4.10. 문제 해결
OpenShift CLI 툴 또는 Velero CLI 툴 을 사용하여 Velero CR(사용자 정의 리소스)을 디버깅할 수 있습니다. Velero CLI 툴에서는 자세한 로그 및 정보를 제공합니다.
설치 문제,백업 및 복원 CR 문제, Restic 문제 등을 확인할 수 있습니다.
must-gather 툴 을 사용하여 로그 및 CR 정보를 수집할 수 있습니다.
다음을 통해 Velero CLI 툴을 가져올 수 있습니다.
- Velero CLI 툴 다운로드
- 클러스터의 Velero 배포에서 Velero 바이너리에 액세스
4.10.1. Velero CLI 툴 다운로드
Velero 문서 페이지의 지침에 따라 Velero CLI 툴을 다운로드하여 설치할 수 있습니다.
페이지에는 다음에 대한 지침이 포함되어 있습니다.
- Homebrew를 사용하여 macOS
- GitHub
- Chocolatey를 사용하여 Windows
사전 요구 사항
- DNS 및 컨테이너 네트워킹이 활성화된 Kubernetes 클러스터 v1.16 이상에 액세스할 수 있습니다.
-
kubectl을 로컬로 설치했습니다.
절차
- 브라우저를 열고 Velero 웹 사이트에서 "Install the CLI" 로 이동합니다.
- macOS, GitHub 또는 Windows에 대한 적절한 절차를 따르십시오.
- OADP 및 OpenShift Container Platform 버전에 적합한 Velero 버전을 다운로드합니다.
4.10.1.1. OADP-Velero-OpenShift Container Platform 버전 관계
4.10.2. 클러스터의 Velero 배포에서 Velero 바이너리에 액세스
shell 명령을 사용하여 클러스터의 Velero 배포에서 Velero 바이너리에 액세스할 수 있습니다.
사전 요구 사항
-
DataProtectionApplication사용자 정의 리소스의 상태는Reconcile complete.
절차
다음 명령을 입력하여 필요한 별칭을 설정합니다.
$ alias velero='oc -n openshift-adp exec deployment/velero -c velero -it -- ./velero'
4.10.3. OpenShift CLI 툴을 사용하여 Velero 리소스 디버깅
OpenShift CLI 툴을 사용하여 Velero CR(사용자 정의 리소스) 및 Velero 포드 로그를 확인하여 실패한 백업 또는 복원을 디버깅할 수 있습니다.
Velero CR
oc describe 명령을 사용하여 백업 또는 복원 CR과 관련된 경고 및 오류 요약을 검색합니다.
$ oc describe <velero_cr> <cr_name>Velero Pod 로그
oc logs 명령을 사용하여 Velero Pod 로그를 검색합니다.
$ oc logs pod/<velero>Velero Pod 디버그 로그
다음 예와 같이 DataProtectionApplication 리소스에서 Velero 로그 수준을 지정할 수 있습니다.
이 옵션은 OADP 1.0.3부터 사용할 수 있습니다.
apiVersion: oadp.openshift.io/v1alpha1
kind: DataProtectionApplication
metadata:
name: velero-sample
spec:
configuration:
velero:
logLevel: warning
다음 logLevel 값을 사용할 수 있습니다.
-
trace -
debug -
info -
경고 -
error -
fatal -
panic
대부분의 로그에 debug 를 사용하는 것이 좋습니다.
4.10.4. Velero CLI 툴을 사용하여 Velero 리소스 디버깅
Backup 및 Restore CR(사용자 정의 리소스)을 디버그하고 Velero CLI 툴을 사용하여 로그를 검색할 수 있습니다.
Velero CLI 툴은 OpenShift CLI 툴보다 자세한 정보를 제공합니다.
구문
oc exec 명령을 사용하여 Velero CLI 명령을 실행합니다.
$ oc -n openshift-adp exec deployment/velero -c velero -- ./velero \
<backup_restore_cr> <command> <cr_name>예제
$ oc -n openshift-adp exec deployment/velero -c velero -- ./velero \
backup describe 0e44ae00-5dc3-11eb-9ca8-df7e5254778b-2d8ql도움말 옵션
velero --help 옵션을 사용하여 모든 Velero CLI 명령을 나열합니다.
$ oc -n openshift-adp exec deployment/velero -c velero -- ./velero \
--helpDescribe 명령
velero describe 명령을 사용하여 Backup 또는 Restore CR과 관련된 경고 및 오류 요약을 검색합니다.
$ oc -n openshift-adp exec deployment/velero -c velero -- ./velero \
<backup_restore_cr> describe <cr_name>예제
$ oc -n openshift-adp exec deployment/velero -c velero -- ./velero \
backup describe 0e44ae00-5dc3-11eb-9ca8-df7e5254778b-2d8qlLogs 명령
velero logs 명령을 사용하여 Backup 또는 Restore CR의 로그를 검색합니다.
$ oc -n openshift-adp exec deployment/velero -c velero -- ./velero \
<backup_restore_cr> logs <cr_name>예제
$ oc -n openshift-adp exec deployment/velero -c velero -- ./velero \
restore logs ccc7c2d0-6017-11eb-afab-85d0007f5a19-x4lbf4.10.5. 메모리 또는 CPU 부족으로 인해 Pod 충돌 또는 재시작
메모리 또는 CPU 부족으로 인해 Velero 또는 Restic Pod가 충돌하는 경우 해당 리소스 중 하나에 대한 특정 리소스 요청을 설정할 수 있습니다.
4.10.5.1. Velero Pod에 대한 리소스 요청 설정
oadp_v1alpha1_dpa.yaml 파일에서 configuration.velero.podConfig.resourceAllocations 사양 필드를 사용하여 Velero Pod에 대한 특정 리소스 요청을 설정할 수 있습니다.
절차
YAML 파일에서
cpu및memory리소스 요청을 설정합니다.Velero 파일의 예
apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication ... configuration: velero: podConfig: resourceAllocations:1 requests: cpu: 200m memory: 256Mi- 1
- 나열된
resourceAllocations는 평균 사용량입니다.
4.10.5.2. Restic Pod에 대한 리소스 요청 설정
configuration.restic.podConfig.resourceAllocations 사양 필드를 사용하여 Restic Pod에 대한 특정 리소스 요청을 설정할 수 있습니다.
절차
YAML 파일에서
cpu및memory리소스 요청을 설정합니다.Restic 파일 예
apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication ... configuration: restic: podConfig: resourceAllocations:1 requests: cpu: 1000m memory: 16Gi- 1
- 나열된
resourceAllocations는 평균 사용량입니다.
리소스 요청 필드의 값은 Kubernetes 리소스 요구 사항과 동일한 형식을 따라야 합니다. 또한 configuration.velero.podConfig.resourceAllocations 또는 configuration.restic.podConfig.resourceAllocations 를 지정하지 않으면 Velero Pod 또는 Restic Pod의 기본 리소스 사양은 다음과 같습니다.
requests:
cpu: 500m
memory: 128Mi4.10.6. Velero 및 승인 Webhook 관련 문제
Velero는 복원 중 승인 Webhook 문제를 해결할 수 있는 기능이 제한되어 있습니다. 승인 Webhook가 있는 워크로드가 있는 경우 추가 Velero 플러그인을 사용하거나 워크로드를 복원하는 방법을 변경해야 할 수 있습니다.
일반적으로 승인 Webhook가 있는 워크로드에서는 먼저 특정 종류의 리소스를 생성해야 합니다. 승인 Webhook가 일반적으로 하위 리소스를 차단하기 때문에 워크로드에 하위 리소스가 있는 경우 특히 중요합니다.
예를 들어 service.serving.knative.dev 와 같은 최상위 오브젝트를 생성하거나 복원하면 일반적으로 하위 리소스가 자동으로 생성됩니다. 먼저 이 작업을 수행하는 경우 Velero를 사용하여 이러한 리소스를 생성하고 복원할 필요가 없습니다. 그러면 Velero가 사용할 수 있는 승인 Webhook에 의해 차단되는 하위 리소스의 문제를 방지할 수 있습니다.
4.10.6.1. 승인 Webhook를 사용하는 Velero 백업의 해결방법 복원
이 섹션에서는 승인 Webhook를 사용하는 여러 유형의 Velero 백업에 대한 리소스를 복원하는 데 필요한 추가 단계를 설명합니다.
4.10.6.1.1. Knative 리소스 복원
승인 Webhook를 사용하는 Knative 리소스를 백업하려면 Velero를 사용하여 문제가 발생할 수 있습니다.
승인 Webhook를 사용하는 Knative 리소스를 백업 및 복원할 때마다 최상위 서비스 리소스를 복원하여 이러한 문제를 방지할 수 있습니다.
절차
최상위
서비스.serving.knavtive.dev Service리소스를 복원합니다.$ velero restore <restore_name> \ --from-backup=<backup_name> --include-resources \ service.serving.knavtive.dev
4.10.6.1.2. IBM AppConnect 리소스 복원
승인 Webhook가 있는 IBM AppConnect 리소스를 복원하기 위해 Velero를 사용할 때 문제가 발생하는 경우 이 프로세스에서 검사를 실행할 수 있습니다.
절차
클러스터에 변경 승인 플러그인이 있는지 확인합니다
: MutatingWebhookConfiguration.$ oc get mutatingwebhookconfigurations-
각
kind: MutatingWebhookConfiguration의 YAML 파일을 검사하여 문제가 발생한 오브젝트의 규칙 블록 생성이 없는지 확인합니다. 자세한 내용은 공식 Kubernetes 설명서를 참조하십시오. -
유형에 있는이 설치된 Operator에서 지원되는지 확인합니다.spec.version: Configuration.appconnect.ibm.com/v1beta1
4.10.6.2. Velero 플러그인에서 "received EOF, stop recv loop" 메시지를 반환
Velero 플러그인은 별도의 프로세스로 시작됩니다. Velero 작업이 성공적으로 완료되거나 실패하면 종료됩니다. 디버그 로그에서 recv 루프 메시지를 중지하여 수신된 EOF 를 수신하면 플러그인 작업이 완료되었음을 나타냅니다. 이는 오류가 발생했음을 의미하지 않습니다.
4.10.7. 설치 문제
데이터 보호 애플리케이션을 설치할 때 유효하지 않은 디렉토리 또는 잘못된 자격 증명을 사용하여 발생한 문제가 발생할 수 있습니다.
4.10.7.1. 백업 스토리지에 잘못된 디렉터리가 포함되어 있습니다.
Velero 포드 로그에 오류 메시지가 표시되고 Backup 스토리지에 잘못된 최상위 디렉터리가 포함되어 있습니다.
원인
오브젝트 스토리지에는 Velero 디렉터리가 아닌 최상위 디렉터리가 포함되어 있습니다.
해결책
오브젝트 스토리지가 Velero에 전용되지 않은 경우 DataProtectionApplication 매니페스트에서 spec.backupLocations.velero.objectStorage.prefix 매개변수를 설정하여 버킷의 접두사를 지정해야 합니다.
4.10.7.2. 잘못된 AWS 인증 정보
oadp-aws-registry Pod 로그에 오류 메시지 InvalidAccessKeyId: AWS Access Key Id가 기록에 존재하지 않습니다.
Velero 포드 로그에 오류 메시지 NoCredentialProviders: no valid providers in chain 을 표시합니다.
원인
Secret 오브젝트를 생성하는 데 사용되는 credentials-velero 파일이 잘못 포맷됩니다.
해결책
다음 예와 같이 credentials-velero 파일이 올바르게 포맷되었는지 확인합니다.
credentials-velero 파일의 예
[default]
aws_access_key_id=AKIAIOSFODNN7EXAMPLE
aws_secret_access_key=wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY4.10.8. OADP Operator 문제
OADP(OpenShift API for Data Protection) Operator는 해결할 수 없는 문제로 인해 문제가 발생할 수 있습니다.
4.10.8.1. OADP Operator가 자동으로 실패
OADP Operator의 S3 버킷은 비어 있을 수 있지만 oc get po -n <OADP_Operator_namespace> 명령을 실행하면 Operator의 상태가 임을 확인할 수 있습니다. 이러한 경우 Operator는 실행 중이라고 잘못 보고하기 때문에 자동으로 실패했다고 합니다.
Running
원인
클라우드 인증 정보가 충분하지 않은 권한을 제공하는 경우 문제가 발생합니다.
해결책
백업 스토리지 위치(BSL) 목록을 검색하고 인증 정보 문제는 각 BSL의 매니페스트를 확인합니다.
절차
다음 명령 중 하나를 실행하여 BSL 목록을 검색합니다.
OpenShift CLI 사용:
$ oc get backupstoragelocation -AVelero CLI 사용:
$ velero backup-location get -n <OADP_Operator_namespace>
BSL 목록을 사용하여 다음 명령을 실행하여 각 BSL의 매니페스트를 표시하고 각 매니페스트에 오류가 있는지 검사합니다.
$ oc get backupstoragelocation -n <namespace> -o yaml
결과 예
apiVersion: v1
items:
- apiVersion: velero.io/v1
kind: BackupStorageLocation
metadata:
creationTimestamp: "2023-11-03T19:49:04Z"
generation: 9703
name: example-dpa-1
namespace: openshift-adp-operator
ownerReferences:
- apiVersion: oadp.openshift.io/v1alpha1
blockOwnerDeletion: true
controller: true
kind: DataProtectionApplication
name: example-dpa
uid: 0beeeaff-0287-4f32-bcb1-2e3c921b6e82
resourceVersion: "24273698"
uid: ba37cd15-cf17-4f7d-bf03-8af8655cea83
spec:
config:
enableSharedConfig: "true"
region: us-west-2
credential:
key: credentials
name: cloud-credentials
default: true
objectStorage:
bucket: example-oadp-operator
prefix: example
provider: aws
status:
lastValidationTime: "2023-11-10T22:06:46Z"
message: "BackupStorageLocation \"example-dpa-1\" is unavailable: rpc
error: code = Unknown desc = WebIdentityErr: failed to retrieve credentials\ncaused
by: AccessDenied: Not authorized to perform sts:AssumeRoleWithWebIdentity\n\tstatus
code: 403, request id: d3f2e099-70a0-467b-997e-ff62345e3b54"
phase: Unavailable
kind: List
metadata:
resourceVersion: ""4.10.9. OADP 시간 초과
시간 제한을 늘리면 복잡하고 리소스를 많이 사용하는 프로세스가 조기 종료되지 않고 성공적으로 완료할 수 있습니다. 이 구성을 사용하면 오류, 재시도 또는 실패 가능성을 줄일 수 있습니다.
프로세스의 기본 문제를 숨길 수 있는 과도하게 긴 시간 초과를 구성하지 않도록 시간 초과 확장의 균형을 조정해야 합니다. 프로세스 및 전체 시스템 성능을 충족하는 적절한 시간 초과 값을 신중하게 고려하고 모니터링합니다.
다음은 이러한 매개변수를 구현하는 방법과 시기에 대한 지침이 포함된 다양한 OADP 시간 초과입니다.
4.10.9.1. Restic 타임아웃
시간 초과는 Restic 타임아웃을 정의합니다. 기본값은 1h 입니다.
다음 시나리오에 대해 Restic 타임아웃 을 사용합니다.
- 500GB보다 큰 총 PV 데이터 사용량이 있는 Restic 백업의 경우
다음 오류로 인해 백업이 시간 초과되는 경우:
level=error msg="Error backing up item" backup=velero/monitoring error="timed out waiting for all PodVolumeBackups to complete"
절차
다음 예와 같이
DataProtectionApplicationCR 매니페스트의spec.configuration.restic.timeout블록에서 값을 편집합니다.apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_name> spec: configuration: restic: timeout: 1h # ...
4.10.9.2. Velero 리소스 시간 초과
resourceTimeout 은 Velero CRD(사용자 정의 리소스 정의) 가용성, volumeSnapshot 삭제 및 리포지토리 가용성과 같이 시간 초과가 발생하기 전에 여러 Velero 리소스를 대기하는 시간을 정의합니다. 기본값은 10m 입니다.
다음 시나리오에 대해 resourceTimeout 을 사용합니다.
총 PV 데이터 사용량이 1TB 이상인 백업의 경우 이 매개 변수는 Velero가 백업을 완료로 표시하기 전에 CSI(Container Storage Interface) 스냅샷을 정리하거나 삭제하려고 할 때 시간 초과 값으로 사용됩니다.
- 이 정리의 하위 작업은 VSC 패치를 시도하며 이 시간 초과는 해당 작업에 사용할 수 있습니다.
- Restic 또는 Kopia에 대한 파일 시스템 기반 백업에 대한 백업 리포지토리를 생성하거나 확인하려면 다음을 수행합니다.
- CR(사용자 정의 리소스) 또는 리소스를 백업에서 복원하기 전에 클러스터에서 Velero CRD를 사용할 수 있는지 확인하려면 다음을 수행합니다.
절차
다음 예제와 같이
DataProtectionApplicationCR 매니페스트의spec.configuration.velero.resourceTimeout블록에서 값을 편집합니다.apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_name> spec: configuration: velero: resourceTimeout: 10m # ...
4.10.9.3. 데이터 Mover 시간 초과
timeout 은 VolumeSnapshotBackup 및 VolumeSnapshotRestore 를 완료하는 사용자 제공 타임아웃입니다. 기본값은 10m 입니다.
다음 시나리오에 대해 Data Mover 시간 초과 를 사용합니다.
-
VolumeSnapshotBackups(VSB) 및VolumeSnapshotRestores(VSR)를 생성하는 경우 10분 후에 시간 초과됩니다. -
총 PV 데이터 사용량이 500GB 이상인 대규모 환경의 경우
1h에 시간 제한을 설정합니다. -
VolumeSnapshotMover(VSM) 플러그인 사용 - OADP 1.1.x에서만 사용
절차
다음 예제와 같이
DataProtectionApplicationCR 매니페스트의spec.features.dataMover.timeout블록에서 값을 편집합니다.apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_name> spec: features: dataMover: timeout: 10m # ...
4.10.9.4. CSI 스냅샷 시간 초과
CSISnapshotTimeout 은 오류를 시간 초과로 반환하기 전에 CSI VolumeSnapshot 상태가 ReadyToUse 상태가 될 때까지 대기하는 시간을 지정합니다. 기본값은 10m 입니다.
다음 시나리오에 CSISnapshotTimeout 을 사용합니다.
- CSI 플러그인 사용
- 스냅샷에 10분 이상 걸릴 수 있는 대용량 스토리지 볼륨의 경우. 로그에 시간 초과가 있는 경우 이 시간 제한을 조정합니다.
일반적으로 기본 설정은 대규모 스토리지 볼륨을 수용할 수 있으므로 CSISnapshotTimeout 의 기본값을 조정할 필요가 없습니다.
절차
다음 예제와 같이
BackupCR 매니페스트의spec.csiSnapshotTimeout블록에서 값을 편집합니다.apiVersion: velero.io/v1 kind: Backup metadata: name: <backup_name> spec: csiSnapshotTimeout: 10m # ...
4.10.9.5. Velero 기본 항목 작업 시간 초과
DefaultItemOperationTimeout은 시간 초과 전에 비동기 BackupItemActions 및 RestoreItemActions 가 완료될 때까지 대기하는 시간을 정의합니다. 기본값은 1h 입니다.
다음 시나리오에 defaultItemOperationTimeout 을 사용합니다.
- Data Mover 1.2.x만 사용할 수 있습니다.
- 특정 백업 또는 복원이 완료될 때까지 대기해야 하는 시간을 지정하려면 다음을 수행합니다. OADP 기능의 컨텍스트에서 이 값은 CSI(Container Storage Interface) 데이터 Mover 기능과 관련된 비동기 작업에 사용됩니다.
-
defaultItemOperationTimeout이defaultItemOperationTimeout을 사용하여 DPA(Data Protection Application)에 정의되면 백업 및 복원 작업에 모두 적용됩니다.itemOperationTimeout을 사용하여 다음 "Item operation timeout - restore" 섹션과 "Item operation timeout - backup" 섹션에 설명된 대로 해당 CR의 백업 또는 복원만 정의할 수 있습니다.
절차
다음 예제와 같이
DataProtectionApplicationCR 매니페스트의spec.configuration.velero.defaultItemOperationTimeout블록에서 값을 편집합니다.apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_name> spec: configuration: velero: defaultItemOperationTimeout: 1h # ...
4.10.9.6. 항목 작업 시간 초과 - 복원
ItemOperationTimeout 은 RestoreItemAction 작업을 기다리는 데 사용되는 시간을 지정합니다. 기본값은 1h 입니다.
다음 시나리오에는 복원 ItemOperationTimeout 을 사용합니다.
- Data Mover 1.2.x만 사용할 수 있습니다.
-
Data Mover가
BackupStorageLocation에 업로드 및 다운로드되는 경우 . 시간 초과에 도달하면 복원 작업이 완료되지 않으면 실패로 표시됩니다. 스토리지 볼륨 크기 때문에 시간 초과 문제로 인해 데이터 Mover 작업이 실패하는 경우 이 시간 초과 설정을 늘려야 할 수 있습니다.
절차
다음 예제와 같이
RestoreCR 매니페스트의Restore.spec.itemOperationTimeout블록에서 값을 편집합니다.apiVersion: velero.io/v1 kind: Restore metadata: name: <restore_name> spec: itemOperationTimeout: 1h # ...
4.10.9.7. 항목 작업 제한 시간 - 백업
ItemOperationTimeout 은 비동기 BackupItemAction 작업을 대기하는 데 사용되는 시간을 지정합니다. 기본값은 1h 입니다.
다음 시나리오에는 ItemOperationTimeout 백업을 사용합니다.
- Data Mover 1.2.x만 사용할 수 있습니다.
-
Data Mover가
BackupStorageLocation에 업로드 및 다운로드되는 경우 . 시간 초과에 도달하면 백업 작업이 완료되지 않으면 실패로 표시됩니다. 스토리지 볼륨 크기 때문에 시간 초과 문제로 인해 데이터 Mover 작업이 실패하는 경우 이 시간 초과 설정을 늘려야 할 수 있습니다.
절차
다음 예제와 같이
BackupCR 매니페스트의Backup.spec.itemOperationTimeout블록에서 값을 편집합니다.apiVersion: velero.io/v1 kind: Backup metadata: name: <backup_name> spec: itemOperationTimeout: 1h # ...
4.10.10. CR 백업 및 복원
백업 및 복원 사용자 정의 리소스(CR)와 관련된 일반적인 문제가 발생할 수 있습니다.
4.10.10.1. Backup CR은 볼륨을 검색할 수 없습니다.
Backup CR에 오류 메시지 InvalidVolume.NotFound: 볼륨 'vol-xxxx'이 존재하지 않습니다.
원인
PV(영구 볼륨) 및 스냅샷 위치는 다른 지역에 있습니다.
해결책
-
스냅샷 위치가 PV와 동일한 리전에 있도록
DataProtectionApplication매니페스트의spec.snapshotLocations.velero.config.region키 값을 편집합니다. -
새
BackupCR을 생성합니다.
4.10.10.2. Backup CR 상태는 진행 중인 상태로 유지됩니다.
Backup CR의 상태는 InProgress 단계에 남아 있으며 완료되지 않습니다.
원인
백업이 중단된 경우 다시 시작할 수 없습니다.
해결책
BackupCR의 세부 정보를 검색합니다.$ oc -n {namespace} exec deployment/velero -c velero -- ./velero \ backup describe <backup>BackupCR을 삭제합니다.$ oc delete backup <backup> -n openshift-adp진행 중인
BackupCR이 오브젝트 스토리지에 파일을 업로드하지 않았기 때문에 백업 위치를 정리할 필요가 없습니다.-
새
BackupCR을 생성합니다.
4.10.10.3. Backup CR 상태는 PartiallyFailed에 남아 있습니다.
Restic이 사용되지 않은 Backup CR의 상태는 PartiallyFailed 단계에 남아 있으며 완료되지 않습니다. 관련 PVC의 스냅샷이 생성되지 않습니다.
원인
CSI 스냅샷 클래스를 기반으로 백업을 생성하지만 라벨이 누락된 경우 CSI 스냅샷 플러그인이 스냅샷을 생성하지 못합니다. 결과적으로 Velero pod는 다음과 유사한 오류를 기록합니다.
+
time="2023-02-17T16:33:13Z" level=error msg="Error backing up item" backup=openshift-adp/user1-backup-check5 error="error executing custom action (groupResource=persistentvolumeclaims, namespace=busy1, name=pvc1-user1): rpc error: code = Unknown desc = failed to get volumesnapshotclass for storageclass ocs-storagecluster-ceph-rbd: failed to get volumesnapshotclass for provisioner openshift-storage.rbd.csi.ceph.com, ensure that the desired volumesnapshot class has the velero.io/csi-volumesnapshot-class label" logSource="/remote-source/velero/app/pkg/backup/backup.go:417" name=busybox-79799557b5-vprq해결책
BackupCR을 삭제합니다.$ oc delete backup <backup> -n openshift-adp-
필요하면
BackupStorageLocation에서 저장된 데이터를 정리하여 공간을 확보합니다. VolumeSnapshotClass오브젝트에velero.io/csi-volumesnapshot-class=true라벨을 적용합니다.$ oc label volumesnapshotclass/<snapclass_name> velero.io/csi-volumesnapshot-class=true-
새
BackupCR을 생성합니다.
4.10.11. Restic 문제
Restic으로 애플리케이션을 백업할 때 이러한 문제가 발생할 수 있습니다.
4.10.11.1. root_squash가 활성화된 NFS 데이터 볼륨에 대한 Restic 권한 오류
Restic pod 로그에 오류 메시지 controller=pod-volume-backup error="fork/exec/usr/bin/restic: permission denied" 가 표시됩니다.
원인
NFS 데이터 볼륨에 root_squash 가 활성화된 경우 Restic 은 nfsnobody 에 매핑되고 백업을 생성할 수 있는 권한이 없습니다.
해결책
Restic 에 대한 추가 그룹을 생성하고 DataProtectionApplication 매니페스트에 그룹 ID를 추가하여 이 문제를 해결할 수 있습니다.
-
NFS 데이터 볼륨에서
Restic에 대한 보조 그룹을 생성합니다. -
그룹 소유권이 상속되도록 NFS 디렉터리에
setgid비트를 설정합니다. 다음 예제와 같이
spec.configuration.restic.supplementalGroups매개변수와 그룹 ID를DataProtectionApplication매니페스트에 추가합니다.spec: configuration: restic: enable: true supplementalGroups: - <group_id>1 - 1
- 보조 그룹 ID를 지정합니다.
-
변경 사항을 적용할 수 있도록
ResticPod가 다시 시작될 때까지 기다립니다.
4.10.11.2. bucket is emptied 후 Restic Backup CR을 다시 생성할 수 없습니다.
네임스페이스에 대한 Restic Backup CR을 생성하고 오브젝트 스토리지 버킷을 비우고 동일한 네임스페이스에 Backup CR을 다시 생성하면 다시 만든 Backup CR이 실패합니다.
velero Pod 로그에는 다음과 같은 오류 메시지가 표시됩니다. stderr=Fatal: unable to open config file: criteria: specified key does not exist.\nIs there a repository at the following location?.
원인
Velero는 Restic 디렉터리가 오브젝트 스토리지에서 삭제되면 ResticRepository 매니페스트에서 Restic 리포지토리를 다시 생성하거나 업데이트하지 않습니다. 자세한 내용은 Velero issue 4421 을 참조하십시오.
해결책
다음 명령을 실행하여 네임스페이스에서 관련 Restic 리포지토리를 제거합니다.
$ oc delete resticrepository openshift-adp <name_of_the_restic_repository>다음 오류 로그에서
mysql-persistent는 문제가 있는 Restic 리포지토리입니다. 저장소 이름은 명확성을 위해 이주에 표시됩니다.time="2021-12-29T18:29:14Z" level=info msg="1 errors encountered backup up item" backup=velero/backup65 logSource="pkg/backup/backup.go:431" name=mysql-7d99fc949-qbkds time="2021-12-29T18:29:14Z" level=error msg="Error backing up item" backup=velero/backup65 error="pod volume backup failed: error running restic backup, stderr=Fatal: unable to open config file: Stat: The specified key does not exist.\nIs there a repository at the following location?\ns3:http://minio-minio.apps.mayap-oadp- veleo-1234.qe.devcluster.openshift.com/mayapvelerooadp2/velero1/ restic/mysql-persistent\n: exit status 1" error.file="/remote-source/ src/github.com/vmware-tanzu/velero/pkg/restic/backupper.go:184" error.function="github.com/vmware-tanzu/velero/ pkg/restic.(*backupper).BackupPodVolumes" logSource="pkg/backup/backup.go:435" name=mysql-7d99fc949-qbkds
4.10.12. must-gather 툴 사용
must-gather 툴을 사용하여 OADP 사용자 정의 리소스에 대한 로그, 메트릭 및 정보를 수집할 수 있습니다.
must-gather 데이터는 모든 고객 사례에 첨부되어야 합니다.
사전 요구 사항
-
cluster-admin역할의 사용자로 OpenShift Container Platform 클러스터에 로그인해야 합니다. -
OpenShift CLI(
oc)가 설치되어 있어야 합니다.
절차
-
must-gather데이터를 저장하려는 디렉터리로 이동합니다. 다음 데이터 수집 옵션 중 하나에 대해
oc adm must-gather명령을 실행합니다.$ oc adm must-gather --image=registry.redhat.io/oadp/oadp-mustgather-rhel8:v1.1데이터는
must-gather/must-gather.tar.gz로 저장됩니다. Red Hat 고객 포털에서 해당 지원 사례에 이 파일을 업로드할 수 있습니다.$ oc adm must-gather --image=registry.redhat.io/oadp/oadp-mustgather-rhel8:v1.1 \ -- /usr/bin/gather_metrics_dump이 작업에는 오랜 시간이 걸릴 수 있습니다. 데이터는
must-gather/metrics/prom_data.tar.gz로 저장됩니다.
4.10.12.1. must-gather 툴을 사용할 때 옵션 결합
현재 must-gather 스크립트를 결합할 수 없습니다(예: 비보안 TLS 연결을 허용하는 동안 시간 초과 임계값 지정). 다음 예와 같이 must-gather 명령줄에서 내부 변수를 설정하여 이러한 제한 사항을 해결할 수 있습니다.
$ oc adm must-gather --image=brew.registry.redhat.io/rh-osbs/oadp-oadp-mustgather-rhel8:1.1.1-8 -- skip_tls=true /usr/bin/gather_with_timeout <timeout_value_in_seconds>
이 예제에서는 gather_with_timeout 스크립트를 실행하기 전에 skip_tls 변수를 설정합니다. 결과는 gather_with_timeout 및 gather_without_tls 의 조합입니다.
이렇게 지정할 수 있는 다른 변수는 다음과 같습니다.
-
logs_since기본 값이72h -
request_timeout, 기본값0s
4.10.13. OADP 모니터링
OpenShift Container Platform에서는 사용자와 관리자가 클러스터를 효과적으로 모니터링 및 관리할 수 있는 모니터링 스택을 제공하고, 이벤트가 발생하는 경우 경고 수신을 포함하여 클러스터에서 실행되는 사용자 애플리케이션 및 서비스의 워크로드 성능을 모니터링 및 분석할 수 있습니다.
4.10.13.1. OADP 모니터링 설정
OADP Operator는 Velero 서비스 끝점에서 지표를 검색하기 위해 OpenShift 모니터링 스택에서 제공하는 OpenShift 사용자 워크로드 모니터링을 활용합니다. 모니터링 스택을 사용하면 OpenShift Metrics 쿼리 프런트 엔드를 사용하여 사용자 정의 경고 규칙을 생성하거나 지표를 쿼리할 수 있습니다.
활성화된 사용자 워크로드 모니터링을 사용하면 Grafana와 같은 Prometheus 호환 타사 UI를 구성하고 사용하여 Velero 지표를 시각화할 수 있습니다.
메트릭을 모니터링하려면 사용자 정의 프로젝트를 모니터링하고 ServiceMonitor 리소스를 생성하여 openshift-adp 네임스페이스에 있는 이미 활성화된 OADP 서비스 끝점에서 해당 메트릭을 스크랩해야 합니다.
사전 요구 사항
-
cluster-admin권한이 있는 계정을 사용하여 OpenShift Container Platform 클러스터에 액세스할 수 있습니다. - 클러스터 모니터링 구성 맵이 생성되어 있습니다.
절차
openshift-monitoring네임스페이스에서cluster-monitoring-configConfigMap오브젝트를 편집합니다.$ oc edit configmap cluster-monitoring-config -n openshift-monitoringdata섹션의config.yaml필드에enableUserWorkload옵션을 추가하거나 활성화합니다.apiVersion: v1 data: config.yaml: | enableUserWorkload: true1 kind: ConfigMap metadata: # ...- 1
- 이 옵션을 추가하거나
true로 설정합니다.
다음 구성 요소가
openshift-user-workload-monitoring네임스페이스에서 실행 중인지 확인하여 짧은 시간 동안 User Workload Monitoring Setup을 확인합니다.$ oc get pods -n openshift-user-workload-monitoring출력 예
NAME READY STATUS RESTARTS AGE prometheus-operator-6844b4b99c-b57j9 2/2 Running 0 43s prometheus-user-workload-0 5/5 Running 0 32s prometheus-user-workload-1 5/5 Running 0 32s thanos-ruler-user-workload-0 3/3 Running 0 32s thanos-ruler-user-workload-1 3/3 Running 0 32sopenshift-user-workload-monitoring에user-workload-monitoring-configConfigMap이 있는지 확인합니다. 존재하는 경우 이 절차의 나머지 단계를 건너뜁니다.$ oc get configmap user-workload-monitoring-config -n openshift-user-workload-monitoring출력 예
Error from server (NotFound): configmaps "user-workload-monitoring-config" not foundUser Workload Monitoring에 대한
user-workload-monitoring-configConfigMap오브젝트를 생성하고2_configure_user_workload_monitoring.yaml파일 이름에 저장합니다.출력 예
apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: |2_configure_user_workload_monitoring.yaml파일을 적용합니다.$ oc apply -f 2_configure_user_workload_monitoring.yaml configmap/user-workload-monitoring-config created
4.10.13.2. OADP 서비스 모니터 생성
OADP는 DPA가 구성될 때 생성되는 openshift-adp-velero-metrics-svc 서비스를 제공합니다. 사용자 워크로드 모니터링에서 사용하는 서비스 모니터는 정의된 서비스를 가리켜야 합니다.
다음 명령을 실행하여 서비스에 대한 세부 정보를 가져옵니다.
절차
openshift-adp-velero-metrics-svc서비스가 있는지 확인합니다.ServiceMonitor오브젝트의 선택기로 사용할app.kubernetes.io/name=velero레이블이 포함되어야 합니다.$ oc get svc -n openshift-adp -l app.kubernetes.io/name=velero출력 예
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE openshift-adp-velero-metrics-svc ClusterIP 172.30.38.244 <none> 8085/TCP 1h기존 서비스 레이블과 일치하는
ServiceMonitorYAML 파일을 생성하고 파일을3_create_oadp_service_monitor.yaml로 저장합니다. 서비스 모니터는openshift-adp-velero-metrics-svc 서비스가 있는 openshift-adp네임스페이스에 생성됩니다.ServiceMonitor오브젝트의 예apiVersion: monitoring.coreos.com/v1 kind: ServiceMonitor metadata: labels: app: oadp-service-monitor name: oadp-service-monitor namespace: openshift-adp spec: endpoints: - interval: 30s path: /metrics targetPort: 8085 scheme: http selector: matchLabels: app.kubernetes.io/name: "velero"3_create_oadp_service_monitor.yaml파일을 적용합니다.$ oc apply -f 3_create_oadp_service_monitor.yaml출력 예
servicemonitor.monitoring.coreos.com/oadp-service-monitor created
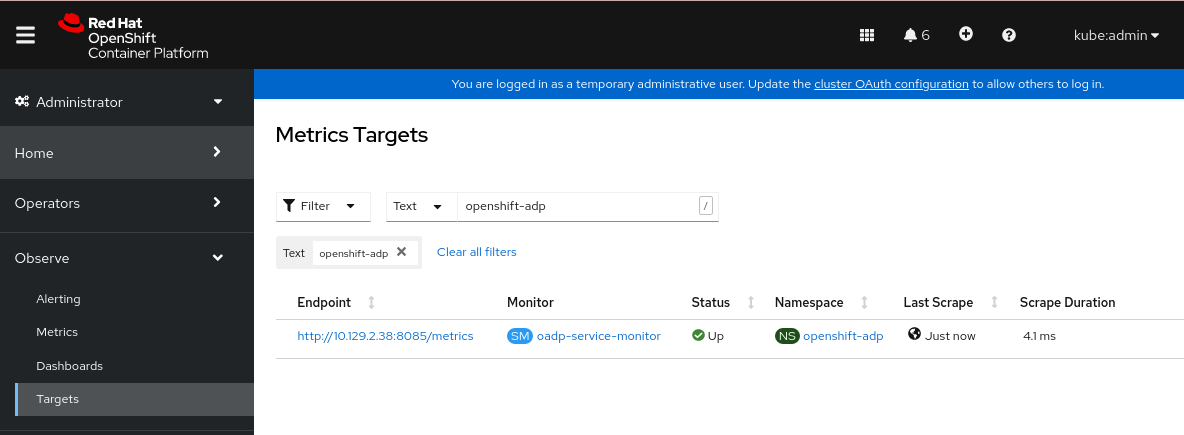
검증
OpenShift Container Platform 웹 콘솔의 관리자 화면을 사용하여 새 서비스 모니터가 Up 상태인지 확인합니다.
-
모니터링
대상 페이지로 이동합니다. -
필터 가 선택되지 않았거나 사용자 소스가 선택되어 있는지 확인하고
텍스트검색 필드에openshift-adp를 입력합니다. 서비스 모니터의 상태 상태가 Up 인지 확인합니다.
그림 4.1. OADP 메트릭 대상
-
모니터링
4.10.13.3. 경고 규칙 생성
OpenShift Container Platform 모니터링 스택을 사용하면 경고 규칙을 사용하여 구성된 경고를 수신할 수 있습니다. OADP 프로젝트에 대한 경고 규칙을 생성하려면 사용자 워크로드 모니터링으로 스크랩되는 지표 중 하나를 사용합니다.
절차
샘플
OADPBackupFailing경고를 사용하여PrometheusRuleYAML 파일을 생성하고4_create_oadp_alert_rule.yaml로 저장합니다.샘플
OADPBackupFailing경고apiVersion: monitoring.coreos.com/v1 kind: PrometheusRule metadata: name: sample-oadp-alert namespace: openshift-adp spec: groups: - name: sample-oadp-backup-alert rules: - alert: OADPBackupFailing annotations: description: 'OADP had {{$value | humanize}} backup failures over the last 2 hours.' summary: OADP has issues creating backups expr: | increase(velero_backup_failure_total{job="openshift-adp-velero-metrics-svc"}[2h]) > 0 for: 5m labels: severity: warning이 샘플에서는 다음 조건 아래에 경고가 표시됩니다.
- 지난 2시간 동안 0보다 큰 새 오류 백업이 증가하고 상태가 최소 5분 동안 지속됩니다.
-
첫 번째 증가 시간이 5분 미만이면 경고가
Pending상태가 되고 그 후에는 실행 중 상태가 됩니다.
openshift-adp네임스페이스에PrometheusRule오브젝트를 생성하는4_create_oadp_alert_rule.yaml파일을 적용합니다.$ oc apply -f 4_create_oadp_alert_rule.yaml출력 예
prometheusrule.monitoring.coreos.com/sample-oadp-alert created
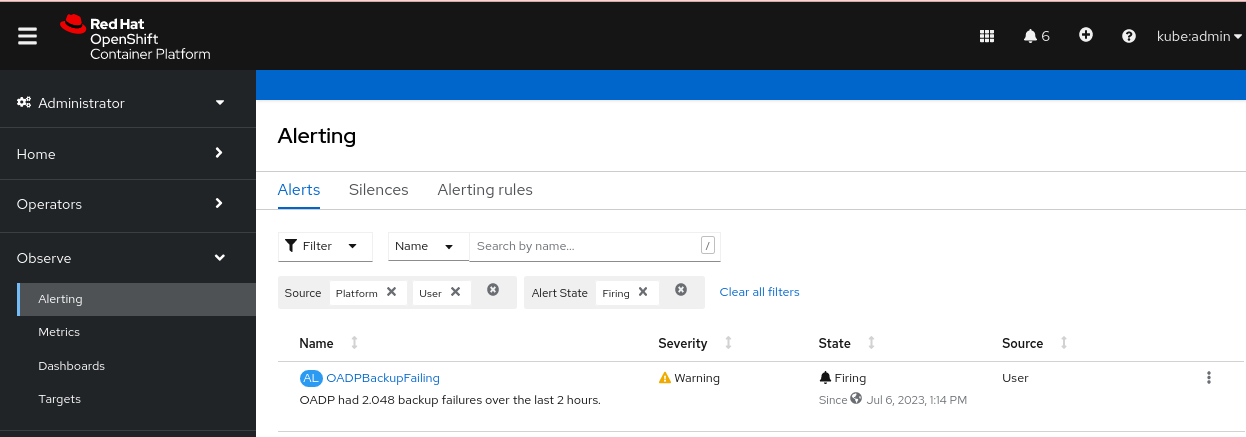
검증
경고가 트리거되면 다음과 같은 방법으로 볼 수 있습니다.
- 개발자 화면에서 모니터링 메뉴를 선택합니다.
관리자 관점에서 모니터링
경고 메뉴의 필터 상자에서 사용자를 선택합니다. 그렇지 않으면 기본적으로 플랫폼 경고만 표시됩니다. 그림 4.2. OADP 백업 실패 경고
4.10.13.4. 사용 가능한 메트릭 목록
이러한 지표는 OADP가 해당 유형과 함께 제공하는 메트릭 목록입니다.
| 메트릭 이름 | 설명 | 유형 |
|---|---|---|
|
| 캐시에서 검색된 바이트 수 | 카운터 |
|
| 캐시에서 콘텐츠를 검색한 횟수 | 카운터 |
|
| 캐시에서 잘못된 콘텐츠를 읽은 횟수 | 카운터 |
|
| 캐시에서 콘텐츠를 찾을 수 없고 가져온 횟수 | 카운터 |
|
| 기본 스토리지에서 검색된 바이트 수 | 카운터 |
|
| 기본 스토리지에서 콘텐츠를 찾을 수 없는 횟수 | 카운터 |
|
| 캐시에 콘텐츠를 저장할 수 없는 횟수 | 카운터 |
|
|
| 카운터 |
|
|
| 카운터 |
|
|
| 카운터 |
|
|
| 카운터 |
|
|
| 카운터 |
|
|
| 카운터 |
|
| 시도된 총 백업 수 | 카운터 |
|
| 시도된 총 백업 삭제 수 | 카운터 |
|
| 실패한 백업 삭제 총 수 | 카운터 |
|
| 성공적인 백업 삭제 총 수 | 카운터 |
|
| 백업 완료 시간(초) | 히스토그램 |
|
| 실패한 총 백업 수 | 카운터 |
|
| 백업 중 발생한 총 오류 수 | 게이지 |
|
| 백업된 총 항목 수 | 게이지 |
|
| 백업의 마지막 상태입니다. 1의 값은 success, 0입니다. | 게이지 |
|
| 백업이 성공적으로 실행된 마지막 시간, Unix 타임스탬프(초) | 게이지 |
|
| 부분적으로 실패한 백업의 총 수 | 카운터 |
|
| 총 성공적인 백업 수 | 카운터 |
|
| 백업의 크기(바이트) | 게이지 |
|
| 현재 존재하는 백업 수 | 게이지 |
|
| 총 검증 실패 백업 수 | 카운터 |
|
| 경고된 총 백업 수 | 카운터 |
|
| 총 CSI 시도 볼륨 스냅샷 수 | 카운터 |
|
| 총 CSI 실패 볼륨 스냅샷 수 | 카운터 |
|
| 총 CSI 성공 볼륨 스냅샷 수 | 카운터 |
|
| 시도한 총 복원 수 | 카운터 |
|
| 실패한 총 복원 수 | 카운터 |
|
| 부분적으로 실패한 복원의 총 수 | 카운터 |
|
| 성공적인 총 복원 수 | 카운터 |
|
| 현재 존재하는 복원 수 | 게이지 |
|
| 검증에 실패한 총 복원 수 | 카운터 |
|
| 시도한 총 볼륨 스냅샷 수 | 카운터 |
|
| 실패한 총 볼륨 스냅샷 수 | 카운터 |
|
| 총 볼륨 스냅샷 수 | 카운터 |
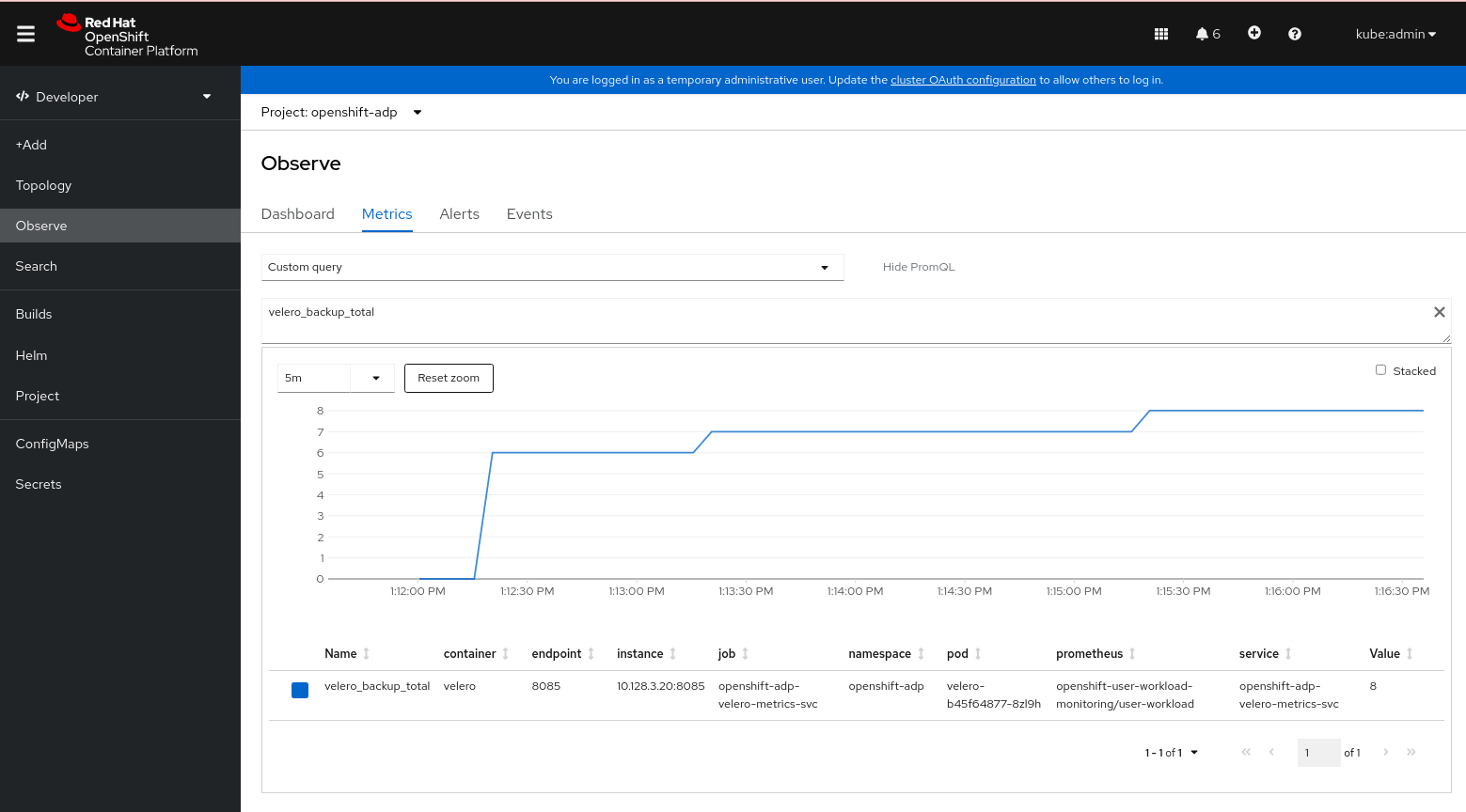
4.10.13.5. 모니터링 UI를 사용하여 메트릭 보기
OpenShift Container Platform 웹 콘솔의 관리자 또는 개발자 화면에서 메트릭을 볼 수 있습니다. openshift-adp 프로젝트에 액세스할 수 있어야 합니다.
절차
모니터링
메트릭 페이지로 이동합니다. 개발자 화면을 사용하는 경우 다음 단계를 따르십시오.
- 사용자 지정 쿼리 를 선택하거나 PromQL 표시 링크를 클릭합니다.
- 쿼리를 입력하고 Enter 를 클릭합니다.
관리자 화면을 사용하는 경우 텍스트 필드에 표현식을 입력하고 Run Queries 를 선택합니다.
그림 4.3. OADP 메트릭 쿼리