17.3. Observability(可观察性)
17.3.1. OpenShift Container Platform 中的可观察性
OpenShift Container Platform 会生成大量数据,如性能指标和来自平台以及其上运行的工作负载的日志。作为管理员,您可以使用各种工具来收集和分析所有可用的数据。以下是配置可观察性堆栈的系统工程师、架构师和管理员的最佳实践概述。
除非另有说明,否则本文档中的材料指的是边缘和核心部署。
17.3.1.1. 了解监控堆栈
监控堆栈使用以下组件:
- Prometheus 会收集和分析 OpenShift Container Platform 组件和工作负载的指标(如果配置为这样做)。
- Alertmanager 是 Prometheus 的一个组件,负责处理警报的路由、分组和静默。
- Thanos 处理指标的长期存储。
图 17.2. OpenShift Container Platform 监控架构
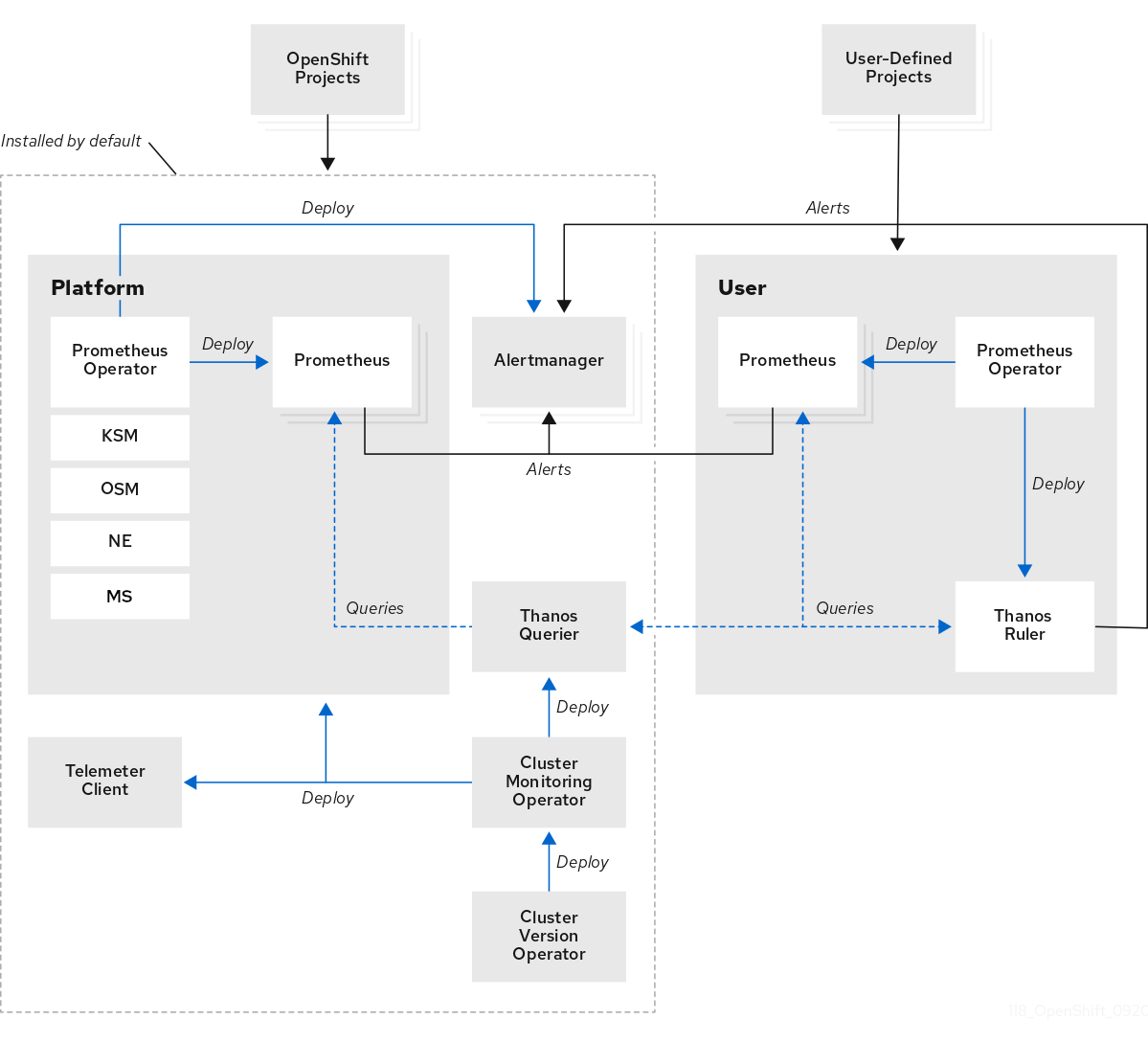
对于单节点 OpenShift 集群,您应该禁用 Alertmanager 和 Thanos,因为集群将所有指标发送到 hub 集群,以便分析和保留。
17.3.1.2. 主要性能指标
根据您的系统,可能会有数百个可用的测量。
以下是您应该注意的一些关键指标:
-
etcd响应时间 - API 响应时间
- Pod 重启和调度
- 资源使用量
- OVN 健康
- 集群 Operator 的整体健康状况
可以遵循的一个好规则是,如果您认为一个指标非常重要,则应该相应有一个警报。
您可以运行以下命令来检查可用的指标:
$ oc -n openshift-monitoring exec -c prometheus prometheus-k8s-0 -- curl -qsk http://localhost:9090/api/v1/metadata | jq '.data17.3.1.2.1. PromQL 中的查询示例
下表显示了您可以使用 OpenShift Container Platform 控制台在指标查询浏览器中探索的一些查询。
控制台的 URL 是 https://<OpenShift Console FQDN>/monitoring/query-browser。您可以运行以下命令来获取 OpenShift 控制台 FQDN:
$ oc get routes -n openshift-console console -o jsonpath='{.status.ingress[0].host}'| 指标 | 查询 |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 组合 |
|
| 指标 | 查询 |
|---|---|
|
|
|
|
|
|
| 领导选举 |
|
| 网络延迟 |
|
| 指标 | 查询 |
|---|---|
| 降级的 Operator |
|
| 每个集群的降级 Operator 总数 |
|
17.3.1.2.2. 指标存储的建议
开箱即用,Prometheus 不使用持久性存储备份保存的指标。如果重启 Prometheus pod,则所有指标数据都会丢失。您应该将监控堆栈配置为使用平台上提供的后端存储。为了满足 Prometheus 的高 IO 要求,您应该使用本地存储。
对于 Telco 核心集群,您可以使用 Local Storage Operator 作为 Prometheus 的持久性存储。
Red Hat OpenShift Data Foundation (ODF)为块、文件和对象存储部署 ceph 集群也是 Telco core 集群的合适候选者。
要在 RAN 单节点 OpenShift 或边缘集群中保持系统资源的要求较低,您不应该为监控堆栈置备后端存储。这些集群将所有指标转发到 hub 集群,您可以在其中置备第三方监控平台。
17.3.1.3. 监控边缘
边缘的单节点 OpenShift 将平台组件的空间保持最小。以下流程演示了如何配置带有小监控占用空间的单节点 OpenShift 节点。
先决条件
- 对于使用 Red Hat Advanced Cluster Management (RHACM)的环境,启用了 Observability 服务。
- hub 集群正在运行 Red Hat OpenShift Data Foundation (ODF)。
流程
创建
ConfigMapCR,并将它保存为monitoringConfigMap.yaml,如下例所示:apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | alertmanagerMain: enabled: false telemeterClient: enabled: false prometheusK8s: retention: 24h在单节点 OpenShift 中,运行以下命令来应用
ConfigMapCR:$ oc apply -f monitoringConfigMap.yaml创建
NameSpaceCR,并将它保存为monitoringNamespace.yaml,如下例所示:apiVersion: v1 kind: Namespace metadata: name: open-cluster-management-observability在 hub 集群中,运行以下命令在 hub 集群中应用
NamespaceCR:$ oc apply -f monitoringNamespace.yaml创建
ObjectBucketClaimCR,并将它保存为monitoringObjectBucketClaim.yaml,如下例所示:apiVersion: objectbucket.io/v1alpha1 kind: ObjectBucketClaim metadata: name: multi-cloud-observability namespace: open-cluster-management-observability spec: storageClassName: openshift-storage.noobaa.io generateBucketName: acm-multi在 hub 集群中,运行以下命令来应用
ObjectBucketClaimCR:$ oc apply -f monitoringObjectBucketClaim.yaml创建
SecretCR,并将它保存为monitoringSecret.yaml,如下例所示:apiVersion: v1 kind: Secret metadata: name: multiclusterhub-operator-pull-secret namespace: open-cluster-management-observability stringData: .dockerconfigjson: 'PULL_SECRET'在 hub 集群中,运行以下命令来应用
SecretCR:$ oc apply -f monitoringSecret.yaml运行以下命令,从 hub 集群获取 NooBaa 服务和后端存储桶名称的密钥:
$ NOOBAA_ACCESS_KEY=$(oc get secret noobaa-admin -n openshift-storage -o json | jq -r '.data.AWS_ACCESS_KEY_ID|@base64d')$ NOOBAA_SECRET_KEY=$(oc get secret noobaa-admin -n openshift-storage -o json | jq -r '.data.AWS_SECRET_ACCESS_KEY|@base64d')$ OBJECT_BUCKET=$(oc get objectbucketclaim -n open-cluster-management-observability multi-cloud-observability -o json | jq -r .spec.bucketName)为存储桶存储创建一个
SecretCR,并将它保存为monitoringBucketSecret.yaml,如下例所示:apiVersion: v1 kind: Secret metadata: name: thanos-object-storage namespace: open-cluster-management-observability type: Opaque stringData: thanos.yaml: | type: s3 config: bucket: ${OBJECT_BUCKET} endpoint: s3.openshift-storage.svc insecure: true access_key: ${NOOBAA_ACCESS_KEY} secret_key: ${NOOBAA_SECRET_KEY}在 hub 集群中,运行以下命令来应用
SecretCR:$ oc apply -f monitoringBucketSecret.yaml创建
MultiClusterObservabilityCR,并将它保存为monitoringMultiClusterObservability.yaml,如下例所示:apiVersion: observability.open-cluster-management.io/v1beta2 kind: MultiClusterObservability metadata: name: observability spec: advanced: retentionConfig: blockDuration: 2h deleteDelay: 48h retentionInLocal: 24h retentionResolutionRaw: 3d enableDownsampling: false observabilityAddonSpec: enableMetrics: true interval: 300 storageConfig: alertmanagerStorageSize: 10Gi compactStorageSize: 100Gi metricObjectStorage: key: thanos.yaml name: thanos-object-storage receiveStorageSize: 25Gi ruleStorageSize: 10Gi storeStorageSize: 25Gi在 hub 集群中,运行以下命令来应用
MultiClusterObservabilityCR:$ oc apply -f monitoringMultiClusterObservability.yaml
验证
运行以下命令,检查命名空间中的路由和 pod,以验证服务是否在 hub 集群中部署:
$ oc get routes,pods -n open-cluster-management-observability输出示例
NAME HOST/PORT PATH SERVICES PORT TERMINATION WILDCARD route.route.openshift.io/alertmanager alertmanager-open-cluster-management-observability.cloud.example.com /api/v2 alertmanager oauth-proxy reencrypt/Redirect None route.route.openshift.io/grafana grafana-open-cluster-management-observability.cloud.example.com grafana oauth-proxy reencrypt/Redirect None1 route.route.openshift.io/observatorium-api observatorium-api-open-cluster-management-observability.cloud.example.com observability-observatorium-api public passthrough/None None route.route.openshift.io/rbac-query-proxy rbac-query-proxy-open-cluster-management-observability.cloud.example.com rbac-query-proxy https reencrypt/Redirect None NAME READY STATUS RESTARTS AGE pod/observability-alertmanager-0 3/3 Running 0 1d pod/observability-alertmanager-1 3/3 Running 0 1d pod/observability-alertmanager-2 3/3 Running 0 1d pod/observability-grafana-685b47bb47-dq4cw 3/3 Running 0 1d <...snip…> pod/observability-thanos-store-shard-0-0 1/1 Running 0 1d pod/observability-thanos-store-shard-1-0 1/1 Running 0 1d pod/observability-thanos-store-shard-2-0 1/1 Running 0 1d- 1
- 在列出的 grafana 路由中可以访问仪表板。您可以使用它来查看所有受管集群的指标。
有关 Red Hat Advanced Cluster Management 中的可观察性的更多信息,请参阅 Observability。
17.3.1.4. 警报
OpenShift Container Platform 包含大量警报规则,在不同版本间可能会有所变化。
17.3.1.4.1. 查看默认警报
使用以下步骤查看集群中的所有警报规则。
流程
要查看集群中的所有警报规则,您可以运行以下命令:
$ oc get cm -n openshift-monitoring prometheus-k8s-rulefiles-0 -o yaml规则可以包含描述,并提供其他信息和缓解措施步骤的链接。例如,这是
etcdHighFsyncDurations的规则:- alert: etcdHighFsyncDurations annotations: description: 'etcd cluster "{{ $labels.job }}": 99th percentile fsync durations are {{ $value }}s on etcd instance {{ $labels.instance }}.' runbook_url: https://github.com/openshift/runbooks/blob/master/alerts/cluster-etcd-operator/etcdHighFsyncDurations.md summary: etcd cluster 99th percentile fsync durations are too high. expr: | histogram_quantile(0.99, rate(etcd_disk_wal_fsync_duration_seconds_bucket{job=~".*etcd.*"}[5m])) > 1 for: 10m labels: severity: critical
17.3.1.4.2. 警报通知
您可以在 OpenShift Container Platform 控制台中查看警报,但管理员应配置外部接收器来将警报转发到。OpenShift Container Platform 支持以下接收器类型:
- PagerDuty:第三方事件响应平台
- Webhook:一个 API 端点,它通过 POST 请求接收警报,并可采取任何必要的操作
- Email:发送电子邮件到指定地址
- Slack :向 slack 频道或单个用户发送通知
17.3.1.5. 工作负载监控
默认情况下,OpenShift Container Platform 不会收集应用程序工作负载的指标。您可以配置集群来收集工作负载指标。
先决条件
- 您已定义了端点来收集集群中的工作负载指标。
流程
创建
ConfigMapCR 并将其保存为monitoringConfigMap.yaml,如下例所示:apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | enableUserWorkload: true1 - 1
- 设置为
true以启用工作负载监控。
运行以下命令来应用
ConfigMapCR:$ oc apply -f monitoringConfigMap.yaml创建
ServiceMonitorCR,并将它保存为monitoringServiceMonitor.yaml,如下例所示:apiVersion: monitoring.coreos.com/v1 kind: ServiceMonitor metadata: labels: app: ui name: myapp namespace: myns spec: endpoints:1 - interval: 30s port: ui-http scheme: http path: /healthz2 selector: matchLabels: app: ui运行以下命令来应用
ServiceMonitorCR:$ oc apply -f monitoringServiceMonitor.yaml
Prometheus 默认提取路径 /metrics,但您可以定义自定义路径。取决于应用程序厂商来公开此端点以进行提取,以及它们相关的指标。
17.3.1.5.1. 创建工作负载警报
您可以为集群中的用户工作负载启用警报。
流程
创建
ConfigMapCR,并将它保存为monitoringConfigMap.yaml,如下例所示:apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | enableUserWorkload: true1 # ...- 1
- 设置为
true以启用工作负载监控。
运行以下命令来应用
ConfigMapCR:$ oc apply -f monitoringConfigMap.yaml为警报规则创建 YAML 文件
monitoringAlertRule.yaml,如下例所示:apiVersion: monitoring.coreos.com/v1 kind: PrometheusRule metadata: name: myapp-alert namespace: myns spec: groups: - name: example rules: - alert: InternalErrorsAlert expr: flask_http_request_total{status="500"} > 0 # ...运行以下命令来应用警报规则:
$ oc apply -f monitoringAlertRule.yaml