1.4. OpenShift 컨테이너 플랫폼 업데이트 기간 이해
OpenShift Container Platform 업데이트 기간은 배포 토폴로지에 따라 다릅니다. 이 페이지는 업데이트 기간에 영향을 미치는 요소를 이해하고 사용자 환경에서 클러스터 업데이트에 걸리는 시간을 추정하는 데 도움이 됩니다.
1.4.1. 업데이트 기간에 영향을 미치는 요소
다음 요인은 클러스터 업데이트 기간에 영향을 줄 수 있습니다.
Machine Config Operator(MCO)를 사용하여 컴퓨트 노드를 새 머신 구성으로 재부팅합니다.
머신 구성 풀의
MaxUnavailable값주의OpenShift Container Platform의 모든 머신 구성 풀에 대한
maxUnavailable의 기본 설정은1입니다. 이 값은 변경하지 말고 한 번에 하나의 제어 평면 노드만 업데이트하는 것이 좋습니다. 제어 평면 풀의 경우 이 값을3으로 변경하지 마세요.- PDB(Pod Disruption Budget)에 설정된 최소 복제본 수 또는 비율
- 클러스터의 노드 수
- 클러스터 노드의 상태
1.4.2. 클러스터 업데이트 단계
OpenShift Container Platform에서 클러스터 업데이트는 두 단계로 진행됩니다.
- 클러스터 버전 운영자(CVO) 대상 업데이트 페이로드 배포
- MCO(Machine Config Operator) 노드 업데이트
1.4.2.1. 클러스터 버전 운영자 대상 업데이트 페이로드 배포
클러스터 버전 운영자(CVO)는 대상 업데이트 릴리스 이미지를 검색하여 클러스터에 적용합니다. 이 단계에서는 포드로 실행되는 모든 구성 요소가 업데이트되고, 호스트 구성 요소는 MCO(Machine Config Operator)에 의해 업데이트됩니다. 이 과정은 60~120분이 걸릴 수 있습니다.
업데이트의 CVO 단계에서는 노드가 다시 시작되지 않습니다.
1.4.2.2. Machine Config Operator 노드 업데이트
MCO(Machine Config Operator)는 각 제어 평면과 컴퓨팅 노드에 새로운 머신 구성을 적용합니다. 이 과정에서 MCO는 클러스터의 각 노드에서 다음과 같은 순차적 작업을 수행합니다.
- 모든 노드를 봉쇄하고 배수합니다.
- 운영체제(OS) 업데이트
- 노드를 재부팅합니다.
- 모든 노드 차단 해제 및 노드에서 워크로드 예약
노드가 격리되면 해당 노드에 작업 부하를 예약할 수 없습니다.
이 프로세스를 완료하는 데 걸리는 시간은 노드와 인프라 구성을 포함한 여러 요인에 따라 달라집니다. 이 프로세스를 완료하는 데 노드당 5분 이상 걸릴 수 있습니다.
MCO 외에도 다음 매개변수의 영향을 고려해야 합니다.
- 제어 평면 노드 업데이트 기간은 예측 가능하며 대개 컴퓨트 노드보다 짧습니다. 제어 평면 작업 부하가 원활한 업데이트와 빠른 비우기에 맞춰 조정되기 때문입니다.
-
MCP(Machine Config Pool)에서
maxUnavailable필드를1보다 큰 값으로 설정하여 컴퓨팅 노드를 병렬로 업데이트할 수 있습니다. MCO는maxUnavailable에 지정된 노드 수를 제한하고 해당 노드를 업데이트할 수 없음으로 표시합니다. -
MCP에서
maxUnavailable을늘리면 풀을 더 빠르게 업데이트하는 데 도움이 될 수 있습니다. 그러나maxUnavailable이 너무 높게 설정되어 있고 여러 노드가 동시에 차단된 경우 복제본을 실행할 예약 가능한 노드를 찾을 수 없어 Pod 중단 예산(PDB)이 보호되는 워크로드가 배출되지 않을 수 있습니다. MCP의maxUnavailable을늘리는 경우 PDB에서 보호되는 워크로드를 비울 수 있을 만큼 충분한 예약 가능한 노드가 있는지 확인하세요. 업데이트를 시작하기 전에 모든 노드를 사용할 수 있는지 확인해야 합니다. 사용할 수 없는 노드는
maxUnavailable및 Pod 중단 예산에 영향을 미치므로 업데이트 기간에 상당한 영향을 미칠 수 있습니다.터미널에서 노드 상태를 확인하려면 다음 명령을 실행하세요.
$ oc get node출력 예
NAME STATUS ROLES AGE VERSION ip-10-0-137-31.us-east-2.compute.internal Ready,SchedulingDisabled worker 12d v1.23.5+3afdacb ip-10-0-151-208.us-east-2.compute.internal Ready master 12d v1.23.5+3afdacb ip-10-0-176-138.us-east-2.compute.internal Ready master 12d v1.23.5+3afdacb ip-10-0-183-194.us-east-2.compute.internal Ready worker 12d v1.23.5+3afdacb ip-10-0-204-102.us-east-2.compute.internal Ready master 12d v1.23.5+3afdacb ip-10-0-207-224.us-east-2.compute.internal Ready worker 12d v1.23.5+3afdacb노드 상태가
NotReady또는SchedulingDisabled인 경우 노드를 사용할 수 없으며 이는 업데이트 기간에 영향을 미칩니다.웹 콘솔의 관리자 관점에서 Compute
Nodes를 확장하여 노드 상태를 확인할 수 있습니다.
1.4.2.3. 클러스터 운영자의 업데이트 기간 예시
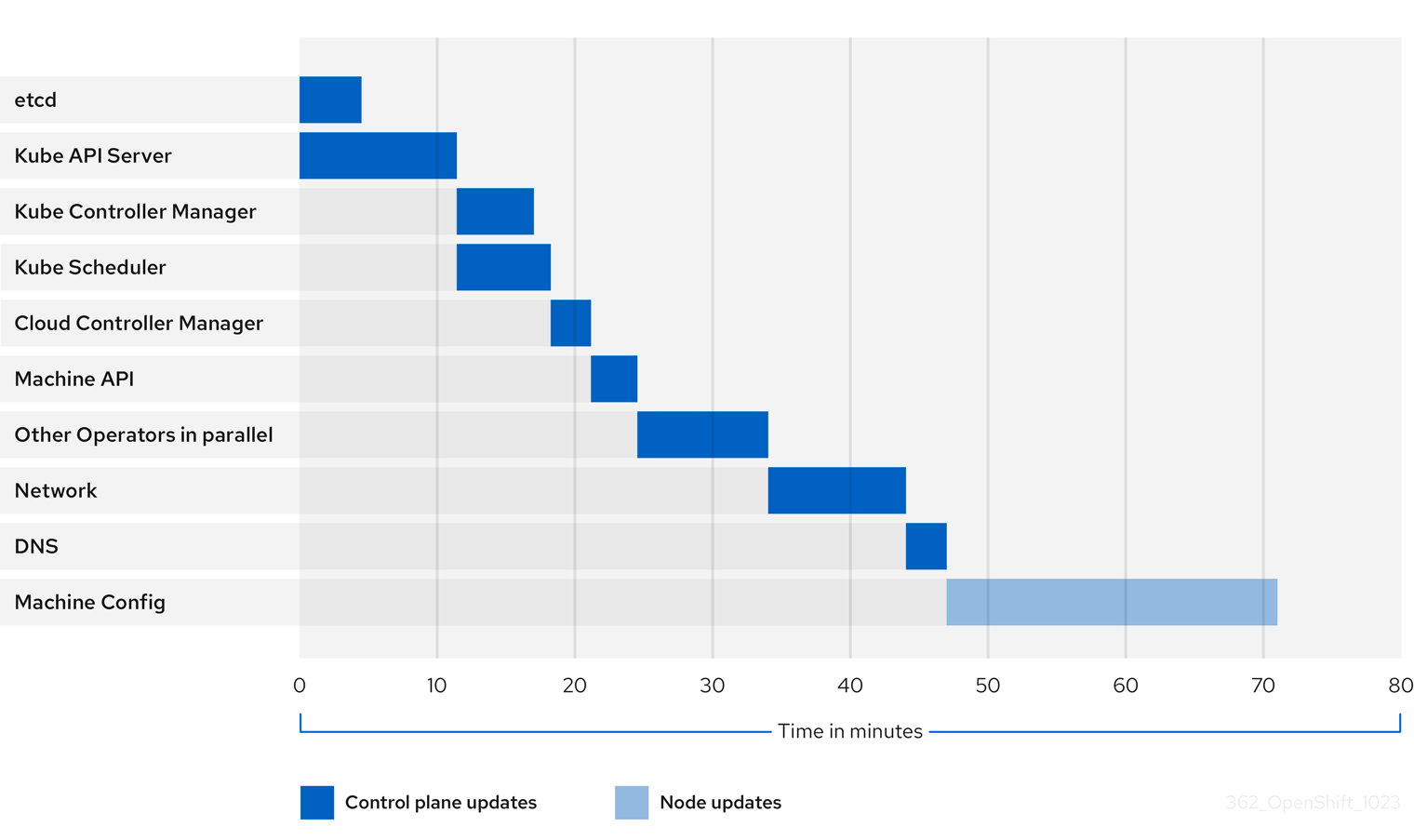
이전 다이어그램은 클러스터 운영자가 새 버전으로 업데이트하는 데 걸리는 시간의 예를 보여줍니다. 이 예제에서는 정상 컴퓨팅 MachineConfigPool 이 있고 4.13에서 4.14로 업데이트하는 데 오래 걸리는 워크로드가 없는 3-노드 AWS OVN 클러스터를 기반으로 합니다.
- 클러스터와 해당 운영자의 구체적인 업데이트 기간은 대상 버전, 노드 수, 노드에 예약된 작업 유형 등 여러 클러스터 특성에 따라 달라질 수 있습니다.
- 클러스터 버전 운영자와 같은 일부 운영자는 짧은 시간 내에 업데이트됩니다. 이러한 연산자는 다이어그램에서 생략되었거나 "병렬의 다른 연산자"로 표시된 더 광범위한 연산자 그룹에 포함됩니다.
각 클러스터 운영자는 자체 업데이트에 걸리는 시간에 영향을 미치는 특성을 가지고 있습니다. 예를 들어 kube-apiserver 가 정상 종료 지원을 제공하므로 이 예제의 Kube API Server Operator는 업데이트하는 데 11분 이상 걸렸습니다. 즉 기존의 in-flight 요청이 정상적으로 완료될 수 있습니다. 이로 인해 kube-apiserver 가 더 오랫동안 종료될 수 있습니다. 이 Operator의 경우 업데이트 속도가 희생되어 업데이트 중에 클러스터 기능이 중단되는 것을 방지하고 제한합니다.
운영자의 업데이트 기간에 영향을 미치는 또 다른 특징은 운영자가 DaemonSets를 활용하는지 여부입니다. 네트워크 및 DNS 운영자는 전체 클러스터 DaemonSets를 활용하는데, 이로 인해 버전 변경 사항을 적용하는 데 시간이 걸릴 수 있습니다. 이는 이러한 운영자가 업데이트하는 데 시간이 더 오래 걸리는 여러 이유 중 하나입니다.
일부 운영자의 업데이트 기간은 클러스터 자체의 특성에 따라 크게 달라집니다. 예를 들어, Machine Config Operator 업데이트는 클러스터의 각 노드에 머신 구성 변경 사항을 적용합니다. 노드가 많은 클러스터는 노드가 적은 클러스터에 비해 Machine Config Operator의 업데이트 기간이 더 깁니다.
각 클러스터 운영자에게는 업데이트가 가능한 단계가 지정됩니다. 동일 단계에 있는 운영자는 동시에 업데이트할 수 있으며, 특정 단계에 있는 운영자는 이전 단계가 모두 완료될 때까지 업데이트를 시작할 수 없습니다. 자세한 내용은 "추가 리소스" 섹션의 "업데이트 중에 매니페스트를 적용하는 방법 이해"를 참조하십시오.
1.4.3. 클러스터 업데이트 시간 추정
유사 클러스터의 과거 업데이트 기간은 향후 클러스터 업데이트에 대한 가장 정확한 추정치를 제공합니다. 그러나 과거 데이터를 사용할 수 없는 경우 다음 규칙을 사용하여 클러스터 업데이트 시간을 추정할 수 있습니다.
Cluster update time = CVO target update payload deployment time + (# node update iterations x MCO node update time)
노드 업데이트 반복은 하나 이상의 노드가 병렬로 업데이트되는 것으로 구성됩니다. 제어 평면 노드는 항상 컴퓨팅 노드와 병렬로 업데이트됩니다. 또한, 하나 이상의 컴퓨팅 노드를 maxUnavailable 값에 따라 병렬로 업데이트할 수 있습니다.
OpenShift Container Platform의 모든 머신 구성 풀에 대한 maxUnavailable 의 기본 설정은 1 입니다. 이 값은 변경하지 말고 한 번에 하나의 제어 평면 노드만 업데이트하는 것이 좋습니다. 제어 평면 풀의 경우 이 값을 3 으로 변경하지 마세요.
예를 들어 업데이트 시간을 추정하려면 컨트롤 플레인 노드와 컴퓨팅 노드 6개가 있는 OpenShift Container Platform 클러스터를 고려하고 각 호스트를 재부팅하는 데 약 5분이 걸립니다.
특정 노드를 재부팅하는 데 걸리는 시간은 상당히 다릅니다. 클라우드 인스턴스에서는 재부팅에 약 1~2분이 소요되지만, 물리적 베어 메탈 호스트에서는 재부팅에 15분 이상 걸릴 수 있습니다.
시나리오
컨트롤 플레인 및 컴퓨팅 노드 MCP(Machine Config Pool) 모두에 maxUnavailable 을 1 로 설정하면 각 반복에서 6개의 컴퓨팅 노드가 각각 하나씩 업데이트됩니다.
Cluster update time = 60 + (6 x 5) = 90 minutes시나리오
컴퓨팅 노드 MCP에 대해 maxUnavailable을 2 로 설정하면 두 개의 컴퓨팅 노드가 각 반복에서 병렬로 업데이트됩니다. 따라서 모든 노드를 업데이트하려면 총 3번의 반복이 필요합니다.
Cluster update time = 60 + (3 x 5) = 75 minutes
OpenShift Container Platform의 모든 MCP에 대해 maxUnavailable 의 기본 설정은 1 입니다. 제어 평면 MCP에서 maxUnavailable 을 변경하지 않는 것이 좋습니다.