17.4. 가시성
17.4.1. 통신사 핵심 CNF 클러스터의 관찰성
OpenShift Container Platform은 플랫폼과 해당 플랫폼에서 실행되는 워크로드 모두에서 성능 지표와 로그 등 방대한 양의 데이터를 생성합니다. 관리자는 다양한 도구를 사용하여 사용 가능한 모든 데이터를 수집하고 분석할 수 있습니다. 다음은 시스템 엔지니어, 설계자 및 관리자를 위한 관찰성 스택 구성 모범 사례 개요입니다.
명시적으로 언급하지 않는 한, 이 문서의 내용은 Edge 및 Core 배포를 모두 참조합니다.
17.4.1.1. 모니터링 스택 이해
모니터링 스택은 다음 구성 요소를 사용합니다.
- Prometheus는 OpenShift Container Platform 구성 요소와 워크로드에서 메트릭을 수집하고 분석합니다(구성된 경우).
- Alertmanager는 알람의 라우팅, 그룹화, 음소거를 처리하는 Prometheus의 구성 요소입니다.
- Thanos는 메트릭의 장기 저장을 처리합니다.
그림 17.2. OpenShift 컨테이너 플랫폼 모니터링 아키텍처
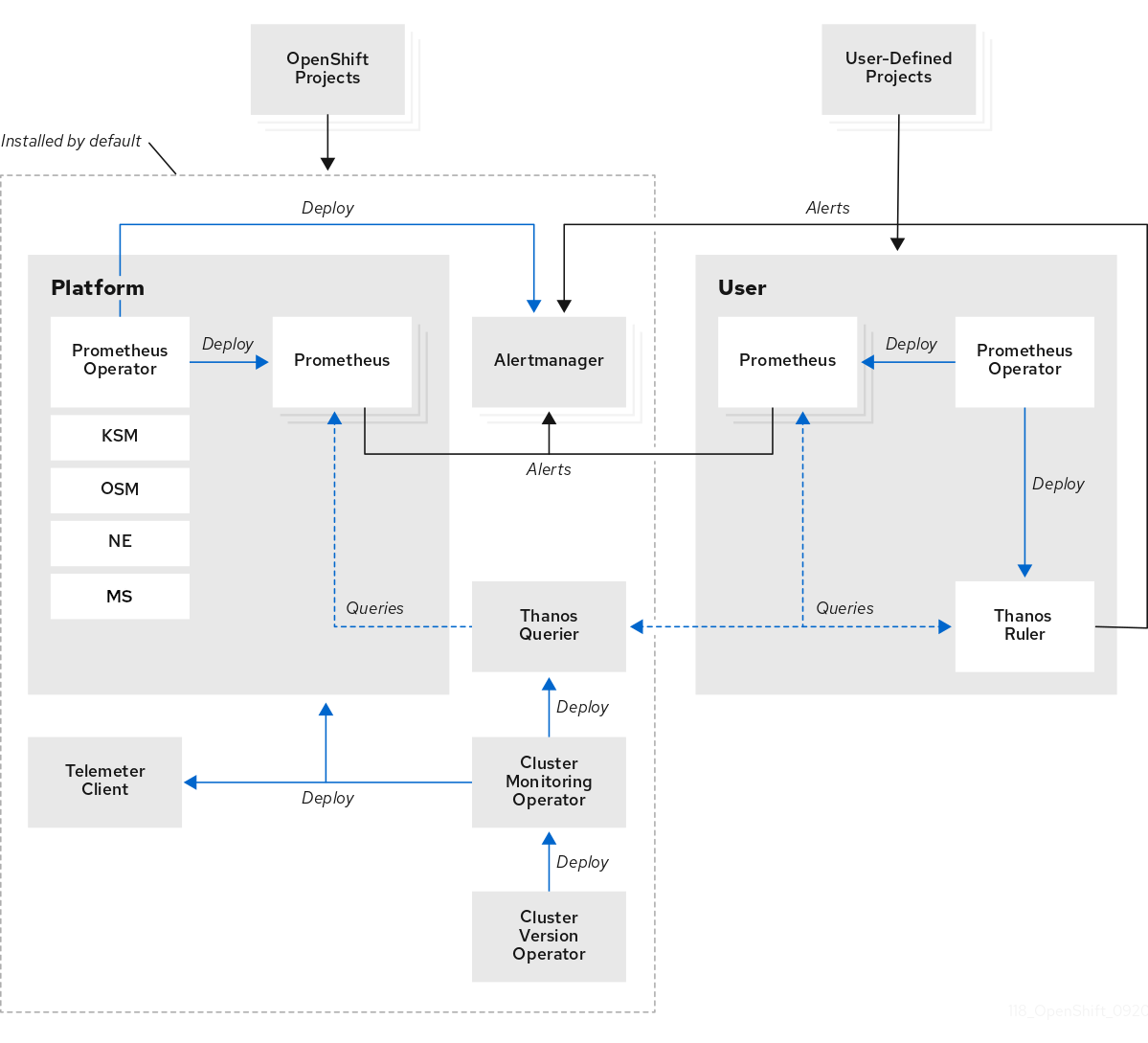
단일 노드 OpenShift 클러스터의 경우 클러스터가 분석 및 보존을 위해 모든 메트릭을 허브 클러스터로 전송하므로 Alertmanager와 Thanos를 비활성화해야 합니다.
17.4.1.2. 주요 성과 지표
시스템에 따라 사용 가능한 측정값이 수백 개일 수 있습니다.
주의해야 할 몇 가지 주요 지표는 다음과 같습니다.
-
etcd응답 시간 - API 응답 시간
- Pod 재시작 및 예약
- 리소스 사용량
- OVN 건강
- 전체 클러스터 운영자 상태
따라야 할 좋은 규칙은 특정 지표가 중요하다고 판단되면 해당 지표에 대한 알림을 제공하는 것입니다.
다음 명령을 실행하여 사용 가능한 메트릭을 확인할 수 있습니다.
oc -n openshift-monitoring exec -c prometheus prometheus-k8s-0 -- curl -qsk http://localhost:9090/api/v1/metadata | jq '.data
$ oc -n openshift-monitoring exec -c prometheus prometheus-k8s-0 -- curl -qsk http://localhost:9090/api/v1/metadata | jq '.data17.4.1.2.1. PromQL의 쿼리 예
다음 표에서는 OpenShift Container Platform 콘솔을 사용하여 메트릭 쿼리 브라우저에서 탐색할 수 있는 몇 가지 쿼리를 보여줍니다.
콘솔의 URL은 https://<OpenShift 콘솔 FQDN>/monitoring/query-browser입니다. 다음 명령을 실행하면 OpenShift 콘솔 FQDN을 얻을 수 있습니다.
oc get routes -n openshift-console console -o jsonpath='{.status.ingress[0].host}'
$ oc get routes -n openshift-console console -o jsonpath='{.status.ingress[0].host}'| 지표 | 쿼리 |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 결합된 |
|
| 지표 | 쿼리 |
|---|---|
|
|
|
|
|
|
| 지도자 선거 |
|
| 네트워크 지연 시간 |
|
| 지표 | 쿼리 |
|---|---|
| 저하된 운영자 |
|
| 클러스터당 저하된 총 연산자 |
|
17.4.1.2.2. 메트릭 저장을 위한 권장 사항
기본적으로 Prometheus는 영구 스토리지를 사용하여 저장된 지표를 백업하지 않습니다. Prometheus Pod를 다시 시작하면 모든 메트릭 데이터가 손실됩니다. 플랫폼에서 사용 가능한 백엔드 스토리지를 사용하도록 모니터링 스택을 구성해야 합니다. Prometheus의 높은 IO 요구 사항을 충족하려면 로컬 스토리지를 사용해야 합니다.
Telco 코어 클러스터의 경우 Prometheus의 영구 저장소로 Local Storage Operator를 사용할 수 있습니다.
블록, 파일, 객체 스토리지를 위한 Ceph 클러스터를 구축하는 Red Hat OpenShift Data Foundation(ODF)도 통신사 코어 클러스터에 적합한 후보입니다.
RAN 단일 노드 OpenShift 또는 Far Edge 클러스터에서 시스템 리소스 요구 사항을 낮게 유지하려면 모니터링 스택에 대한 백엔드 스토리지를 프로비저닝해서는 안 됩니다. 이러한 클러스터는 모든 측정 항목을 허브 클러스터로 전달하며, 여기서 타사 모니터링 플랫폼을 프로비저닝할 수 있습니다.
17.4.1.3. 에지 모니터링
에지의 단일 노드 OpenShift는 플랫폼 구성 요소의 설치 공간을 최소한으로 유지합니다. 다음 절차는 모니터링 공간이 작은 단일 노드 OpenShift 노드를 구성하는 방법의 예입니다.
사전 요구 사항
- Red Hat Advanced Cluster Management(RHACM)를 사용하는 환경의 경우 Observability 서비스를 활성화했습니다.
- 허브 클러스터는 Red Hat OpenShift Data Foundation(ODF)을 실행하고 있습니다.
프로세스
다음 예와 같이
ConfigMapCR을 만들고monitoringConfigMap.yaml로 저장합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 단일 노드 OpenShift에서 다음 명령을 실행하여
ConfigMapCR을 적용합니다.oc apply -f monitoringConfigMap.yaml
$ oc apply -f monitoringConfigMap.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 다음 예와 같이
NameSpaceCR을 만들고monitoringNamespace.yaml로 저장합니다.apiVersion: v1 kind: Namespace metadata: name: open-cluster-management-observability
apiVersion: v1 kind: Namespace metadata: name: open-cluster-management-observabilityCopy to Clipboard Copied! Toggle word wrap Toggle overflow 허브 클러스터에서 다음 명령을 실행하여 허브 클러스터에
네임스페이스CR을 적용합니다.oc apply -f monitoringNamespace.yaml
$ oc apply -f monitoringNamespace.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 다음 예와 같이
ObjectBucketClaimCR을 만들고monitoringObjectBucketClaim.yaml로 저장합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 허브 클러스터에서 다음 명령을 실행하여
ObjectBucketClaimCR을 적용합니다.oc apply -f monitoringObjectBucketClaim.yaml
$ oc apply -f monitoringObjectBucketClaim.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 다음 예와 같이
비밀CR을 만들고monitoringSecret.yaml로 저장합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 허브 클러스터에서 다음 명령을 실행하여
SecretCR을 적용합니다.oc apply -f monitoringSecret.yaml
$ oc apply -f monitoringSecret.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 다음 명령을 실행하여 허브 클러스터에서 NooBaa 서비스에 대한 키와 백엔드 버킷 이름을 가져옵니다.
NOOBAA_ACCESS_KEY=$(oc get secret noobaa-admin -n openshift-storage -o json | jq -r '.data.AWS_ACCESS_KEY_ID|@base64d')
$ NOOBAA_ACCESS_KEY=$(oc get secret noobaa-admin -n openshift-storage -o json | jq -r '.data.AWS_ACCESS_KEY_ID|@base64d')Copy to Clipboard Copied! Toggle word wrap Toggle overflow NOOBAA_SECRET_KEY=$(oc get secret noobaa-admin -n openshift-storage -o json | jq -r '.data.AWS_SECRET_ACCESS_KEY|@base64d')
$ NOOBAA_SECRET_KEY=$(oc get secret noobaa-admin -n openshift-storage -o json | jq -r '.data.AWS_SECRET_ACCESS_KEY|@base64d')Copy to Clipboard Copied! Toggle word wrap Toggle overflow OBJECT_BUCKET=$(oc get objectbucketclaim -n open-cluster-management-observability multi-cloud-observability -o json | jq -r .spec.bucketName)
$ OBJECT_BUCKET=$(oc get objectbucketclaim -n open-cluster-management-observability multi-cloud-observability -o json | jq -r .spec.bucketName)Copy to Clipboard Copied! Toggle word wrap Toggle overflow 다음 예와 같이 버킷 저장소에 대한
비밀CR을 만들고monitoringBucketSecret.yaml로 저장합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 허브 클러스터에서 다음 명령을 실행하여
SecretCR을 적용합니다.oc apply -f monitoringBucketSecret.yaml
$ oc apply -f monitoringBucketSecret.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 다음 예와 같이
MultiClusterObservabilityCR을 만들고monitoringMultiClusterObservability.yaml로 저장합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 허브 클러스터에서 다음 명령을 실행하여
MultiClusterObservabilityCR을 적용합니다.oc apply -f monitoringMultiClusterObservability.yaml
$ oc apply -f monitoringMultiClusterObservability.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
다음 명령을 실행하여 네임스페이스의 경로와 포드를 확인하여 서비스가 허브 클러스터에 배포되었는지 확인합니다.
oc get routes,pods -n open-cluster-management-observability
$ oc get routes,pods -n open-cluster-management-observabilityCopy to Clipboard Copied! Toggle word wrap Toggle overflow 출력 예
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 대시보드는 나열된 그래피나 경로에서 접근할 수 있습니다. 이를 사용하면 관리되는 모든 클러스터의 메트릭을 볼 수 있습니다.
Red Hat Advanced Cluster Management의 관찰성에 대한 자세한 내용은 관찰성을 참조하세요.
17.4.1.4. 경고
OpenShift Container Platform에는 많은 수의 알림 규칙이 포함되어 있으며, 이러한 알림 규칙은 릴리스마다 변경될 수 있습니다.
17.4.1.4.1. 기본 알림 보기
다음 절차에 따라 클러스터의 모든 알림 규칙을 검토하세요.
프로세스
클러스터의 모든 알림 규칙을 검토하려면 다음 명령을 실행하세요.
oc get cm -n openshift-monitoring prometheus-k8s-rulefiles-0 -o yaml
$ oc get cm -n openshift-monitoring prometheus-k8s-rulefiles-0 -o yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 규칙에는 설명을 포함하고 추가 정보 및 완화 단계에 대한 링크를 제공할 수 있습니다. 예를 들어,
etcdHighFsyncDurations에 대한 규칙은 다음과 같습니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
17.4.1.4.2. 알림 알림
OpenShift Container Platform 콘솔에서 알림을 볼 수 있지만, 관리자는 알림을 전달할 외부 수신기를 구성해야 합니다. OpenShift Container Platform은 다음과 같은 수신기 유형을 지원합니다.
- PagerDuty: 제3자 사고 대응 플랫폼
- Webhook: POST 요청을 통해 알림을 받고 필요한 모든 조치를 취할 수 있는 임의의 API 엔드포인트
- 이메일: 지정된 주소로 이메일을 보냅니다.
- Slack: Slack 채널이나 개별 사용자에게 알림을 보냅니다.
17.4.1.5. 작업 부하 모니터링
기본적으로 OpenShift Container Platform은 애플리케이션 워크로드에 대한 메트릭을 수집하지 않습니다. 워크로드 지표를 수집하도록 클러스터를 구성할 수 있습니다.
사전 요구 사항
- 클러스터에서 작업 부하 측정 항목을 수집하기 위해 엔드포인트를 정의했습니다.
프로세스
다음 예와 같이
ConfigMapCR을 만들고monitoringConfigMap.yaml로 저장합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 작업 부하 모니터링을 활성화하려면
true로 설정합니다.
다음 명령을 실행하여
ConfigMapCR을 적용합니다.oc apply -f monitoringConfigMap.yaml
$ oc apply -f monitoringConfigMap.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 다음 예와 같이
ServiceMonitorCR을 만들고monitoringServiceMonitor.yaml로 저장합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 다음 명령을 실행하여
ServiceMonitorCR을 적용합니다.oc apply -f monitoringServiceMonitor.yaml
$ oc apply -f monitoringServiceMonitor.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
Prometheus는 기본적으로 /metrics 경로를 스크래핑하지만 사용자 지정 경로를 정의할 수 있습니다. 스크래핑을 위해 이 엔드포인트를 공개하고 관련성이 있다고 생각되는 측정항목을 제공하는 것은 애플리케이션 공급업체의 몫입니다.
17.4.1.5.1. 작업 부하 알림 생성
클러스터의 사용자 워크로드에 대한 알림을 활성화할 수 있습니다.
프로세스
다음 예와 같이
ConfigMapCR을 만들고monitoringConfigMap.yaml로 저장합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 작업 부하 모니터링을 활성화하려면
true로 설정합니다.
다음 명령을 실행하여
ConfigMapCR을 적용합니다.oc apply -f monitoringConfigMap.yaml
$ oc apply -f monitoringConfigMap.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 다음 예와 같이 알림 규칙에 대한 YAML 파일인
monitoringAlertRule.yaml을 만듭니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 다음 명령을 실행하여 알림 규칙을 적용합니다.
oc apply -f monitoringAlertRule.yaml
$ oc apply -f monitoringAlertRule.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow