17.2. 통신사 핵심 CNF 클러스터 업그레이드
17.2.1. 통신사 핵심 CNF 클러스터 업데이트
OpenShift Container Platform은 모든 릴리스와 EUS 릴리스 간 업데이트 경로에 대해 장기 지원 또는 확장 업데이트 지원(EUS)을 제공합니다. 한 EUS 버전에서 다음 EUS 버전으로 업데이트할 수 있습니다. y-stream과 z-stream 버전 간에 업데이트하는 것도 가능합니다.
17.2.1.1. 통신사 핵심 CNF 클러스터에 대한 클러스터 업데이트
클러스터를 업데이트하는 것은 버그와 잠재적인 보안 취약점이 패치되었는지 확인하는 중요한 작업입니다. 종종 클라우드 기반 네트워크 기능(CNF)을 업데이트하려면 클러스터 버전을 업데이트할 때 제공되는 플랫폼의 추가 기능이 필요합니다. 또한 클러스터 플랫폼 버전이 지원되는지 확인하려면 클러스터를 주기적으로 업데이트해야 합니다.
EUS 릴리스를 최신 상태로 유지하고 중요한 z-stream 릴리스로만 업그레이드하면 업데이트를 적용하는 데 필요한 노력을 최소화할 수 있습니다.
클러스터의 업데이트 경로는 클러스터의 크기와 토폴로지에 따라 달라질 수 있습니다. 여기에 설명된 업데이트 절차는 3노드 클러스터부터 통신사 규모 팀에서 인증한 가장 큰 규모의 클러스터까지 대부분의 클러스터에 유효합니다. 여기에는 혼합 작업 부하 클러스터에 대한 몇 가지 시나리오가 포함됩니다.
다음 업데이트 시나리오는 다음과 같습니다.
- 제어 평면만 업데이트
- Y-스트림 업데이트
- Z-스트림 업데이트
제어 평면 전용 업데이트는 이전에는 EUS-EUS 업데이트로 알려져 있었습니다. Control Plane Only 업데이트는 OpenShift Container Platform의 짝수 번째 마이너 버전 간에만 실행 가능합니다.
17.2.2. 업데이트 버전 간 클러스터 API 버전 확인
구성 요소가 업데이트됨에 따라 API는 시간이 지남에 따라 변경됩니다. 업데이트된 클러스터 버전과 클라우드 기반 네트워크 기능(CNF) API가 호환되는지 확인하는 것이 중요합니다.
17.2.2.1. OpenShift 컨테이너 플랫폼 API 호환성
새로운 y-stream 업데이트의 일부로 어떤 z-stream 릴리스로 업데이트할지 고려할 때, 이전 z-stream 버전에 있는 모든 패치가 새로운 z-stream 버전에 있는지 확인해야 합니다. 업데이트한 버전에 필요한 패치가 모두 포함되어 있지 않으면 Kubernetes의 기본 호환성이 손상됩니다.
예를 들어, 클러스터 버전이 4.15.32인 경우 4.15.32에 적용된 모든 패치가 포함된 4.16 z-stream 릴리스로 업데이트해야 합니다.
17.2.2.1.1. Kubernetes 버전 왜곡에 관하여
각 클러스터 Operator는 특정 API 버전을 지원합니다. Kubernetes API는 시간이 지남에 따라 발전하며, 최신 버전은 더 이상 사용되지 않거나 기존 API를 변경할 수 있습니다. 이것을 "버전 왜곡"이라고 합니다. 새로운 릴리스가 나올 때마다 API 변경 사항을 검토해야 합니다. API는 여러 Operator 릴리스 간에 호환될 수 있지만 호환성은 보장되지 않습니다. 버전 불균형으로 인해 발생하는 문제를 완화하려면 명확하게 정의된 업데이트 전략을 따르세요.
17.2.2.2. 클러스터 버전 업데이트 경로 결정
Red Hat OpenShift Container Platform Update Graph 도구를 사용하여 업데이트하려는 z-stream 릴리스에 대한 경로가 유효한지 확인합니다. 업데이트 경로가 통신사 구현에 유효한지 확인하려면 Red Hat 기술 계정 관리자에게 업데이트를 확인하세요.
업데이트하는 <4.y+1.z> 또는 <4.y+2.z> 버전은 업데이트하려는 <4.yz> 릴리스와 동일한 패치 레벨을 가져야 합니다.
OpenShift 업데이트 프로세스에서는 특정 <4.yz> 릴리스에 수정 사항이 있는 경우 해당 수정 사항이 업데이트 대상 <4.y+1.z> 릴리스에도 있어야 한다고 규정하고 있습니다.
그림 17.1. 버그 수정 백포팅 및 업데이트 그래프
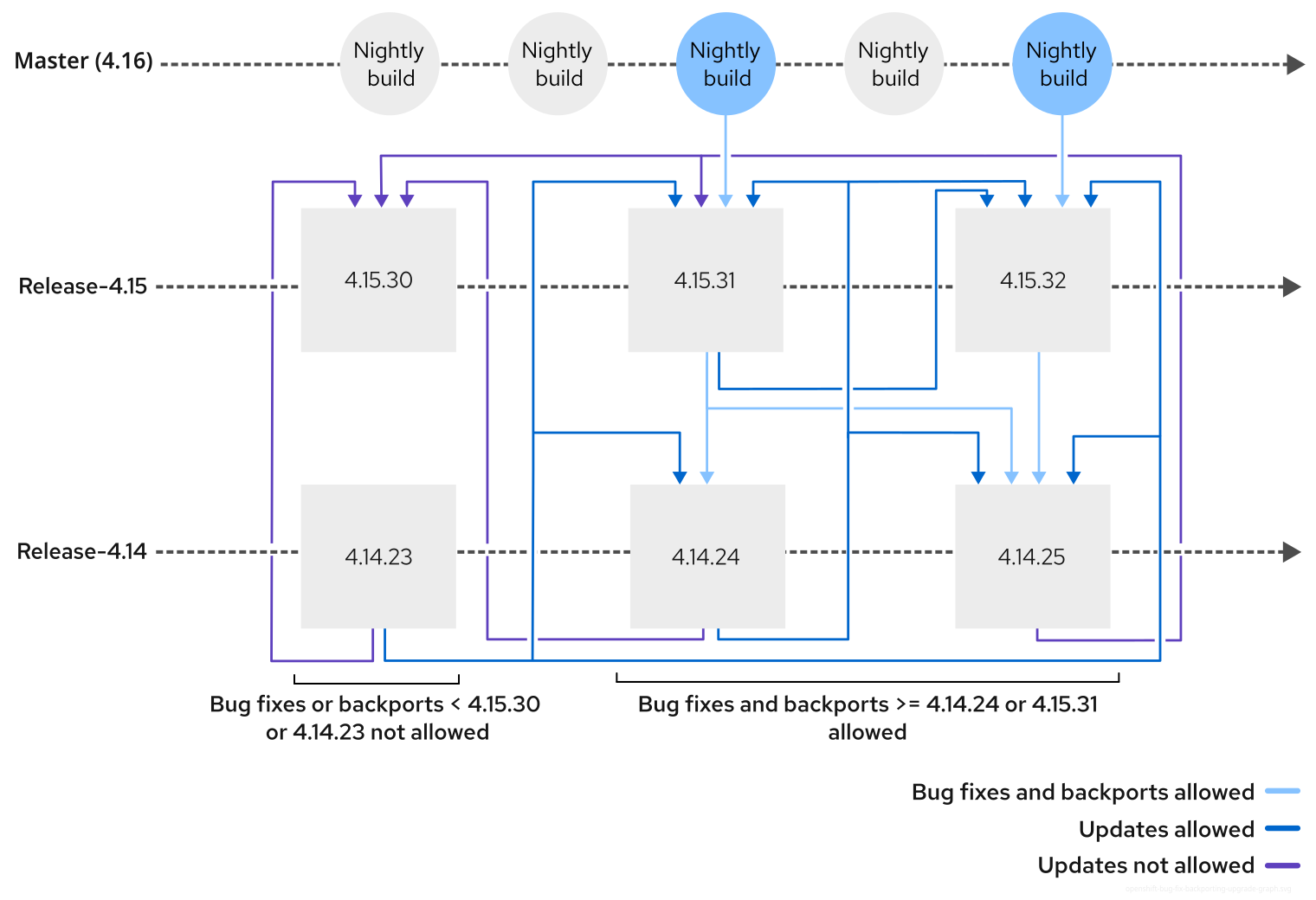
OpenShift 개발에는 회귀를 방지하는 엄격한 백포트 정책이 있습니다. 예를 들어, 버그는 4.15.z에서 수정되기 전에 4.16.z에서 수정되어야 합니다. 즉, 업데이트 그래프는 하위 버전이 더 높더라도(예: 4.15.24에서 4.16.2로 업데이트) 시간순으로 더 오래된 릴리스로의 업데이트를 허용하지 않습니다.
17.2.2.3. 대상 릴리스 선택
Red Hat OpenShift Container Platform 업데이트 그래프 또는 cincinnati-graph-data 저장소를 사용하여 업데이트할 릴리스를 확인하세요.
17.2.2.3.1. 사용 가능한 z-stream 업데이트 확인
새로운 z-stream 릴리스로 업데이트하기 전에 어떤 버전을 사용할 수 있는지 알아야 합니다.
z-stream 업데이트를 수행할 때 채널을 변경할 필요는 없습니다.
프로세스
어떤 z-stream 릴리스가 사용 가능한지 확인하세요. 다음 명령을 실행합니다.
$ oc adm upgrade출력 예
Cluster version is 4.14.34 Upstream is unset, so the cluster will use an appropriate default. Channel: stable-4.14 (available channels: candidate-4.14, candidate-4.15, eus-4.14, eus-4.16, fast-4.14, fast-4.15, stable-4.14, stable-4.15) Recommended updates: VERSION IMAGE 4.14.37 quay.io/openshift-release-dev/ocp-release@sha256:14e6ba3975e6c73b659fa55af25084b20ab38a543772ca70e184b903db73092b 4.14.36 quay.io/openshift-release-dev/ocp-release@sha256:4bc4925e8028158e3f313aa83e59e181c94d88b4aa82a3b00202d6f354e8dfed 4.14.35 quay.io/openshift-release-dev/ocp-release@sha256:883088e3e6efa7443b0ac28cd7682c2fdbda889b576edad626769bf956ac0858
17.2.2.3.2. 제어 평면 전용 업데이트에 대한 채널 변경
Control Plane Only 업데이트를 위해서는 채널을 필요한 버전으로 변경해야 합니다.
z-stream 업데이트를 수행할 때 채널을 변경할 필요는 없습니다.
프로세스
현재 구성된 업데이트 채널을 확인하세요.
$ oc get clusterversion -o=jsonpath='{.items[*].spec}' | jq출력 예
{ "channel": "stable-4.14", "clusterID": "01eb9a57-2bfb-4f50-9d37-dc04bd5bac75" }업데이트하려는 새 채널을 가리키도록 채널을 변경하세요.
$ oc adm upgrade channel eus-4.16업데이트된 채널을 확인하세요.
$ oc get clusterversion -o=jsonpath='{.items[*].spec}' | jq출력 예
{ "channel": "eus-4.16", "clusterID": "01eb9a57-2bfb-4f50-9d37-dc04bd5bac75" }
17.2.2.3.2.1. 조기 EUS 업데이트를 위한 채널 변경
OpenShift Container Platform의 새로운 릴리스에 대한 업데이트 경로는 사소한 릴리스의 최초 GA 이후 45~90일이 지나야 EUS 채널이나 안정적인 채널에서 사용할 수 있습니다.
새로운 릴리스에 대한 업데이트 테스트를 시작하려면 빠른 채널을 사용할 수 있습니다.
프로세스
채널을
fast-<y+1>로 변경합니다. 예를 들어 다음 명령을 실행합니다.$ oc adm upgrade channel fast-4.16새로운 채널에서 업데이트 경로를 확인하세요. 다음 명령을 실행합니다.
$ oc adm upgradeCluster version is 4.15.33 Upgradeable=False Reason: AdminAckRequired Message: Kubernetes 1.28 and therefore OpenShift 4.16 remove several APIs which require admin consideration. Please see the knowledge article https://access.redhat.com/articles/6958394 for details and instructions. Upstream is unset, so the cluster will use an appropriate default. Channel: fast-4.16 (available channels: candidate-4.15, candidate-4.16, eus-4.15, eus-4.16, fast-4.15, fast-4.16, stable-4.15, stable-4.16) Recommended updates: VERSION IMAGE 4.16.14 quay.io/openshift-release-dev/ocp-release@sha256:6618dd3c0f5 4.16.13 quay.io/openshift-release-dev/ocp-release@sha256:7a72abc3 4.16.12 quay.io/openshift-release-dev/ocp-release@sha256:1c8359fc2 4.16.11 quay.io/openshift-release-dev/ocp-release@sha256:bc9006febfe 4.16.10 quay.io/openshift-release-dev/ocp-release@sha256:dece7b61b1 4.15.36 quay.io/openshift-release-dev/ocp-release@sha256:c31a56d19 4.15.35 quay.io/openshift-release-dev/ocp-release@sha256:f21253 4.15.34 quay.io/openshift-release-dev/ocp-release@sha256:2dd69c5버전 4.16으로 업데이트하려면 업데이트 절차를 따르세요(버전 4.15에서 <y+1>)
참고빠른 채널을 사용하는 경우에도 EUS 릴리스 사이에 작업자 노드를 일시 중지할 수 있습니다.
-
필요한 <y+1> 릴리스에 도달하면 채널을 다시 변경하고 이번에는
fast-<y+2>로 변경합니다. - 필요한 <y+2> 릴리스를 받으려면 EUS 업데이트 절차를 따르세요.
17.2.2.3.3. y-스트림 업데이트를 위한 채널 변경
y-stream 업데이트에서는 채널을 다음 릴리스 채널로 변경합니다.
프로덕션 클러스터에는 안정적인 릴리스 채널이나 EUS 릴리스 채널을 사용하세요.
프로세스
업데이트 채널 변경:
$ oc adm upgrade channel stable-4.15새로운 채널에서 업데이트 경로를 확인하세요. 다음 명령을 실행합니다.
$ oc adm upgrade출력 예
Cluster version is 4.14.34 Upgradeable=False Reason: AdminAckRequired Message: Kubernetes 1.27 and therefore OpenShift 4.15 remove several APIs which require admin consideration. Please see the knowledge article https://access.redhat.com/articles/6958394 for details and instructions. Upstream is unset, so the cluster will use an appropriate default. Channel: stable-4.15 (available channels: candidate-4.14, candidate-4.15, eus-4.14, eus-4.15, fast-4.14, fast-4.15, stable-4.14, stable-4.15) Recommended updates: VERSION IMAGE 4.15.33 quay.io/openshift-release-dev/ocp-release@sha256:7142dd4b560 4.15.32 quay.io/openshift-release-dev/ocp-release@sha256:cda8ea5b13dc9 4.15.31 quay.io/openshift-release-dev/ocp-release@sha256:07cf61e67d3eeee 4.15.30 quay.io/openshift-release-dev/ocp-release@sha256:6618dd3c0f5 4.15.29 quay.io/openshift-release-dev/ocp-release@sha256:7a72abc3 4.15.28 quay.io/openshift-release-dev/ocp-release@sha256:1c8359fc2 4.15.27 quay.io/openshift-release-dev/ocp-release@sha256:bc9006febfe 4.15.26 quay.io/openshift-release-dev/ocp-release@sha256:dece7b61b1 4.14.38 quay.io/openshift-release-dev/ocp-release@sha256:c93914c62d7 4.14.37 quay.io/openshift-release-dev/ocp-release@sha256:c31a56d19 4.14.36 quay.io/openshift-release-dev/ocp-release@sha256:f21253 4.14.35 quay.io/openshift-release-dev/ocp-release@sha256:2dd69c5
17.2.3. 업데이트를 위한 통신사 핵심 클러스터 플랫폼 준비
일반적으로 통신사 클러스터는 베어메탈 하드웨어에서 실행됩니다. 종종 중요한 보안 문제를 해결하거나, 새로운 기능을 추가하거나, OpenShift Container Platform의 새로운 릴리스와의 호환성을 유지하기 위해 펌웨어를 업데이트해야 합니다.
17.2.3.1. 호스트 펌웨어가 업데이트와 호환되는지 확인
클러스터에서 실행하는 펌웨어 버전에 대한 책임은 사용자에게 있습니다. 호스트 펌웨어 업데이트는 OpenShift Container Platform 업데이트 프로세스의 일부가 아닙니다. OpenShift Container Platform 버전과 함께 펌웨어를 업데이트하는 것은 권장되지 않습니다.
하드웨어 공급업체에서는 현재 사용 중인 특정 하드웨어에 대해 최신 인증 펌웨어 버전을 적용하는 것이 가장 좋다고 조언합니다. 통신용 사례의 경우 프로덕션 환경에서 적용하기 전에 항상 테스트 환경에서 펌웨어 업데이트를 확인합니다. 통신 CNF 워크로드의 높은 처리량은 최적의 호스트 펌웨어의 영향을 받지 않을 수 있습니다.
현재 버전의 OpenShift Container Platform에서 예상대로 작동하는지 확인하려면 새로운 펌웨어 업데이트를 철저히 테스트해야 합니다. 대상 OpenShift Container Platform 업데이트 버전을 사용하여 최신 펌웨어 버전을 테스트하는 것이 좋습니다.
17.2.3.2. 계층형 제품이 업데이트와 호환되는지 확인
업데이트를 시작하기 전에 모든 계층화된 제품이 업데이트하려는 OpenShift Container Platform 버전에서 실행되는지 확인하세요. 여기에는 일반적으로 모든 운영자가 포함됩니다.
프로세스
클러스터에 현재 설치된 운영자를 확인합니다. 예를 들어 다음 명령을 실행합니다.
$ oc get csv -A출력 예
NAMESPACE NAME DISPLAY VERSION REPLACES PHASE gitlab-operator-kubernetes.v0.17.2 GitLab 0.17.2 gitlab-operator-kubernetes.v0.17.1 Succeeded openshift-operator-lifecycle-manager packageserver Package Server 0.19.0 SucceededOLM과 함께 설치한 운영자가 업데이트 버전과 호환되는지 확인하세요.
Operator Lifecycle Manager(OLM)와 함께 설치된 운영자는 표준 클러스터 운영자 세트에 포함되지 않습니다.
운영자 업데이트 정보 검사기를 사용하여 y-스트림을 업데이트할 때마다 운영자를 업데이트해야 하는지, 아니면 다음 EUS 릴리스로 완전히 업데이트할 때까지 기다려도 되는지 확인하세요.
작은 정보또한 Operator Update Information Checker를 사용하여 특정 Operator 릴리스와 호환되는 OpenShift Container Platform 버전을 확인할 수 있습니다.
OLM 외부에 설치한 운영자가 업데이트 버전과 호환되는지 확인하세요.
Red Hat에서 직접 지원하지 않는 모든 OLM 설치 Operator의 경우, Operator 공급업체에 문의하여 릴리스 호환성을 확인하세요.
- 일부 운영자는 OpenShift Container Platform의 여러 릴리스와 호환됩니다. 클러스터 업데이트를 완료하기 전까지는 운영자를 업데이트하지 않아도 될 수도 있습니다. 자세한 내용은 "워커 노드 업데이트"를 참조하세요.
- 첫 번째 y-stream 컨트롤 플레인 업데이트를 수행한 후 Operator를 업데이트하는 방법에 대한 정보는 "모든 OLM Operator 업그레이드"를 참조하십시오.
17.2.3.3. 업데이트 전에 노드에 MachineConfigPool 레이블 적용
대략 8~10개의 노드로 구성된 그룹으로 노드를 그룹화하기 위해 MachineConfigPool ( mcp ) 노드 레이블을 준비합니다. mcp 그룹을 사용하면 클러스터의 나머지 부분과 별도로 노드 그룹을 재부팅할 수 있습니다.
업데이트 프로세스 중에 노드 세트를 일시 중지하거나 일시 중지를 해제하려면 mcp 노드 레이블을 사용하면 원하는 시간에 업데이트를 수행하고 재부팅할 수 있습니다.
17.2.3.3.1. 클러스터 업데이트 단계적 진행
업데이트 중에 문제가 발생하는 경우가 있습니다. 종종 문제는 하드웨어 오류나 노드 재설정 필요성과 관련이 있습니다. MCP 노드 레이블을 사용하면 중요한 순간에 업데이트를 일시 중지하고, 진행하면서 일시 중지된 노드와 일시 중지 해제된 노드를 추적하여 단계적으로 노드를 업데이트할 수 있습니다. 문제가 발생하면 일시 중지되지 않은 상태의 노드를 사용하여 모든 애플리케이션 포드가 계속 실행될 수 있도록 충분한 노드가 실행되고 있는지 확인합니다.
17.2.3.3.2. 작업자 노드를 MachineConfigPool 그룹으로 나누기
워커 노드를 MCP 그룹으로 나누는 방법은 클러스터에 있는 노드 수나 노드 역할에 할당한 노드 수에 따라 달라질 수 있습니다. 기본적으로 클러스터의 두 가지 역할은 제어 평면과 작업자입니다.
통신사 워크로드를 실행하는 클러스터에서는 CNF 제어 평면과 CNF 데이터 평면 역할 간에 작업자 노드를 추가로 분할할 수 있습니다. 작업자 노드를 두 그룹으로 분할하는 mcp 역할 레이블을 추가합니다.
대규모 클러스터는 CNF 제어 평면 역할에 최대 100개의 작업자 노드를 가질 수 있습니다. 클러스터에 노드가 몇 개 있든 각 MachineConfigPool 그룹의 노드 수는 약 10개로 유지하세요. 이를 통해 한 번에 얼마나 많은 노드를 제거할지 제어할 수 있습니다. 여러 MachineConfigPool 그룹을 사용하면 여러 그룹의 일시 중지를 동시에 해제하여 업데이트를 가속화하거나 2개 이상의 유지 관리 창에 걸쳐 업데이트를 분할할 수 있습니다.
- 15개의 작업자 노드가 있는 클러스터 예
15개의 작업자 노드가 있는 클러스터를 생각해 보세요.
- 10개의 워커 노드는 CNF 제어 평면 노드입니다.
- 5개의 워커 노드는 CNF 데이터 플레인 노드입니다.
CNF 제어 평면과 데이터 평면 작업자 노드 역할을 각각 최소 2개의
mcp그룹으로 분할합니다. 역할당 2개의MCP그룹이 있다는 것은 업데이트의 영향을 받지 않는 노드 세트를 하나만 가질 수 있다는 것을 의미합니다.- 6개의 작업자 노드가 있는 클러스터 예
6개의 작업자 노드가 있는 클러스터를 생각해 보세요.
-
워커 노드를 각각 2개의 노드로 구성된 3개의
MCP그룹으로 나눕니다.
mcp그룹 중 하나를 업그레이드합니다. 다른 4개 노드에서 업데이트를 완료하기 전에 CNF 호환성을 검증할 수 있도록 업데이트된 노드를 하루 동안 기다리세요.-
워커 노드를 각각 2개의 노드로 구성된 3개의
MCP 그룹의 일시 중지를 해제하는 프로세스와 속도는 CNF 애플리케이션과 구성에 따라 결정됩니다.
CNF 포드가 클러스터의 노드 전반에 걸쳐 스케줄링을 처리할 수 있다면, 여러 MCP 그룹의 일시 중지를 한 번에 해제하고 MCP 사용자 정의 리소스(CR)의 MaxUnavailable 을 최대 50%까지 설정할 수 있습니다. 이를 통해 mcp 그룹의 노드 중 최대 절반을 다시 시작하고 업데이트할 수 있습니다.
17.2.3.3.3. 구성된 클러스터 MachineConfigPool 역할 검토
클러스터에서 현재 구성된 MachineConfigPool 역할을 검토합니다.
프로세스
클러스터에 현재 구성된
mcp그룹을 가져옵니다.$ oc get mcp출력 예
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE master rendered-master-bere83 True False False 3 3 3 0 25d worker rendered-worker-245c4f True False False 2 2 2 0 25dmcp역할 목록을 클러스터의 노드 목록과 비교하세요.$ oc get nodes출력 예
NAME STATUS ROLES AGE VERSION ctrl-plane-0 Ready control-plane,master 39d v1.27.15+6147456 ctrl-plane-1 Ready control-plane,master 39d v1.27.15+6147456 ctrl-plane-2 Ready control-plane,master 39d v1.27.15+6147456 worker-0 Ready worker 39d v1.27.15+6147456 worker-1 Ready worker 39d v1.27.15+6147456참고mcp그룹 변경을 적용하면 노드 역할이 업데이트됩니다.워커 노드를
MCP그룹으로 분리하는 방법을 결정합니다.
17.2.3.3.4. 클러스터에 대한 MachineConfigPool 그룹 생성
mcp 그룹을 만드는 것은 2단계 프로세스입니다.
-
클러스터의 노드에
mcp레이블을 추가합니다. -
레이블을 기준으로 노드를 구성하는 클러스터에
mcpCR을 적용합니다.
프로세스
노드에 레이블을 지정하여
mcp그룹에 넣을 수 있도록 합니다. 다음 명령을 실행합니다.$ oc label node worker-0 node-role.kubernetes.io/mcp-1=$ oc label node worker-1 node-role.kubernetes.io/mcp-2=mcp-1과mcp-2라벨이 노드에 적용됩니다. 예를 들면 다음과 같습니다.출력 예
NAME STATUS ROLES AGE VERSION ctrl-plane-0 Ready control-plane,master 39d v1.27.15+6147456 ctrl-plane-1 Ready control-plane,master 39d v1.27.15+6147456 ctrl-plane-2 Ready control-plane,master 39d v1.27.15+6147456 worker-0 Ready mcp-1,worker 39d v1.27.15+6147456 worker-1 Ready mcp-2,worker 39d v1.27.15+6147456클러스터에서 레이블을
mcpCR로 적용하는 YAML 사용자 정의 리소스(CR)를 만듭니다. 다음 YAML을mcps.yaml파일에 저장합니다.--- apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfigPool metadata: name: mcp-2 spec: machineConfigSelector: matchExpressions: - { key: machineconfiguration.openshift.io/role, operator: In, values: [worker,mcp-2] } nodeSelector: matchLabels: node-role.kubernetes.io/mcp-2: "" --- apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfigPool metadata: name: mcp-1 spec: machineConfigSelector: matchExpressions: - { key: machineconfiguration.openshift.io/role, operator: In, values: [worker,mcp-1] } nodeSelector: matchLabels: node-role.kubernetes.io/mcp-1: ""MachineConfigPool리소스를 만듭니다.$ oc apply -f mcps.yaml출력 예
machineconfigpool.machineconfiguration.openshift.io/mcp-2 created
검증
클러스터에 적용되는 MachineConfigPool 리소스를 모니터링합니다. mcp 리소스를 적용하면 노드가 새 머신 구성 풀에 추가됩니다. 이 작업에는 몇 분 정도 걸립니다.
노드는 mcp 그룹에 추가되는 동안 재부팅되지 않습니다. 원래의 작업자 및 마스터 MCP 그룹은 변경되지 않습니다.
새로운
mcp리소스의 상태를 확인하세요.$ oc get mcp출력 예
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE master rendered-master-be3e83 True False False 3 3 3 0 25d mcp-1 rendered-mcp-1-2f4c4f False True True 1 0 0 0 10s mcp-2 rendered-mcp-2-2r4s1f False True True 1 0 0 0 10s worker rendered-worker-23fc4f False True True 0 0 0 2 25d결국, 리소스가 완전히 적용됩니다.
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE master rendered-master-be3e83 True False False 3 3 3 0 25d mcp-1 rendered-mcp-1-2f4c4f True False False 1 1 1 0 7m33s mcp-2 rendered-mcp-2-2r4s1f True False False 1 1 1 0 51s worker rendered-worker-23fc4f True False False 0 0 0 0 25d
17.2.3.4. 통신사 배포 환경 고려 사항
통신 환경에서 대부분의 클러스터는 연결이 끊긴 네트워크에 있습니다. 이러한 환경에서 클러스터를 업데이트하려면 오프라인 이미지 저장소를 업데이트해야 합니다.
17.2.3.5. 클러스터 플랫폼 업데이트를 위한 준비
클러스터를 업데이트하기 전에 몇 가지 기본 검사와 검증을 수행하여 클러스터가 업데이트할 준비가 되었는지 확인하세요.
프로세스
다음 명령을 실행하여 클러스터에 실패했거나 진행 중인 포드가 없는지 확인하세요.
$ oc get pods -A | grep -E -vi 'complete|running'참고보류 상태의 포드가 있는 경우 이 명령을 두 번 이상 실행해야 할 수도 있습니다.
클러스터의 모든 노드를 사용할 수 있는지 확인합니다.
$ oc get nodes출력 예
NAME STATUS ROLES AGE VERSION ctrl-plane-0 Ready control-plane,master 32d v1.27.15+6147456 ctrl-plane-1 Ready control-plane,master 32d v1.27.15+6147456 ctrl-plane-2 Ready control-plane,master 32d v1.27.15+6147456 worker-0 Ready mcp-1,worker 32d v1.27.15+6147456 worker-1 Ready mcp-2,worker 32d v1.27.15+6147456모든 베어 메탈 노드가 프로비저닝되고 준비되었는지 확인합니다.
$ oc get bmh -n openshift-machine-api출력 예
NAME STATE CONSUMER ONLINE ERROR AGE ctrl-plane-0 unmanaged cnf-58879-master-0 true 33d ctrl-plane-1 unmanaged cnf-58879-master-1 true 33d ctrl-plane-2 unmanaged cnf-58879-master-2 true 33d worker-0 unmanaged cnf-58879-worker-0-45879 true 33d worker-1 progressing cnf-58879-worker-0-dszsh false 1d1 - 1
Worker-1노드를 프로비저닝하는 동안 오류가 발생했습니다.
검증
모든 클러스터 운영자가 준비되었는지 확인하세요.
$ oc get co출력 예
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE authentication 4.14.34 True False False 17h baremetal 4.14.34 True False False 32d ... service-ca 4.14.34 True False False 32d storage 4.14.34 True False False 32d
17.2.4. 통신사 핵심 CNF 클러스터를 업데이트하기 전에 CNF 포드 구성
업데이트 중에 클러스터가 Pod를 예약할 수 있도록 클라우드 기반 네트워크 기능(CNF)을 개발할 때 Kubernetes에 대한 Red Hat 모범 사례 의 지침을 따르세요.
항상 배포 리소스를 사용하여 그룹으로 포드를 배포합니다. 배포 리소스는 사용 가능한 모든 포드에 작업 부하를 분산시켜 단일 장애 지점이 없도록 보장합니다. 배포 리소스에서 관리하는 Pod가 삭제되면 새 Pod가 자동으로 해당 자리를 대신합니다.
17.2.4.1. CNF 워크로드가 Pod 중단 예산으로 중단 없이 실행되도록 합니다.
PodDisruptionBudget 사용자 정의 리소스(CR)에서 포드 중단 예산을 설정하여 CNF 워크로드가 중단 없이 실행될 수 있도록 배포에서 최소한의 포드 수를 구성할 수 있습니다. 이 값을 설정할 때는 주의하세요. 잘못 설정하면 업데이트가 실패할 수 있습니다.
예를 들어, 배포에 4개의 포드가 있고 포드 중단 예산을 4로 설정하면 클러스터 스케줄러는 항상 4개의 포드를 계속 실행합니다. 즉, 포드를 축소할 수 없습니다.
대신, 포드 중단 예산을 2로 설정하여 4개의 포드 중 2개가 중단으로 예약되도록 합니다. 그런 다음 해당 포드가 위치한 워커 노드를 재부팅할 수 있습니다.
포드 중단 예산을 2로 설정한다고 해서 배포가 일정 기간(예: 업데이트 중) 동안 2개의 포드에서만 실행된다는 의미는 아닙니다. 클러스터 스케줄러는 2개의 기존 Pod를 대체하기 위해 2개의 새로운 Pod를 생성합니다. 하지만 새로운 포드가 온라인에 올라오고 기존 포드가 삭제되는 사이에는 짧은 시간 간격이 있습니다.
17.2.4.2. 포드가 동일한 클러스터 노드에서 실행되지 않도록 보장
쿠버네티스에서 고가용성을 구현하려면 클러스터의 별도 노드에서 복제 프로세스를 실행해야 합니다. 이렇게 하면 한 노드를 사용할 수 없게 되더라도 애플리케이션이 계속 실행됩니다. OpenShift Container Platform에서는 배포 시 프로세스를 별도의 Pod에 자동으로 복제할 수 있습니다. 배포 내의 포드가 동일한 클러스터 노드에서 실행되지 않도록 하려면 Pod 사양에서 반친화성을 구성합니다.
업데이트 중에 Pod 반친화성을 설정하면 Pod가 클러스터의 노드에 균등하게 분산됩니다. 즉, 업데이트 중에 노드를 재부팅하는 것이 더 쉬워집니다. 예를 들어, 노드에 단일 배포로 인해 4개의 Pod가 있고 Pod 중단 예산이 한 번에 1개의 Pod만 삭제되도록 설정된 경우, 해당 노드를 재부팅하는 데 4배 더 오랜 시간이 걸립니다. Pod 반친화성을 설정하면 Pod가 클러스터 전체에 퍼져서 이런 일이 발생하지 않습니다.
17.2.4.3. 애플리케이션 활성 상태, 준비 상태 및 시작 프로브
업데이트를 예약하기 전에 활성, 준비 및 시작 프로브를 사용하여 활성 애플리케이션 컨테이너의 상태를 확인할 수 있습니다. 이러한 도구는 애플리케이션 컨테이너의 상태를 유지하는 데 의존하는 포드와 함께 사용할 때 매우 유용합니다.
- 활성 상태 점검
- 컨테이너가 실행 중인지 확인합니다. 컨테이너의 활성 프로브가 실패하면 포드는 재시작 정책에 따라 응답합니다.
- Readiness 프로브
- 컨테이너가 서비스 요청을 수락할 준비가 되었는지 확인합니다. 컨테이너에 대한 준비 상태 프로브가 실패하면 kubelet에서 사용 가능한 서비스 끝점 목록에서 Pod를 제거합니다.
- Startup 프로브
-
시작 프로브는 컨테이너 내 애플리케이션이 시작되었는지를 나타냅니다. 기타 모든 프로브는 시작 프로브가 성공할 때까지 비활성화됩니다. 시작 프로브가 성공하지 못하면 kubelet은 컨테이너를 종료하고 컨테이너는 pod
restartPolicy설정의 적용을 받습니다.
17.2.5. Telco Core CNF 클러스터를 업데이트하기 전에
클러스터 업데이트를 시작하기 전에 작업자 노드를 일시 중지하고, etcd 데이터베이스를 백업하고, 진행하기 전에 최종 클러스터 상태 확인을 수행해야 합니다.
17.2.5.1. 업데이트 전에 작업자 노드 일시 중지
업데이트를 진행하기 전에 작업자 노드를 일시 중지해야 합니다. 다음 예에서는 mcp-1 과 mcp-2라는 2개의 mcp 그룹이 있습니다. 이러한 각 MachineConfigPool 그룹에 대해 spec.paused 필드를 true 로 패치합니다.
프로세스
다음 명령을 실행하여
mcpCR에 패치를 적용하여 노드를 일시 중지하고 해당 노드에서 포드를 비우고 제거합니다.$ oc patch mcp/mcp-1 --type merge --patch '{"spec":{"paused":true}}'$ oc patch mcp/mcp-2 --type merge --patch '{"spec":{"paused":true}}'일시 중지된
mcp그룹의 상태를 가져옵니다.$ oc get mcp -o json | jq -r '["MCP","Paused"], ["---","------"], (.items[] | [(.metadata.name), (.spec.paused)]) | @tsv' | grep -v worker출력 예
MCP Paused --- ------ master false mcp-1 true mcp-2 true
기본 제어 평면과 작업자 MCP 그룹은 업데이트 중에 변경되지 않습니다.
17.2.5.2. 업데이트를 진행하기 전에 etcd 데이터베이스를 백업하세요.
업데이트를 진행하기 전에 etcd 데이터베이스를 백업해야 합니다.
17.2.5.2.1. etcd 데이터 백업
다음 단계에 따라 etcd 스냅샷을 작성하고 정적 pod의 리소스를 백업하여 etcd 데이터를 백업합니다. 이 백업을 저장하여 etcd를 복원해야하는 경우 나중에 사용할 수 있습니다.
단일 컨트롤 플레인 호스트의 백업만 저장합니다. 클러스터의 각 컨트롤 플레인 호스트에서 백업을 수행하지 마십시오.
사전 요구 사항
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다. 클러스터 전체의 프록시가 활성화되어 있는지 확인해야 합니다.
작은 정보oc get proxy cluster -o yaml의 출력을 확인하여 프록시가 사용 가능한지 여부를 확인할 수 있습니다.httpProxy,httpsProxy및noProxy필드에 값이 설정되어 있으면 프록시가 사용됩니다.
프로세스
제어 평면 노드의 루트로 디버그 세션을 시작합니다.
$ oc debug --as-root node/<node_name>디버그 셸에서 루트 디렉토리를
/host로 변경하세요.sh-4.4# chroot /host클러스터 전체 프록시가 활성화된 경우 다음 명령을 실행하여
NO_PROXY,HTTP_PROXY및HTTPS_PROXY환경 변수를 내보냅니다.$ export HTTP_PROXY=http://<your_proxy.example.com>:8080$ export HTTPS_PROXY=https://<your_proxy.example.com>:8080$ export NO_PROXY=<example.com>디버그 셸에서
cluster-backup.sh스크립트를 실행하고 백업을 저장할 위치를 전달합니다.작은 정보cluster-backup.sh스크립트는 etcd Cluster Operator의 구성 요소로 유지 관리되며etcdctl snapshot save명령 관련 래퍼입니다.sh-4.4# /usr/local/bin/cluster-backup.sh /home/core/assets/backup스크립트 출력 예
found latest kube-apiserver: /etc/kubernetes/static-pod-resources/kube-apiserver-pod-6 found latest kube-controller-manager: /etc/kubernetes/static-pod-resources/kube-controller-manager-pod-7 found latest kube-scheduler: /etc/kubernetes/static-pod-resources/kube-scheduler-pod-6 found latest etcd: /etc/kubernetes/static-pod-resources/etcd-pod-3 ede95fe6b88b87ba86a03c15e669fb4aa5bf0991c180d3c6895ce72eaade54a1 etcdctl version: 3.4.14 API version: 3.4 {"level":"info","ts":1624647639.0188997,"caller":"snapshot/v3_snapshot.go:119","msg":"created temporary db file","path":"/home/core/assets/backup/snapshot_2021-06-25_190035.db.part"} {"level":"info","ts":"2021-06-25T19:00:39.030Z","caller":"clientv3/maintenance.go:200","msg":"opened snapshot stream; downloading"} {"level":"info","ts":1624647639.0301006,"caller":"snapshot/v3_snapshot.go:127","msg":"fetching snapshot","endpoint":"https://10.0.0.5:2379"} {"level":"info","ts":"2021-06-25T19:00:40.215Z","caller":"clientv3/maintenance.go:208","msg":"completed snapshot read; closing"} {"level":"info","ts":1624647640.6032252,"caller":"snapshot/v3_snapshot.go:142","msg":"fetched snapshot","endpoint":"https://10.0.0.5:2379","size":"114 MB","took":1.584090459} {"level":"info","ts":1624647640.6047094,"caller":"snapshot/v3_snapshot.go:152","msg":"saved","path":"/home/core/assets/backup/snapshot_2021-06-25_190035.db"} Snapshot saved at /home/core/assets/backup/snapshot_2021-06-25_190035.db {"hash":3866667823,"revision":31407,"totalKey":12828,"totalSize":114446336} snapshot db and kube resources are successfully saved to /home/core/assets/backup이 예제에서는 컨트롤 플레인 호스트의
/home/core/assets/backup/디렉토리에 두 개의 파일이 생성됩니다.-
snapshot_<datetimestamp>.db:이 파일은 etcd 스냅샷입니다.cluster-backup.sh스크립트는 유효성을 확인합니다. static_kuberesources_<datetimestamp>.tar.gz: 이 파일에는 정적 pod 리소스가 포함되어 있습니다. etcd 암호화가 활성화되어 있는 경우 etcd 스냅 샷의 암호화 키도 포함됩니다.참고etcd 암호화가 활성화되어 있는 경우 보안상의 이유로 이 두 번째 파일을 etcd 스냅 샷과 별도로 저장하는 것이 좋습니다. 그러나 이 파일은 etcd 스냅 샷에서 복원하는데 필요합니다.
etcd 암호화는 키가 아닌 값만 암호화합니다. 즉, 리소스 유형, 네임 스페이스 및 개체 이름은 암호화되지 않습니다.
-
17.2.5.2.2. 단일 자동화된 etcd 백업 생성
다음 단계에 따라 CR(사용자 정의 리소스)을 생성하고 적용하여 단일 etcd 백업을 생성합니다.
사전 요구 사항
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다. -
OpenShift CLI(
oc)에 액세스할 수 있습니다.
프로세스
동적으로 프로비저닝된 스토리지를 사용할 수 있는 경우 다음 단계를 완료하여 단일 자동화된 etcd 백업을 만듭니다.
다음 예와 같은 콘텐츠를 사용하여
etcd-backup-pvc.yaml이라는 PVC(영구 볼륨 클레임)를 생성합니다.kind: PersistentVolumeClaim apiVersion: v1 metadata: name: etcd-backup-pvc namespace: openshift-etcd spec: accessModes: - ReadWriteOnce resources: requests: storage: 200Gi1 volumeMode: Filesystem- 1
- PVC에서 사용할 수 있는 스토리지 용량입니다. 요구 사항에 맞게 이 값을 조정합니다.
다음 명령을 실행하여 PVC를 적용합니다.
$ oc apply -f etcd-backup-pvc.yaml다음 명령을 실행하여 PVC 생성을 확인합니다.
$ oc get pvc출력 예
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE etcd-backup-pvc Bound 51s참고동적 PVC는 마운트될 때까지
Pending상태로 유지됩니다.다음 예와 같은 콘텐츠를 사용하여
etcd-single-backup.yaml이라는 CR 파일을 만듭니다.apiVersion: operator.openshift.io/v1alpha1 kind: EtcdBackup metadata: name: etcd-single-backup namespace: openshift-etcd spec: pvcName: etcd-backup-pvc1 - 1
- 백업을 저장할 PVC의 이름입니다. 환경에 따라 이 값을 조정합니다.
CR을 적용하여 단일 백업을 시작합니다.
$ oc apply -f etcd-single-backup.yaml
동적으로 프로비저닝된 스토리지를 사용할 수 없는 경우 다음 단계를 완료하여 단일 자동화된 etcd 백업을 만듭니다.
다음 콘텐츠를 사용하여
etcd-backup-local-storage.yaml이라는StorageClassCR 파일을 만듭니다.apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: etcd-backup-local-storage provisioner: kubernetes.io/no-provisioner volumeBindingMode: Immediate다음 명령을 실행하여
StorageClassCR을 적용합니다.$ oc apply -f etcd-backup-local-storage.yaml다음 예시와 같은 내용으로
etcd-backup-pv-fs.yaml이라는 PV를 만듭니다.apiVersion: v1 kind: PersistentVolume metadata: name: etcd-backup-pv-fs spec: capacity: storage: 100Gi1 volumeMode: Filesystem accessModes: - ReadWriteOnce persistentVolumeReclaimPolicy: Retain storageClassName: etcd-backup-local-storage local: path: /mnt nodeAffinity: required: nodeSelectorTerms: - matchExpressions: - key: kubernetes.io/hostname operator: In values: - <example_master_node>2 다음 명령을 실행하여 PV 생성을 확인합니다.
$ oc get pv출력 예
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE etcd-backup-pv-fs 100Gi RWO Retain Available etcd-backup-local-storage 10s다음 예와 같은 콘텐츠를 사용하여
etcd-backup-pvc.yaml이라는 PVC를 만듭니다.kind: PersistentVolumeClaim apiVersion: v1 metadata: name: etcd-backup-pvc namespace: openshift-etcd spec: accessModes: - ReadWriteOnce volumeMode: Filesystem resources: requests: storage: 10Gi1 - 1
- PVC에서 사용할 수 있는 스토리지 용량입니다. 요구 사항에 맞게 이 값을 조정합니다.
다음 명령을 실행하여 PVC를 적용합니다.
$ oc apply -f etcd-backup-pvc.yaml다음 예와 같은 콘텐츠를 사용하여
etcd-single-backup.yaml이라는 CR 파일을 만듭니다.apiVersion: operator.openshift.io/v1alpha1 kind: EtcdBackup metadata: name: etcd-single-backup namespace: openshift-etcd spec: pvcName: etcd-backup-pvc1 - 1
- <.> 백업을 저장할 PVC(영구 볼륨 클레임)의 이름입니다. 환경에 따라 이 값을 조정합니다.
CR을 적용하여 단일 백업을 시작합니다.
$ oc apply -f etcd-single-backup.yaml
17.2.5.3. 클러스터 상태 확인
업데이트하는 동안 클러스터 상태를 자주 확인해야 합니다. 노드 상태, 클러스터 운영자 상태 및 실패한 Pod를 확인합니다.
프로세스
다음 명령을 실행하여 클러스터 운영자의 상태를 확인하세요.
$ oc get co출력 예
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE authentication 4.14.34 True False False 4d22h baremetal 4.14.34 True False False 4d22h cloud-controller-manager 4.14.34 True False False 4d23h cloud-credential 4.14.34 True False False 4d23h cluster-autoscaler 4.14.34 True False False 4d22h config-operator 4.14.34 True False False 4d22h console 4.14.34 True False False 4d22h ... service-ca 4.14.34 True False False 4d22h storage 4.14.34 True False False 4d22h클러스터 노드의 상태를 확인합니다.
$ oc get nodes출력 예
NAME STATUS ROLES AGE VERSION ctrl-plane-0 Ready control-plane,master 4d22h v1.27.15+6147456 ctrl-plane-1 Ready control-plane,master 4d22h v1.27.15+6147456 ctrl-plane-2 Ready control-plane,master 4d22h v1.27.15+6147456 worker-0 Ready mcp-1,worker 4d22h v1.27.15+6147456 worker-1 Ready mcp-2,worker 4d22h v1.27.15+6147456진행 중인 포드나 실패한 포드가 없는지 확인하세요. 다음 명령을 실행하면 아무 포드도 반환되지 않아야 합니다.
$ oc get po -A | grep -E -iv 'running|complete'
17.2.6. 제어 평면 전용 클러스터 업데이트 완료
다음 단계에 따라 제어 평면 전용 클러스터 업데이트를 수행하고 업데이트가 완료될 때까지 모니터링합니다.
제어 평면 전용 업데이트는 이전에는 EUS-EUS 업데이트로 알려져 있었습니다. Control Plane Only 업데이트는 OpenShift Container Platform의 짝수 번째 마이너 버전 간에만 실행 가능합니다.
17.2.6.1. 제어 평면 전용 또는 y-스트림 업데이트 확인
4.11 이상 버전의 모든 버전으로 업데이트하는 경우 업데이트를 계속할 수 있음을 수동으로 확인해야 합니다.
업데이트를 확인하기 전에 업데이트하려는 버전에서 제거된 Kubernetes API를 사용하고 있지 않은지 확인하세요. 예를 들어, OpenShift Container Platform 4.17에서는 API가 제거되지 않았습니다. 자세한 내용은 "Kubernetes API 제거"를 참조하세요.
사전 요구 사항
- 클러스터에서 실행되는 모든 애플리케이션의 API가 OpenShift Container Platform의 다음 Y-stream 릴리스와 호환되는지 확인했습니다. 호환성에 대한 자세한 내용은 "업데이트 버전 간 클러스터 API 버전 확인"을 참조하세요.
프로세스
다음 명령을 실행하여 클러스터 업데이트를 시작하기 위한 관리 승인을 완료합니다.
$ oc adm upgrade클러스터 업데이트가 성공적으로 완료되지 않으면 업데이트 실패에 대한 자세한 내용은
이유및메시지섹션에 제공됩니다.출력 예
Cluster version is 4.15.45 Upgradeable=False Reason: MultipleReasons Message: Cluster should not be upgraded between minor versions for multiple reasons: AdminAckRequired,ResourceDeletesInProgress * Kubernetes 1.29 and therefore OpenShift 4.16 remove several APIs which require admin consideration. Please see the knowledge article https://access.redhat.com/articles/7031404 for details and instructions. * Cluster minor level upgrades are not allowed while resource deletions are in progress; resources=PrometheusRule "openshift-kube-apiserver/kube-apiserver-recording-rules" ReleaseAccepted=False Reason: PreconditionChecks Message: Preconditions failed for payload loaded version="4.16.34" image="quay.io/openshift-release-dev/ocp-release@sha256:41bb08c560f6db5039ccdf242e590e8b23049b5eb31e1c4f6021d1d520b353b8": Precondition "ClusterVersionUpgradeable" failed because of "MultipleReasons": Cluster should not be upgraded between minor versions for multiple reasons: AdminAckRequired,ResourceDeletesInProgress * Kubernetes 1.29 and therefore OpenShift 4.16 remove several APIs which require admin consideration. Please see the knowledge article https://access.redhat.com/articles/7031404 for details and instructions. * Cluster minor level upgrades are not allowed while resource deletions are in progress; resources=PrometheusRule "openshift-kube-apiserver/kube-apiserver-recording-rules" Upstream is unset, so the cluster will use an appropriate default. Channel: eus-4.16 (available channels: candidate-4.15, candidate-4.16, eus-4.16, fast-4.15, fast-4.16, stable-4.15, stable-4.16) Recommended updates: VERSION IMAGE 4.16.34 quay.io/openshift-release-dev/ocp-release@sha256:41bb08c560f6db5039ccdf242e590e8b23049b5eb31e1c4f6021d1d520b353b8참고이 예에서 링크된 Red Hat Knowledgebase 문서( OpenShift Container Platform 4.16으로 업그레이드 준비 )에서는 릴리스 간 API 호환성을 확인하는 방법에 대한 자세한 내용을 제공합니다.
검증
다음 명령을 실행하여 업데이트를 확인하세요.
$ oc get configmap admin-acks -n openshift-config -o json | jq .data출력 예
{ "ack-4.14-kube-1.28-api-removals-in-4.15": "true", "ack-4.15-kube-1.29-api-removals-in-4.16": "true" }참고이 예에서 클러스터는 버전 4.14에서 4.15로 업데이트되고, 그런 다음 Control Plane Only 업데이트에서 버전 4.15에서 4.16으로 업데이트됩니다.
17.2.6.2. 클러스터 업데이트 시작
한 y-stream 릴리스에서 다음 릴리스로 업데이트할 때 중간 z-stream 릴리스도 호환되는지 확인해야 합니다.
oc adm upgrade 명령을 실행하여 실행 가능한 릴리스로 업데이트하고 있는지 확인할 수 있습니다. oc adm upgrade 명령은 호환되는 업데이트 릴리스를 나열합니다.
17.2.6.3. 클러스터 업데이트 모니터링
업데이트하는 동안 클러스터 상태를 자주 확인해야 합니다. 노드 상태, 클러스터 운영자 상태 및 실패한 Pod를 확인합니다.
프로세스
클러스터 업데이트를 모니터링합니다. 예를 들어, 버전 4.14에서 4.15로의 클러스터 업데이트를 모니터링하려면 다음 명령을 실행합니다.
$ watch "oc get clusterversion; echo; oc get co | head -1; oc get co | grep 4.14; oc get co | grep 4.15; echo; oc get no; echo; oc get po -A | grep -E -iv 'running|complete'"출력 예
NAME VERSION AVAILABLE PROGRESSING SINCE STATUS version 4.14.34 True True 4m6s Working towards 4.15.33: 111 of 873 done (12% complete), waiting on kube-apiserver NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE authentication 4.14.34 True False False 4d22h baremetal 4.14.34 True False False 4d23h cloud-controller-manager 4.14.34 True False False 4d23h cloud-credential 4.14.34 True False False 4d23h cluster-autoscaler 4.14.34 True False False 4d23h console 4.14.34 True False False 4d22h ... storage 4.14.34 True False False 4d23h config-operator 4.15.33 True False False 4d23h etcd 4.15.33 True False False 4d23h NAME STATUS ROLES AGE VERSION ctrl-plane-0 Ready control-plane,master 4d23h v1.27.15+6147456 ctrl-plane-1 Ready control-plane,master 4d23h v1.27.15+6147456 ctrl-plane-2 Ready control-plane,master 4d23h v1.27.15+6147456 worker-0 Ready mcp-1,worker 4d23h v1.27.15+6147456 worker-1 Ready mcp-2,worker 4d23h v1.27.15+6147456 NAMESPACE NAME READY STATUS RESTARTS AGE openshift-marketplace redhat-marketplace-rf86t 0/1 ContainerCreating 0 0s
검증
업데이트 중에 watch 명령은 한 번에 하나 이상의 클러스터 운영자를 순환하며 MESSAGE 열에 운영자 업데이트 상태를 제공합니다.
클러스터 운영자 업데이트 프로세스가 완료되면 각 제어 평면 노드가 한 번에 하나씩 재부팅됩니다.
이 업데이트 부분에서는 상태 클러스터 운영자가 다시 업데이트 중이거나 성능이 저하되었다는 메시지가 보고됩니다. 이는 노드를 재부팅하는 동안 제어 평면 노드가 오프라인 상태이기 때문입니다.
마지막 제어 평면 노드 재부팅이 완료되면 클러스터 버전이 업데이트된 것으로 표시됩니다.
제어 평면 업데이트가 완료되면 다음과 같은 메시지가 표시됩니다. 이 예에서는 중간 y-스트림 릴리스에 완료된 업데이트를 보여줍니다.
NAME VERSION AVAILABLE PROGRESSING SINCE STATUS
version 4.15.33 True False 28m Cluster version is 4.15.33
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE
authentication 4.15.33 True False False 5d
baremetal 4.15.33 True False False 5d
cloud-controller-manager 4.15.33 True False False 5d1h
cloud-credential 4.15.33 True False False 5d1h
cluster-autoscaler 4.15.33 True False False 5d
config-operator 4.15.33 True False False 5d
console 4.15.33 True False False 5d
...
service-ca 4.15.33 True False False 5d
storage 4.15.33 True False False 5d
NAME STATUS ROLES AGE VERSION
ctrl-plane-0 Ready control-plane,master 5d v1.28.13+2ca1a23
ctrl-plane-1 Ready control-plane,master 5d v1.28.13+2ca1a23
ctrl-plane-2 Ready control-plane,master 5d v1.28.13+2ca1a23
worker-0 Ready mcp-1,worker 5d v1.28.13+2ca1a23
worker-1 Ready mcp-2,worker 5d v1.28.13+2ca1a2317.2.6.4. OLM 운영자 업데이트
통신 환경에서는 소프트웨어를 프로덕션 클러스터에 로드하기 전에 검증해야 합니다. 프로덕션 클러스터도 연결이 끊긴 네트워크에 구성되므로 항상 인터넷에 직접 연결되어 있지는 않습니다. 클러스터가 연결되지 않은 네트워크에 있기 때문에 OpenShift Operator는 설치 중에 수동 업데이트가 가능하도록 구성되어 새 버전을 클러스터별로 관리할 수 있습니다. 다음 절차에 따라 Operator를 최신 버전으로 옮기세요.
프로세스
어떤 운영자를 업데이트해야 하는지 확인하세요.
$ oc get installplan -A | grep -E 'APPROVED|false'출력 예
NAMESPACE NAME CSV APPROVAL APPROVED metallb-system install-nwjnh metallb-operator.v4.16.0-202409202304 Manual false openshift-nmstate install-5r7wr kubernetes-nmstate-operator.4.16.0-202409251605 Manual false다음 운영자에 대한
InstallPlan리소스를 패치합니다.$ oc patch installplan -n metallb-system install-nwjnh --type merge --patch \ '{"spec":{"approved":true}}'출력 예
installplan.operators.coreos.com/install-nwjnh patched다음 명령을 실행하여 네임스페이스를 생성합니다.
$ oc get all -n metallb-system출력 예
NAME READY STATUS RESTARTS AGE pod/metallb-operator-controller-manager-69b5f884c-8bp22 0/1 ContainerCreating 0 4s pod/metallb-operator-controller-manager-77895bdb46-bqjdx 1/1 Running 0 4m1s pod/metallb-operator-webhook-server-5d9b968896-vnbhk 0/1 ContainerCreating 0 4s pod/metallb-operator-webhook-server-d76f9c6c8-57r4w 1/1 Running 0 4m1s ... NAME DESIRED CURRENT READY AGE replicaset.apps/metallb-operator-controller-manager-69b5f884c 1 1 0 4s replicaset.apps/metallb-operator-controller-manager-77895bdb46 1 1 1 4m1s replicaset.apps/metallb-operator-controller-manager-99b76f88 0 0 0 4m40s replicaset.apps/metallb-operator-webhook-server-5d9b968896 1 1 0 4s replicaset.apps/metallb-operator-webhook-server-6f7dbfdb88 0 0 0 4m40s replicaset.apps/metallb-operator-webhook-server-d76f9c6c8 1 1 1 4m1s업데이트가 완료되면 필요한 포드가
실행상태가 되고 필요한ReplicaSet리소스가 준비되어야 합니다.NAME READY STATUS RESTARTS AGE pod/metallb-operator-controller-manager-69b5f884c-8bp22 1/1 Running 0 25s pod/metallb-operator-webhook-server-5d9b968896-vnbhk 1/1 Running 0 25s ... NAME DESIRED CURRENT READY AGE replicaset.apps/metallb-operator-controller-manager-69b5f884c 1 1 1 25s replicaset.apps/metallb-operator-controller-manager-77895bdb46 0 0 0 4m22s replicaset.apps/metallb-operator-webhook-server-5d9b968896 1 1 1 25s replicaset.apps/metallb-operator-webhook-server-d76f9c6c8 0 0 0 4m22s
검증
운영자를 두 번째로 업데이트할 필요가 없는지 확인하세요.
$ oc get installplan -A | grep -E 'APPROVED|false'반환된 출력이 없어야 합니다.
참고일부 운영자가 최종 버전에 앞서 설치해야 하는 임시 z-stream 릴리스 버전을 보유하고 있기 때문에 업데이트를 두 번 승인해야 하는 경우가 있습니다.
17.2.6.4.1. 두 번째 y-스트림 업데이트 수행
첫 번째 y-stream 업데이트를 완료한 후에는 y-stream 제어 평면 버전을 새로운 EUS 버전으로 업데이트해야 합니다.
프로세스
선택한 <4.yz> 릴리스가 여전히 이동할 수 있는 좋은 채널로 나열되어 있는지 확인하세요.
$ oc adm upgrade출력 예
Cluster version is 4.15.33 Upgradeable=False Reason: AdminAckRequired Message: Kubernetes 1.29 and therefore OpenShift 4.16 remove several APIs which require admin consideration. Please see the knowledge article https://access.redhat.com/articles/7031404 for details and instructions. Upstream is unset, so the cluster will use an appropriate default. Channel: eus-4.16 (available channels: candidate-4.15, candidate-4.16, eus-4.16, fast-4.15, fast-4.16, stable-4.15, stable-4.16) Recommended updates: VERSION IMAGE 4.16.14 quay.io/openshift-release-dev/ocp-release@sha256:0521a0f1acd2d1b77f76259cb9bae9c743c60c37d9903806a3372c1414253658 4.16.13 quay.io/openshift-release-dev/ocp-release@sha256:6078cb4ae197b5b0c526910363b8aff540343bfac62ecb1ead9e068d541da27b 4.15.34 quay.io/openshift-release-dev/ocp-release@sha256:f2e0c593f6ed81250c11d0bac94dbaf63656223477b7e8693a652f933056af6e참고새로운 Y-스트림 릴리스의 최초 GA 직후에 업데이트를 수행하는 경우
oc adm upgrade명령을 실행하면 사용 가능한 새로운 Y-스트림 릴리스가 표시되지 않을 수 있습니다.선택 사항: 권장되지 않는 잠재적인 업데이트 릴리스를 확인합니다. 다음 명령을 실행합니다.
$ oc adm upgrade --include-not-recommended출력 예
Cluster version is 4.15.33 Upgradeable=False Reason: AdminAckRequired Message: Kubernetes 1.29 and therefore OpenShift 4.16 remove several APIs which require admin consideration. Please see the knowledge article https://access.redhat.com/articles/7031404 for details and instructions. Upstream is unset, so the cluster will use an appropriate default.Channel: eus-4.16 (available channels: candidate-4.15, candidate-4.16, eus-4.16, fast-4.15, fast-4.16, stable-4.15, stable-4.16) Recommended updates: VERSION IMAGE 4.16.14 quay.io/openshift-release-dev/ocp-release@sha256:0521a0f1acd2d1b77f76259cb9bae9c743c60c37d9903806a3372c1414253658 4.16.13 quay.io/openshift-release-dev/ocp-release@sha256:6078cb4ae197b5b0c526910363b8aff540343bfac62ecb1ead9e068d541da27b 4.15.34 quay.io/openshift-release-dev/ocp-release@sha256:f2e0c593f6ed81250c11d0bac94dbaf63656223477b7e8693a652f933056af6e Supported but not recommended updates: Version: 4.16.15 Image: quay.io/openshift-release-dev/ocp-release@sha256:671bc35e Recommended: Unknown Reason: EvaluationFailed Message: Exposure to AzureRegistryImagePreservation is unknown due to an evaluation failure: invalid PromQL result length must be one, but is 0 In Azure clusters, the in-cluster image registry may fail to preserve images on update. https://issues.redhat.com/browse/IR-461참고이 예제는 Microsoft Azure에 호스팅된 클러스터에 영향을 줄 수 있는 잠재적 오류를 보여줍니다. 베어 메탈 클러스터의 위험은 보여주지 않습니다.
17.2.6.4.2. y-stream 릴리스 업데이트 확인
y-stream 릴리스 간에 전환할 때는 패치 명령을 실행하여 업데이트를 명시적으로 확인해야 합니다. oc adm upgrade 명령의 출력에는 실행할 특정 명령을 보여주는 URL이 제공됩니다.
업데이트를 확인하기 전에 업데이트하려는 버전에서 제거된 Kubernetes API를 사용하고 있지 않은지 확인하세요. 예를 들어, OpenShift Container Platform 4.17에서는 API가 제거되지 않았습니다. 자세한 내용은 "Kubernetes API 제거"를 참조하세요.
사전 요구 사항
- 클러스터에서 실행되는 모든 애플리케이션의 API가 OpenShift Container Platform의 다음 Y-stream 릴리스와 호환되는지 확인했습니다. 호환성에 대한 자세한 내용은 "업데이트 버전 간 클러스터 API 버전 확인"을 참조하세요.
프로세스
다음 명령을 실행하여 클러스터 업데이트를 시작하기 위한 관리 승인을 완료합니다.
$ oc adm upgrade클러스터 업데이트가 성공적으로 완료되지 않으면 업데이트 실패에 대한 자세한 내용은
이유및메시지섹션에 제공됩니다.출력 예
Cluster version is 4.15.45 Upgradeable=False Reason: MultipleReasons Message: Cluster should not be upgraded between minor versions for multiple reasons: AdminAckRequired,ResourceDeletesInProgress * Kubernetes 1.29 and therefore OpenShift 4.16 remove several APIs which require admin consideration. Please see the knowledge article https://access.redhat.com/articles/7031404 for details and instructions. * Cluster minor level upgrades are not allowed while resource deletions are in progress; resources=PrometheusRule "openshift-kube-apiserver/kube-apiserver-recording-rules" ReleaseAccepted=False Reason: PreconditionChecks Message: Preconditions failed for payload loaded version="4.16.34" image="quay.io/openshift-release-dev/ocp-release@sha256:41bb08c560f6db5039ccdf242e590e8b23049b5eb31e1c4f6021d1d520b353b8": Precondition "ClusterVersionUpgradeable" failed because of "MultipleReasons": Cluster should not be upgraded between minor versions for multiple reasons: AdminAckRequired,ResourceDeletesInProgress * Kubernetes 1.29 and therefore OpenShift 4.16 remove several APIs which require admin consideration. Please see the knowledge article https://access.redhat.com/articles/7031404 for details and instructions. * Cluster minor level upgrades are not allowed while resource deletions are in progress; resources=PrometheusRule "openshift-kube-apiserver/kube-apiserver-recording-rules" Upstream is unset, so the cluster will use an appropriate default. Channel: eus-4.16 (available channels: candidate-4.15, candidate-4.16, eus-4.16, fast-4.15, fast-4.16, stable-4.15, stable-4.16) Recommended updates: VERSION IMAGE 4.16.34 quay.io/openshift-release-dev/ocp-release@sha256:41bb08c560f6db5039ccdf242e590e8b23049b5eb31e1c4f6021d1d520b353b8참고이 예에서 링크된 Red Hat Knowledgebase 문서( OpenShift Container Platform 4.16으로 업그레이드 준비 )에서는 릴리스 간 API 호환성을 확인하는 방법에 대한 자세한 내용을 제공합니다.
검증
다음 명령을 실행하여 업데이트를 확인하세요.
$ oc get configmap admin-acks -n openshift-config -o json | jq .data출력 예
{ "ack-4.14-kube-1.28-api-removals-in-4.15": "true", "ack-4.15-kube-1.29-api-removals-in-4.16": "true" }참고이 예에서 클러스터는 버전 4.14에서 4.15로 업데이트되고, 그런 다음 Control Plane Only 업데이트에서 버전 4.15에서 4.16으로 업데이트됩니다.
17.2.6.5. y-stream 제어 평면 업데이트 시작
이동할 새 릴리스 전체를 확인한 후 oc adm upgrade –to=xyz 명령을 실행할 수 있습니다.
프로세스
y-stream 제어 평면 업데이트를 시작합니다. 예를 들어 다음 명령을 실행합니다.
$ oc adm upgrade --to=4.16.14출력 예
Requested update to 4.16.14현재 실행 중인 플랫폼 외의 다른 플랫폼에서 잠재적으로 문제가 발생할 수 있는 z-stream 릴리스로 전환할 수도 있습니다. 다음 예는 Microsoft Azure의 클러스터 업데이트에 발생할 수 있는 문제를 보여줍니다.
$ oc adm upgrade --to=4.16.15출력 예
error: the update 4.16.15 is not one of the recommended updates, but is available as a conditional update. To accept the Recommended=Unknown risk and to proceed with update use --allow-not-recommended. Reason: EvaluationFailed Message: Exposure to AzureRegistryImagePreservation is unknown due to an evaluation failure: invalid PromQL result length must be one, but is 0 In Azure clusters, the in-cluster image registry may fail to preserve images on update. https://issues.redhat.com/browse/IR-461참고이 예제는 Microsoft Azure에 호스팅된 클러스터에 영향을 줄 수 있는 잠재적 오류를 보여줍니다. 베어 메탈 클러스터의 위험은 보여주지 않습니다.
$ oc adm upgrade --to=4.16.15 --allow-not-recommended출력 예
warning: with --allow-not-recommended you have accepted the risks with 4.14.11 and bypassed Recommended=Unknown EvaluationFailed: Exposure to AzureRegistryImagePreservation is unknown due to an evaluation failure: invalid PromQL result length must be one, but is 0 In Azure clusters, the in-cluster image registry may fail to preserve images on update. https://issues.redhat.com/browse/IR-461 Requested update to 4.16.15
17.2.6.6. 클러스터 업데이트의 두 번째 부분 모니터링
<y+1> 버전에 대한 클러스터 업데이트의 두 번째 부분을 모니터링합니다.
프로세스
<y+1> 업데이트의 두 번째 부분의 진행 상황을 모니터링합니다. 예를 들어, 4.15에서 4.16으로의 업데이트를 모니터링하려면 다음 명령을 실행합니다.
$ watch "oc get clusterversion; echo; oc get co | head -1; oc get co | grep 4.15; oc get co | grep 4.16; echo; oc get no; echo; oc get po -A | grep -E -iv 'running|complete'"출력 예
NAME VERSION AVAILABLE PROGRESSING SINCE STATUS version 4.15.33 True True 10m Working towards 4.16.14: 132 of 903 done (14% complete), waiting on kube-controller-manager, kube-scheduler NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE authentication 4.15.33 True False False 5d3h baremetal 4.15.33 True False False 5d4h cloud-controller-manager 4.15.33 True False False 5d4h cloud-credential 4.15.33 True False False 5d4h cluster-autoscaler 4.15.33 True False False 5d4h console 4.15.33 True False False 5d3h ... config-operator 4.16.14 True False False 5d4h etcd 4.16.14 True False False 5d4h kube-apiserver 4.16.14 True True False 5d4h NodeInstallerProgressing: 1 node is at revision 15; 2 nodes are at revision 17 NAME STATUS ROLES AGE VERSION ctrl-plane-0 Ready control-plane,master 5d4h v1.28.13+2ca1a23 ctrl-plane-1 Ready control-plane,master 5d4h v1.28.13+2ca1a23 ctrl-plane-2 Ready control-plane,master 5d4h v1.28.13+2ca1a23 worker-0 Ready mcp-1,worker 5d4h v1.27.15+6147456 worker-1 Ready mcp-2,worker 5d4h v1.27.15+6147456 NAMESPACE NAME READY STATUS RESTARTS AGE openshift-kube-apiserver kube-apiserver-ctrl-plane-0 0/5 Pending 0 <invalid>마지막 제어 평면 노드가 완료되는 즉시 클러스터 버전이 새로운 EUS 릴리스로 업데이트됩니다. 예를 들면 다음과 같습니다.
NAME VERSION AVAILABLE PROGRESSING SINCE STATUS version 4.16.14 True False 123m Cluster version is 4.16.14 NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE authentication 4.16.14 True False False 5d6h baremetal 4.16.14 True False False 5d7h cloud-controller-manager 4.16.14 True False False 5d7h cloud-credential 4.16.14 True False False 5d7h cluster-autoscaler 4.16.14 True False False 5d7h config-operator 4.16.14 True False False 5d7h console 4.16.14 True False False 5d6h #... operator-lifecycle-manager-packageserver 4.16.14 True False False 5d7h service-ca 4.16.14 True False False 5d7h storage 4.16.14 True False False 5d7h NAME STATUS ROLES AGE VERSION ctrl-plane-0 Ready control-plane,master 5d7h v1.29.8+f10c92d ctrl-plane-1 Ready control-plane,master 5d7h v1.29.8+f10c92d ctrl-plane-2 Ready control-plane,master 5d7h v1.29.8+f10c92d worker-0 Ready mcp-1,worker 5d7h v1.27.15+6147456 worker-1 Ready mcp-2,worker 5d7h v1.27.15+6147456
17.2.6.7. 모든 OLM 운영자 업데이트
다중 버전 업그레이드의 두 번째 단계에서는 모든 운영자를 승인해야 하며, 업그레이드하려는 다른 운영자에 대한 설치 계획을 추가해야 합니다.
"OLM 운영자 업데이트"에 설명된 것과 동일한 절차를 따르세요. 필요에 따라 OLM이 아닌 운영자도 업데이트해야 합니다.
프로세스
클러스터 업데이트를 모니터링합니다. 예를 들어, 버전 4.14에서 4.15로의 클러스터 업데이트를 모니터링하려면 다음 명령을 실행합니다.
$ watch "oc get clusterversion; echo; oc get co | head -1; oc get co | grep 4.14; oc get co | grep 4.15; echo; oc get no; echo; oc get po -A | grep -E -iv 'running|complete'"어떤 운영자를 업데이트해야 하는지 확인하세요.
$ oc get installplan -A | grep -E 'APPROVED|false'다음 운영자에 대한
InstallPlan리소스를 패치합니다.$ oc patch installplan -n metallb-system install-nwjnh --type merge --patch \ '{"spec":{"approved":true}}'다음 명령을 실행하여 네임스페이스를 생성합니다.
$ oc get all -n metallb-system업데이트가 완료되면 필요한 포드가
실행상태가 되고, 필요한ReplicaSet리소스가 준비됩니다.
검증
업데이트 중에 watch 명령은 한 번에 하나 이상의 클러스터 운영자를 순환하며 MESSAGE 열에 운영자 업데이트 상태를 제공합니다.
클러스터 운영자 업데이트 프로세스가 완료되면 각 제어 평면 노드가 한 번에 하나씩 재부팅됩니다.
이 업데이트 부분에서는 상태 클러스터 운영자가 다시 업데이트 중이거나 성능이 저하되었다는 메시지가 보고됩니다. 이는 노드를 재부팅하는 동안 제어 평면 노드가 오프라인 상태이기 때문입니다.
17.2.6.8. 작업자 노드 업데이트
관련 MCP 그룹의 일시 중지를 해제하여 제어 평면을 업데이트한 후 작업자 노드를 업그레이드합니다. mcp 그룹의 일시 중지를 해제하면 해당 그룹의 작업자 노드에 대한 업그레이드 프로세스가 시작됩니다. 클러스터의 각 워커 노드는 필요에 따라 새로운 EUS, y-stream 또는 z-stream 버전으로 업그레이드하기 위해 재부팅됩니다.
Control Plane Only 업그레이드의 경우, 워커 노드가 업데이트되면 한 번만 재부팅하고 <y+2>-릴리스 버전으로 넘어갑니다. 이 기능은 대규모 베어 메탈 클러스터를 업그레이드하는 데 걸리는 시간을 줄이기 위해 추가되었습니다.
이곳은 잠재적인 보류 지점입니다. 작업자 노드가 <y-2>-릴리스 버전인 동안 제어 평면이 새로운 EUS 릴리스로 업데이트되어 프로덕션에서 실행되도록 완벽하게 지원되는 클러스터 버전을 가질 수 있습니다. 이를 통해 대규모 클러스터를 여러 유지 관리 창에 걸쳐 단계적으로 업그레이드할 수 있습니다.
mcp그룹에서 관리되는 노드의 수를 확인할 수 있습니다. 다음 명령을 실행하여mcp그룹 목록을 가져옵니다.$ oc get mcp출력 예
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE master rendered-master-c9a52144456dbff9c9af9c5a37d1b614 True False False 3 3 3 0 36d mcp-1 rendered-mcp-1-07fe50b9ad51fae43ed212e84e1dcc8e False False False 1 0 0 0 47h mcp-2 rendered-mcp-2-07fe50b9ad51fae43ed212e84e1dcc8e False False False 1 0 0 0 47h worker rendered-worker-f1ab7b9a768e1b0ac9290a18817f60f0 True False False 0 0 0 0 36d참고한 번에 얼마나 많은
MCP그룹을 업그레이드할지 결정합니다. 이는 한 번에 얼마나 많은 CNF 포드를 제거할 수 있는지, 그리고 포드 중단 예산과 안티-어피니티 설정이 어떻게 구성되어 있는지에 따라 달라집니다.클러스터의 노드 목록을 가져옵니다.
$ oc get nodes출력 예
NAME STATUS ROLES AGE VERSION ctrl-plane-0 Ready control-plane,master 5d8h v1.29.8+f10c92d ctrl-plane-1 Ready control-plane,master 5d8h v1.29.8+f10c92d ctrl-plane-2 Ready control-plane,master 5d8h v1.29.8+f10c92d worker-0 Ready mcp-1,worker 5d8h v1.27.15+6147456 worker-1 Ready mcp-2,worker 5d8h v1.27.15+6147456일시 중지된
MachineConfigPool그룹을 확인하세요.$ oc get mcp -o json | jq -r '["MCP","Paused"], ["---","------"], (.items[] | [(.metadata.name), (.spec.paused)]) | @tsv' | grep -v worker출력 예
MCP Paused --- ------ master false mcp-1 true mcp-2 true참고각
MachineConfigPool은독립적으로 일시 중지를 해제할 수 있습니다. 따라서 유지 관리 기간이 끝나더라도 다른 MCP의 일시 중지를 즉시 해제할 필요는 없습니다. 클러스터는 일부 작업자 노드가 여전히 <y-2>-릴리스 버전인 상태에서 실행되도록 지원됩니다.업그레이드를 시작하려면 필요한
mcp그룹의 일시 중지를 해제하세요.$ oc patch mcp/mcp-1 --type merge --patch '{"spec":{"paused":false}}'출력 예
machineconfigpool.machineconfiguration.openshift.io/mcp-1 patched필수
mcp그룹이 일시 중지 해제되었는지 확인하세요.$ oc get mcp -o json | jq -r '["MCP","Paused"], ["---","------"], (.items[] | [(.metadata.name), (.spec.paused)]) | @tsv' | grep -v worker출력 예
MCP Paused --- ------ master false mcp-1 false mcp-2 true각
mcp그룹이 업그레이드되면 일시 중지를 계속 해제하고 나머지 노드를 업그레이드합니다.$ oc get nodes출력 예
NAME STATUS ROLES AGE VERSION ctrl-plane-0 Ready control-plane,master 5d8h v1.29.8+f10c92d ctrl-plane-1 Ready control-plane,master 5d8h v1.29.8+f10c92d ctrl-plane-2 Ready control-plane,master 5d8h v1.29.8+f10c92d worker-0 Ready mcp-1,worker 5d8h v1.29.8+f10c92d worker-1 NotReady,SchedulingDisabled mcp-2,worker 5d8h v1.27.15+6147456
17.2.6.9. 새로 업데이트된 클러스터의 상태 확인
클러스터를 업데이트한 후 다음 명령을 실행하여 클러스터가 다시 백업되고 실행 중인지 확인하세요.
프로세스
다음 명령을 실행하여 클러스터 버전을 확인하세요.
$ oc get clusterversion출력 예
NAME VERSION AVAILABLE PROGRESSING SINCE STATUS version 4.16.14 True False 4h38m Cluster version is 4.16.14이렇게 하면 새로운 클러스터 버전이 반환되고
PROGRESSING열은False를반환해야 합니다.모든 노드가 준비되었는지 확인하세요.
$ oc get nodes출력 예
NAME STATUS ROLES AGE VERSION ctrl-plane-0 Ready control-plane,master 5d9h v1.29.8+f10c92d ctrl-plane-1 Ready control-plane,master 5d9h v1.29.8+f10c92d ctrl-plane-2 Ready control-plane,master 5d9h v1.29.8+f10c92d worker-0 Ready mcp-1,worker 5d9h v1.29.8+f10c92d worker-1 Ready mcp-2,worker 5d9h v1.29.8+f10c92d클러스터의 모든 노드는
준비상태여야 하며 동일한 버전을 실행해야 합니다.클러스터에 일시 중지된
mcp리소스가 없는지 확인합니다.$ oc get mcp -o json | jq -r '["MCP","Paused"], ["---","------"], (.items[] | [(.metadata.name), (.spec.paused)]) | @tsv' | grep -v worker출력 예
MCP Paused --- ------ master false mcp-1 false mcp-2 false모든 클러스터 운영자가 사용 가능한지 확인하세요.
$ oc get co출력 예
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE authentication 4.16.14 True False False 5d9h baremetal 4.16.14 True False False 5d9h cloud-controller-manager 4.16.14 True False False 5d10h cloud-credential 4.16.14 True False False 5d10h cluster-autoscaler 4.16.14 True False False 5d9h config-operator 4.16.14 True False False 5d9h console 4.16.14 True False False 5d9h control-plane-machine-set 4.16.14 True False False 5d9h csi-snapshot-controller 4.16.14 True False False 5d9h dns 4.16.14 True False False 5d9h etcd 4.16.14 True False False 5d9h image-registry 4.16.14 True False False 85m ingress 4.16.14 True False False 5d9h insights 4.16.14 True False False 5d9h kube-apiserver 4.16.14 True False False 5d9h kube-controller-manager 4.16.14 True False False 5d9h kube-scheduler 4.16.14 True False False 5d9h kube-storage-version-migrator 4.16.14 True False False 4h48m machine-api 4.16.14 True False False 5d9h machine-approver 4.16.14 True False False 5d9h machine-config 4.16.14 True False False 5d9h marketplace 4.16.14 True False False 5d9h monitoring 4.16.14 True False False 5d9h network 4.16.14 True False False 5d9h node-tuning 4.16.14 True False False 5d7h openshift-apiserver 4.16.14 True False False 5d9h openshift-controller-manager 4.16.14 True False False 5d9h openshift-samples 4.16.14 True False False 5h24m operator-lifecycle-manager 4.16.14 True False False 5d9h operator-lifecycle-manager-catalog 4.16.14 True False False 5d9h operator-lifecycle-manager-packageserver 4.16.14 True False False 5d9h service-ca 4.16.14 True False False 5d9h storage 4.16.14 True False False 5d9h모든 클러스터 운영자는
AVAILABLE열에True를보고해야 합니다.모든 포드가 건강한지 확인하세요.
$ oc get po -A | grep -E -iv 'complete|running'이렇게 하면 포드가 반환되지 않습니다.
참고업데이트 후에도 몇몇 포드가 계속 움직이는 것을 볼 수 있습니다. 잠시 지켜보면서 모든 포드가 비워졌는지 확인하세요.
17.2.7. y-stream 클러스터 업데이트 완료
다음 단계에 따라 y-stream 클러스터 업데이트를 수행하고 업데이트가 완료될 때까지 모니터링하세요. y-스트림 업데이트를 완료하는 것은 제어 평면 전용 업데이트보다 더 간단합니다.
17.2.7.1. 제어 평면 전용 또는 y-스트림 업데이트 확인
4.11 이상 버전의 모든 버전으로 업데이트하는 경우 업데이트를 계속할 수 있음을 수동으로 확인해야 합니다.
업데이트를 확인하기 전에 업데이트하려는 버전에서 제거된 Kubernetes API를 사용하고 있지 않은지 확인하세요. 예를 들어, OpenShift Container Platform 4.17에서는 API가 제거되지 않았습니다. 자세한 내용은 "Kubernetes API 제거"를 참조하세요.
사전 요구 사항
- 클러스터에서 실행되는 모든 애플리케이션의 API가 OpenShift Container Platform의 다음 Y-stream 릴리스와 호환되는지 확인했습니다. 호환성에 대한 자세한 내용은 "업데이트 버전 간 클러스터 API 버전 확인"을 참조하세요.
프로세스
다음 명령을 실행하여 클러스터 업데이트를 시작하기 위한 관리 승인을 완료합니다.
$ oc adm upgrade클러스터 업데이트가 성공적으로 완료되지 않으면 업데이트 실패에 대한 자세한 내용은
이유및메시지섹션에 제공됩니다.출력 예
Cluster version is 4.15.45 Upgradeable=False Reason: MultipleReasons Message: Cluster should not be upgraded between minor versions for multiple reasons: AdminAckRequired,ResourceDeletesInProgress * Kubernetes 1.29 and therefore OpenShift 4.16 remove several APIs which require admin consideration. Please see the knowledge article https://access.redhat.com/articles/7031404 for details and instructions. * Cluster minor level upgrades are not allowed while resource deletions are in progress; resources=PrometheusRule "openshift-kube-apiserver/kube-apiserver-recording-rules" ReleaseAccepted=False Reason: PreconditionChecks Message: Preconditions failed for payload loaded version="4.16.34" image="quay.io/openshift-release-dev/ocp-release@sha256:41bb08c560f6db5039ccdf242e590e8b23049b5eb31e1c4f6021d1d520b353b8": Precondition "ClusterVersionUpgradeable" failed because of "MultipleReasons": Cluster should not be upgraded between minor versions for multiple reasons: AdminAckRequired,ResourceDeletesInProgress * Kubernetes 1.29 and therefore OpenShift 4.16 remove several APIs which require admin consideration. Please see the knowledge article https://access.redhat.com/articles/7031404 for details and instructions. * Cluster minor level upgrades are not allowed while resource deletions are in progress; resources=PrometheusRule "openshift-kube-apiserver/kube-apiserver-recording-rules" Upstream is unset, so the cluster will use an appropriate default. Channel: eus-4.16 (available channels: candidate-4.15, candidate-4.16, eus-4.16, fast-4.15, fast-4.16, stable-4.15, stable-4.16) Recommended updates: VERSION IMAGE 4.16.34 quay.io/openshift-release-dev/ocp-release@sha256:41bb08c560f6db5039ccdf242e590e8b23049b5eb31e1c4f6021d1d520b353b8참고이 예에서 링크된 Red Hat Knowledgebase 문서( OpenShift Container Platform 4.16으로 업그레이드 준비 )에서는 릴리스 간 API 호환성을 확인하는 방법에 대한 자세한 내용을 제공합니다.
검증
다음 명령을 실행하여 업데이트를 확인하세요.
$ oc get configmap admin-acks -n openshift-config -o json | jq .data출력 예
{ "ack-4.14-kube-1.28-api-removals-in-4.15": "true", "ack-4.15-kube-1.29-api-removals-in-4.16": "true" }참고이 예에서 클러스터는 버전 4.14에서 4.15로 업데이트되고, 그런 다음 Control Plane Only 업데이트에서 버전 4.15에서 4.16으로 업데이트됩니다.
17.2.7.2. 클러스터 업데이트 시작
한 y-stream 릴리스에서 다음 릴리스로 업데이트할 때 중간 z-stream 릴리스도 호환되는지 확인해야 합니다.
oc adm upgrade 명령을 실행하여 실행 가능한 릴리스로 업데이트하고 있는지 확인할 수 있습니다. oc adm upgrade 명령은 호환되는 업데이트 릴리스를 나열합니다.
17.2.7.3. 클러스터 업데이트 모니터링
업데이트하는 동안 클러스터 상태를 자주 확인해야 합니다. 노드 상태, 클러스터 운영자 상태 및 실패한 Pod를 확인합니다.
프로세스
클러스터 업데이트를 모니터링합니다. 예를 들어, 버전 4.14에서 4.15로의 클러스터 업데이트를 모니터링하려면 다음 명령을 실행합니다.
$ watch "oc get clusterversion; echo; oc get co | head -1; oc get co | grep 4.14; oc get co | grep 4.15; echo; oc get no; echo; oc get po -A | grep -E -iv 'running|complete'"출력 예
NAME VERSION AVAILABLE PROGRESSING SINCE STATUS version 4.14.34 True True 4m6s Working towards 4.15.33: 111 of 873 done (12% complete), waiting on kube-apiserver NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE authentication 4.14.34 True False False 4d22h baremetal 4.14.34 True False False 4d23h cloud-controller-manager 4.14.34 True False False 4d23h cloud-credential 4.14.34 True False False 4d23h cluster-autoscaler 4.14.34 True False False 4d23h console 4.14.34 True False False 4d22h ... storage 4.14.34 True False False 4d23h config-operator 4.15.33 True False False 4d23h etcd 4.15.33 True False False 4d23h NAME STATUS ROLES AGE VERSION ctrl-plane-0 Ready control-plane,master 4d23h v1.27.15+6147456 ctrl-plane-1 Ready control-plane,master 4d23h v1.27.15+6147456 ctrl-plane-2 Ready control-plane,master 4d23h v1.27.15+6147456 worker-0 Ready mcp-1,worker 4d23h v1.27.15+6147456 worker-1 Ready mcp-2,worker 4d23h v1.27.15+6147456 NAMESPACE NAME READY STATUS RESTARTS AGE openshift-marketplace redhat-marketplace-rf86t 0/1 ContainerCreating 0 0s
검증
업데이트 중에 watch 명령은 한 번에 하나 이상의 클러스터 운영자를 순환하며 MESSAGE 열에 운영자 업데이트 상태를 제공합니다.
클러스터 운영자 업데이트 프로세스가 완료되면 각 제어 평면 노드가 한 번에 하나씩 재부팅됩니다.
이 업데이트 부분에서는 상태 클러스터 운영자가 다시 업데이트 중이거나 성능이 저하되었다는 메시지가 보고됩니다. 이는 노드를 재부팅하는 동안 제어 평면 노드가 오프라인 상태이기 때문입니다.
마지막 제어 평면 노드 재부팅이 완료되면 클러스터 버전이 업데이트된 것으로 표시됩니다.
제어 평면 업데이트가 완료되면 다음과 같은 메시지가 표시됩니다. 이 예에서는 중간 y-스트림 릴리스에 완료된 업데이트를 보여줍니다.
NAME VERSION AVAILABLE PROGRESSING SINCE STATUS
version 4.15.33 True False 28m Cluster version is 4.15.33
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE
authentication 4.15.33 True False False 5d
baremetal 4.15.33 True False False 5d
cloud-controller-manager 4.15.33 True False False 5d1h
cloud-credential 4.15.33 True False False 5d1h
cluster-autoscaler 4.15.33 True False False 5d
config-operator 4.15.33 True False False 5d
console 4.15.33 True False False 5d
...
service-ca 4.15.33 True False False 5d
storage 4.15.33 True False False 5d
NAME STATUS ROLES AGE VERSION
ctrl-plane-0 Ready control-plane,master 5d v1.28.13+2ca1a23
ctrl-plane-1 Ready control-plane,master 5d v1.28.13+2ca1a23
ctrl-plane-2 Ready control-plane,master 5d v1.28.13+2ca1a23
worker-0 Ready mcp-1,worker 5d v1.28.13+2ca1a23
worker-1 Ready mcp-2,worker 5d v1.28.13+2ca1a2317.2.7.4. OLM 운영자 업데이트
통신 환경에서는 소프트웨어를 프로덕션 클러스터에 로드하기 전에 검증해야 합니다. 프로덕션 클러스터도 연결이 끊긴 네트워크에 구성되므로 항상 인터넷에 직접 연결되어 있지는 않습니다. 클러스터가 연결되지 않은 네트워크에 있기 때문에 OpenShift Operator는 설치 중에 수동 업데이트가 가능하도록 구성되어 새 버전을 클러스터별로 관리할 수 있습니다. 다음 절차에 따라 Operator를 최신 버전으로 옮기세요.
프로세스
어떤 운영자를 업데이트해야 하는지 확인하세요.
$ oc get installplan -A | grep -E 'APPROVED|false'출력 예
NAMESPACE NAME CSV APPROVAL APPROVED metallb-system install-nwjnh metallb-operator.v4.16.0-202409202304 Manual false openshift-nmstate install-5r7wr kubernetes-nmstate-operator.4.16.0-202409251605 Manual false다음 운영자에 대한
InstallPlan리소스를 패치합니다.$ oc patch installplan -n metallb-system install-nwjnh --type merge --patch \ '{"spec":{"approved":true}}'출력 예
installplan.operators.coreos.com/install-nwjnh patched다음 명령을 실행하여 네임스페이스를 생성합니다.
$ oc get all -n metallb-system출력 예
NAME READY STATUS RESTARTS AGE pod/metallb-operator-controller-manager-69b5f884c-8bp22 0/1 ContainerCreating 0 4s pod/metallb-operator-controller-manager-77895bdb46-bqjdx 1/1 Running 0 4m1s pod/metallb-operator-webhook-server-5d9b968896-vnbhk 0/1 ContainerCreating 0 4s pod/metallb-operator-webhook-server-d76f9c6c8-57r4w 1/1 Running 0 4m1s ... NAME DESIRED CURRENT READY AGE replicaset.apps/metallb-operator-controller-manager-69b5f884c 1 1 0 4s replicaset.apps/metallb-operator-controller-manager-77895bdb46 1 1 1 4m1s replicaset.apps/metallb-operator-controller-manager-99b76f88 0 0 0 4m40s replicaset.apps/metallb-operator-webhook-server-5d9b968896 1 1 0 4s replicaset.apps/metallb-operator-webhook-server-6f7dbfdb88 0 0 0 4m40s replicaset.apps/metallb-operator-webhook-server-d76f9c6c8 1 1 1 4m1s업데이트가 완료되면 필요한 포드가
실행상태가 되고 필요한ReplicaSet리소스가 준비되어야 합니다.NAME READY STATUS RESTARTS AGE pod/metallb-operator-controller-manager-69b5f884c-8bp22 1/1 Running 0 25s pod/metallb-operator-webhook-server-5d9b968896-vnbhk 1/1 Running 0 25s ... NAME DESIRED CURRENT READY AGE replicaset.apps/metallb-operator-controller-manager-69b5f884c 1 1 1 25s replicaset.apps/metallb-operator-controller-manager-77895bdb46 0 0 0 4m22s replicaset.apps/metallb-operator-webhook-server-5d9b968896 1 1 1 25s replicaset.apps/metallb-operator-webhook-server-d76f9c6c8 0 0 0 4m22s
검증
운영자를 두 번째로 업데이트할 필요가 없는지 확인하세요.
$ oc get installplan -A | grep -E 'APPROVED|false'반환된 출력이 없어야 합니다.
참고일부 운영자가 최종 버전에 앞서 설치해야 하는 임시 z-stream 릴리스 버전을 보유하고 있기 때문에 업데이트를 두 번 승인해야 하는 경우가 있습니다.
17.2.7.5. 작업자 노드 업데이트
관련 MCP 그룹의 일시 중지를 해제하여 제어 평면을 업데이트한 후 작업자 노드를 업그레이드합니다. mcp 그룹의 일시 중지를 해제하면 해당 그룹의 작업자 노드에 대한 업그레이드 프로세스가 시작됩니다. 클러스터의 각 워커 노드는 필요에 따라 새로운 EUS, y-stream 또는 z-stream 버전으로 업그레이드하기 위해 재부팅됩니다.
Control Plane Only 업그레이드의 경우, 워커 노드가 업데이트되면 한 번만 재부팅하고 <y+2>-릴리스 버전으로 넘어갑니다. 이 기능은 대규모 베어 메탈 클러스터를 업그레이드하는 데 걸리는 시간을 줄이기 위해 추가되었습니다.
이곳은 잠재적인 보류 지점입니다. 작업자 노드가 <y-2>-릴리스 버전인 동안 제어 평면이 새로운 EUS 릴리스로 업데이트되어 프로덕션에서 실행되도록 완벽하게 지원되는 클러스터 버전을 가질 수 있습니다. 이를 통해 대규모 클러스터를 여러 유지 관리 창에 걸쳐 단계적으로 업그레이드할 수 있습니다.
mcp그룹에서 관리되는 노드의 수를 확인할 수 있습니다. 다음 명령을 실행하여mcp그룹 목록을 가져옵니다.$ oc get mcp출력 예
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE master rendered-master-c9a52144456dbff9c9af9c5a37d1b614 True False False 3 3 3 0 36d mcp-1 rendered-mcp-1-07fe50b9ad51fae43ed212e84e1dcc8e False False False 1 0 0 0 47h mcp-2 rendered-mcp-2-07fe50b9ad51fae43ed212e84e1dcc8e False False False 1 0 0 0 47h worker rendered-worker-f1ab7b9a768e1b0ac9290a18817f60f0 True False False 0 0 0 0 36d참고한 번에 얼마나 많은
MCP그룹을 업그레이드할지 결정합니다. 이는 한 번에 얼마나 많은 CNF 포드를 제거할 수 있는지, 그리고 포드 중단 예산과 안티-어피니티 설정이 어떻게 구성되어 있는지에 따라 달라집니다.클러스터의 노드 목록을 가져옵니다.
$ oc get nodes출력 예
NAME STATUS ROLES AGE VERSION ctrl-plane-0 Ready control-plane,master 5d8h v1.29.8+f10c92d ctrl-plane-1 Ready control-plane,master 5d8h v1.29.8+f10c92d ctrl-plane-2 Ready control-plane,master 5d8h v1.29.8+f10c92d worker-0 Ready mcp-1,worker 5d8h v1.27.15+6147456 worker-1 Ready mcp-2,worker 5d8h v1.27.15+6147456일시 중지된
MachineConfigPool그룹을 확인하세요.$ oc get mcp -o json | jq -r '["MCP","Paused"], ["---","------"], (.items[] | [(.metadata.name), (.spec.paused)]) | @tsv' | grep -v worker출력 예
MCP Paused --- ------ master false mcp-1 true mcp-2 true참고각
MachineConfigPool은독립적으로 일시 중지를 해제할 수 있습니다. 따라서 유지 관리 기간이 끝나더라도 다른 MCP의 일시 중지를 즉시 해제할 필요는 없습니다. 클러스터는 일부 작업자 노드가 여전히 <y-2>-릴리스 버전인 상태에서 실행되도록 지원됩니다.업그레이드를 시작하려면 필요한
mcp그룹의 일시 중지를 해제하세요.$ oc patch mcp/mcp-1 --type merge --patch '{"spec":{"paused":false}}'출력 예
machineconfigpool.machineconfiguration.openshift.io/mcp-1 patched필수
mcp그룹이 일시 중지 해제되었는지 확인하세요.$ oc get mcp -o json | jq -r '["MCP","Paused"], ["---","------"], (.items[] | [(.metadata.name), (.spec.paused)]) | @tsv' | grep -v worker출력 예
MCP Paused --- ------ master false mcp-1 false mcp-2 true각
mcp그룹이 업그레이드되면 일시 중지를 계속 해제하고 나머지 노드를 업그레이드합니다.$ oc get nodes출력 예
NAME STATUS ROLES AGE VERSION ctrl-plane-0 Ready control-plane,master 5d8h v1.29.8+f10c92d ctrl-plane-1 Ready control-plane,master 5d8h v1.29.8+f10c92d ctrl-plane-2 Ready control-plane,master 5d8h v1.29.8+f10c92d worker-0 Ready mcp-1,worker 5d8h v1.29.8+f10c92d worker-1 NotReady,SchedulingDisabled mcp-2,worker 5d8h v1.27.15+6147456
17.2.7.6. 새로 업데이트된 클러스터의 상태 확인
클러스터를 업데이트한 후 다음 명령을 실행하여 클러스터가 다시 백업되고 실행 중인지 확인하세요.
프로세스
다음 명령을 실행하여 클러스터 버전을 확인하세요.
$ oc get clusterversion출력 예
NAME VERSION AVAILABLE PROGRESSING SINCE STATUS version 4.16.14 True False 4h38m Cluster version is 4.16.14이렇게 하면 새로운 클러스터 버전이 반환되고
PROGRESSING열은False를반환해야 합니다.모든 노드가 준비되었는지 확인하세요.
$ oc get nodes출력 예
NAME STATUS ROLES AGE VERSION ctrl-plane-0 Ready control-plane,master 5d9h v1.29.8+f10c92d ctrl-plane-1 Ready control-plane,master 5d9h v1.29.8+f10c92d ctrl-plane-2 Ready control-plane,master 5d9h v1.29.8+f10c92d worker-0 Ready mcp-1,worker 5d9h v1.29.8+f10c92d worker-1 Ready mcp-2,worker 5d9h v1.29.8+f10c92d클러스터의 모든 노드는
준비상태여야 하며 동일한 버전을 실행해야 합니다.클러스터에 일시 중지된
mcp리소스가 없는지 확인합니다.$ oc get mcp -o json | jq -r '["MCP","Paused"], ["---","------"], (.items[] | [(.metadata.name), (.spec.paused)]) | @tsv' | grep -v worker출력 예
MCP Paused --- ------ master false mcp-1 false mcp-2 false모든 클러스터 운영자가 사용 가능한지 확인하세요.
$ oc get co출력 예
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE authentication 4.16.14 True False False 5d9h baremetal 4.16.14 True False False 5d9h cloud-controller-manager 4.16.14 True False False 5d10h cloud-credential 4.16.14 True False False 5d10h cluster-autoscaler 4.16.14 True False False 5d9h config-operator 4.16.14 True False False 5d9h console 4.16.14 True False False 5d9h control-plane-machine-set 4.16.14 True False False 5d9h csi-snapshot-controller 4.16.14 True False False 5d9h dns 4.16.14 True False False 5d9h etcd 4.16.14 True False False 5d9h image-registry 4.16.14 True False False 85m ingress 4.16.14 True False False 5d9h insights 4.16.14 True False False 5d9h kube-apiserver 4.16.14 True False False 5d9h kube-controller-manager 4.16.14 True False False 5d9h kube-scheduler 4.16.14 True False False 5d9h kube-storage-version-migrator 4.16.14 True False False 4h48m machine-api 4.16.14 True False False 5d9h machine-approver 4.16.14 True False False 5d9h machine-config 4.16.14 True False False 5d9h marketplace 4.16.14 True False False 5d9h monitoring 4.16.14 True False False 5d9h network 4.16.14 True False False 5d9h node-tuning 4.16.14 True False False 5d7h openshift-apiserver 4.16.14 True False False 5d9h openshift-controller-manager 4.16.14 True False False 5d9h openshift-samples 4.16.14 True False False 5h24m operator-lifecycle-manager 4.16.14 True False False 5d9h operator-lifecycle-manager-catalog 4.16.14 True False False 5d9h operator-lifecycle-manager-packageserver 4.16.14 True False False 5d9h service-ca 4.16.14 True False False 5d9h storage 4.16.14 True False False 5d9h모든 클러스터 운영자는
AVAILABLE열에True를보고해야 합니다.모든 포드가 건강한지 확인하세요.
$ oc get po -A | grep -E -iv 'complete|running'이렇게 하면 포드가 반환되지 않습니다.
참고업데이트 후에도 몇몇 포드가 계속 움직이는 것을 볼 수 있습니다. 잠시 지켜보면서 모든 포드가 비워졌는지 확인하세요.
17.2.8. z-stream 클러스터 업데이트 완료
다음 단계에 따라 z-stream 클러스터 업데이트를 수행하고 업데이트가 완료될 때까지 모니터링하세요. z-스트림 업데이트를 완료하는 것은 제어 평면 전용 업데이트나 y-스트림 업데이트를 완료하는 것보다 더 간단합니다.
17.2.8.1. 클러스터 업데이트 시작
한 y-stream 릴리스에서 다음 릴리스로 업데이트할 때 중간 z-stream 릴리스도 호환되는지 확인해야 합니다.
oc adm upgrade 명령을 실행하여 실행 가능한 릴리스로 업데이트하고 있는지 확인할 수 있습니다. oc adm upgrade 명령은 호환되는 업데이트 릴리스를 나열합니다.
17.2.8.2. 작업자 노드 업데이트
관련 MCP 그룹의 일시 중지를 해제하여 제어 평면을 업데이트한 후 작업자 노드를 업그레이드합니다. mcp 그룹의 일시 중지를 해제하면 해당 그룹의 작업자 노드에 대한 업그레이드 프로세스가 시작됩니다. 클러스터의 각 워커 노드는 필요에 따라 새로운 EUS, y-stream 또는 z-stream 버전으로 업그레이드하기 위해 재부팅됩니다.
Control Plane Only 업그레이드의 경우, 워커 노드가 업데이트되면 한 번만 재부팅하고 <y+2>-릴리스 버전으로 넘어갑니다. 이 기능은 대규모 베어 메탈 클러스터를 업그레이드하는 데 걸리는 시간을 줄이기 위해 추가되었습니다.
이곳은 잠재적인 보류 지점입니다. 작업자 노드가 <y-2>-릴리스 버전인 동안 제어 평면이 새로운 EUS 릴리스로 업데이트되어 프로덕션에서 실행되도록 완벽하게 지원되는 클러스터 버전을 가질 수 있습니다. 이를 통해 대규모 클러스터를 여러 유지 관리 창에 걸쳐 단계적으로 업그레이드할 수 있습니다.
mcp그룹에서 관리되는 노드의 수를 확인할 수 있습니다. 다음 명령을 실행하여mcp그룹 목록을 가져옵니다.$ oc get mcp출력 예
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE master rendered-master-c9a52144456dbff9c9af9c5a37d1b614 True False False 3 3 3 0 36d mcp-1 rendered-mcp-1-07fe50b9ad51fae43ed212e84e1dcc8e False False False 1 0 0 0 47h mcp-2 rendered-mcp-2-07fe50b9ad51fae43ed212e84e1dcc8e False False False 1 0 0 0 47h worker rendered-worker-f1ab7b9a768e1b0ac9290a18817f60f0 True False False 0 0 0 0 36d참고한 번에 얼마나 많은
MCP그룹을 업그레이드할지 결정합니다. 이는 한 번에 얼마나 많은 CNF 포드를 제거할 수 있는지, 그리고 포드 중단 예산과 안티-어피니티 설정이 어떻게 구성되어 있는지에 따라 달라집니다.클러스터의 노드 목록을 가져옵니다.
$ oc get nodes출력 예
NAME STATUS ROLES AGE VERSION ctrl-plane-0 Ready control-plane,master 5d8h v1.29.8+f10c92d ctrl-plane-1 Ready control-plane,master 5d8h v1.29.8+f10c92d ctrl-plane-2 Ready control-plane,master 5d8h v1.29.8+f10c92d worker-0 Ready mcp-1,worker 5d8h v1.27.15+6147456 worker-1 Ready mcp-2,worker 5d8h v1.27.15+6147456일시 중지된
MachineConfigPool그룹을 확인하세요.$ oc get mcp -o json | jq -r '["MCP","Paused"], ["---","------"], (.items[] | [(.metadata.name), (.spec.paused)]) | @tsv' | grep -v worker출력 예
MCP Paused --- ------ master false mcp-1 true mcp-2 true참고각
MachineConfigPool은독립적으로 일시 중지를 해제할 수 있습니다. 따라서 유지 관리 기간이 끝나더라도 다른 MCP의 일시 중지를 즉시 해제할 필요는 없습니다. 클러스터는 일부 작업자 노드가 여전히 <y-2>-릴리스 버전인 상태에서 실행되도록 지원됩니다.업그레이드를 시작하려면 필요한
mcp그룹의 일시 중지를 해제하세요.$ oc patch mcp/mcp-1 --type merge --patch '{"spec":{"paused":false}}'출력 예
machineconfigpool.machineconfiguration.openshift.io/mcp-1 patched필수
mcp그룹이 일시 중지 해제되었는지 확인하세요.$ oc get mcp -o json | jq -r '["MCP","Paused"], ["---","------"], (.items[] | [(.metadata.name), (.spec.paused)]) | @tsv' | grep -v worker출력 예
MCP Paused --- ------ master false mcp-1 false mcp-2 true각
mcp그룹이 업그레이드되면 일시 중지를 계속 해제하고 나머지 노드를 업그레이드합니다.$ oc get nodes출력 예
NAME STATUS ROLES AGE VERSION ctrl-plane-0 Ready control-plane,master 5d8h v1.29.8+f10c92d ctrl-plane-1 Ready control-plane,master 5d8h v1.29.8+f10c92d ctrl-plane-2 Ready control-plane,master 5d8h v1.29.8+f10c92d worker-0 Ready mcp-1,worker 5d8h v1.29.8+f10c92d worker-1 NotReady,SchedulingDisabled mcp-2,worker 5d8h v1.27.15+6147456
17.2.8.3. 새로 업데이트된 클러스터의 상태 확인
클러스터를 업데이트한 후 다음 명령을 실행하여 클러스터가 다시 백업되고 실행 중인지 확인하세요.
프로세스
다음 명령을 실행하여 클러스터 버전을 확인하세요.
$ oc get clusterversion출력 예
NAME VERSION AVAILABLE PROGRESSING SINCE STATUS version 4.16.14 True False 4h38m Cluster version is 4.16.14이렇게 하면 새로운 클러스터 버전이 반환되고
PROGRESSING열은False를반환해야 합니다.모든 노드가 준비되었는지 확인하세요.
$ oc get nodes출력 예
NAME STATUS ROLES AGE VERSION ctrl-plane-0 Ready control-plane,master 5d9h v1.29.8+f10c92d ctrl-plane-1 Ready control-plane,master 5d9h v1.29.8+f10c92d ctrl-plane-2 Ready control-plane,master 5d9h v1.29.8+f10c92d worker-0 Ready mcp-1,worker 5d9h v1.29.8+f10c92d worker-1 Ready mcp-2,worker 5d9h v1.29.8+f10c92d클러스터의 모든 노드는
준비상태여야 하며 동일한 버전을 실행해야 합니다.클러스터에 일시 중지된
mcp리소스가 없는지 확인합니다.$ oc get mcp -o json | jq -r '["MCP","Paused"], ["---","------"], (.items[] | [(.metadata.name), (.spec.paused)]) | @tsv' | grep -v worker출력 예
MCP Paused --- ------ master false mcp-1 false mcp-2 false모든 클러스터 운영자가 사용 가능한지 확인하세요.
$ oc get co출력 예
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE authentication 4.16.14 True False False 5d9h baremetal 4.16.14 True False False 5d9h cloud-controller-manager 4.16.14 True False False 5d10h cloud-credential 4.16.14 True False False 5d10h cluster-autoscaler 4.16.14 True False False 5d9h config-operator 4.16.14 True False False 5d9h console 4.16.14 True False False 5d9h control-plane-machine-set 4.16.14 True False False 5d9h csi-snapshot-controller 4.16.14 True False False 5d9h dns 4.16.14 True False False 5d9h etcd 4.16.14 True False False 5d9h image-registry 4.16.14 True False False 85m ingress 4.16.14 True False False 5d9h insights 4.16.14 True False False 5d9h kube-apiserver 4.16.14 True False False 5d9h kube-controller-manager 4.16.14 True False False 5d9h kube-scheduler 4.16.14 True False False 5d9h kube-storage-version-migrator 4.16.14 True False False 4h48m machine-api 4.16.14 True False False 5d9h machine-approver 4.16.14 True False False 5d9h machine-config 4.16.14 True False False 5d9h marketplace 4.16.14 True False False 5d9h monitoring 4.16.14 True False False 5d9h network 4.16.14 True False False 5d9h node-tuning 4.16.14 True False False 5d7h openshift-apiserver 4.16.14 True False False 5d9h openshift-controller-manager 4.16.14 True False False 5d9h openshift-samples 4.16.14 True False False 5h24m operator-lifecycle-manager 4.16.14 True False False 5d9h operator-lifecycle-manager-catalog 4.16.14 True False False 5d9h operator-lifecycle-manager-packageserver 4.16.14 True False False 5d9h service-ca 4.16.14 True False False 5d9h storage 4.16.14 True False False 5d9h모든 클러스터 운영자는
AVAILABLE열에True를보고해야 합니다.모든 포드가 건강한지 확인하세요.
$ oc get po -A | grep -E -iv 'complete|running'이렇게 하면 포드가 반환되지 않습니다.
참고업데이트 후에도 몇몇 포드가 계속 움직이는 것을 볼 수 있습니다. 잠시 지켜보면서 모든 포드가 비워졌는지 확인하세요.