disable and stop self-healing
Run the following commands to disable data, metadata, and entry self-heal, and the self-heal daemon.# gluster volume set VOLNAME cluster.data-self-heal off # gluster volume set VOLNAME cluster.metadata-self-heal off # gluster volume set VOLNAME cluster.entry-self-heal off # gluster volume set VOLNAME self-heal-daemon offAdd arbiter bricks to the volume
Convert the volume by adding an arbiter brick for each replicated sub-volume.# gluster volume add-brick VOLNAME replica 3 arbiter 1 HOST:arbiter-brick-pathFor example, if you have an existing two-way replicated volume called testvol, and a new brick for the arbiter to use, you can add a brick as an arbiter with the following command:# gluster volume add-brick testvol replica 3 arbiter 1 server:/bricks/arbiter_brickIf you have an existing two-way distributed-replicated volume, you need a new brick for each sub-volume in order to convert it to an arbitrated distributed-replicated volume, for example:# gluster volume add-brick testvol replica 3 arbiter 1 server1:/bricks/arbiter_brick1 server2:/bricks/arbiter_brick2Wait for client volfiles to update
This takes about 5 minutes.Verify that bricks added successfully
# gluster volume info VOLNAME # gluster volume status VOLNAMERe-enable self-healing
Run the following commands to re-enable self-healing on the servers.# gluster volume set VOLNAME cluster.data-self-heal on # gluster volume set VOLNAME cluster.metadata-self-heal on # gluster volume set VOLNAME cluster.entry-self-heal on # gluster volume set VOLNAME self-heal-daemon onVerify all entries are healed
# gluster volume heal VOLNAME infoWait until pending heal entries is0to ensure that all heals completed successfully.
Procedure 5.2. Converting a replica 3 volume to an arbitrated volume
Warning
Verify that healing is not in progress
# gluster volume heal VOLNAME infoWait until pending heal entries is0before proceeding.Reduce the replica count of the volume to 2
Remove one brick from every sub-volume in the volume so that the replica count is reduced to 2. For example, in a replica 3 volume that distributes data across 2 sub-volumes, run the following command:# gluster volume remove-brick VOLNAME replica 2 HOST:subvol1-brick-path HOST:subvol2-brick-path forceNote
In a distributed replicated volume, data is distributed across sub-volumes, and replicated across bricks in a sub-volume. This means that to reduce the replica count of a volume, you need to remove a brick from every sub-volume.Bricks are grouped by sub-volume in thegluster volume infooutput. If the replica count is 3, the first 3 bricks form the first sub-volume, the next 3 bricks form the second sub-volume, and so on.# gluster volume info VOLNAME [...] Number of Bricks: 2 x 3 = 6 Transport-type: tcp Bricks: Brick1: node1:/test1/brick Brick2: node2:/test2/brick Brick3: node3:/test3/brick Brick4: node1:/test4/brick Brick5: node2:/test5/brick Brick6: node3:/test6/brick [...]In this volume, data is distributed across two sub-volumes, which each consist of three bricks. The first sub-volume consists of bricks 1, 2, and 3. The second sub-volume consists of bricks 4, 5, and 6. Removing any one brick from each subvolume using the following command reduces the replica count to 2 as required.# gluster volume remove-brick VOLNAME replica 2 HOST:subvol1-brick-path HOST:subvol2-brick-path forceDisable and stop self-healing
Run the following commands to disable data, metadata, and entry self-heal, and the self-heal daemon.# gluster volume set VOLNAME cluster.data-self-heal off # gluster volume set VOLNAME cluster.metadata-self-heal off # gluster volume set VOLNAME cluster.entry-self-heal off # gluster volume set VOLNAME self-heal-daemon offAdd arbiter bricks to the volume
Convert the volume by adding an arbiter brick for each replicated sub-volume.# gluster volume add-brick VOLNAME replica 3 arbiter 1 HOST:arbiter-brick-pathFor example, if you have an existing replicated volume:# gluster volume add-brick testvol replica 3 arbiter 1 server:/bricks/brickIf you have an existing distributed-replicated volume:# gluster volume add-brick testvol replica 3 arbiter 1 server1:/bricks/arbiter_brick1 server2:/bricks/arbiter_brick2Wait for client volfiles to update
This takes about 5 minutes. Verify that this is complete by running the following command on each client.# grep -ir connected mount-path/.meta/graphs/active/volname-client-*/privateThe number of timesconnected=1appears in the output is the number of bricks connected to the client.Verify that bricks added successfully
# gluster volume info VOLNAME # gluster volume status VOLNAMERe-enable self-healing
Run the following commands to re-enable self-healing on the servers.# gluster volume set VOLNAME cluster.data-self-heal on # gluster volume set VOLNAME cluster.metadata-self-heal on # gluster volume set VOLNAME cluster.entry-self-heal on # gluster volume set VOLNAME self-heal-daemon onVerify all entries are healed
# gluster volume heal VOLNAME infoWait until pending heal entries is0to ensure that all heals completed successfully.
5.8.6. Converting an arbitrated volume to a three-way replicated volume
Warning
Procedure 5.3. Converting an arbitrated volume to a replica 3 volume
Verify that healing is not in progress
# gluster volume heal VOLNAME infoWait until pending heal entries is0before proceeding.Remove arbiter bricks from the volume
Check which bricks are listed as(arbiter), and then remove those bricks from the volume.# gluster volume info VOLNAME# gluster volume remove-brick VOLNAME replica 2 HOST:arbiter-brick-path forceDisable and stop self-healing
Run the following commands to disable data, metadata, and entry self-heal, and the self-heal daemon.# gluster volume set VOLNAME cluster.data-self-heal off # gluster volume set VOLNAME cluster.metadata-self-heal off # gluster volume set VOLNAME cluster.entry-self-heal off # gluster volume set VOLNAME self-heal-daemon offAdd full bricks to the volume
Convert the volume by adding a brick for each replicated sub-volume.# gluster volume add-brick VOLNAME replica 3 HOST:brick-pathFor example, if you have an existing arbitrated replicated volume:# gluster volume add-brick testvol replica 3 server:/bricks/brickIf you have an existing arbitrated distributed-replicated volume:# gluster volume add-brick testvol replica 3 server1:/bricks/brick1 server2:/bricks/brick2Wait for client volfiles to update
This takes about 5 minutes.Verify that bricks added successfully
# gluster volume info VOLNAME # gluster volume status VOLNAMERe-enable self-healing
Run the following commands to re-enable self-healing on the servers.# gluster volume set VOLNAME cluster.data-self-heal on # gluster volume set VOLNAME cluster.metadata-self-heal on # gluster volume set VOLNAME cluster.entry-self-heal on # gluster volume set VOLNAME self-heal-daemon onVerify all entries are healed
# gluster volume heal VOLNAME infoWait until pending heal entries is0to ensure that all heals completed successfully.
5.8.7. Tuning recommendations for arbitrated volumes
- For dedicated arbiter nodes, use JBOD for arbiter bricks, and RAID6 for data bricks.
- For chained arbiter volumes, use the same RAID6 drive for both data and arbiter bricks.