2.3. クラスター
2.3.1. クラスターの概要
クラスターは、同じストレージドメインを共有し、同じタイプの CPU (Intel または AMD) を持つホストの論理グループです。ホストに異なる CPU モデルの生成がある場合は、すべてのモデルに存在する機能のみを使用します。
システム内の各クラスターはデータセンターに属し、システム内の各ホストはクラスターに属している必要があります。仮想マシンはクラスター内の任意のホストに動的に割り当てられ、仮想マシン上のクラスターおよび設定に合わせて、それらのホスト間で移行することができます。クラスターは、電源および負荷分散ポリシーを定義できる最上位です。
クラスターに属するホストおよび仮想マシンの数は、Host Count および VM Count の結果一覧にそれぞれ表示されます。
クラスターは仮想マシンまたは Red Hat Gluster Storage サーバーを実行します。これら 2 つの目的は相互排他的です。単一クラスターでは仮想化とストレージホストをまとめてサポートできません。
Red Hat Virtualization は、インストール時にデフォルトのデータセンターにデフォルトのクラスターを作成します。
図2.2 クラスター
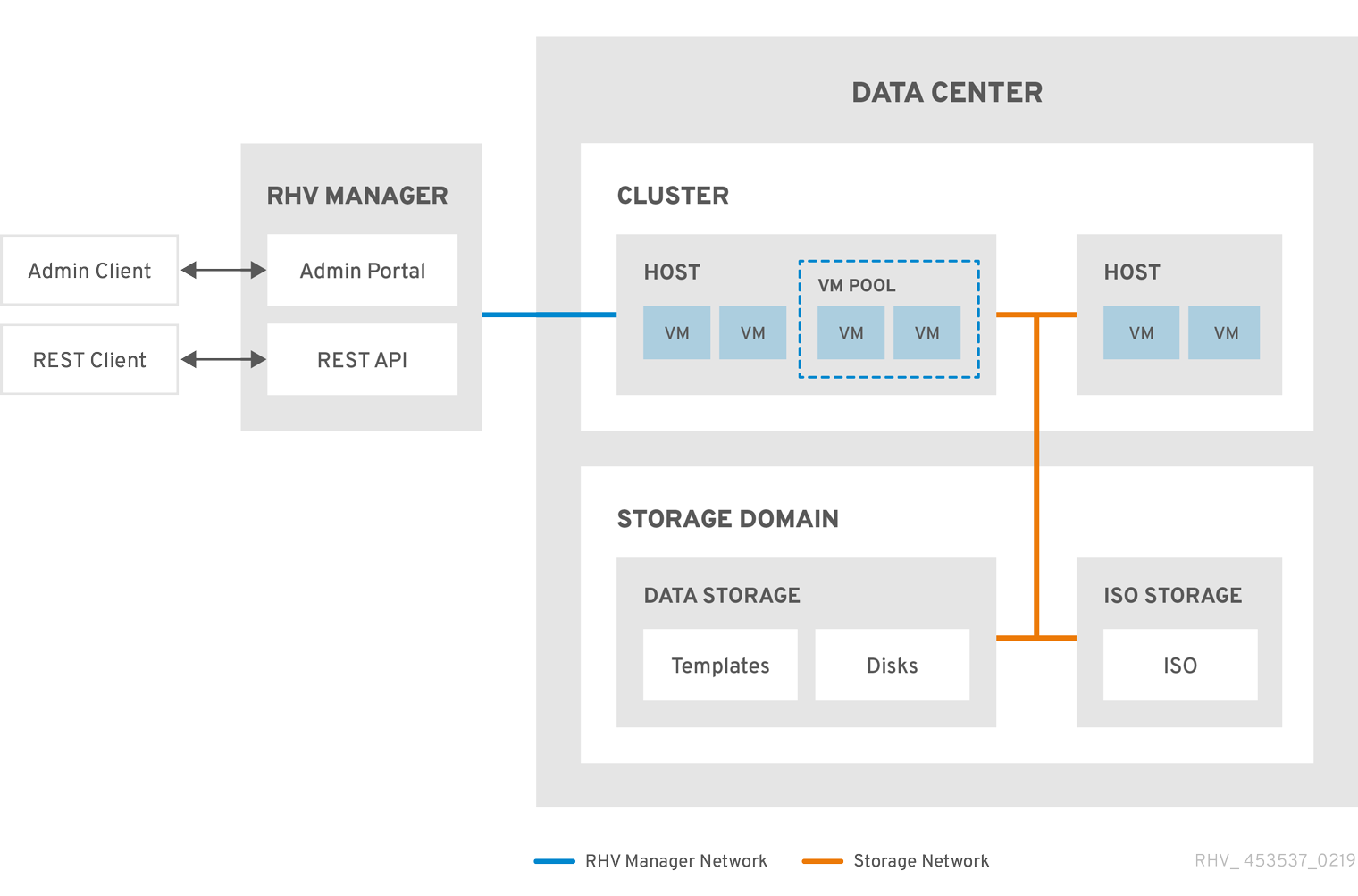
2.3.2. クラスタータスク
一部のクラスターオプションは Gluster クラスターには適用されません。Red Hat Virtualization で Red Hat Gluster Storage を使用する方法の詳細は、Red Hat Gluster Storage を使用した Red Hat Virtualization の設定 を参照してください。
2.3.2.1. 新規クラスターの作成
データセンターには複数のクラスターを含めることができ、クラスターには複数のホストを含めることができます。クラスター内のすべてのホストに同じ CPU アーキテクチャーがなければなりません。CPU タイプを最適化するには、クラスターを作成する前にホストを作成します。クラスターを作成したら、Guide Me ボタンを使用してホストを設定できます。
手順
-
をクリックします。 - New をクリックします。
- ドロップダウンリストからクラスターが所属するData Center を選択します。
- クラスターの Name および Description を入力します。
- Management Network のドロップダウンリストからネットワークを選択して、管理ネットワークロールを割り当てます。
- CPU Architecture を選択します。
CPU Type には、このクラスターの一部であるホスト間で、最も古い CPU プロセッサーファミリー を選択します。CPU タイプは、最も古いものから最新の順に一覧表示されます。
重要CPU プロセッサーファミリーが CPU Type で指定したホストよりも古いホストは、このクラスターの一部にすることはできません。詳細は、RHEV3 または RHV4 クラスターをどの CPU ファミリーに設定する必要があるか を参照してください。
- ドロップダウンリストからクラスターの FIPS Mode を選択します。
- ドロップダウンリストから、クラスターの Compatibility Version を選択します。
- ドロップダウンリストから Switch Type を選択します。
クラスター内のホストの Firewall Type (Firewalld (デフォルト) または iptables) を選択します。
注記iptables がサポートされるのは、互換バージョン 4.2 または 4.3 のクラスターの Red Hat Enterprise Linux 7 ホストのみです。Red Hat Enterprise Linux 8 ホストは、ファイアウォールタイプが firewalld のクラスターにのみ追加できます。
- Enable Virt Service または Enable Gluster Service チェックボックスを選択して、クラスターが仮想マシンホストまたは Gluster 対応ノードと共に設定されるかどうかを定義します。
- Enable to set VM maintenance reason チェックボックスを選択すると、仮想マシンを Manager からシャットダウンする際に任意の reason フィールドが有効になり、管理者はメンテナンスの説明を提供できます。
- Enable to set Host maintenance reason チェックボックスを選択すると、ホストを Manager からメンテナンスモードにする時に任意の reason フィールドが有効になり、管理者はメンテナンスの説明を提供できます。
- オプションで /dev/hwrng source (外部ハードウェアデバイス) のチェックボックスを選択し、クラスター内のすべてのホストが使用する乱数ジェネレーターデバイスを指定します。/dev/urandom source (Linux が提供するデバイス) はデフォルトで有効になっています。
- Optimization タブをクリックしてクラスターのメモリーページ共有しきい値を選択し、必要に応じてクラスター内のホストで CPU スレッド処理とメモリーバルーンを有効にします。
- Migration Policy タブをクリックして、クラスターの仮想マシン移行ポリシーを定義します。
- Scheduling Policy (スケジューリングポリシー) タブをクリックして、スケジューリングポリシーの設定、スケジューラー最適化の設定、クラスター内のホストの信頼できるサービスの有効化、HA Reservation の有効化、シリアル番号ポリシーを選択します。
- Console タブをクリックしてオプションでグローバル SPICE プロキシー (ある場合) を上書きし、クラスターに含まれるホストの SPICE プロキシーのアドレスを指定します。
- Fencing policy タブをクリックして、クラスターでフェンシングを有効または無効にします。また、フェンシングオプションを選択します。
- MAC Address Poolタブをクリックして、クラスターのデフォルトプール以外の MAC アドレスプールを指定します。MAC アドレスプールの作成、編集、削除に関するその他のオプションについては、MAC アドレスプール を参照してください。
- をクリックしてクラスターを作成し、Cluster - Guide Me ウインドウを開きます。
-
Guide Me ウィンドウには、クラスターに設定する必要のあるエンティティーが一覧表示されます。これらのエンティティーを設定するか、Configure Later ボタンをクリックして設定を延期します。設定を再開するには、クラスターを選択し、More Actions (
 ) をクリックしてから、Guide Me をクリックします。
) をクリックしてから、Guide Me をクリックします。
2.3.2.2. 一般的なクラスター設定に関する説明
以下の表は、New Cluster および Edit Cluster ウィンドウの General タブの設定を説明しています。 をクリックすると、無効なエントリーはオレンジ色で囲まれ、変更は承認されません。さらに、フィールドプロンプトには、予想される値または値の範囲が示されます。
| フィールド | 説明/アクション |
|---|---|
| Data Center | クラスターが含まれるデータセンター。クラスターを追加する前にデータセンターを作成する必要があります。 |
| Name | クラスターの名前。このテキストフィールドには 40 文字の制限があり、大文字、小文字、数字、ハイフン、およびアンダースコアの組み合わせが含まれる一意の名前である必要があります。 |
| Description / Comment | クラスターまたは追加のメモの説明。これらのフィールドは推奨されますが、必須ではありません。 |
| Management Network | 管理ネットワークロールを割り当てる論理ネットワーク。デフォルトは ovirtmgmt です。移行ネットワークが移行元または移行先ホストに正しくアタッチされていない場合、このネットワークが仮想マシンの移行にも使用されます。 既存のクラスターでは、詳細ビューの Logical Networks タブにある Manage Networks ボタンを使用すると、管理ネットワークを変更できます。 |
| CPU Architecture | クラスターの CPU アーキテクチャー。クラスター内のすべてのホストは、指定したアーキテクチャーを実行する必要があります。選択した CPU アーキテクチャーに応じて、さまざまな CPU タイプを利用できます。
|
| CPU Type | クラスター内の最も古い CPU ファミリー。CPU タイプの一覧は、プランニングおよび前提条件に関するガイド の CPU の要件 を参照してください。作成したクラスターは、重大な中断が発生しない限り変更できません。CPU タイプをクラスター内の最も古い CPU モデルに設定します。すべてのモデルに存在する機能のみ使用できます。Intel タイプおよび AMD CPU タイプの両方の場合、リストされた CPU モデルは、最も古いものから最新の順に論理的に使用されます。 |
| Chipset/Firmware Type | この設定は、クラスターの CPU Architecture が x86_64 に設定されている場合にのみ使用できます。この設定では、チップセットとファームウェアのタイプを指定します。オプションは以下のとおりです。
詳細は、管理ガイドの UEFI および Q35 チップセット を参照してください。 |
| Change Existing VMs/Templates from 1440fx to Q35 Chipset with Bios | クラスターのチップセットが I440FX から Q35 に変更された場合、既存のワークロードを変更するには、このチェックボックスを選択します。 |
| FIPS Mode | クラスターが使用する FIPS モード。クラスター内のすべてのホストは、指定する FIPS モードを実行する必要があります。実行しないと、稼働しなくなります。
|
| Compatibility Version | Red Hat Virtualization のバージョン。データセンターに指定したバージョンよりも前のバージョンは選択できません。 |
| Switch Type | クラスターが使用するスイッチのタイプ。Linux Bridge は、標準の Red Hat Virtualization スイッチです。OVS は、Open vSwitch のネットワーク機能をサポートします。 |
| Firewall Type | クラスター内のホストのファイアウォールタイプ (firewalld (デフォルト) または iptables のいずれか) を指定します。iptables がサポートされるのは、互換バージョン 4.2 または 4.3 のクラスターの Red Hat Enterprise Linux 7 ホストのみです。Red Hat Enterprise Linux 8 ホストは、ファイアウォールタイプ firewalld のクラスターにのみ追加できます。既存のクラスターのファイアウォールタイプを変更する場合は、クラスターで すべてのホストを再インストール し、変更を適用する必要があります。 |
| Default Network Provider | クラスターが使用するデフォルトの外部ネットワークプロバイダーを指定します。Open Virtual Network (OVN) を選択する場合、クラスターに追加されたホストは OVN プロバイダーと通信するように自動的に設定されます。 デフォルトのネットワークプロバイダーを変更する場合は、クラスターのすべてのホストを再インストール し、変更を適用する必要があります。 |
| Maximum Log Memory Threshold |
最大メモリー消費のロギングしきい値を、パーセンテージまたは絶対値 (MB 単位) で指定します。ホストのメモリー使用量がパーセンテージ値を超えている場合や、ホストで利用可能なメモリーが絶対値 (MB 単位) を下回る場合にログに記録されます。デフォルトは |
| Enable Virt Service | このチェックボックスを選択すると、このクラスター内のホストは仮想マシンの実行に使用されます。 |
| Enable Gluster Service | このチェックボックスを選択すると、このクラスターのホストは Red Hat Gluster Storage Server ノードとして使用され、仮想マシンの実行には使用されません。 |
| Import existing gluster configuration | このチェックボックスは、Enable Gluster Service ラジオボタンが選択されている場合にのみ利用できます。このオプションを使用すると、既存の Gluster 対応クラスターおよびその割り当てられたすべてのホストを Red Hat Virtualization Manager にインポートできます。 以下のオプションは、インポートされているクラスター内のホストごとに必要です。
|
| Additional Random Number Generator source | このチェックボックスを選択すると、クラスター内のすべてのホストで追加の乱数ジェネレーターデバイスを使用できます。これにより、乱数ジェネレーターデバイスから仮想マシンへのエントロピーのパススルーが可能になります。 |
| Gluster Tuned Profile | このチェックボックスは、Enable Gluster Service チェックボックスが選択されている場合にのみ利用できます。このオプションは、virtual-host チューニングプロファイルを指定してダーティーメモリーページのさらに積極的なライトバックを有効にし、ホストのパフォーマンスを向上させます。 |
2.3.2.3. 最適化設定の説明
メモリーに関する考慮事項
メモリーページの共有により、仮想マシンは、他の仮想マシンで未使用のメモリーを利用することで、割り当てられたメモリーの最大 200% を使用できます。このプロセスは、Red Hat Virtualization 環境内のすべての仮想マシンが同時に全容量を使用して実行されるわけではなく、未使用のメモリーが一時的に特定の仮想マシンに割り当てられることを前提としています。
CPU の考慮事項
CPU 負荷が高くないワークロードの場合、ホスト内のコア数よりも大きいプロセッサーコアの合計数で仮想マシンを実行できます (単一仮想マシンのプロセッサーコア数は、ホストのコア数を超えることができません)。以下の利点があります。
- より多くの仮想マシンを実行することができます。これにより、ハードウェアの要件が減少します。
- 仮想コア数がホストコア数とホストスレッド数の間にある場合など、それ以外の場合は不可能な CPU トポロジーで仮想マシンを設定できます。
- 最適なパフォーマンス、特に CPU 集約型のワークロードの場合、ホストと同じトポロジーを仮想マシンで使用し、ホストと仮想マシンが同じキャッシュの使用を想定するようにします。ホストのハイパースレッディングが有効な場合、QEMU がホストのハイパースレッドをコアとして扱うため、仮想マシンは複数のスレッドを持つ単一のコアで実行されていることを認識しません。ホストコアのハイパースレッドに実際に対応する仮想コアは、仮想マシンのパフォーマンスに影響する可能性があります。これは、同じホストコアのハイパースレッドと単一のキャッシュを共有する可能性がありますが、仮想マシンは別のコアとして扱います。
以下の表は、New Cluster および Edit Cluster ウィンドウの Optimization タブの設定を説明しています。
| フィールド | 説明/アクション |
|---|---|
| Memory Optimization |
|
| CPU Threads | Count Threads As Cores チェックボックスをオンにすると、ホスト内のコア数よりも大きいプロセッサーコアの合計数で仮想マシンを実行できます (単一仮想マシンのプロセッサーコア数は、ホストのコア数を超えることができません)。 このチェックボックスを選択すると、公開されるホストスレッドは仮想マシンが使用できるコアとして扱われます。たとえば、コアごとに 2 つのスレッドがある 24 コアのシステム (全部で 48 スレッド) では、最大 48 コアを持つ仮想マシンを実行できます。そして、ホストの CPU 負荷を計算するアルゴリズムでは、潜在的に使用されるコアの 2 倍に対して負荷を比較します。 |
| Memory Balloon | Enable Memory Balloon Optimization のチェックボックスを選択し、このクラスターのホストで実行している仮想マシンでメモリーのオーバーコミットを有効にします。このチェックボックスを選択すると、Memory Overcommit Manager (MoM) は、可能な限りバルーニングを開始し、すべての仮想マシンの保証メモリーサイズを制限します。
バルーンを実行するには、仮想マシンに適切なドライバーを持つバルーンデバイスが必要です。各仮想マシンには、特に削除しない限り、バルーンデバイスが含まれます。このクラスター内の各ホストは、ステータスが 状況によっては、バルーニングが KSM と競合する可能性がある点を理解することが重要です。このような場合、MoM は競合の可能性を最小限に抑えるためにバルーンサイズの調整を試みます。また、バルーニングによって仮想マシンのパフォーマンスが最適化されない場合もあります。ルーニングの最適化に関して、管理者は慎重に使用することが推奨されます。 |
| KSM control | Enable KSM チェックボックスを選択すると、MoM は必要に応じて、CPU コストを上回るメモリー節約効果が得られる場合に、Kernel Same-page Merging (KSM) を実行できます。 |
2.3.2.4. 移行ポリシー設定の説明
移行ポリシーは、ホストに障害が発生した場合に仮想マシンをライブマイグレーションするための条件を定義します。これらの条件には、移行中の仮想マシンのダウンタイム、ネットワーク帯域幅、および仮想マシンの優先順位が含まれます。
| ポリシー | 説明 |
|---|---|
| Cluster default (Minimal downtime) |
|
| Minimal downtime | 仮想マシンを一般的な状況で移行できるようにするポリシー。仮想マシンで重大なダウンタイムは発生しません。移行は、長時間 (QEMU の反復により最大 500 ミリ秒) 経過しても仮想マシンの移行が収束されない場合に中止されます。ゲストエージェントフックメカニズムは有効化されています。 |
| Post-copy migration | post-copy migration を使用すると、移行元のホスト上にある移行対象の仮想マシンの vCPU が一時停止され、最小限のメモリーページのみ転送されます。次に、移行先ホストにある仮想マシンの vCPU がアクティブ化され、移行先で仮想マシンが動作している間に残りのメモリーページが転送されます。 post-copy ポリシーでは、まず pre-copy を実行して収束するか検証します。長時間経過しても仮想マシンの移行が収束しない場合、post-copy に切り替わります。 これにより、移行先の仮想マシンのダウンタイムが大幅に短縮されるとともに、移行元の仮想マシンのメモリーページがどれだけ急激に変化しても、確実に移行が完了されます。標準的な pre-copy の移行では対応できない、連続使用率の高い仮想マシンの移行に最適です。 このポリシーの欠点として、post-copy フェーズではメモリーの不足部分がホスト間で転送されるため、仮想マシンが大幅に遅くなる可能性があります。 警告 post-copy プロセスの完了前にネットワーク接続が切断されると、Manager は一時停止し、実行中の仮想マシンを強制終了します。仮想マシンの可用性が重要である場合や、移行ネットワークが不安定な場合は、post-copy migration を使用しないでください。 |
| Suspend workload if needed | 負荷の高いワークロードを実行している仮想マシンを含め、ほとんどの状況で仮想マシンを移行できるポリシー。結果として、他の設定よりも重大なダウンタイムが仮想マシンで発生する場合があります。ワークロードが極端な場合、移行が中止される可能性があります。ゲストエージェントフックメカニズムは有効化されています。 |
帯域幅設定は、ホストごとの送信移行と受信移行の両方の最大帯域幅を定義します。
| ポリシー | 説明 |
|---|---|
| Auto | 帯域幅は、データセンターの Host Network QoS の Rate Limit [Mbps] 設定からコピーされます。レート制限が定義されていない場合は、ネットワークインターフェイスの送受信における最小リンク速度として計算されます。レート制限が設定されていない場合や、リンク速度が利用できない場合には、ホスト送信時にローカルの VDSM 設定により決定されます。 |
| Hypervisor default | 帯域幅は、ホスト送信時にローカルの VDSM 設定によって制御されます。 |
| Custom | ユーザーにより定義されます (Mbps 単位)。この値は、同時移行の数 (デフォルトは ingoing と outgoing の移行を考慮して 2) で分割されます。したがって、ユーザー定義の帯域幅は、すべての同時移行に対応できる十分な大きさである必要があります。
たとえば、 |
耐障害性ポリシーは、移行での仮想マシンの優先順位を定義します。
| フィールド | 説明/アクション |
|---|---|
| Migrate Virtual Machines | 定義された優先順位で、すべての仮想マシンを移行します。 |
| Migrate only Highly Available Virtual Machines | 他のホストのオーバーロードを防ぐために、高可用性の仮想マシンのみを移行します。 |
| Do Not Migrate Virtual Machines | 仮想マシンを移行しないようにします。 |
| フィールド | 説明/アクション |
|---|---|
| Enable Migration Encryption | 移行中に仮想マシンを暗号化できるようにします。
|
| Parallel Migrations | 使用する並列移行接続の有無と数を指定できます。
|
| Number of VM Migration Connections | この設定は、Custom が選択されている場合にのみ利用できます。カスタム並列移行の推奨数は 2 から 255 です。 |
2.3.2.5. スケジューリングポリシー設定に関する説明
スケジューリングポリシーにより、利用可能なホスト間での仮想マシンの使用状況および分散を指定することができます。スケジューリングポリシーを定義して、クラスター内のホスト全体で自動負荷分散を有効にします。スケジューリングポリシーに関わらず、CPU が過負荷状態のホストでは仮想マシンが起動しません。デフォルトでは、ホストの CPU が 5 分間 80% 以上の負荷がかかった場合に過負荷と判断されますが、この値はスケジューリングポリシーを使って変更できます。詳細は、管理ガイド の スケジューリングポリシー を参照してください。
| フィールド | 説明/アクション |
|---|---|
| Select Policy | ドロップダウンリストからポリシーを選択します。
|
| Properties | 以下のプロパティーは、選択したポリシーに応じて表示されます。必要に応じてこれを編集します。
|
| Scheduler Optimization | ホストの重み付け/順序のスケジューリングを最適化します。
|
| Enable Trusted Service |
OpenAttestation サーバーとのインテグレーションを有効にします。これを有効にする前に、 |
| Enable HA Reservation | Manager が高可用性仮想マシンのクラスター容量を監視できるようにします。Manager は、既存のホストに予期せぬ障害が発生した場合に移行するため、高可用性として指定された仮想マシンのクラスター内に適切な容量が存在することを確認します。 |
| Serial Number Policy | クラスター内の各新規仮想マシンにシリアル番号を割り当てるポリシーを設定します。
|
| Custom Serial Number | クラスター内の新しい仮想マシンに適用するカスタムのシリアル番号を指定します。 |
ホストの空きメモリーが 20% 未満になると、mom.Controllers.Balloon - INFO Ballooning guest:half1 from 1096400 to 1991580 が /var/log/vdsm/mom.log に記録されます。/var/log/vdsm/mom.log は、Memory Overcommit Manager のログファイルです。
2.3.2.6. MaxFreeMemoryForOverUtilized および MinFreeMemoryForUnderUtilized クラスタースケジューリングポリシーのプロパティー
スケジューラーには、現在のクラスタースケジューリングポリシーおよびそのパラメーターに従って仮想マシンを移行するバックグラウンドプロセスがあります。スケジューラーは、さまざまな基準と相対的な重みに基づいて、継続的にホストを 移行元ホスト または 移行先ホスト に分類し、個々の仮想マシンを移行元ホストから移行先ホストに移行します。
以下は、evenly_distributed および power_saving クラスタースケジューリングポリシーと、MaxFreeMemoryForOverUtilized および MinFreeMemoryForUnderUtilized プロパティーとの相互作用を説明しています。どちらのポリシーも CPU とメモリーの負荷を考慮しますが、CPU 負荷は MaxFreeMemoryForOverUtilized プロパティーおよび MinFreeMemoryForUnderUtilized プロパティーには関係ありません。
MaxFreeMemoryForOverUtilized プロパティーおよび MinFreeMemoryForUnderUtilized プロパティーを evenly_distributed ポリシーの一部として定義する場合:
- 空きメモリーが MaxFreeMemoryForOverUtilized より少ないホストが過剰使用とみなされ、移行元ホストになります。
- 空きメモリーが MinFreeMemoryForUnderUtilized よりも大きいホストが、十分に使用されていないとみなされ、移行先ホストになります。
- MaxFreeMemoryForOverUtilized が定義されていない場合、スケジューラーはメモリー負荷に基づいて仮想マシンを移行しません。(CPU 負荷など、ポリシーの他の基準に基づく仮想マシンの移行は継続されます。)
- MinFreeMemoryForUnderUtilized が定義されていない場合、スケジューラーはすべてのホストを移行先ホストとして適格であるとみなします。
power_saving ポリシーの一部として MaxFreeMemoryForOverUtilized および MinFreeMemoryForUnderUtilized プロパティーを定義する場合:
- 空きメモリーが MaxFreeMemoryForOverUtilized より少ないホストが過剰使用とみなされ、移行元ホストになります。
- 空きメモリーが MinFreeMemoryForUnderUtilized よりも大きいホストが過小使用とみなされ、移行元ホストになります。
- 空きメモリーが MaxFreeMemoryForOverUtilized よりも大きいホストが過剰使用ではないとみなされ、移行先ホストになります。
- 空きメモリーが MinFreeMemoryForUnderUtilized より少ないホストが過小使用ではないとみなされ、移行先ホストになります。
- スケジューラーは仮想マシンを移行する際に、過剰使用でも過小使用でもないホストへの移行を優先します。該当するホストが不足する場合、スケジューラーは仮想マシンを使用率の低いホストに移行できます。この目的で使用率の低いホストが必要ない場合は、スケジューラーはそのホストの電源を切ることができます。
- MaxFreeMemoryForOverUtilized が定義されていない場合は、ホストは過剰使用とみなされません。そのため、使用率の低いホストのみが移行元ホストとなり、クラスター内のすべてのホストが移行先ホストとみなされます。
- MinFreeMemoryForUnderUtilized が定義されていない場合は、使用率の低いホストのみが移行元ホストとなり、過剰使用されていないホストが移行先ホストになります。
ホストによるすべての物理 CPU の過剰使用を防ぐには、仮想 CPU と物理 CPU の比率 (VCpuToPhysicalCpuRatio) を 0.1 - 2.9 の値で定義します。このパラメーターを設定すると、仮想マシンをスケジュールするときに CPU 使用率が低いホストが優先されます。
仮想マシンを追加すると比率が制限を超える場合、VCpuToPhysicalCpuRatio と CPU 使用率の両方が考慮されます。
実行環境では、ホスト VCpuToPhysicalCpuRatio が 2.5 を超えると、一部の仮想マシンが負荷分散され、VCpuToPhysicalCpuRatio が低いホストに移動される可能性があります。
関連情報
2.3.2.7. クラスターコンソール設定の説明
以下の表は、New Cluster および Edit Cluster ウィンドウの Console タブの設定を説明しています。
| フィールド | 説明/アクション |
|---|---|
| Define SPICE Proxy for Cluster | このチェックボックスを選択すると、グローバル設定で定義された SPICE プロキシーのオーバーライドが有効になります。この機能は、ハイパーバイザーが存在するネットワークの外部にユーザー (たとえば、仮想マシンポータル経由で接続するユーザー) がいる場合に役に立ちます。 |
| Overridden SPICE proxy address | SPICE クライアントが仮想マシンに接続するプロキシー。アドレスは以下の形式でなければなりません。 |
2.3.2.8. フェンシングポリシー設定の説明
以下の表は、New Cluster および Edit Cluster ウィンドウの Fencing Policy タブの設定を説明しています。
| フィールド | 説明/アクション |
|---|---|
| Enable fencing | クラスターのフェンシングを有効にします。フェンシングはデフォルトで有効になっていますが、必要に応じて無効にできます。たとえば、一時的なネットワークの問題が発生したり、予想される場合に、管理者は診断またはメンテナンスアクティビティーが完了するまでフェンシングを無効にできます。フェンシングが無効になっている場合、応答しないホストで実行している高可用性仮想マシンは、別の場所で再起動されないことに注意してください。 |
| Skip fencing if host has live lease on storage | このチェックボックスが選択されている場合、クラスター内でレスポンスがなく、引き続きストレージに接続されているホストはフェンスされません。 |
| Skip fencing on cluster connectivity issues | このチェックボックスを選択すると、接続の問題が発生するクラスター内のホストのパーセンテージが、定義された Threshold 以上になると、フェンシングが一時的に無効になります。Threshold 値はドロップダウンリストから選択されます。利用可能な値は 25、50、75、および 100 です。 |
| Skip fencing if gluster bricks are up | このオプションは、Red Hat Gluster Storage 機能が有効にされている場合にのみ利用できます。このチェックボックスを選択すると、ブリックが実行中で、他のピアから到達できる場合にフェンシングはスキップされます。 2 章を参照してください。フェンシングポリシー を使用して高可用性を設定します。詳細は、Red Hat ハイパーコンバージドインフラストラクチャーのメンテナンス の 付録 A. Red Hat Gluster Storage のフェンシングポリシー を参照してください。 |
| Skip fencing if gluster quorum not met | このオプションは、Red Hat Gluster Storage 機能が有効にされている場合にのみ利用できます。このチェックボックスが選択されている場合、ブリックが実行されているとフェンシングがスキップされ、ホストをシャットダウンするとクォーラムが失われます。 2 章を参照してください。フェンシングポリシー を使用して高可用性を設定します。詳細は、Red Hat ハイパーコンバージドインフラストラクチャーのメンテナンス の 付録 A. Red Hat Gluster Storage のフェンシングポリシー を参照してください。 |
2.3.2.9. クラスター内のホストの負荷および電源管理ポリシーの設定
evenly_distributed および power_saving スケジューリングポリシーを使用すると、許容可能なメモリーおよび CPU 使用率の値と、仮想マシンとホスト間の移行が必要なポイントを指定することができます。vm_evenly_distributed スケジューリングポリシーは、仮想マシンの数に基づいて、ホスト間で仮想マシンを均等に配布します。スケジューリングポリシーを定義して、クラスター内のホスト全体で自動負荷分散を有効にします。各スケジューリングポリシーの詳細は、クラスタースケジューリングポリシーの設定 を参照してください。
手順
-
をクリックし、クラスターを選択します。 - Edit をクリックします。
- Scheduling Policy タブをクリックします。
以下のポリシーのいずれかを選択します。
- none
vm_evenly_distributed
- HighVmCount フィールドで、少なくとも 1 台のホストで実行されている必要がある仮想マシンの最小数を設定して、負荷分散を有効にします。
- MigrationThreshold フィールドで、最も使用率の高いホスト上の仮想マシン数と、最も使用率の低いホスト上の仮想マシン数の、許容可能な最大差を定義します。
- SpmVmGrace フィールドで、SPM ホストで予約される仮想マシンのスロット数を定義します。
- 必要に応じて HeSparesCount フィールドで、移行またはシャットダウンした場合に Manager 用仮想マシンを起動できる十分な空きメモリーを確保する、追加のセルフホスト型エンジンノードの数を入力します。詳細は、セルフホスト型エンジン用に予約されているメモリースロットの設定 を参照してください。
evenly_distributed
- CpuOverCommitDurationMinutes フィールドで、スケジューリングポリシーによりアクションが実行される前に、定義された使用率値の範囲外となる CPU 負荷をホストで実行できる時間 (分単位) を設定します。
- HighUtilization フィールドに、仮想マシンが他のホストへの移行を開始する CPU 使用率をパーセンテージで入力します。
- 必要に応じて HeSparesCount フィールドで、移行またはシャットダウンした場合に Manager 用仮想マシンを起動できる十分な空きメモリーを確保する、追加のセルフホスト型エンジンノードの数を入力します。詳細は、セルフホスト型エンジン用に予約されているメモリースロットの設定 を参照してください。
ホストによるすべての物理 CPU の過剰使用を防ぐには、仮想 CPU と物理 CPU の比率 (VCpuToPhysicalCpuRatio) を 0.1 - 2.9 の値で定義します (オプション)。このパラメーターを設定すると、仮想マシンをスケジュールするときに CPU 使用率が低いホストが優先されます。
仮想マシンを追加すると比率が制限を超える場合、VCpuToPhysicalCpuRatio と CPU 使用率の両方が考慮されます。
実行環境では、ホスト VCpuToPhysicalCpuRatio が 2.5 を超えると、一部の仮想マシンが負荷分散され、VCpuToPhysicalCpuRatio が低いホストに移動される可能性があります。
power_saving
- CpuOverCommitDurationMinutes フィールドで、スケジューリングポリシーによりアクションが実行される前に、定義された使用率値の範囲外となる CPU 負荷をホストで実行できる時間 (分単位) を設定します。
- LowUtilization フィールドに、その値を下回った場合に使用率が低すぎるとホストが判断する CPU 使用率を入力します。
- HighUtilization フィールドに、仮想マシンが他のホストへの移行を開始する CPU 使用率をパーセンテージで入力します。
- 必要に応じて HeSparesCount フィールドで、移行またはシャットダウンした場合に Manager 用仮想マシンを起動できる十分な空きメモリーを確保する、追加のセルフホスト型エンジンノードの数を入力します。詳細は、セルフホスト型エンジン用に予約されているメモリースロットの設定 を参照してください。
クラスターの Scheduler Optimization として、以下のいずれかを選択します。
- Optimize for Utilization を選択すると、スケジューリングに重みモジュールが追加され、最適な選択が可能になります。
- Optimize for Speed を選択すると、保留中のリクエスト数が 10 を上回る場合にホストの重み付けをスキップします。
-
OpenAttestation サーバーを使用してホストを確認し、
engine-configツールを使用してサーバーの詳細を設定している場合は、Enable Trusted Service チェックボックスを選択します。
OpenAttestation および Intel Trusted Execution Technology (Intel TXT) は利用できなくなりました。
- 必要に応じて、Enable HA Reservation チェックボックスを選択し、Manager が高可用性仮想マシンのクラスター容量を監視できるようにします。
オプションで、クラスター内の仮想マシンの Serial Number Policy を選択します。
-
System Default: エンジン設定ツール、
DefaultSerialNumberPolicy、DefaultCustomSerialNumberキー名を使用して Manager データベースに設定されたシステム全体のデフォルトを使用します。DefaultSerialNumberPolicyのデフォルト値は Host ID を使用します。詳細は、管理ガイド の スケジューリングポリシー を参照してください。 - Host ID: 仮想マシンのシリアル番号を、ホストの UUID に設定します。
- VM ID: 仮想マシンの UUID にそれぞれの仮想マシンのシリアル番号を設定します。
- Custom serial number: 各仮想マシンのシリアル番号を、以下の Custom Serial Number パラメーターで指定した値に設定します。
-
System Default: エンジン設定ツール、
- をクリックします。
2.3.2.10. クラスター内のホストでの MoM ポリシーの更新
Memory Overcommit Manager は、ホストのメモリーバルーンと KSM 機能を処理します。クラスターのこれらの機能への変更は、次回再起動後またはメンテナンスモードでホストが Up のステータスに移行するときにホストに渡されます。ただし、必要な場合は、ホストが Up のときに MoM ポリシーを同期することにより、重要な変更をホストをすぐに適用することができます。以下の手順は、各ホストで個別に実行する必要があります。
手順
-
をクリックします。 - クラスターの名前をクリックします。詳細ビューが開きます。
- Hosts タブをクリックして、更新後の MoM ポリシーが必要なホストを選択します。
- Sync MoM Policy をクリックします。
ホストの MoM ポリシーが更新されます。その際に、ホストをメンテナンスモードに移行してから Up に戻す必要はありません。
2.3.2.11. CPU プロファイルの作成
CPU プロファイルは、クラスター内の仮想マシンが、実行しているホストでアクセスできる最大処理機能を定義します。これは、そのホストで利用可能な合計処理能力に対するパーセントで表現されます。CPU プロファイルは、データセンターで定義された CPU プロファイルに基づいて作成され、クラスター内のすべての仮想マシンには自動的に適用されません。プロファイルを有効にするには、個々の仮想マシンに手動で割り当てる必要があります。
この手順では、クラスターが属するデータセンター配下に 1 つ以上の CPU QoS エントリーがすでに定義されていることを前提としています。
手順
-
をクリックします。 - クラスターの名前をクリックします。詳細ビューが開きます。
- CPU Profiles タブをクリックします。
- New をクリックします。
- CPU プロファイルの Name および Description を入力します。
- QoS 一覧から CPU プロファイルに適用する QoS を選択します。
- をクリックします。
2.3.2.12. CPU プロファイルの削除
Red Hat Virtualization 環境から、既存の CPU プロファイルを削除します。
手順
-
をクリックします。 - クラスターの名前をクリックします。詳細ビューが開きます。
- CPU Profiles タブをクリックし、削除する CPU プロファイルを選択します。
- Remove をクリックします。
- をクリックします。
CPU プロファイルが仮想マシンに割り当てられている場合、それらの仮想マシンには default CPU プロファイルが自動的に割り当てられます。
2.3.2.13. 既存の Red Hat Gluster Storage クラスターのインポート
Red Hat Gluster Storage クラスターおよびクラスターに属するすべてのホストを、Red Hat Virtualization Manager にインポートできます。
クラスター内の任意のホストの IP アドレス、またはホスト名やパスワードなどの詳細を指定すると、SSH を介してそのホストで gluster peer status コマンドが実行され、クラスターの一部であるホストの一覧が表示されます。各ホストのフィンガープリントを手動で検証し、パスワードを提供する必要があります。クラスター内のいずれかのホストが停止している、または到達できない場合、クラスターをインポートすることはできません。新規インポートされたホストに VDSM がインストールされていないため、ブートストラップスクリプトは、インポート後にホストに必要な VDSM パッケージをすべてインストールして再起動します。
手順
-
をクリックします。 - New をクリックします。
- クラスターが属する Data Center を選択します。
- クラスターの Name および Description を入力します。
Enable Gluster Service チェックボックスを選択し、Import existing gluster configuration チェックボックスを選択します。
Import existing gluster configuration フィールドは、Enable Gluster Service が選択されている場合にのみ表示されます。
Hostname フィールドには、クラスター内のサーバーのホスト名または IP アドレスを入力します。
ホストの SSH Fingerprint が表示され、正しいホストに接続していることを確認します。ホストが到達不能な場合や、ネットワークエラーが発生した場合には、Error in fetching fingerprint のエラーが Fingerprint フィールドに表示されます。
- サーバーの Password を入力し、 をクリックします。
- Add Hosts 画面が開き、クラスターに含まれるホストの一覧が表示されます。
- 各ホストに Name と Root Password を入力します。
すべてのホストに同じパスワードを使用する場合は、Use a Common Password チェックボックスを選択して、指定したテキストフィールドにパスワードを入力します。
Apply をクリックして、すべてのホストに入力したパスワードを設定します。
フィンガープリントが有効であることを確認し、OK をクリックして変更を送信します。
ブートストラップスクリプトは、インポート後にホストに必要な VDSM パッケージをすべてインストールして再起動します。これで、Red Hat Virtualization Manager に既存の Red Hat Gluster Storage クラスターが正常にインポートされました。
2.3.2.14. Add Hosts ウィンドウの設定の説明
Add Hosts ウィンドウで、Gluster 対応クラスターの一部としてインポートされたホストの詳細を指定できます。このウィンドウは、New Cluster ウィンドウで Enable Gluster Service チェックボックスを選択し、必要なホストの詳細を指定すると表示されます。
| フィールド | 説明 |
|---|---|
| Use a common password | このチェックボックスをオンにすると、クラスターに属するすべてのホストに同じパスワードを使用します。Password フィールドにパスワードを入力し、Apply ボタンをクリックして全ホストにパスワードを設定します。 |
| Name | ホストの名前を入力します。 |
| Hostname/IP | このフィールドには、New Cluster ウィンドウで指定したホストの完全修飾ドメイン名または IP が自動的に設定されます。 |
| Root Password | 各ホストに異なる root パスワードを使用するには、このフィールドにパスワードを入力します。このフィールドは、クラスター内のすべてのホストに提供される共通パスワードをオーバーライドします。 |
| Fingerprint | ホストのフィンガープリントが表示され、正しいホストに接続していることを確認できます。このフィールドには、New Cluster ウィンドウで指定したホストのフィンガープリントが自動的に入力されます。 |
2.3.2.15. クラスターの削除
クラスターを削除する前に、すべてのホストをクラスターから移動します。
Default クラスターは Blank テンプレートを保持するため、削除できません。ただし、Default クラスターの名前を変更し、新しいデータセンターに追加することは可能です。
手順
-
をクリックし、クラスターを選択します。 - クラスターにホストがないことを確認します。
- Remove をクリックします。
- をクリックします。
2.3.2.16. メモリーの最適化
ホストの仮想マシン数を増やすには、メモリーのオーバーコミット を使用できます。その場合、仮想マシンに割り当てるメモリーは RAM を超え、スワップ領域に依存します。
ただし、メモリーのオーバーコミットには潜在的な問題があります。
- スワッピングパフォーマンス - スワップ領域が遅くなり、RAM よりも多くの CPU リソースを消費し、仮想マシンのパフォーマンスに影響を及ぼします。過度なスワッピングは、CPU のスラッシングにつながる可能性があります。
- OOM (Out-of-memory) killer: ホストがスワップ領域を使い果たすと、新規プロセスは開始できなくなり、カーネルの OOM killer デーモンは仮想マシンゲストなどのアクティブなプロセスのシャットダウンを開始します。
これらの欠点に対処するために、以下を実行できます。
- Memory Optimization 設定および Memory Overcommit Manager (MoM) を使用してメモリーのオーバーコミットを制限します。
- 仮想メモリーの潜在的な最大要求に対応できる大きな swap 領域を作成し、安全マージンを残します。
- memory ballooning および Kernel Same-page Merging (KSM) を有効にして、仮想メモリーサイズを縮小します。
2.3.2.17. メモリーの最適化とメモリーオーバーコミット
Memory Optimization 設定 (None (0%)、150%、または 200% のいずれか) を選択して、メモリーのオーバーコミット量を制限できます。
各設定は、RAM に対する割合を表します。たとえば RAM が 64 GB のホストの場合、150% を選択すると、32 GB をオーバーコミットでき、仮想メモリーは合計 96 GB となります。ホストが 4 GB を使用している場合、残りの 92 GB が利用可能になります。そのほとんどを仮想マシンに割り当てることができます (System タブの Memory Size) が、安全マージンとして、その一部を割り当てずに残しておくことを検討してください。
仮想メモリーの要求が急増すると、MoM、メモリーバルーン、および KSM が仮想メモリーを再最適化するまで、パフォーマンスに影響が出る可能性があります。この影響を軽減するには、実行するアプリケーションおよびワークロードの種類に適した制限を選択します。
- 必要なメモリーの増分が大きいワークロードの場合は、200% または 150% などの高いパーセンテージを選択します。
- 必要なメモリーが急激に増加する重大なアプリケーションまたはワークロードの場合は、150% や None (0%) などの低いパーセンテージを選択します。None を選択するとメモリーのオーバーコミットを防ぎつつ、MoM、メモリーバルーンデバイス、および KSM における仮想メモリーの最適化を継続できます。
設定を実稼働環境にデプロイする前に、さまざまな条件下で Memory Optimization の設定を必ずテストしてください。
Memory Optimization を設定するには、New Cluster または Edit Cluster ウィンドウの Optimization タブをクリックします。クラスター最適化設定の説明 を参照してください。
その他のコメント:
- ホスト統計ビュー には、オーバーコミットメント率のサイズを決定するための有用な履歴情報が表示されます。
- KSM とメモリーバルーニングにより得られるメモリー最適化のサイズは継続的に変化するため、実際に利用可能なメモリーをリアルタイムで決定することはできません。
- 仮想マシンが仮想メモリー制限に達すると、新しいアプリを開始できません。
- ホストで実行する仮想マシンの数を計画する際には、最大仮想メモリー (物理メモリーサイズと Memory Optimization 設定) から開始します。メモリーバルーニングや KSM などのメモリー最適化により実現される、より小さい仮想メモリーは考慮しないでください。
2.3.2.18. swap 領域とメモリーオーバーコミットメント
Red Hat は、スワップ領域の設定に関する推奨事項 を提供しています。
これらの推奨事項を適用する場合は、ガイダンスに従い、ワーストケースシナリオにおける "最後のメモリー" としてスワップ領域のサイズを決定してください。物理メモリーのサイズと Memory Optimization 設定を、仮想メモリーサイズの合計を見積もるためのベースとして使用します。MoM、メモリーバルーニング、および KSM による最適化から仮想メモリーサイズの減少を除外してください。
OOM 状態を回避するには、ワーストケースのシナリオを処理するのに十分な swap 領域を確保し、安全マージンを確保してください。実稼働環境にデプロイする前に、さまざまな条件で設定を常にテストしてください。
2.3.2.19. Memory Overcommit Manager(MoM)
Memory Overcommit Manager (MoM) は、以下の 2 つを行います。
- これは、前述のセクションで説明されているように、クラスターのホストに Memory Optimization 設定を適用してメモリーのオーバーコミットを制限します。
- 以下のセクションで説明されているように、メモリーバルーニング と KSM を管理することで、メモリーを最適化します。
MoM を有効または無効にする必要はありません。
ホストの空きメモリーが 20% 未満になると、mom.Controllers.Balloon - INFO Ballooning guest:half1 from 1096400 to 1991580 が Memory Overcommit Manager ログファイル /var/log/vdsm/mom.log に記録されます。
2.3.2.20. メモリーバルーニング
仮想マシンは、割り当てた仮想メモリーの全量で開始されます。仮想メモリー使用量が RAM を超えると、スワップ領域へのホストの依存が大きくなります。メモリーバルーニング を有効にすると、仮想マシンはそのメモリーの未使用部分を解放できます。解放されたメモリーは、ホスト上の他のプロセスおよび仮想マシンで再利用できます。メモリーフットプリントが削減されると、スワッピングの可能性が低くなり、パフォーマンスが向上します。
メモリーバルーンデバイスとドライバーを提供する virtio-balloon パッケージは、ローダーブルカーネルモジュール (LKM) として出荷されます。デフォルトでは、自動的にロードするように設定されています。モジュールを拒否リストに追加するかアンロードすると、バルーニングが無効になります。
メモリーバルーンデバイスは、相互に直接調整しません。MoM (ホストの Memory Overcommit Manager) プロセスに依存して、各仮想マシンのニーズを継続的に監視し、バルーンデバイスに仮想メモリーの増減を指示します。
パフォーマンスに関する考慮事項:
- Red Hat は、高パフォーマンスと低レイテンシーを継続的に必要とするワークロードには、メモリーバルーンおよびオーバーコミットを推奨しません。高パフォーマンスの仮想マシンテンプレートおよびプールの設定 を参照してください。
- パフォーマンスよりも仮想マシンの密度 (経済性) を高めることが重要な場合は、メモリーバルーニングを使用します。
- メモリーバルーニングは CPU 使用率に大きな影響を及ぼしません。(KSM は一部の CPU リソースを消費しますが、負荷がかかっても消費量は変化しません。)
メモリーバルーニングを有効にするには、New Cluster または Edit Cluster ウィンドウの Optimization タブをクリックします。次に、Enable Memory Balloon Optimization チェックボックスを選択します。この設定により、このクラスターのホストで実行されている仮想マシンでメモリーのオーバーコミットが有効になります。このチェックボックスを選択すると、MoM はバルーニングを開始し、可能な場合はすべての仮想マシンのメモリーサイズが保証されます。クラスター最適化設定の説明 を参照してください。
このクラスター内の各ホストは、ステータスが Up に変わったときにバルーンポリシーの更新を受け取ります。必要に応じて、ステータスを変更せずに、ホストのバルーンポリシーを手動で更新できます。クラスター内のホストにおける MoM ポリシーの更新 を参照してください。
2.3.2.21. Kernel Same-page Merging (KSM)
仮想マシンの実行時には、一般的なライブラリーや使用頻度の高いデータといったアイテム向けに、重複したメモリーページが作成されることがあります。さらに、同じようなゲスト OS やアプリケーションを実行している仮想マシンでは、仮想メモリー内のメモリーページが重複してしまいます。
KSM (Kernel Sam-page Merging) を有効にすると、ホスト上の仮想メモリーを調査し、重複するメモリーページを排除して、残りのメモリーページを複数のアプリケーションや仮想マシンで共有できます。これらの共有メモリーページにはコピーオンライトのマークがついており、仮想マシンでページに変更を書き込む必要がある場合には、先にコピーを作成してからそのコピーに変更を書き込みます。
KSM が有効な間は、MoM が KSM を管理します。KSM を手動で設定制御する必要はありません。
KSM は、2 つの方法で仮想メモリーのパフォーマンスを向上させます。共有メモリーのページは使用頻度が高いため、ホストはそのページをキャッシュやメインメモリーに格納する可能性が高くなり、メモリーアクセス速度が向上します。さらに、メモリーオーバーコミットを使用することで、KSM は仮想メモリーのフットプリントを減らし、スワッピング発生の可能性を軽減してパフォーマンスを向上させます。
KSM はメモリーバルーニングよりも多くの CPU リソースを消費します。KSM の CPU 消費量は、負荷をかけても変わりません。同一の仮想マシンやアプリケーションをホスト上で実行すると、KSM は異なる仮想マシンを実行する場合と比較して、メモリーページをマージする機会が多くなります。異なる仮想マシンやアプリケーションを多く実行している場合には、KSM を使用するための CPU コストにより利点が相殺されてしまう可能性があります。
パフォーマンスに関する考慮事項:
- KSM デーモンが大量のメモリーをマージした後に、カーネルメモリーアカウンティング統計が最終的に矛盾することがあります。システムに大量の空きメモリーがある場合には、KSM を無効にするとパフォーマンスが向上することがあります。
- Red Hat は、パフォーマンスが高く、低レイテンシーを必要とするワークロードには KSM およびオーバーコミットを推奨しません。高パフォーマンスの仮想マシンテンプレートおよびプールの設定 を参照してください。
- パフォーマンスよりも仮想マシンの密度 (経済性) を高めることが重要な場合は、KSM を使用します。
KSM を有効にするには、New Cluster またはEdit Cluster ウィンドウの Optimization タブをクリックします。次に、Enable KSMのチェックボックスを選択します。この設定を使用すると、MoM は必要なときに KSM を実行でき、CPU コストを上回るメモリー節約のメリットが得られます。クラスター最適化設定の説明 を参照してください。
2.3.2.22. UEFI と Q35 チップセット
新しい仮想マシンのデフォルトのチップセットであるインテル Q35 チップセットは、従来の BIOS に代わる UEFI (Unified Extensible Firmware Interface) に対応しています。
また、UEFI に対応していないレガシーの Intel i440fx チップセットを使用するように仮想マシンやクラスターを設定することもできます。
UEFI には、従来の BIOS に比べて以下のようなメリットがあります。
- 最新のブートローダー
- ブートローダーのデジタル署名を認証する SecureBoot
- 2TB 以上のディスクに対応した GUID パーティションテーブル (GPT)
仮想マシンで UEFI を使用するには、仮想マシンクラスターの互換性レベルを 4.4 以降に設定する必要があります。その後、既存の仮想マシンに UEFI を設定したり、クラスター内の新しい仮想マシンのデフォルト BIOS タイプに設定したりすることができます。以下のオプションを設定できます。
| BIOS タイプ | 説明 |
|---|---|
| Q35 チップセットとレガシー BIOS | UEFI 未対応のレガシー BIOS (互換性バージョン 4.4 のクラスターのデフォルト) |
| UEFI BIOS 対応の Q35 チップセット | UEFI 対応の BIOS |
| Q35 チップセット (SecureBoot 対応) | ブートローダーのデジタル署名を認証する SecureBoot に対応した UEFI |
| レガシー | レガシー BIOS に対応した i440fx チップセット |
OS インストール前の BIOS タイプの設定
オペレーティングシステムをインストールする前に、Q35 チップセットと UEFI を使用するように仮想マシンを設定できます。オペレーティングシステムのインストール後に、仮想マシンのレガシー BIOS から UEFI への変換はサポートされていません。
2.3.2.23. Q35 チップセットと UEFI を使用するクラスターの設定
クラスターを Red Hat Virtualization 4.4 にアップグレードすると、クラスター内のすべての仮想マシンが VDSM の 4.4 バージョンを実行します。クラスターのデフォルトの BIOS タイプを設定すると、そのクラスターで作成する新しい仮想マシンのデフォルトの BIOS タイプが決定されます。必要に応じて、仮想マシンの作成時に異なる BIOS タイプを指定して、クラスターのデフォルトの BIOS タイプを上書きできます。
手順
-
仮想マシンポータルまたは管理ポータルで、
をクリックします。 - クラスターを選択し、Edit をクリックします。
- General をクリックします。
クラスター内の新しい仮想マシンのデフォルトの BIOS タイプを定義するには、BIOS Type ドロップダウンメニューをクリックし、以下のいずれかを選択します。
- Legacy
- Q35 Chipset with Legacy BIOS
- Q35 Chipset with UEFI BIOS
- Q35 チップセット (SecureBoot 対応)
- Compatibility Version ドロップダウンメニューから 4.4 を選択します。Manager は、稼働中のすべてのホストが 4.4 と互換性があるかどうかを確認し、互換性がある場合は 4.4 の機能を使用します。
- クラスター内の既存の仮想マシンが新しい BIOS タイプを使用する必要がある場合は、そのように設定します。BIOS タイプとして Cluster default を使用するように設定されたクラスター内の新しい仮想マシンは、選択した BIOS タイプを使用するようになりました。詳細は、仮想マシンで Q35 チップセットと UEFI を使用するための設定 を参照してください。
BIOS タイプの変更はオペレーティングシステムのインストール前にしかできないため、BIOS タイプとして Cluster default を使用するように設定されている既存の仮想マシンについては、BIOS タイプを以前のデフォルトクラスターの BIOS タイプに変更してください。そうしないと、仮想マシンが起動しないことがあります。また、仮想マシンの OS を再インストールする方法もあります。
2.3.2.24. 仮想マシンで Q35 チップセットと UEFI を使用するための設定
オペレーティングシステムをインストールする前に、Q35 チップセットと UEFI を使用するように仮想マシンを設定できます。仮想マシンをレガシー BIOS から UEFI に変換したり、UEFI からレガシー BIOS に変換したりすると、仮想マシンが起動しなくなることがあります。既存の仮想マシンの BIOS タイプを変更した場合は、OS を再インストールしてください。
仮想マシンの BIOS タイプが Cluster default に設定されている場合、クラスターの BIOS タイプを変更すると、仮想マシンの BIOS タイプも変更されます。仮想マシンにオペレーティングシステムがインストールされている場合、クラスターの BIOS タイプを変更すると、仮想マシンの起動に失敗することがあります。
手順
Q35 チップセットと UEFI を使用するように仮想マシンを設定する方法:
-
仮想マシンポータルまたは管理ポータルで
をクリックします。 - 仮想マシンを選択し、Edit をクリックします。
- General タブで Show Advanced Options をクリックします。
-
をクリックします。 BIOS Typeドロップダウンメニューから以下のいずれかを選択します。
- Cluster default
- Q35 Chipset with Legacy BIOS
- Q35 Chipset with UEFI BIOS
- Q35 チップセット (SecureBoot 対応)
- をクリックします。
- 仮想マシンポータルまたは管理ポータルから、仮想マシンの電源をオフにします。次に仮想マシンを起動すると、選択した新しい BIOS タイプで実行されます。
2.3.2.25. クラスターの互換バージョンの変更
Red Hat Virtualization のクラスターには互換バージョンがあります。クラスターの互換バージョンは、そのクラスター内のすべてのホストがサポートする Red Hat Virtualization の機能を示します。クラスターの互換バージョンは、そのクラスター内で最も機能性の低いホストオペレーティングシステムのバージョンに応じて設定されます。
前提条件
- クラスターの互換レベルを変更するには、まず、クラスター内のすべてのホストを更新して、必要な互換性レベルをサポートするレベルにする必要がある。更新が利用可能であることを示すアイコンがホストの横にあるかどうかを確認します。
制限
クラスター互換性レベルを 4.6 にアップグレードすると、VirtIO NIC は別のデバイスとして列挙されます。そのため、NIC の再設定が必要になる場合があります。Red Hat は、仮想マシンをテストするために、クラスターをアップグレードする前に仮想マシンでクラスター互換性レベルを 4.6 に設定し、ネットワーク接続を確認することをお勧めします。
仮想マシンのネットワーク接続に失敗した場合は、クラスターをアップグレードする前に、現在のエミュレートされたマシンと一致するカスタムのエミュレートされたマシンを使用して、仮想マシンを設定します (例: 4.5 互換バージョンの場合は pc-q35-rhel8.3.0)。
手順
-
管理ポータルで、
をクリックします。 - 変更を行うクラスターを選択し、 をクリックします。
- General タブで Compatibility Version を必要な値に変更します。
- をクリックします。Change Cluster Compatibility Version の確認ダイアログが開きます。
- をクリックして確定します。
一部の仮想マシンおよびテンプレートが不適切に設定されていることを警告するエラーメッセージが表示される場合があります。このエラーを修正するには、それぞれの仮想マシンを手動で編集します。Edit Virtual Machine ウィンドウには、修正が必要な項目を示す追加の検証および警告が表示されます。問題が自動的に修正され、仮想マシンの設定を再度保存するだけで十分な場合もあります。それぞれの仮想マシンを編集したら、クラスターの互換バージョンを変更することができます。
クラスターの互換バージョンを更新したら、実行中または一時停止中のすべての仮想マシンについてクラスターの互換バージョンを更新する必要があります。そのためには、管理ポータルから再起動するか、REST API を使用するか、ゲストオペレーティングシステム内から更新する必要があります。再起動が必要な仮想マシンには、変更が保留されていることを示すアイコン (
 ) が付きます。プレビュー段階の仮想マシンスナップショットの場合、クラスターの互換バージョンは変更できません。まずコミットするか、プレビューを取り消す必要があります。
) が付きます。プレビュー段階の仮想マシンスナップショットの場合、クラスターの互換バージョンは変更できません。まずコミットするか、プレビューを取り消す必要があります。
セルフホスト型エンジン環境では、Manager 仮想マシンを再起動する必要はありません。
別途適切な時期に仮想マシンを再起動することもできますが、仮想マシンで最新の設定が使用されるように、直ちに再起動することを強く推奨します。更新されていない仮想マシンは古い設定で実行され、再起動前に仮想マシンに他の変更を加えた場合には新しい設定が上書きされてしまう可能性があります。
データセンター内のすべてのクラスターと仮想マシンの互換性バージョンを更新したら、データセンター自体の互換性バージョンを変更できます。