Chapter 12. Troubleshooting
This section describes resources for troubleshooting the Migration Toolkit for Containers (MTC).
For known issues, see the MTC release notes.
12.1. MTC workflow
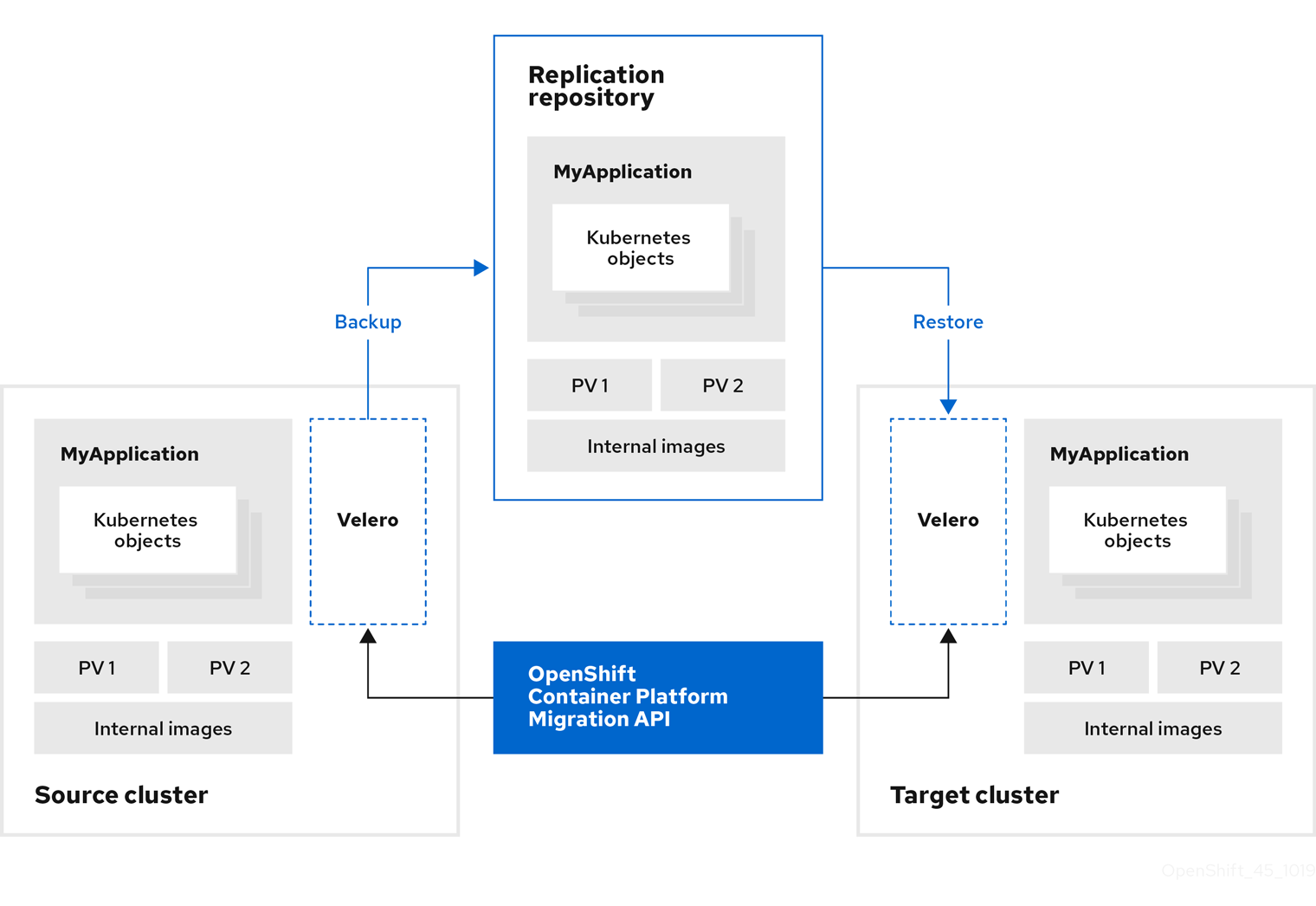
You can migrate Kubernetes resources, persistent volume data, and internal container images to OpenShift Container Platform 4.15 by using the Migration Toolkit for Containers (MTC) web console or the Kubernetes API.
MTC migrates the following resources:
- A namespace specified in a migration plan.
Namespace-scoped resources: When the MTC migrates a namespace, it migrates all the objects and resources associated with that namespace, such as services or pods. Additionally, if a resource that exists in the namespace but not at the cluster level depends on a resource that exists at the cluster level, the MTC migrates both resources.
For example, a security context constraint (SCC) is a resource that exists at the cluster level and a service account (SA) is a resource that exists at the namespace level. If an SA exists in a namespace that the MTC migrates, the MTC automatically locates any SCCs that are linked to the SA and also migrates those SCCs. Similarly, the MTC migrates persistent volumes that are linked to the persistent volume claims of the namespace.
NoteCluster-scoped resources might have to be migrated manually, depending on the resource.
- Custom resources (CRs) and custom resource definitions (CRDs): MTC automatically migrates CRs and CRDs at the namespace level.
Migrating an application with the MTC web console involves the following steps:
Install the Migration Toolkit for Containers Operator on all clusters.
You can install the Migration Toolkit for Containers Operator in a restricted environment with limited or no internet access. The source and target clusters must have network access to each other and to a mirror registry.
Configure the replication repository, an intermediate object storage that MTC uses to migrate data.
The source and target clusters must have network access to the replication repository during migration. If you are using a proxy server, you must configure it to allow network traffic between the replication repository and the clusters.
- Add the source cluster to the MTC web console.
- Add the replication repository to the MTC web console.
Create a migration plan, with one of the following data migration options:
Copy: MTC copies the data from the source cluster to the replication repository, and from the replication repository to the target cluster.
NoteIf you are using direct image migration or direct volume migration, the images or volumes are copied directly from the source cluster to the target cluster.
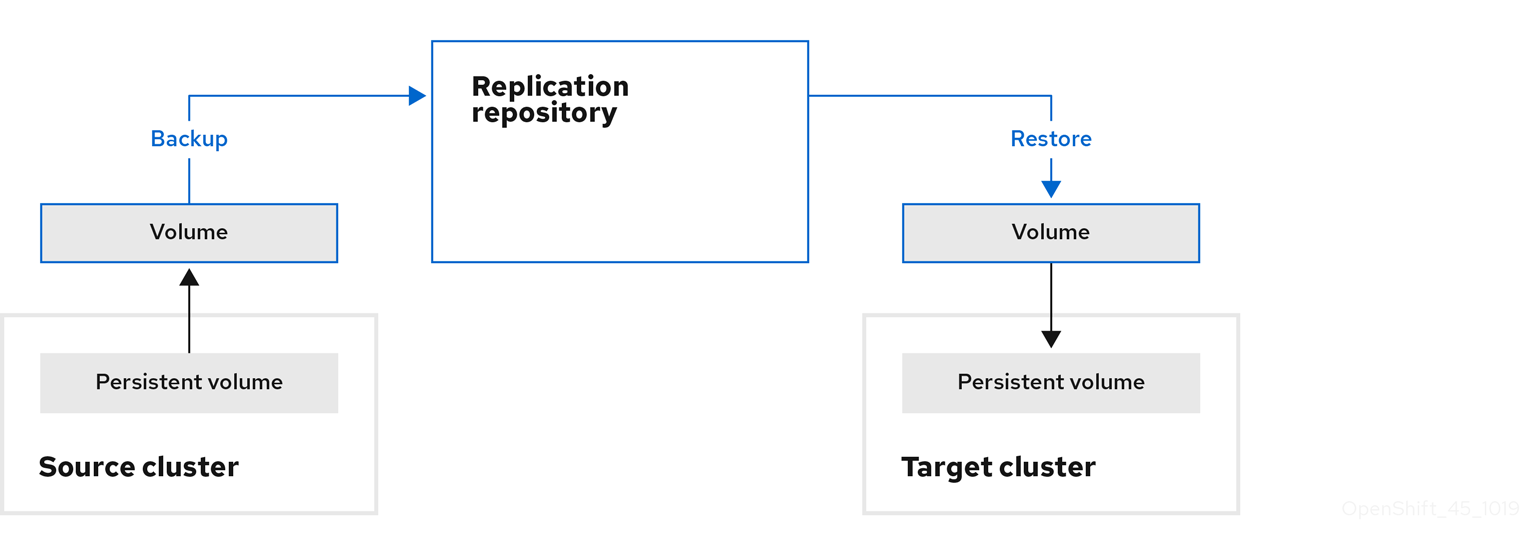
Move: MTC unmounts a remote volume, for example, NFS, from the source cluster, creates a PV resource on the target cluster pointing to the remote volume, and then mounts the remote volume on the target cluster. Applications running on the target cluster use the same remote volume that the source cluster was using. The remote volume must be accessible to the source and target clusters.
NoteAlthough the replication repository does not appear in this diagram, it is required for migration.

Run the migration plan, with one of the following options:
Stage copies data to the target cluster without stopping the application.
A stage migration can be run multiple times so that most of the data is copied to the target before migration. Running one or more stage migrations reduces the duration of the cutover migration.
Cutover stops the application on the source cluster and moves the resources to the target cluster.
Optional: You can clear the Halt transactions on the source cluster during migration checkbox.
About MTC custom resources
The Migration Toolkit for Containers (MTC) creates the following custom resources (CRs):
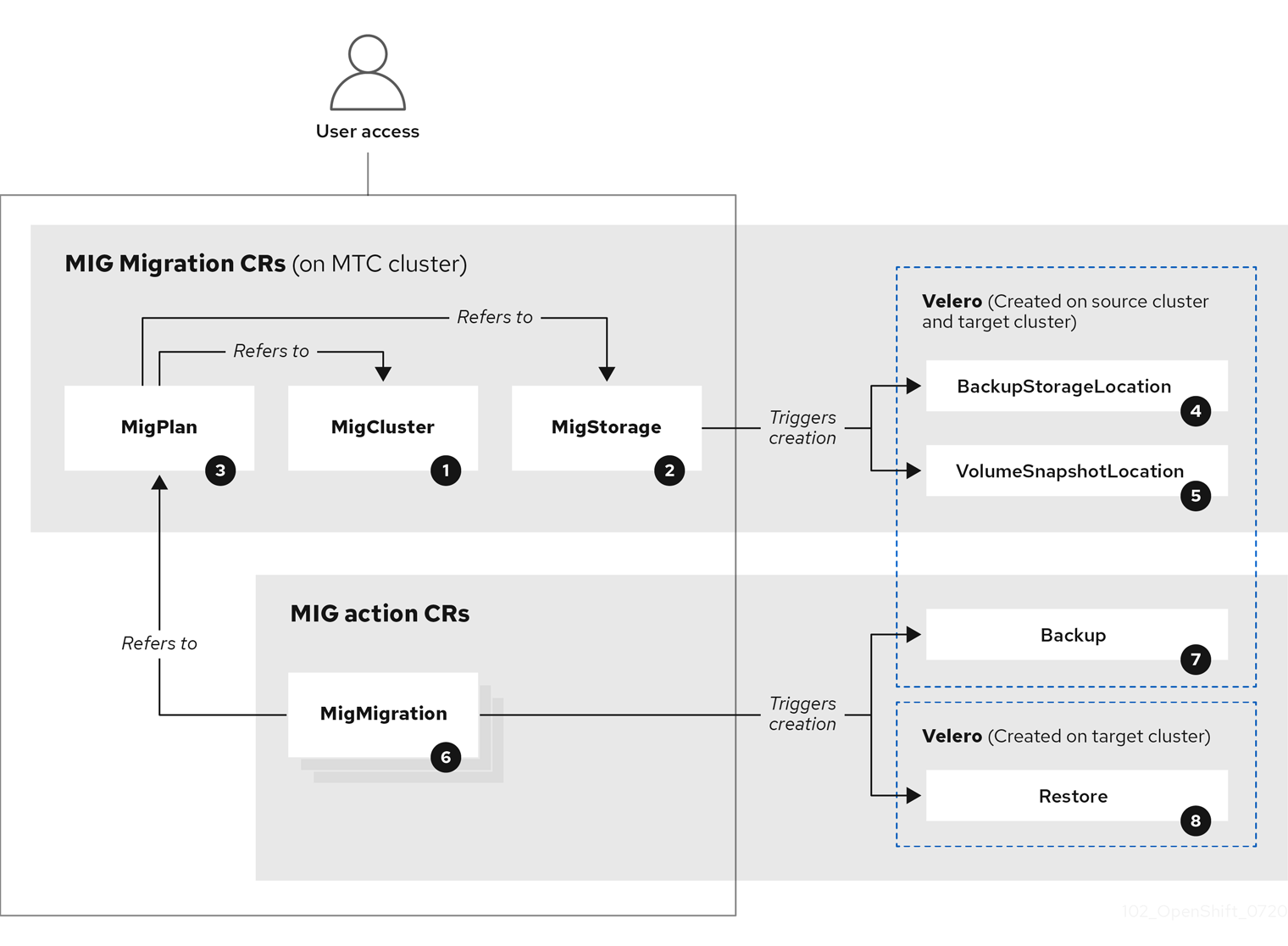
![]() MigCluster (configuration, MTC cluster): Cluster definition
MigCluster (configuration, MTC cluster): Cluster definition
![]() MigStorage (configuration, MTC cluster): Storage definition
MigStorage (configuration, MTC cluster): Storage definition
![]() MigPlan (configuration, MTC cluster): Migration plan
MigPlan (configuration, MTC cluster): Migration plan
The MigPlan CR describes the source and target clusters, replication repository, and namespaces being migrated. It is associated with 0, 1, or many MigMigration CRs.
Deleting a MigPlan CR deletes the associated MigMigration CRs.
![]() BackupStorageLocation (configuration, MTC cluster): Location of
BackupStorageLocation (configuration, MTC cluster): Location of Velero backup objects
![]() VolumeSnapshotLocation (configuration, MTC cluster): Location of
VolumeSnapshotLocation (configuration, MTC cluster): Location of Velero volume snapshots
![]() MigMigration (action, MTC cluster): Migration, created every time you stage or migrate data. Each
MigMigration (action, MTC cluster): Migration, created every time you stage or migrate data. Each MigMigration CR is associated with a MigPlan CR.
![]() Backup (action, source cluster): When you run a migration plan, the
Backup (action, source cluster): When you run a migration plan, the MigMigration CR creates two Velero backup CRs on each source cluster:
- Backup CR #1 for Kubernetes objects
- Backup CR #2 for PV data
![]() Restore (action, target cluster): When you run a migration plan, the
Restore (action, target cluster): When you run a migration plan, the MigMigration CR creates two Velero restore CRs on the target cluster:
- Restore CR #1 (using Backup CR #2) for PV data
- Restore CR #2 (using Backup CR #1) for Kubernetes objects
12.2. Migration Toolkit for Containers custom resource manifests
Migration Toolkit for Containers (MTC) uses the following custom resource (CR) manifests for migrating applications.
12.2.1. DirectImageMigration
The DirectImageMigration CR copies images directly from the source cluster to the destination cluster.
apiVersion: migration.openshift.io/v1alpha1
kind: DirectImageMigration
metadata:
labels:
controller-tools.k8s.io: "1.0"
name: <direct_image_migration>
spec:
srcMigClusterRef:
name: <source_cluster>
namespace: openshift-migration
destMigClusterRef:
name: <destination_cluster>
namespace: openshift-migration
namespaces:
- <source_namespace_1>
- <source_namespace_2>:<destination_namespace_3> 12.2.2. DirectImageStreamMigration
The DirectImageStreamMigration CR copies image stream references directly from the source cluster to the destination cluster.
apiVersion: migration.openshift.io/v1alpha1
kind: DirectImageStreamMigration
metadata:
labels:
controller-tools.k8s.io: "1.0"
name: <direct_image_stream_migration>
spec:
srcMigClusterRef:
name: <source_cluster>
namespace: openshift-migration
destMigClusterRef:
name: <destination_cluster>
namespace: openshift-migration
imageStreamRef:
name: <image_stream>
namespace: <source_image_stream_namespace>
destNamespace: <destination_image_stream_namespace>12.2.3. DirectVolumeMigration
The DirectVolumeMigration CR copies persistent volumes (PVs) directly from the source cluster to the destination cluster.
apiVersion: migration.openshift.io/v1alpha1
kind: DirectVolumeMigration
metadata:
name: <direct_volume_migration>
namespace: openshift-migration
spec:
createDestinationNamespaces: false
deleteProgressReportingCRs: false
destMigClusterRef:
name: <host_cluster>
namespace: openshift-migration
persistentVolumeClaims:
- name: <pvc>
namespace: <pvc_namespace>
srcMigClusterRef:
name: <source_cluster>
namespace: openshift-migration- 1
- Set to
trueto create namespaces for the PVs on the destination cluster. - 2
- Set to
trueto deleteDirectVolumeMigrationProgressCRs after migration. The default isfalseso thatDirectVolumeMigrationProgressCRs are retained for troubleshooting. - 3
- Update the cluster name if the destination cluster is not the host cluster.
- 4
- Specify one or more PVCs to be migrated.
12.2.4. DirectVolumeMigrationProgress
The DirectVolumeMigrationProgress CR shows the progress of the DirectVolumeMigration CR.
apiVersion: migration.openshift.io/v1alpha1
kind: DirectVolumeMigrationProgress
metadata:
labels:
controller-tools.k8s.io: "1.0"
name: <direct_volume_migration_progress>
spec:
clusterRef:
name: <source_cluster>
namespace: openshift-migration
podRef:
name: <rsync_pod>
namespace: openshift-migration12.2.5. MigAnalytic
The MigAnalytic CR collects the number of images, Kubernetes resources, and the persistent volume (PV) capacity from an associated MigPlan CR.
You can configure the data that it collects.
apiVersion: migration.openshift.io/v1alpha1
kind: MigAnalytic
metadata:
annotations:
migplan: <migplan>
name: <miganalytic>
namespace: openshift-migration
labels:
migplan: <migplan>
spec:
analyzeImageCount: true
analyzeK8SResources: true
analyzePVCapacity: true
listImages: false
listImagesLimit: 50
migPlanRef:
name: <migplan>
namespace: openshift-migration- 1
- Optional: Returns the number of images.
- 2
- Optional: Returns the number, kind, and API version of the Kubernetes resources.
- 3
- Optional: Returns the PV capacity.
- 4
- Returns a list of image names. The default is
falseso that the output is not excessively long. - 5
- Optional: Specify the maximum number of image names to return if
listImagesistrue.
12.2.6. MigCluster
The MigCluster CR defines a host, local, or remote cluster.
apiVersion: migration.openshift.io/v1alpha1
kind: MigCluster
metadata:
labels:
controller-tools.k8s.io: "1.0"
name: <host_cluster>
namespace: openshift-migration
spec:
isHostCluster: true
# The 'azureResourceGroup' parameter is relevant only for Microsoft Azure.
azureResourceGroup: <azure_resource_group>
caBundle: <ca_bundle_base64>
insecure: false
refresh: false
# The 'restartRestic' parameter is relevant for a source cluster.
restartRestic: true
# The following parameters are relevant for a remote cluster.
exposedRegistryPath: <registry_route>
url: <destination_cluster_url>
serviceAccountSecretRef:
name: <source_secret>
namespace: openshift-config- 1
- Update the cluster name if the
migration-controllerpod is not running on this cluster. - 2
- The
migration-controllerpod runs on this cluster iftrue. - 3
- Microsoft Azure only: Specify the resource group.
- 4
- Optional: If you created a certificate bundle for self-signed CA certificates and if the
insecureparameter value isfalse, specify the base64-encoded certificate bundle. - 5
- Set to
trueto disable SSL verification. - 6
- Set to
trueto validate the cluster. - 7
- Set to
trueto restart theResticpods on the source cluster after theStagepods are created. - 8
- Remote cluster and direct image migration only: Specify the exposed secure registry path.
- 9
- Remote cluster only: Specify the URL.
- 10
- Remote cluster only: Specify the name of the
Secretobject.
12.2.7. MigHook
The MigHook CR defines a migration hook that runs custom code at a specified stage of the migration. You can create up to four migration hooks. Each hook runs during a different phase of the migration.
You can configure the hook name, runtime duration, a custom image, and the cluster where the hook will run.
The migration phases and namespaces of the hooks are configured in the MigPlan CR.
apiVersion: migration.openshift.io/v1alpha1
kind: MigHook
metadata:
generateName: <hook_name_prefix>
name: <mighook>
namespace: openshift-migration
spec:
activeDeadlineSeconds: 1800
custom: false
image: <hook_image>
playbook: <ansible_playbook_base64>
targetCluster: source - 1
- Optional: A unique hash is appended to the value for this parameter so that each migration hook has a unique name. You do not need to specify the value of the
nameparameter. - 2
- Specify the migration hook name, unless you specify the value of the
generateNameparameter. - 3
- Optional: Specify the maximum number of seconds that a hook can run. The default is
1800. - 4
- The hook is a custom image if
true. The custom image can include Ansible or it can be written in a different programming language. - 5
- Specify the custom image, for example,
quay.io/konveyor/hook-runner:latest. Required ifcustomistrue. - 6
- Base64-encoded Ansible playbook. Required if
customisfalse. - 7
- Specify the cluster on which the hook will run. Valid values are
sourceordestination.
12.2.8. MigMigration
The MigMigration CR runs a MigPlan CR.
You can configure a Migmigration CR to run a stage or incremental migration, to cancel a migration in progress, or to roll back a completed migration.
apiVersion: migration.openshift.io/v1alpha1
kind: MigMigration
metadata:
labels:
controller-tools.k8s.io: "1.0"
name: <migmigration>
namespace: openshift-migration
spec:
canceled: false
rollback: false
stage: false
quiescePods: true
keepAnnotations: true
verify: false
migPlanRef:
name: <migplan>
namespace: openshift-migration- 1
- Set to
trueto cancel a migration in progress. - 2
- Set to
trueto roll back a completed migration. - 3
- Set to
trueto run a stage migration. Data is copied incrementally and the pods on the source cluster are not stopped. - 4
- Set to
trueto stop the application during migration. The pods on the source cluster are scaled to0after theBackupstage. - 5
- Set to
trueto retain the labels and annotations applied during the migration. - 6
- Set to
trueto check the status of the migrated pods on the destination cluster are checked and to return the names of pods that are not in aRunningstate.
12.2.9. MigPlan
The MigPlan CR defines the parameters of a migration plan.
You can configure destination namespaces, hook phases, and direct or indirect migration.
By default, a destination namespace has the same name as the source namespace. If you configure a different destination namespace, you must ensure that the namespaces are not duplicated on the source or the destination clusters because the UID and GID ranges are copied during migration.
apiVersion: migration.openshift.io/v1alpha1
kind: MigPlan
metadata:
labels:
controller-tools.k8s.io: "1.0"
name: <migplan>
namespace: openshift-migration
spec:
closed: false
srcMigClusterRef:
name: <source_cluster>
namespace: openshift-migration
destMigClusterRef:
name: <destination_cluster>
namespace: openshift-migration
hooks:
- executionNamespace: <namespace>
phase: <migration_phase>
reference:
name: <hook>
namespace: <hook_namespace>
serviceAccount: <service_account>
indirectImageMigration: true
indirectVolumeMigration: false
migStorageRef:
name: <migstorage>
namespace: openshift-migration
namespaces:
- <source_namespace_1>
- <source_namespace_2>
- <source_namespace_3>:<destination_namespace_4>
refresh: false - 1
- The migration has completed if
true. You cannot create anotherMigMigrationCR for thisMigPlanCR. - 2
- Optional: You can specify up to four migration hooks. Each hook must run during a different migration phase.
- 3
- Optional: Specify the namespace in which the hook will run.
- 4
- Optional: Specify the migration phase during which a hook runs. One hook can be assigned to one phase. Valid values are
PreBackup,PostBackup,PreRestore, andPostRestore. - 5
- Optional: Specify the name of the
MigHookCR. - 6
- Optional: Specify the namespace of
MigHookCR. - 7
- Optional: Specify a service account with
cluster-adminprivileges. - 8
- Direct image migration is disabled if
true. Images are copied from the source cluster to the replication repository and from the replication repository to the destination cluster. - 9
- Direct volume migration is disabled if
true. PVs are copied from the source cluster to the replication repository and from the replication repository to the destination cluster. - 10
- Specify one or more source namespaces. If you specify only the source namespace, the destination namespace is the same.
- 11
- Specify the destination namespace if it is different from the source namespace.
- 12
- The
MigPlanCR is validated iftrue.
12.2.10. MigStorage
The MigStorage CR describes the object storage for the replication repository.
Amazon Web Services (AWS), Microsoft Azure, Google Cloud Storage, Multi-Cloud Object Gateway, and generic S3-compatible cloud storage are supported.
AWS and the snapshot copy method have additional parameters.
apiVersion: migration.openshift.io/v1alpha1
kind: MigStorage
metadata:
labels:
controller-tools.k8s.io: "1.0"
name: <migstorage>
namespace: openshift-migration
spec:
backupStorageProvider: <backup_storage_provider>
volumeSnapshotProvider: <snapshot_storage_provider>
backupStorageConfig:
awsBucketName: <bucket>
awsRegion: <region>
credsSecretRef:
namespace: openshift-config
name: <storage_secret>
awsKmsKeyId: <key_id>
awsPublicUrl: <public_url>
awsSignatureVersion: <signature_version>
volumeSnapshotConfig:
awsRegion: <region>
credsSecretRef:
namespace: openshift-config
name: <storage_secret>
refresh: false - 1
- Specify the storage provider.
- 2
- Snapshot copy method only: Specify the storage provider.
- 3
- AWS only: Specify the bucket name.
- 4
- AWS only: Specify the bucket region, for example,
us-east-1. - 5
- Specify the name of the
Secretobject that you created for the storage. - 6
- AWS only: If you are using the AWS Key Management Service, specify the unique identifier of the key.
- 7
- AWS only: If you granted public access to the AWS bucket, specify the bucket URL.
- 8
- AWS only: Specify the AWS signature version for authenticating requests to the bucket, for example,
4. - 9
- Snapshot copy method only: Specify the geographical region of the clusters.
- 10
- Snapshot copy method only: Specify the name of the
Secretobject that you created for the storage. - 11
- Set to
trueto validate the cluster.
12.3. Logs and debugging tools
This section describes logs and debugging tools that you can use for troubleshooting.
12.3.1. Viewing migration plan resources
You can view migration plan resources to monitor a running migration or to troubleshoot a failed migration by using the MTC web console and the command-line interface (CLI).
Procedure
- In the MTC web console, click Migration Plans.
- Click the Migrations number next to a migration plan to view the Migrations page.
- Click a migration to view the Migration details.
Expand Migration resources to view the migration resources and their status in a tree view.
NoteTo troubleshoot a failed migration, start with a high-level resource that has failed and then work down the resource tree towards the lower-level resources.
Click the Options menu
 next to a resource and select one of the following options:
next to a resource and select one of the following options:
Copy
oc describecommand copies the command to your clipboard.Log in to the relevant cluster and then run the command.
The conditions and events of the resource are displayed in YAML format.
Copy
oc logscommand copies the command to your clipboard.Log in to the relevant cluster and then run the command.
If the resource supports log filtering, a filtered log is displayed.
View JSON displays the resource data in JSON format in a web browser.
The data is the same as the output for the
oc get <resource>command.
12.3.2. Viewing a migration plan log
You can view an aggregated log for a migration plan. You use the MTC web console to copy a command to your clipboard and then run the command from the command-line interface (CLI).
The command displays the filtered logs of the following pods:
-
Migration Controller -
Velero -
Restic -
Rsync -
Stunnel -
Registry
Procedure
- In the MTC web console, click Migration Plans.
- Click the Migrations number next to a migration plan.
- Click View logs.
-
Click the Copy icon to copy the
oc logscommand to your clipboard. Log in to the relevant cluster and enter the command on the CLI.
The aggregated log for the migration plan is displayed.
12.3.3. Using the migration log reader
You can use the migration log reader to display a single filtered view of all the migration logs.
Procedure
Get the
mig-log-readerpod:$ oc -n openshift-migration get pods | grep logEnter the following command to display a single migration log:
$ oc -n openshift-migration logs -f <mig-log-reader-pod> -c color1 - 1
- The
-c plainoption displays the log without colors.
12.3.4. Accessing performance metrics
The MigrationController custom resource (CR) records metrics and pulls them into on-cluster monitoring storage. You can query the metrics by using Prometheus Query Language (PromQL) to diagnose migration performance issues. All metrics are reset when the Migration Controller pod restarts.
You can access the performance metrics and run queries by using the OpenShift Container Platform web console.
Procedure
-
In the OpenShift Container Platform web console, click Observe
Metrics. Enter a PromQL query, select a time window to display, and click Run Queries.
If your web browser does not display all the results, use the Prometheus console.
12.3.4.1. Provided metrics
The MigrationController custom resource (CR) provides metrics for the MigMigration CR count and for its API requests.
12.3.4.1.1. cam_app_workload_migrations
This metric is a count of MigMigration CRs over time. It is useful for viewing alongside the mtc_client_request_count and mtc_client_request_elapsed metrics to collate API request information with migration status changes. This metric is included in Telemetry.
| Queryable label name | Sample label values | Label description |
|---|---|---|
| status |
|
Status of the |
| type | stage, final |
Type of the |
12.3.4.1.2. mtc_client_request_count
This metric is a cumulative count of Kubernetes API requests that MigrationController issued. It is not included in Telemetry.
| Queryable label name | Sample label values | Label description |
|---|---|---|
| cluster |
| Cluster that the request was issued against |
| component |
| Sub-controller API that issued request |
| function |
| Function that the request was issued from |
| kind |
| Kubernetes kind the request was issued for |
12.3.4.1.3. mtc_client_request_elapsed
This metric is a cumulative latency, in milliseconds, of Kubernetes API requests that MigrationController issued. It is not included in Telemetry.
| Queryable label name | Sample label values | Label description |
|---|---|---|
| cluster |
| Cluster that the request was issued against |
| component |
| Sub-controller API that issued request |
| function |
| Function that the request was issued from |
| kind |
| Kubernetes resource that the request was issued for |
12.3.4.1.4. Useful queries
The table lists some helpful queries that can be used for monitoring performance.
| Query | Description |
|---|---|
|
| Number of API requests issued, sorted by request type |
|
| Total number of API requests issued |
|
| API request latency, sorted by request type |
|
| Total latency of API requests |
|
| Average latency of API requests |
|
| Average latency of API requests, sorted by request type |
|
| Count of running migrations, multiplied by 100 for easier viewing alongside request counts |
12.3.5. Using the must-gather tool
You can collect logs, metrics, and information about MTC custom resources by using the must-gather tool.
The must-gather data must be attached to all customer cases.
You can collect data for a one-hour or a 24-hour period and view the data with the Prometheus console.
Prerequisites
-
You must be logged in to the OpenShift Container Platform cluster as a user with the
cluster-adminrole. -
You must have the OpenShift CLI (
oc) installed.
Procedure
-
Navigate to the directory where you want to store the
must-gatherdata. Run the
oc adm must-gathercommand for one of the following data collection options:To collect data for the past 24 hours, run the following command:
$ oc adm must-gather --image=registry.redhat.io/rhmtc/openshift-migration-must-gather-rhel8:v1.8This command saves the data as the
must-gather/must-gather.tar.gzfile. You can upload this file to a support case on the Red Hat Customer Portal.To collect data for the past 24 hours, run the following command:
$ oc adm must-gather --image=registry.redhat.io/rhmtc/openshift-migration-must-gather-rhel8:v1.8 -- /usr/bin/gather_metrics_dumpThis operation can take a long time. This command saves the data as the
must-gather/metrics/prom_data.tar.gzfile.
12.3.6. Debugging Velero resources with the Velero CLI tool
Debug Backup and Restore custom resources (CRs) and retrieve logs with the Velero CLI tool. The Velero CLI tool provides more detailed information than the OpenShift CLI tool.
Procedure
Use the
oc execcommand to run a Velero CLI command:$ oc -n openshift-migration exec deployment/velero -c velero -- ./velero \ <backup_restore_cr> <command> <cr_name>Example
oc execcommand$ oc -n openshift-migration exec deployment/velero -c velero -- ./velero \ backup describe 0e44ae00-5dc3-11eb-9ca8-df7e5254778b-2d8qlList all Velero CLI commands by using the following
velero --helpoption:$ oc -n openshift-migration exec deployment/velero -c velero -- ./velero \ --helpRetrieve the logs of a
BackuporRestoreCR by using the followingvelero logscommand:$ oc -n openshift-migration exec deployment/velero -c velero -- ./velero \ <backup_restore_cr> logs <cr_name>Example
velero logscommand$ oc -n openshift-migration exec deployment/velero -c velero -- ./velero \ restore logs ccc7c2d0-6017-11eb-afab-85d0007f5a19-x4lbfRetrieve a summary of warnings and errors associated with a
BackuporRestoreCR by using the followingvelero describecommand:$ oc -n openshift-migration exec deployment/velero -c velero -- ./velero \ <backup_restore_cr> describe <cr_name>Example
velero describecommand$ oc -n openshift-migration exec deployment/velero -c velero -- ./velero \ backup describe 0e44ae00-5dc3-11eb-9ca8-df7e5254778b-2d8qlThe following types of restore errors and warnings are shown in the output of a
velero describerequest:-
Velero: A list of messages related to the operation of Velero itself, for example, messages related to connecting to the cloud, reading a backup file, and so on -
Cluster: A list of messages related to backing up or restoring cluster-scoped resources Namespaces: A list of list of messages related to backing up or restoring resources stored in namespacesOne or more errors in one of these categories results in a
Restoreoperation receiving the status ofPartiallyFailedand notCompleted. Warnings do not lead to a change in the completion status.Consider the following points for these restore errors:
-
For resource-specific errors, that is,
ClusterandNamespaceserrors, therestore describe --detailsoutput includes a resource list that includes all resources that Velero restored. For any resource that has such an error, check if the resource is actually in the cluster. -
For resource-specific errors, that is,
ClusterandNamespaceserrors, therestore describe --detailsoutput includes a resource list that includes all resources that Velero restored. For any resource that has such an error, check if the resource is actually in the cluster. If there are
Veleroerrors but no resource-specific errors in the output of adescribecommand, it is possible that the restore completed without any actual problems in restoring workloads. In this case, carefully validate post-restore applications.For example, if the output contains
PodVolumeRestoreor node agent-related errors, check the status ofPodVolumeRestoresandDataDownloads. If none of these are failed or still running, then volume data might have been fully restored.
12.3.7. Debugging a partial migration failure
You can debug a partial migration failure warning message by using the Velero CLI to examine the Restore custom resource (CR) logs.
A partial failure occurs when Velero encounters an issue that does not cause a migration to fail. For example, if a custom resource definition (CRD) is missing or if there is a discrepancy between CRD versions on the source and target clusters, the migration completes but the CR is not created on the target cluster.
Velero logs the issue as a partial failure and then processes the rest of the objects in the Backup CR.
Procedure
Check the status of a
MigMigrationCR:$ oc get migmigration <migmigration> -o yamlExample output
status: conditions: - category: Warn durable: true lastTransitionTime: "2021-01-26T20:48:40Z" message: 'Final Restore openshift-migration/ccc7c2d0-6017-11eb-afab-85d0007f5a19-x4lbf: partially failed on destination cluster' status: "True" type: VeleroFinalRestorePartiallyFailed - category: Advisory durable: true lastTransitionTime: "2021-01-26T20:48:42Z" message: The migration has completed with warnings, please look at `Warn` conditions. reason: Completed status: "True" type: SucceededWithWarningsCheck the status of the
RestoreCR by using the Velerodescribecommand:$ oc -n {namespace} exec deployment/velero -c velero -- ./velero \ restore describe <restore>Example output
Phase: PartiallyFailed (run 'velero restore logs ccc7c2d0-6017-11eb-afab-85d0007f5a19-x4lbf' for more information) Errors: Velero: <none> Cluster: <none> Namespaces: migration-example: error restoring example.com/migration-example/migration-example: the server could not find the requested resourceCheck the
RestoreCR logs by using the Velerologscommand:$ oc -n {namespace} exec deployment/velero -c velero -- ./velero \ restore logs <restore>Example output
time="2021-01-26T20:48:37Z" level=info msg="Attempting to restore migration-example: migration-example" logSource="pkg/restore/restore.go:1107" restore=openshift-migration/ccc7c2d0-6017-11eb-afab-85d0007f5a19-x4lbf time="2021-01-26T20:48:37Z" level=info msg="error restoring migration-example: the server could not find the requested resource" logSource="pkg/restore/restore.go:1170" restore=openshift-migration/ccc7c2d0-6017-11eb-afab-85d0007f5a19-x4lbfThe
RestoreCR log error message,the server could not find the requested resource, indicates the cause of the partially failed migration.
12.3.8. Using MTC custom resources for troubleshooting
You can check the following Migration Toolkit for Containers (MTC) custom resources (CRs) to troubleshoot a failed migration:
-
MigCluster -
MigStorage -
MigPlan BackupStorageLocationThe
BackupStorageLocationCR contains amigrationcontrollerlabel to identify the MTC instance that created the CR:labels: migrationcontroller: ebe13bee-c803-47d0-a9e9-83f380328b93VolumeSnapshotLocationThe
VolumeSnapshotLocationCR contains amigrationcontrollerlabel to identify the MTC instance that created the CR:labels: migrationcontroller: ebe13bee-c803-47d0-a9e9-83f380328b93-
MigMigration BackupMTC changes the reclaim policy of migrated persistent volumes (PVs) to
Retainon the target cluster. TheBackupCR contains anopenshift.io/orig-reclaim-policyannotation that indicates the original reclaim policy. You can manually restore the reclaim policy of the migrated PVs.-
Restore
Procedure
List the
MigMigrationCRs in theopenshift-migrationnamespace:$ oc get migmigration -n openshift-migrationExample output
NAME AGE 88435fe0-c9f8-11e9-85e6-5d593ce65e10 6m42sInspect the
MigMigrationCR:$ oc describe migmigration 88435fe0-c9f8-11e9-85e6-5d593ce65e10 -n openshift-migrationThe output is similar to the following examples.
MigMigration example output
name: 88435fe0-c9f8-11e9-85e6-5d593ce65e10
namespace: openshift-migration
labels: <none>
annotations: touch: 3b48b543-b53e-4e44-9d34-33563f0f8147
apiVersion: migration.openshift.io/v1alpha1
kind: MigMigration
metadata:
creationTimestamp: 2019-08-29T01:01:29Z
generation: 20
resourceVersion: 88179
selfLink: /apis/migration.openshift.io/v1alpha1/namespaces/openshift-migration/migmigrations/88435fe0-c9f8-11e9-85e6-5d593ce65e10
uid: 8886de4c-c9f8-11e9-95ad-0205fe66cbb6
spec:
migPlanRef:
name: socks-shop-mig-plan
namespace: openshift-migration
quiescePods: true
stage: false
status:
conditions:
category: Advisory
durable: True
lastTransitionTime: 2019-08-29T01:03:40Z
message: The migration has completed successfully.
reason: Completed
status: True
type: Succeeded
phase: Completed
startTimestamp: 2019-08-29T01:01:29Z
events: <none>Velero backup CR #2 example output that describes the PV data
apiVersion: velero.io/v1
kind: Backup
metadata:
annotations:
openshift.io/migrate-copy-phase: final
openshift.io/migrate-quiesce-pods: "true"
openshift.io/migration-registry: 172.30.105.179:5000
openshift.io/migration-registry-dir: /socks-shop-mig-plan-registry-44dd3bd5-c9f8-11e9-95ad-0205fe66cbb6
openshift.io/orig-reclaim-policy: delete
creationTimestamp: "2019-08-29T01:03:15Z"
generateName: 88435fe0-c9f8-11e9-85e6-5d593ce65e10-
generation: 1
labels:
app.kubernetes.io/part-of: migration
migmigration: 8886de4c-c9f8-11e9-95ad-0205fe66cbb6
migration-stage-backup: 8886de4c-c9f8-11e9-95ad-0205fe66cbb6
velero.io/storage-location: myrepo-vpzq9
name: 88435fe0-c9f8-11e9-85e6-5d593ce65e10-59gb7
namespace: openshift-migration
resourceVersion: "87313"
selfLink: /apis/velero.io/v1/namespaces/openshift-migration/backups/88435fe0-c9f8-11e9-85e6-5d593ce65e10-59gb7
uid: c80dbbc0-c9f8-11e9-95ad-0205fe66cbb6
spec:
excludedNamespaces: []
excludedResources: []
hooks:
resources: []
includeClusterResources: null
includedNamespaces:
- sock-shop
includedResources:
- persistentvolumes
- persistentvolumeclaims
- namespaces
- imagestreams
- imagestreamtags
- secrets
- configmaps
- pods
labelSelector:
matchLabels:
migration-included-stage-backup: 8886de4c-c9f8-11e9-95ad-0205fe66cbb6
storageLocation: myrepo-vpzq9
ttl: 720h0m0s
volumeSnapshotLocations:
- myrepo-wv6fx
status:
completionTimestamp: "2019-08-29T01:02:36Z"
errors: 0
expiration: "2019-09-28T01:02:35Z"
phase: Completed
startTimestamp: "2019-08-29T01:02:35Z"
validationErrors: null
version: 1
volumeSnapshotsAttempted: 0
volumeSnapshotsCompleted: 0
warnings: 0Velero restore CR #2 example output that describes the Kubernetes resources
apiVersion: velero.io/v1
kind: Restore
metadata:
annotations:
openshift.io/migrate-copy-phase: final
openshift.io/migrate-quiesce-pods: "true"
openshift.io/migration-registry: 172.30.90.187:5000
openshift.io/migration-registry-dir: /socks-shop-mig-plan-registry-36f54ca7-c925-11e9-825a-06fa9fb68c88
creationTimestamp: "2019-08-28T00:09:49Z"
generateName: e13a1b60-c927-11e9-9555-d129df7f3b96-
generation: 3
labels:
app.kubernetes.io/part-of: migration
migmigration: e18252c9-c927-11e9-825a-06fa9fb68c88
migration-final-restore: e18252c9-c927-11e9-825a-06fa9fb68c88
name: e13a1b60-c927-11e9-9555-d129df7f3b96-gb8nx
namespace: openshift-migration
resourceVersion: "82329"
selfLink: /apis/velero.io/v1/namespaces/openshift-migration/restores/e13a1b60-c927-11e9-9555-d129df7f3b96-gb8nx
uid: 26983ec0-c928-11e9-825a-06fa9fb68c88
spec:
backupName: e13a1b60-c927-11e9-9555-d129df7f3b96-sz24f
excludedNamespaces: null
excludedResources:
- nodes
- events
- events.events.k8s.io
- backups.velero.io
- restores.velero.io
- resticrepositories.velero.io
includedNamespaces: null
includedResources: null
namespaceMapping: null
restorePVs: true
status:
errors: 0
failureReason: ""
phase: Completed
validationErrors: null
warnings: 1512.4. Common issues and concerns
This section describes common issues and concerns that can cause issues during migration.
12.4.1. Direct volume migration does not complete
If direct volume migration does not complete, the target cluster might not have the same node-selector annotations as the source cluster.
Migration Toolkit for Containers (MTC) migrates namespaces with all annotations to preserve security context constraints and scheduling requirements. During direct volume migration, MTC creates Rsync transfer pods on the target cluster in the namespaces that were migrated from the source cluster. If a target cluster namespace does not have the same annotations as the source cluster namespace, the Rsync transfer pods cannot be scheduled. The Rsync pods remain in a Pending state.
You can identify and fix this issue by performing the following procedure.
Procedure
Check the status of the
MigMigrationCR:$ oc describe migmigration <pod> -n openshift-migrationThe output includes the following status message:
Example output
Some or all transfer pods are not running for more than 10 mins on destination clusterOn the source cluster, obtain the details of a migrated namespace:
$ oc get namespace <namespace> -o yaml1 - 1
- Specify the migrated namespace.
On the target cluster, edit the migrated namespace:
$ oc edit namespace <namespace>Add the missing
openshift.io/node-selectorannotations to the migrated namespace as in the following example:apiVersion: v1 kind: Namespace metadata: annotations: openshift.io/node-selector: "region=east" ...- Run the migration plan again.
12.4.2. Error messages and resolutions
This section describes common error messages you might encounter with the Migration Toolkit for Containers (MTC) and how to resolve their underlying causes.
12.4.2.1. CA certificate error displayed when accessing the MTC console for the first time
If a CA certificate error message is displayed the first time you try to access the MTC console, the likely cause is the use of self-signed CA certificates in one of the clusters.
To resolve this issue, navigate to the oauth-authorization-server URL displayed in the error message and accept the certificate. To resolve this issue permanently, add the certificate to the trust store of your web browser.
If an Unauthorized message is displayed after you have accepted the certificate, navigate to the MTC console and refresh the web page.
12.4.2.2. OAuth timeout error in the MTC console
If a connection has timed out message is displayed in the MTC console after you have accepted a self-signed certificate, the causes are likely to be the following:
- Interrupted network access to the OAuth server
- Interrupted network access to the OpenShift Container Platform console
-
Proxy configuration that blocks access to the
oauth-authorization-serverURL. See MTC console inaccessible because of OAuth timeout error for details.
To determine the cause of the timeout:
- Inspect the MTC console web page with a browser web inspector.
-
Check the
Migration UIpod log for errors.
12.4.2.3. Certificate signed by unknown authority error
If you use a self-signed certificate to secure a cluster or a replication repository for the MTC, certificate verification might fail with the following error message: Certificate signed by unknown authority.
You can create a custom CA certificate bundle file and upload it in the MTC web console when you add a cluster or a replication repository.
Procedure
Download a CA certificate from a remote endpoint and save it as a CA bundle file:
$ echo -n | openssl s_client -connect <host_FQDN>:<port> \
| sed -ne '/-BEGIN CERTIFICATE-/,/-END CERTIFICATE-/p' > <ca_bundle.cert> 12.4.2.4. Backup storage location errors in the Velero pod log
If a Velero Backup custom resource contains a reference to a backup storage location (BSL) that does not exist, the Velero pod log might display the following error messages:
$ oc logs <Velero_Pod> -n openshift-migrationExample output
level=error msg="Error checking repository for stale locks" error="error getting backup storage location: BackupStorageLocation.velero.io \"ts-dpa-1\" not found" error.file="/remote-source/src/github.com/vmware-tanzu/velero/pkg/restic/repository_manager.go:259"You can ignore these error messages. A missing BSL cannot cause a migration to fail.
12.4.2.5. Pod volume backup timeout error in the Velero pod log
If a migration fails because Restic times out, the following error is displayed in the Velero pod log.
level=error msg="Error backing up item" backup=velero/monitoring error="timed out waiting for all PodVolumeBackups to complete" error.file="/go/src/github.com/heptio/velero/pkg/restic/backupper.go:165" error.function="github.com/heptio/velero/pkg/restic.(*backupper).BackupPodVolumes" group=v1
The default value of restic_timeout is one hour. You can increase this parameter for large migrations, keeping in mind that a higher value may delay the return of error messages.
Procedure
-
In the OpenShift Container Platform web console, navigate to Operators
Installed Operators. - Click Migration Toolkit for Containers Operator.
- In the MigrationController tab, click migration-controller.
In the YAML tab, update the following parameter value:
spec: restic_timeout: 1h1 - 1
- Valid units are
h(hours),m(minutes), ands(seconds), for example,3h30m15s.
- Click Save.
12.4.2.6. Restic verification errors in the MigMigration custom resource
If data verification fails when migrating a persistent volume with the file system data copy method, the following error is displayed in the MigMigration CR.
Example output
status:
conditions:
- category: Warn
durable: true
lastTransitionTime: 2020-04-16T20:35:16Z
message: There were verify errors found in 1 Restic volume restores. See restore `<registry-example-migration-rvwcm>`
for details
status: "True"
type: ResticVerifyErrors A data verification error does not cause the migration process to fail.
You can check the Restore CR to identify the source of the data verification error.
Procedure
- Log in to the target cluster.
View the
RestoreCR:$ oc describe <registry-example-migration-rvwcm> -n openshift-migrationThe output identifies the persistent volume with
PodVolumeRestoreerrors.Example output
status: phase: Completed podVolumeRestoreErrors: - kind: PodVolumeRestore name: <registry-example-migration-rvwcm-98t49> namespace: openshift-migration podVolumeRestoreResticErrors: - kind: PodVolumeRestore name: <registry-example-migration-rvwcm-98t49> namespace: openshift-migrationView the
PodVolumeRestoreCR:$ oc describe <migration-example-rvwcm-98t49>The output identifies the
Resticpod that logged the errors.Example output
completionTimestamp: 2020-05-01T20:49:12Z errors: 1 resticErrors: 1 ... resticPod: <restic-nr2v5>View the
Resticpod log to locate the errors:$ oc logs -f <restic-nr2v5>
12.4.2.7. Restic permission error when migrating from NFS storage with root_squash enabled
If you are migrating data from NFS storage and root_squash is enabled, Restic maps to nfsnobody and does not have permission to perform the migration. The following error is displayed in the Restic pod log.
Example output
backup=openshift-migration/<backup_id> controller=pod-volume-backup error="fork/exec /usr/bin/restic: permission denied" error.file="/go/src/github.com/vmware-tanzu/velero/pkg/controller/pod_volume_backup_controller.go:280" error.function="github.com/vmware-tanzu/velero/pkg/controller.(*podVolumeBackupController).processBackup" logSource="pkg/controller/pod_volume_backup_controller.go:280" name=<backup_id> namespace=openshift-migration
You can resolve this issue by creating a supplemental group for Restic and adding the group ID to the MigrationController CR manifest.
Procedure
- Create a supplemental group for Restic on the NFS storage.
-
Set the
setgidbit on the NFS directories so that group ownership is inherited. Add the
restic_supplemental_groupsparameter to theMigrationControllerCR manifest on the source and target clusters:spec: restic_supplemental_groups: <group_id>1 - 1
- Specify the supplemental group ID.
-
Wait for the
Resticpods to restart so that the changes are applied.
12.4.3. Applying the Skip SELinux relabel workaround with spc_t automatically on workloads running on OpenShift Container Platform
When attempting to migrate a namespace with Migration Toolkit for Containers (MTC) and a substantial volume associated with it, the rsync-server may become frozen without any further information to troubleshoot the issue.
12.4.3.1. Diagnosing the need for the Skip SELinux relabel workaround
Search for an error of Unable to attach or mount volumes for pod…timed out waiting for the condition in the kubelet logs from the node where the rsync-server for the Direct Volume Migration (DVM) runs.
Example kubelet log
kubenswrapper[3879]: W0326 16:30:36.749224 3879 volume_linux.go:49] Setting volume ownership for /var/lib/kubelet/pods/8905d88e-6531-4d65-9c2a-eff11dc7eb29/volumes/kubernetes.io~csi/pvc-287d1988-3fd9-4517-a0c7-22539acd31e6/mount and fsGroup set. If the volume has a lot of files then setting volume ownership could be slow, see https://github.com/kubernetes/kubernetes/issues/69699
kubenswrapper[3879]: E0326 16:32:02.706363 3879 kubelet.go:1841] "Unable to attach or mount volumes for pod; skipping pod" err="unmounted volumes=[8db9d5b032dab17d4ea9495af12e085a], unattached volumes=[crane2-rsync-server-secret 8db9d5b032dab17d4ea9495af12e085a kube-api-access-dlbd2 crane2-stunnel-server-config crane2-stunnel-server-secret crane2-rsync-server-config]: timed out waiting for the condition" pod="caboodle-preprod/rsync-server"
kubenswrapper[3879]: E0326 16:32:02.706496 3879 pod_workers.go:965] "Error syncing pod, skipping" err="unmounted volumes=[8db9d5b032dab17d4ea9495af12e085a], unattached volumes=[crane2-rsync-server-secret 8db9d5b032dab17d4ea9495af12e085a kube-api-access-dlbd2 crane2-stunnel-server-config crane2-stunnel-server-secret crane2-rsync-server-config]: timed out waiting for the condition" pod="caboodle-preprod/rsync-server" podUID=8905d88e-6531-4d65-9c2a-eff11dc7eb2912.4.3.2. Resolving using the Skip SELinux relabel workaround
To resolve this issue, set the migration_rsync_super_privileged parameter to true in both the source and destination MigClusters using the MigrationController custom resource (CR).
Example MigrationController CR
apiVersion: migration.openshift.io/v1alpha1
kind: MigrationController
metadata:
name: migration-controller
namespace: openshift-migration
spec:
migration_rsync_super_privileged: true
azure_resource_group: ""
cluster_name: host
mig_namespace_limit: "10"
mig_pod_limit: "100"
mig_pv_limit: "100"
migration_controller: true
migration_log_reader: true
migration_ui: true
migration_velero: true
olm_managed: true
restic_timeout: 1h
version: 1.8.3- 1
- The value of the
migration_rsync_super_privilegedparameter indicates whether or not to run Rsync Pods as super privileged containers (spc_t selinux context). Valid settings aretrueorfalse.
12.5. Rolling back a migration
You can roll back a migration by using the MTC web console or the CLI.
You can also roll back a migration manually.
12.5.1. Rolling back a migration by using the MTC web console
You can roll back a migration by using the Migration Toolkit for Containers (MTC) web console.
The following resources remain in the migrated namespaces for debugging after a failed direct volume migration (DVM):
- Config maps (source and destination clusters)
-
Secretobjects (source and destination clusters) -
RsyncCRs (source cluster)
These resources do not affect rollback. You can delete them manually.
If you later run the same migration plan successfully, the resources from the failed migration are deleted automatically.
If your application was stopped during a failed migration, you must roll back the migration to prevent data corruption in the persistent volume.
Rollback is not required if the application was not stopped during migration because the original application is still running on the source cluster.
Procedure
- In the MTC web console, click Migration plans.
-
Click the Options menu
beside a migration plan and select Rollback under Migration.
Click Rollback and wait for rollback to complete.
In the migration plan details, Rollback succeeded is displayed.
Verify that rollback was successful in the OpenShift Container Platform web console of the source cluster:
-
Click Home
Projects. - Click the migrated project to view its status.
- In the Routes section, click Location to verify that the application is functioning, if applicable.
-
Click Workloads
Pods to verify that the pods are running in the migrated namespace. -
Click Storage
Persistent volumes to verify that the migrated persistent volume is correctly provisioned.
-
Click Home
12.5.2. Rolling back a migration from the command-line interface
You can roll back a migration by creating a MigMigration custom resource (CR) from the command-line interface.
The following resources remain in the migrated namespaces for debugging after a failed direct volume migration (DVM):
- Config maps (source and destination clusters)
-
Secretobjects (source and destination clusters) -
RsyncCRs (source cluster)
These resources do not affect rollback. You can delete them manually.
If you later run the same migration plan successfully, the resources from the failed migration are deleted automatically.
If your application was stopped during a failed migration, you must roll back the migration to prevent data corruption in the persistent volume.
Rollback is not required if the application was not stopped during migration because the original application is still running on the source cluster.
Procedure
Create a
MigMigrationCR based on the following example:$ cat << EOF | oc apply -f - apiVersion: migration.openshift.io/v1alpha1 kind: MigMigration metadata: labels: controller-tools.k8s.io: "1.0" name: <migmigration> namespace: openshift-migration spec: ... rollback: true ... migPlanRef: name: <migplan>1 namespace: openshift-migration EOF- 1
- Specify the name of the associated
MigPlanCR.
- In the MTC web console, verify that the migrated project resources have been removed from the target cluster.
- Verify that the migrated project resources are present in the source cluster and that the application is running.
12.5.3. Rolling back a migration manually
You can roll back a failed migration manually by deleting the stage pods and unquiescing the application.
If you run the same migration plan successfully, the resources from the failed migration are deleted automatically.
The following resources remain in the migrated namespaces after a failed direct volume migration (DVM):
- Config maps (source and destination clusters)
-
Secretobjects (source and destination clusters) -
RsyncCRs (source cluster)
These resources do not affect rollback. You can delete them manually.
Procedure
Delete the
stagepods on all clusters:$ oc delete $(oc get pods -l migration.openshift.io/is-stage-pod -n <namespace>)1 - 1
- Namespaces specified in the
MigPlanCR.
Unquiesce the application on the source cluster by scaling the replicas to their premigration number:
$ oc scale deployment <deployment> --replicas=<premigration_replicas>The
migration.openshift.io/preQuiesceReplicasannotation in theDeploymentCR displays the premigration number of replicas:apiVersion: extensions/v1beta1 kind: Deployment metadata: annotations: deployment.kubernetes.io/revision: "1" migration.openshift.io/preQuiesceReplicas: "1"Verify that the application pods are running on the source cluster:
$ oc get pod -n <namespace>