This documentation is for a release that is no longer maintained
See documentation for the latest supported version 3 or the latest supported version 4.14.6. 故障排除
14.6.1. 安装程序工作流故障排除
在对安装环境进行故障排除之前,了解裸机上安装程序置备安装的整体流至关重要。下图提供了故障排除流程,并按步骤划分环境。
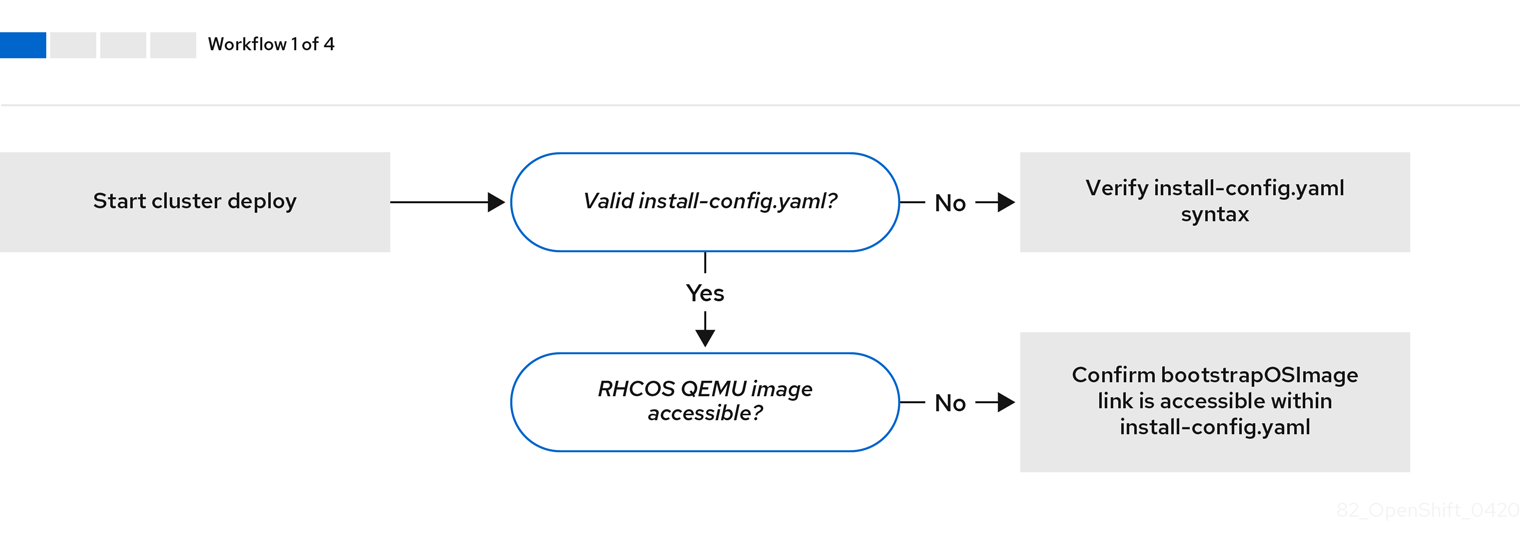
当 install-config.yaml 文件出错或者无法访问 Red Hat Enterprise Linux CoreOS(RHCOS)镜像时,工作流 1(共 4 步) 的工作流演示了故障排除工作流。故障排除建议可在 故障排除 install-config.yaml 中找到。
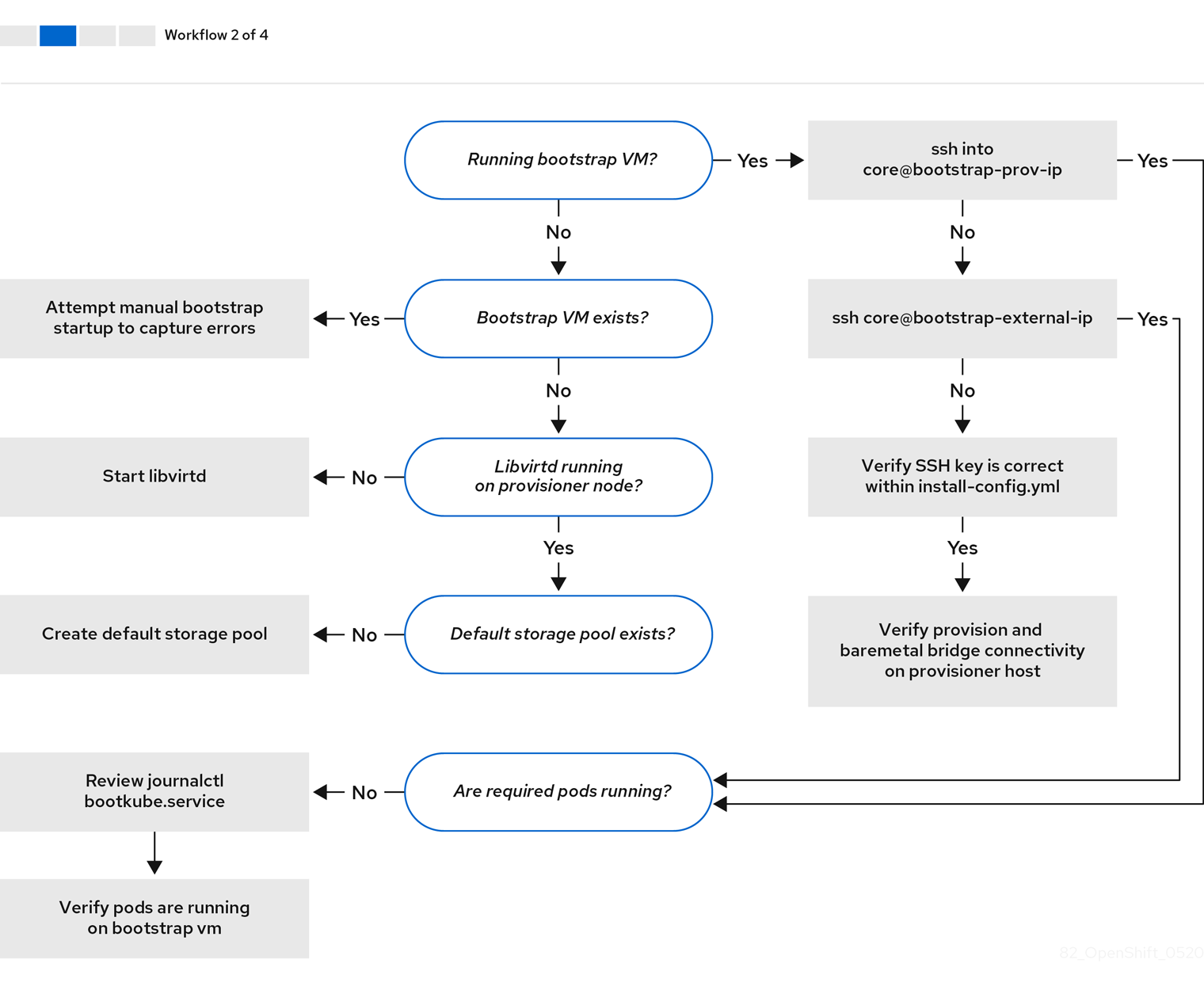
工作流 2(共 4 步)描述了对 bootstrap 虚拟机问题、 无法引导集群节点的 bootstrap 虚拟机 以及 检查日志 的故障排除工作流。当在没有 provisioning 网络的情况下安装 OpenShift Container Platform 集群时,此工作流将不应用。
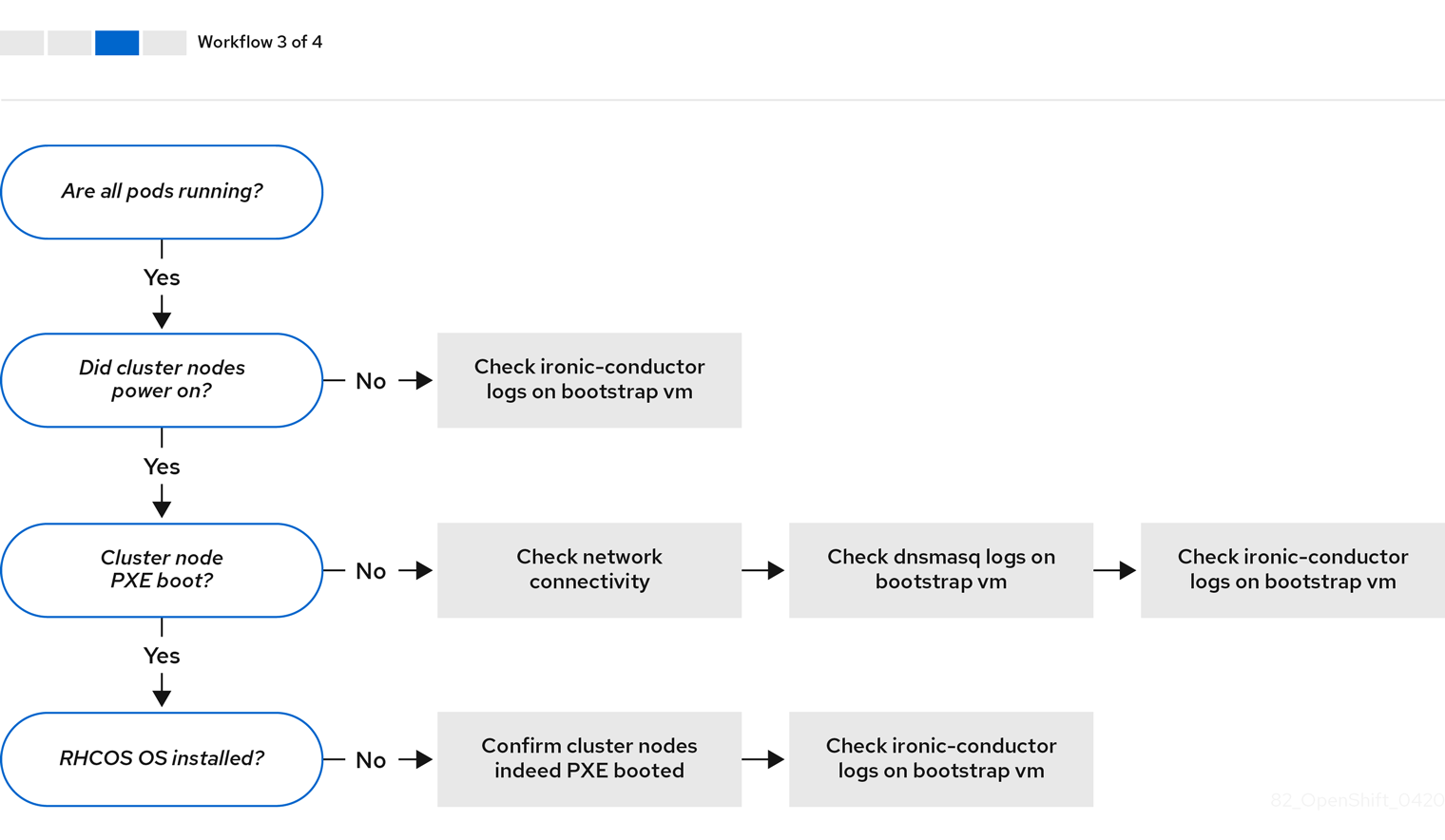
工作流 3(共 4 步)描述了 不能 PXE 引导的集群节点 的故障排除工作流。如果使用 RedFish Virtual Media 进行安装,则每个节点都必须满足安装程序部署该节点的最低固件要求。如需了解更多详细信息,请参阅先决条件部分中的使用虚拟介质安装的固件要求。
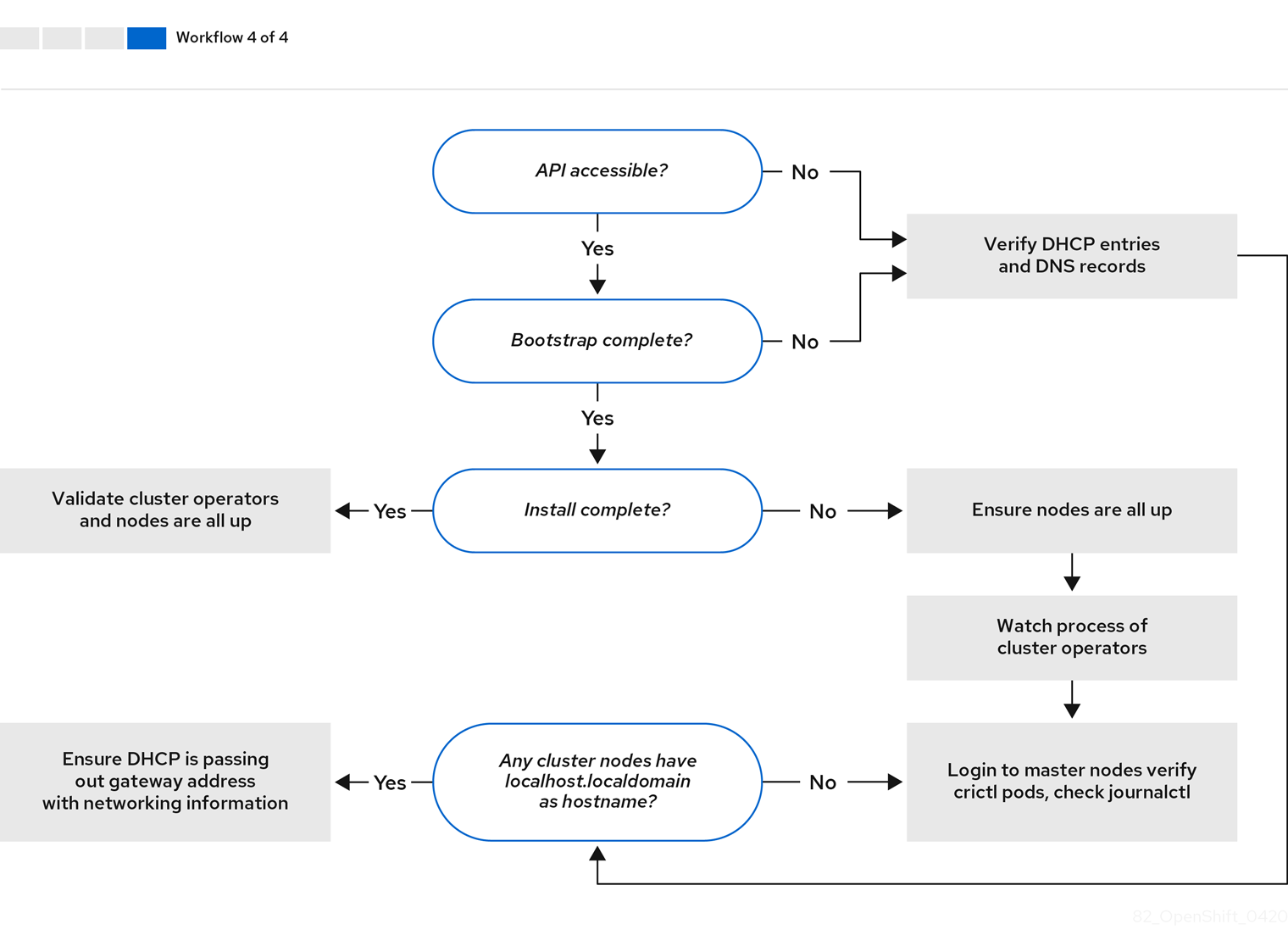
14.6.2. install-config.yaml故障排除
install-config.yaml 配置文件代表属于 OpenShift Container Platform 集群的所有节点。该文件包含由 apiVersion、baseDomain、imageContentSources 和虚拟 IP 地址组成的必要选项。如果在 OpenShift Container Platform 集群部署早期发生错误,install-config.yaml 配置文件中可能会出现错误。
流程
- 使用 YAML-tips 中的指南。
- 使用 syntax-check 验证 YAML 语法是否正确。
验证 Red Hat Enterprise Linux CoreOS(RHCOS)QEMU 镜像是否已正确定义,并可通过
install-config.yaml提供的 URL 访问。例如:curl -s -o /dev/null -I -w "%{http_code}\n" http://webserver.example.com:8080/rhcos-44.81.202004250133-0-qemu.<architecture>.qcow2.gz?sha256=7d884b46ee54fe87bbc3893bf2aa99af3b2d31f2e19ab5529c60636fbd0f1ce7$ curl -s -o /dev/null -I -w "%{http_code}\n" http://webserver.example.com:8080/rhcos-44.81.202004250133-0-qemu.<architecture>.qcow2.gz?sha256=7d884b46ee54fe87bbc3893bf2aa99af3b2d31f2e19ab5529c60636fbd0f1ce7Copy to Clipboard Copied! Toggle word wrap Toggle overflow 如果输出为
200,则会从存储 bootstrap 虚拟机镜像的 webserver 获得有效的响应。
14.6.3. Bootstrap 虚拟机问题
OpenShift Container Platform 安装程序生成 bootstrap 节点虚拟机,该虚拟机处理置备 OpenShift Container Platform 集群节点。
流程
触发安装程序后大约 10 到 15 分钟,使用
virsh命令检查 bootstrap 虚拟机是否正常工作:sudo virsh list
$ sudo virsh listCopy to Clipboard Copied! Toggle word wrap Toggle overflow Id Name State -------------------------------------------- 12 openshift-xf6fq-bootstrap running
Id Name State -------------------------------------------- 12 openshift-xf6fq-bootstrap runningCopy to Clipboard Copied! Toggle word wrap Toggle overflow 注意bootstrap 虚拟机的名称始终是集群名称,后跟一组随机字符,并以"bootstrap"结尾。
如果 bootstrap 虚拟机在 10-15 分钟后没有运行,请对它进行故障排除。可能的问题包括:
验证
libvirtd是否在系统中运行:systemctl status libvirtd
$ systemctl status libvirtdCopy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow 如果 bootstrap 虚拟机可以正常工作,请登录它。
使用
virsh console命令查找 bootstrap 虚拟机的 IP 地址:sudo virsh console example.com
$ sudo virsh console example.comCopy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow 重要当在没有
provisioning网络的情况下部署 OpenShift Container Platform 集群时,您必须使用公共 IP 地址,而不是专用 IP 地址,如172.22.0.2。获取 IP 地址后,使用
ssh命令登录到 bootstrap 虚拟机:注意在上一步的控制台输出中,您可以使用 ens3 提供的 IPv6 IP 地址或
ens4 提供的 IPv4 IP 地址。ssh core@172.22.0.2
$ ssh core@172.22.0.2Copy to Clipboard Copied! Toggle word wrap Toggle overflow
如果您无法成功登录 bootstrap 虚拟机,您可能会遇到以下情况之一:
-
您无法访问
172.22.0.0/24网络。验证 provisioner 和provisioning网桥之间的网络连接。如果您使用provisioning网络,则可能会出现此问题。' -
您无法通过公共网络访问 bootstrap 虚拟机。当尝试 SSH via
baremetal 网络时,验证provisioner主机上的连接情况,特别是baremetal网桥的连接。 -
您遇到了
Permission denied(publickey,password,keyboard-interactive)的问题。当尝试访问 bootstrap 虚拟机时,可能会出现Permission denied错误。验证尝试登录到虚拟机的用户的 SSH 密钥是否在install-config.yaml文件中设置。
14.6.3.1. Bootstrap 虚拟机无法引导集群节点
在部署过程中,bootstrap 虚拟机可能无法引导集群节点,这会阻止虚拟机使用 RHCOS 镜像置备节点。这可能是因为以下原因:
-
install-config.yaml文件存在问题。 - 使用 baremetal 网络时出现带外网络访问的问题。
要验证这个问题,有三个与 ironic 相关的容器:
-
ironic -
ironic-inspector
流程
登录到 bootstrap 虚拟机:
ssh core@172.22.0.2
$ ssh core@172.22.0.2Copy to Clipboard Copied! Toggle word wrap Toggle overflow 要检查容器日志,请执行以下操作:
sudo podman logs -f <container_name>
[core@localhost ~]$ sudo podman logs -f <container_name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 将
<container_name>替换为ironic或ironic-inspector之一。如果您遇到 control plane 节点没有从 PXE 引导的问题,请检查ironicpod。ironicpod 包含有关尝试引导集群节点的信息,因为它尝试通过 IPMI 登录节点。
潜在原因
集群节点在部署启动时可能处于 ON 状态。
解决方案
在通过 IPMI 开始安装前关闭 OpenShift Container Platform 集群节点:
ipmitool -I lanplus -U root -P <password> -H <out_of_band_ip> power off
$ ipmitool -I lanplus -U root -P <password> -H <out_of_band_ip> power off14.6.3.2. 检查日志
在下载或访问 RHCOS 镜像时,首先验证 install-config.yaml 配置文件中的 URL 是否正确。
内部 webserver 托管 RHCOS 镜像的示例
bootstrapOSImage: http://<ip:port>/rhcos-43.81.202001142154.0-qemu.<architecture>.qcow2.gz?sha256=9d999f55ff1d44f7ed7c106508e5deecd04dc3c06095d34d36bf1cd127837e0c clusterOSImage: http://<ip:port>/rhcos-43.81.202001142154.0-openstack.<architecture>.qcow2.gz?sha256=a1bda656fa0892f7b936fdc6b6a6086bddaed5dafacedcd7a1e811abb78fe3b0
bootstrapOSImage: http://<ip:port>/rhcos-43.81.202001142154.0-qemu.<architecture>.qcow2.gz?sha256=9d999f55ff1d44f7ed7c106508e5deecd04dc3c06095d34d36bf1cd127837e0c
clusterOSImage: http://<ip:port>/rhcos-43.81.202001142154.0-openstack.<architecture>.qcow2.gz?sha256=a1bda656fa0892f7b936fdc6b6a6086bddaed5dafacedcd7a1e811abb78fe3b0
coreos-downloader 容器从 webserver 或外部 quay.io registry 下载资源(由 install-config.yaml 配置文件指定)。验证 coreos-downloader 容器是否正在运行,并根据需要检查其日志。
流程
登录到 bootstrap 虚拟机:
ssh core@172.22.0.2
$ ssh core@172.22.0.2Copy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令,检查 bootstrap 虚拟机中的
coreos-downloader容器的状态:sudo podman logs -f coreos-downloader
[core@localhost ~]$ sudo podman logs -f coreos-downloaderCopy to Clipboard Copied! Toggle word wrap Toggle overflow 如果 bootstrap 虚拟机无法访问镜像的 URL,请使用
curl命令验证虚拟机是否可以访问镜像。要检查
bootkube日志,以指示部署阶段是否启动了所有容器,请执行以下操作:journalctl -xe
[core@localhost ~]$ journalctl -xeCopy to Clipboard Copied! Toggle word wrap Toggle overflow journalctl -b -f -u bootkube.service
[core@localhost ~]$ journalctl -b -f -u bootkube.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow 验证包括
dnsmasq、mariadb、httpd和ironic等所有 pod 都在运行:sudo podman ps
[core@localhost ~]$ sudo podman psCopy to Clipboard Copied! Toggle word wrap Toggle overflow 如果 pod 存在问题,请检查有问题的容器日志。要检查
ironic服务的日志,请运行以下命令:sudo podman logs ironic
[core@localhost ~]$ sudo podman logs ironicCopy to Clipboard Copied! Toggle word wrap Toggle overflow
14.6.4. 集群节点不能 PXE 引导
当 OpenShift Container Platform 集群节点无法 PXE 引导时,请在不能 PXE 引导的集群节点上执行以下检查。在没有 provisioning 网络安装 OpenShift Container Platform 集群时,此流程不适用。
流程
-
检查与
provisioning网络的网络连接。 -
确保
provisioning网络的 NIC 上启用了 PXE,并为所有其他 NIC 禁用 PXE。 验证
install-config.yaml配置文件具有正确的硬件配置集,以及连接到provisioning网络的 NIC 的引导 MAC 地址。例如:control plane 节点设置
bootMACAddress: 24:6E:96:1B:96:90 # MAC of bootable provisioning NIC hardwareProfile: default #control plane node settings
bootMACAddress: 24:6E:96:1B:96:90 # MAC of bootable provisioning NIC hardwareProfile: default #control plane node settingsCopy to Clipboard Copied! Toggle word wrap Toggle overflow Worker 节点设置
bootMACAddress: 24:6E:96:1B:96:90 # MAC of bootable provisioning NIC hardwareProfile: unknown #worker node settings
bootMACAddress: 24:6E:96:1B:96:90 # MAC of bootable provisioning NIC hardwareProfile: unknown #worker node settingsCopy to Clipboard Copied! Toggle word wrap Toggle overflow
14.6.5. 无法使用 BMC 发现新的裸机主机
在某些情况下,安装程序将无法发现新的裸机主机并发出错误,因为它无法挂载远程虚拟介质共享。
例如:
在这种情况下,如果您使用带有未知证书颁发机构的虚拟介质,您可以配置基板管理控制器 (BMC) 远程文件共享设置,以信任未知证书颁发机构以避免这个错误。
这个解析已在带有 Dell iDRAC 9 的 OpenShift Container Platform 4.11 上测试,固件版本 5.10.50。
14.6.6. API 无法访问
当集群正在运行且客户端无法访问 API 时,域名解析问题可能会妨碍对 API 的访问。
流程
主机名解析: 检查集群节点,确保它们具有完全限定域名,而不只是
localhost.localdomain。例如:hostname
$ hostnameCopy to Clipboard Copied! Toggle word wrap Toggle overflow 如果没有设置主机名,请设置正确的主机名。例如:
hostnamectl set-hostname <hostname>
$ hostnamectl set-hostname <hostname>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 错误的名称解析: 使用
dig和nslookup,确保每个节点在 DNS 服务器中具有正确的名称解析。例如:dig api.<cluster_name>.example.com
$ dig api.<cluster_name>.example.comCopy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow 示例中的输出显示
api.<cluster_name>.example.comVIP 的适当 IP 地址为10.19.13.86。此 IP 地址应当位于baremetal网络中。
14.6.7. 无法加入集群的 worker 节点故障排除
安装程序置备的集群使用 DNS 服务器部署,其中包含 api-int.<cluster_name>.<base_domain> URL 的 DNS 条目。如果集群中的节点使用外部或上游 DNS 服务器解析 api-int.<cluster_name>.<base_domain> URL,且没有这样的条目,则 worker 节点可能无法加入集群。确保集群中的所有节点都可以解析域名。
流程
添加 DNS A/AAAA 或 CNAME 记录,以内部标识 API 负载均衡器。例如,在使用 dnsmasq 时,修改
dnsmasq.conf配置文件:sudo nano /etc/dnsmasq.conf
$ sudo nano /etc/dnsmasq.confCopy to Clipboard Copied! Toggle word wrap Toggle overflow address=/api-int.<cluster_name>.<base_domain>/<IP_address> address=/api-int.mycluster.example.com/192.168.1.10 address=/api-int.mycluster.example.com/2001:0db8:85a3:0000:0000:8a2e:0370:7334
address=/api-int.<cluster_name>.<base_domain>/<IP_address> address=/api-int.mycluster.example.com/192.168.1.10 address=/api-int.mycluster.example.com/2001:0db8:85a3:0000:0000:8a2e:0370:7334Copy to Clipboard Copied! Toggle word wrap Toggle overflow 添加 DNS PTR 记录以内部标识 API 负载均衡器。例如,在使用 dnsmasq 时,修改
dnsmasq.conf配置文件:sudo nano /etc/dnsmasq.conf
$ sudo nano /etc/dnsmasq.confCopy to Clipboard Copied! Toggle word wrap Toggle overflow ptr-record=<IP_address>.in-addr.arpa,api-int.<cluster_name>.<base_domain> ptr-record=10.1.168.192.in-addr.arpa,api-int.mycluster.example.com
ptr-record=<IP_address>.in-addr.arpa,api-int.<cluster_name>.<base_domain> ptr-record=10.1.168.192.in-addr.arpa,api-int.mycluster.example.comCopy to Clipboard Copied! Toggle word wrap Toggle overflow 重启 DNS 服务器。例如,在使用 dnsmasq 时执行以下命令:
sudo systemctl restart dnsmasq
$ sudo systemctl restart dnsmasqCopy to Clipboard Copied! Toggle word wrap Toggle overflow
这些记录必须可以从集群中的所有节点解析。
14.6.8. 清理以前的安装
如果以前部署失败,在尝试再次部署 OpenShift Container Platform 前从失败的尝试中删除工件。
流程
在安装 OpenShift Container Platform 集群前关闭所有裸机节点:
ipmitool -I lanplus -U <user> -P <password> -H <management_server_ip> power off
$ ipmitool -I lanplus -U <user> -P <password> -H <management_server_ip> power offCopy to Clipboard Copied! Toggle word wrap Toggle overflow 删除所有旧的 bootstrap 资源(如果以前的部署尝试中保留):
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 从
clusterconfigs目录中删除以下内容以防止 Terraform 失败:rm -rf ~/clusterconfigs/auth ~/clusterconfigs/terraform* ~/clusterconfigs/tls ~/clusterconfigs/metadata.json
$ rm -rf ~/clusterconfigs/auth ~/clusterconfigs/terraform* ~/clusterconfigs/tls ~/clusterconfigs/metadata.jsonCopy to Clipboard Copied! Toggle word wrap Toggle overflow
14.6.9. 创建 registry 的问题
在创建断开连接的 registry 时,在尝试镜像 registry 时,可能会遇到 "User Not Authorized" 错误。如果您没有将新身份验证附加到现有的 pull-secret.txt 文件中,可能会发生这个错误。
流程
检查以确保身份验证成功:
/usr/local/bin/oc adm release mirror \ -a pull-secret-update.json
$ /usr/local/bin/oc adm release mirror \ -a pull-secret-update.json --from=$UPSTREAM_REPO \ --to-release-image=$LOCAL_REG/$LOCAL_REPO:${VERSION} \ --to=$LOCAL_REG/$LOCAL_REPOCopy to Clipboard Copied! Toggle word wrap Toggle overflow 注意用于镜像安装镜像的变量输出示例:
UPSTREAM_REPO=${RELEASE_IMAGE} LOCAL_REG=<registry_FQDN>:<registry_port> LOCAL_REPO='ocp4/openshift4'UPSTREAM_REPO=${RELEASE_IMAGE} LOCAL_REG=<registry_FQDN>:<registry_port> LOCAL_REPO='ocp4/openshift4'Copy to Clipboard Copied! Toggle word wrap Toggle overflow 在为 OpenShift 安装设置环境 部分的 获取 OpenShift 安装程序 步骤中,设置了
RELEASE_IMAGE和VERSION的值。镜像 registry 后,确认您可以在断开连接的环境中访问它:
curl -k -u <user>:<password> https://registry.example.com:<registry_port>/v2/_catalog
$ curl -k -u <user>:<password> https://registry.example.com:<registry_port>/v2/_catalog {"repositories":["<Repo_Name>"]}Copy to Clipboard Copied! Toggle word wrap Toggle overflow
14.6.10. 其它问题
14.6.10.1. 解决 运行时网络未就绪 错误
部署集群后,您可能会收到以下错误:
`runtime network not ready: NetworkReady=false reason:NetworkPluginNotReady message:Network plugin returns error: Missing CNI default network`
`runtime network not ready: NetworkReady=false reason:NetworkPluginNotReady message:Network plugin returns error: Missing CNI default network`
Cluster Network Operator 负责部署网络组件以响应安装程序创建的特殊对象。它会在安装过程的早期阶段运行(在 control plane(master)节点启动后,bootstrap control plane 被停止前运行。它可能表明存在更细微的安装程序问题,如启动 control plane(master)节点时延迟时间过长,或者 apiserver 通讯的问题。
流程
检查
openshift-network-operator命名空间中的 pod:oc get all -n openshift-network-operator
$ oc get all -n openshift-network-operatorCopy to Clipboard Copied! Toggle word wrap Toggle overflow NAME READY STATUS RESTARTS AGE pod/network-operator-69dfd7b577-bg89v 0/1 ContainerCreating 0 149m
NAME READY STATUS RESTARTS AGE pod/network-operator-69dfd7b577-bg89v 0/1 ContainerCreating 0 149mCopy to Clipboard Copied! Toggle word wrap Toggle overflow 在
provisioner节点上,确定存在网络配置:kubectl get network.config.openshift.io cluster -oyaml
$ kubectl get network.config.openshift.io cluster -oyamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow 如果不存在,安装程序不会创建它。要确定安装程序没有创建它的原因,请执行以下操作:
openshift-install create manifests
$ openshift-install create manifestsCopy to Clipboard Copied! Toggle word wrap Toggle overflow 检查
network-operator是否正在运行:kubectl -n openshift-network-operator get pods
$ kubectl -n openshift-network-operator get podsCopy to Clipboard Copied! Toggle word wrap Toggle overflow 检索日志:
kubectl -n openshift-network-operator logs -l "name=network-operator"
$ kubectl -n openshift-network-operator logs -l "name=network-operator"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 在具有三个或更多 control plane(master)节点的高可用性集群中,Operator 将执行领导选举机制,所有其他 Operator 会休眠。如需了解更多详细信息,请参阅 故障排除。
14.6.10.2. 集群节点没有通过 DHCP 获得正确的 IPv6 地址
如果集群节点没有通过 DHCP 获得正确的 IPv6 地址,请检查以下内容:
- 确保保留的 IPv6 地址不在 DHCP 范围内。
在 DHCP 服务器上的 IP 地址保留中,确保保留指定了正确的 DHCP 唯一标识符(DUID)。例如:
This is a dnsmasq dhcp reservation, 'id:00:03:00:01' is the client id and '18:db:f2:8c:d5:9f' is the MAC Address for the NIC
# This is a dnsmasq dhcp reservation, 'id:00:03:00:01' is the client id and '18:db:f2:8c:d5:9f' is the MAC Address for the NIC id:00:03:00:01:18:db:f2:8c:d5:9f,openshift-master-1,[2620:52:0:1302::6]Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 确保路由声明正常工作。
- 确保 DHCP 服务器正在侦听提供 IP 地址范围所需的接口。
14.6.10.3. 集群节点没有通过 DHCP 获得正确的主机名
在 IPv6 部署过程中,集群节点必须通过 DHCP 获得其主机名。有时 NetworkManager 不会立即分配主机名。control plane(master)节点可能会报告错误,例如:
Failed Units: 2 NetworkManager-wait-online.service nodeip-configuration.service
Failed Units: 2
NetworkManager-wait-online.service
nodeip-configuration.service
这个错误表示集群节点可能在没有从 DHCP 服务器接收主机名的情况下引导,这会导致 kubelet 使用 localhost.localdomain 主机名引导。要解决错误,请强制节点更新主机名。
流程
检索
主机名:hostname
[core@master-X ~]$ hostnameCopy to Clipboard Copied! Toggle word wrap Toggle overflow 如果主机名是
localhost,请执行以下步骤。注意其中
X是 control plane 节点号。强制集群节点续订 DHCP 租期:
sudo nmcli con up "<bare_metal_nic>"
[core@master-X ~]$ sudo nmcli con up "<bare_metal_nic>"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 将
<bare_metal_nic>替换为与baremetal网络对应的有线连接。再次检查
主机名:hostname
[core@master-X ~]$ hostnameCopy to Clipboard Copied! Toggle word wrap Toggle overflow 如果主机名仍然是
localhost.localdomain,重启NetworkManager:sudo systemctl restart NetworkManager
[core@master-X ~]$ sudo systemctl restart NetworkManagerCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
如果主机名仍然是
localhost.localdomain,请等待几分钟并再次检查。如果主机名仍为localhost.localdomain,请重复前面的步骤。 重启
nodeip-configuration服务:sudo systemctl restart nodeip-configuration.service
[core@master-X ~]$ sudo systemctl restart nodeip-configuration.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow 此服务将使用正确的主机名引用来重新配置
kubelet服务。因为 kubelet 在上一步中更改,所以重新载入单元文件定义:
sudo systemctl daemon-reload
[core@master-X ~]$ sudo systemctl daemon-reloadCopy to Clipboard Copied! Toggle word wrap Toggle overflow 重启
kubelet服务:sudo systemctl restart kubelet.service
[core@master-X ~]$ sudo systemctl restart kubelet.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow 确保
kubelet使用正确的主机名引导:sudo journalctl -fu kubelet.service
[core@master-X ~]$ sudo journalctl -fu kubelet.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow
如果集群节点在集群启动并运行后没有通过 DHCP 获得正确的主机名,比如在重启过程中,集群会有一个待处理的 csr。不要 批准 csr,否则可能会出现其他问题。
处理 csr
在集群上获取 CSR:
oc get csr
$ oc get csrCopy to Clipboard Copied! Toggle word wrap Toggle overflow 验证待处理的
csr是否包含Subject Name: localhost.localdomain:oc get csr <pending_csr> -o jsonpath='{.spec.request}' | base64 --decode | openssl req -noout -text$ oc get csr <pending_csr> -o jsonpath='{.spec.request}' | base64 --decode | openssl req -noout -textCopy to Clipboard Copied! Toggle word wrap Toggle overflow 删除包含
Subject Name: localhost.localdomain的任何csr:oc delete csr <wrong_csr>
$ oc delete csr <wrong_csr>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
14.6.10.4. 路由无法访问端点
在安装过程中,可能会出现虚拟路由器冗余协议(VRRP)冲突。如果之前使用特定集群名称部署的 OpenShift Container Platform 节点仍在运行,但不是使用相同集群名称部署的当前 OpenShift Container Platform 集群的一部分,则可能会出现冲突。例如,一个集群使用集群名称 openshift 部署,它 部署了三个 control plane(master)节点和三个 worker 节点。之后,一个单独的安装使用相同的集群名称 openshift,但这个重新部署只安装了三个 control plane(master)节点,使以前部署的三个 worker 节点处于 ON 状态。这可能导致 Virtual Router Identifier(VRID)冲突和 VRRP 冲突。
获取路由:
oc get route oauth-openshift
$ oc get route oauth-openshiftCopy to Clipboard Copied! Toggle word wrap Toggle overflow 检查服务端点:
oc get svc oauth-openshift
$ oc get svc oauth-openshiftCopy to Clipboard Copied! Toggle word wrap Toggle overflow NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE oauth-openshift ClusterIP 172.30.19.162 <none> 443/TCP 59m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE oauth-openshift ClusterIP 172.30.19.162 <none> 443/TCP 59mCopy to Clipboard Copied! Toggle word wrap Toggle overflow 尝试从 control plane(master)节点访问该服务:
curl -k https://172.30.19.162
[core@master0 ~]$ curl -k https://172.30.19.162Copy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow 识别
provisioner节点的 authentication-operator错误:oc logs deployment/authentication-operator -n openshift-authentication-operator
$ oc logs deployment/authentication-operator -n openshift-authentication-operatorCopy to Clipboard Copied! Toggle word wrap Toggle overflow Event(v1.ObjectReference{Kind:"Deployment", Namespace:"openshift-authentication-operator", Name:"authentication-operator", UID:"225c5bd5-b368-439b-9155-5fd3c0459d98", APIVersion:"apps/v1", ResourceVersion:"", FieldPath:""}): type: 'Normal' reason: 'OperatorStatusChanged' Status for clusteroperator/authentication changed: Degraded message changed from "IngressStateEndpointsDegraded: All 2 endpoints for oauth-server are reporting"Event(v1.ObjectReference{Kind:"Deployment", Namespace:"openshift-authentication-operator", Name:"authentication-operator", UID:"225c5bd5-b368-439b-9155-5fd3c0459d98", APIVersion:"apps/v1", ResourceVersion:"", FieldPath:""}): type: 'Normal' reason: 'OperatorStatusChanged' Status for clusteroperator/authentication changed: Degraded message changed from "IngressStateEndpointsDegraded: All 2 endpoints for oauth-server are reporting"Copy to Clipboard Copied! Toggle word wrap Toggle overflow
解决方案
- 确保每个部署的集群名称都是唯一的,确保没有冲突。
- 关闭所有不是使用相同集群名称的集群部署的一部分的节点。否则,OpenShift Container Platform 集群的身份验证 pod 可能无法成功启动。
14.6.10.5. 在 Firstboot 过程中 Ignition 失败
在 Firstboot 过程中,Ignition 配置可能会失败。
流程
连接到 Ignition 配置失败的节点:
Failed Units: 1 machine-config-daemon-firstboot.service
Failed Units: 1 machine-config-daemon-firstboot.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow 重启
machine-config-daemon-firstboot服务:sudo systemctl restart machine-config-daemon-firstboot.service
[core@worker-X ~]$ sudo systemctl restart machine-config-daemon-firstboot.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow
14.6.10.6. NTP 不同步
OpenShift Container Platform 集群的部署需要集群节点间的 NTP 同步时钟。如果没有同步时钟,如果时间差大于 2 秒,则部署可能会因为时钟偏移而失败。
流程
检查集群节点的
AGE的不同。例如:oc get nodes
$ oc get nodesCopy to Clipboard Copied! Toggle word wrap Toggle overflow NAME STATUS ROLES AGE VERSION master-0.cloud.example.com Ready master 145m v1.24.0 master-1.cloud.example.com Ready master 135m v1.24.0 master-2.cloud.example.com Ready master 145m v1.24.0 worker-2.cloud.example.com Ready worker 100m v1.24.0
NAME STATUS ROLES AGE VERSION master-0.cloud.example.com Ready master 145m v1.24.0 master-1.cloud.example.com Ready master 135m v1.24.0 master-2.cloud.example.com Ready master 145m v1.24.0 worker-2.cloud.example.com Ready worker 100m v1.24.0Copy to Clipboard Copied! Toggle word wrap Toggle overflow 检查时钟偏移导致的时间延迟。例如:
oc get bmh -n openshift-machine-api
$ oc get bmh -n openshift-machine-apiCopy to Clipboard Copied! Toggle word wrap Toggle overflow master-1 error registering master-1 ipmi://<out_of_band_ip>
master-1 error registering master-1 ipmi://<out_of_band_ip>Copy to Clipboard Copied! Toggle word wrap Toggle overflow sudo timedatectl
$ sudo timedatectlCopy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow
处理现有集群中的时钟偏移
创建一个 Butane 配置文件,其中包含要发送到节点的
chrony.conf文件的内容。在以下示例中,创建99-master-chrony.bu将文件添加到 control plane 节点。您可以修改 worker 节点的 文件,或者对 worker 角色重复此步骤。注意有关 Butane 的信息,请参阅"使用 Butane 创建机器配置"。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 将
<NTP_server>替换为 NTP 服务器的 IP 地址。
使用 Butane 生成
MachineConfig对象文件99-master-chrony.yaml,其中包含要交付至节点的配置:butane 99-master-chrony.bu -o 99-master-chrony.yaml
$ butane 99-master-chrony.bu -o 99-master-chrony.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 应用
MachineConfig对象文件:oc apply -f 99-master-chrony.yaml
$ oc apply -f 99-master-chrony.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 确保
系统时钟同步值为 yes :sudo timedatectl
$ sudo timedatectlCopy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow 要在部署前设置时钟同步,请生成清单文件并将此文件添加到
openshift目录中。例如:cp chrony-masters.yaml ~/clusterconfigs/openshift/99_masters-chrony-configuration.yaml
$ cp chrony-masters.yaml ~/clusterconfigs/openshift/99_masters-chrony-configuration.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 然后,继续创建集群。
14.6.11. 检查安装
安装后,请确保安装程序成功部署了节点和容器集。
流程
当正确安装 OpenShift Container Platform 集群节点时,在
STATUS列中会显示以下Ready 状态:oc get nodes
$ oc get nodesCopy to Clipboard Copied! Toggle word wrap Toggle overflow NAME STATUS ROLES AGE VERSION master-0.example.com Ready master,worker 4h v1.24.0 master-1.example.com Ready master,worker 4h v1.24.0 master-2.example.com Ready master,worker 4h v1.24.0
NAME STATUS ROLES AGE VERSION master-0.example.com Ready master,worker 4h v1.24.0 master-1.example.com Ready master,worker 4h v1.24.0 master-2.example.com Ready master,worker 4h v1.24.0Copy to Clipboard Copied! Toggle word wrap Toggle overflow 确认安装程序成功部署了所有容器集。以下命令将移除仍在运行或已完成的 pod 作为输出的一部分。
oc get pods --all-namespaces | grep -iv running | grep -iv complete
$ oc get pods --all-namespaces | grep -iv running | grep -iv completeCopy to Clipboard Copied! Toggle word wrap Toggle overflow