5.4. 재해 복구
5.4.1. 재해 복구 정보
재해 복구 문서에서는 관리자에게 OpenShift Container Platform 클러스터에서 발생할 수있는 여러 재해 상황을 복구하는 방법에 대한 정보를 제공합니다. 관리자는 클러스터를 작동 상태로 복원하려면 다음 절차 중 하나 이상을 수행해야합니다.
재해 복구를 위해서는 하나 이상의 정상 컨트롤 플레인 호스트가 있어야 합니다.
- 이전 클러스터 상태로 복원
클러스터를 이전 상태로 복원하려는 경우 (예: 관리자가 일부 주요 정보를 삭제한 경우) 이 솔루션을 사용할 수 있습니다. 이에는 대부분의 컨트롤 플레인 호스트가 손실되고 etcd 쿼럼이 손실되고 클러스터가 오프라인인 상태에서도 사용할 수 있습니다. etcd 백업을 수행한 경우 이 절차에 따라 클러스터를 이전 상태로 복원할 수 있습니다.
해당하는 경우 만료된 컨트롤 플레인 인증서에서 복구해야 할 수도 있습니다.
주의이전 클러스터 상태로 복원하는 것은 실행 중인 클러스터에서 수행하기에 위험하고 불안정한 작업입니다. 이 절차는 마지막 수단으로만 사용해야 합니다.
복원을 수행하기 전에 클러스터에 미치는 영향에 대한 자세한 내용은 클러스터 상태 복원을 참조하십시오.
참고대다수의 마스터를 계속 사용할 수 있고 etcd 쿼럼이 있는 경우 절차에 따라 비정상적인 단일 etcd 멤버를 교체 합니다.
- 만료된 컨트롤 플레인 인증서 복구
- 컨트롤 플레인 인증서가 만료된 경우 이 솔루션을 사용할 수 있습니다. 예를 들어, 설치 후 24 시간 내에 발생하는 첫 번째 인증서 교체 전에 클러스터를 종료하면 인증서가 교체되지 않고 만료됩니다. 다음 단계에 따라 만료된 컨트롤 플레인 인증서를 복구할 수 있습니다.
5.4.2. 이전 클러스터 상태로 복원
클러스터를 이전 상태로 복원하려면 스냅샷을 생성하여 etcd 데이터를 백업해야 합니다. 이 스냅샷을 사용하여 클러스터 상태를 복구합니다. 자세한 내용은 " etcd 데이터 백업"을 참조하십시오.
5.4.2.1. 클러스터 상태 복원 정보
etcd 백업을 사용하여 클러스터를 이전 상태로 복원할 수 있습니다. 이를 사용하여 다음과 같은 상황에서 복구할 수 있습니다.
- 클러스터에서 대부분의 컨트롤 플레인 호스트가 손실되었습니다(쿼럼 손실).
- 관리자가 중요한 것을 삭제했으며 클러스터를 복구하려면 복원해야 합니다.
이전 클러스터 상태로 복원하는 것은 실행 중인 클러스터에서 수행하기에 위험하고 불안정한 작업입니다. 이는 마지막 수단으로만 사용해야 합니다.
Kubernetes API 서버를 사용하여 데이터를 검색할 수 있는 경우 etcd를 사용할 수 있으며 etcd 백업을 사용하여 복원할 수 없습니다.
etcd를 복원하려면 클러스터를 효율적으로 복원하는 데 시간이 걸리며 모든 클라이언트가 충돌하는 병렬 기록이 발생합니다. 이는 kubelets, Kubernetes 컨트롤러 관리자, SDN 컨트롤러 및 영구 볼륨 컨트롤러와 같은 구성 요소 모니터링 동작에 영향을 줄 수 있습니다.
이로 인해 etcd의 콘텐츠가 디스크의 실제 콘텐츠와 일치하지 않을 때 Operator가 문제가 발생하여 디스크의 파일이 etcd의 콘텐츠와 충돌할 때 Kubernetes API 서버, Kubernetes 컨트롤러 관리자, Kubernetes 스케줄러 및 etcd의 Operator가 중단될 수 있습니다. 여기에는 문제를 해결하기 위해 수동 작업이 필요할 수 있습니다.
극단적인 경우 클러스터에서 영구 볼륨 추적을 손실하고, 더 이상 존재하지 않는 중요한 워크로드를 삭제하고, 시스템을 다시 이미지화하고, 만료된 인증서로 CA 번들을 다시 작성할 수 있습니다.
5.4.2.2. 이전 클러스터 상태로 복원
저장된 etcd 백업을 사용하여 이전 클러스터 상태를 복원하거나 대부분의 컨트롤 플레인 호스트가 손실된 클러스터를 복원할 수 있습니다.
클러스터에서 컨트롤 플레인 머신 세트를 사용하는 경우 etcd 복구 프로시저의 "Troubleshooting the control Plane machine set"에서 "Recovering a degraded etcd Operator"를 참조하십시오.
클러스터를 복원할 때 동일한 z-stream 릴리스에서 가져온 etcd 백업을 사용해야 합니다. 예를 들어 OpenShift Container Platform 4.7.2 클러스터는 4.7.2에서 가져온 etcd 백업을 사용해야 합니다.
사전 요구 사항
-
설치 중에 사용된 인증서 기반
kubeconfig파일을 통해cluster-admin역할의 사용자로 클러스터에 액세스할 수 있습니다. - 복구 호스트로 사용할 정상적인 컨트롤 플레인 호스트가 있어야 합니다.
- 컨트롤 플레인 호스트에 대한 SSH 액세스.
-
동일한 백업에서 가져온 etcd 스냅샷과 정적 pod 리소스가 모두 포함된 백업 디렉토리입니다. 디렉토리의 파일 이름은
snapshot_<datetimestamp>.db및static_kuberesources_<datetimestamp>.tar.gz형식이어야합니다.
복구되지 않은 컨트롤 플레인 노드의 경우 SSH 연결을 설정하거나 고정 Pod를 중지할 필요가 없습니다. 다른 비 복구, 컨트롤 플레인 시스템을 삭제하고 하나씩 다시 생성할 수 있습니다.
절차
- 복구 호스트로 사용할 컨트롤 플레인 호스트를 선택합니다. 이는 복구 작업을 실행할 호스트입니다.
복구 호스트를 포함하여 각 컨트롤 플레인 노드에 SSH 연결을 설정합니다.
복구 프로세스가 시작된 후에는 Kubernetes API 서버에 액세스할 수 없으므로 컨트롤 플레인 노드에 액세스할 수 없습니다. 따라서 다른 터미널에서 각 컨트롤 플레인 호스트에 대한 SSH 연결을 설정하는 것이 좋습니다.
중요이 단계를 완료하지 않으면 컨트롤 플레인 호스트에 액세스하여 복구 프로세스를 완료할 수 없으며 이 상태에서 클러스터를 복구할 수 없습니다.
etcd 백업 디렉토리를 복구 컨트롤 플레인 호스트에 복사합니다.
이 단계에서는 etcd 스냅샷 및 정적 pod의 리소스가 포함된
backup디렉터리를 복구 컨트롤 플레인 호스트의/home/core/디렉터리에 복사하는 것을 전제로하고 있습니다.다른 컨트롤 플레인 노드에서 고정 Pod를 중지합니다.
참고복구 호스트에서 정적 Pod를 중지할 필요가 없습니다.
- 복구 호스트가 아닌 컨트롤 플레인 호스트에 액세스합니다.
kubelet 매니페스트 디렉토리에서 기존 etcd pod 파일을 이동합니다.
$ sudo mv -v /etc/kubernetes/manifests/etcd-pod.yaml /tmpetcd pod가 중지되었는지 확인합니다.
$ sudo crictl ps | grep etcd | egrep -v "operator|etcd-guard"이 명령의 출력은 비어 있어야합니다. 비어 있지 않은 경우 몇 분 기다렸다가 다시 확인하십시오.
kubelet 매니페스트 디렉토리에서 기존 Kubernetes API 서버 pod 파일을 이동합니다.
$ sudo mv -v /etc/kubernetes/manifests/kube-apiserver-pod.yaml /tmpKubernetes API 서버 pod가 중지되었는지 확인합니다.
$ sudo crictl ps | grep kube-apiserver | egrep -v "operator|guard"이 명령의 출력은 비어 있어야합니다. 비어 있지 않은 경우 몇 분 기다렸다가 다시 확인하십시오.
etcd 데이터 디렉토리를 다른 위치로 이동합니다.
$ sudo mv -v /var/lib/etcd/ /tmp/etc/kubernetes/manifests/keepalived.yaml파일이 있고 노드가 삭제되면 다음 단계를 따르십시오.kubelet 매니페스트 디렉토리에서
/etc/kubernetes/manifests/keepalived.yaml파일을 이동합니다.$ sudo mv -v /etc/kubernetes/manifests/keepalived.yaml /tmpkeepalived데몬에서 관리하는 컨테이너가 중지되었는지 확인합니다.$ sudo crictl ps --name keepalived이 명령의 출력은 비어 있어야합니다. 비어 있지 않은 경우 몇 분 기다렸다가 다시 확인하십시오.
컨트롤 플레인에 VIP가 할당되어 있는지 확인합니다.
$ ip -o address | egrep '<api_vip>|<ingress_vip>'보고된 각 VIP에 대해 다음 명령을 실행하여 제거합니다.
$ sudo ip address del <reported_vip> dev <reported_vip_device>
- 복구 호스트가 아닌 다른 컨트롤 플레인 호스트에서 이 단계를 반복합니다.
- 복구 컨트롤 플레인 호스트에 액세스합니다.
keepalived데몬이 사용 중인 경우 복구 컨트롤 플레인 노드가 VIP를 소유하고 있는지 확인합니다.$ ip -o address | grep <api_vip>VIP 주소가 있는 경우 출력에 강조 표시됩니다. VIP가 잘못 설정되거나 구성되지 않은 경우 이 명령은 빈 문자열을 반환합니다.
클러스터 전체의 프록시가 활성화되어 있는 경우
NO_PROXY,HTTP_PROXY및https_proxy환경 변수를 내보내고 있는지 확인합니다.작은 정보oc get proxy cluster -o yaml의 출력을 확인하여 프록시가 사용 가능한지 여부를 확인할 수 있습니다.httpProxy,httpsProxy및noProxy필드에 값이 설정되어 있으면 프록시가 사용됩니다.복구 컨트롤 플레인 호스트에서 복원 스크립트를 실행하고 etcd 백업 디렉터리에 경로를 전달합니다.
$ sudo -E /usr/local/bin/cluster-restore.sh /home/core/assets/backup스크립트 출력 예
...stopping kube-scheduler-pod.yaml ...stopping kube-controller-manager-pod.yaml ...stopping etcd-pod.yaml ...stopping kube-apiserver-pod.yaml Waiting for container etcd to stop .complete Waiting for container etcdctl to stop .............................complete Waiting for container etcd-metrics to stop complete Waiting for container kube-controller-manager to stop complete Waiting for container kube-apiserver to stop ..........................................................................................complete Waiting for container kube-scheduler to stop complete Moving etcd data-dir /var/lib/etcd/member to /var/lib/etcd-backup starting restore-etcd static pod starting kube-apiserver-pod.yaml static-pod-resources/kube-apiserver-pod-7/kube-apiserver-pod.yaml starting kube-controller-manager-pod.yaml static-pod-resources/kube-controller-manager-pod-7/kube-controller-manager-pod.yaml starting kube-scheduler-pod.yaml static-pod-resources/kube-scheduler-pod-8/kube-scheduler-pod.yaml참고마지막 etcd 백업 후 노드 인증서가 업데이트된 경우 복원 프로세스에서 노드가
NotReady상태가 될 수 있습니다.노드가
Ready상태에 있는지 확인합니다.다음 명령을 실행합니다.
$ oc get nodes -w샘플 출력
NAME STATUS ROLES AGE VERSION host-172-25-75-28 Ready master 3d20h v1.25.0 host-172-25-75-38 Ready infra,worker 3d20h v1.25.0 host-172-25-75-40 Ready master 3d20h v1.25.0 host-172-25-75-65 Ready master 3d20h v1.25.0 host-172-25-75-74 Ready infra,worker 3d20h v1.25.0 host-172-25-75-79 Ready worker 3d20h v1.25.0 host-172-25-75-86 Ready worker 3d20h v1.25.0 host-172-25-75-98 Ready infra,worker 3d20h v1.25.0모든 노드가 상태를 보고하는 데 몇 분이 걸릴 수 있습니다.
NotReady상태인 노드가 있는 경우 노드에 로그인하고 각 노드의/var/lib/kubelet/pki디렉터리에서 모든 PEM 파일을 삭제합니다. 노드에 SSH를 사용하거나 웹 콘솔에서 터미널 창을 사용할 수 있습니다.$ ssh -i <ssh-key-path> core@<master-hostname>pki디렉터리 샘플sh-4.4# pwd /var/lib/kubelet/pki sh-4.4# ls kubelet-client-2022-04-28-11-24-09.pem kubelet-server-2022-04-28-11-24-15.pem kubelet-client-current.pem kubelet-server-current.pem
모든 컨트롤 플레인 호스트에서 kubelet 서비스를 다시 시작합니다.
복구 호스트에서 다음 명령을 실행합니다.
$ sudo systemctl restart kubelet.service- 다른 모든 컨트롤 플레인 호스트에서 이 단계를 반복합니다.
보류 중인 CSR을 승인합니다.
참고3개의 스케줄링 가능한 컨트롤 플레인 노드로 구성된 단일 노드 클러스터 또는 클러스터와 같이 작업자 노드가 없는 클러스터에는 승인할 보류 중인 CSR이 없습니다. 이 단계에서 나열된 모든 명령을 건너뛸 수 있습니다.
현재 CSR의 목록을 가져옵니다.
$ oc get csr출력 예
NAME AGE SIGNERNAME REQUESTOR CONDITION csr-2s94x 8m3s kubernetes.io/kubelet-serving system:node:<node_name> Pending1 csr-4bd6t 8m3s kubernetes.io/kubelet-serving system:node:<node_name> Pending2 csr-4hl85 13m kubernetes.io/kube-apiserver-client-kubelet system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending3 csr-zhhhp 3m8s kubernetes.io/kube-apiserver-client-kubelet system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending4 ...CSR의 세부 사항을 검토하여 CSR이 유효한지 확인합니다.
$ oc describe csr <csr_name>1 - 1
<csr_name>은 현재 CSR 목록에 있는 CSR의 이름입니다.
각각의 유효한
node-bootstrapperCSR을 승인합니다.$ oc adm certificate approve <csr_name>사용자 프로비저닝 설치의 경우 각 유효한 kubelet 서비스 CSR을 승인합니다.
$ oc adm certificate approve <csr_name>
단일 멤버 컨트롤 플레인이 제대로 시작되었는지 확인합니다.
복구 호스트에서 etcd 컨테이너가 실행 중인지 확인합니다.
$ sudo crictl ps | grep etcd | egrep -v "operator|etcd-guard"출력 예
3ad41b7908e32 36f86e2eeaaffe662df0d21041eb22b8198e0e58abeeae8c743c3e6e977e8009 About a minute ago Running etcd 0 7c05f8af362f0복구 호스트에서 etcd pod가 실행 중인지 확인합니다.
$ oc -n openshift-etcd get pods -l k8s-app=etcd출력 예
NAME READY STATUS RESTARTS AGE etcd-ip-10-0-143-125.ec2.internal 1/1 Running 1 2m47sPending상태에 있거나 출력에 여러 실행중인 etcd pod가 나열되어 있는 경우 몇 분 기다렸다가 다시 확인합니다.
OVNKubernetes네트워크 플러그인을 사용하는 경우 복구 컨트롤 플레인 호스트가 아닌 컨트롤 플레인 호스트와 연결된 노드 오브젝트를 삭제합니다.$ oc delete node <non-recovery-controlplane-host-1> <non-recovery-controlplane-host-2>CNO(Cluster Network Operator)가 OVN-Kubernetes 컨트롤 플레인을 재배포하고 더 이상 복구되지 않은 컨트롤러 IP 주소를 참조하지 않는지 확인합니다. 이 결과를 확인하려면 다음 명령의 출력을 정기적으로 확인하십시오. 다음 단계의 모든 호스트에서 OVN(Open Virtual Network) Kubernetes Pod를 다시 시작하기 전에 빈 결과를 반환할 때까지 기다립니다.
$ oc -n openshift-ovn-kubernetes get ds/ovnkube-master -o yaml | grep -E '<non-recovery_controller_ip_1>|<non-recovery_controller_ip_2>'참고OVN-Kubernetes 컨트롤 플레인을 재배포하고 이전 명령을 사용하여 빈 출력을 반환하는 데 최소 5-10 분이 걸릴 수 있습니다.
OVN-Kubernetes 네트워크 플러그인을 사용하는 경우 모든 호스트에서 OVN(Open Virtual Network) Kubernetes Pod를 다시 시작합니다.
참고승인 Webhook 확인 및 변경은 Pod를 거부할 수 있습니다.
failurePolicy를Fail로 설정하여 추가 Webhook를 추가하는 경우 Pod를 거부하고 복원 프로세스가 실패할 수 있습니다. 클러스터 상태를 복원하는 동안 Webhook를 저장하고 삭제하여 이 문제를 방지할 수 있습니다. 클러스터 상태가 성공적으로 복원되면 Webhook를 다시 활성화할 수 있습니다.또는 클러스터 상태를 복원하는 동안
failurePolicy를Ignore로 일시적으로 설정할 수 있습니다. 클러스터 상태가 성공적으로 복원된 후failurePolicy를Fail로 설정할 수 있습니다.northbound 데이터베이스(nbdb) 및 southbound 데이터베이스(sbdb)를 제거합니다. SSH(Secure Shell)를 사용하여 복구 호스트와 나머지 컨트롤 플레인 노드에 액세스하고 다음 명령을 실행합니다.
$ sudo rm -f /var/lib/ovn/etc/*.db다음 명령을 실행하여 모든 OVN-Kubernetes 컨트롤 플레인 Pod를 삭제합니다.
$ oc delete pods -l app=ovnkube-master -n openshift-ovn-kubernetes다음 명령을 실행하여 OVN-Kubernetes 컨트롤 플레인 Pod가 다시 배포되고
Running상태에 있는지 확인합니다.$ oc get pods -l app=ovnkube-master -n openshift-ovn-kubernetes출력 예
NAME READY STATUS RESTARTS AGE ovnkube-master-nb24h 4/4 Running 0 48s다음 명령을 실행하여
ovnkube-nodePod를 모두 삭제합니다.$ oc get pods -n openshift-ovn-kubernetes -o name | grep ovnkube-node | while read p ; do oc delete $p -n openshift-ovn-kubernetes ; done다음 명령을 실행하여 OVN Pod의 상태를 확인합니다.
$ oc get po -n openshift-ovn-kubernetesOVN Pod가
종료상태에 있는 경우 다음 명령을 실행하여 해당 OVN Pod를 실행 중인 노드를 삭제합니다. <node>를 삭제 중인 노드의 이름으로 바꿉니다.$ oc delete node <node>다음 명령을 실행하여 SSH를 사용하여
종료상태의 OVN pod 노드에 로그인합니다.$ ssh -i <ssh-key-path> core@<node>다음 명령을 실행하여
/var/lib/kubelet/pki디렉토리에서 모든 PEM 파일을 이동합니다.$ sudo mv /var/lib/kubelet/pki/* /tmp다음 명령을 실행하여 kubelet 서비스를 다시 시작합니다.
$ sudo systemctl restart kubelet.service다음 명령을 실행하여 복구 etcd 머신으로 돌아갑니다.
$ oc get csr출력 예
NAME AGE SIGNERNAME REQUESTOR CONDITION csr-<uuid> 8m3s kubernetes.io/kubelet-serving system:node:<node_name> Pending다음 명령을 실행하여 새 CSR을 모두 승인하고
csr-<uuid>를 CSR 이름으로 교체하십시오.oc adm certificate approve csr-<uuid>다음 명령을 실행하여 노드가 다시 있는지 확인합니다.
$ oc get nodes
모든
ovnkube-nodePod가 다시 배포되어 다음 명령을 실행하여Running상태인지 확인합니다.$ oc get pods -n openshift-ovn-kubernetes | grep ovnkube-node
복구되지 않는 다른 컨트롤 플레인 시스템을 삭제하고 하나씩 다시 생성합니다. 머신이 다시 생성되면 새 버전이 강제 생성되고 etcd가 자동으로 확장됩니다.
사용자가 프로비저닝한 베어 메탈 설치를 사용하는 경우 원래 사용했던 것과 동일한 방법을 사용하여 컨트롤 플레인 시스템을 다시 생성할 수 있습니다. 자세한 내용은 " 베어 메탈에 사용자 프로비저닝 클러스터 설치"를 참조하십시오.
주의복구 호스트의 시스템을 삭제하고 다시 생성하지 마십시오.
설치 관리자 프로비저닝 인프라를 실행 중이거나 Machine API를 사용하여 머신을 생성한 경우 다음 단계를 따르십시오.
주의복구 호스트의 시스템을 삭제하고 다시 생성하지 마십시오.
설치 관리자 프로비저닝 인프라에 베어 메탈 설치의 경우 컨트롤 플레인 머신이 다시 생성되지 않습니다. 자세한 내용은 " 베어 메탈 컨트롤 플레인 노드 교체"를 참조하십시오.
손실된 컨트롤 플레인 호스트 중 하나에 대한 시스템을 가져옵니다.
cluster-admin 사용자로 클러스터에 액세스할 수 있는 터미널에서 다음 명령을 실행합니다.
$ oc get machines -n openshift-machine-api -o wide출력 예:
NAME PHASE TYPE REGION ZONE AGE NODE PROVIDERID STATE clustername-8qw5l-master-0 Running m4.xlarge us-east-1 us-east-1a 3h37m ip-10-0-131-183.ec2.internal aws:///us-east-1a/i-0ec2782f8287dfb7e stopped1 clustername-8qw5l-master-1 Running m4.xlarge us-east-1 us-east-1b 3h37m ip-10-0-143-125.ec2.internal aws:///us-east-1b/i-096c349b700a19631 running clustername-8qw5l-master-2 Running m4.xlarge us-east-1 us-east-1c 3h37m ip-10-0-154-194.ec2.internal aws:///us-east-1c/i-02626f1dba9ed5bba running clustername-8qw5l-worker-us-east-1a-wbtgd Running m4.large us-east-1 us-east-1a 3h28m ip-10-0-129-226.ec2.internal aws:///us-east-1a/i-010ef6279b4662ced running clustername-8qw5l-worker-us-east-1b-lrdxb Running m4.large us-east-1 us-east-1b 3h28m ip-10-0-144-248.ec2.internal aws:///us-east-1b/i-0cb45ac45a166173b running clustername-8qw5l-worker-us-east-1c-pkg26 Running m4.large us-east-1 us-east-1c 3h28m ip-10-0-170-181.ec2.internal aws:///us-east-1c/i-06861c00007751b0a running- 1
- 이는 손실된 컨트롤 플레인 호스트
ip-10-0-131-183.ec2.internal의 컨트롤 플레인 시스템입니다.
다음을 실행하여 손실된 컨트롤 플레인 호스트의 시스템을 삭제합니다.
$ oc delete machine -n openshift-machine-api clustername-8qw5l-master-01 - 1
- 손실된 컨트롤 플레인 호스트의 컨트롤 플레인 시스템의 이름을 지정합니다.
손실된 컨트롤 플레인 호스트의 시스템을 삭제한 후 새 시스템이 자동으로 프로비저닝됩니다.
다음을 실행하여 새 시스템이 생성되었는지 확인합니다.
$ oc get machines -n openshift-machine-api -o wide출력 예:
NAME PHASE TYPE REGION ZONE AGE NODE PROVIDERID STATE clustername-8qw5l-master-1 Running m4.xlarge us-east-1 us-east-1b 3h37m ip-10-0-143-125.ec2.internal aws:///us-east-1b/i-096c349b700a19631 running clustername-8qw5l-master-2 Running m4.xlarge us-east-1 us-east-1c 3h37m ip-10-0-154-194.ec2.internal aws:///us-east-1c/i-02626f1dba9ed5bba running clustername-8qw5l-master-3 Provisioning m4.xlarge us-east-1 us-east-1a 85s ip-10-0-173-171.ec2.internal aws:///us-east-1a/i-015b0888fe17bc2c8 running1 clustername-8qw5l-worker-us-east-1a-wbtgd Running m4.large us-east-1 us-east-1a 3h28m ip-10-0-129-226.ec2.internal aws:///us-east-1a/i-010ef6279b4662ced running clustername-8qw5l-worker-us-east-1b-lrdxb Running m4.large us-east-1 us-east-1b 3h28m ip-10-0-144-248.ec2.internal aws:///us-east-1b/i-0cb45ac45a166173b running clustername-8qw5l-worker-us-east-1c-pkg26 Running m4.large us-east-1 us-east-1c 3h28m ip-10-0-170-181.ec2.internal aws:///us-east-1c/i-06861c00007751b0a running- 1
- 새 시스템
clustername-8qw5l-master-3이 생성되고 단계가Provisioning에서Running으로 변경된 후 준비 상태가 됩니다.
새 시스템을 만드는 데 몇 분이 소요될 수 있습니다. etcd 클러스터 Operator는 머신 또는 노드가 정상 상태로 돌아 오면 자동으로 동기화됩니다.
- 복구 호스트가 아닌 각 손실된 컨트롤 플레인 호스트에 대해 이 단계를 반복합니다.
다음 명령을 입력하여 쿼럼 보호기를 끄십시오.
$ oc patch etcd/cluster --type=merge -p '{"spec": {"unsupportedConfigOverrides": {"useUnsupportedUnsafeNonHANonProductionUnstableEtcd": true}}}'이 명령을 사용하면 보안을 다시 생성하고 정적 Pod를 롤아웃할 수 있습니다.
복구 호스트 내의 별도의 터미널 창에서 다음 명령을 실행하여 복구
kubeconfig파일을 내보냅니다.$ export KUBECONFIG=/etc/kubernetes/static-pod-resources/kube-apiserver-certs/secrets/node-kubeconfigs/localhost-recovery.kubeconfigetcd를 강제로 재배포합니다.
복구
kubeconfig파일을 내보낸 동일한 터미널 창에서 다음 명령을 실행합니다.$ oc patch etcd cluster -p='{"spec": {"forceRedeploymentReason": "recovery-'"$( date --rfc-3339=ns )"'"}}' --type=merge1 - 1
forceRedeploymentReason값은 고유해야하므로 타임 스탬프가 추가됩니다.
etcd 클러스터 Operator가 재배포를 실행하면 기존 노드가 초기 부트 스트랩 확장과 유사한 새 pod를 사용하기 시작합니다.
다음 명령을 입력하여 쿼럼 보호기를 다시 켭니다.
$ oc patch etcd/cluster --type=merge -p '{"spec": {"unsupportedConfigOverrides": null}}'다음 명령을 입력하여
unsupportedConfigOverrides섹션이 오브젝트에서 제거되었는지 확인할 수 있습니다.$ oc get etcd/cluster -oyaml모든 노드가 최신 버전으로 업데이트되었는지 확인합니다.
클러스터에 액세스할 수 있는 터미널에서
cluster-admin사용자로 다음 명령을 실행합니다.$ oc get etcd -o=jsonpath='{range .items[0].status.conditions[?(@.type=="NodeInstallerProgressing")]}{.reason}{"\n"}{.message}{"\n"}'etcd의
NodeInstallerProgressing상태 조건을 확인하고 모든 노드가 최신 버전인지 확인합니다. 업데이트가 성공적으로 실행되면 출력에AllNodesAtLatestRevision이 표시됩니다.AllNodesAtLatestRevision 3 nodes are at revision 71 - 1
- 이 예에서 최신 버전 번호는
7입니다.
출력에
2 nodes are at revision 6; 1 nodes are at revision 7와 같은 여러 버전 번호가 표시되면 이는 업데이트가 아직 진행 중임을 의미합니다. 몇 분 기다린 후 다시 시도합니다.etcd를 재배포한 후 컨트롤 플레인에 새 롤아웃을 강제 실행합니다. kubelet이 내부 로드 밸런서를 사용하여 API 서버에 연결되어 있으므로 Kubernetes API 서버는 다른 노드에 다시 설치됩니다.
cluster-admin사용자로 클러스터에 액세스할 수있는 터미널에서 다음 명령을 실행합니다.Kubernetes API 서버에 대해 새 롤아웃을 강제 적용합니다.
$ oc patch kubeapiserver cluster -p='{"spec": {"forceRedeploymentReason": "recovery-'"$( date --rfc-3339=ns )"'"}}' --type=merge모든 노드가 최신 버전으로 업데이트되었는지 확인합니다.
$ oc get kubeapiserver -o=jsonpath='{range .items[0].status.conditions[?(@.type=="NodeInstallerProgressing")]}{.reason}{"\n"}{.message}{"\n"}'NodeInstallerProgressing상태 조건을 확인하고 모든 노드가 최신 버전인지 확인합니다. 업데이트가 성공적으로 실행되면 출력에AllNodesAtLatestRevision이 표시됩니다.AllNodesAtLatestRevision 3 nodes are at revision 71 - 1
- 이 예에서 최신 버전 번호는
7입니다.
출력에
2 nodes are at revision 6; 1 nodes are at revision 7와 같은 여러 버전 번호가 표시되면 이는 업데이트가 아직 진행 중임을 의미합니다. 몇 분 기다린 후 다시 시도합니다.Kubernetes 컨트롤러 관리자에 대해 새 롤아웃을 강제 적용합니다.
$ oc patch kubecontrollermanager cluster -p='{"spec": {"forceRedeploymentReason": "recovery-'"$( date --rfc-3339=ns )"'"}}' --type=merge모든 노드가 최신 버전으로 업데이트되었는지 확인합니다.
$ oc get kubecontrollermanager -o=jsonpath='{range .items[0].status.conditions[?(@.type=="NodeInstallerProgressing")]}{.reason}{"\n"}{.message}{"\n"}'NodeInstallerProgressing상태 조건을 확인하고 모든 노드가 최신 버전인지 확인합니다. 업데이트가 성공적으로 실행되면 출력에AllNodesAtLatestRevision이 표시됩니다.AllNodesAtLatestRevision 3 nodes are at revision 71 - 1
- 이 예에서 최신 버전 번호는
7입니다.
출력에
2 nodes are at revision 6; 1 nodes are at revision 7와 같은 여러 버전 번호가 표시되면 이는 업데이트가 아직 진행 중임을 의미합니다. 몇 분 기다린 후 다시 시도합니다.Kubernetes 스케줄러에 대해 새 롤아웃을 강제 적용합니다.
$ oc patch kubescheduler cluster -p='{"spec": {"forceRedeploymentReason": "recovery-'"$( date --rfc-3339=ns )"'"}}' --type=merge모든 노드가 최신 버전으로 업데이트되었는지 확인합니다.
$ oc get kubescheduler -o=jsonpath='{range .items[0].status.conditions[?(@.type=="NodeInstallerProgressing")]}{.reason}{"\n"}{.message}{"\n"}'NodeInstallerProgressing상태 조건을 확인하고 모든 노드가 최신 버전인지 확인합니다. 업데이트가 성공적으로 실행되면 출력에AllNodesAtLatestRevision이 표시됩니다.AllNodesAtLatestRevision 3 nodes are at revision 71 - 1
- 이 예에서 최신 버전 번호는
7입니다.
출력에
2 nodes are at revision 6; 1 nodes are at revision 7와 같은 여러 버전 번호가 표시되면 이는 업데이트가 아직 진행 중임을 의미합니다. 몇 분 기다린 후 다시 시도합니다.
모든 컨트롤 플레인 호스트가 클러스터를 시작하여 참여하고 있는지 확인합니다.
클러스터에 액세스할 수 있는 터미널에서
cluster-admin사용자로 다음 명령을 실행합니다.$ oc -n openshift-etcd get pods -l k8s-app=etcd출력 예
etcd-ip-10-0-143-125.ec2.internal 2/2 Running 0 9h etcd-ip-10-0-154-194.ec2.internal 2/2 Running 0 9h etcd-ip-10-0-173-171.ec2.internal 2/2 Running 0 9h
복구 절차에 따라 모든 워크로드가 일반 작업으로 돌아가도록 하려면 Kubernetes API 정보를 저장하는 각 Pod를 다시 시작합니다. 여기에는 라우터, Operator 및 타사 구성 요소와 같은 OpenShift Container Platform 구성 요소가 포함됩니다.
이전 절차 단계를 완료하면 모든 서비스가 복원된 상태로 돌아올 때까지 몇 분 정도 기다려야 할 수 있습니다. 예를 들어, OAuth 서버 pod가 다시 시작될 때까지 oc login을 사용한 인증이 즉시 작동하지 않을 수 있습니다.
즉각적인 인증을 위해 system:admin kubeconfig 파일을 사용하는 것이 좋습니다. 이 방법은 OAuth 토큰에 대해 SSL/TLS 클라이언트 인증서에 대한 인증을 기반으로 합니다. 다음 명령을 실행하여 이 파일로 인증할 수 있습니다.
$ export KUBECONFIG=<installation_directory>/auth/kubeconfig다음 명령을 실행하여 인증된 사용자 이름을 표시합니다.
$ oc whoami5.4.2.3. etcd 백업에서 수동으로 클러스터 복원
"이전 클러스터 상태로 복원" 섹션에 설명된 복원 절차:
-
UPI 설치 시 컨트롤 플레인 노드에 대한
Machine또는ControlPlaneMachineset을 생성하지 않으므로 UPI 설치 방법을 사용하여 설치된 클러스터에 대한 2개의 컨트롤 플레인 노드를 완전히 다시 생성해야 합니다. - 새 단일 멤버 etcd 클러스터를 시작한 /usr/local/bin/cluster-restore.sh 스크립트를 사용하여 세 멤버로 확장합니다.
이와 반대로 이 절차는 다음과 같습니다.
- 컨트롤 플레인 노드를 다시 생성할 필요가 없습니다.
- 3개의 멤버 etcd 클러스터를 직접 시작합니다.
클러스터에서 컨트롤 플레인에 MachineSet 을 사용하는 경우 etcd 복구 절차를 위해 "Restoring to a previous cluster state"를 사용하는 것이 좋습니다.
클러스터를 복원할 때 동일한 z-stream 릴리스에서 가져온 etcd 백업을 사용해야 합니다. 예를 들어 OpenShift Container Platform 4.7.2 클러스터는 4.7.2에서 가져온 etcd 백업을 사용해야 합니다.
사전 요구 사항
-
cluster-admin역할(예:kubeadmin사용자)을 사용하여 사용자로 클러스터에 액세스합니다. -
호스트 사용자를 사용하여 모든 컨트롤 플레인 호스트에 대한 SSH 액세스
(예: 기본코어호스트 사용자) -
이전 etcd 스냅샷과 동일한 백업의 정적 pod 리소스가 모두 포함된 백업 디렉터리입니다. 디렉토리의 파일 이름은
snapshot_<datetimestamp>.db및static_kuberesources_<datetimestamp>.tar.gz형식이어야합니다.
절차
SSH를 사용하여 각 컨트롤 플레인 노드에 연결합니다.
복구 프로세스가 시작된 후에는 Kubernetes API 서버에 액세스할 수 없으므로 컨트롤 플레인 노드에 액세스할 수 없습니다. 따라서 별도의 터미널에서 액세스하려는 각 컨트롤 플레인 호스트에 SSH 연결을 사용하는 것이 좋습니다.
중요이 단계를 완료하지 않으면 컨트롤 플레인 호스트에 액세스하여 복구 프로세스를 완료할 수 없으며 이 상태에서 클러스터를 복구할 수 없습니다.
etcd 백업 디렉터리를 각 컨트롤 플레인 호스트에 복사합니다.
이 절차에서는 etcd 스냅샷과 정적 pod의 리소스가 포함된
백업디렉터리를 각 컨트롤 플레인 호스트의/home/core/assets디렉터리에 복사하는 것을 전제로 합니다. 아직 존재하지 않는 경우 이러한assets폴더를 생성해야 할 수도 있습니다.모든 컨트롤 플레인 노드에서 정적 Pod를 중지합니다. 한 번에 하나의 호스트입니다.
kubelet 매니페스트 디렉터리에서 기존 Kubernetes API Server 정적 Pod를 표시합니다.
$ mkdir -p /root/manifests-backup $ mv /etc/kubernetes/manifests/kube-apiserver-pod.yaml /root/manifests-backup/명령을 사용하여 Kubernetes API 서버 컨테이너가 중지되었는지 확인합니다.
$ crictl ps | grep kube-apiserver | grep -E -v "operator|guard"이 명령의 출력은 비어 있어야합니다. 비어 있지 않은 경우 몇 분 기다렸다가 다시 확인하십시오.
Kubernetes API Server 컨테이너가 계속 실행 중인 경우 다음 명령을 사용하여 수동으로 종료합니다.
$ crictl stop <container_id>kube-controller-manager-pod.yaml,kube-scheduler-pod.yaml및 마지막으로etcd-pod.yaml에 대해 동일한 단계를 반복합니다.다음 명령을 사용하여
kube-controller-managerPod를 중지합니다.$ mv /etc/kubernetes/manifests/kube-controller-manager-pod.yaml /root/manifests-backup/다음 명령을 사용하여 컨테이너가 중지되었는지 확인합니다.
$ crictl ps | grep kube-controller-manager | grep -E -v "operator|guard"다음 명령을 사용하여
kube-schedulerPod를 중지합니다.$ mv /etc/kubernetes/manifests/kube-scheduler-pod.yaml /root/manifests-backup/다음 명령을 사용하여 컨테이너가 중지되었는지 확인합니다.
$ crictl ps | grep kube-scheduler | grep -E -v "operator|guard"다음 명령을 사용하여
etcdpod를 중지합니다.$ mv /etc/kubernetes/manifests/etcd-pod.yaml /root/manifests-backup/다음 명령을 사용하여 컨테이너가 중지되었는지 확인합니다.
$ crictl ps | grep etcd | grep -E -v "operator|guard"
각 컨트롤 플레인 호스트에서 현재
etcd데이터를백업폴더로 이동하여 저장합니다.$ mkdir /home/core/assets/old-member-data $ mv /var/lib/etcd/member /home/core/assets/old-member-data이 데이터는
etcd백업 복원이 작동하지 않고etcd클러스터를 현재 상태로 복원해야 하는 경우 유용합니다.각 컨트롤 플레인 호스트에 대해 올바른 etcd 매개변수를 찾습니다.
<
ETCD_NAME>의 값은 각 컨트롤 플레인 호스트에 대해 고유하며 매니페스트/etc/kubernetes/static-pod-resources/etcd-certs/configmaps/restore-etcd-pod/pod.yaml파일의ETCD_NAME변수와 동일합니다. 다음 명령을 사용하여 찾을 수 있습니다.RESTORE_ETCD_POD_YAML="/etc/kubernetes/static-pod-resources/etcd-certs/configmaps/restore-etcd-pod/pod.yaml" cat $RESTORE_ETCD_POD_YAML | \ grep -A 1 $(cat $RESTORE_ETCD_POD_YAML | grep 'export ETCD_NAME' | grep -Eo 'NODE_.+_ETCD_NAME') | \ grep -Po '(?<=value: ").+(?=")'<
UUID>의 값은 명령을 사용하여 컨트롤 플레인 호스트에서 생성할 수 있습니다.$ uuidgen참고<
UUID>의 값은 한 번만 생성되어야 합니다. 하나의 컨트롤 플레인 호스트에서UUID를 생성한 후 다른 컨트롤 플레인 호스트에서 다시 생성하지 마십시오. 모든 컨트롤 플레인 호스트의 다음 단계에서 동일한UUID를 사용합니다.ETCD_NODE_PEER_URL의 값은 다음 예와 같이 설정해야 합니다.https://<IP_CURRENT_HOST>:2380올바른 IP는 특정 컨트롤 플레인 호스트의 <
ETCD_NAME>에서 명령을 사용하여 찾을 수 있습니다.$ echo <ETCD_NAME> | \ sed -E 's/[.-]/_/g' | \ xargs -I {} grep {} /etc/kubernetes/static-pod-resources/etcd-certs/configmaps/etcd-scripts/etcd.env | \ grep "IP" | grep -Po '(?<=").+(?=")'<
ETCD_INITIAL_CLUSTER>의 값은 다음과 같이 설정해야 합니다. 여기서 <ETCD_NAME_n>은 각 컨트롤 플레인 호스트의 <ETCD_NAME>입니다.참고사용되는 포트는 2380이어야 하며 2379가 아닙니다. 포트 2379는 etcd 데이터베이스 관리에 사용되며 컨테이너의 etcd start 명령에 직접 구성됩니다.
출력 예
<ETCD_NAME_0>=<ETCD_NODE_PEER_URL_0>,<ETCD_NAME_1>=<ETCD_NODE_PEER_URL_1>,<ETCD_NAME_2>=<ETCD_NODE_PEER_URL_2>1 - 1
- 각 컨트롤 플레인 호스트의
ETCD_NODE_PEER_URL값을 지정합니다.
&
lt;ETCD_INITIAL_CLUSTER> 값은 모든 컨트롤 플레인 호스트에서 동일하게 유지됩니다. 모든 컨트롤 플레인 호스트의 다음 단계에서 동일한 값이 필요합니다.
백업에서 etcd 데이터베이스를 다시 생성합니다.
이러한 작업은 각 컨트롤 플레인 호스트에서 실행해야 합니다.
다음 명령을 사용하여
etcd백업을/var/lib/etcd디렉토리에 복사합니다.$ cp /home/core/assets/backup/<snapshot_yyyy-mm-dd_hhmmss>.db /var/lib/etcd계속하기 전에 올바른
etcdctl이미지를 식별합니다. 다음 명령을 사용하여 Pod 매니페스트 백업에서 이미지를 검색합니다.$ jq -r '.spec.containers[]|select(.name=="etcdctl")|.image' /root/manifests-backup/etcd-pod.yaml$ podman run --rm -it --entrypoint="/bin/bash" -v /var/lib/etcd:/var/lib/etcd:z <image-hash>etcdctl도구 버전이 백업이 생성된etcd서버의 버전인지 확인합니다.$ etcdctl version현재 호스트에 올바른 값을 사용하여
etcd데이터베이스를 다시 생성하려면 다음 명령을 실행합니다.$ ETCDCTL_API=3 /usr/bin/etcdctl snapshot restore /var/lib/etcd/<snapshot_yyyy-mm-dd_hhmmss>.db \ --name "<ETCD_NAME>" \ --initial-cluster="<ETCD_INITIAL_CLUSTER>" \ --initial-cluster-token "openshift-etcd-<UUID>" \ --initial-advertise-peer-urls "<ETCD_NODE_PEER_URL>" \ --data-dir="/var/lib/etcd/restore-<UUID>" \ --skip-hash-check=true참고etcd데이터베이스를 다시 생성할 때는 따옴표가 필요합니다.
추가된 멤버로그에 출력된 값을 기록합니다. 예를 들면 다음과 같습니다.출력 예
2022-06-28T19:52:43Z info membership/cluster.go:421 added member {"cluster-id": "c5996b7c11c30d6b", "local-member-id": "0", "added-peer-id": "56cd73b614699e7", "added-peer-peer-urls": ["https://10.0.91.5:2380"], "added-peer-is-learner": false} 2022-06-28T19:52:43Z info membership/cluster.go:421 added member {"cluster-id": "c5996b7c11c30d6b", "local-member-id": "0", "added-peer-id": "1f63d01b31bb9a9e", "added-peer-peer-urls": ["https://10.0.90.221:2380"], "added-peer-is-learner": false} 2022-06-28T19:52:43Z info membership/cluster.go:421 added member {"cluster-id": "c5996b7c11c30d6b", "local-member-id": "0", "added-peer-id": "fdc2725b3b70127c", "added-peer-peer-urls": ["https://10.0.94.214:2380"], "added-peer-is-learner": false}- 컨테이너를 종료합니다.
-
다른 컨트롤 플레인 호스트에서 이러한 단계를 반복하여
추가된 멤버로그에 출력된 값이 모든 컨트롤 플레인 호스트에 대해 동일한지 확인합니다.
재생성된
etcd데이터베이스를 기본 위치로 이동합니다.이러한 작업은 각 컨트롤 플레인 호스트에서 실행해야 합니다.
재현된 데이터베이스(이전
etcdctl snapshot restore명령으로 생성된멤버폴더)를 기본 etcd 위치/var/lib/etcd:로 이동합니다.$ mv /var/lib/etcd/restore-<UUID>/member /var/lib/etcd/var/lib/etcd/member 폴더에서/var/lib/etcd/member폴더의 SELinux 컨텍스트를 복원합니다.$ restorecon -vR /var/lib/etcd/남은 파일과 디렉터리를 제거합니다.
$ rm -rf /var/lib/etcd/restore-<UUID>$ rm /var/lib/etcd/<snapshot_yyyy-mm-dd_hhmmss>.db중요완료되면
/var/lib/etcd디렉토리에 폴더멤버만 포함되어야 합니다.- 다른 컨트롤 플레인 호스트에서 이 단계를 반복합니다.
etcd 클러스터를 다시 시작하십시오.
- 다음 단계는 모든 컨트롤 플레인 호스트에서 실행해야 하지만 한 번에 하나의 호스트 를 실행해야 합니다.
kubelet이 관련 컨테이너를 시작하도록 하려면
etcd정적 Pod 매니페스트를 kubelet 매니페스트 디렉터리로 다시 이동합니다.$ mv /tmp/etcd-pod.yaml /etc/kubernetes/manifests모든
etcd컨테이너가 시작되었는지 확인합니다.$ crictl ps | grep etcd | grep -v operator출력 예
38c814767ad983 f79db5a8799fd2c08960ad9ee22f784b9fbe23babe008e8a3bf68323f004c840 28 seconds ago Running etcd-health-monitor 2 fe4b9c3d6483c e1646b15207c6 9d28c15860870e85c91d0e36b45f7a6edd3da757b113ec4abb4507df88b17f06 About a minute ago Running etcd-metrics 0 fe4b9c3d6483c 08ba29b1f58a7 9d28c15860870e85c91d0e36b45f7a6edd3da757b113ec4abb4507df88b17f06 About a minute ago Running etcd 0 fe4b9c3d6483c 2ddc9eda16f53 9d28c15860870e85c91d0e36b45f7a6edd3da757b113ec4abb4507df88b17f06 About a minute ago Running etcdctl이 명령의 출력이 비어 있으면 몇 분 기다렸다가 다시 확인하십시오.
etcd클러스터의 상태를 확인합니다.다음 명령을 사용하여 컨트롤 플레인 호스트에서
etcd클러스터의 상태를 확인합니다.$ crictl exec -it $(crictl ps | grep etcdctl | awk '{print $1}') etcdctl endpoint status -w table출력 예
+--------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+ | ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS | +--------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+ | https://10.0.89.133:2379 | 682e4a83a0cec6c0 | 3.5.0 | 67 MB | true | false | 2 | 218 | 218 | | | https://10.0.92.74:2379 | 450bcf6999538512 | 3.5.0 | 67 MB | false | false | 2 | 218 | 218 | | | https://10.0.93.129:2379 | 358efa9c1d91c3d6 | 3.5.0 | 67 MB | false | false | 2 | 218 | 218 | | +--------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
다른 정적 pod를 다시 시작합니다.
한 번에 하나의 호스트이지만 모든 컨트롤 플레인 호스트에서 다음 단계를 실행해야 합니다.
Kubernetes API Server 정적 Pod 매니페스트를 kubelet 매니페스트 디렉터리로 다시 이동하여 kubelet이 명령을 사용하여 관련 컨테이너를 시작합니다.
$ mv /root/manifests-backup/kube-apiserver-pod.yaml /etc/kubernetes/manifests모든 Kubernetes API Server 컨테이너가 시작되었는지 확인합니다.
$ crictl ps | grep kube-apiserver | grep -v operator참고다음 명령의 출력이 비어 있으면 몇 분 기다렸다가 다시 확인합니다.
kube-controller-manager-pod.yaml및kube-scheduler-pod.yaml파일에 대해 동일한 단계를 반복합니다.다음 명령을 사용하여 모든 노드에서 kubelet을 다시 시작합니다.
$ systemctl restart kubelet다음 명령을 사용하여 나머지 컨트롤 플레인 Pod를 시작합니다.
$ mv /root/manifests-backup/kube-* /etc/kubernetes/manifests/kube-apiserver,kube-scheduler및kube-controller-managerPod가 올바르게 시작되었는지 확인합니다.$ crictl ps | grep -E 'kube-(apiserver|scheduler|controller-manager)' | grep -v -E 'operator|guard'다음 명령을 사용하여 OVN 데이터베이스를 지웁니다.
for NODE in $(oc get node -o name | sed 's:node/::g') do oc debug node/${NODE} -- chroot /host /bin/bash -c 'rm -f /var/lib/ovn-ic/etc/ovn*.db && systemctl restart ovs-vswitchd ovsdb-server' oc -n openshift-ovn-kubernetes delete pod -l app=ovnkube-node --field-selector=spec.nodeName=${NODE} --wait oc -n openshift-ovn-kubernetes wait pod -l app=ovnkube-node --field-selector=spec.nodeName=${NODE} --for condition=ContainersReady --timeout=600s done
5.4.2.5. 영구 스토리지 상태 복원을 위한 문제 및 해결 방법
OpenShift Container Platform 클러스터에서 모든 형식의 영구저장장치를 사용하는 경우 일반적으로 클러스터의 상태가 etcd 외부에 저장됩니다. StatefulSet 오브젝트에서 실행 중인 Pod 또는 데이터베이스에서 실행 중인 Elasticsearch 클러스터일 수 있습니다. etcd 백업에서 복원하면 OpenShift Container Platform의 워크로드 상태도 복원됩니다. 그러나 etcd 스냅샷이 오래된 경우 상태가 유효하지 않거나 오래되었을 수 있습니다.
PV(영구 볼륨)의 내용은 etcd 스냅샷의 일부가 아닙니다. etcd 스냅샷에서 OpenShift Container Platform 클러스터를 복원할 때 중요하지 않은 워크로드가 중요한 데이터에 액세스할 수 있으며 그 반대의 경우로도 할 수 있습니다.
다음은 사용되지 않는 상태를 생성하는 몇 가지 예제 시나리오입니다.
- MySQL 데이터베이스는 PV 오브젝트에서 지원하는 pod에서 실행됩니다. etcd 스냅샷에서 OpenShift Container Platform을 복원해도 스토리지 공급자의 볼륨을 다시 가져오지 않으며 pod를 반복적으로 시작하려고 하지만 실행 중인 MySQL pod는 생성되지 않습니다. 스토리지 공급자에서 볼륨을 복원한 다음 새 볼륨을 가리키도록 PV를 편집하여 이 Pod를 수동으로 복원해야 합니다.
- Pod P1에서는 노드 X에 연결된 볼륨 A를 사용합니다. 다른 pod가 노드 Y에서 동일한 볼륨을 사용하는 동안 etcd 스냅샷을 가져오는 경우 etcd 복원이 수행되면 해당 볼륨이 여전히 Y 노드에 연결되어 있으므로 Pod P1이 제대로 시작되지 않을 수 있습니다. OpenShift Container Platform은 연결을 인식하지 못하고 자동으로 연결을 분리하지 않습니다. 이 경우 볼륨이 노드 X에 연결된 다음 Pod P1이 시작될 수 있도록 노드 Y에서 볼륨을 수동으로 분리해야 합니다.
- etcd 스냅샷을 만든 후 클라우드 공급자 또는 스토리지 공급자 인증 정보가 업데이트되었습니다. 이로 인해 해당 인증 정보를 사용하는 CSI 드라이버 또는 Operator가 작동하지 않습니다. 해당 드라이버 또는 Operator에 필요한 인증 정보를 수동으로 업데이트해야 할 수 있습니다.
etcd 스냅샷을 만든 후 OpenShift Container Platform 노드에서 장치가 제거되거나 이름이 변경됩니다. Local Storage Operator는
/dev/disk/by-id또는/dev디렉터리에서 관리하는 각 PV에 대한 심볼릭 링크를 생성합니다. 이 경우 로컬 PV가 더 이상 존재하지 않는 장치를 참조할 수 있습니다.이 문제를 해결하려면 관리자가 다음을 수행해야 합니다.
- 잘못된 장치가 있는 PV를 수동으로 제거합니다.
- 각 노드에서 심볼릭 링크를 제거합니다.
-
LocalVolume또는LocalVolumeSet오브젝트를 삭제합니다 (스토리지영구 스토리지 구성 로컬 볼륨을 사용하는 영구 스토리지 Local Storage Operator 리소스 삭제참조).
5.4.3. 만료된 컨트롤 플레인 인증서 복구
5.4.3.1. 만료된 컨트롤 플레인 인증서 복구
클러스터는 만료된 컨트롤 플레인 인증서에서 자동으로 복구될 수 있습니다.
그러나 kubelet 인증서를 복구하려면 대기 중인 node-bootstrapper 인증서 서명 요청(CSR)을 수동으로 승인해야 합니다. 사용자 프로비저닝 설치의 경우 보류 중인 kubelet 서비스 CSR을 승인해야 할 수도 있습니다.
보류중인 CSR을 승인하려면 다음 단계를 수행합니다.
절차
현재 CSR의 목록을 가져옵니다.
$ oc get csr출력 예
NAME AGE SIGNERNAME REQUESTOR CONDITION csr-2s94x 8m3s kubernetes.io/kubelet-serving system:node:<node_name> Pending1 csr-4bd6t 8m3s kubernetes.io/kubelet-serving system:node:<node_name> Pending csr-4hl85 13m kubernetes.io/kube-apiserver-client-kubelet system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending2 csr-zhhhp 3m8s kubernetes.io/kube-apiserver-client-kubelet system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending ...CSR의 세부 사항을 검토하여 CSR이 유효한지 확인합니다.
$ oc describe csr <csr_name>1 - 1
<csr_name>은 현재 CSR 목록에 있는 CSR의 이름입니다.
각각의 유효한
node-bootstrapperCSR을 승인합니다.$ oc adm certificate approve <csr_name>사용자 프로비저닝 설치의 경우 CSR을 제공하는 각 유효한 kubelet을 승인합니다.
$ oc adm certificate approve <csr_name>
5.4.4. AWS 리전 내에서 호스팅된 클러스터의 재해 복구
호스팅된 클러스터의 재해 복구(DR)가 필요한 경우 호스팅된 클러스터를 AWS 내의 동일한 리전으로 복구할 수 있습니다. 예를 들어 관리 클러스터 업그레이드에 실패하고 호스팅된 클러스터가 읽기 전용 상태인 경우 DR이 필요합니다.
호스트 컨트롤 플레인은 기술 프리뷰 기능 전용입니다. 기술 프리뷰 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원되지 않으며 기능적으로 완전하지 않을 수 있습니다. 따라서 프로덕션 환경에서 사용하는 것은 권장하지 않습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다.
Red Hat 기술 프리뷰 기능의 지원 범위에 대한 자세한 내용은 기술 프리뷰 기능 지원 범위를 참조하십시오.
DR 프로세스에는 다음 세 가지 주요 단계가 포함됩니다.
- 소스 관리 클러스터에서 호스팅된 클러스터 백업
- 대상 관리 클러스터에서 호스팅된 클러스터 복원
- 소스 관리 클러스터에서 호스팅된 클러스터 삭제
워크로드는 프로세스 중에 계속 실행됩니다. 일정 기간 Cluster API를 사용할 수 없지만 작업자 노드에서 실행 중인 서비스에는 영향을 미치지 않습니다.
다음 예제와 같이 소스 관리 클러스터와 대상 관리 클러스터에 모두 API 서버 URL을 유지하려면 --external-dns 플래그가 있어야 합니다.
예: 외부 DNS 플래그
--external-dns-provider=aws \
--external-dns-credentials=<AWS Credentials location> \
--external-dns-domain-filter=<DNS Base Domain>
이렇게 하면 서버 URL이 https://api-sample-hosted.sample-hosted.aws.openshift.com 로 끝납니다.
API 서버 URL을 유지하기 위해 --external-dns 플래그를 포함하지 않으면 호스팅 클러스터를 마이그레이션할 수 없습니다.
5.4.4.1. 환경 및 컨텍스트 예
복원할 클러스터가 3개 있는 경우를 고려해 보십시오. 두 개는 관리 클러스터이며 하나는 호스팅된 클러스터입니다. 컨트롤 플레인만 또는 컨트롤 플레인과 노드를 복원할 수 있습니다. 시작하기 전에 다음 정보가 필요합니다.
- 소스 MGMT 네임스페이스: 소스 관리 네임스페이스
- Source MGMT ClusterName: 소스 관리 클러스터 이름
-
Source MGMT Kubeconfig: 소스 관리
kubeconfig파일 -
대상 MGMT Kubeconfig: 대상 관리
kubeconfig파일 -
HC Kubeconfig: 호스팅된 클러스터
kubeconfig파일 - SSH 키 파일: SSH 공개 키
- pull secret: 릴리스 이미지에 액세스할 수 있는 풀 시크릿 파일
- AWS 인증 정보
- AWS 리전
- 기본 도메인: 외부 DNS로 사용할 DNS 기본 도메인
- S3 버킷 이름: etcd 백업을 업로드할 AWS 리전의 버킷
이 정보는 다음 예제 환경 변수에 표시됩니다.
환경 변수 예
SSH_KEY_FILE=${HOME}/.ssh/id_rsa.pub
BASE_PATH=${HOME}/hypershift
BASE_DOMAIN="aws.sample.com"
PULL_SECRET_FILE="${HOME}/pull_secret.json"
AWS_CREDS="${HOME}/.aws/credentials"
AWS_ZONE_ID="Z02718293M33QHDEQBROL"
CONTROL_PLANE_AVAILABILITY_POLICY=SingleReplica
HYPERSHIFT_PATH=${BASE_PATH}/src/hypershift
HYPERSHIFT_CLI=${HYPERSHIFT_PATH}/bin/hypershift
HYPERSHIFT_IMAGE=${HYPERSHIFT_IMAGE:-"quay.io/${USER}/hypershift:latest"}
NODE_POOL_REPLICAS=${NODE_POOL_REPLICAS:-2}
# MGMT Context
MGMT_REGION=us-west-1
MGMT_CLUSTER_NAME="${USER}-dev"
MGMT_CLUSTER_NS=${USER}
MGMT_CLUSTER_DIR="${BASE_PATH}/hosted_clusters/${MGMT_CLUSTER_NS}-${MGMT_CLUSTER_NAME}"
MGMT_KUBECONFIG="${MGMT_CLUSTER_DIR}/kubeconfig"
# MGMT2 Context
MGMT2_CLUSTER_NAME="${USER}-dest"
MGMT2_CLUSTER_NS=${USER}
MGMT2_CLUSTER_DIR="${BASE_PATH}/hosted_clusters/${MGMT2_CLUSTER_NS}-${MGMT2_CLUSTER_NAME}"
MGMT2_KUBECONFIG="${MGMT2_CLUSTER_DIR}/kubeconfig"
# Hosted Cluster Context
HC_CLUSTER_NS=clusters
HC_REGION=us-west-1
HC_CLUSTER_NAME="${USER}-hosted"
HC_CLUSTER_DIR="${BASE_PATH}/hosted_clusters/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}"
HC_KUBECONFIG="${HC_CLUSTER_DIR}/kubeconfig"
BACKUP_DIR=${HC_CLUSTER_DIR}/backup
BUCKET_NAME="${USER}-hosted-${MGMT_REGION}"
# DNS
AWS_ZONE_ID="Z07342811SH9AA102K1AC"
EXTERNAL_DNS_DOMAIN="hc.jpdv.aws.kerbeross.com"5.4.4.2. 백업 및 복원 프로세스 개요
백업 및 복원 프로세스는 다음과 같이 작동합니다.
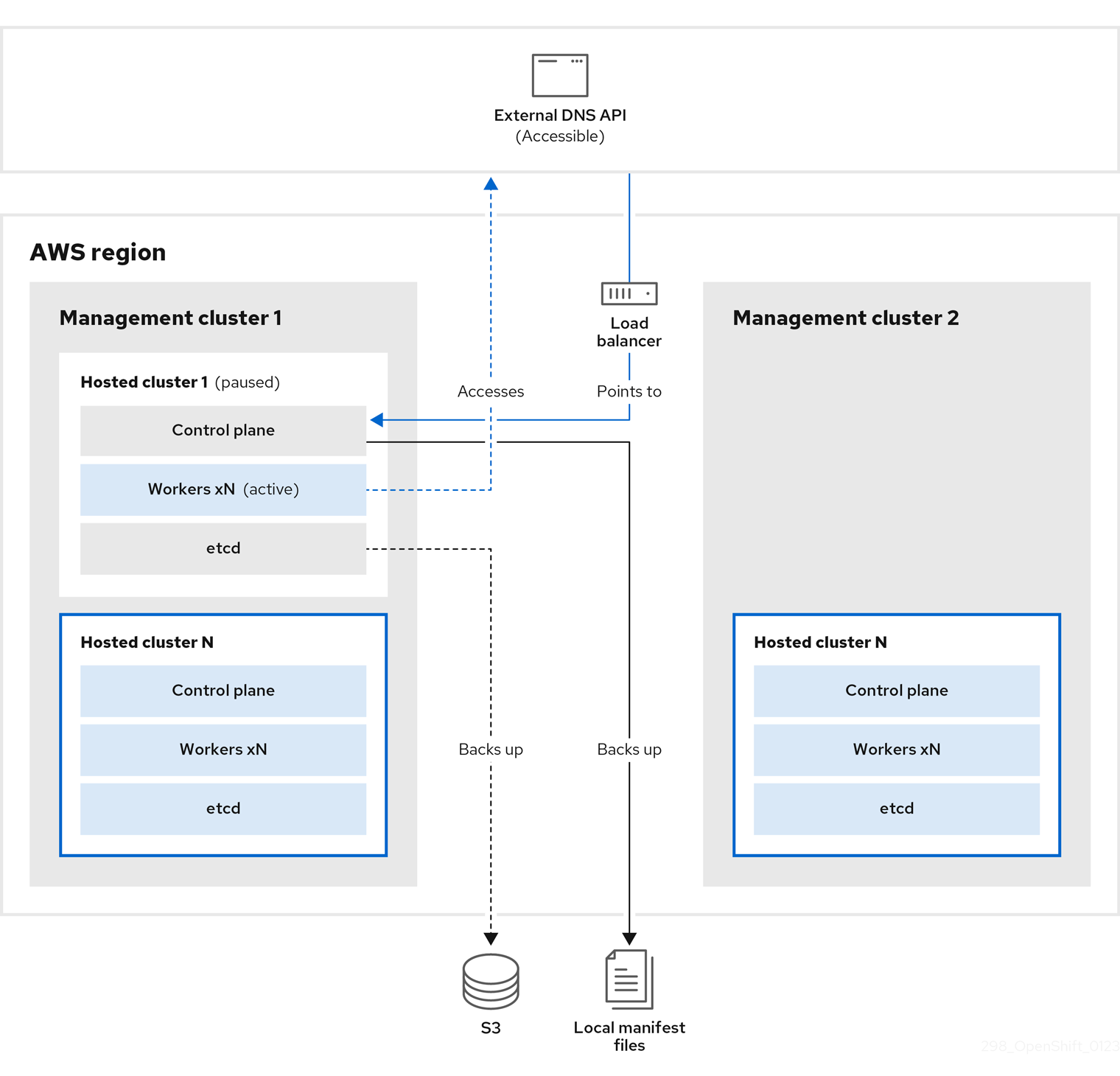
관리 클러스터 1에서 소스 관리 클러스터로 간주할 수 있으며 컨트롤 플레인 및 작업자는 외부 DNS API를 사용하여 상호 작용합니다. 외부 DNS API에 액세스할 수 있으며 로드 밸런서는 관리 클러스터 사이에 있습니다.

etcd, 컨트롤 플레인 및 작업자 노드가 포함된 호스팅 클러스터의 스냅샷을 생성합니다. 이 프로세스 중에 작업자 노드는 액세스할 수 없는 경우에도 외부 DNS API에 계속 액세스하려고 하며 워크로드가 실행되고 컨트롤 플레인은 로컬 매니페스트 파일에 저장되고 etcd는 S3 버킷으로 백업됩니다. 데이터 플레인이 활성화되고 컨트롤 플레인이 일시 중지되었습니다.
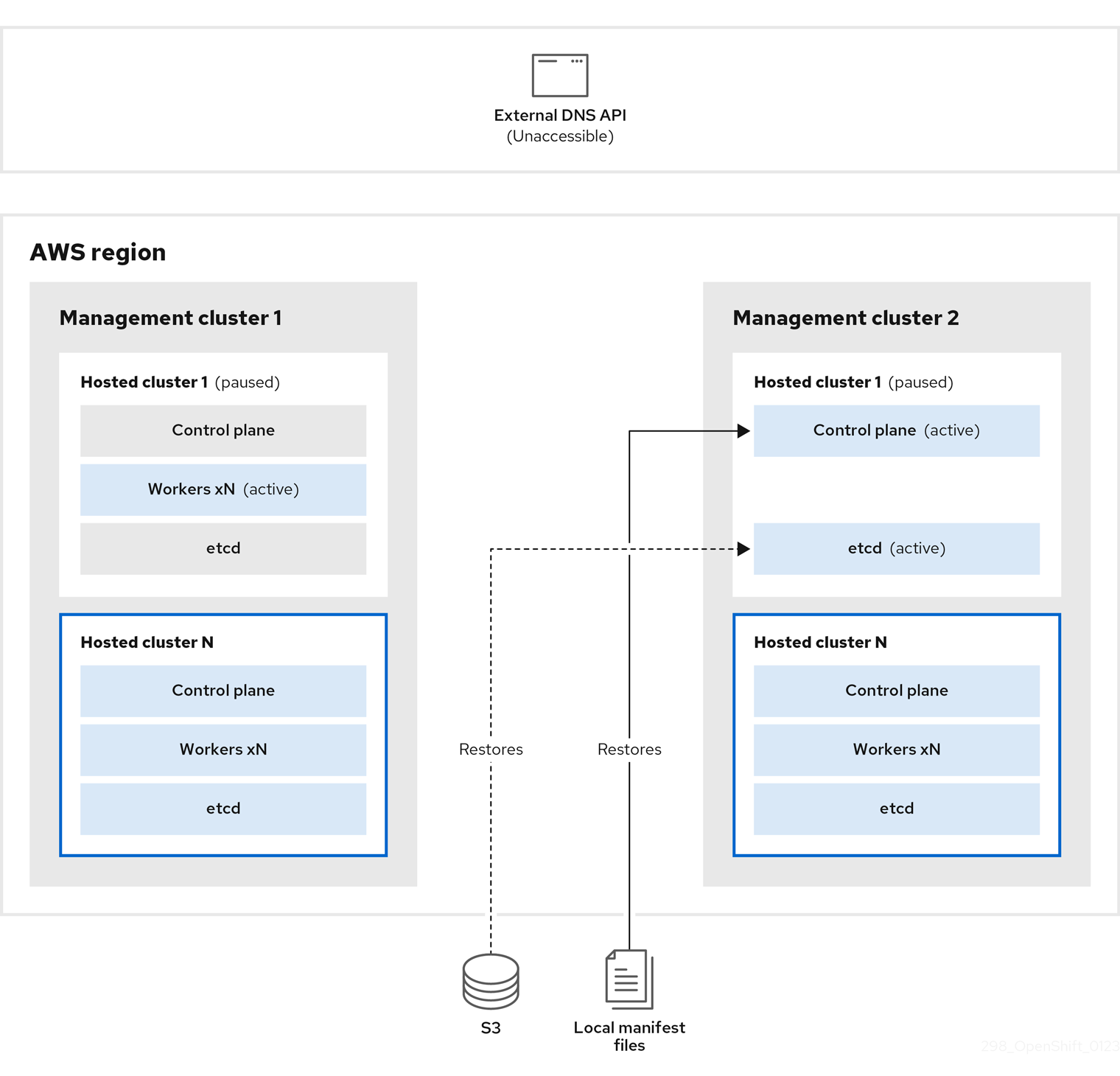
대상 관리 클러스터 2의 경우 S3 버킷에서 etcd를 복원하고 로컬 매니페스트 파일에서 컨트롤 플레인을 복원합니다. 이 프로세스 중에 외부 DNS API가 중지되고 호스트된 클러스터 API에 액세스할 수 없게 되고 API를 사용하는 모든 작업자는 매니페스트 파일을 업데이트할 수 없지만 워크로드가 계속 실행되고 있습니다.
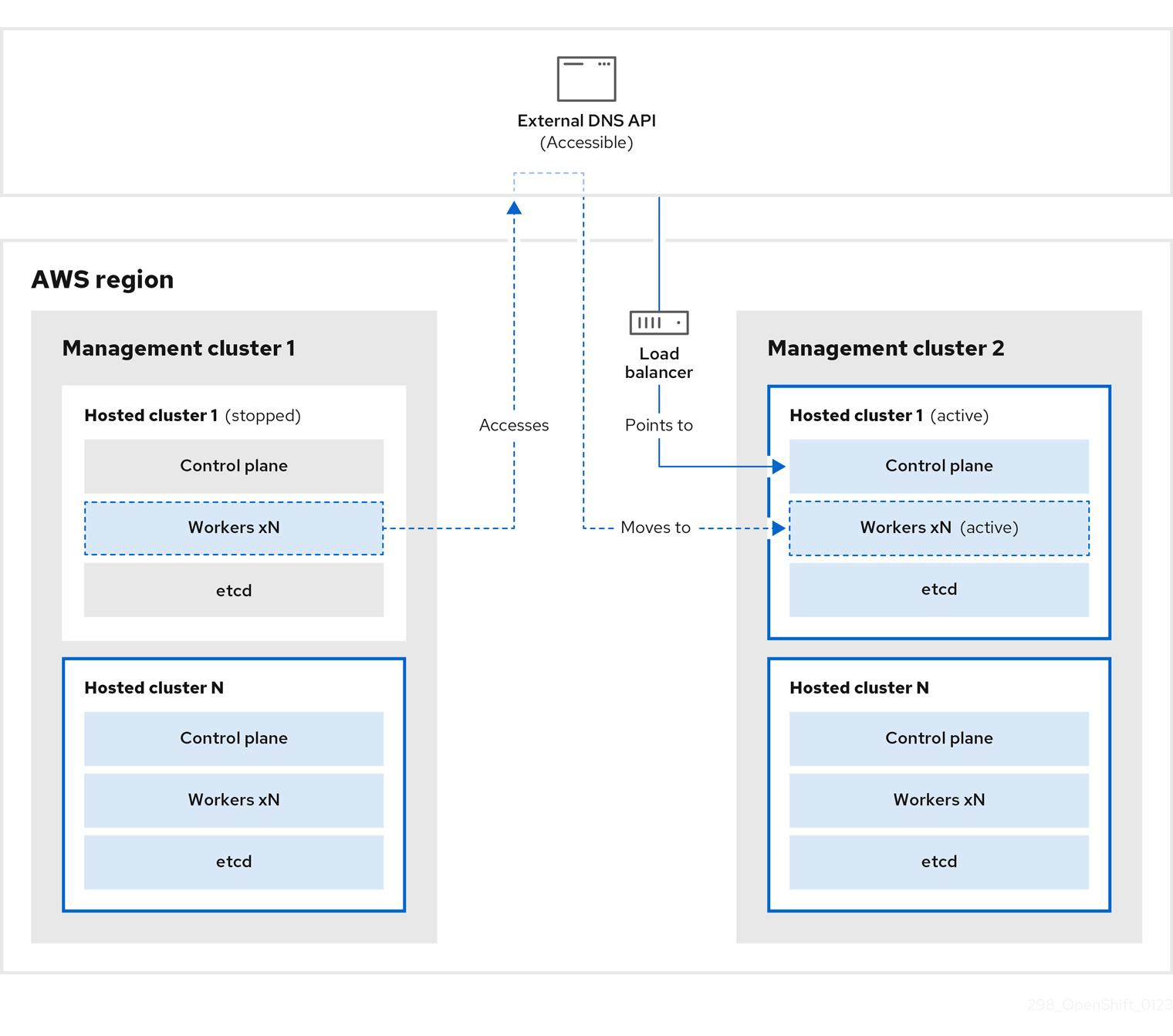
외부 DNS API는 다시 액세스할 수 있으며 작업자 노드는 이를 사용하여 관리 클러스터 2로 이동합니다. 외부 DNS API는 컨트롤 플레인을 가리키는 로드 밸런서에 액세스할 수 있습니다.
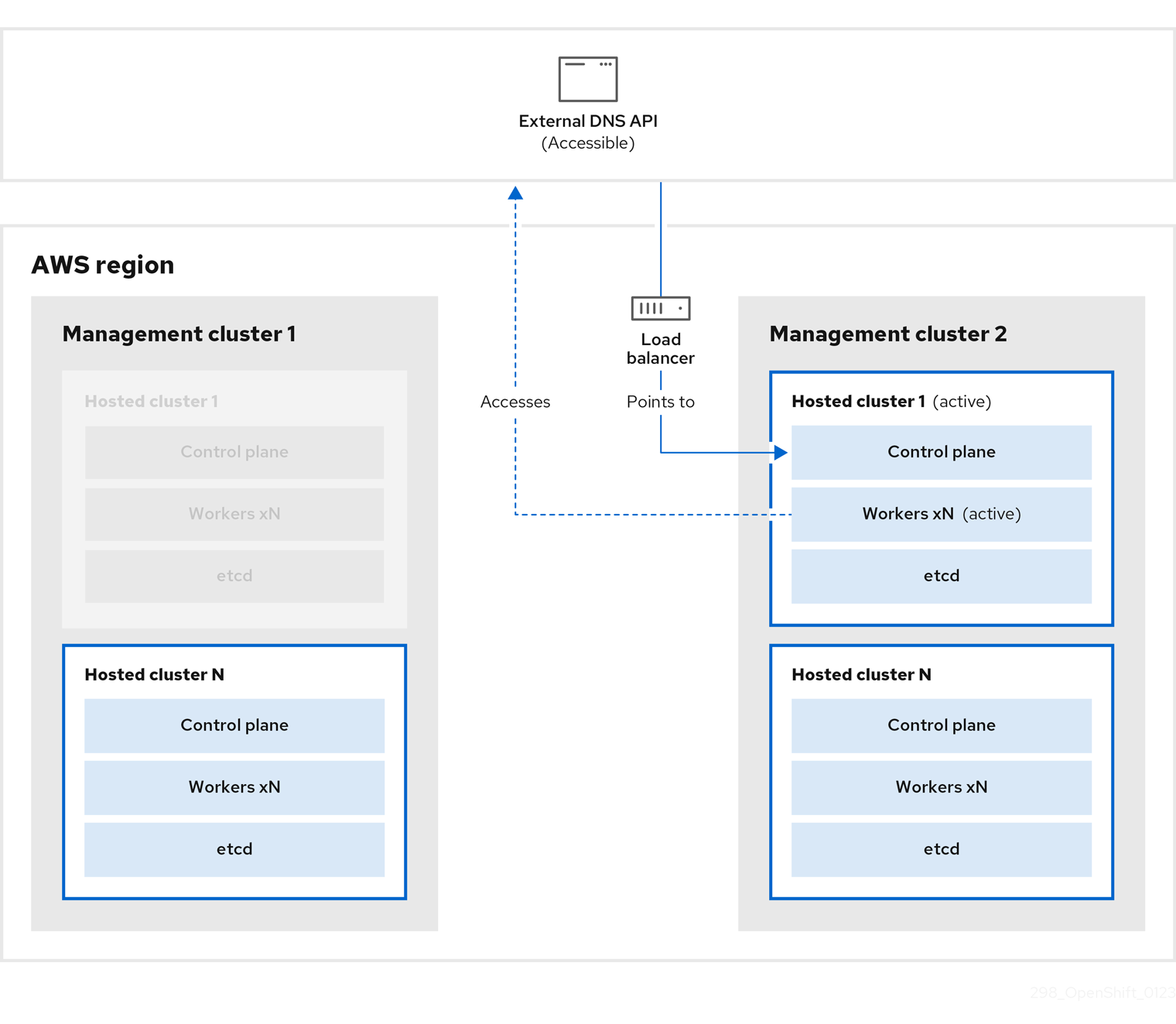
관리 클러스터 2에서 컨트롤 플레인 및 작업자 노드는 외부 DNS API를 사용하여 상호 작용합니다. 리소스는 etcd의 S3 백업을 제외하고 관리 클러스터 1에서 삭제됩니다. mangagement 클러스터 1에서 호스트 클러스터를 다시 설정하려고 하면 작동하지 않습니다.
호스팅된 클러스터를 수동으로 백업 및 복원하거나 스크립트를 실행하여 프로세스를 완료할 수 있습니다. 스크립트에 대한 자세한 내용은 "호스트된 클러스터를 백업 및 복원하기 위해 스크립트 실행"을 참조하십시오.
5.4.4.3. 호스팅된 클러스터 백업
대상 관리 클러스터에서 호스팅된 클러스터를 복구하려면 먼저 관련 데이터를 모두 백업해야 합니다.
절차
다음 명령을 입력하여 소스 관리 클러스터를 선언할 configmap 파일을 생성합니다.
$ oc create configmap mgmt-parent-cluster -n default --from-literal=from=${MGMT_CLUSTER_NAME}다음 명령을 입력하여 호스팅 클러스터 및 노드 풀에서 조정을 종료합니다.
$ PAUSED_UNTIL="true" $ oc patch -n ${HC_CLUSTER_NS} hostedclusters/${HC_CLUSTER_NAME} -p '{"spec":{"pausedUntil":"'${PAUSED_UNTIL}'"}}' --type=merge $ oc scale deployment -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --replicas=0 kube-apiserver openshift-apiserver openshift-oauth-apiserver control-plane-operator$ PAUSED_UNTIL="true" $ oc patch -n ${HC_CLUSTER_NS} hostedclusters/${HC_CLUSTER_NAME} -p '{"spec":{"pausedUntil":"'${PAUSED_UNTIL}'"}}' --type=merge $ oc patch -n ${HC_CLUSTER_NS} nodepools/${NODEPOOLS} -p '{"spec":{"pausedUntil":"'${PAUSED_UNTIL}'"}}' --type=merge $ oc scale deployment -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --replicas=0 kube-apiserver openshift-apiserver openshift-oauth-apiserver control-plane-operator다음 bash 스크립트를 실행하여 etcd를 백업하고 S3 버킷에 데이터를 업로드합니다.
작은 정보이 스크립트를 함수로 래핑하고 main 함수에서 호출합니다.
# ETCD Backup ETCD_PODS="etcd-0" if [ "${CONTROL_PLANE_AVAILABILITY_POLICY}" = "HighlyAvailable" ]; then ETCD_PODS="etcd-0 etcd-1 etcd-2" fi for POD in ${ETCD_PODS}; do # Create an etcd snapshot oc exec -it ${POD} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -- env ETCDCTL_API=3 /usr/bin/etcdctl --cacert /etc/etcd/tls/client/etcd-client-ca.crt --cert /etc/etcd/tls/client/etcd-client.crt --key /etc/etcd/tls/client/etcd-client.key --endpoints=localhost:2379 snapshot save /var/lib/data/snapshot.db oc exec -it ${POD} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -- env ETCDCTL_API=3 /usr/bin/etcdctl -w table snapshot status /var/lib/data/snapshot.db FILEPATH="/${BUCKET_NAME}/${HC_CLUSTER_NAME}-${POD}-snapshot.db" CONTENT_TYPE="application/x-compressed-tar" DATE_VALUE=`date -R` SIGNATURE_STRING="PUT\n\n${CONTENT_TYPE}\n${DATE_VALUE}\n${FILEPATH}" set +x ACCESS_KEY=$(grep aws_access_key_id ${AWS_CREDS} | head -n1 | cut -d= -f2 | sed "s/ //g") SECRET_KEY=$(grep aws_secret_access_key ${AWS_CREDS} | head -n1 | cut -d= -f2 | sed "s/ //g") SIGNATURE_HASH=$(echo -en ${SIGNATURE_STRING} | openssl sha1 -hmac "${SECRET_KEY}" -binary | base64) set -x # FIXME: this is pushing to the OIDC bucket oc exec -it etcd-0 -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -- curl -X PUT -T "/var/lib/data/snapshot.db" \ -H "Host: ${BUCKET_NAME}.s3.amazonaws.com" \ -H "Date: ${DATE_VALUE}" \ -H "Content-Type: ${CONTENT_TYPE}" \ -H "Authorization: AWS ${ACCESS_KEY}:${SIGNATURE_HASH}" \ https://${BUCKET_NAME}.s3.amazonaws.com/${HC_CLUSTER_NAME}-${POD}-snapshot.db doneetcd 백업에 대한 자세한 내용은 "호스트된 클러스터에서 etcd 백업 및 복원"을 참조하십시오.
다음 명령을 입력하여 Kubernetes 및 OpenShift Container Platform 오브젝트를 백업합니다. 다음 오브젝트를 백업해야 합니다.
-
HostedCluster네임스페이스의 HostedCluster 및NodePool오브젝트 -
HostedCluster네임스페이스의 HostedCluster 시크릿 -
HostedControl Plane네임스페이스의 HostedControlPlane -
호스팅된 컨트롤 플레인 네임스페이스의 클러스터 -
AWSCluster,AWSMachineTemplate,AWSMachineTemplate 네임스페이스의 AWSMachineTemplate -
MachineDeployments,MachineSets, Hosted Control Plane 네임스페이스의머신 호스팅된
컨트롤 플레인 네임스페이스의 controlPlane시크릿$ mkdir -p ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS} ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} $ chmod 700 ${BACKUP_DIR}/namespaces/ # HostedCluster $ echo "Backing Up HostedCluster Objects:" $ oc get hc ${HC_CLUSTER_NAME} -n ${HC_CLUSTER_NS} -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/hc-${HC_CLUSTER_NAME}.yaml $ echo "--> HostedCluster" $ sed -i '' -e '/^status:$/,$d' ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/hc-${HC_CLUSTER_NAME}.yaml # NodePool $ oc get np ${NODEPOOLS} -n ${HC_CLUSTER_NS} -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/np-${NODEPOOLS}.yaml $ echo "--> NodePool" $ sed -i '' -e '/^status:$/,$ d' ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/np-${NODEPOOLS}.yaml # Secrets in the HC Namespace $ echo "--> HostedCluster Secrets:" for s in $(oc get secret -n ${HC_CLUSTER_NS} | grep "^${HC_CLUSTER_NAME}" | awk '{print $1}'); do oc get secret -n ${HC_CLUSTER_NS} $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/secret-${s}.yaml done # Secrets in the HC Control Plane Namespace $ echo "--> HostedCluster ControlPlane Secrets:" for s in $(oc get secret -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} | egrep -v "docker|service-account-token|oauth-openshift|NAME|token-${HC_CLUSTER_NAME}" | awk '{print $1}'); do oc get secret -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/secret-${s}.yaml done # Hosted Control Plane $ echo "--> HostedControlPlane:" $ oc get hcp ${HC_CLUSTER_NAME} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/hcp-${HC_CLUSTER_NAME}.yaml # Cluster $ echo "--> Cluster:" $ CL_NAME=$(oc get hcp ${HC_CLUSTER_NAME} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o jsonpath={.metadata.labels.\*} | grep ${HC_CLUSTER_NAME}) $ oc get cluster ${CL_NAME} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/cl-${HC_CLUSTER_NAME}.yaml # AWS Cluster $ echo "--> AWS Cluster:" $ oc get awscluster ${HC_CLUSTER_NAME} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/awscl-${HC_CLUSTER_NAME}.yaml # AWS MachineTemplate $ echo "--> AWS Machine Template:" $ oc get awsmachinetemplate ${NODEPOOLS} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/awsmt-${HC_CLUSTER_NAME}.yaml # AWS Machines $ echo "--> AWS Machine:" $ CL_NAME=$(oc get hcp ${HC_CLUSTER_NAME} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o jsonpath={.metadata.labels.\*} | grep ${HC_CLUSTER_NAME}) for s in $(oc get awsmachines -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --no-headers | grep ${CL_NAME} | cut -f1 -d\ ); do oc get -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} awsmachines $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/awsm-${s}.yaml done # MachineDeployments $ echo "--> HostedCluster MachineDeployments:" for s in $(oc get machinedeployment -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name); do mdp_name=$(echo ${s} | cut -f 2 -d /) oc get -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machinedeployment-${mdp_name}.yaml done # MachineSets $ echo "--> HostedCluster MachineSets:" for s in $(oc get machineset -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name); do ms_name=$(echo ${s} | cut -f 2 -d /) oc get -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machineset-${ms_name}.yaml done # Machines $ echo "--> HostedCluster Machine:" for s in $(oc get machine -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name); do m_name=$(echo ${s} | cut -f 2 -d /) oc get -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machine-${m_name}.yaml done
-
다음 명령을 입력하여
ControlPlane경로를 정리합니다.$ oc delete routes -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --all해당 명령을 입력하여 ExternalDNS Operator에서 Route53 항목을 삭제할 수 있습니다.
이 스크립트를 실행하여 Route53 항목이 정리되었는지 확인합니다.
function clean_routes() { if [[ -z "${1}" ]];then echo "Give me the NS where to clean the routes" exit 1 fi # Constants if [[ -z "${2}" ]];then echo "Give me the Route53 zone ID" exit 1 fi ZONE_ID=${2} ROUTES=10 timeout=40 count=0 # This allows us to remove the ownership in the AWS for the API route oc delete route -n ${1} --all while [ ${ROUTES} -gt 2 ] do echo "Waiting for ExternalDNS Operator to clean the DNS Records in AWS Route53 where the zone id is: ${ZONE_ID}..." echo "Try: (${count}/${timeout})" sleep 10 if [[ $count -eq timeout ]];then echo "Timeout waiting for cleaning the Route53 DNS records" exit 1 fi count=$((count+1)) ROUTES=$(aws route53 list-resource-record-sets --hosted-zone-id ${ZONE_ID} --max-items 10000 --output json | grep -c ${EXTERNAL_DNS_DOMAIN}) done } # SAMPLE: clean_routes "<HC ControlPlane Namespace>" "<AWS_ZONE_ID>" clean_routes "${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}" "${AWS_ZONE_ID}"
검증
모든 OpenShift Container Platform 오브젝트와 S3 버킷을 확인하여 모든 항목이 예상대로 표시되는지 확인합니다.
다음 단계
호스팅된 클러스터를 복원합니다.
5.4.4.4. 호스트 클러스터 복원
백업한 모든 오브젝트를 수집하여 대상 관리 클러스터에서 복원합니다.
사전 요구 사항
소스 관리 클러스터에서 데이터를 백업합니다.
대상 관리 클러스터의 kubeconfig 파일이 KUBECONFIG 변수에 설정된 대로 배치되거나 스크립트를 사용하는 경우 MGMT2_KUBECONFIG 변수에 배치되어 있는지 확인합니다. 내보내기 KUBECONFIG=<Kubeconfig FilePath > 또는 스크립트를 사용하는 경우 내보내기 KUBECONFIG=${MGMT2_KUBECONFIG} 를 사용합니다.
절차
다음 명령을 입력하여 새 관리 클러스터에 복원 중인 클러스터의 네임스페이스가 포함되어 있지 않은지 확인합니다.
# Just in case $ export KUBECONFIG=${MGMT2_KUBECONFIG} $ BACKUP_DIR=${HC_CLUSTER_DIR}/backup # Namespace deletion in the destination Management cluster $ oc delete ns ${HC_CLUSTER_NS} || true $ oc delete ns ${HC_CLUSTER_NS}-{HC_CLUSTER_NAME} || true다음 명령을 입력하여 삭제된 네임스페이스를 다시 생성합니다.
# Namespace creation $ oc new-project ${HC_CLUSTER_NS} $ oc new-project ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}다음 명령을 입력하여 HC 네임스페이스에 보안을 복원합니다.
$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/secret-*다음 명령을 입력하여
HostedCluster컨트롤 플레인 네임스페이스의 오브젝트를 복원합니다.# Secrets $ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/secret-* # Cluster $ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/hcp-* $ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/cl-*AWS 인스턴스를 재사용하기 위해 노드와 노드 풀을 복구하는 경우 다음 명령을 입력하여 HC 컨트롤 플레인 네임스페이스의 오브젝트를 복원합니다.
# AWS $ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/awscl-* $ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/awsmt-* $ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/awsm-* # Machines $ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machinedeployment-* $ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machineset-* $ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machine-*이 bash 스크립트를 실행하여 etcd 데이터 및 호스팅 클러스터를 복원하십시오.
ETCD_PODS="etcd-0" if [ "${CONTROL_PLANE_AVAILABILITY_POLICY}" = "HighlyAvailable" ]; then ETCD_PODS="etcd-0 etcd-1 etcd-2" fi HC_RESTORE_FILE=${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/hc-${HC_CLUSTER_NAME}-restore.yaml HC_BACKUP_FILE=${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/hc-${HC_CLUSTER_NAME}.yaml HC_NEW_FILE=${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/hc-${HC_CLUSTER_NAME}-new.yaml cat ${HC_BACKUP_FILE} > ${HC_NEW_FILE} cat > ${HC_RESTORE_FILE} <<EOF restoreSnapshotURL: EOF for POD in ${ETCD_PODS}; do # Create a pre-signed URL for the etcd snapshot ETCD_SNAPSHOT="s3://${BUCKET_NAME}/${HC_CLUSTER_NAME}-${POD}-snapshot.db" ETCD_SNAPSHOT_URL=$(AWS_DEFAULT_REGION=${MGMT2_REGION} aws s3 presign ${ETCD_SNAPSHOT}) # FIXME no CLI support for restoreSnapshotURL yet cat >> ${HC_RESTORE_FILE} <<EOF - "${ETCD_SNAPSHOT_URL}" EOF done cat ${HC_RESTORE_FILE} if ! grep ${HC_CLUSTER_NAME}-snapshot.db ${HC_NEW_FILE}; then sed -i '' -e "/type: PersistentVolume/r ${HC_RESTORE_FILE}" ${HC_NEW_FILE} sed -i '' -e '/pausedUntil:/d' ${HC_NEW_FILE} fi HC=$(oc get hc -n ${HC_CLUSTER_NS} ${HC_CLUSTER_NAME} -o name || true) if [[ ${HC} == "" ]];then echo "Deploying HC Cluster: ${HC_CLUSTER_NAME} in ${HC_CLUSTER_NS} namespace" oc apply -f ${HC_NEW_FILE} else echo "HC Cluster ${HC_CLUSTER_NAME} already exists, avoiding step" fiAWS 인스턴스를 재사용하기 위해 노드와 노드 풀을 복구하는 경우 다음 명령을 입력하여 노드 풀을 복원합니다.
$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/np-*
검증
노드가 완전히 복원되었는지 확인하려면 다음 기능을 사용하십시오.
timeout=40 count=0 NODE_STATUS=$(oc get nodes --kubeconfig=${HC_KUBECONFIG} | grep -v NotReady | grep -c "worker") || NODE_STATUS=0 while [ ${NODE_POOL_REPLICAS} != ${NODE_STATUS} ] do echo "Waiting for Nodes to be Ready in the destination MGMT Cluster: ${MGMT2_CLUSTER_NAME}" echo "Try: (${count}/${timeout})" sleep 30 if [[ $count -eq timeout ]];then echo "Timeout waiting for Nodes in the destination MGMT Cluster" exit 1 fi count=$((count+1)) NODE_STATUS=$(oc get nodes --kubeconfig=${HC_KUBECONFIG} | grep -v NotReady | grep -c "worker") || NODE_STATUS=0 done
다음 단계
클러스터를 종료하고 삭제합니다.
5.4.4.5. 소스 관리 클러스터에서 호스팅된 클러스터 삭제
호스팅된 클러스터를 백업하고 이를 대상 관리 클러스터에 복원한 후 소스 관리 클러스터에서 호스팅된 클러스터를 종료하고 삭제합니다.
사전 요구 사항
데이터를 백업하고 이를 소스 관리 클러스터로 복원했습니다.
대상 관리 클러스터의 kubeconfig 파일이 KUBECONFIG 변수에 설정되어 있거나 스크립트를 사용하는 경우 MGMT_KUBECONFIG 변수에 배치되어 있는지 확인합니다. 내보내기 KUBECONFIG=<Kubeconfig FilePath > 또는 스크립트를 사용하는 경우 내보내기 KUBECONFIG=${MGMT_KUBECONFIG} 를 사용합니다.
절차
다음 명령을 입력하여
배포및상태 저장 세트오브젝트를 확장합니다.# Just in case $ export KUBECONFIG=${MGMT_KUBECONFIG} # Scale down deployments $ oc scale deployment -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --replicas=0 --all $ oc scale statefulset.apps -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --replicas=0 --all $ sleep 15다음 명령을 입력하여
NodePool오브젝트를 삭제합니다.NODEPOOLS=$(oc get nodepools -n ${HC_CLUSTER_NS} -o=jsonpath='{.items[?(@.spec.clusterName=="'${HC_CLUSTER_NAME}'")].metadata.name}') if [[ ! -z "${NODEPOOLS}" ]];then oc patch -n "${HC_CLUSTER_NS}" nodepool ${NODEPOOLS} --type=json --patch='[ { "op":"remove", "path": "/metadata/finalizers" }]' oc delete np -n ${HC_CLUSTER_NS} ${NODEPOOLS} fi다음 명령을 입력하여
machine및machineset오브젝트를 삭제합니다.# Machines for m in $(oc get machines -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name); do oc patch -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} ${m} --type=json --patch='[ { "op":"remove", "path": "/metadata/finalizers" }]' || true oc delete -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} ${m} || true done $ oc delete machineset -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --all || true다음 명령을 입력하여 클러스터 오브젝트를 삭제합니다.
# Cluster $ C_NAME=$(oc get cluster -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name) $ oc patch -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} ${C_NAME} --type=json --patch='[ { "op":"remove", "path": "/metadata/finalizers" }]' $ oc delete cluster.cluster.x-k8s.io -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --all이러한 명령을 입력하여 AWS 머신(Kubernetes 오브젝트)을 삭제합니다. 실제 AWS 머신 삭제에 대해 우려하지 마십시오. 클라우드 인스턴스는 영향을 받지 않습니다.
# AWS Machines for m in $(oc get awsmachine.infrastructure.cluster.x-k8s.io -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name) do oc patch -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} ${m} --type=json --patch='[ { "op":"remove", "path": "/metadata/finalizers" }]' || true oc delete -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} ${m} || true done다음 명령을 입력하여
Hosted및 ControlPlane HC 네임스페이스 오브젝트를 삭제합니다.ControlPlane# Delete HCP and ControlPlane HC NS $ oc patch -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} hostedcontrolplane.hypershift.openshift.io ${HC_CLUSTER_NAME} --type=json --patch='[ { "op":"remove", "path": "/metadata/finalizers" }]' $ oc delete hostedcontrolplane.hypershift.openshift.io -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --all $ oc delete ns ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} || true다음 명령을 입력하여
HostedCluster및 HC 네임스페이스 오브젝트를 삭제합니다.# Delete HC and HC Namespace $ oc -n ${HC_CLUSTER_NS} patch hostedclusters ${HC_CLUSTER_NAME} -p '{"metadata":{"finalizers":null}}' --type merge || true $ oc delete hc -n ${HC_CLUSTER_NS} ${HC_CLUSTER_NAME} || true $ oc delete ns ${HC_CLUSTER_NS} || true
검증
모든 기능이 작동하는지 확인하려면 다음 명령을 입력합니다.
# Validations $ export KUBECONFIG=${MGMT2_KUBECONFIG} $ oc get hc -n ${HC_CLUSTER_NS} $ oc get np -n ${HC_CLUSTER_NS} $ oc get pod -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} $ oc get machines -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} # Inside the HostedCluster $ export KUBECONFIG=${HC_KUBECONFIG} $ oc get clusterversion $ oc get nodes
다음 단계
새 관리 클러스터에서 실행되는 새 OVN 컨트롤 플레인에 연결할 수 있도록 호스팅 클러스터에서 OVN Pod를 삭제합니다.
-
호스트 클러스터의 kubeconfig 경로를 사용하여
KUBECONFIG환경 변수를 로드합니다. 다음 명령을 입력합니다.
$ oc delete pod -n openshift-ovn-kubernetes --all
5.4.4.6. 호스팅된 클러스터를 백업하고 복원하는 스크립트 실행
호스팅된 클러스터를 백업하고 AWS의 동일한 리전 내에서 복원하는 프로세스를 신속하게 수행하려면 스크립트를 수정하고 실행할 수 있습니다.
절차
다음 스크립트의 변수를 정보로 교체합니다.
# Fill the Common variables to fit your environment, this is just a sample SSH_KEY_FILE=${HOME}/.ssh/id_rsa.pub BASE_PATH=${HOME}/hypershift BASE_DOMAIN="aws.sample.com" PULL_SECRET_FILE="${HOME}/pull_secret.json" AWS_CREDS="${HOME}/.aws/credentials" CONTROL_PLANE_AVAILABILITY_POLICY=SingleReplica HYPERSHIFT_PATH=${BASE_PATH}/src/hypershift HYPERSHIFT_CLI=${HYPERSHIFT_PATH}/bin/hypershift HYPERSHIFT_IMAGE=${HYPERSHIFT_IMAGE:-"quay.io/${USER}/hypershift:latest"} NODE_POOL_REPLICAS=${NODE_POOL_REPLICAS:-2} # MGMT Context MGMT_REGION=us-west-1 MGMT_CLUSTER_NAME="${USER}-dev" MGMT_CLUSTER_NS=${USER} MGMT_CLUSTER_DIR="${BASE_PATH}/hosted_clusters/${MGMT_CLUSTER_NS}-${MGMT_CLUSTER_NAME}" MGMT_KUBECONFIG="${MGMT_CLUSTER_DIR}/kubeconfig" # MGMT2 Context MGMT2_CLUSTER_NAME="${USER}-dest" MGMT2_CLUSTER_NS=${USER} MGMT2_CLUSTER_DIR="${BASE_PATH}/hosted_clusters/${MGMT2_CLUSTER_NS}-${MGMT2_CLUSTER_NAME}" MGMT2_KUBECONFIG="${MGMT2_CLUSTER_DIR}/kubeconfig" # Hosted Cluster Context HC_CLUSTER_NS=clusters HC_REGION=us-west-1 HC_CLUSTER_NAME="${USER}-hosted" HC_CLUSTER_DIR="${BASE_PATH}/hosted_clusters/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}" HC_KUBECONFIG="${HC_CLUSTER_DIR}/kubeconfig" BACKUP_DIR=${HC_CLUSTER_DIR}/backup BUCKET_NAME="${USER}-hosted-${MGMT_REGION}" # DNS AWS_ZONE_ID="Z026552815SS3YPH9H6MG" EXTERNAL_DNS_DOMAIN="guest.jpdv.aws.kerbeross.com"- 로컬 파일 시스템에 스크립트를 저장합니다.
다음 명령을 입력하여 스크립트를 실행합니다.
source <env_file>여기서:
env_file은 스크립트를 저장한 파일의 이름입니다.마이그레이션 스크립트는 다음 리포지토리에서 유지 관리됩니다. https://github.com/openshift/hypershift/blob/main/contrib/migration/migrate-hcp.sh.