4.5. データがコレクションにある場合のインテグレーションの動作
コネクションは、すべて同じタイプの複数の値が含まれるコレクションを返すことがあります。コネクションがコレクションを返すと、フローは以下を含む複数の方法でコレクションで操作できます。
- 各ステップを 1 度、コレクションに実行します。
- 各ステップを 1 度、コレクションの各要素に実行します。
- 一部のステップを 1 度、コレクションに実行し、他のステップを 1 度、コレクションの各要素に実行します。
フローのコレクションでの操作方法を決定するには、フローが接続するアプリケーション、それらのアプリケーションがコレクションに対応できるかどうか、およびフローが達成することを知っている必要があります。その後、以下の情報を使用して、コレクションを処理するフローにステップを追加できます。
4.5.1. データ型とコレクションについて
データマッパーはソースフィールドとターゲットフィールドを表示し、必要なフィールド間のマッピングを定義します。
データマッパーでは、フィールドは以下のいずれかになります。
-
単一の値を格納する プリミティブ タイプ。プリミティブタイプの例には、
boolean、char、byte、short、int、long、float、およびdoubleがあります。プリミティブタイプは単一のフィールドであるため拡張できません。 - 異なるタイプの複数のフィールドで設定される コンプレックス タイプ。コンプレックスタイプの子フィールドを設計時に定義します。データマッパーではコンプレックスタイプを拡張して子フィールドを表示できます。
各タイプのフィールド (プリミティブおよびコンプレックス) をコレクションとすることもできます。コレクションは、複数の値を持つことができる単一のフィールドです。コレクションのアイテム数はランタイム時に決定されます。設計時、データマッパーではコレクションは
![]() で示されます。コレクションがデータマッパーインターフェイスで拡張可能かどうかは、タイプにより決定されます。コレクションがプリミティブタイプの場合、拡張できません。コレクションがコンプレックスタイプの場合、データマッパーを展開し、コレクションの子フィールドを表示できます。各フィールドをマップ元またはマップ先とすることができます。
で示されます。コレクションがデータマッパーインターフェイスで拡張可能かどうかは、タイプにより決定されます。コレクションがプリミティブタイプの場合、拡張できません。コレクションがコンプレックスタイプの場合、データマッパーを展開し、コレクションの子フィールドを表示できます。各フィールドをマップ元またはマップ先とすることができます。
以下に例を示します。
-
idはプリミティブタイプのフィールド (int) です。実行時に、社員はIDを 1 つだけ持てます。たとえば、ID=823のみを持てます。そのため、IDはコレクションではないプリミティブタイプです。データマッパーでは、IDは拡張できません。 -
emailはプリミティブタイプのフィールド (文字列) です。実行時に、社員は複数のemailの値を持つことができます。たとえば、email<0>=aslan@home.comおよびemail<1>=aslan@business.comを持つことができます。そのため、emailはコレクションでもあるプリミティブタイプです。データマッパーは、 を使用して、
を使用して、emailフィールドがコレクションであることを示しますが、emailはプリミティブタイプであるため (子フィールドがない)、拡張できません。 -
employeeは、IDやemailを含む複数の子フィールドを持つ複雑なオブジェクトフィールドです。会社には多くの従業員がいるため、起動時にemployeeはコレクションでもあります。
設計時に、データマッパーは
を使用して employeeがコレクションであることを示します。employeeフィールドは、子フィールドが含まれるコンプレックスタイプであるため、拡張可能です。
4.5.2. コレクションの処理
フローがコレクションを処理する最も簡単な方法は、データマッパーを使用してソースコレクションにあるフィールドをターゲットコレクションにあるフィールドにマップすることです。多くのフローでは、これだけが必要になります。たとえば、フローはデータベースから社員のレコードのコレクションを取得し、それらのレコードをスプレッドシートに挿入します。データマッパーステップは、データベースコネクションと Google スプレッドシートコネクションの間でデータベースフィールドを Google スプレッドシートフィールドにマップします。ソースとターゲットはコレクションであるため、Fuse Online がフローを実行すると、Google スプレッドシートコネクションを 1 度呼び出します。この呼び出しで、Fuse Online はレコードを繰り返し処理し、スプレッドシートが適切に入力されます。
フローによっては、コレクションを個別のオブジェクトに分割する必要がある場合があります。たとえば、データベースに接続し、特定の日付までに割り当てられた休暇を取らないと休暇が失効してしまう社員のコレクションを取得する場合など考えられます。その後、フローはこれらの各社員にメール通知を送信する必要があります。このフローでは、データベースコネクションの後に分割ステップ (split step) を追加します。その後、社員のレコードのソースフィールドを、メッセージを送信する Gmail コネクションのターゲットフィールドにマップする、データマッパーステップを追加します。Fuse Online がフローを実行すると、データマッパーステップと Gmail コネクションを社員ごとに 1 度実行します。
場合によっては、フローのコレクションを分割し、フローがコレクションの各要素に一部のステップを 1 度実行した後、フローをコレクションで再度操作したいことがあります。前述の例について考えてみましょう。Gmail コネクションでメッセージを各従業員に送信した後に、通知済みの従業員一覧をスプレッドシートに追加すると仮定します。このシナリオでは、Gmail コネクションの後に、集約の手順を追加して、従業員名のコレクションを作成します。次に、ソースコレクションのフィールドをターゲット Google スプレッドシートコネクションのフィールドにマップするデータマッパーステップを追加します。Fuse Online がフローを実行すると、新しいデータマッパーステップと Google スプレッドシートコネクションをコレクションに 1 度実行します。
これが、フローのコレクションを処理する最も一般的なシナリオになります。ただし、より複雑な処理も可能です。たとえば、コレクションの要素自体がコレクションである場合、分割および集約ステップを他の分割および集約ステップ内で入れ子にすることができます。
4.5.3. データマッパーを使用したコレクションの処理
フローでは、ステップがコレクションを出力し、フローの後続のコネクションはコレクションを入力として想定する場合、データマッパーを使用してフローがどのようにコレクションを処理するかを指定できます。
ステップがコレクションを出力すると、フロービジュアライゼーションはステップの詳細で Collection を表示します。以下に例を示します。
データマッパーステップを、コレクションを提供するステップの後およびマッピングを必要とするステップの前に追加します。フローでこのデータマッパーステップが必要な場所は、フローの他のステップによって異なります。以下のイメージは、ソースコレクションフィールドからターゲットコレクションフィールドへのマッピングを示しています。
ソースおよびターゲットパネルで、データマッパーは
![]() を表示し、コレクションを示します。
を表示し、コレクションを示します。
コレクションがコンプレックスタイプの場合、データマッパにコレクションの子フィールドが表示されます。各フィールドをマップ元またはマップ先とすることができます。
ソースフィールドが複数のコレクションで入れ子になっている場合、以下の条件の 1 つを満たすターゲットフィールドにマップできます。
ターゲットフィールドは、ソースフィールドと同じ数のコレクションで入れ子になっています。たとえば、以下のマッピングが許可されます。
-
/A<>/B<>/C
/D<>/E<>/F -
/A<>/B<>/C
/G<>/H/I<>/J
-
/A<>/B<>/C
ターゲットフィールドは 1 つのコレクションでのみ入れ子になっています。たとえば、以下のマッピングが許可されます。
/A<>/B<>/C
/K<>/L この場合、データマッパーで深さ優先アルゴリズムが使用され、ソースのすべての値が反復処理されます。データマッパーによって、ソース値は発生順に単一のターゲットコレクションに配置されます。
以下のマッピングは許可されません。
/A<>/B<>/C cannot-map-to /M<>/N/O<>/P<>/Q
Fuse Online でフローが実行されると、ソースコレクション要素が繰り返し処理され、ターゲットコレクション要素が入力されます。1 つ以上のソースコレクションフィールドをターゲットコレクションまたはターゲットコレクションフィールドにマップする場合、ターゲットコレクション要素にはマップされたフィールドのみの値が含まれます。
ソースコレクションまたはソースコレクションのフィールドをコレクションではないターゲットフィールドにマップする場合、Fuse Online がフローを実行するときにソースコレクションの最後の要素のみから値を割り当てます。コレクションの他の要素は、そのマッピングステップで無視されます。しかし、後続のマッピングステップはソースコレクションのすべての要素にアクセスできます。
コネクションが JSON または Java ドキュメントに定義されたコレクションを返すと、データマッパーは通常コレクションとしてソースドキュメントを処理できます。
4.5.4. 分割ステップの追加
フローの実行中に、コネクションがオブジェクトのコレクションを返すと、Fuse Online はコレクションに後続のステップを 1 度実行します。コレクションにある各オブジェクトに後続のステップを 1 度実行する場合は、分割ステップを追加します。たとえば、Google スプレッドシートコネクションは行オブジェクトのコレクションを返します。行ごとに後続のステップを 1 度実行するには、Google スプレッドシートコネクションの後に分割ステップを追加します。
分割ステップへの入力が常にコレクションであるようにしてください。分割ステップが、コレクションタイプではないソースドキュメントを取得する場合、ステップは空白文字で入力を分割します。たとえば、Fuse Online は Hello world! の入力を Hello と world! という 2 つの要素に分割し、これらの要素をフローの次のステップに渡します。特に XML データはコレクションタイプではありません。
前提条件
- フローを作成または編集することになります。
- フローに必要なコネクションがすべて存在する必要があります。
- フロービジュアライゼーションでは、ソースデータを取得するコネクションはデータが (Collection) であると示します。
手順
-
フロービジュアライゼーションの分割ステップを追加する場所で
 をクリックします。
をクリックします。
- Split をクリックします。このステップに設定は必要ありません。
- Next をクリックします。
関連情報
通常、データマッパーステップを追加する前に、分割ステップと集約ステップを追加します。これは、データがコレクションまたは個々のオブジェクトであるかがマッピングに影響するためです。データマッパーステップを追加して分割ステップを追加する場合、通常はマッピングをやり直す必要があります。同様に、分割または集約ステップを削除する場合もマッピングをやり直す必要があります。
4.5.5. 集約ステップの追加
フローに、Fuse Online が個別のオブジェクトからコレクションを作成する、集約ステップを追加します。実行中、Fuse Online は集約ステップの後に各オブジェクトに対して後続のステップを 1 度実行せずに、コレクションに対して後続のステップを 1 度実行します。
集約ステップをフローに追加するかどうかを決定する場合は、フローのコネクションを考慮してください。分割ステップの後、Fuse Online は後続の各コネクションに対して、フローのデータの各要素のために 1 度アプリケーションに接続します。コネクションによっては、複数回接続するよりも 1 度接続した方が望ましいことがあります。
前提条件
- フローを作成または編集することになります。
- フローに必要なコネクションがすべて存在する必要があります。
- 前の手順でコレクションを個別のオブジェクトに分割している必要があります。
手順
-
フロービジュアライゼーションの、集約ステップをフローに追加する場所で
をクリックします。
- Aggregate をクリックします。このステップに設定は必要ありません。
- Next をクリックします。
関連情報
通常、データマッパーステップを追加する前に、分割および集約ステップを追加します。これは、データがコレクションまたは個々のオブジェクトであるかがマッピングに影響するためです。データマッパーステップを追加して集約ステップを追加する場合、通常はマッピングをやり直す必要があります。同様に、集約ステップを削除する場合もマッピングをやり直す必要があります。
4.5.6. フローでコレクションを処理する例
このシンプルなインテグレーションは、Fuse Online によって提供されるサンプルデータベースからタスクのコレクションを取得します。フローはコレクションを個別のタスクオブジェクトに分割し、これらのオブジェクトをフィルターして実行されたタスクを見つけます。その後、フローは完了したタスクをコレクションで集約し、そのコレクションのフィールドをスプレッドシートのフィールドにマップします。完了したタスクのリストをスプレッドシートに追加して終了します。
以下の手順は、このシンプルなインテグレーションを作成する方法を説明します。
前提条件
- Google スプレッドシートコネクションが作成済みである必要があります。
- Google スプレッドシートコネクションがアクセスするアカウントに、データベースレコードを受信するスプレッドシートがある必要があります。
手順
- Create Integration をクリックします。
最初のコネクションを追加します。
- Choose a connection ページで PostgresDB をクリックします。
- Choose an action ページで Periodic SQL Invocation を選択します。
-
SQL Statement フィールドに
select * from todoを入力し、Next をクリックします。
このコネクションは、タスクオブジェクトのコレクションを返します。
最後のコネクションを追加します。
- Choose a connection ページで、Google スプレッドシートコネクションをクリックします。
- Choose an action ページで Append values to a sheet を選択します。
- SpreadsheetId フィールドにスプレッドシートの ID を入力し、タスクの一覧を追加します。
-
Range フィールドに
A:Bを値を追加するターゲット列として入力します。最初のコラムである A はタスク ID のコラムです。次のコラムである B は、タスク名のコラムです。 - Major Dimension と Value Input Option のデフォルト値を受け入れ、Next をクリックします。
Google スプレッドシートコネクションは、コレクションの各要素をスプレッドシートに追加してフローを終了します。
フローに分割ステップを追加します。
- フロービジュアライゼーションで、プラス記号をクリックします。
- Split をクリックします。
フローが分割ステップを実行した後、結果は個別のタスクオブジェクトのセットになります。Fuse Online は、各タスクオブジェクトに対してフローの後続ステップを 1 度実行します。
フィルターステップをフローに追加します。
- フロービジュアライゼーションにて、分割ステップの後でプラスマークをクリックします。
Basic Filter をクリックし、以下のようにフィルターを設定します。
-
最初のフィールドをクリックし、評価するデータが含まれるフィールドの名前である
completedを選択します。 - 2 つ目のフィールドに、completed フィールドの値が満たさなければならない条件として equals を選択します。
-
3 番目のフィールドに、completed フィールドになければならない値として
1を指定します。1は、タスクが完了したことを示します。
-
最初のフィールドをクリックし、評価するデータが含まれるフィールドの名前である
- Next をクリックします。
実行中、フローは各タスクオブジェクトに対してフィルターステップを 1 度実行します。結果は、個別の完了したタスクオブジェクトのセットになります。
集約ステップをフローに追加します。
- フロービジュアライゼーションにて、フィルターステップの後でプラス記号をクリックします。
- Aggregate をクリックします。
結果セットには、完了したタスクごとに要素が含まれるコレクションが含まれるようになりました。
データマッパーステップをフローに追加します。
- フロービジュアライゼーションにて、集約ステップの後でプラスマークをクリックします。
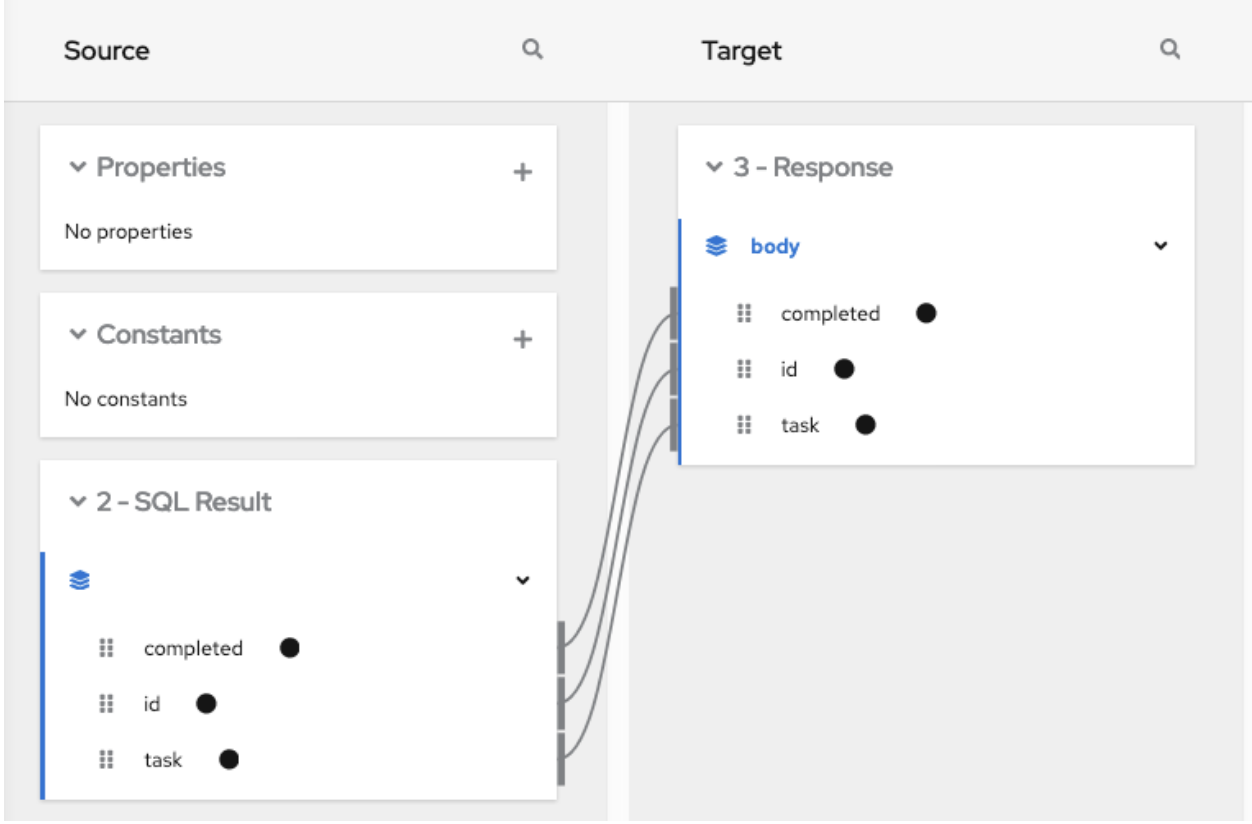
Data Mapper をクリックし、以下のフィールドを SQL 結果ソースのコレクションから Google スプレッドシートのターゲットコレクションにマップします。
- id から A
- task から B
- Done をクリックします。
- Publish をクリックします。
結果
インテグレーションの実行時に、毎分サンプルデータベースからタスクを取得し、完了したタスクをスプレッドシートの最初のシートに追加します。インテグレーションは、タスク ID を最初の列である A にマップし、タスク名を 2 番目の列である B にマップします。