4.4. DMN decision logic in boxed expressions
Boxed expressions in DMN are tables that you use to define the underlying logic of decision nodes and business knowledge models in a decision requirements diagram (DRD). Some boxed expressions can contain other boxed expressions, but the top-level boxed expression corresponds to the decision logic of a single DRD artifact. While DRDs represent the flow of a DMN decision model, boxed expressions define the actual decision logic of individual nodes. DRDs and boxed expressions together form a complete and functional DMN decision model.
The following are the types of DMN boxed expressions:
- Decision tables
- Literal expressions
- Contexts
- Relations
- Functions
- Invocations
- Lists
Red Hat Decision Manager does not provide boxed list expressions in Business Central, but supports a FEEL list data type that you can use in boxed literal expressions. For more information about the list data type and other FEEL data types in Red Hat Decision Manager, see 「Data types in FEEL」.
All Friendly Enough Expression Language (FEEL) expressions that you use in your boxed expressions must conform to the FEEL syntax requirements in the OMG Decision Model and Notation specification.
4.4.1. DMN decision tables
A decision table in DMN is a visual representation of one or more business rules in a tabular format. You use decision tables to define rules for a decision node that applies those rules at a given point in the decision model. Each rule consists of a single row in the table, and includes columns that define the conditions (input) and outcome (output) for that particular row. The definition of each row is precise enough to derive the outcome using the values of the conditions. Input and output values can be FEEL expressions or defined data type values.
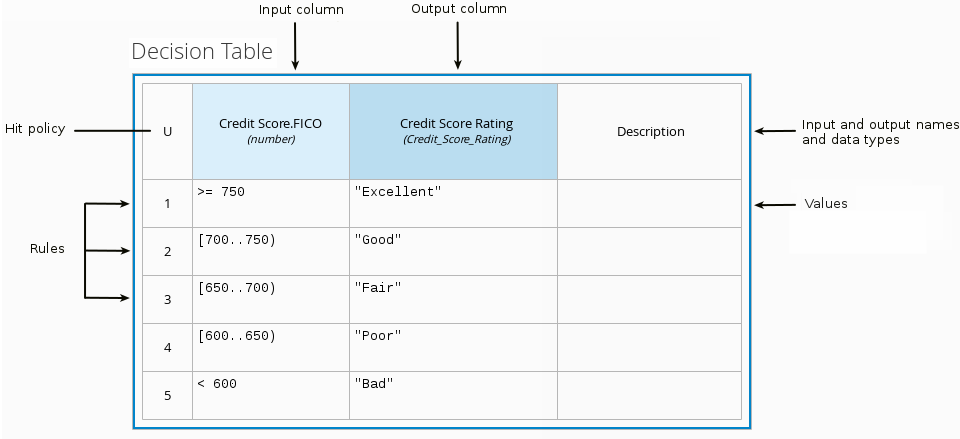
For example, the following decision table determines credit score ratings based on a defined range of a loan applicant’s credit score:
図4.3 Decision table for credit score rating
The following decision table determines the next step in a lending strategy for applicants depending on applicant loan eligibility and the bureau call type:
図4.4 Decision table for lending strategy

The following decision table determines applicant qualification for a loan as the concluding decision node in a loan prequalification decision model:
図4.5 Decision table for loan prequalification

Decision tables are a popular way of modeling rules and decision logic, and are used in many methodologies (such as DMN) and implementation frameworks (such as Drools).
Red Hat Decision Manager supports both DMN decision tables and Drools-native decision tables, but they are different types of assets with different syntax requirements and are not interchangeable. For more information about Drools-native decision tables in Red Hat Decision Manager, see Designing a decision service using spreadsheet decision tables.
4.4.1.1. Hit policies in DMN decision tables
Hit policies determine how to reach an outcome when multiple rules in a decision table match the provided input values. For example, if one rule in a decision table applies a sales discount to military personnel and another rule applies a discount to students, then when a customer is both a student and in the military, the decision table hit policy must indicate whether to apply one discount or the other (Unique, First) or both discounts (Collect Sum). You specify the single character of the hit policy (U, F, C+) in the upper-left corner of the decision table.
The following decision table hit policies are supported in DMN:
- Unique (U): Permits only one rule to match. Any overlap raises an error.
- Any (A): Permits multiple rules to match, but they must all have the same output. If multiple matching rules do not have the same output, an error is raised.
- Priority (P): Permits multiple rules to match, with different outputs. The output that comes first in the output values list is selected.
- First (F): Uses the first match in rule order.
Collect (C+, C>, C<, C#): Aggregates output from multiple rules based on an aggregation function.
- Collect ( C ): Aggregates values in an arbitrary list.
- Collect Sum (C+): Outputs the sum of all collected values. Values must be numeric.
- Collect Min (C<): Outputs the minimum value among the matches. The resulting values must be comparable, such as numbers, dates, or text (lexicographic order).
- Collect Max (C>): Outputs the maximum value among the matches. The resulting values must be comparable, such as numbers, dates or text (lexicographic order).
- Collect Count (C#): Outputs the number of matching rules.