8.4. Splitter
概要
Splitter は、受信メッセージを一連の送信メッセージに分割するルーターの種類です。それぞれの送信メッセージには、元のメッセージの一部が含まれています。Apache Camel では、図8.4「Splitter パターン」 に示される Splitter パターンは、split() Java DSL コマンドによって実装されます。
図8.4 Splitter パターン
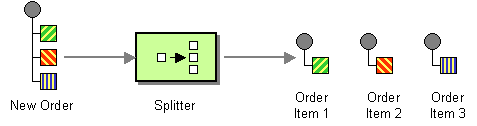
Apache Camel Splitter は、以下の 2 つのパターンをサポートします。
- Simple splitter - Splitter パターンを独自に実装します。
- Splitter/Aggregator - Splitter パターンと Aggregator パターンを組み合わせることで、メッセージの断片が処理された後に再結合されます。
Splitter はオリジナルのメッセージを分割する前に、オリジナルのメッセージのシャローコピーを作成します。シャローコピーでは、元のメッセージのヘッダーおよびペイロードは参照としてのみコピーされます。Splitter 自体は、結果として得られたメッセージの一部を異るエンドポイントにルーティングすることはありませんが、分割されたメッセージの一部は、セカンダリールーティングの影響を受ける可能性があります。
メッセージ部分はシャローコピーであるため、元のメッセージにリンクされたままになります。そのため、それらを単独で修正することはできません。複数のエンドポイントにルーティングする前に、メッセージの異なるコピーへカスタムロジックを適用する場合、splitter 句の onPrepareRef DSL オプションを使用して、オリジナルのメッセージのディープコピーを作成する必要があります。オプションの使用方法は、「オプション」 を参照してください。
Java DSL の例
以下の例は、seda:a から seda:b へのルートを定義し、受信メッセージの各行を個別の送信メッセージへ変換することでメッセージを分割しています。
RouteBuilder builder = new RouteBuilder() {
public void configure() {
from("seda:a")
.split(bodyAs(String.class).tokenize("\n"))
.to("seda:b");
}
};
Splitter は式言語を使用できるため、XPath、XQuery、SQL などのサポートされているスクリプト言語を使用して、メッセージを分割することができます (パートII「ルーティング式と述語言語」 を参照)。以下の例は、受信メッセージから bar 要素を抽出し、それらを別々の送信メッセージに挿入しています。
from("activemq:my.queue")
.split(xpath("//foo/bar"))
.to("file://some/directory")XML 設定の例
以下の例は、XPath スクリプト言語を使用して、XML で Splitter ルートを定義する方法を示しています。
<camelContext id="buildSplitter" xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="seda:a"/>
<split>
<xpath>//foo/bar</xpath>
<to uri="seda:b"/>
</split>
</route>
</camelContext>
XML DSL の tokenize 式を使用して、トークンを使い、ボディーまたはヘッダーを分割できます。tokenize 式は、tokenize 要素で定義します。以下の例では、メッセージボディーは \n 区切り文字を使用してトークン化されています。正規表現パターンを使用するには、tokenize 要素に regex=true を設定します。
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<split>
<tokenize token="\n"/>
<to uri="mock:result"/>
</split>
</route>
</camelContext>行のグループに分割
大きなファイルを 1000 行のブロックに分割するには、以下のように Splitter ルートを定義します。
from("file:inbox")
.split().tokenize("\n", 1000).streaming()
.to("activemq:queue:order");
tokenize への第 2 引数は、1 つのチャンクにグループ化されるべき行数を指定します。streaming() 句は、ファイル全体を同時に読み取りしないよう Splitter に指示します (ファイルが大きい場合のパフォーマンスがはるかに改善されます)。
以下のように、XML DSL で同じルートを定義できます。
<route>
<from uri="file:inbox"/>
<split streaming="true">
<tokenize token="\n" group="1000"/>
<to uri="activemq:queue:order"/>
</split>
</route>
group オプションを使用する際の出力は常に、java.lang.String 型になります。
最初の項目のスキップ
メッセージの最初の項目をスキップするには、skipFirst オプションを使用します。
Java DSL では、tokenize パラメーターの 3 番目のオプションに true を指定します。
from("direct:start")
// split by new line and group by 3, and skip the very first element
.split().tokenize("\n", 3, true).streaming()
.to("mock:group");以下のように、XML DSL で同じルートを定義できます。
<route>
<from uri="file:inbox"/>
<split streaming="true">
<tokenize token="\n" group="1000" skipFirst="true" />
<to uri="activemq:queue:order"/>
</split>
</route>Splitter のリプライ
Splitter に入るエクスチェンジが InOut メッセージ交換パターンである場合 (つまりリプライが想定される場合)、Splitter は元の入力メッセージのコピーを Out メッセージスロットのリプライメッセージとして返します。独自の 集約ストラテジー を実装して、このデフォルト動作をオーバーライドすることができます。
並列実行
生成されたメッセージを並行に実行する場合、並列処理オプションを有効にして、生成されたメッセージを処理するためのスレッドプールをインスタンス化します。以下に例を示します。
XPathBuilder xPathBuilder = new XPathBuilder("//foo/bar");
from("activemq:my.queue").split(xPathBuilder).parallelProcessing().to("activemq:my.parts");
並行 Splitter で使用される基盤となる ThreadPoolExecutor をカスタマイズすることができます。たとえば、以下のように Java DSL でカスタムエクゼキューターを指定することができます。
XPathBuilder xPathBuilder = new XPathBuilder("//foo/bar");
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(8, 16, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue());
from("activemq:my.queue")
.split(xPathBuilder)
.parallelProcessing()
.executorService(threadPoolExecutor)
.to("activemq:my.parts");以下のように、XML DSL でカスタムエクゼキューターを指定できます。
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:parallel-custom-pool"/>
<split executorServiceRef="threadPoolExecutor">
<xpath>/invoice/lineItems</xpath>
<to uri="mock:result"/>
</split>
</route>
</camelContext>
<bean id="threadPoolExecutor" class="java.util.concurrent.ThreadPoolExecutor">
<constructor-arg index="0" value="8"/>
<constructor-arg index="1" value="16"/>
<constructor-arg index="2" value="0"/>
<constructor-arg index="3" value="MILLISECONDS"/>
<constructor-arg index="4"><bean class="java.util.concurrent.LinkedBlockingQueue"/></constructor-arg>
</bean>Bean を使用した分割処理の実行
Splitter は 任意 の式を使用して分割処理ができるので、method() 式を呼び出すことで、Bean を使用して分割処理を実行できます。Bean は、java.util.Collection、java.util.Iterator、または配列などの反復可能な値を返す必要があります。
以下のルートは、mySplitterBean Bean インスタンスのメソッドを呼び出す method() 式を定義しています。
from("direct:body")
// here we use a POJO bean mySplitterBean to do the split of the payload
.split()
.method("mySplitterBean", "splitBody")
.to("mock:result");
from("direct:message")
// here we use a POJO bean mySplitterBean to do the split of the message
// with a certain header value
.split()
.method("mySplitterBean", "splitMessage")
.to("mock:result");
mySplitterBean は MySplitterBean クラスのインスタンスで、以下のように定義されます。
public class MySplitterBean {
/**
* The split body method returns something that is iteratable such as a java.util.List.
*
* @param body the payload of the incoming message
* @return a list containing each part split
*/
public List<String> splitBody(String body) {
// since this is based on an unit test you can of couse
// use different logic for splitting as {router} have out
// of the box support for splitting a String based on comma
// but this is for show and tell, since this is java code
// you have the full power how you like to split your messages
List<String> answer = new ArrayList<String>();
String[] parts = body.split(",");
for (String part : parts) {
answer.add(part);
}
return answer;
}
/**
* The split message method returns something that is iteratable such as a java.util.List.
*
* @param header the header of the incoming message with the name user
* @param body the payload of the incoming message
* @return a list containing each part split
*/
public List<Message> splitMessage(@Header(value = "user") String header, @Body String body) {
// we can leverage the Parameter Binding Annotations
// http://camel.apache.org/parameter-binding-annotations.html
// to access the message header and body at same time,
// then create the message that we want, splitter will
// take care rest of them.
// *NOTE* this feature requires {router} version >= 1.6.1
List<Message> answer = new ArrayList<Message>();
String[] parts = header.split(",");
for (String part : parts) {
DefaultMessage message = new DefaultMessage();
message.setHeader("user", part);
message.setBody(body);
answer.add(message);
}
return answer;
}
}
Splitter EIP で BeanIOSplitter オブジェクトを使用して、ストリームモードによりコンテンツ全体をメモリーに読み込まないようにしながら、大きなペイロードを分割することができます。以下の例は、クラスパスから読み込まれるマッピングファイルを使用して、BeanIOSplitter オブジェクトを設定する方法を示しています。
BeanIOSplitter クラスは Camel 2.18 で新たに追加されました。Camel 2.17 では利用できません。
BeanIOSplitter splitter = new BeanIOSplitter();
splitter.setMapping("org/apache/camel/dataformat/beanio/mappings.xml");
splitter.setStreamName("employeeFile");
// Following is a route that uses the beanio data format to format CSV data
// in Java objects:
from("direct:unmarshal")
// Here the message body is split to obtain a message for each row:
.split(splitter).streaming()
.to("log:line")
.to("mock:beanio-unmarshal");以下の例は、エラーハンドラーを追加しています:
BeanIOSplitter splitter = new BeanIOSplitter();
splitter.setMapping("org/apache/camel/dataformat/beanio/mappings.xml");
splitter.setStreamName("employeeFile");
splitter.setBeanReaderErrorHandlerType(MyErrorHandler.class);
from("direct:unmarshal")
.split(splitter).streaming()
.to("log:line")
.to("mock:beanio-unmarshal");エクスチェンジプロパティー
以下のプロパティーは、分割されたエクスチェンジごとに設定されます。
| ヘッダー | 型 | description |
|---|---|---|
|
|
| Apache Camel 2.0: 各エクスチェンジが分割されるたびに増加するスプリットカウンター。カウンターは 0 から始まります。 |
|
|
| Apache Camel 2.0: 分割されたエクスチェンジの合計数。このヘッダーは、ストリームベースの分割には適用されません。 |
|
|
| Apache Camel 2.4: このエクスチェンジが最後であるかどうか。 |
Splitter/Aggregator パターン
個々のコンポーネントの処理が完了した後、分割されたメッセージを単一のエクスチェンジに集約する一般的なパターンです。このパターンをサポートするために、split() DSL コマンドでは、第 2 引数として AggregationStrategy オブジェクトを指定することができます。
Java DSL の例
以下の例は、カスタム集約ストラテジーを使用して、すべての分割されたメッセージが処理された後に、メッセージを再結合する方法を示しています。
from("direct:start")
.split(body().tokenize("@"), new MyOrderStrategy())
// each split message is then send to this bean where we can process it
.to("bean:MyOrderService?method=handleOrder")
// this is important to end the splitter route as we do not want to do more routing
// on each split message
.end()
// after we have split and handled each message we want to send a single combined
// response back to the original caller, so we let this bean build it for us
// this bean will receive the result of the aggregate strategy: MyOrderStrategy
.to("bean:MyOrderService?method=buildCombinedResponse")AggregationStrategy の実装
上記のルートで使用されるカスタム集約ストラテジー MyOrderStrategy は、以下のように実装されています。
/**
* This is our own order aggregation strategy where we can control
* how each split message should be combined. As we do not want to
* lose any message, we copy from the new to the old to preserve the
* order lines as long we process them
*/
public static class MyOrderStrategy implements AggregationStrategy {
public Exchange aggregate(Exchange oldExchange, Exchange newExchange) {
// put order together in old exchange by adding the order from new exchange
if (oldExchange == null) {
// the first time we aggregate we only have the new exchange,
// so we just return it
return newExchange;
}
String orders = oldExchange.getIn().getBody(String.class);
String newLine = newExchange.getIn().getBody(String.class);
LOG.debug("Aggregate old orders: " + orders);
LOG.debug("Aggregate new order: " + newLine);
// put orders together separating by semi colon
orders = orders + ";" + newLine;
// put combined order back on old to preserve it
oldExchange.getIn().setBody(orders);
// return old as this is the one that has all the orders gathered until now
return oldExchange;
}
}ストリームベースの処理
並列処理を有効にすると、後ろの分割されたメッセージが、前の分割されたメッセージよりも先に、集約の準備が整うことが理論的に起こりえます。つまり、分割された個々のメッセージは、異る順序で Aggregator へ到着する可能性があります。デフォルトでは、Splitter 実装は分割されたメッセージを Aggregator へ渡す前に元の順序に再配置するため、これが発生しません。
分割されたメッセージの処理が完了次第集約する場合は、以下のようにストリーミングオプションを有効にできます (メッセージの順序が乱れる可能性があります)。
from("direct:streaming")
.split(body().tokenize(","), new MyOrderStrategy())
.parallelProcessing()
.streaming()
.to("activemq:my.parts")
.end()
.to("activemq:all.parts");以下に示すように、ストリーミングで使用するカスタムイテレーターを指定することもできます。
// Java
import static org.apache.camel.builder.ExpressionBuilder.beanExpression;
...
from("direct:streaming")
.split(beanExpression(new MyCustomIteratorFactory(), "iterator"))
.streaming().to("activemq:my.parts")ストリーミングモードを XPath と併用することはできません。XPath は、メモリー内に完全な DOM XML ドキュメントを必要とします。
XML を使用したストリームベースの処理
受信メッセージが非常に大きな XML ファイルである場合、ストリーミングモードで tokenizeXML サブコマンドを使用して最も効率的にメッセージを処理することができます。
たとえば、order 要素のシーケンスを含む大きな XML ファイルの場合、以下のようなルートを使用してファイルを order 要素に分割することができます。
from("file:inbox")
.split().tokenizeXML("order").streaming()
.to("activemq:queue:order");以下のようなルートを定義することで、XML でも同じことができます。
<route>
<from uri="file:inbox"/>
<split streaming="true">
<tokenize token="order" xml="true"/>
<to uri="activemq:queue:order"/>
</split>
</route>トークン要素のエンクロージング (ancestor) 要素で定義される namespace へのアクセスが必要になる場合がよくあります。namespace の定義を ancestor 要素のいずれかから token 要素にコピーするには、namespace 定義を継承する要素を指定する必要があります。
Java DSL で、ancestor 要素を tokenizeXML の第 2 引数として指定します。たとえば、enclosing orders 要素から namespace 定義を継承するには、以下のようにします。
from("file:inbox")
.split().tokenizeXML("order", "orders").streaming()
.to("activemq:queue:order");
XML DSL では、inheritNamespaceTagName 属性を使用して ancestor 要素を指定します。以下に例を示します。
<route>
<from uri="file:inbox"/>
<split streaming="true">
<tokenize token="order"
xml="true"
inheritNamespaceTagName="orders"/>
<to uri="activemq:queue:order"/>
</split>
</route>オプション
split DSL コマンドは以下のオプションをサポートします。
| 名前 | デフォルト値 | 説明 |
|
| AggregationStrategy を参照し、分割されたメッセージのリプライを集約して、「Splitter」 からの単一となる送信メッセージを生成します。デフォルトで使用されているものには、What does the splitter return というタイトルの項を参照してください。 | |
|
|
POJO を | |
|
|
|
POJO を |
|
|
| 有効にすると、分割されたメッセージの処理が並列で行われます。呼び出し元スレッドは、すべての分割されたメッセージが完全に処理されるまで待機してから続行することに注意してください。 |
|
|
|
有効にすると、 |
|
| 並列処理に使用するカスタムスレッドプールを参照します。このオプションを設定すると、並列処理は自動的に適用されるため、並列処理用オプションも有効にする必要はありません。 | |
|
|
| Camel 2.2: 例外発生時、すぐに継続処理を停止するかどうか。無効にすると、Camel は分割されたメッセージの 1 つが失敗しても、分割処理を継続します。AggregationStrategy クラス内で、例外処理を完全に制御することができます。 |
|
|
| 有効にすると、Camel はストリーミング方式で input メッセージを分割します。これにより、メモリーのオーバーヘッドが軽減されます。たとえば、大きなメッセージを分割する場合には、streaming オプションを有効にすることが推奨されます。streaming オプションが有効になっていると、分割されたメッセージのリプライは、順不同で集約されます (例: 分割後の処理が終了したメッセージ順)。無効な場合、Camel は分割された順序と同じ順序で、分割されたメッセージを集約します。 |
|
|
Camel 2.5: 合計タイムアウト値をミリ秒単位で設定します。「受信者リスト」 が指定された時間内に分割してすべてのリプライを処理できない場合、タイムアウト発生して 「Splitter」 から抜け出し続行します。AggregationStrategy を提供した場合、 | |
|
| camel 2.8: カスタムプロセッサーを参照することで、エクスチェンジの分割されたメッセージが処理される前に準備をすることができます。これにより、必要に応じてメッセージのペイロードをディープクローンするなど、カスタムロジックを実行できます。 | |
|
|
| Camel 2.8: Unit of Work を共有すべきかどうか。詳細につていは以下をご覧ください |