17.3. Red Hat Ceph Storage Cluster の設定
以下の手順では、フォールトトレランスを確保するために Red Hat Ceph Storage クラスターを設定する方法を説明します。CRUSH バケットを作成し、Object Storage Device (OSD) ノードを実際の物理インストールを反映したデータセンターに集約します。さらに、CRUSH に対してストレージプールでデータを複製する方法を指示するルールを作成します。以下の手順は、Ceph インストールで作成されたデフォルトの CRUSH マップを更新します。
前提条件
- Red Hat Ceph Storage クラスターがすでにインストールされている。詳細は、Installing Red Hat Ceph Storage を参照してください。
- Red Hat Ceph Storage が配置グループ (PG) を使用してプール内に多数のデータオブジェクトを整理する方法、およびプールで使用する PG の数を計算する方法を理解する必要があります。詳細は、Placement Groups (PGs) を参照してください。
- プール内のオブジェクトレプリカ数の設定方法を理解している。詳細は、Set the Number of Object Replicas を参照してください。
手順
CRUSH バケットを作成し、OSD ノードを整理します。バケットは、データセンターなどの物理的な場所に基づく OSD の一覧です。Ceph では、これらの物理的な場所は 障害ドメイン と呼ばれます。
ceph osd crush add-bucket dc1 datacenter ceph osd crush add-bucket dc2 datacenterOSD ノードのホストマシンを、作成したデータセンター CRUSH バケットに移動します。ホスト名
host1-host4は、ホスト マシン名に置き換えます。ceph osd crush move host1 datacenter=dc1 ceph osd crush move host2 datacenter=dc1 ceph osd crush move host3 datacenter=dc2 ceph osd crush move host4 datacenter=dc2作成した CRUSH バケットが
デフォルトの CRUSH ツリーに含まれていることを確認します。ceph osd crush move dc1 root=default ceph osd crush move dc2 root=defaultデータセンター全体でストレージオブジェクトレプリカをマッピングするルールを作成します。これにより、データ損失を回避でき、1 つのデータセンターが停止した場合にクラスターが稼働を継続できるようになります。
ルールを作成するコマンドは、
ceph osd crush rule create-replicated <rule-name> <root> <failure-domain> <class>構文を使用します。以下に例を示します。ceph osd crush rule create-replicated multi-dc default datacenter hdd注記上記のコマンドでは、ストレージクラスターがソリッドステートドライブ (SSD) を使用する場合は、
hdd( ハードディスクドライブ ) の代わりにssdを指定します。作成したルールを使用するように、Ceph データおよびメタデータプールを設定します。最初は、これにより、CRUSH アルゴリズムによって決定されるストレージの宛先にデータがバックフィルされる可能性があります。
ceph osd pool set cephfs_data crush_rule multi-dc ceph osd pool set cephfs_metadata crush_rule multi-dcメタデータおよびデータプールの配置グループ (PG) および配置グループ (PGP) の数を指定します。PGP の値は PG の値と同じである必要があります。
ceph osd pool set cephfs_metadata pg_num 128 ceph osd pool set cephfs_metadata pgp_num 128 ceph osd pool set cephfs_data pg_num 128 ceph osd pool set cephfs_data pgp_num 128データおよびメタデータプールによって使用されるレプリカの数を指定します。
ceph osd pool set cephfs_data min_size 1 ceph osd pool set cephfs_metadata min_size 1 ceph osd pool set cephfs_data size 2 ceph osd pool set cephfs_metadata size 2
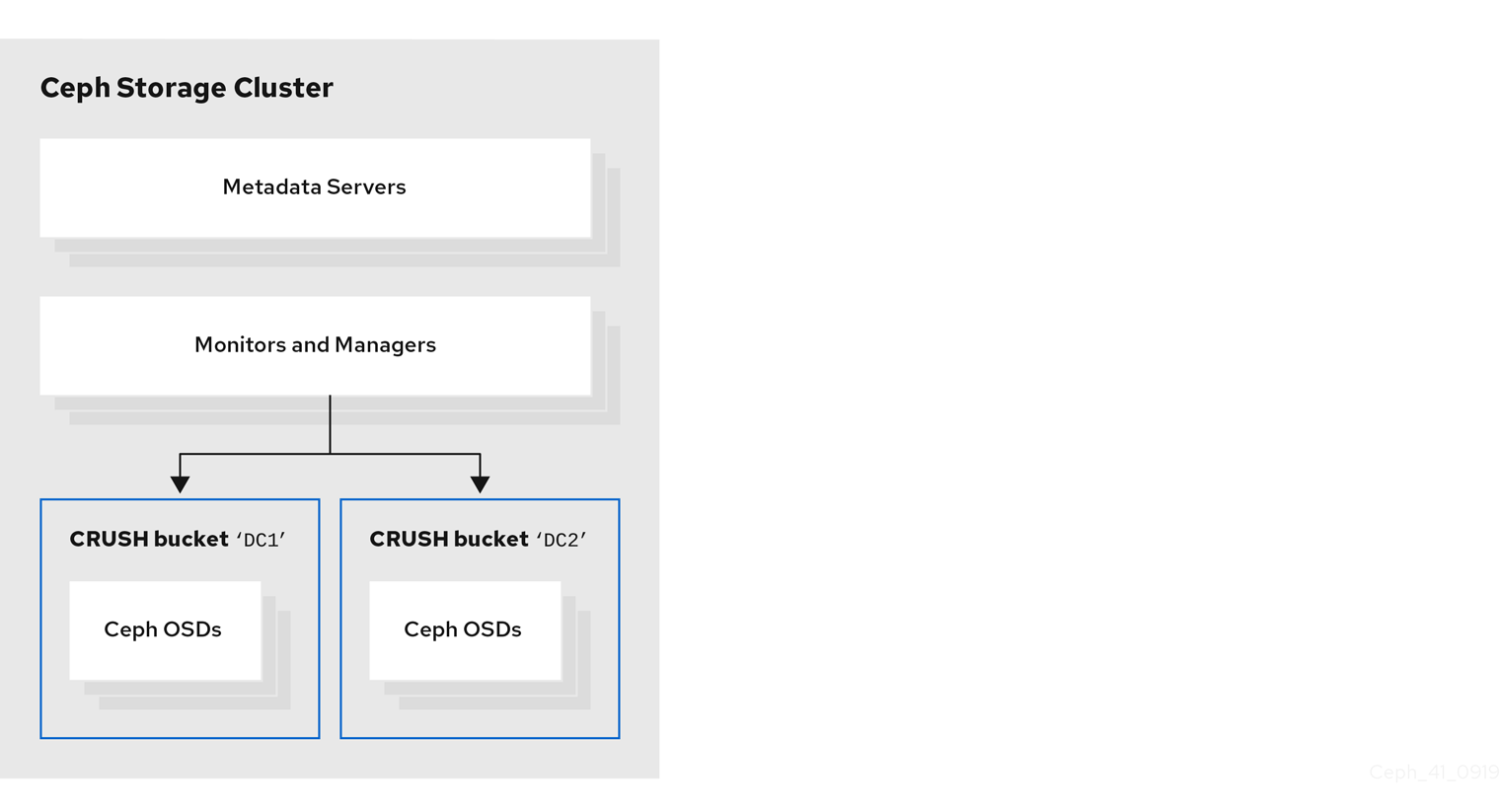
以下の図は、前述の例で作成した Red Hat Ceph Storage クラスターを示しています。ストレージクラスターには、データセンターに対応する CRUSH バケットに OSD が編成されています。
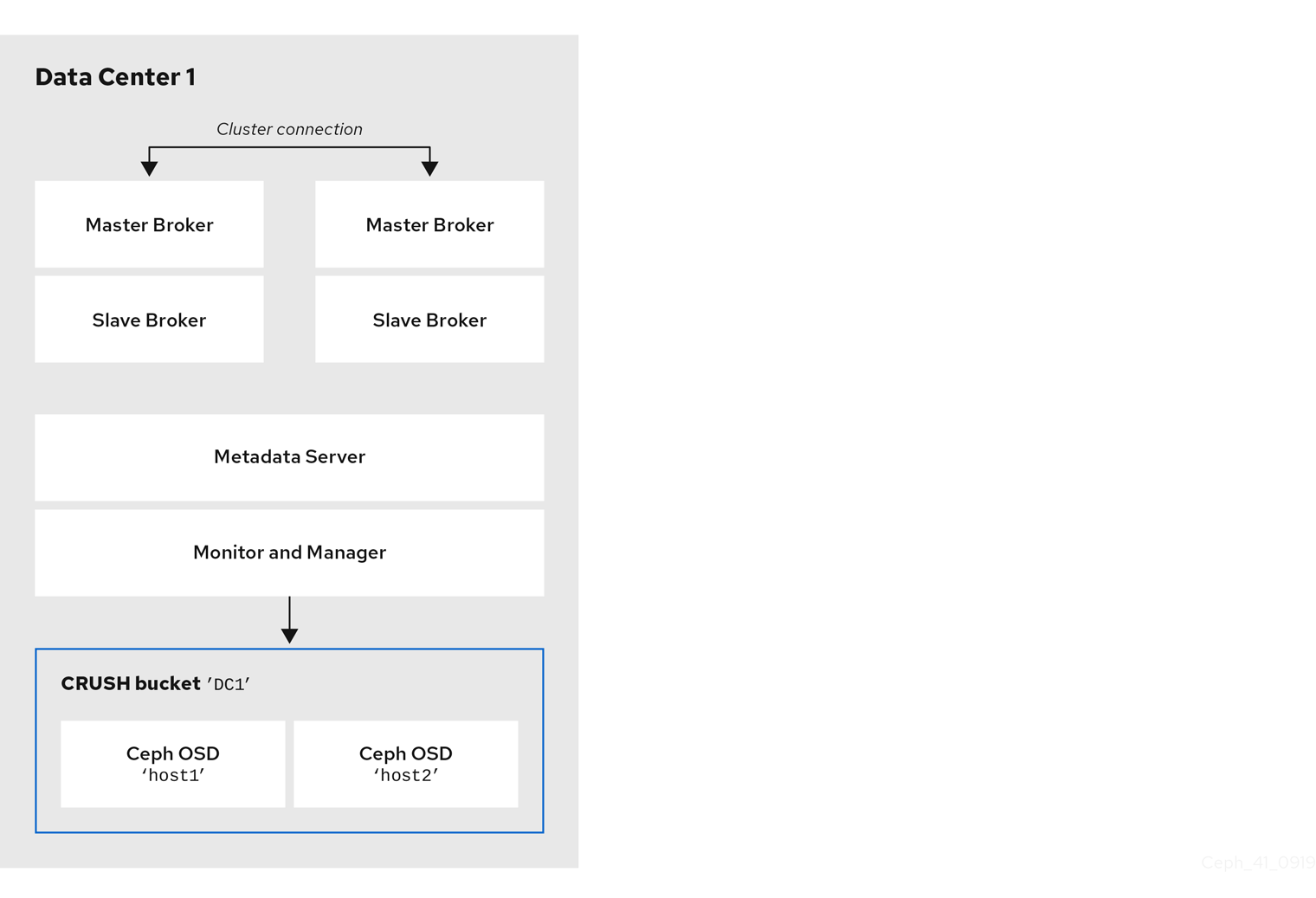
以下の図は、ブローカーサーバーを含む最初のデータセンターのレイアウトを示しています。特に、データセンターホスト。
- 2 つのライブバックアップブローカーペアのサーバー
- 前の手順で最初のデータセンターに割り当てられた OSD ノード
- 単一の Metadata Server、Monitor、および Manager ノード。Monitor ノードおよび Manager ノードは通常、同じマシンに共存します。
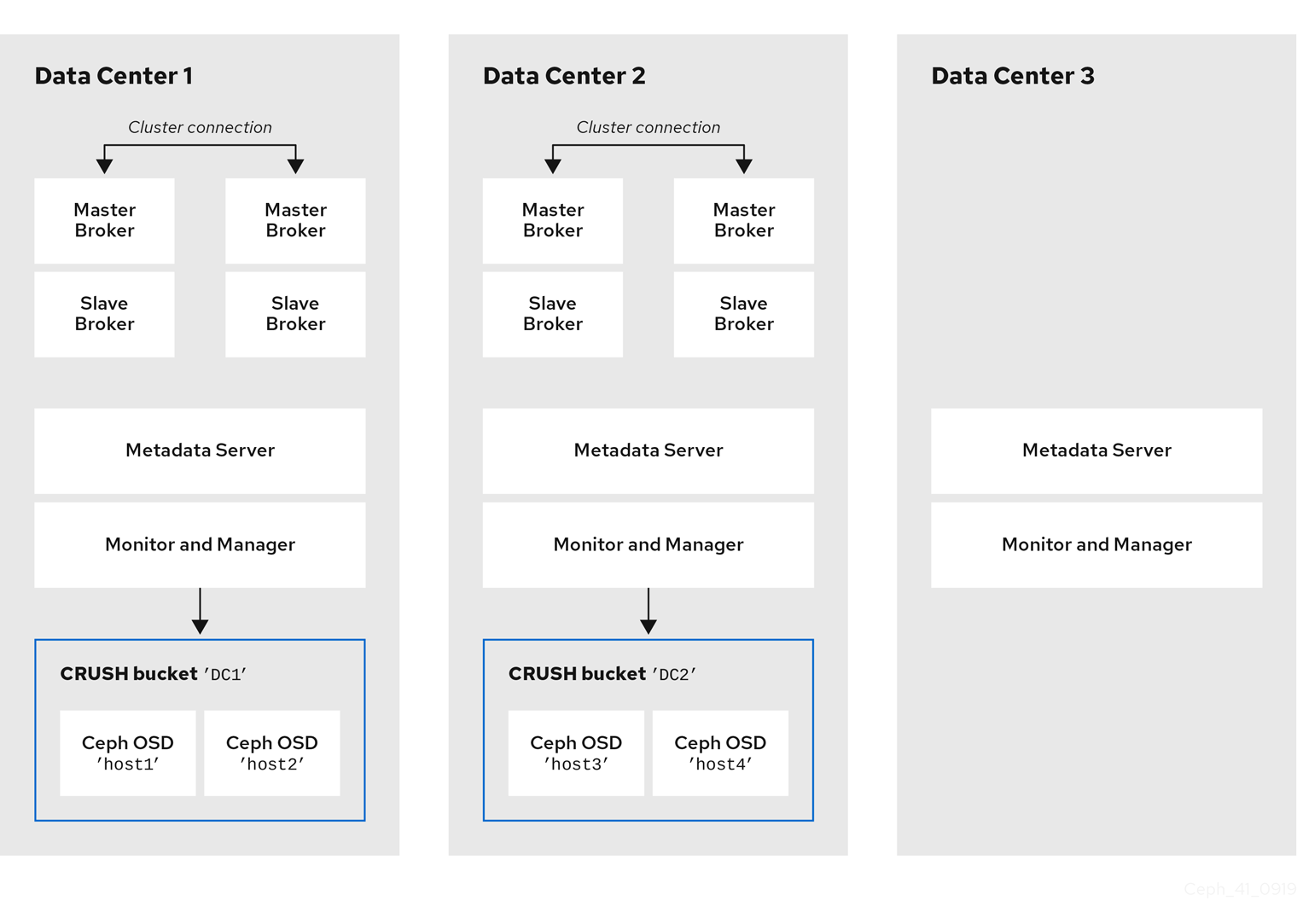
OSD、MON、MGR、および MDS ノードは、同じまたは別個の物理または仮想マシンで実行できます。ただし、Red Hat Ceph Storage クラスター内でフォールトトレランスを確保するには、これらのタイプのノードを異なるデータセンターに分散することが推奨されます。特に、1 つのデータセンターが停止した場合に、ストレージクラスターに少なくとも 2 つの MON ノードが含まれるようにする必要があります。そのため、クラスターに 3 つの MON ノードがある場合、それらの各ノードは別々のデータセンターにある別のホストマシンで実行する必要があります。
以下の図は、トポロジーの完全な例を示しています。ストレージクラスターでのフォールトトレランスを確保するために、MON、MGR、および MDS ノードは 3 つの異なるデータセンターに分散されます。
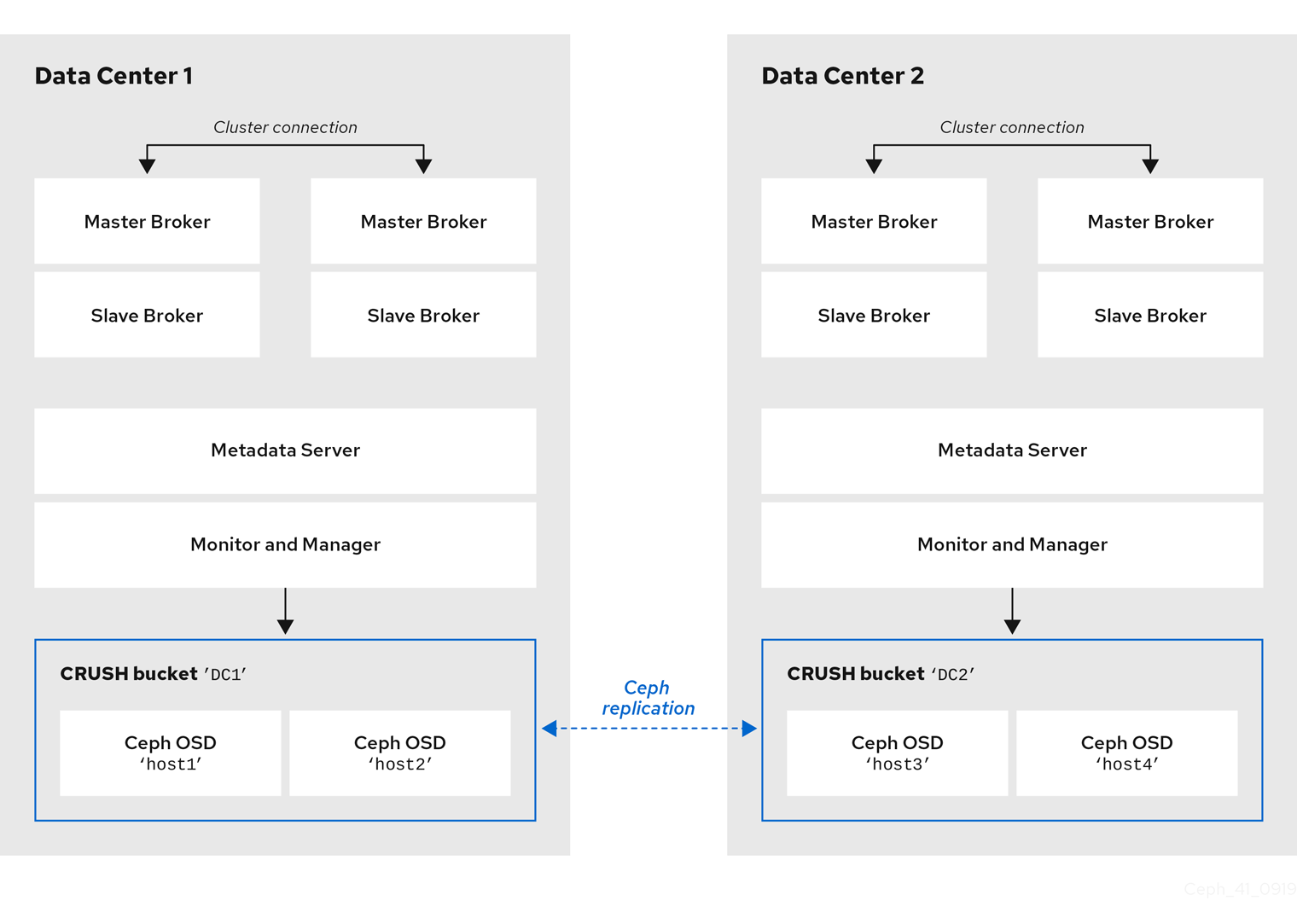
ブローカーサーバーと同じデータセンターに特定の OSD ノードのホストマシンを見つけると、メッセージングデータを特定の OSD ノードに保存するわけではありません。メッセージングデータを Ceph File System の指定されたディレクトリーに保存するようにブローカーを設定します。クラスター内の Metadata Server ノードは、保存したデータをデータセンターで利用可能なすべての OSD に配信し、データセンター全体でこのデータの複製を処理する方法を決定します。以下のセクションでは、ブローカーを設定して Ceph File System にメッセージングデータを保存する方法を紹介します。
以下の図は、ブローカーサーバーを持つ 2 つのデータセンター間のデータレプリケーションを示しています。
関連情報
詳細情報:
- Red Hat Ceph Storage クラスターの CRUSH の管理については、CRUSH Administration を参照してください。
- ストレージプールに設定できる属性の完全なセットについては、Pool Values を参照してください。