8.2. 개발자 지표
8.2.1. 서버리스 개발자 메트릭 개요
지표를 사용하면 개발자가 Knative 서비스 성능을 모니터링할 수 있습니다. OpenShift Container Platform 모니터링 스택을 사용하여 Knative 서비스에 대한 상태 점검 및 메트릭을 기록하고 확인할 수 있습니다.
OpenShift Container Platform 웹 콘솔 개발자 화면에서 대시보드로 이동하여 OpenShift Serverless의 다양한 메트릭을 볼 수 있습니다.
Service Mesh가 mTLS를 사용하여 사용하도록 설정된 경우 Service Mesh가 Prometheus의 메트릭 스크랩을 허용하지 않기 때문에 기본적으로 Knative Serviceing에 대한 메트릭이 사용되지 않도록 설정됩니다.
이 문제를 해결하는 방법에 대한 자세한 내용은 mTLS를 사용하여 서비스 메시를 사용할 때 Knative Serving 메트릭 활성화를 참조하십시오.
메트릭을 스크랩하는 작업은 스크랩 요청이 활성화를 통과하지 않기 때문에 Knative 서비스의 자동 확장에 영향을 미치지 않습니다. 결과적으로 실행 중인 Pod가 없는 경우 스크랩이 수행되지 않습니다.
8.2.2. 기본적으로 노출되는 Knative 서비스 메트릭
| 메트릭 이름, 단위 및 유형 | 설명 | 메트릭 태그 |
|---|---|---|
|
메트릭 단위: 무차원 단위 메트릭 유형: 게이지 | 큐 프록시에 도달하는 초당 요청 수입니다.
Formula:
| destination_configuration="event-display", destination_namespace="pingsource1", destination_pod="event-display-00001-deployment-6b455479cb-75p6w", destination_revision="event-display-00001" |
|
메트릭 단위: 무차원 단위 메트릭 유형: 게이지 | 초당 프록시된 요청 수입니다.
공식:
| |
|
메트릭 단위: 무차원 단위 메트릭 유형: 게이지 | 이 Pod에서 현재 처리 중인 요청 수입니다.
평균 동시성은 다음과 같이 네트워킹
| destination_configuration="event-display", destination_namespace="pingsource1", destination_pod="event-display-00001-deployment-6b455479cb-75p6w", destination_revision="event-display-00001" |
|
메트릭 단위: 무차원 단위 메트릭 유형: 게이지 | 이 Pod에서 현재 처리하는 프록시된 요청 수입니다.
| destination_configuration="event-display", destination_namespace="pingsource1", destination_pod="event-display-00001-deployment-6b455479cb-75p6w", destination_revision="event-display-00001" |
|
메트릭 단위: 초 메트릭 유형: 게이지 | 프로세스가 작동된 시간(초)입니다. | destination_configuration="event-display", destination_namespace="pingsource1", destination_pod="event-display-00001-deployment-6b455479cb-75p6w", destination_revision="event-display-00001" |
| 메트릭 이름, 단위 및 유형 | 설명 | 메트릭 태그 |
|---|---|---|
|
메트릭 단위: 무차원 단위 메트릭 유형: 카운터 |
| configuration_name="event-display", container_name="queue-proxy", namespace_name="apiserversource1", pod_name="event-display-00001-deployment-658fd4f9cf-qcnr5", response_code="200", response_code_class="2xx", revision_name="event-display-00001", service_name="event-display" |
|
메트릭 단위: 밀리초 메트릭 유형: 히스토그램 | 응답 시간(밀리초)입니다. | configuration_name="event-display", container_name="queue-proxy", namespace_name="apiserversource1", pod_name="event-display-00001-deployment-658fd4f9cf-qcnr5", response_code="200", response_code_class="2xx", revision_name="event-display-00001", service_name="event-display" |
|
메트릭 단위: 무차원 단위 메트릭 유형: 카운터 |
| configuration_name="event-display", container_name="queue-proxy", namespace_name="apiserversource1", pod_name="event-display-00001-deployment-658fd4f9cf-qcnr5", response_code="200", response_code_class="2xx", revision_name="event-display-00001", service_name="event-display" |
|
메트릭 단위: 밀리초 메트릭 유형: 히스토그램 | 응답 시간(밀리초)입니다. | configuration_name="event-display", container_name="queue-proxy", namespace_name="apiserversource1", pod_name="event-display-00001-deployment-658fd4f9cf-qcnr5", response_code="200", response_code_class="2xx", revision_name="event-display-00001", service_name="event-display" |
|
메트릭 단위: 무차원 단위 메트릭 유형: 게이지 |
서비스 및 대기열에 있는 현재 항목 수 또는 무제한 동시 실행인 경우 보고되지 않은 항목 수입니다. | configuration_name="event-display", container_name="queue-proxy", namespace_name="apiserversource1", pod_name="event-display-00001-deployment-658fd4f9cf-qcnr5", response_code="200", response_code_class="2xx", revision_name="event-display-00001", service_name="event-display" |
8.2.3. 사용자 정의 애플리케이션 메트릭이 있는 Knative 서비스
Knative 서비스에서 내보낸 메트릭 집합을 확장할 수 있습니다. 정확한 구현은 애플리케이션 및 사용된 언어에 따라 다릅니다.
다음 목록에서는 처리된 이벤트 사용자 지정 메트릭을 내보내는 샘플 Go 애플리케이션을 구현합니다.
package main
import (
"fmt"
"log"
"net/http"
"os"
"github.com/prometheus/client_golang/prometheus"
"github.com/prometheus/client_golang/prometheus/promauto"
"github.com/prometheus/client_golang/prometheus/promhttp"
)
var (
opsProcessed = promauto.NewCounter(prometheus.CounterOpts{
Name: "myapp_processed_ops_total",
Help: "The total number of processed events",
})
)
func handler(w http.ResponseWriter, r *http.Request) {
log.Print("helloworld: received a request")
target := os.Getenv("TARGET")
if target == "" {
target = "World"
}
fmt.Fprintf(w, "Hello %s!\n", target)
opsProcessed.Inc()
}
func main() {
log.Print("helloworld: starting server...")
port := os.Getenv("PORT")
if port == "" {
port = "8080"
}
http.HandleFunc("/", handler)
// Separate server for metrics requests
go func() {
mux := http.NewServeMux()
server := &http.Server{
Addr: fmt.Sprintf(":%s", "9095"),
Handler: mux,
}
mux.Handle("/metrics", promhttp.Handler())
log.Printf("prometheus: listening on port %s", 9095)
log.Fatal(server.ListenAndServe())
}()
// Use same port as normal requests for metrics
//http.Handle("/metrics", promhttp.Handler())
log.Printf("helloworld: listening on port %s", port)
log.Fatal(http.ListenAndServe(fmt.Sprintf(":%s", port), nil))
}8.2.4. 사용자 정의 메트릭 스크랩 구성
사용자 정의 메트릭 스크랩은 사용자 워크로드 모니터링을 위해 Prometheus의 인스턴스에서 수행합니다. 사용자 워크로드 모니터링을 활성화하고 애플리케이션을 생성한 후에는 모니터링 스택에서 메트릭을 스크랩하는 방법을 정의하는 구성이 필요합니다.
다음 샘플 구성은 애플리케이션에 대한 ksvc를 정의하고 서비스 모니터를 구성합니다. 정확한 구성은 애플리케이션과 메트릭을 내보내는 방법에 따라 다릅니다.
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: helloworld-go
spec:
template:
metadata:
labels:
app: helloworld-go
annotations:
spec:
containers:
- image: docker.io/skonto/helloworld-go:metrics
resources:
requests:
cpu: "200m"
env:
- name: TARGET
value: "Go Sample v1"
---
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
name: helloworld-go-sm
spec:
endpoints:
- port: queue-proxy-metrics
scheme: http
- port: app-metrics
scheme: http
namespaceSelector: {}
selector:
matchLabels:
name: helloworld-go-sm
---
apiVersion: v1
kind: Service
metadata:
labels:
name: helloworld-go-sm
name: helloworld-go-sm
spec:
ports:
- name: queue-proxy-metrics
port: 9091
protocol: TCP
targetPort: 9091
- name: app-metrics
port: 9095
protocol: TCP
targetPort: 9095
selector:
serving.knative.dev/service: helloworld-go
type: ClusterIP8.2.5. 서비스의 메트릭 검사
메트릭을 내보내도록 애플리케이션을 구성하고 모니터링 스택을 스크랩하면 웹 콘솔에서 메트릭을 검사할 수 있습니다.
사전 요구 사항
- OpenShift Container Platform 웹 콘솔에 로그인했습니다.
- OpenShift Serverless Operator 및 Knative Serving이 설치되어 있습니다.
절차
선택 사항: 메트릭에서 볼 수 있는 애플리케이션에 대한 요청을 실행합니다.
$ hello_route=$(oc get ksvc helloworld-go -n ns1 -o jsonpath='{.status.url}') && \ curl $hello_route출력 예
Hello Go Sample v1!-
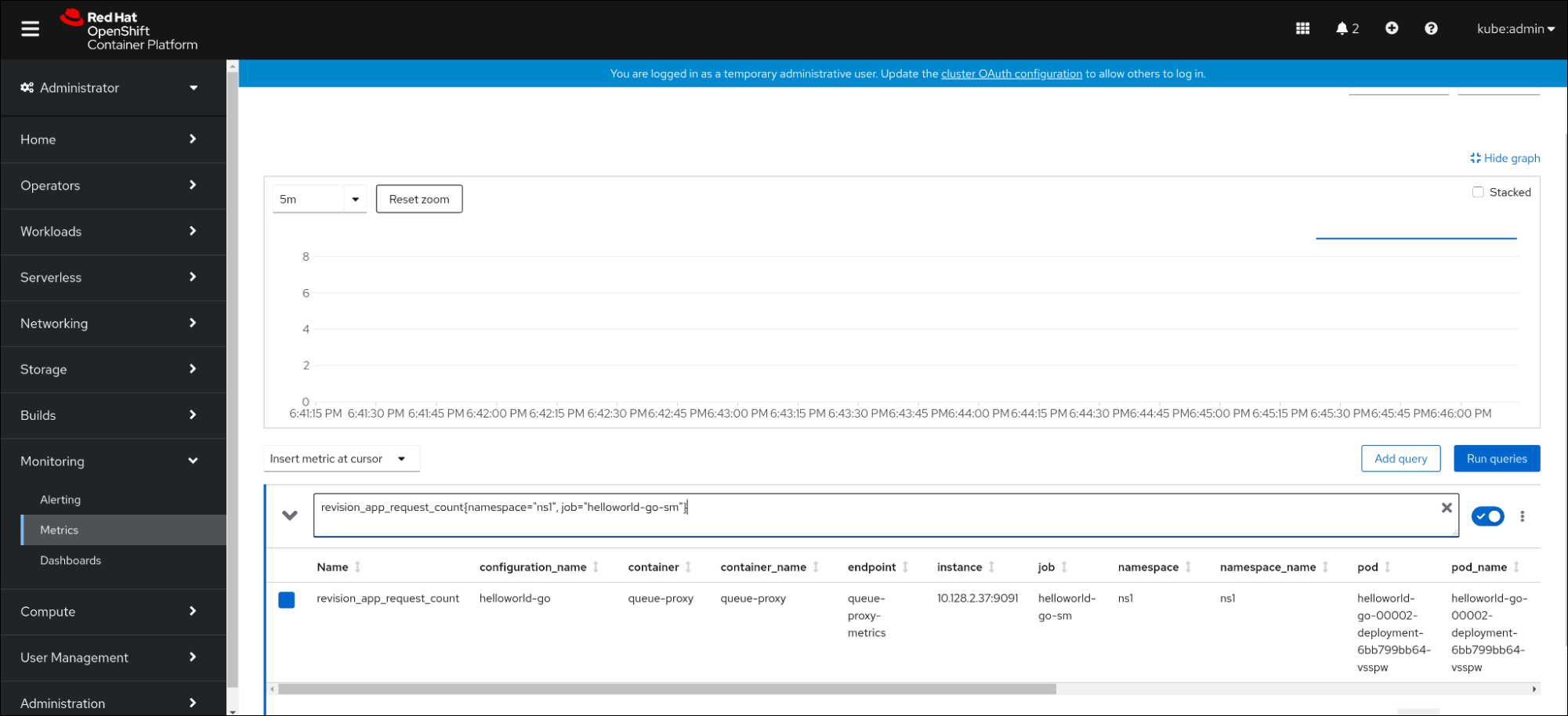
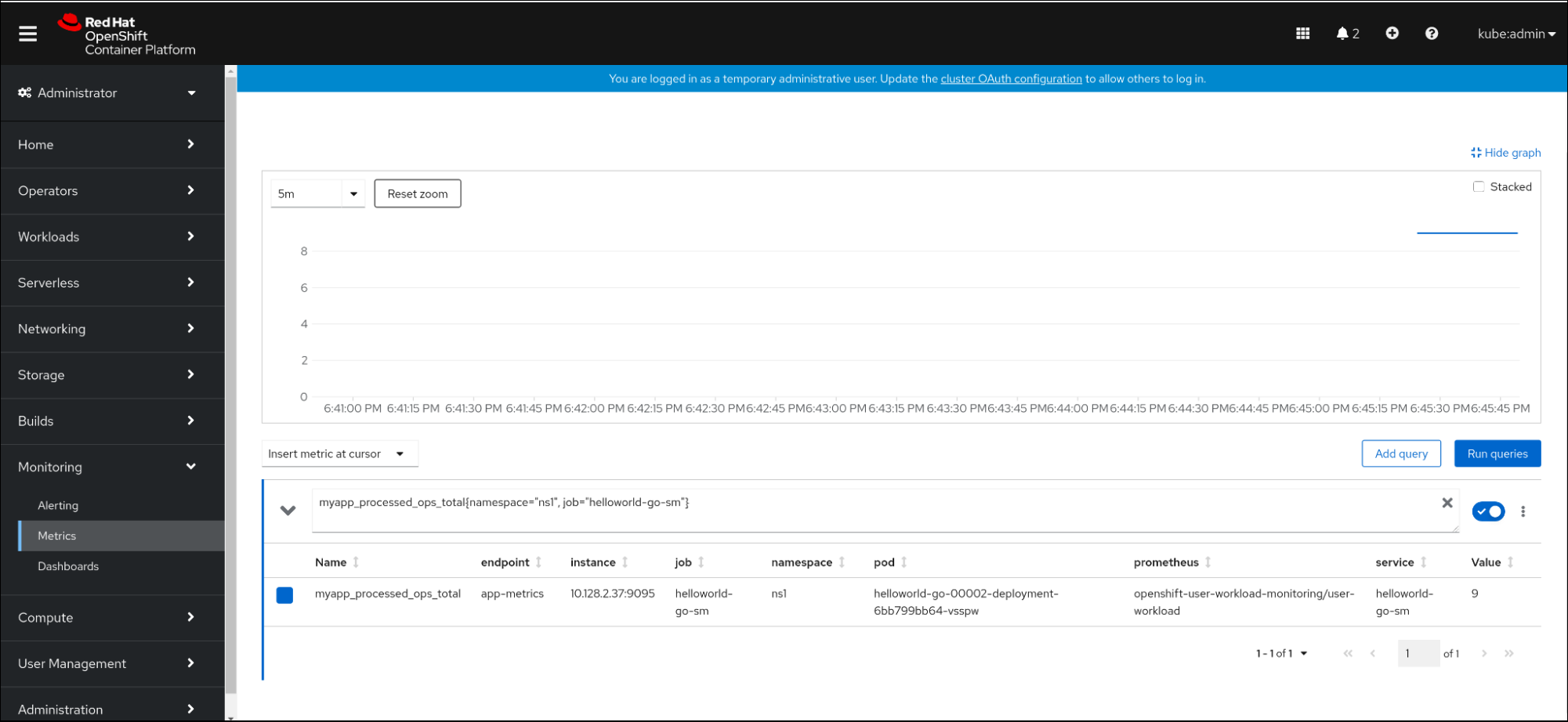
웹 콘솔에서 Observe
Metrics 인터페이스로 이동합니다. 입력 필드에 모니터링할 메트릭의 쿼리를 입력합니다. 예를 들면 다음과 같습니다.
revision_app_request_count{namespace="ns1", job="helloworld-go-sm"}다른 예:
myapp_processed_ops_total{namespace="ns1", job="helloworld-go-sm"}시각화된 메트릭을 모니터링합니다.
8.2.5.1. 대기열 프록시 메트릭
각 Knative 서비스에는 애플리케이션 컨테이너에 대한 연결을 프록시하는 프록시 컨테이너가 있습니다. 큐 프록시 성능에 대해 여러 메트릭이 보고됩니다.
다음 메트릭을 사용하여 요청이 프록시 측에 대기되었는지 및 애플리케이션에서 요청을 처리할 때의 실제 지연을 측정할 수 있습니다.
| 메트릭 이름 | 설명 | 유형 | 태그 | 단위 |
|---|---|---|---|---|
|
|
| 카운터 |
| 정수(단위 없음) |
|
| 수정 버전 요청의 응답 시간입니다. | 히스토그램 |
| 밀리초 |
|
|
| 카운터 |
| 정수(단위 없음) |
|
| 수정 버전 앱 요청의 응답 시간입니다. | 히스토그램 |
| 밀리초 |
|
|
| 게이지 |
| 정수(단위 없음) |
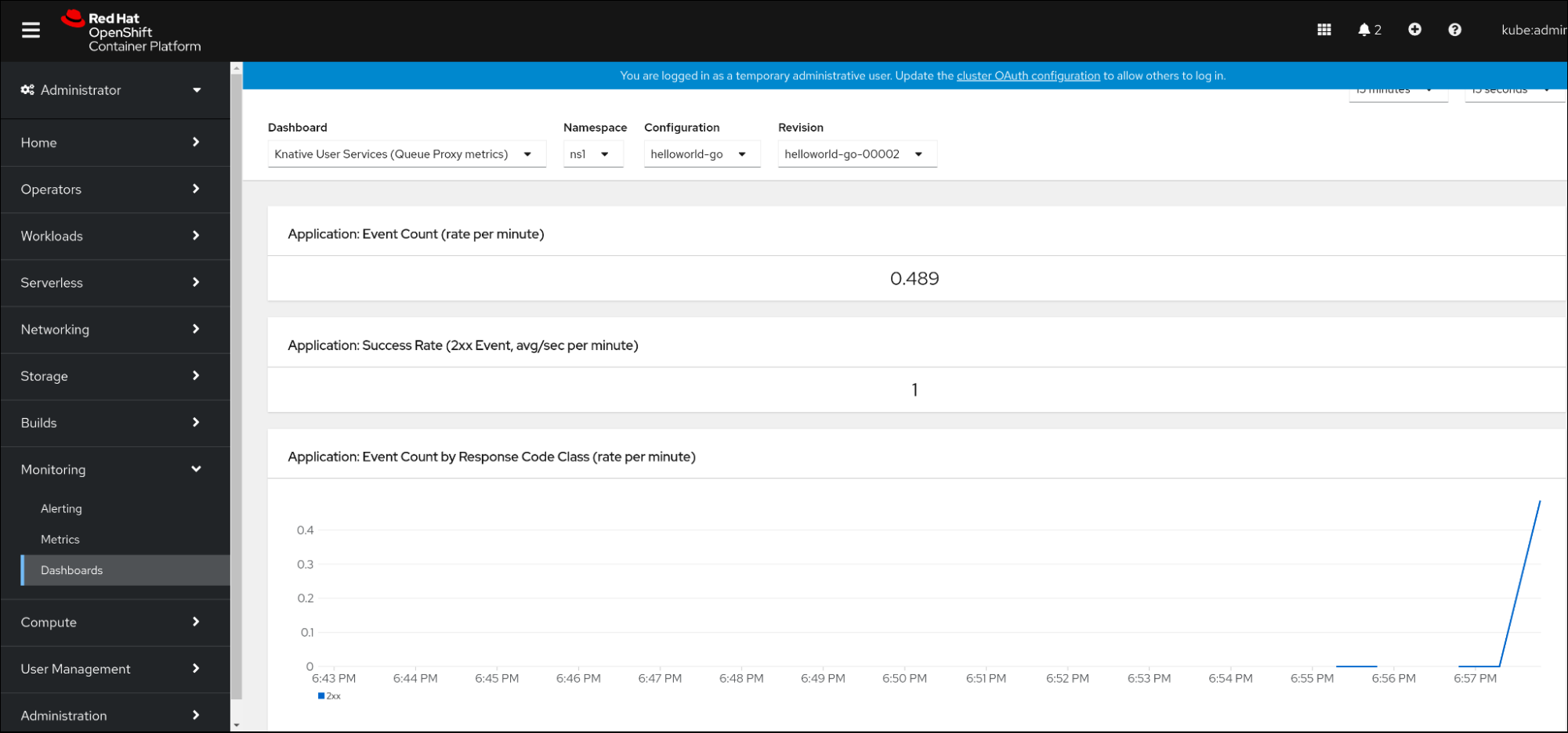
8.2.6. 서비스 메트릭 대시보드
네임스페이스별로 큐 프록시 메트릭을 집계하는 전용 대시보드를 사용하여 메트릭을 검사할 수 있습니다.
8.2.6.1. 대시보드에서 서비스의 메트릭 검사
사전 요구 사항
- OpenShift Container Platform 웹 콘솔에 로그인했습니다.
- OpenShift Serverless Operator 및 Knative Serving이 설치되어 있습니다.
절차
-
웹 콘솔에서 Observe
Metrics 인터페이스로 이동합니다. -
Knative 사용자 서비스(Queue 프록시 메트릭)대시보드를 선택합니다. - 애플리케이션에 해당하는 네임스페이스,구성 및 개정 버전을 선택합니다.
시각화된 메트릭을 모니터링합니다.