5.4. 灾难恢复
5.4.1. 关于灾难恢复
灾难恢复文档为管理员提供了如何从 OpenShift Container Platform 集群可能出现的几个灾难情形中恢复的信息。作为管理员,您可能需要遵循以下一个或多个步骤将集群恢复为工作状态。
灾难恢复要求您至少有一个健康的 control plane 主机。
- 恢复到一个以前的集群状态
如果您希望将集群恢复到一个以前的状态时(例如,管理员错误地删除了一些关键信息),则可以使用这个解决方案。这包括您丢失了大多数 control plane 主机并导致 etcd 仲裁丢失,且集群离线的情况。只要您执行了 etcd 备份,就可以按照这个步骤将集群恢复到之前的状态。
如果适用,可能还需要从过期的 control plane 证书中恢复。
警告在一个正在运行的集群中恢复到以前的集群状态是破坏性的,而不稳定的操作。这仅应作为最后的手段使用。
在执行恢复前,请参阅关于恢复集群状态以了解有关对集群的影响的更多信息。
注意如果大多数 master 仍可用,且仍有 etcd 仲裁,请按照以下步骤替换一个不健康的 etcd 成员。
- 从 control plane 证书已过期的情况下恢复
- 如果 control plane 证书已经过期,则可以使用这个解决方案。例如:在第一次证书轮转前(在安装后 24 小时内)关闭了集群,您的证书将不会被轮转,且会过期。可以按照以下步骤从已过期的 control plane 证书中恢复。
5.4.2. 恢复到一个以前的集群状态
要将集群恢复到以前的状态,您必须已通过创建快照来备份 etcd 数据。您将需要使用此快照来还原集群状态。如需更多信息,请参阅"恢复 etcd 数据"。
5.4.2.1. 关于恢复集群状态
您可以使用 etcd 备份将集群恢复到以前的状态。在以下情况中可以使用这个方法进行恢复:
- 集群丢失了大多数 control plane 主机(仲裁丢失)。
- 管理员删除了一些关键内容,必须恢复才能恢复集群。
在一个正在运行的集群中恢复到以前的集群状态是破坏性的,而不稳定的操作。这仅应作为最后的手段使用。
如果您可以使用 Kubernetes API 服务器检索数据,则代表 etcd 可用,且您不应该使用 etcd 备份来恢复。
恢复 etcd 实际相当于把集群返回到以前的一个状态,所有客户端都会遇到一个有冲突的、并行历史记录。这会影响 kubelet、Kubernetes 控制器、SDN 控制器和持久性卷控制器等监视组件的行为。
当 etcd 中的内容与磁盘上的实际内容不匹配时,可能会导致 Operator churn,从而导致 Kubernetes API 服务器、Kubernetes 控制器管理器、Kubernetes 调度程序和 etcd 的 Operator 在磁盘上的文件与 etcd 中的内容冲突时卡住。这可能需要手动操作来解决问题。
在极端情况下,集群可能会丢失持久性卷跟踪,删除已不存在的关键工作负载,重新镜像机器,以及重写带有过期证书的 CA 捆绑包。
5.4.2.2. 恢复到一个以前的集群状态
您可以使用保存的 etcd 备份来恢复以前的集群状态,或恢复丢失了大多数 control plane 主机的集群。
如果您的集群使用 control plane 机器集,请参阅"为 etcd 恢复 control plane 机器集"中的"恢复降级的 etcd Operator"。
恢复集群时,必须使用同一 z-stream 发行版本中获取的 etcd 备份。例如,OpenShift Container Platform 4.7.2 集群必须使用从 4.7.2 开始的 etcd 备份。
先决条件
-
通过一个基于证书的
kubeconfig使用具有cluster-admin角色的用户访问集群,如安装期间的情况。 - 用作恢复主机的健康 control plane 主机。
- SSH 对 control plane 主机的访问。
-
包含从同一备份中获取的 etcd 快照和静态 pod 资源的备份目录。该目录中的文件名必须采用以下格式:
snapshot_<datetimestamp>.db和static_kuberesources_<datetimestamp>.tar.gz。
对于非恢复 control plane 节点,不需要建立 SSH 连接或停止静态 pod。您可以逐个删除并重新创建其他非恢复 control plane 机器。
流程
- 选择一个要用作恢复主机的 control plane 主机。这是您要在其中运行恢复操作的主机。
建立到每个 control plane 节点(包括恢复主机)的 SSH 连接。
恢复过程启动后,Kubernetes API 服务器将无法访问,因此您无法访问 control plane 节点。因此,建议在一个单独的终端中建立到每个control plane 主机的 SSH 连接。
重要如果没有完成这个步骤,将无法访问 control plane 主机来完成恢复过程,您将无法从这个状态恢复集群。
将 etcd 备份目录复制复制到恢复 control plane 主机上。
此流程假设您将
backup目录(其中包含 etcd 快照和静态 pod 资源)复制到恢复 control plane 主机的/home/core/目录中。在任何其他 control plane 节点上停止静态 pod。
注意您不需要停止恢复主机上的静态 pod。
- 访问不是恢复主机的 control plane 主机。
将现有 etcd pod 文件从 Kubelet 清单目录中移出:
$ sudo mv -v /etc/kubernetes/manifests/etcd-pod.yaml /tmp验证 etcd pod 是否已停止。
$ sudo crictl ps | grep etcd | egrep -v "operator|etcd-guard"命令输出应该为空。如果它不是空的,请等待几分钟后再重新检查。
将现有 Kubernetes API 服务器 pod 文件移出 kubelet 清单目录中:
$ sudo mv -v /etc/kubernetes/manifests/kube-apiserver-pod.yaml /tmp验证 Kubernetes API 服务器 pod 是否已停止。
$ sudo crictl ps | grep kube-apiserver | egrep -v "operator|guard"命令输出应该为空。如果它不是空的,请等待几分钟后再重新检查。
将 etcd 数据目录移到不同的位置:
$ sudo mv -v /var/lib/etcd/ /tmp如果
/etc/kubernetes/manifests/keepalived.yaml文件存在,且节点被删除,请按照以下步骤执行:将
/etc/kubernetes/manifests/keepalived.yaml文件从 kubelet 清单目录中移出:$ sudo mv -v /etc/kubernetes/manifests/keepalived.yaml /tmp容器验证由
keepalived守护进程管理的任何容器是否已停止:$ sudo crictl ps --name keepalived命令输出应该为空。如果它不是空的,请等待几分钟后再重新检查。
检查 control plane 是否已分配任何 Virtual IP (VIP):
$ ip -o address | egrep '<api_vip>|<ingress_vip>'对于每个报告的 VIP,运行以下命令将其删除:
$ sudo ip address del <reported_vip> dev <reported_vip_device>
- 在其他不是恢复主机的 control plane 主机上重复此步骤。
- 访问恢复 control plane 主机。
如果使用
keepalived守护进程,请验证恢复 control plane 节点是否拥有 VIP:$ ip -o address | grep <api_vip>如果存在 VIP 的地址(如果存在)。如果 VIP 没有设置或配置不正确,这个命令会返回一个空字符串。
如果启用了集群范围的代理,请确定已导出了
NO_PROXY、HTTP_PROXY和HTTPS_PROXY环境变量。提示您可以通过查看
oc get proxy cluster -o yaml的输出来检查代理是否已启用。如果httpProxy、httpsProxy和noProxy字段设置了值,则会启用代理。在恢复 control plane 主机上运行恢复脚本,提供到 etcd 备份目录的路径:
$ sudo -E /usr/local/bin/cluster-restore.sh /home/core/assets/backup脚本输出示例
...stopping kube-scheduler-pod.yaml ...stopping kube-controller-manager-pod.yaml ...stopping etcd-pod.yaml ...stopping kube-apiserver-pod.yaml Waiting for container etcd to stop .complete Waiting for container etcdctl to stop .............................complete Waiting for container etcd-metrics to stop complete Waiting for container kube-controller-manager to stop complete Waiting for container kube-apiserver to stop ..........................................................................................complete Waiting for container kube-scheduler to stop complete Moving etcd data-dir /var/lib/etcd/member to /var/lib/etcd-backup starting restore-etcd static pod starting kube-apiserver-pod.yaml static-pod-resources/kube-apiserver-pod-7/kube-apiserver-pod.yaml starting kube-controller-manager-pod.yaml static-pod-resources/kube-controller-manager-pod-7/kube-controller-manager-pod.yaml starting kube-scheduler-pod.yaml static-pod-resources/kube-scheduler-pod-8/kube-scheduler-pod.yaml注意如果在上次 etcd 备份后更新了节点,则恢复过程可能会导致节点进入
NotReady状态。检查节点以确保它们处于
Ready状态。运行以下命令:
$ oc get nodes -w输出示例
NAME STATUS ROLES AGE VERSION host-172-25-75-28 Ready master 3d20h v1.25.0 host-172-25-75-38 Ready infra,worker 3d20h v1.25.0 host-172-25-75-40 Ready master 3d20h v1.25.0 host-172-25-75-65 Ready master 3d20h v1.25.0 host-172-25-75-74 Ready infra,worker 3d20h v1.25.0 host-172-25-75-79 Ready worker 3d20h v1.25.0 host-172-25-75-86 Ready worker 3d20h v1.25.0 host-172-25-75-98 Ready infra,worker 3d20h v1.25.0所有节点都可能需要几分钟时间报告其状态。
如果有任何节点处于
NotReady状态,登录到节点,并从每个节点上的/var/lib/kubelet/pki目录中删除所有 PEM 文件。您可以 SSH 到节点,或使用 web 控制台中的终端窗口。$ ssh -i <ssh-key-path> core@<master-hostname>pki目录示例sh-4.4# pwd /var/lib/kubelet/pki sh-4.4# ls kubelet-client-2022-04-28-11-24-09.pem kubelet-server-2022-04-28-11-24-15.pem kubelet-client-current.pem kubelet-server-current.pem
在所有 control plane 主机上重启 kubelet 服务。
在恢复主机中运行以下命令:
$ sudo systemctl restart kubelet.service- 在所有其他 control plane 主机上重复此步骤。
批准待处理的 CSR:
注意没有 worker 节点的集群(如单节点集群或由三个可调度的 control plane 节点组成的集群)不会批准任何待处理的 CSR。您可以跳过此步骤中列出的所有命令。
获取当前 CSR 列表:
$ oc get csr输出示例
NAME AGE SIGNERNAME REQUESTOR CONDITION csr-2s94x 8m3s kubernetes.io/kubelet-serving system:node:<node_name> Pending1 csr-4bd6t 8m3s kubernetes.io/kubelet-serving system:node:<node_name> Pending2 csr-4hl85 13m kubernetes.io/kube-apiserver-client-kubelet system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending3 csr-zhhhp 3m8s kubernetes.io/kube-apiserver-client-kubelet system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending4 ...查看一个 CSR 的详细信息以验证其是否有效:
$ oc describe csr <csr_name>1 - 1
<csr_name>是当前 CSR 列表中 CSR 的名称。
批准每个有效的
node-bootstrapperCSR:$ oc adm certificate approve <csr_name>对于用户置备的安装,请批准每个有效的 kubelet 服务 CSR:
$ oc adm certificate approve <csr_name>
确认单个成员 control plane 已被成功启动。
从恢复主机上,验证 etcd 容器是否正在运行。
$ sudo crictl ps | grep etcd | egrep -v "operator|etcd-guard"输出示例
3ad41b7908e32 36f86e2eeaaffe662df0d21041eb22b8198e0e58abeeae8c743c3e6e977e8009 About a minute ago Running etcd 0 7c05f8af362f0从恢复主机上,验证 etcd pod 是否正在运行。
$ oc -n openshift-etcd get pods -l k8s-app=etcd输出示例
NAME READY STATUS RESTARTS AGE etcd-ip-10-0-143-125.ec2.internal 1/1 Running 1 2m47s如果状态是
Pending,或者输出中列出了多个正在运行的 etcd pod,请等待几分钟,然后再次检查。
如果使用
OVNKubernetes网络插件,请删除与不是恢复 control plane 主机的 control plane 主机关联的节点对象。$ oc delete node <non-recovery-controlplane-host-1> <non-recovery-controlplane-host-2>验证 Cluster Network Operator (CNO) 是否已重新部署 OVN-Kubernetes control plane,并且不再引用非恢复控制器 IP 地址。要验证此结果,请定期检查以下命令的输出。等待返回空结果,然后继续下一步的所有主机上重启 Open Virtual Network (OVN) Kubernetes pod。
$ oc -n openshift-ovn-kubernetes get ds/ovnkube-master -o yaml | grep -E '<non-recovery_controller_ip_1>|<non-recovery_controller_ip_2>'注意重新部署 OVN-Kubernetes control plane 并至少需要 5 到 10 分钟,并且上一命令返回空输出。
如果使用 OVN-Kubernetes 网络插件,请在所有主机上重启 Open Virtual Network (OVN) Kubernetes pod。
注意验证和变异准入 Webhook 可能会拒绝 pod。如果您添加了额外的 Webhook,其
failurePolicy被设置为Fail的,则它们可能会拒绝 pod,恢复过程可能会失败。您可以通过在恢复集群状态时保存和删除 Webhook 来避免这种情况。成功恢复集群状态后,您可以再次启用 Webhook。另外,您可以在恢复集群状态时临时将
failurePolicy设置为Ignore。成功恢复集群状态后,您可以将failurePolicy设置为Fail。删除北向数据库 (nbdb) 和南向数据库 (sbdb)。使用 Secure Shell (SSH) 访问恢复主机和剩余的 control plane 节点,再运行以下命令:
$ sudo rm -f /var/lib/ovn/etc/*.db运行以下命令删除所有 OVN-Kubernetes control plane pod:
$ oc delete pods -l app=ovnkube-master -n openshift-ovn-kubernetes运行以下命令,确保任何 OVN-Kubernetes control plane pod 已再次部署,并处于
Running状态:$ oc get pods -l app=ovnkube-master -n openshift-ovn-kubernetes输出示例
NAME READY STATUS RESTARTS AGE ovnkube-master-nb24h 4/4 Running 0 48s运行以下命令删除所有
ovnkube-nodepod:$ oc get pods -n openshift-ovn-kubernetes -o name | grep ovnkube-node | while read p ; do oc delete $p -n openshift-ovn-kubernetes ; done运行以下命令,检查 OVN pod 的状态:
$ oc get po -n openshift-ovn-kubernetes如果有任何 OVN pod 处于
Terminating状态,请运行以下命令来删除运行该 OVN pod 的节点。将<node> 替换为您要删除的节点的名称:$ oc delete node <node>运行以下命令,使用 SSH 登录到带有
Terminating状态的 OVN pod 节点:$ ssh -i <ssh-key-path> core@<node>运行以下命令,从
/var/lib/kubelet/pki目录中移动所有 PEM 文件:$ sudo mv /var/lib/kubelet/pki/* /tmp运行以下命令来重启 kubelet 服务:
$ sudo systemctl restart kubelet.service运行以下命令返回恢复 etcd 机器:
$ oc get csr输出示例
NAME AGE SIGNERNAME REQUESTOR CONDITION csr-<uuid> 8m3s kubernetes.io/kubelet-serving system:node:<node_name> Pending运行以下命令来批准所有新的 CSR,将
csr-<uuid> 替换为 CSR 的名称:oc adm certificate approve csr-<uuid>运行以下命令验证节点是否已返回:
$ oc get nodes
运行以下命令,确保所有
ovnkube-nodepod 已再次部署,并处于Running状态:$ oc get pods -n openshift-ovn-kubernetes | grep ovnkube-node
逐个删除并重新创建其他非恢复 control plane 机器。重新创建机器后,会强制一个新修订版本,etcd 会自动扩展。
如果使用用户置备的裸机安装,您可以使用最初创建它时使用的相同方法重新创建 control plane 机器。如需更多信息,请参阅"在裸机上安装用户置备的集群"。
警告不要为恢复主机删除并重新创建机器。
如果您正在运行安装程序置备的基础架构,或者您使用 Machine API 创建机器,请按照以下步骤执行:
警告不要为恢复主机删除并重新创建机器。
对于安装程序置备的基础架构上的裸机安装,不会重新创建 control plane 机器。如需更多信息,请参阅"替换裸机控制平面节点"。
为丢失的 control plane 主机之一获取机器。
在一个终端中使用 cluster-admin 用户连接到集群,运行以下命令:
$ oc get machines -n openshift-machine-api -o wide输出示例:
NAME PHASE TYPE REGION ZONE AGE NODE PROVIDERID STATE clustername-8qw5l-master-0 Running m4.xlarge us-east-1 us-east-1a 3h37m ip-10-0-131-183.ec2.internal aws:///us-east-1a/i-0ec2782f8287dfb7e stopped1 clustername-8qw5l-master-1 Running m4.xlarge us-east-1 us-east-1b 3h37m ip-10-0-143-125.ec2.internal aws:///us-east-1b/i-096c349b700a19631 running clustername-8qw5l-master-2 Running m4.xlarge us-east-1 us-east-1c 3h37m ip-10-0-154-194.ec2.internal aws:///us-east-1c/i-02626f1dba9ed5bba running clustername-8qw5l-worker-us-east-1a-wbtgd Running m4.large us-east-1 us-east-1a 3h28m ip-10-0-129-226.ec2.internal aws:///us-east-1a/i-010ef6279b4662ced running clustername-8qw5l-worker-us-east-1b-lrdxb Running m4.large us-east-1 us-east-1b 3h28m ip-10-0-144-248.ec2.internal aws:///us-east-1b/i-0cb45ac45a166173b running clustername-8qw5l-worker-us-east-1c-pkg26 Running m4.large us-east-1 us-east-1c 3h28m ip-10-0-170-181.ec2.internal aws:///us-east-1c/i-06861c00007751b0a running- 1
- 这是用于丢失的 control plane 主机
ip-10-0-131-183.ec2.internal的 control plane 机器。
运行以下命令,删除丢失的 control plane 主机的机器:
$ oc delete machine -n openshift-machine-api clustername-8qw5l-master-01 - 1
- 为丢失的 control plane 主机指定 control plane 机器的名称。
删除丢失的 control plane 主机的机器后,会自动置备新机器。
运行以下命令验证新机器是否已创建:
$ oc get machines -n openshift-machine-api -o wide输出示例:
NAME PHASE TYPE REGION ZONE AGE NODE PROVIDERID STATE clustername-8qw5l-master-1 Running m4.xlarge us-east-1 us-east-1b 3h37m ip-10-0-143-125.ec2.internal aws:///us-east-1b/i-096c349b700a19631 running clustername-8qw5l-master-2 Running m4.xlarge us-east-1 us-east-1c 3h37m ip-10-0-154-194.ec2.internal aws:///us-east-1c/i-02626f1dba9ed5bba running clustername-8qw5l-master-3 Provisioning m4.xlarge us-east-1 us-east-1a 85s ip-10-0-173-171.ec2.internal aws:///us-east-1a/i-015b0888fe17bc2c8 running1 clustername-8qw5l-worker-us-east-1a-wbtgd Running m4.large us-east-1 us-east-1a 3h28m ip-10-0-129-226.ec2.internal aws:///us-east-1a/i-010ef6279b4662ced running clustername-8qw5l-worker-us-east-1b-lrdxb Running m4.large us-east-1 us-east-1b 3h28m ip-10-0-144-248.ec2.internal aws:///us-east-1b/i-0cb45ac45a166173b running clustername-8qw5l-worker-us-east-1c-pkg26 Running m4.large us-east-1 us-east-1c 3h28m ip-10-0-170-181.ec2.internal aws:///us-east-1c/i-06861c00007751b0a running- 1
- 新机器
clustername-8qw5l-master-3会被创建,并在阶段从Provisioning变为Running后就绪。
创建新机器可能需要几分钟时间。当机器或节点返回一个健康状态时,etcd cluster Operator 将自动同步。
- 对不是恢复主机的每个已丢失的 control plane 主机重复此步骤。
输入以下命令关闭仲裁保护:
$ oc patch etcd/cluster --type=merge -p '{"spec": {"unsupportedConfigOverrides": {"useUnsupportedUnsafeNonHANonProductionUnstableEtcd": true}}}'此命令可确保您可以成功重新创建机密并推出静态 pod。
在恢复主机中的一个单独的终端窗口中,运行以下命令来导出恢复
kubeconfig文件:$ export KUBECONFIG=/etc/kubernetes/static-pod-resources/kube-apiserver-certs/secrets/node-kubeconfigs/localhost-recovery.kubeconfig强制 etcd 重新部署。
在导出恢复
kubeconfig文件的同一终端窗口中,运行以下命令:$ oc patch etcd cluster -p='{"spec": {"forceRedeploymentReason": "recovery-'"$( date --rfc-3339=ns )"'"}}' --type=merge1 - 1
forceRedeploymentReason值必须是唯一的,这就是为什么附加时间戳的原因。
当 etcd cluster Operator 执行重新部署时,现有节点开始使用与初始 bootstrap 扩展类似的新 pod。
输入以下命令重新打开仲裁保护:
$ oc patch etcd/cluster --type=merge -p '{"spec": {"unsupportedConfigOverrides": null}}'您可以输入以下命令验证
unsupportedConfigOverrides部分是否已从对象中删除:$ oc get etcd/cluster -oyaml验证所有节点是否已更新至最新的修订版本。
在一个终端中使用
cluster-admin用户连接到集群,运行以下命令:$ oc get etcd -o=jsonpath='{range .items[0].status.conditions[?(@.type=="NodeInstallerProgressing")]}{.reason}{"\n"}{.message}{"\n"}'查看 etcd 的
NodeInstallerProgressing状态条件,以验证所有节点是否处于最新的修订。在更新成功后,输出会显示AllNodesAtLatestRevision:AllNodesAtLatestRevision 3 nodes are at revision 71 - 1
- 在本例中,最新的修订版本号是
7。
如果输出包含多个修订号,如
2 个节点为修订版本 6;1 个节点为修订版本 7,这意味着更新仍在进行中。等待几分钟后重试。在重新部署 etcd 后,为 control plane 强制进行新的 rollout。由于 kubelet 使用内部负载平衡器连接到 API 服务器,因此 Kubernetes API 将在其他节点上重新安装自己。
在一个终端中使用
cluster-admin用户连接到集群,运行以下命令。为 Kubernetes API 服务器强制进行新的推出部署:
$ oc patch kubeapiserver cluster -p='{"spec": {"forceRedeploymentReason": "recovery-'"$( date --rfc-3339=ns )"'"}}' --type=merge验证所有节点是否已更新至最新的修订版本。
$ oc get kubeapiserver -o=jsonpath='{range .items[0].status.conditions[?(@.type=="NodeInstallerProgressing")]}{.reason}{"\n"}{.message}{"\n"}'查看
NodeInstallerProgressing状态条件,以验证所有节点是否处于最新版本。在更新成功后,输出会显示AllNodesAtLatestRevision:AllNodesAtLatestRevision 3 nodes are at revision 71 - 1
- 在本例中,最新的修订版本号是
7。
如果输出包含多个修订号,如
2 个节点为修订版本 6;1 个节点为修订版本 7,这意味着更新仍在进行中。等待几分钟后重试。为 Kubernetes 控制器管理器强制进行新的推出部署:
$ oc patch kubecontrollermanager cluster -p='{"spec": {"forceRedeploymentReason": "recovery-'"$( date --rfc-3339=ns )"'"}}' --type=merge验证所有节点是否已更新至最新的修订版本。
$ oc get kubecontrollermanager -o=jsonpath='{range .items[0].status.conditions[?(@.type=="NodeInstallerProgressing")]}{.reason}{"\n"}{.message}{"\n"}'查看
NodeInstallerProgressing状态条件,以验证所有节点是否处于最新版本。在更新成功后,输出会显示AllNodesAtLatestRevision:AllNodesAtLatestRevision 3 nodes are at revision 71 - 1
- 在本例中,最新的修订版本号是
7。
如果输出包含多个修订号,如
2 个节点为修订版本 6;1 个节点为修订版本 7,这意味着更新仍在进行中。等待几分钟后重试。为 Kubernetes 调度程序强制进行新的推出部署:
$ oc patch kubescheduler cluster -p='{"spec": {"forceRedeploymentReason": "recovery-'"$( date --rfc-3339=ns )"'"}}' --type=merge验证所有节点是否已更新至最新的修订版本。
$ oc get kubescheduler -o=jsonpath='{range .items[0].status.conditions[?(@.type=="NodeInstallerProgressing")]}{.reason}{"\n"}{.message}{"\n"}'查看
NodeInstallerProgressing状态条件,以验证所有节点是否处于最新版本。在更新成功后,输出会显示AllNodesAtLatestRevision:AllNodesAtLatestRevision 3 nodes are at revision 71 - 1
- 在本例中,最新的修订版本号是
7。
如果输出包含多个修订号,如
2 个节点为修订版本 6;1 个节点为修订版本 7,这意味着更新仍在进行中。等待几分钟后重试。
验证所有 control plane 主机是否已启动并加入集群。
在一个终端中使用
cluster-admin用户连接到集群,运行以下命令:$ oc -n openshift-etcd get pods -l k8s-app=etcd输出示例
etcd-ip-10-0-143-125.ec2.internal 2/2 Running 0 9h etcd-ip-10-0-154-194.ec2.internal 2/2 Running 0 9h etcd-ip-10-0-173-171.ec2.internal 2/2 Running 0 9h
为确保所有工作负载在恢复过程后返回到正常操作,请重启存储 Kubernetes API 信息的每个 pod。这包括 OpenShift Container Platform 组件,如路由器、Operator 和第三方组件。
完成前面的流程步骤后,您可能需要等待几分钟,让所有服务返回到恢复的状态。例如,在重启 OAuth 服务器 pod 前,使用 oc login 进行身份验证可能无法立即正常工作。
考虑使用 system:admin kubeconfig 文件立即进行身份验证。这个方法基于 SSL/TLS 客户端证书作为 OAuth 令牌的身份验证。您可以发出以下命令来使用此文件进行身份验证:
$ export KUBECONFIG=<installation_directory>/auth/kubeconfig发出以下命令以显示您的验证的用户名:
$ oc whoami5.4.2.3. 从 etcd 备份手动恢复集群
恢复过程在 "Restoring to a previous cluster state" 部分中介绍:
-
需要 2 个 control plane 节点的完整重新创建,这可能是使用 UPI 安装方法安装的集群的一个复杂步骤,因为 UPI 安装不会为 control plane 节点创建任何
Machine或ControlPlaneMachineset。 - 使用脚本 /usr/local/bin/cluster-restore.sh,它会启动新的单成员 etcd 集群,然后将其扩展到三个成员。
相反,这个过程:
- 不需要重新创建任何 control plane 节点。
- 直接启动一个三成员 etcd 集群。
如果集群使用 MachineSet 用于 control plane,建议使用 "Restoring to a previous cluster state" 用于简化 etcd 恢复的步骤。
恢复集群时,必须使用同一 z-stream 发行版本中获取的 etcd 备份。例如,OpenShift Container Platform 4.7.2 集群必须使用从 4.7.2 开始的 etcd 备份。
先决条件
-
使用具有
cluster-admin角色的用户访问集群,例如kubeadmin用户。 -
通过 SSH 访问所有 control plane 主机,允许主机用户成为
root用户;例如,默认的core主机用户。 -
包含之前 etcd 快照和来自同一备份的静态 pod 资源的备份目录。该目录中的文件名必须采用以下格式:
snapshot_<datetimestamp>.db和static_kuberesources_<datetimestamp>.tar.gz。
流程
使用 SSH 连接到每个 control plane 节点。
恢复过程启动后,Kubernetes API 服务器将无法访问,因此您无法访问 control plane 节点。因此,建议针对每个 control plane 主机都使用一个单独的终端来进行 SSH 连接。
重要如果没有完成这个步骤,将无法访问 control plane 主机来完成恢复过程,您将无法从这个状态恢复集群。
将 etcd 备份目录复制到每个 control plane 主机上。
此流程假设您将
backup目录(其中包含 etcd 快照和静态 pod 资源)复制到每个 control plane 主机的/home/core/assets目录中。如果尚未存在,您可能需要创建此assets文件夹。停止所有 control plane 节点上的静态 pod;一次只针对一个主机进行。
将现有 Kubernetes API Server 静态 pod 清单从 kubelet 清单目录中移出。
$ mkdir -p /root/manifests-backup $ mv /etc/kubernetes/manifests/kube-apiserver-pod.yaml /root/manifests-backup/使用以下命令验证 Kubernetes API 服务器容器是否已停止:
$ crictl ps | grep kube-apiserver | grep -E -v "operator|guard"命令输出应该为空。如果它不是空的,请等待几分钟后再重新检查。
如果 Kubernetes API 服务器容器仍在运行,使用以下命令手动终止它们:
$ crictl stop <container_id>对
kube-controller-manager-pod.yaml、kube-scheduler-pod.yaml最后为etcd-pod.yaml重复相同的步骤,。使用以下命令停止
kube-controller-managerpod:$ mv /etc/kubernetes/manifests/kube-controller-manager-pod.yaml /root/manifests-backup/使用以下命令检查容器是否已停止:
$ crictl ps | grep kube-controller-manager | grep -E -v "operator|guard"使用以下命令停止
kube-schedulerpod:$ mv /etc/kubernetes/manifests/kube-scheduler-pod.yaml /root/manifests-backup/使用以下命令检查容器是否已停止:
$ crictl ps | grep kube-scheduler | grep -E -v "operator|guard"使用以下命令停止
etcdpod:$ mv /etc/kubernetes/manifests/etcd-pod.yaml /root/manifests-backup/使用以下命令检查容器是否已停止:
$ crictl ps | grep etcd | grep -E -v "operator|guard"
在每个 control plane 主机上,保存当前的
etcd数据(将它移到backup目录中):$ mkdir /home/core/assets/old-member-data $ mv /var/lib/etcd/member /home/core/assets/old-member-data当
etcd备份恢复无法正常工作,且etcd集群必须恢复到当前状态,则这些数据将很有用。为每个 control plane 主机找到正确的 etcd 参数。
<ETCD_NAME>的值对每个 control plane 主机都是唯一的,它等于特定 control plane 主机上的清单/etc/kubernetes/static-pod-resources/etcd-certs/configmaps/restore-etcd-pod/pod.yaml文件中的ETCD_NAME变量的值。它可以通过以下命令找到:RESTORE_ETCD_POD_YAML="/etc/kubernetes/static-pod-resources/etcd-certs/configmaps/restore-etcd-pod/pod.yaml" cat $RESTORE_ETCD_POD_YAML | \ grep -A 1 $(cat $RESTORE_ETCD_POD_YAML | grep 'export ETCD_NAME' | grep -Eo 'NODE_.+_ETCD_NAME') | \ grep -Po '(?<=value: ").+(?=")'<UUID>的值可使用以下命令在 control plane 主机中生成:$ uuidgen注意<UUID>的值必须只生成一次。在一个 control plane 主机上生成UUID后,请不要在其他主机上再次生成它。相同的UUID会在后续步骤中的所有 control plane 主机上使用。ETCD_NODE_PEER_URL的值应设置为类似以下示例:https://<IP_CURRENT_HOST>:2380正确的 IP 可以从特定 control plane 主机的
<ETCD_NAME>中找到,使用以下命令:$ echo <ETCD_NAME> | \ sed -E 's/[.-]/_/g' | \ xargs -I {} grep {} /etc/kubernetes/static-pod-resources/etcd-certs/configmaps/etcd-scripts/etcd.env | \ grep "IP" | grep -Po '(?<=").+(?=")'<ETCD_INITIAL_CLUSTER>的值应设置为如下所示,其中<ETCD_NAME_n>是每个 control plane 主机的<ETCD_NAME>。注意使用的端口必须是 2380,而不是 2379。端口 2379 用于 etcd 数据库管理,并直接在容器中的 etcd start 命令中配置。
输出示例
<ETCD_NAME_0>=<ETCD_NODE_PEER_URL_0>,<ETCD_NAME_1>=<ETCD_NODE_PEER_URL_1>,<ETCD_NAME_2>=<ETCD_NODE_PEER_URL_2>1 - 1
- 指定每个 control plane 主机中的
ETCD_NODE_PEER_URL值。
<ETCD_INITIAL_CLUSTER>值在所有 control plane 主机上都是相同的。在后续步骤中,每个 control plane 主机都需要使用相同的值。
从备份中重新生成 etcd 数据库。
此类操作必须在每个 control plane 主机上执行。
使用以下命令将
etcd备份复制到/var/lib/etcd目录中:$ cp /home/core/assets/backup/<snapshot_yyyy-mm-dd_hhmmss>.db /var/lib/etcd在继续操作前,识别正确的
etcdctl镜像。使用以下命令从 pod 清单的备份中检索镜像:$ jq -r '.spec.containers[]|select(.name=="etcdctl")|.image' /root/manifests-backup/etcd-pod.yaml$ podman run --rm -it --entrypoint="/bin/bash" -v /var/lib/etcd:/var/lib/etcd:z <image-hash>检查
etcdctl工具的版本是创建备份的etcd服务器的版本:$ etcdctl version运行以下命令重新生成
etcd数据库,为当前主机使用正确的值:$ ETCDCTL_API=3 /usr/bin/etcdctl snapshot restore /var/lib/etcd/<snapshot_yyyy-mm-dd_hhmmss>.db \ --name "<ETCD_NAME>" \ --initial-cluster="<ETCD_INITIAL_CLUSTER>" \ --initial-cluster-token "openshift-etcd-<UUID>" \ --initial-advertise-peer-urls "<ETCD_NODE_PEER_URL>" \ --data-dir="/var/lib/etcd/restore-<UUID>" \ --skip-hash-check=true注意在重新生成
etcd数据库时,引号是必需的。
记录下在
added member日志中的值,例如:输出示例
2022-06-28T19:52:43Z info membership/cluster.go:421 added member {"cluster-id": "c5996b7c11c30d6b", "local-member-id": "0", "added-peer-id": "56cd73b614699e7", "added-peer-peer-urls": ["https://10.0.91.5:2380"], "added-peer-is-learner": false} 2022-06-28T19:52:43Z info membership/cluster.go:421 added member {"cluster-id": "c5996b7c11c30d6b", "local-member-id": "0", "added-peer-id": "1f63d01b31bb9a9e", "added-peer-peer-urls": ["https://10.0.90.221:2380"], "added-peer-is-learner": false} 2022-06-28T19:52:43Z info membership/cluster.go:421 added member {"cluster-id": "c5996b7c11c30d6b", "local-member-id": "0", "added-peer-id": "fdc2725b3b70127c", "added-peer-peer-urls": ["https://10.0.94.214:2380"], "added-peer-is-learner": false}- 退出容器。
-
在其他 control plane 主机上重复这些步骤,检查
added member日志中的值对于所有 control plane 主机都是一样的。
将重新生成的
etcd数据库移到默认位置。此类操作必须在每个 control plane 主机上执行。
将重新生成的数据库(上一个
etcdctl snapshot restore命令创建的member文件夹)移到默认的 etcd 位置/var/lib/etcd:$ mv /var/lib/etcd/restore-<UUID>/member /var/lib/etcd在
/var/lib/etcd目录中恢复/var/lib/etcd/member文件夹的 SELinux 上下文:$ restorecon -vR /var/lib/etcd/删除剩下的文件和目录:
$ rm -rf /var/lib/etcd/restore-<UUID>$ rm /var/lib/etcd/<snapshot_yyyy-mm-dd_hhmmss>.db重要完成后,
/var/lib/etcd目录只能包含文件夹member。- 在其他 control plane 主机上重复这些步骤。
重启 etcd 集群。
- 必须在所有 control plane 主机上执行以下步骤,但一次只针对一个主机执行。
将
etcd静态 pod 清单移回到 kubelet 清单目录,以便 kubelet 启动相关的容器:$ mv /root/manifests-backup/etcd-pod.yaml /etc/kubernetes/manifests验证所有
etcd容器是否已启动:$ crictl ps | grep etcd | grep -v operator输出示例
38c814767ad983 f79db5a8799fd2c08960ad9ee22f784b9fbe23babe008e8a3bf68323f004c840 28 seconds ago Running etcd-health-monitor 2 fe4b9c3d6483c e1646b15207c6 9d28c15860870e85c91d0e36b45f7a6edd3da757b113ec4abb4507df88b17f06 About a minute ago Running etcd-metrics 0 fe4b9c3d6483c 08ba29b1f58a7 9d28c15860870e85c91d0e36b45f7a6edd3da757b113ec4abb4507df88b17f06 About a minute ago Running etcd 0 fe4b9c3d6483c 2ddc9eda16f53 9d28c15860870e85c91d0e36b45f7a6edd3da757b113ec4abb4507df88b17f06 About a minute ago Running etcdctl如果这个命令的输出为空,请等待几分钟,然后再次检查。
检查
etcd集群的状态。在任何 control plane 主机上,使用以下命令检查
etcd集群的状态:$ crictl exec -it $(crictl ps | grep etcdctl | awk '{print $1}') etcdctl endpoint status -w table输出示例
+--------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+ | ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS | +--------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+ | https://10.0.89.133:2379 | 682e4a83a0cec6c0 | 3.5.0 | 67 MB | true | false | 2 | 218 | 218 | | | https://10.0.92.74:2379 | 450bcf6999538512 | 3.5.0 | 67 MB | false | false | 2 | 218 | 218 | | | https://10.0.93.129:2379 | 358efa9c1d91c3d6 | 3.5.0 | 67 MB | false | false | 2 | 218 | 218 | | +--------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
重启其他静态 pod。
必须在所有 control plane 主机上执行以下步骤,但一次只针对一个主机执行。
将 Kubernetes API Server 静态 pod 清单重新移到 kubelet 清单目录中,以便 kubelet 使用命令启动相关的容器:
$ mv /root/manifests-backup/kube-apiserver-pod.yaml /etc/kubernetes/manifests验证所有 Kubernetes API 服务器容器是否已启动:
$ crictl ps | grep kube-apiserver | grep -v operator注意如果以下命令的输出为空,请等待几分钟,然后再次检查。
对
kube-controller-manager-pod.yaml和kube-scheduler-pod.yaml文件重复相同的步骤。使用以下命令重启所有节点中的 kubelet:
$ systemctl restart kubelet使用以下命令启动剩余的 control plane pod:
$ mv /root/manifests-backup/kube-* /etc/kubernetes/manifests/检查
kube-apiserver、kube-scheduler和kube-controller-managerpod 是否已正确启动:$ crictl ps | grep -E 'kube-(apiserver|scheduler|controller-manager)' | grep -v -E 'operator|guard'使用以下命令擦除 OVN 数据库:
for NODE in $(oc get node -o name | sed 's:node/::g') do oc debug node/${NODE} -- chroot /host /bin/bash -c 'rm -f /var/lib/ovn-ic/etc/ovn*.db && systemctl restart ovs-vswitchd ovsdb-server' oc -n openshift-ovn-kubernetes delete pod -l app=ovnkube-node --field-selector=spec.nodeName=${NODE} --wait oc -n openshift-ovn-kubernetes wait pod -l app=ovnkube-node --field-selector=spec.nodeName=${NODE} --for condition=ContainersReady --timeout=600s done
5.4.2.5. 恢复持久性存储状态的问题和解决方法
如果您的 OpenShift Container Platform 集群使用任何形式的持久性存储,集群的状态通常存储在 etcd 外部。它可能是在 pod 中运行的 Elasticsearch 集群,或者在 StatefulSet 对象中运行的数据库。从 etcd 备份中恢复时,还会恢复 OpenShift Container Platform 中工作负载的状态。但是,如果 etcd 快照是旧的,其状态可能无效或过期。
持久性卷(PV)的内容绝不会属于 etcd 快照的一部分。从 etcd 快照恢复 OpenShift Container Platform 集群时,非关键工作负载可能会访问关键数据,反之亦然。
以下是生成过时状态的一些示例情况:
- MySQL 数据库在由 PV 对象支持的 pod 中运行。从 etcd 快照恢复 OpenShift Container Platform 不会使卷恢复到存储供应商上,且不会生成正在运行的 MySQL pod,尽管 pod 会重复尝试启动。您必须通过在存储供应商中恢复卷,然后编辑 PV 以指向新卷来手动恢复这个 pod。
- Pod P1 使用卷 A,它附加到节点 X。如果另一个 pod 在节点 Y 上使用相同的卷,则执行 etcd 恢复时,pod P1 可能无法正确启动,因为卷仍然被附加到节点 Y。OpenShift Container Platform 并不知道附加,且不会自动分离它。发生这种情况时,卷必须从节点 Y 手动分离,以便卷可以在节点 X 上附加,然后 pod P1 才可以启动。
- 在执行 etcd 快照后,云供应商或存储供应商凭证会被更新。这会导致任何依赖于这些凭证的 CSI 驱动程序或 Operator 无法正常工作。您可能需要手动更新这些驱动程序或 Operator 所需的凭证。
在生成 etcd 快照后,会从 OpenShift Container Platform 节点中删除或重命名设备。Local Storage Operator 会为从
/dev/disk/by-id或/dev目录中管理的每个 PV 创建符号链接。这种情况可能会导致本地 PV 引用不再存在的设备。要解决这个问题,管理员必须:
- 手动删除带有无效设备的 PV。
- 从对应节点中删除符号链接。
-
删除
LocalVolume或LocalVolumeSet对象(请参阅 StorageConfiguring persistent storage Persistent storage Persistent storage Deleting the Local Storage Operator Resources)。
5.4.3. 从 control plane 证书已过期的情况下恢复
5.4.3.1. 从 control plane 证书已过期的情况下恢复
集群可以从过期的 control plane 证书中自动恢复。
但是,您需要手动批准待处理的 node-bootstrapper 证书签名请求(CSR)来恢复 kubelet 证书。对于用户置备的安装,您可能需要批准待处理的 kubelet 服务 CSR。
使用以下步骤批准待处理的 CSR:
流程
获取当前 CSR 列表:
$ oc get csr输出示例
NAME AGE SIGNERNAME REQUESTOR CONDITION csr-2s94x 8m3s kubernetes.io/kubelet-serving system:node:<node_name> Pending1 csr-4bd6t 8m3s kubernetes.io/kubelet-serving system:node:<node_name> Pending csr-4hl85 13m kubernetes.io/kube-apiserver-client-kubelet system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending2 csr-zhhhp 3m8s kubernetes.io/kube-apiserver-client-kubelet system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending ...查看一个 CSR 的详细信息以验证其是否有效:
$ oc describe csr <csr_name>1 - 1
<csr_name>是当前 CSR 列表中 CSR 的名称。
批准每个有效的
node-bootstrapperCSR:$ oc adm certificate approve <csr_name>对于用户置备的安装,请批准每个有效的 kubelet 服务 CSR:
$ oc adm certificate approve <csr_name>
5.4.4. AWS 区域托管的集群的灾难恢复
对于托管集群需要灾难恢复 (DR) 的情况,您可以将托管集群恢复到 AWS 中的同一区域。例如,当升级管理集群时,需要 DR,托管的集群处于只读状态。
托管的 control plane 只是一个技术预览功能。技术预览功能不受红帽产品服务等级协议(SLA)支持,且功能可能并不完整。红帽不推荐在生产环境中使用它们。这些技术预览功能可以使用户提早试用新的功能,并有机会在开发阶段提供反馈意见。
有关红帽技术预览功能支持范围的更多信息,请参阅技术预览功能支持范围。
DR 进程涉及三个主要步骤:
- 在源集群中备份托管集群
- 在目标管理集群中恢复托管集群
- 从源管理集群中删除托管的集群
您的工作负载在此过程中保持运行。集群 API 可能会在一段时间内不可用,但不会影响 worker 节点上运行的服务。
源管理集群和目标管理集群必须具有 --external-dns 标志才能维护 API 服务器 URL,如下例所示:
示例:外部 DNS 标记
--external-dns-provider=aws \
--external-dns-credentials=<AWS Credentials location> \
--external-dns-domain-filter=<DNS Base Domain>
这样,服务器 URL 以 https://api-sample-hosted.sample-hosted.aws.openshift.com 结尾。
如果没有包含 --external-dns 标志来维护 API 服务器 URL,则无法迁移托管集群。
5.4.4.1. 环境和上下文示例
假设您有三个集群需要恢复的情况。两个是管理集群,一个是托管的集群。您只能恢复 control plane 或 control plane 和节点。开始前,您需要以下信息:
- 源 MGMT 命名空间:源管理命名空间
- Source MGMT ClusterName :源管理集群名称
-
源 MGMT Kubeconfig :源管理
kubeconfig文件 -
Destination MGMT Kubeconfig :目标管理
kubeconfig文件 -
HC Kubeconfig :托管的集群
kubeconfig文件 - SSH 密钥文件:SSH 公钥
- Pull secret:用于访问发行镜像的 pull secret 文件
- AWS 凭证
- AWS 区域
- Base domain:用作外部 DNS 的 DNS 基域
- S3 bucket name:计划上传 etcd 备份的 AWS 区域中的存储桶
此信息显示在以下示例环境变量中。
环境变量示例
SSH_KEY_FILE=${HOME}/.ssh/id_rsa.pub
BASE_PATH=${HOME}/hypershift
BASE_DOMAIN="aws.sample.com"
PULL_SECRET_FILE="${HOME}/pull_secret.json"
AWS_CREDS="${HOME}/.aws/credentials"
AWS_ZONE_ID="Z02718293M33QHDEQBROL"
CONTROL_PLANE_AVAILABILITY_POLICY=SingleReplica
HYPERSHIFT_PATH=${BASE_PATH}/src/hypershift
HYPERSHIFT_CLI=${HYPERSHIFT_PATH}/bin/hypershift
HYPERSHIFT_IMAGE=${HYPERSHIFT_IMAGE:-"quay.io/${USER}/hypershift:latest"}
NODE_POOL_REPLICAS=${NODE_POOL_REPLICAS:-2}
# MGMT Context
MGMT_REGION=us-west-1
MGMT_CLUSTER_NAME="${USER}-dev"
MGMT_CLUSTER_NS=${USER}
MGMT_CLUSTER_DIR="${BASE_PATH}/hosted_clusters/${MGMT_CLUSTER_NS}-${MGMT_CLUSTER_NAME}"
MGMT_KUBECONFIG="${MGMT_CLUSTER_DIR}/kubeconfig"
# MGMT2 Context
MGMT2_CLUSTER_NAME="${USER}-dest"
MGMT2_CLUSTER_NS=${USER}
MGMT2_CLUSTER_DIR="${BASE_PATH}/hosted_clusters/${MGMT2_CLUSTER_NS}-${MGMT2_CLUSTER_NAME}"
MGMT2_KUBECONFIG="${MGMT2_CLUSTER_DIR}/kubeconfig"
# Hosted Cluster Context
HC_CLUSTER_NS=clusters
HC_REGION=us-west-1
HC_CLUSTER_NAME="${USER}-hosted"
HC_CLUSTER_DIR="${BASE_PATH}/hosted_clusters/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}"
HC_KUBECONFIG="${HC_CLUSTER_DIR}/kubeconfig"
BACKUP_DIR=${HC_CLUSTER_DIR}/backup
BUCKET_NAME="${USER}-hosted-${MGMT_REGION}"
# DNS
AWS_ZONE_ID="Z07342811SH9AA102K1AC"
EXTERNAL_DNS_DOMAIN="hc.jpdv.aws.kerbeross.com"5.4.4.2. 备份和恢复过程概述
备份和恢复过程按如下方式工作:
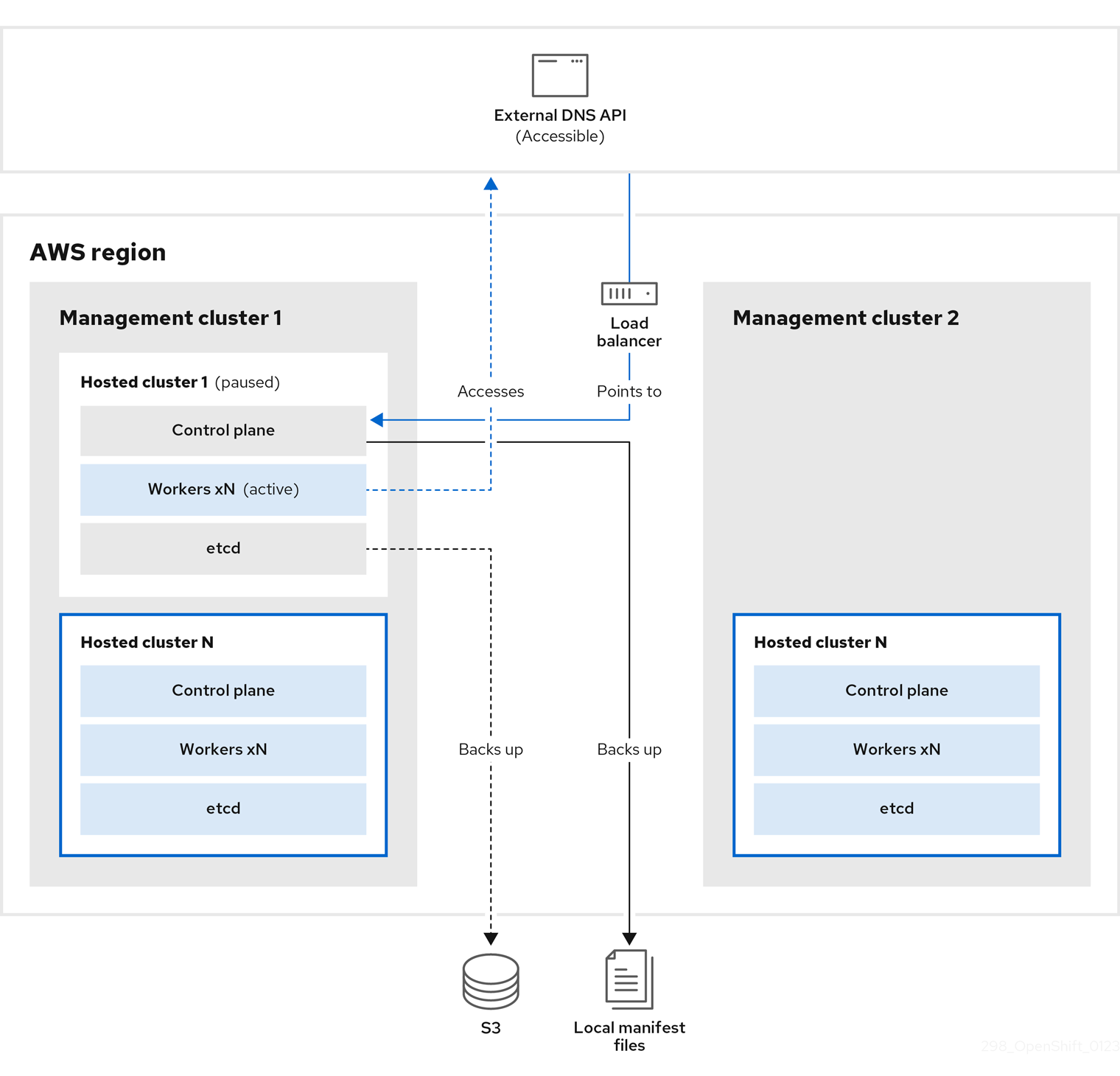
在管理集群 1 中,您可以将其视为源管理集群,control plane 和 worker 使用 ExternalDNS API 进行交互。可以访问外部 DNS API,并且一个负载均衡器位于管理集群之间。

您为托管集群执行快照,其中包括 etcd、control plane 和 worker 节点。在此过程中,worker 节点仍然会尝试访问外部 DNS API,即使无法访问它,工作负载正在运行,control plane 存储在本地清单文件中,etcd 会备份到 S3 存储桶。data plane 处于活跃状态,control plane 已暂停。
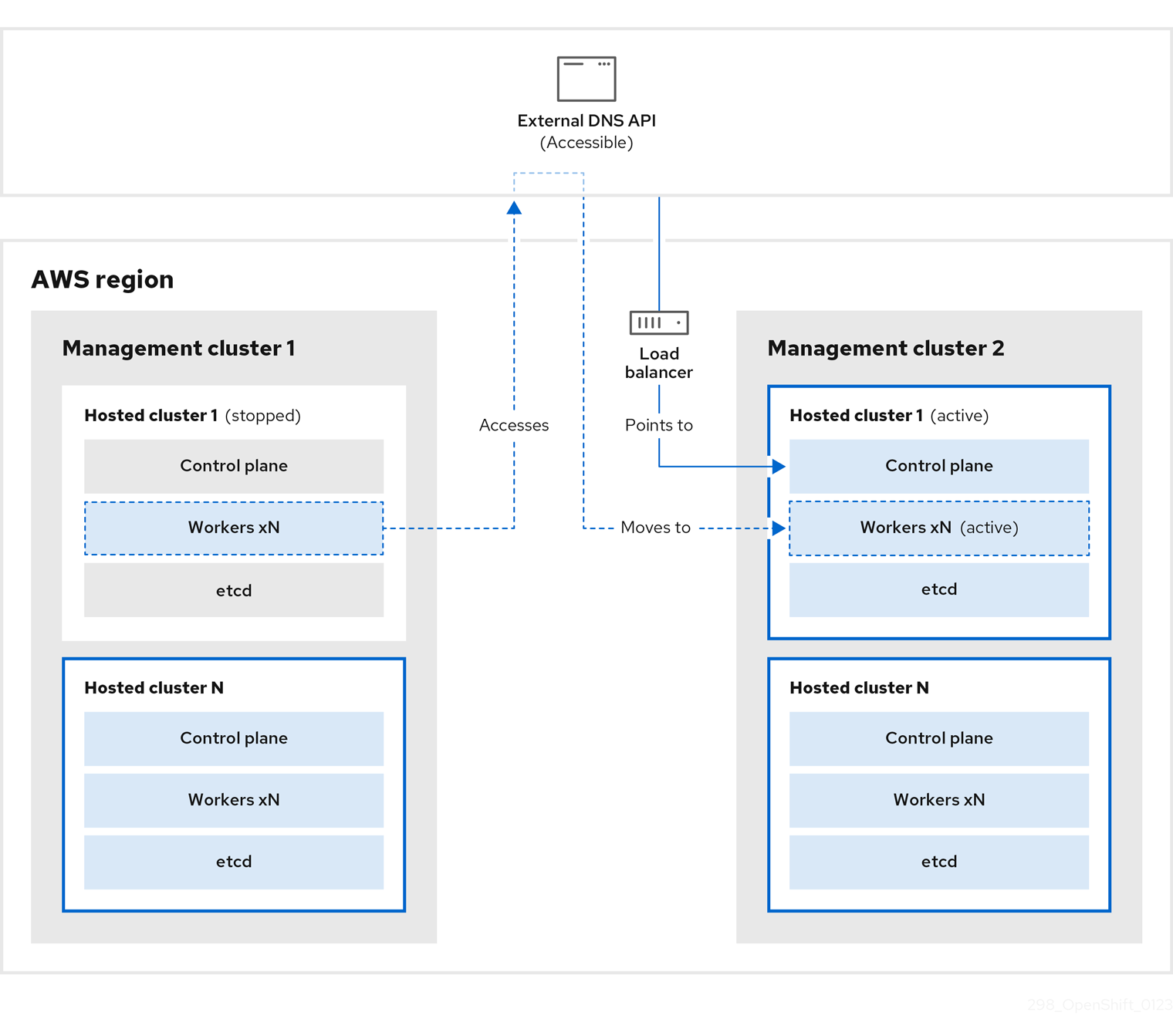
在管理集群 2 中,您可以将其视为目标管理集群,您可以从 S3 存储桶中恢复 etcd,并从本地清单文件恢复 control plane。在此过程中,外部 DNS API 会停止,托管集群 API 变得不可访问,任何使用 API 的 worker 都无法更新其清单文件,但工作负载仍在运行。

外部 DNS API 可以再次访问,worker 节点使用它来移至管理集群 2。外部 DNS API 可以访问指向 control plane 的负载均衡器。
在管理集群 2 中,control plane 和 worker 节点使用外部 DNS API 进行交互。资源从管理集群 1 中删除,但 etcd 的 S3 备份除外。如果您尝试在 mangagement 集群 1 上再次设置托管集群,它将无法正常工作。
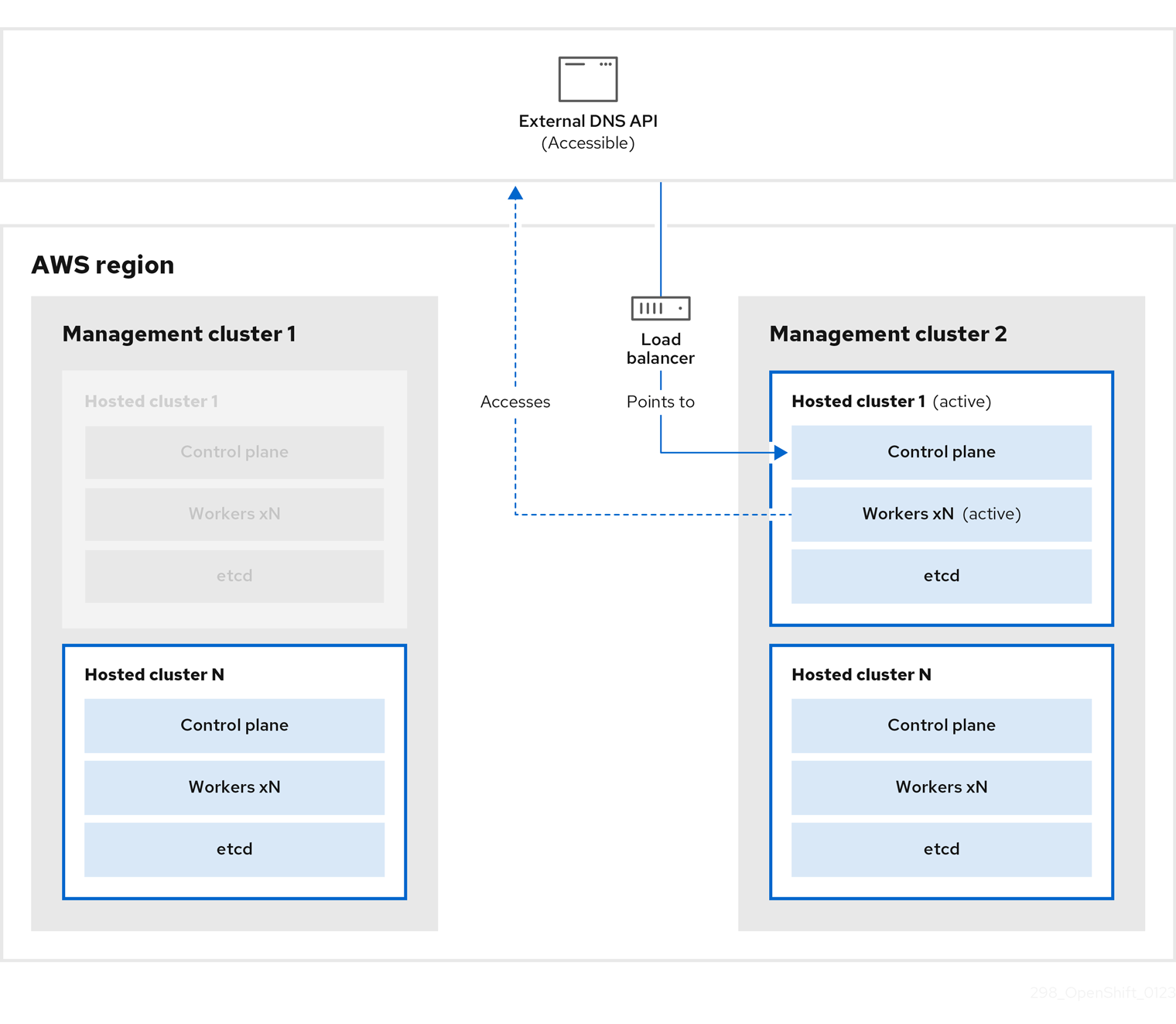
您可以手动备份和恢复托管集群,也可以运行脚本来完成这个过程。有关脚本的更多信息,请参阅"运行脚本以备份和恢复托管集群"。
5.4.4.3. 备份托管集群
要在目标管理集群中恢复托管集群,首先需要备份所有相关数据。
流程
输入以下命令创建 configmap 文件来声明源管理集群:
$ oc create configmap mgmt-parent-cluster -n default --from-literal=from=${MGMT_CLUSTER_NAME}输入这些命令,在托管集群和节点池中关闭协调:
$ PAUSED_UNTIL="true" $ oc patch -n ${HC_CLUSTER_NS} hostedclusters/${HC_CLUSTER_NAME} -p '{"spec":{"pausedUntil":"'${PAUSED_UNTIL}'"}}' --type=merge $ oc scale deployment -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --replicas=0 kube-apiserver openshift-apiserver openshift-oauth-apiserver control-plane-operator$ PAUSED_UNTIL="true" $ oc patch -n ${HC_CLUSTER_NS} hostedclusters/${HC_CLUSTER_NAME} -p '{"spec":{"pausedUntil":"'${PAUSED_UNTIL}'"}}' --type=merge $ oc patch -n ${HC_CLUSTER_NS} nodepools/${NODEPOOLS} -p '{"spec":{"pausedUntil":"'${PAUSED_UNTIL}'"}}' --type=merge $ oc scale deployment -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --replicas=0 kube-apiserver openshift-apiserver openshift-oauth-apiserver control-plane-operator运行此 bash 脚本备份 etcd 并将数据上传到 S3 存储桶:
提示将此脚本嵌套在函数中,并从主功能调用它。
# ETCD Backup ETCD_PODS="etcd-0" if [ "${CONTROL_PLANE_AVAILABILITY_POLICY}" = "HighlyAvailable" ]; then ETCD_PODS="etcd-0 etcd-1 etcd-2" fi for POD in ${ETCD_PODS}; do # Create an etcd snapshot oc exec -it ${POD} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -- env ETCDCTL_API=3 /usr/bin/etcdctl --cacert /etc/etcd/tls/client/etcd-client-ca.crt --cert /etc/etcd/tls/client/etcd-client.crt --key /etc/etcd/tls/client/etcd-client.key --endpoints=localhost:2379 snapshot save /var/lib/data/snapshot.db oc exec -it ${POD} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -- env ETCDCTL_API=3 /usr/bin/etcdctl -w table snapshot status /var/lib/data/snapshot.db FILEPATH="/${BUCKET_NAME}/${HC_CLUSTER_NAME}-${POD}-snapshot.db" CONTENT_TYPE="application/x-compressed-tar" DATE_VALUE=`date -R` SIGNATURE_STRING="PUT\n\n${CONTENT_TYPE}\n${DATE_VALUE}\n${FILEPATH}" set +x ACCESS_KEY=$(grep aws_access_key_id ${AWS_CREDS} | head -n1 | cut -d= -f2 | sed "s/ //g") SECRET_KEY=$(grep aws_secret_access_key ${AWS_CREDS} | head -n1 | cut -d= -f2 | sed "s/ //g") SIGNATURE_HASH=$(echo -en ${SIGNATURE_STRING} | openssl sha1 -hmac "${SECRET_KEY}" -binary | base64) set -x # FIXME: this is pushing to the OIDC bucket oc exec -it etcd-0 -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -- curl -X PUT -T "/var/lib/data/snapshot.db" \ -H "Host: ${BUCKET_NAME}.s3.amazonaws.com" \ -H "Date: ${DATE_VALUE}" \ -H "Content-Type: ${CONTENT_TYPE}" \ -H "Authorization: AWS ${ACCESS_KEY}:${SIGNATURE_HASH}" \ https://${BUCKET_NAME}.s3.amazonaws.com/${HC_CLUSTER_NAME}-${POD}-snapshot.db done有关备份 etcd 的更多信息,请参阅 "Backing and restore etcd on a hosted cluster"。
输入以下命令备份 Kubernetes 和 OpenShift Container Platform 对象。您需要备份以下对象:
-
来自 HostedCluster 命名空间的
HostedCluster和NodePool对象 -
来自 HostedCluster 命名空间中的
HostedClustersecret -
来自 Hosted Control Plane 命名空间中的
HostedControlPlane -
来自 Hosted Control Plane 命名空间的
Cluster -
来自 Hosted Control Plane 命名空间的
AWSCluster,AWSMachineTemplate, 和AWSMachine -
来自 Hosted Control Plane 命名空间的
MachineDeployments,MachineSets, 和Machines。 来自 Hosted Control Plane 命名空间的
ControlPlane$ mkdir -p ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS} ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} $ chmod 700 ${BACKUP_DIR}/namespaces/ # HostedCluster $ echo "Backing Up HostedCluster Objects:" $ oc get hc ${HC_CLUSTER_NAME} -n ${HC_CLUSTER_NS} -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/hc-${HC_CLUSTER_NAME}.yaml $ echo "--> HostedCluster" $ sed -i '' -e '/^status:$/,$d' ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/hc-${HC_CLUSTER_NAME}.yaml # NodePool $ oc get np ${NODEPOOLS} -n ${HC_CLUSTER_NS} -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/np-${NODEPOOLS}.yaml $ echo "--> NodePool" $ sed -i '' -e '/^status:$/,$ d' ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/np-${NODEPOOLS}.yaml # Secrets in the HC Namespace $ echo "--> HostedCluster Secrets:" for s in $(oc get secret -n ${HC_CLUSTER_NS} | grep "^${HC_CLUSTER_NAME}" | awk '{print $1}'); do oc get secret -n ${HC_CLUSTER_NS} $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/secret-${s}.yaml done # Secrets in the HC Control Plane Namespace $ echo "--> HostedCluster ControlPlane Secrets:" for s in $(oc get secret -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} | egrep -v "docker|service-account-token|oauth-openshift|NAME|token-${HC_CLUSTER_NAME}" | awk '{print $1}'); do oc get secret -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/secret-${s}.yaml done # Hosted Control Plane $ echo "--> HostedControlPlane:" $ oc get hcp ${HC_CLUSTER_NAME} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/hcp-${HC_CLUSTER_NAME}.yaml # Cluster $ echo "--> Cluster:" $ CL_NAME=$(oc get hcp ${HC_CLUSTER_NAME} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o jsonpath={.metadata.labels.\*} | grep ${HC_CLUSTER_NAME}) $ oc get cluster ${CL_NAME} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/cl-${HC_CLUSTER_NAME}.yaml # AWS Cluster $ echo "--> AWS Cluster:" $ oc get awscluster ${HC_CLUSTER_NAME} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/awscl-${HC_CLUSTER_NAME}.yaml # AWS MachineTemplate $ echo "--> AWS Machine Template:" $ oc get awsmachinetemplate ${NODEPOOLS} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/awsmt-${HC_CLUSTER_NAME}.yaml # AWS Machines $ echo "--> AWS Machine:" $ CL_NAME=$(oc get hcp ${HC_CLUSTER_NAME} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o jsonpath={.metadata.labels.\*} | grep ${HC_CLUSTER_NAME}) for s in $(oc get awsmachines -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --no-headers | grep ${CL_NAME} | cut -f1 -d\ ); do oc get -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} awsmachines $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/awsm-${s}.yaml done # MachineDeployments $ echo "--> HostedCluster MachineDeployments:" for s in $(oc get machinedeployment -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name); do mdp_name=$(echo ${s} | cut -f 2 -d /) oc get -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machinedeployment-${mdp_name}.yaml done # MachineSets $ echo "--> HostedCluster MachineSets:" for s in $(oc get machineset -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name); do ms_name=$(echo ${s} | cut -f 2 -d /) oc get -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machineset-${ms_name}.yaml done # Machines $ echo "--> HostedCluster Machine:" for s in $(oc get machine -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name); do m_name=$(echo ${s} | cut -f 2 -d /) oc get -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machine-${m_name}.yaml done
-
来自 HostedCluster 命名空间的
输入以下命令清理
ControlPlane路由:$ oc delete routes -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --all输入该命令,您可以启用 ExternalDNS Operator 来删除 Route53 条目。
运行该脚本验证 Route53 条目是否清理:
function clean_routes() { if [[ -z "${1}" ]];then echo "Give me the NS where to clean the routes" exit 1 fi # Constants if [[ -z "${2}" ]];then echo "Give me the Route53 zone ID" exit 1 fi ZONE_ID=${2} ROUTES=10 timeout=40 count=0 # This allows us to remove the ownership in the AWS for the API route oc delete route -n ${1} --all while [ ${ROUTES} -gt 2 ] do echo "Waiting for ExternalDNS Operator to clean the DNS Records in AWS Route53 where the zone id is: ${ZONE_ID}..." echo "Try: (${count}/${timeout})" sleep 10 if [[ $count -eq timeout ]];then echo "Timeout waiting for cleaning the Route53 DNS records" exit 1 fi count=$((count+1)) ROUTES=$(aws route53 list-resource-record-sets --hosted-zone-id ${ZONE_ID} --max-items 10000 --output json | grep -c ${EXTERNAL_DNS_DOMAIN}) done } # SAMPLE: clean_routes "<HC ControlPlane Namespace>" "<AWS_ZONE_ID>" clean_routes "${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}" "${AWS_ZONE_ID}"
验证
检查所有 OpenShift Container Platform 对象和 S3 存储桶,以验证所有内容是否如预期。
后续步骤
恢复托管集群。
5.4.4.4. 恢复托管集群
收集您备份和恢复目标管理集群中的所有对象。
先决条件
您已从源集群备份数据。
确保目标管理集群的 kubeconfig 文件放置在 KUBECONFIG 变量中,或者在 MGMT2_KUBECONFIG 变量中设置。使用 export KUBECONFIG=<Kubeconfig FilePath>,或者使用 export KUBECONFIG=${MGMT2_KUBECONFIG}。
流程
输入以下命令验证新管理集群是否不包含您要恢复的集群中的任何命名空间:
$ export KUBECONFIG=${MGMT2_KUBECONFIG}$ BACKUP_DIR=${HC_CLUSTER_DIR}/backup目标管理集群中的命名空间删除
$ oc delete ns ${HC_CLUSTER_NS} || true$ oc delete ns ${HC_CLUSTER_NS}-{HC_CLUSTER_NAME} || true输入以下命令重新创建已删除的命名空间:
命名空间创建命令
$ oc new-project ${HC_CLUSTER_NS}$ oc new-project ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}输入以下命令恢复 HC 命名空间中的 secret:
$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/secret-*输入以下命令恢复
HostedClustercontrol plane 命名空间中的对象:恢复 secret 命令
$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/secret-*集群恢复命令
$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/hcp-*$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/cl-*如果您要恢复节点和节点池来重复利用 AWS 实例,请输入以下命令恢复 HC control plane 命名空间中的对象:
AWS 命令
$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/awscl-*$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/awsmt-*$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/awsm-*机器的命令
$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machinedeployment-*$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machineset-*$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machine-*运行此 bash 脚本恢复 etcd 数据和托管集群:
ETCD_PODS="etcd-0" if [ "${CONTROL_PLANE_AVAILABILITY_POLICY}" = "HighlyAvailable" ]; then ETCD_PODS="etcd-0 etcd-1 etcd-2" fi HC_RESTORE_FILE=${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/hc-${HC_CLUSTER_NAME}-restore.yaml HC_BACKUP_FILE=${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/hc-${HC_CLUSTER_NAME}.yaml HC_NEW_FILE=${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/hc-${HC_CLUSTER_NAME}-new.yaml cat ${HC_BACKUP_FILE} > ${HC_NEW_FILE} cat > ${HC_RESTORE_FILE} <<EOF restoreSnapshotURL: EOF for POD in ${ETCD_PODS}; do # Create a pre-signed URL for the etcd snapshot ETCD_SNAPSHOT="s3://${BUCKET_NAME}/${HC_CLUSTER_NAME}-${POD}-snapshot.db" ETCD_SNAPSHOT_URL=$(AWS_DEFAULT_REGION=${MGMT2_REGION} aws s3 presign ${ETCD_SNAPSHOT}) # FIXME no CLI support for restoreSnapshotURL yet cat >> ${HC_RESTORE_FILE} <<EOF - "${ETCD_SNAPSHOT_URL}" EOF done cat ${HC_RESTORE_FILE} if ! grep ${HC_CLUSTER_NAME}-snapshot.db ${HC_NEW_FILE}; then sed -i '' -e "/type: PersistentVolume/r ${HC_RESTORE_FILE}" ${HC_NEW_FILE} sed -i '' -e '/pausedUntil:/d' ${HC_NEW_FILE} fi HC=$(oc get hc -n ${HC_CLUSTER_NS} ${HC_CLUSTER_NAME} -o name || true) if [[ ${HC} == "" ]];then echo "Deploying HC Cluster: ${HC_CLUSTER_NAME} in ${HC_CLUSTER_NS} namespace" oc apply -f ${HC_NEW_FILE} else echo "HC Cluster ${HC_CLUSTER_NAME} already exists, avoiding step" fi如果您要恢复节点和节点池来重复利用 AWS 实例,请输入以下命令恢复节点池:
$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/np-*
验证
要验证节点是否已完全恢复,请使用此功能:
timeout=40 count=0 NODE_STATUS=$(oc get nodes --kubeconfig=${HC_KUBECONFIG} | grep -v NotReady | grep -c "worker") || NODE_STATUS=0 while [ ${NODE_POOL_REPLICAS} != ${NODE_STATUS} ] do echo "Waiting for Nodes to be Ready in the destination MGMT Cluster: ${MGMT2_CLUSTER_NAME}" echo "Try: (${count}/${timeout})" sleep 30 if [[ $count -eq timeout ]];then echo "Timeout waiting for Nodes in the destination MGMT Cluster" exit 1 fi count=$((count+1)) NODE_STATUS=$(oc get nodes --kubeconfig=${HC_KUBECONFIG} | grep -v NotReady | grep -c "worker") || NODE_STATUS=0 done
后续步骤
关闭并删除集群。
5.4.4.5. 从源集群中删除托管集群
备份托管集群并将其恢复到目标管理集群后,您将关闭并删除源管理集群中的托管集群。
先决条件
您备份了数据并将其恢复到源管理集群。
确保目标管理集群的 kubeconfig 文件放置在 KUBECONFIG 变量中,或者在 MGMT_KUBECONFIG 变量中设置。使用 export KUBECONFIG=<Kubeconfig FilePath> 或使用脚本,请使用 export KUBECONFIG=${MGMT_KUBECONFIG}。
流程
输入以下命令来扩展
deployment和statefulset对象:$ export KUBECONFIG=${MGMT_KUBECONFIG}缩减部署命令
$ oc scale deployment -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --replicas=0 --all$ oc scale statefulset.apps -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --replicas=0 --all$ sleep 15输入以下命令来删除
NodePool对象:NODEPOOLS=$(oc get nodepools -n ${HC_CLUSTER_NS} -o=jsonpath='{.items[?(@.spec.clusterName=="'${HC_CLUSTER_NAME}'")].metadata.name}') if [[ ! -z "${NODEPOOLS}" ]];then oc patch -n "${HC_CLUSTER_NS}" nodepool ${NODEPOOLS} --type=json --patch='[ { "op":"remove", "path": "/metadata/finalizers" }]' oc delete np -n ${HC_CLUSTER_NS} ${NODEPOOLS} fi输入以下命令删除
machine和machineset对象:# Machines for m in $(oc get machines -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name); do oc patch -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} ${m} --type=json --patch='[ { "op":"remove", "path": "/metadata/finalizers" }]' || true oc delete -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} ${m} || true done$ oc delete machineset -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --all || true输入以下命令删除集群对象:
$ C_NAME=$(oc get cluster -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name)$ oc patch -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} ${C_NAME} --type=json --patch='[ { "op":"remove", "path": "/metadata/finalizers" }]'$ oc delete cluster.cluster.x-k8s.io -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --all输入这些命令来删除 AWS 机器 (Kubernetes 对象)。不用担心删除实际的 AWS 机器。云实例不会受到影响。
for m in $(oc get awsmachine.infrastructure.cluster.x-k8s.io -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name) do oc patch -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} ${m} --type=json --patch='[ { "op":"remove", "path": "/metadata/finalizers" }]' || true oc delete -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} ${m} || true done输入以下命令删除
HostedControlPlane和ControlPlaneHC 命名空间对象:删除 HCP 和 ControlPlane HC NS 命令
$ oc patch -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} hostedcontrolplane.hypershift.openshift.io ${HC_CLUSTER_NAME} --type=json --patch='[ { "op":"remove", "path": "/metadata/finalizers" }]'$ oc delete hostedcontrolplane.hypershift.openshift.io -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --all$ oc delete ns ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} || true输入以下命令删除
HostedCluster和 HC 命名空间对象:删除 HC 和 HC 命名空间命令
$ oc -n ${HC_CLUSTER_NS} patch hostedclusters ${HC_CLUSTER_NAME} -p '{"metadata":{"finalizers":null}}' --type merge || true$ oc delete hc -n ${HC_CLUSTER_NS} ${HC_CLUSTER_NAME} || true$ oc delete ns ${HC_CLUSTER_NS} || true
验证
要验证所有内容是否正常工作,请输入以下命令:
验证命令
$ export KUBECONFIG=${MGMT2_KUBECONFIG}$ oc get hc -n ${HC_CLUSTER_NS}$ oc get np -n ${HC_CLUSTER_NS}$ oc get pod -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}$ oc get machines -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}HostedCluster 内的命令
$ export KUBECONFIG=${HC_KUBECONFIG}$ oc get clusterversion$ oc get nodes
后续步骤
删除托管的集群中的 OVN pod,以便您可以连接到新管理集群中运行的新 OVN control plane:
-
使用托管的集群的 kubeconfig 路径加载
KUBECONFIG环境变量。 输入这个命令:
$ oc delete pod -n openshift-ovn-kubernetes --all
5.4.4.6. 运行脚本来备份和恢复托管集群
要加快进程来备份托管集群并在 AWS 上的同一区域恢复它,您可以修改并运行脚本。
流程
将以下脚本中的变量替换为您的信息:
# Fill the Common variables to fit your environment, this is just a sample SSH_KEY_FILE=${HOME}/.ssh/id_rsa.pub BASE_PATH=${HOME}/hypershift BASE_DOMAIN="aws.sample.com" PULL_SECRET_FILE="${HOME}/pull_secret.json" AWS_CREDS="${HOME}/.aws/credentials" CONTROL_PLANE_AVAILABILITY_POLICY=SingleReplica HYPERSHIFT_PATH=${BASE_PATH}/src/hypershift HYPERSHIFT_CLI=${HYPERSHIFT_PATH}/bin/hypershift HYPERSHIFT_IMAGE=${HYPERSHIFT_IMAGE:-"quay.io/${USER}/hypershift:latest"} NODE_POOL_REPLICAS=${NODE_POOL_REPLICAS:-2} # MGMT Context MGMT_REGION=us-west-1 MGMT_CLUSTER_NAME="${USER}-dev" MGMT_CLUSTER_NS=${USER} MGMT_CLUSTER_DIR="${BASE_PATH}/hosted_clusters/${MGMT_CLUSTER_NS}-${MGMT_CLUSTER_NAME}" MGMT_KUBECONFIG="${MGMT_CLUSTER_DIR}/kubeconfig" # MGMT2 Context MGMT2_CLUSTER_NAME="${USER}-dest" MGMT2_CLUSTER_NS=${USER} MGMT2_CLUSTER_DIR="${BASE_PATH}/hosted_clusters/${MGMT2_CLUSTER_NS}-${MGMT2_CLUSTER_NAME}" MGMT2_KUBECONFIG="${MGMT2_CLUSTER_DIR}/kubeconfig" # Hosted Cluster Context HC_CLUSTER_NS=clusters HC_REGION=us-west-1 HC_CLUSTER_NAME="${USER}-hosted" HC_CLUSTER_DIR="${BASE_PATH}/hosted_clusters/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}" HC_KUBECONFIG="${HC_CLUSTER_DIR}/kubeconfig" BACKUP_DIR=${HC_CLUSTER_DIR}/backup BUCKET_NAME="${USER}-hosted-${MGMT_REGION}" # DNS AWS_ZONE_ID="Z026552815SS3YPH9H6MG" EXTERNAL_DNS_DOMAIN="guest.jpdv.aws.kerbeross.com"- 将脚本保存到本地文件系统中。
输入以下命令运行脚本:
source <env_file>其中:
env_file是保存脚本的文件的名称。迁移脚本在以下软件仓库中维护:https://github.com/openshift/hypershift/blob/main/contrib/migration/migrate-hcp.sh。