Questo contenuto non è disponibile nella lingua selezionata.
Chapter 5. Visualizing power monitoring metrics
Power monitoring is a Technology Preview feature only. Technology Preview features are not supported with Red Hat production service level agreements (SLAs) and might not be functionally complete. Red Hat does not recommend using them in production. These features provide early access to upcoming product features, enabling customers to test functionality and provide feedback during the development process.
For more information about the support scope of Red Hat Technology Preview features, see Technology Preview Features Support Scope.
You can visualize power monitoring metrics in the OpenShift Container Platform web console by accessing power monitoring dashboards or by exploring Metrics under the Observe tab.
5.1. Power monitoring dashboards overview
There are two types of power monitoring dashboards. Both provide different levels of details around power consumption metrics for a single cluster:
Power Monitoring / Overview dashboard
With this dashboard, you can observe the following information:
-
An aggregated view of CPU architecture and its power source (
rapl-sysfs,rapl-msr, orestimator) along with total nodes with this configuration - Total energy consumption by a cluster in the last 24 hours (measured in kilowatt-hour)
- The amount of power consumed by the top 10 namespaces in a cluster in the last 24 hours
- Detailed node information, such as its CPU architecture and component power source
These features allow you to effectively monitor the energy consumption of the cluster without needing to investigate each namespace separately.
Ensure that the Components Source column does not display estimator as the power source.
Figure 5.1. The Detailed Node Information table with rapl-sysfs as the component power source
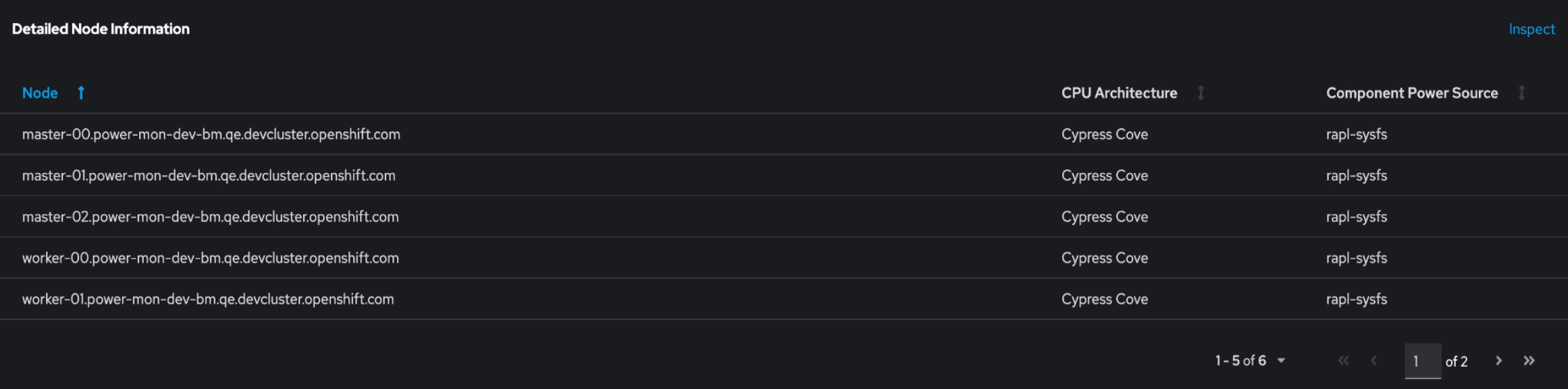
If Kepler is unable to obtain hardware power consumption metrics, the Components Source column displays estimator as the power source, which is not supported in Technology Preview. If that happens, then the values from the nodes are not accurate.
Power Monitoring / Namespace dashboard
This dashboard allows you to view metrics by namespace and pod. You can observe the following information:
- The power consumption metrics, such as consumption in DRAM and PKG
- The energy consumption metrics in the last hour, such as consumption in DRAM and PKG for core and uncore components
This feature allows you to investigate key peaks and easily identify the primary root causes of high consumption.
5.2. Accessing power monitoring dashboards as a cluster administrator
You can access power monitoring dashboards from the Administrator perspective of the OpenShift Container Platform web console.
Prerequisites
- You have access to the OpenShift Container Platform web console.
-
You are logged in as a user with the
cluster-adminrole. - You have installed the Power monitoring Operator.
- You have deployed Kepler in your cluster.
- You have enabled monitoring for user-defined projects.
Procedure
-
In the Administrator perspective of the web console, go to Observe
Dashboards. From the Dashboard drop-down list, select the power monitoring dashboard you want to see:
- Power Monitoring / Overview
- Power Monitoring / Namespace
5.3. Accessing power monitoring dashboards as a developer
You can access power monitoring dashboards from the Developer perspective of the OpenShift Container Platform web console.
Prerequisites
- You have access to the OpenShift Container Platform web console.
- You have access to the cluster as a developer or as a user.
- You have installed the Power monitoring Operator.
- You have deployed Kepler in your cluster.
- You have enabled monitoring for user-defined projects.
-
You have
viewpermissions for the namespaceopenshift-power-monitoring, the namespace where Kepler is deployed to.
Procedure
-
In the Developer perspective of the web console, go to Observe
Dashboard. From the Dashboard drop-down list, select the power monitoring dashboard you want to see:
- Power Monitoring / Overview
5.4. Power monitoring metrics overview
The Power monitoring Operator exposes the following metrics, which you can view by using the OpenShift Container Platform web console under the Observe
This list of exposed metrics is not definitive. Metrics might be added or removed in future releases.
| Metric name | Description |
|---|---|
|
| The aggregated package or socket energy consumption of CPU, DRAM, and other host components by a container. |
|
|
The total energy consumption across CPU cores used by a container. If the system has access to |
|
| The total energy consumption of DRAM by a container. |
|
| The cumulative energy consumption by uncore components used by a container. The number of components might vary depending on the system. The uncore metric is processor model-specific and might not be available on some server CPUs. |
|
| The cumulative energy consumed by the CPU socket used by a container. It includes all core and uncore components. |
|
| The cumulative energy consumption of host components, excluding CPU and DRAM, used by a container. Generally, this metric is the energy consumption of ACPI hosts. |
|
| The total CPU time used by the container that utilizes the BPF tracing. |
|
| The total CPU cycles used by the container that utilizes hardware counters. CPU cycles is a metric directly related to CPU frequency. On systems where processors run at a fixed frequency, CPU cycles and total CPU time are roughly equivalent. On systems where processors run at varying frequencies, CPU cycles and total CPU time have different values. |
|
| The total CPU instructions used by the container that utilizes hardware counters. CPU instructions is a metric that accounts how the CPU is used. |
|
| The total cache miss that occurs for a container that uses hardware counters. |
|
| The total CPU time used by a container reading from control group statistics. |
|
| The total memory in bytes used by a container reading from control group statistics. |
|
| The total CPU time in kernel space used by the container reading from control group statistics. |
|
| The total CPU time in user space used by a container reading from control group statistics. |
|
| The total number of packets transmitted to network cards of a container that uses the BPF tracing. |
|
| The total number of packets received from network cards of a container that uses the BPF tracing. |
|
| The total number of block I/O calls of a container that uses the BPF tracing. |
|
| The node metadata, such as the node CPU architecture. |
|
| The total energy consumption across CPU cores used by all containers running on a node and operating system. |
|
| The cumulative energy consumption by uncore components used by all containers running on the node and operating system. The number of components might vary depending on the system. |
|
| The total energy consumption of DRAM by all containers running on the node and operating system. |
|
| The cumulative energy consumed by the CPU socket used by all containers running on the node and operating system. It includes all core and uncore components. |
|
| The cumulative energy consumption of host components, excluding CPU and DRAM, used by all containers running on the node and operating system. Generally, this metric is the energy consumption of ACPI hosts. |
|
| The total energy consumption of the host. Generally, this metric is the host energy consumption from Redfish BMC or ACPI. |
|
| Multiple metrics from nodes labeled with container resource utilization control group metrics that are used in the model server. |
|
| The utilization of the accelerator Intel QAT on a certain node. If the system contains Intel QATs, Kepler can calculate the utilization of the node’s QATs through telemetry. |