Chapter 5. Networking Operators
5.1. Kubernetes NMState Operator
The Kubernetes NMState Operator provides a Kubernetes API for performing state-driven network configuration across the OpenShift Container Platform cluster’s nodes with NMState. The Kubernetes NMState Operator provides users with functionality to configure various network interface types, DNS, and routing on cluster nodes. Additionally, the daemons on the cluster nodes periodically report on the state of each node’s network interfaces to the API server.
Red Hat supports the Kubernetes NMState Operator in production environments on bare-metal, IBM Power®, IBM Z®, IBM® LinuxONE, VMware vSphere, and OpenStack installations.
Before you can use NMState with OpenShift Container Platform, you must install the Kubernetes NMState Operator. After you install the Kubernetes NMState Operator, you can complete the following tasks:
- Observing and updating the node network state and configuration
-
Creating a manifest object that includes a customized
br-exbridge For more information on these tasks, see the Additional resources section
Before you can use NMState with OpenShift Container Platform, you must install the Kubernetes NMState Operator.
The Kubernetes NMState Operator updates the network configuration of a secondary NIC. The Operator cannot update the network configuration of the primary NIC, or update the br-ex bridge on most on-premise networks.
On a bare-metal platform, using the Kubernetes NMState Operator to update the br-ex bridge network configuration is only supported if you set the br-ex bridge as the interface in a machine config manifest file. To update the br-ex bridge as a postinstallation task, you must set the br-ex bridge as the interface in the NMState configuration of the NodeNetworkConfigurationPolicy custom resource (CR) for your cluster. For more information, see Creating a manifest object that includes a customized br-ex bridge in Postinstallation configuration.
OpenShift Container Platform uses nmstate to report on and configure the state of the node network. This makes it possible to modify the network policy configuration, such as by creating a Linux bridge on all nodes, by applying a single configuration manifest to the cluster.
Node networking is monitored and updated by the following objects:
NodeNetworkState- Reports the state of the network on that node.
NodeNetworkConfigurationPolicy-
Describes the requested network configuration on nodes. You update the node network configuration, including adding and removing interfaces, by applying a
NodeNetworkConfigurationPolicyCR to the cluster. NodeNetworkConfigurationEnactment- Reports the network policies enacted upon each node.
Do not make configuration changes to the br-ex bridge or its underlying interfaces as a postinstallation task.
5.1.1. Installing the Kubernetes NMState Operator
You can install the Kubernetes NMState Operator by using the web console or the CLI.
5.1.1.1. Installing the Kubernetes NMState Operator by using the web console
You can install the Kubernetes NMState Operator by using the web console. After you install the Kubernetes NMState Operator, the Operator has deployed the NMState State Controller as a daemon set across all of the cluster nodes.
Prerequisites
-
You are logged in as a user with
cluster-adminprivileges.
Procedure
-
Select Operators
OperatorHub. -
In the search field below All Items, enter
nmstateand click Enter to search for the Kubernetes NMState Operator. - Click on the Kubernetes NMState Operator search result.
- Click on Install to open the Install Operator window.
- Click Install to install the Operator.
- After the Operator finishes installing, click View Operator.
-
Under Provided APIs, click Create Instance to open the dialog box for creating an instance of
kubernetes-nmstate. In the Name field of the dialog box, ensure the name of the instance is
nmstate.NoteThe name restriction is a known issue. The instance is a singleton for the entire cluster.
- Accept the default settings and click Create to create the instance.
5.1.1.2. Installing the Kubernetes NMState Operator by using the CLI
You can install the Kubernetes NMState Operator by using the OpenShift CLI (oc). After it is installed, the Operator deploys the NMState State Controller as a daemon set across all of the cluster nodes to manage the node network state and configuration.
Prerequisites
-
You have installed the OpenShift CLI (
oc). -
You are logged in as a user with
cluster-adminprivileges.
Procedure
Create the
nmstateOperator namespace:$ cat << EOF | oc apply -f - apiVersion: v1 kind: Namespace metadata: name: openshift-nmstate spec: finalizers: - kubernetes EOFCreate the
OperatorGroup:$ cat << EOF | oc apply -f - apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: openshift-nmstate namespace: openshift-nmstate spec: targetNamespaces: - openshift-nmstate EOFSubscribe to the
nmstateOperator:$ cat << EOF| oc apply -f - apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: kubernetes-nmstate-operator namespace: openshift-nmstate spec: channel: stable installPlanApproval: Automatic name: kubernetes-nmstate-operator source: redhat-operators sourceNamespace: openshift-marketplace EOFConfirm the
ClusterServiceVersion(CSV) status for thenmstateOperator deployment equalsSucceeded:$ oc get clusterserviceversion -n openshift-nmstate \ -o custom-columns=Name:.metadata.name,Phase:.status.phaseCreate an instance of the
nmstateOperator:$ cat << EOF | oc apply -f - apiVersion: nmstate.io/v1 kind: NMState metadata: name: nmstate EOFIf your cluster has problems with the DNS health check probe because of DNS connectivity issues, you can add the following DNS host name configuration to the
NMStateCRD to build in health checks that can resolve these issues:apiVersion: nmstate.io/v1 kind: NMState metadata: name: nmstate spec: probeConfiguration: dns: host: redhat.com # ...Apply the DNS host name configuration to your cluster network by running the following command. Ensure that you replace
<filename>with the name of your CRD file.$ oc apply -f <filename>.yamlMonitor the
nmstateCRD until the resource reaches theAvailablecondition by running the following command. Ensure that you set a value for the--timeoutoption so that if theAvailablecondition is not met within this set maximum waiting time, the command times out and generates an error message.$ oc wait --for=condition=Available nmstate/nmstate --timeout=600s
Verification
Verify that all pods for the NMState Operator have the
Runningstatus by entering the following command:$ oc get pod -n openshift-nmstate
5.1.2. Uninstalling the Kubernetes NMState Operator
Remove the Kubernetes NMState Operator and related resources when they are no longer needed.
You can use the Operator Lifecycle Manager (OLM) to uninstall the Kubernetes NMState Operator, but by design OLM does not delete any associated custom resource definitions (CRDs), custom resources (CRs), or API Services.
Before you uninstall the Kubernetes NMState Operator from the Subcription resource used by OLM, identify what Kubernetes NMState Operator resources to delete. This identification ensures that you can delete resources without impacting your running cluster.
If you need to reinstall the Kubernetes NMState Operator, see "Installing the Kubernetes NMState Operator by using the CLI" or "Installing the Kubernetes NMState Operator by using the web console".
Prerequisites
-
You have installed the OpenShift CLI (
oc). -
You have installed the
jqCLI tool. -
You are logged in as a user with
cluster-adminprivileges.
Procedure
Unsubscribe the Kubernetes NMState Operator from the
Subcriptionresource by running the following command:$ oc delete --namespace openshift-nmstate subscription kubernetes-nmstate-operatorFind the
ClusterServiceVersion(CSV) resource that associates with the Kubernetes NMState Operator:$ oc get --namespace openshift-nmstate clusterserviceversionExample output that lists a CSV resource
NAME DISPLAY VERSION REPLACES PHASE kubernetes-nmstate-operator.v4.18.0 Kubernetes NMState Operator 4.18.0 SucceededDelete the CSV resource. After you delete the file, OLM deletes certain resources, such as
RBAC, that it created for the Operator.$ oc delete --namespace openshift-nmstate clusterserviceversion kubernetes-nmstate-operator.v4.18.0Delete the
nmstateCR and any associatedDeploymentresources by running the following commands:$ oc -n openshift-nmstate delete nmstate nmstate$ oc delete --all deployments --namespace=openshift-nmstateAfter you deleted the
nmstateCR, remove thenmstate-console-pluginconsole plugin name from theconsole.operator.openshift.io/clusterCR.Store the position of the
nmstate-console-pluginentry that exists among the list of enable plugins by running the following command. The following command uses thejqCLI tool to store the index of the entry in an environment variable namedINDEX:INDEX=$(oc get console.operator.openshift.io cluster -o json | jq -r '.spec.plugins | to_entries[] | select(.value == "nmstate-console-plugin") | .key')Remove the
nmstate-console-pluginentry from theconsole.operator.openshift.io/clusterCR by running the following patch command:$ oc patch console.operator.openshift.io cluster --type=json -p "[{\"op\": \"remove\", \"path\": \"/spec/plugins/$INDEX\"}]"-
INDEXis an auxiliary variable. You can specify a different name for this variable.
-
Optional: To preserve CR instances so that you can restore them after you delete CRDs, enter the following command:
$ oc get -A nncp -o yaml > cluster-nncp.yamlImportantTo reuse preserved CRs, such as NNCPs, you must uninstall the Kubernetes NMState Operator, reinstall the Kubernetes NMState Operator, and then run the following command to restore the CRs:
$ oc apply -f cluster-nncp.yamlDelete all the CRDs, such as
nmstates.nmstate.io, by running the following commands:$ oc delete crd nmstates.nmstate.io$ oc delete crd nodenetworkconfigurationenactments.nmstate.io$ oc delete crd nodenetworkstates.nmstate.io$ oc delete crd nodenetworkconfigurationpolicies.nmstate.ioDelete the namespace:
$ oc delete namespace kubernetes-nmstate
5.2. AWS Load Balancer Operator
5.2.1. AWS Load Balancer Operator release notes
The AWS Load Balancer (ALB) Operator deploys and manages an instance of the AWSLoadBalancerController resource.
The AWS Load Balancer (ALB) Operator is only supported on the x86_64 architecture.
These release notes track the development of the AWS Load Balancer Operator in OpenShift Container Platform.
For an overview of the AWS Load Balancer Operator, see AWS Load Balancer Operator in OpenShift Container Platform.
AWS Load Balancer Operator currently does not support AWS GovCloud.
5.2.1.1. AWS Load Balancer Operator 1.2.0
The following advisory is available for the AWS Load Balancer Operator version 1.2.0:
5.2.1.1.1. Notable changes
- This release supports the AWS Load Balancer Controller version 2.8.2.
-
With this release, the platform tags defined in the
Infrastructureresource will now be added to all AWS objects created by the controller.
5.2.1.2. AWS Load Balancer Operator 1.1.1
The following advisory is available for the AWS Load Balancer Operator version 1.1.1:
5.2.1.3. AWS Load Balancer Operator 1.1.0
The AWS Load Balancer Operator version 1.1.0 supports the AWS Load Balancer Controller version 2.4.4.
The following advisory is available for the AWS Load Balancer Operator version 1.1.0:
5.2.1.3.1. Notable changes
- This release uses the Kubernetes API version 0.27.2.
5.2.1.3.2. New features
- The AWS Load Balancer Operator now supports a standardized Security Token Service (STS) flow by using the Cloud Credential Operator.
5.2.1.3.3. Bug fixes
A FIPS-compliant cluster must use TLS version 1.2. Previously, webhooks for the AWS Load Balancer Controller only accepted TLS 1.3 as the minimum version, resulting in an error such as the following on a FIPS-compliant cluster:
remote error: tls: protocol version not supportedNow, the AWS Load Balancer Controller accepts TLS 1.2 as the minimum TLS version, resolving this issue. (OCPBUGS-14846)
5.2.1.4. AWS Load Balancer Operator 1.0.1
The following advisory is available for the AWS Load Balancer Operator version 1.0.1:
5.2.1.5. AWS Load Balancer Operator 1.0.0
The AWS Load Balancer Operator is now generally available with this release. The AWS Load Balancer Operator version 1.0.0 supports the AWS Load Balancer Controller version 2.4.4.
The following advisory is available for the AWS Load Balancer Operator version 1.0.0:
The AWS Load Balancer (ALB) Operator version 1.x.x cannot upgrade automatically from the Technology Preview version 0.x.x. To upgrade from an earlier version, you must uninstall the ALB operands and delete the aws-load-balancer-operator namespace.
5.2.1.5.1. Notable changes
-
This release uses the new
v1API version.
5.2.1.5.2. Bug fixes
- Previously, the controller provisioned by the AWS Load Balancer Operator did not properly use the configuration for the cluster-wide proxy. These settings are now applied appropriately to the controller. (OCPBUGS-4052, OCPBUGS-5295)
5.2.1.6. Earlier versions
The two earliest versions of the AWS Load Balancer Operator are available as a Technology Preview. These versions should not be used in a production cluster. For more information about the support scope of Red Hat Technology Preview features, see Technology Preview Features Support Scope.
The following advisory is available for the AWS Load Balancer Operator version 0.2.0:
The following advisory is available for the AWS Load Balancer Operator version 0.0.1:
5.2.2. AWS Load Balancer Operator in OpenShift Container Platform
The AWS Load Balancer Operator deploys and manages the AWS Load Balancer Controller. You can install the AWS Load Balancer Operator from OperatorHub by using OpenShift Container Platform web console or CLI.
5.2.2.1. AWS Load Balancer Operator considerations
Review the following limitations before installing and using the AWS Load Balancer Operator:
- The IP traffic mode only works on AWS Elastic Kubernetes Service (EKS). The AWS Load Balancer Operator disables the IP traffic mode for the AWS Load Balancer Controller. As a result of disabling the IP traffic mode, the AWS Load Balancer Controller cannot use the pod readiness gate.
-
The AWS Load Balancer Operator adds command-line flags such as
--disable-ingress-class-annotationand--disable-ingress-group-name-annotationto the AWS Load Balancer Controller. Therefore, the AWS Load Balancer Operator does not allow using thekubernetes.io/ingress.classandalb.ingress.kubernetes.io/group.nameannotations in theIngressresource. -
You have configured the AWS Load Balancer Operator so that the SVC type is
NodePort(notLoadBalancerorClusterIP).
5.2.2.2. AWS Load Balancer Operator
The AWS Load Balancer Operator can tag the public subnets if the kubernetes.io/role/elb tag is missing. Also, the AWS Load Balancer Operator detects the following information from the underlying AWS cloud:
- The ID of the virtual private cloud (VPC) on which the cluster hosting the Operator is deployed in.
- Public and private subnets of the discovered VPC.
The AWS Load Balancer Operator supports the Kubernetes service resource of type LoadBalancer by using Network Load Balancer (NLB) with the instance target type only.
Procedure
To deploy the AWS Load Balancer Operator on-demand from OperatorHub, create a
Subscriptionobject by running the following command:$ oc -n aws-load-balancer-operator get sub aws-load-balancer-operator --template='{{.status.installplan.name}}{{"\n"}}'Check if the status of an install plan is
Completeby running the following command:$ oc -n aws-load-balancer-operator get ip <install_plan_name> --template='{{.status.phase}}{{"\n"}}'View the status of the
aws-load-balancer-operator-controller-managerdeployment by running the following command:$ oc get -n aws-load-balancer-operator deployment/aws-load-balancer-operator-controller-managerExample output
NAME READY UP-TO-DATE AVAILABLE AGE aws-load-balancer-operator-controller-manager 1/1 1 1 23h
5.2.2.3. Using the AWS Load Balancer Operator in an AWS VPC cluster extended into an Outpost
You can configure the AWS Load Balancer Operator to provision an AWS Application Load Balancer in an AWS VPC cluster extended into an Outpost. AWS Outposts does not support AWS Network Load Balancers. As a result, the AWS Load Balancer Operator cannot provision Network Load Balancers in an Outpost.
You can create an AWS Application Load Balancer either in the cloud subnet or in the Outpost subnet. An Application Load Balancer in the cloud can attach to cloud-based compute nodes and an Application Load Balancer in the Outpost can attach to edge compute nodes. You must annotate Ingress resources with the Outpost subnet or the VPC subnet, but not both.
Prerequisites
- You have extended an AWS VPC cluster into an Outpost.
-
You have installed the OpenShift CLI (
oc). - You have installed the AWS Load Balancer Operator and created the AWS Load Balancer Controller.
Procedure
Configure the
Ingressresource to use a specified subnet:Example
Ingressresource configurationapiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: <application_name> annotations: alb.ingress.kubernetes.io/subnets: <subnet_id>1 spec: ingressClassName: alb rules: - http: paths: - path: / pathType: Exact backend: service: name: <application_name> port: number: 80- 1
- Specifies the subnet to use.
- To use the Application Load Balancer in an Outpost, specify the Outpost subnet ID.
- To use the Application Load Balancer in the cloud, you must specify at least two subnets in different availability zones.
5.2.3. Preparing an AWS STS cluster for the AWS Load Balancer Operator
You can install the Amazon Web Services (AWS) Load Balancer Operator on a cluster that uses the Security Token Service (STS). Follow these steps to prepare your cluster before installing the Operator.
The AWS Load Balancer Operator relies on the CredentialsRequest object to bootstrap the Operator and the AWS Load Balancer Controller. The AWS Load Balancer Operator waits until the required secrets are created and available.
5.2.3.1. Prerequisites
-
You installed the OpenShift CLI (
oc). You know the infrastructure ID of your cluster. To show this ID, run the following command in your CLI:
$ oc get infrastructure cluster -o=jsonpath="{.status.infrastructureName}"You know the OpenID Connect (OIDC) DNS information for your cluster. To show this information, enter the following command in your CLI:
$ oc get authentication.config cluster -o=jsonpath="{.spec.serviceAccountIssuer}"1 - 1
- An OIDC DNS example is
https://rh-oidc.s3.us-east-1.amazonaws.com/28292va7ad7mr9r4he1fb09b14t59t4f.
-
You logged into the AWS Web Console, navigated to IAM
Access management Identity providers, and located the OIDC Amazon Resource Name (ARN) information. An OIDC ARN example is arn:aws:iam::777777777777:oidc-provider/<oidc_dns_url>.
5.2.3.2. Creating an IAM role for the AWS Load Balancer Operator
An additional Amazon Web Services (AWS) Identity and Access Management (IAM) role is required to successfully install the AWS Load Balancer Operator on a cluster that uses STS. The IAM role is required to interact with subnets and Virtual Private Clouds (VPCs). The AWS Load Balancer Operator generates the CredentialsRequest object with the IAM role to bootstrap itself.
You can create the IAM role by using the following options:
-
Using the Cloud Credential Operator utility (
ccoctl) and a predefinedCredentialsRequestobject. - Using the AWS CLI and predefined AWS manifests.
Use the AWS CLI if your environment does not support the ccoctl command.
5.2.3.2.1. Creating an AWS IAM role by using the Cloud Credential Operator utility
You can use the Cloud Credential Operator utility (ccoctl) to create an AWS IAM role for the AWS Load Balancer Operator. An AWS IAM role interacts with subnets and Virtual Private Clouds (VPCs).
Prerequisites
-
You must extract and prepare the
ccoctlbinary.
Procedure
Download the
CredentialsRequestcustom resource (CR) and store it in a directory by running the following command:$ curl --create-dirs -o <credentials_requests_dir>/operator.yaml https://raw.githubusercontent.com/openshift/aws-load-balancer-operator/main/hack/operator-credentials-request.yamlUse the
ccoctlutility to create an AWS IAM role by running the following command:$ ccoctl aws create-iam-roles \ --name <name> \ --region=<aws_region> \ --credentials-requests-dir=<credentials_requests_dir> \ --identity-provider-arn <oidc_arn>Example output
2023/09/12 11:38:57 Role arn:aws:iam::777777777777:role/<name>-aws-load-balancer-operator-aws-load-balancer-operator created1 2023/09/12 11:38:57 Saved credentials configuration to: /home/user/<credentials_requests_dir>/manifests/aws-load-balancer-operator-aws-load-balancer-operator-credentials.yaml 2023/09/12 11:38:58 Updated Role policy for Role <name>-aws-load-balancer-operator-aws-load-balancer-operator created- 1
- Note the Amazon Resource Name (ARN) of an AWS IAM role that was created for the AWS Load Balancer Operator, such as
arn:aws:iam::777777777777:role/<name>-aws-load-balancer-operator-aws-load-balancer-operator.
NoteThe length of an AWS IAM role name must be less than or equal to 12 characters.
5.2.3.2.2. Creating an AWS IAM role by using the AWS CLI
You can use the AWS Command Line Interface to create an IAM role for the AWS Load Balancer Operator. The IAM role is used to interact with subnets and Virtual Private Clouds (VPCs).
Prerequisites
-
You must have access to the AWS Command Line Interface (
aws).
Procedure
Generate a trust policy file by using your identity provider by running the following command:
$ cat <<EOF > albo-operator-trust-policy.json { "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Federated": "<oidc_arn>"1 }, "Action": "sts:AssumeRoleWithWebIdentity", "Condition": { "StringEquals": { "<cluster_oidc_endpoint>:sub": "system:serviceaccount:aws-load-balancer-operator:aws-load-balancer-operator-controller-manager"2 } } } ] } EOF- 1
- Specifies the Amazon Resource Name (ARN) of the OIDC identity provider, such as
arn:aws:iam::777777777777:oidc-provider/rh-oidc.s3.us-east-1.amazonaws.com/28292va7ad7mr9r4he1fb09b14t59t4f. - 2
- Specifies the service account for the AWS Load Balancer Controller. An example of
<cluster_oidc_endpoint>isrh-oidc.s3.us-east-1.amazonaws.com/28292va7ad7mr9r4he1fb09b14t59t4f.
Create the IAM role with the generated trust policy by running the following command:
$ aws iam create-role --role-name albo-operator --assume-role-policy-document file://albo-operator-trust-policy.jsonExample output
ROLE arn:aws:iam::<aws_account_number>:role/albo-operator 2023-08-02T12:13:22Z1 ASSUMEROLEPOLICYDOCUMENT 2012-10-17 STATEMENT sts:AssumeRoleWithWebIdentity Allow STRINGEQUALS system:serviceaccount:aws-load-balancer-operator:aws-load-balancer-controller-manager PRINCIPAL arn:aws:iam:<aws_account_number>:oidc-provider/<cluster_oidc_endpoint>- 1
- Note the ARN of the created AWS IAM role that was created for the AWS Load Balancer Operator, such as
arn:aws:iam::777777777777:role/albo-operator.
Download the permission policy for the AWS Load Balancer Operator by running the following command:
$ curl -o albo-operator-permission-policy.json https://raw.githubusercontent.com/openshift/aws-load-balancer-operator/main/hack/operator-permission-policy.jsonAttach the permission policy for the AWS Load Balancer Controller to the IAM role by running the following command:
$ aws iam put-role-policy --role-name albo-operator --policy-name perms-policy-albo-operator --policy-document file://albo-operator-permission-policy.json
5.2.3.3. Configuring the ARN role for the AWS Load Balancer Operator
You can configure the Amazon Resource Name (ARN) role for the AWS Load Balancer Operator as an environment variable. You can configure the ARN role by using the CLI.
Prerequisites
-
You have installed the OpenShift CLI (
oc).
Procedure
Create the
aws-load-balancer-operatorproject by running the following command:$ oc new-project aws-load-balancer-operatorCreate the
OperatorGroupobject by running the following command:$ cat <<EOF | oc apply -f - apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: aws-load-balancer-operator namespace: aws-load-balancer-operator spec: targetNamespaces: [] EOFCreate the
Subscriptionobject by running the following command:$ cat <<EOF | oc apply -f - apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: aws-load-balancer-operator namespace: aws-load-balancer-operator spec: channel: stable-v1 name: aws-load-balancer-operator source: redhat-operators sourceNamespace: openshift-marketplace config: env: - name: ROLEARN value: "<albo_role_arn>"1 EOF- 1
- Specifies the ARN role to be used in the
CredentialsRequestto provision the AWS credentials for the AWS Load Balancer Operator. An example for<albo_role_arn>isarn:aws:iam::<aws_account_number>:role/albo-operator.
NoteThe AWS Load Balancer Operator waits until the secret is created before moving to the
Availablestatus.
5.2.3.4. Creating an IAM role for the AWS Load Balancer Controller
The CredentialsRequest object for the AWS Load Balancer Controller must be set with a manually provisioned IAM role.
You can create the IAM role by using the following options:
-
Using the Cloud Credential Operator utility (
ccoctl) and a predefinedCredentialsRequestobject. - Using the AWS CLI and predefined AWS manifests.
Use the AWS CLI if your environment does not support the ccoctl command.
5.2.3.4.1. Creating an AWS IAM role for the controller by using the Cloud Credential Operator utility
You can use the Cloud Credential Operator utility (ccoctl) to create an AWS IAM role for the AWS Load Balancer Controller. An AWS IAM role is used to interact with subnets and Virtual Private Clouds (VPCs).
Prerequisites
-
You must extract and prepare the
ccoctlbinary.
Procedure
Download the
CredentialsRequestcustom resource (CR) and store it in a directory by running the following command:$ curl --create-dirs -o <credentials_requests_dir>/controller.yaml https://raw.githubusercontent.com/openshift/aws-load-balancer-operator/main/hack/controller/controller-credentials-request.yamlUse the
ccoctlutility to create an AWS IAM role by running the following command:$ ccoctl aws create-iam-roles \ --name <name> \ --region=<aws_region> \ --credentials-requests-dir=<credentials_requests_dir> \ --identity-provider-arn <oidc_arn>Example output
2023/09/12 11:38:57 Role arn:aws:iam::777777777777:role/<name>-aws-load-balancer-operator-aws-load-balancer-controller created1 2023/09/12 11:38:57 Saved credentials configuration to: /home/user/<credentials_requests_dir>/manifests/aws-load-balancer-operator-aws-load-balancer-controller-credentials.yaml 2023/09/12 11:38:58 Updated Role policy for Role <name>-aws-load-balancer-operator-aws-load-balancer-controller created- 1
- Note the Amazon Resource Name (ARN) of an AWS IAM role that was created for the AWS Load Balancer Controller, such as
arn:aws:iam::777777777777:role/<name>-aws-load-balancer-operator-aws-load-balancer-controller.
NoteThe length of an AWS IAM role name must be less than or equal to 12 characters.
5.2.3.4.2. Creating an AWS IAM role for the controller by using the AWS CLI
You can use the AWS command-line interface to create an AWS IAM role for the AWS Load Balancer Controller. An AWS IAM role is used to interact with subnets and Virtual Private Clouds (VPCs).
Prerequisites
-
You must have access to the AWS command-line interface (
aws).
Procedure
Generate a trust policy file using your identity provider by running the following command:
$ cat <<EOF > albo-controller-trust-policy.json { "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Federated": "<oidc_arn>"1 }, "Action": "sts:AssumeRoleWithWebIdentity", "Condition": { "StringEquals": { "<cluster_oidc_endpoint>:sub": "system:serviceaccount:aws-load-balancer-operator:aws-load-balancer-operator-controller-manager"2 } } } ] } EOF- 1
- Specifies the Amazon Resource Name (ARN) of the OIDC identity provider, such as
arn:aws:iam::777777777777:oidc-provider/rh-oidc.s3.us-east-1.amazonaws.com/28292va7ad7mr9r4he1fb09b14t59t4f. - 2
- Specifies the service account for the AWS Load Balancer Controller. An example of
<cluster_oidc_endpoint>isrh-oidc.s3.us-east-1.amazonaws.com/28292va7ad7mr9r4he1fb09b14t59t4f.
Create an AWS IAM role with the generated trust policy by running the following command:
$ aws iam create-role --role-name albo-controller --assume-role-policy-document file://albo-controller-trust-policy.jsonExample output
ROLE arn:aws:iam::<aws_account_number>:role/albo-controller 2023-08-02T12:13:22Z1 ASSUMEROLEPOLICYDOCUMENT 2012-10-17 STATEMENT sts:AssumeRoleWithWebIdentity Allow STRINGEQUALS system:serviceaccount:aws-load-balancer-operator:aws-load-balancer-operator-controller-manager PRINCIPAL arn:aws:iam:<aws_account_number>:oidc-provider/<cluster_oidc_endpoint>- 1
- Note the ARN of an AWS IAM role for the AWS Load Balancer Controller, such as
arn:aws:iam::777777777777:role/albo-controller.
Download the permission policy for the AWS Load Balancer Controller by running the following command:
$ curl -o albo-controller-permission-policy.json https://raw.githubusercontent.com/openshift/aws-load-balancer-operator/main/assets/iam-policy.jsonAttach the permission policy for the AWS Load Balancer Controller to an AWS IAM role by running the following command:
$ aws iam put-role-policy --role-name albo-controller --policy-name perms-policy-albo-controller --policy-document file://albo-controller-permission-policy.jsonCreate a YAML file that defines the
AWSLoadBalancerControllerobject:Example
sample-aws-lb-manual-creds.yamlfileapiVersion: networking.olm.openshift.io/v1 kind: AWSLoadBalancerController1 metadata: name: cluster2 spec: credentialsRequestConfig: stsIAMRoleARN: <albc_role_arn>3 - 1
- Defines the
AWSLoadBalancerControllerobject. - 2
- Defines the AWS Load Balancer Controller name. All related resources use this instance name as a suffix.
- 3
- Specifies the ARN role for the AWS Load Balancer Controller. The
CredentialsRequestobject uses this ARN role to provision the AWS credentials. An example of<albc_role_arn>isarn:aws:iam::777777777777:role/albo-controller.
5.2.4. Installing the AWS Load Balancer Operator
The AWS Load Balancer Operator deploys and manages the AWS Load Balancer Controller. You can install the AWS Load Balancer Operator from the OperatorHub by using OpenShift Container Platform web console or CLI.
5.2.4.1. Installing the AWS Load Balancer Operator by using the web console
You can install the AWS Load Balancer Operator by using the web console.
Prerequisites
-
You have logged in to the OpenShift Container Platform web console as a user with
cluster-adminpermissions. - Your cluster is configured with AWS as the platform type and cloud provider.
- If you are using a security token service (STS) or user-provisioned infrastructure, follow the related preparation steps. For example, if you are using AWS Security Token Service, see "Preparing for the AWS Load Balancer Operator on a cluster using the AWS Security Token Service (STS)".
Procedure
-
Navigate to Operators
OperatorHub in the OpenShift Container Platform web console. - Select the AWS Load Balancer Operator. You can use the Filter by keyword text box or use the filter list to search for the AWS Load Balancer Operator from the list of Operators.
-
Select the
aws-load-balancer-operatornamespace. On the Install Operator page, select the following options:
- Update the channel as stable-v1.
- Installation mode as All namespaces on the cluster (default).
-
Installed Namespace as
aws-load-balancer-operator. If theaws-load-balancer-operatornamespace does not exist, it gets created during the Operator installation. - Select Update approval as Automatic or Manual. By default, the Update approval is set to Automatic. If you select automatic updates, the Operator Lifecycle Manager (OLM) automatically upgrades the running instance of your Operator without any intervention. If you select manual updates, the OLM creates an update request. As a cluster administrator, you must then manually approve that update request to update the Operator updated to the new version.
- Click Install.
Verification
- Verify that the AWS Load Balancer Operator shows the Status as Succeeded on the Installed Operators dashboard.
5.2.4.2. Installing the AWS Load Balancer Operator by using the CLI
You can install the AWS Load Balancer Operator by using the CLI.
Prerequisites
-
You are logged in to the OpenShift Container Platform web console as a user with
cluster-adminpermissions. - Your cluster is configured with AWS as the platform type and cloud provider.
-
You are logged into the OpenShift CLI (
oc).
Procedure
Create a
Namespaceobject:Create a YAML file that defines the
Namespaceobject:Example
namespace.yamlfileapiVersion: v1 kind: Namespace metadata: name: aws-load-balancer-operatorCreate the
Namespaceobject by running the following command:$ oc apply -f namespace.yaml
Create an
OperatorGroupobject:Create a YAML file that defines the
OperatorGroupobject:Example
operatorgroup.yamlfileapiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: aws-lb-operatorgroup namespace: aws-load-balancer-operator spec: upgradeStrategy: DefaultCreate the
OperatorGroupobject by running the following command:$ oc apply -f operatorgroup.yaml
Create a
Subscriptionobject:Create a YAML file that defines the
Subscriptionobject:Example
subscription.yamlfileapiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: aws-load-balancer-operator namespace: aws-load-balancer-operator spec: channel: stable-v1 installPlanApproval: Automatic name: aws-load-balancer-operator source: redhat-operators sourceNamespace: openshift-marketplaceCreate the
Subscriptionobject by running the following command:$ oc apply -f subscription.yaml
Verification
Get the name of the install plan from the subscription:
$ oc -n aws-load-balancer-operator \ get subscription aws-load-balancer-operator \ --template='{{.status.installplan.name}}{{"\n"}}'Check the status of the install plan:
$ oc -n aws-load-balancer-operator \ get ip <install_plan_name> \ --template='{{.status.phase}}{{"\n"}}'The output must be
Complete.
5.2.4.3. Creating the AWS Load Balancer Controller
You can install only a single instance of the AWSLoadBalancerController object in a cluster. You can create the AWS Load Balancer Controller by using CLI. The AWS Load Balancer Operator reconciles only the cluster named resource.
Prerequisites
-
You have created the
echoservernamespace. -
You have access to the OpenShift CLI (
oc).
Procedure
Create a YAML file that defines the
AWSLoadBalancerControllerobject:Example
sample-aws-lb.yamlfileapiVersion: networking.olm.openshift.io/v1 kind: AWSLoadBalancerController1 metadata: name: cluster2 spec: subnetTagging: Auto3 additionalResourceTags:4 - key: example.org/security-scope value: staging ingressClass: alb5 config: replicas: 26 enabledAddons:7 - AWSWAFv28 - 1
- Defines the
AWSLoadBalancerControllerobject. - 2
- Defines the AWS Load Balancer Controller name. This instance name gets added as a suffix to all related resources.
- 3
- Configures the subnet tagging method for the AWS Load Balancer Controller. The following values are valid:
-
Auto: The AWS Load Balancer Operator determines the subnets that belong to the cluster and tags them appropriately. The Operator cannot determine the role correctly if the internal subnet tags are not present on internal subnet. -
Manual: You manually tag the subnets that belong to the cluster with the appropriate role tags. Use this option if you installed your cluster on user-provided infrastructure.
-
- 4
- Defines the tags used by the AWS Load Balancer Controller when it provisions AWS resources.
- 5
- Defines the ingress class name. The default value is
alb. - 6
- Specifies the number of replicas of the AWS Load Balancer Controller.
- 7
- Specifies annotations as an add-on for the AWS Load Balancer Controller.
- 8
- Enables the
alb.ingress.kubernetes.io/wafv2-acl-arnannotation.
Create the
AWSLoadBalancerControllerobject by running the following command:$ oc create -f sample-aws-lb.yamlCreate a YAML file that defines the
Deploymentresource:Example
sample-aws-lb.yamlfileapiVersion: apps/v1 kind: Deployment1 metadata: name: <echoserver>2 namespace: echoserver spec: selector: matchLabels: app: echoserver replicas: 33 template: metadata: labels: app: echoserver spec: containers: - image: openshift/origin-node command: - "/bin/socat" args: - TCP4-LISTEN:8080,reuseaddr,fork - EXEC:'/bin/bash -c \"printf \\\"HTTP/1.0 200 OK\r\n\r\n\\\"; sed -e \\\"/^\r/q\\\"\"' imagePullPolicy: Always name: echoserver ports: - containerPort: 8080Create a YAML file that defines the
Serviceresource:Example
service-albo.yamlfileapiVersion: v1 kind: Service1 metadata: name: <echoserver>2 namespace: echoserver spec: ports: - port: 80 targetPort: 8080 protocol: TCP type: NodePort selector: app: echoserverCreate a YAML file that defines the
Ingressresource:Example
ingress-albo.yamlfileapiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: <name>1 namespace: echoserver annotations: alb.ingress.kubernetes.io/scheme: internet-facing alb.ingress.kubernetes.io/target-type: instance spec: ingressClassName: alb rules: - http: paths: - path: / pathType: Exact backend: service: name: <echoserver>2 port: number: 80
Verification
Save the status of the
Ingressresource in theHOSTvariable by running the following command:$ HOST=$(oc get ingress -n echoserver echoserver --template='{{(index .status.loadBalancer.ingress 0).hostname}}')Verify the status of the
Ingressresource by running the following command:$ curl $HOST
5.2.5. Configuring the AWS Load Balancer Operator
5.2.5.1. Trusting the certificate authority of the cluster-wide proxy
You can configure the cluster-wide proxy in the AWS Load Balancer Operator. After configuring the cluster-wide proxy, Operator Lifecycle Manager (OLM) automatically updates all the deployments of the Operators with the environment variables such as HTTP_PROXY, HTTPS_PROXY, and NO_PROXY. These variables are populated to the managed controller by the AWS Load Balancer Operator.
Create the config map to contain the certificate authority (CA) bundle in the
aws-load-balancer-operatornamespace by running the following command:$ oc -n aws-load-balancer-operator create configmap trusted-caTo inject the trusted CA bundle into the config map, add the
config.openshift.io/inject-trusted-cabundle=truelabel to the config map by running the following command:$ oc -n aws-load-balancer-operator label cm trusted-ca config.openshift.io/inject-trusted-cabundle=trueUpdate the AWS Load Balancer Operator subscription to access the config map in the AWS Load Balancer Operator deployment by running the following command:
$ oc -n aws-load-balancer-operator patch subscription aws-load-balancer-operator --type='merge' -p '{"spec":{"config":{"env":[{"name":"TRUSTED_CA_CONFIGMAP_NAME","value":"trusted-ca"}],"volumes":[{"name":"trusted-ca","configMap":{"name":"trusted-ca"}}],"volumeMounts":[{"name":"trusted-ca","mountPath":"/etc/pki/tls/certs/albo-tls-ca-bundle.crt","subPath":"ca-bundle.crt"}]}}}'After the AWS Load Balancer Operator is deployed, verify that the CA bundle is added to the
aws-load-balancer-operator-controller-managerdeployment by running the following command:$ oc -n aws-load-balancer-operator exec deploy/aws-load-balancer-operator-controller-manager -c manager -- bash -c "ls -l /etc/pki/tls/certs/albo-tls-ca-bundle.crt; printenv TRUSTED_CA_CONFIGMAP_NAME"Example output
-rw-r--r--. 1 root 1000690000 5875 Jan 11 12:25 /etc/pki/tls/certs/albo-tls-ca-bundle.crt trusted-caOptional: Restart deployment of the AWS Load Balancer Operator every time the config map changes by running the following command:
$ oc -n aws-load-balancer-operator rollout restart deployment/aws-load-balancer-operator-controller-manager
5.2.5.2. Adding TLS termination on the AWS Load Balancer
You can route the traffic for the domain to pods of a service and add TLS termination on the AWS Load Balancer.
Prerequisites
-
You have an access to the OpenShift CLI (
oc).
Procedure
Create a YAML file that defines the
AWSLoadBalancerControllerresource:Example
add-tls-termination-albc.yamlfileapiVersion: networking.olm.openshift.io/v1 kind: AWSLoadBalancerController metadata: name: cluster spec: subnetTagging: Auto ingressClass: tls-termination1 - 1
- Defines the ingress class name. If the ingress class is not present in your cluster the AWS Load Balancer Controller creates one. The AWS Load Balancer Controller reconciles the additional ingress class values if
spec.controlleris set toingress.k8s.aws/alb.
Create a YAML file that defines the
Ingressresource:Example
add-tls-termination-ingress.yamlfileapiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: <example>1 annotations: alb.ingress.kubernetes.io/scheme: internet-facing2 alb.ingress.kubernetes.io/certificate-arn: arn:aws:acm:us-west-2:xxxxx3 spec: ingressClassName: tls-termination4 rules: - host: example.com5 http: paths: - path: / pathType: Exact backend: service: name: <example_service>6 port: number: 80- 1
- Specifies the ingress name.
- 2
- The controller provisions the load balancer for ingress in a public subnet to access the load balancer over the internet.
- 3
- The Amazon Resource Name (ARN) of the certificate that you attach to the load balancer.
- 4
- Defines the ingress class name.
- 5
- Defines the domain for traffic routing.
- 6
- Defines the service for traffic routing.
5.2.5.3. Creating multiple ingress resources through a single AWS Load Balancer
You can route the traffic to different services with multiple ingress resources that are part of a single domain through a single AWS Load Balancer. Each ingress resource provides different endpoints of the domain.
Prerequisites
-
You have an access to the OpenShift CLI (
oc).
Procedure
Create an
IngressClassParamsresource YAML file, for example,sample-single-lb-params.yaml, as follows:apiVersion: elbv2.k8s.aws/v1beta11 kind: IngressClassParams metadata: name: single-lb-params2 spec: group: name: single-lb3 Create the
IngressClassParamsresource by running the following command:$ oc create -f sample-single-lb-params.yamlCreate the
IngressClassresource YAML file, for example,sample-single-lb-class.yaml, as follows:apiVersion: networking.k8s.io/v11 kind: IngressClass metadata: name: single-lb2 spec: controller: ingress.k8s.aws/alb3 parameters: apiGroup: elbv2.k8s.aws4 kind: IngressClassParams5 name: single-lb-params6 - 1
- Defines the API group and version of the
IngressClassresource. - 2
- Specifies the ingress class name.
- 3
- Defines the controller name. The
ingress.k8s.aws/albvalue denotes that all ingress resources of this class should be managed by the AWS Load Balancer Controller. - 4
- Defines the API group of the
IngressClassParamsresource. - 5
- Defines the resource type of the
IngressClassParamsresource. - 6
- Defines the
IngressClassParamsresource name.
Create the
IngressClassresource by running the following command:$ oc create -f sample-single-lb-class.yamlCreate the
AWSLoadBalancerControllerresource YAML file, for example,sample-single-lb.yaml, as follows:apiVersion: networking.olm.openshift.io/v1 kind: AWSLoadBalancerController metadata: name: cluster spec: subnetTagging: Auto ingressClass: single-lb1 - 1
- Defines the name of the
IngressClassresource.
Create the
AWSLoadBalancerControllerresource by running the following command:$ oc create -f sample-single-lb.yamlCreate the
Ingressresource YAML file, for example,sample-multiple-ingress.yaml, as follows:apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: example-11 annotations: alb.ingress.kubernetes.io/scheme: internet-facing2 alb.ingress.kubernetes.io/group.order: "1"3 alb.ingress.kubernetes.io/target-type: instance4 spec: ingressClassName: single-lb5 rules: - host: example.com6 http: paths: - path: /blog7 pathType: Prefix backend: service: name: example-18 port: number: 809 --- apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: example-2 annotations: alb.ingress.kubernetes.io/scheme: internet-facing alb.ingress.kubernetes.io/group.order: "2" alb.ingress.kubernetes.io/target-type: instance spec: ingressClassName: single-lb rules: - host: example.com http: paths: - path: /store pathType: Prefix backend: service: name: example-2 port: number: 80 --- apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: example-3 annotations: alb.ingress.kubernetes.io/scheme: internet-facing alb.ingress.kubernetes.io/group.order: "3" alb.ingress.kubernetes.io/target-type: instance spec: ingressClassName: single-lb rules: - host: example.com http: paths: - path: / pathType: Prefix backend: service: name: example-3 port: number: 80- 1
- Specifies the ingress name.
- 2
- Indicates the load balancer to provision in the public subnet to access the internet.
- 3
- Specifies the order in which the rules from the multiple ingress resources are matched when the request is received at the load balancer.
- 4
- Indicates that the load balancer will target OpenShift Container Platform nodes to reach the service.
- 5
- Specifies the ingress class that belongs to this ingress.
- 6
- Defines a domain name used for request routing.
- 7
- Defines the path that must route to the service.
- 8
- Defines the service name that serves the endpoint configured in the
Ingressresource. - 9
- Defines the port on the service that serves the endpoint.
Create the
Ingressresource by running the following command:$ oc create -f sample-multiple-ingress.yaml
5.2.5.4. AWS Load Balancer Operator logs
You can view the AWS Load Balancer Operator logs by using the oc logs command.
Procedure
View the logs of the AWS Load Balancer Operator by running the following command:
$ oc logs -n aws-load-balancer-operator deployment/aws-load-balancer-operator-controller-manager -c manager
5.3. External DNS Operator
5.3.1. External DNS Operator release notes
The External DNS Operator deploys and manages ExternalDNS to provide name resolution for services and routes. This enables your external DNS provider to resolve hostnames directly to OpenShift Container Platform resources.
The External DNS Operator is only supported on the x86_64 architecture.
These release notes track the development of the External DNS Operator in OpenShift Container Platform.
5.3.1.1. External DNS Operator 1.2
The External DNS Operator 1.2 release notes summarize all new features and enhancements, notable technical changes, major corrections from previous versions, and any known bugs upon general availability.
- External DNS Operator 1.2.0
The following advisory is available for the External DNS Operator version 1.2.0:
RHEA-2022:5867 ExternalDNS Operator 1.2 Operator or operand containers
New features:
The External DNS Operator now supports AWS shared VPC. For more information, "Creating DNS records in a different AWS Account using a shared VPC".
Bug fixes
-
The update strategy for the operand changed from
RollingtoRecreate. (OCPBUGS-3630)
5.3.1.2. External DNS Operator 1.1
The External DNS Operator 1.1 release notes summarize all new features and enhancements, notable technical changes, major corrections from previous versions, and any known bugs upon general availability.
- External DNS Operator 1.1.1
The following advisory is available for the External DNS Operator version 1.1.1:
- External DNS Operator 1.1.0
This release included a rebase of the operand from the upstream project version 0.13.1. The following advisory is available for the External DNS Operator version 1.1.0:
RHEA-2022:9086-01 ExternalDNS Operator 1.1 Operator or operand containers
Bug fixes:
-
Previously, the ExternalDNS Operator enforced an empty
defaultModevalue for volumes, which caused constant updates due to a conflict with the OpenShift API. Now, thedefaultModevalue is not enforced and operand deployment does not update constantly. (OCPBUGS-2793)
5.3.1.3. External DNS Operator 1.0
The External DNS Operator 1.0 release notes summarize all new features and enhancements, notable technical changes, major corrections from previous versions, and any known bugs upon general availability.
- External DNS Operator 1.0.1
The following advisory is available for the External DNS Operator version 1.0.1:
- External DNS Operator 1.0.0
The following advisory is available for the External DNS Operator version 1.0.0:
RHEA-2022:5867 ExternalDNS Operator 1.0 Operator or operand containers
Bug fixes:
- Previously, the External DNS Operator issued a warning about the violation of the restricted SCC policy during ExternalDNS operand pod deployments. This issue has been resolved. (BZ#2086408)
5.3.2. Understanding the External DNS Operator
To provide name resolution for services and routes from an External DNS provider to OpenShift Container Platform, use the External DNS Operator. This Operator deploys and manages ExternalDNS to synchronize your cluster resources with the external provider.
5.3.2.1. External DNS Operator domain name limitations
To prevent configuration errors when deploying the ExternalDNS resource, review the domain name limitations enforced by the External DNS Operator. Understanding these constraints ensures that your requested hostnames and domains are compatible with your underlying DNS provider.
The External DNS Operator uses the TXT registry that adds the prefix for TXT records. This reduces the maximum length of the domain name for TXT records. A DNS record cannot be present without a corresponding TXT record, so the domain name of the DNS record must follow the same limit as the TXT records. For example, a DNS record of <domain_name_from_source> results in a TXT record of external-dns-<record_type>-<domain_name_from_source>.
The domain name of the DNS records generated by the External DNS Operator has the following limitations:
| Record type | Number of characters |
|---|---|
| CNAME | 44 |
| Wildcard CNAME records on AzureDNS | 42 |
| A | 48 |
| Wildcard A records on AzureDNS | 46 |
The following error shows in the External DNS Operator logs if the generated domain name exceeds any of the domain name limitations:
time="2022-09-02T08:53:57Z" level=error msg="Failure in zone test.example.io. [Id: /hostedzone/Z06988883Q0H0RL6UMXXX]"
time="2022-09-02T08:53:57Z" level=error msg="InvalidChangeBatch: [FATAL problem: DomainLabelTooLong (Domain label is too long) encountered with 'external-dns-a-hello-openshift-aaaaaaaaaa-bbbbbbbbbb-ccccccc']\n\tstatus code: 400, request id: e54dfd5a-06c6-47b0-bcb9-a4f7c3a4e0c6"5.3.2.2. Deploying the External DNS Operator
You can deploy the External DNS Operator on-demand from the Software Catalog. Deploying the External DNS Operator creates a Subscription object.
The External DNS Operator implements the External DNS API from the olm.openshift.io API group. The External DNS Operator updates services, routes, and external DNS providers.
Prerequisites
-
You have installed the
yqCLI tool.
Procedure
Check the name of an install plan, such as
install-zcvlr, by running the following command:$ oc -n external-dns-operator get sub external-dns-operator -o yaml | yq '.status.installplan.name'Check if the status of an install plan is
Completeby running the following command:$ oc -n external-dns-operator get ip <install_plan_name> -o yaml | yq '.status.phase'View the status of the
external-dns-operatordeployment by running the following command:$ oc get -n external-dns-operator deployment/external-dns-operatorExample output
NAME READY UP-TO-DATE AVAILABLE AGE external-dns-operator 1/1 1 1 23h
5.3.2.3. Viewing External DNS Operator logs
To troubleshoot DNS configuration issues, view the External DNS Operator logs. Use the oc logs command to retrieve diagnostic information directly from the Operator pod.
Procedure
View the logs of the External DNS Operator by running the following command:
$ oc logs -n external-dns-operator deployment/external-dns-operator -c external-dns-operator
5.3.3. Installing the External DNS Operator
To manage DNS records on your cloud infrastructure, install the External DNS Operator. This Operator supports deployment on major cloud providers, including Amazon Web Services (AWS), Microsoft Azure, and Google Cloud.
5.3.3.1. Installing the External DNS Operator with OperatorHub
You can install the External DNS Operator by using the OpenShift Container Platform OperatorHub. You can then manage the Operator lifecycle directly from the web console.
Procedure
-
Click Operators
OperatorHub in the OpenShift Container Platform web console. - Click External DNS Operator. You can use the Filter by keyword text box or the filter list to search for External DNS Operator from the list of Operators.
-
Select the
external-dns-operatornamespace. - On the External DNS Operator page, click Install.
On the Install Operator page, ensure that you selected the following options:
- Update the channel as stable-v1.
- Installation mode as A specific name on the cluster.
-
Installed namespace as
external-dns-operator. If namespaceexternal-dns-operatordoes not exist, the Operator gets created during the Operator installation. - Select Approval Strategy as Automatic or Manual. The Approval Strategy defaults to Automatic.
Click Install.
If you select Automatic updates, the Operator Lifecycle Manager (OLM) automatically upgrades the running instance of your Operator without any intervention.
If you select Manual updates, the OLM creates an update request. As a cluster administrator, you must then manually approve that update request to have the Operator updated to the new version.
Verification
- Verify that the External DNS Operator shows the Status as Succeeded on the Installed Operators dashboard.
5.3.3.2. Installing the External DNS Operator by using the CLI
You can use the OpenShift CLI (oc) to install the External DNS Operator. The Operator manages the installation process directly from your terminal without you having to use the web console.
Prerequisites
-
You are logged in to the OpenShift CLI (
oc).
Procedure
Create a
Namespaceobject:Create a YAML file that defines the
Namespaceobject:Example
namespace.yamlfileapiVersion: v1 kind: Namespace metadata: name: external-dns-operator # ...Create the
Namespaceobject by running the following command:$ oc apply -f namespace.yaml
Create an
OperatorGroupobject:Create a YAML file that defines the
OperatorGroupobject:Example
operatorgroup.yamlfileapiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: external-dns-operator namespace: external-dns-operator spec: upgradeStrategy: Default targetNamespaces: - external-dns-operator # ...Create the
OperatorGroupobject by running the following command:$ oc apply -f operatorgroup.yaml
Create a
Subscriptionobject:Create a YAML file that defines the
Subscriptionobject:Example
subscription.yamlfileapiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: external-dns-operator namespace: external-dns-operator spec: channel: stable-v1 installPlanApproval: Automatic name: external-dns-operator source: redhat-operators sourceNamespace: openshift-marketplace # ...Create the
Subscriptionobject by running the following command:$ oc apply -f subscription.yaml
Verification
Get the name of the install plan from the subscription by running the following command:
$ oc -n external-dns-operator \ get subscription external-dns-operator \ --template='{{.status.installplan.name}}{{"\n"}}'Verify that the status of the install plan is
Completeby running the following command:$ oc -n external-dns-operator \ get ip <install_plan_name> \ --template='{{.status.phase}}{{"\n"}}'Verify that the status of the
external-dns-operatorpod isRunningby running the following command:$ oc -n external-dns-operator get podExample output
NAME READY STATUS RESTARTS AGE external-dns-operator-5584585fd7-5lwqm 2/2 Running 0 11mVerify that the catalog source of the subscription is
redhat-operatorsby running the following command:$ oc -n external-dns-operator get subscriptionCheck the
external-dns-operatorversion by running the following command:$ oc -n external-dns-operator get csv
5.3.4. External DNS Operator configuration parameters
To customize the behavior of the External DNS Operator, configure the available parameters in the ExternalDNS custom resource (CR). By configuraing parameters, you can control how the Operator synchronizes services and routes with your external DNS provider.
5.3.4.1. External DNS Operator configuration parameters
To customize the behavior of the External DNS Operator, configure the available parameters in the ExternalDNS custom resource (CR). By configuring parameters, you can control how the Operator synchronizes services and routes with your external DNS provider.
| Parameter | Description |
|---|---|
|
| Enables the type of a cloud provider.
|
|
|
Enables you to specify DNS zones by their domains. If you do not specify zones, the
|
|
|
Enables you to specify AWS zones by their domains. If you do not specify domains, the
|
|
|
Enables you to specify the source for the DNS records,
|
5.3.5. Creating DNS records on AWS
To create DNS records on AWS and AWS GovCloud, use the External DNS Operator. The Operator manages external name resolution for your cluster services directly through the Operator.
5.3.5.1. Creating DNS records on a public hosted zone for AWS by using Red Hat External DNS Operator
You can create DNS records on a public hosted zone for AWS by using the Red Hat External DNS Operator. You can use the same instructions to create DNS records on a hosted zone for AWS GovCloud.
Procedure
Check the user profile by running the following command. The profile, such as
system:admin, must have access to thekube-systemnamespace. If you do not have the credentials, you can fetch the credentials from thekube-systemnamespace to use the cloud provider client by running the following command:$ oc whoamiFetch the values from the
aws-credssecret that exists in thekube-systemnamespace.$ export AWS_ACCESS_KEY_ID=$(oc get secrets aws-creds -n kube-system --template={{.data.aws_access_key_id}} | base64 -d)$ export AWS_SECRET_ACCESS_KEY=$(oc get secrets aws-creds -n kube-system --template={{.data.aws_secret_access_key}} | base64 -d)Get the routes to check the domain:
$ oc get routes --all-namespaces | grep consoleExample output
openshift-console console console-openshift-console.apps.testextdnsoperator.apacshift.support console https reencrypt/Redirect None openshift-console downloads downloads-openshift-console.apps.testextdnsoperator.apacshift.support downloads http edge/Redirect NoneGet the list of DNS zones and find the DNS zone that corresponds to the domain of the route that you previously queried:
$ aws route53 list-hosted-zones | grep testextdnsoperator.apacshift.supportExample output
HOSTEDZONES terraform /hostedzone/Z02355203TNN1XXXX1J6O testextdnsoperator.apacshift.support. 5Create the
ExternalDNSCR for theroutesource:$ cat <<EOF | oc create -f - apiVersion: externaldns.olm.openshift.io/v1beta1 kind: ExternalDNS metadata: name: sample-aws spec: domains: - filterType: Include matchType: Exact name: testextdnsoperator.apacshift.support provider: type: AWS source: type: OpenShiftRoute openshiftRouteOptions: routerName: default EOFwhere:
metadata.name- Specifies the name of the external DNS resource.
spec.domains- By default all hosted zones are selected as potential targets. You can include a hosted zone that you need.
domains.matchType- Specifies that the matching of the domain from the target zone has to be exact. Exact as opposed to regular expression match.
domains.name- Specifies the exact domain of the zone you want to update. The hostname of the routes must be subdomains of the specified domain.
provider.type-
Specifies the
AWS Route53DNS provider. source- Specifies the options for the source of DNS records.
source.type-
Specifies the
OpenShiftRouteresource as the source for the DNS records which gets created in the previously specified DNS provider. openshiftRouteOptions.routerName-
If the source is
OpenShiftRoute, then you can pass the OpenShift Ingress Controller name. External DNS Operator selects the canonical hostname of that router as the target while creating the CNAME record.
Check the records created for OpenShift Container Platform routes by using the following command:
$ aws route53 list-resource-record-sets --hosted-zone-id Z02355203TNN1XXXX1J6O --query "ResourceRecordSets[?Type == 'CNAME']" | grep console
5.3.5.2. Creating DNS records in a different AWS account by using a shared VPC
To create DNS records in a different AWS account, configure the ExternalDNS Operator to use a shared Virtual Private Cloud (VPC). Your organization can then use a single Route 53 instance for name resolution across multiple accounts and projects.
Prerequisites
- You have created two Amazon AWS accounts: one with a VPC and a Route 53 private hosted zone configured (Account A), and another for installing a cluster (Account B).
- You have created an IAM Policy and IAM Role with the appropriate permissions in Account A for Account B to create DNS records in the Route 53 hosted zone of Account A.
- You have installed a cluster in Account B into the existing VPC for Account A.
- You have installed the ExternalDNS Operator in the cluster in Account B.
Procedure
Get the Role ARN of the IAM Role that you created to allow Account B to access Account A’s Route 53 hosted zone by running the following command:
$ aws --profile account-a iam get-role --role-name user-rol1 | head -1Example output
ROLE arn:aws:iam::1234567890123:role/user-rol1 2023-09-14T17:21:54+00:00 3600 / AROA3SGB2ZRKRT5NISNJN user-rol1Locate the private hosted zone to use with Account A’s credentials by running the following command:
$ aws --profile account-a route53 list-hosted-zones | grep testextdnsoperator.apacshift.supportExample output
HOSTEDZONES terraform /hostedzone/Z02355203TNN1XXXX1J6O testextdnsoperator.apacshift.support. 5Create the
ExternalDNSobject by running the following command:$ cat <<EOF | oc create -f - apiVersion: externaldns.olm.openshift.io/v1beta1 kind: ExternalDNS metadata: name: sample-aws spec: domains: - filterType: Include matchType: Exact name: testextdnsoperator.apacshift.support provider: type: AWS aws: assumeRole: arn: arn:aws:iam::12345678901234:role/user-rol1 source: type: OpenShiftRoute openshiftRouteOptions: routerName: default EOFwhere:
arn- Specifies the Role ARN to have DNS records created in Account A.
Check the records created for OpenShift Container Platform routes by entering the following command:
$ aws --profile account-a route53 list-resource-record-sets --hosted-zone-id Z02355203TNN1XXXX1J6O --query "ResourceRecordSets[?Type == 'CNAME']" | grep console-openshift-console
5.3.6. Creating DNS records on Azure
To create DNS records on Microsoft Azure, use the External DNS Operator. By using this Operator, you can manage external name resolution for your cluster services.
Using the External DNS Operator on a Microsoft Entra Workload ID-enabled cluster or a cluster that runs in Microsoft Azure Government (MAG) regions is not supported.
5.3.6.1. Creating DNS records on an Azure DNS zone
To create DNS records on a public or private DNS zone for Azure, use the External DNS Operator. The Operator manages external name resolution for your cluster.
Prerequisites
- You must have administrator privileges.
-
The
adminuser must have access to thekube-systemnamespace.
Procedure
Fetch the credentials from the
kube-systemnamespace to use the cloud provider client by running the following command:$ CLIENT_ID=$(oc get secrets azure-credentials -n kube-system --template={{.data.azure_client_id}} | base64 -d)$ CLIENT_SECRET=$(oc get secrets azure-credentials -n kube-system --template={{.data.azure_client_secret}} | base64 -d)$ RESOURCE_GROUP=$(oc get secrets azure-credentials -n kube-system --template={{.data.azure_resourcegroup}} | base64 -d)$ SUBSCRIPTION_ID=$(oc get secrets azure-credentials -n kube-system --template={{.data.azure_subscription_id}} | base64 -d)$ TENANT_ID=$(oc get secrets azure-credentials -n kube-system --template={{.data.azure_tenant_id}} | base64 -d)Log in to Azure by running the following command:
$ az login --service-principal -u "${CLIENT_ID}" -p "${CLIENT_SECRET}" --tenant "${TENANT_ID}"Get a list of routes by running the following command:
$ oc get routes --all-namespaces | grep consoleExample output
openshift-console console console-openshift-console.apps.test.azure.example.com console https reencrypt/Redirect None openshift-console downloads downloads-openshift-console.apps.test.azure.example.com downloads http edge/Redirect NoneGet a list of DNS zones.
For public DNS zones, enter the following command:
$ az network dns zone list --resource-group "${RESOURCE_GROUP}"For private DNS zones, enter the following command:
$ az network private-dns zone list -g "${RESOURCE_GROUP}"
Create a YAML file, for example,
external-dns-sample-azure.yaml, that defines theExternalDNSobject:Example
external-dns-sample-azure.yamlfileapiVersion: externaldns.olm.openshift.io/v1beta1 kind: ExternalDNS metadata: name: sample-azure spec: zones: - "/subscriptions/1234567890/resourceGroups/test-azure-xxxxx-rg/providers/Microsoft.Network/dnszones/test.azure.example.com" provider: type: Azure source: openshiftRouteOptions: routerName: default type: OpenShiftRoute # ...where:
metadata.name- Specifies the External DNS name.
spec.zones-
Specifies the zone ID. For a private DNS zone, change
dnszonestoprivateDnsZones. provider.type- Specifies the provider type.
source.openshiftRouteOptions- Specifies the options for the source of DNS records.
routerName-
If the source type is
OpenShiftRoute, you can pass the OpenShift Ingress Controller name. The External DNS Operator selects the canonical hostname of that router as the target while creating the CNAME record. source.type-
Specifies the
routeresource as the source for the Azure DNS records.
Troubleshooting
Check the records created for the routes.
For public DNS zones, enter the following command:
$ az network dns record-set list -g "${RESOURCE_GROUP}" -z "${ZONE_NAME}" | grep consoleFor private DNS zones, enter the following command:
$ az network private-dns record-set list -g "${RESOURCE_GROUP}" -z "${ZONE_NAME}" | grep console
5.3.7. Creating DNS records on Google Cloud Platform
To create DNS records on Google Cloud, use the External DNS Operator. The DNS Operator manages external name resolution for your cluster services.
Using the External DNS Operator on a cluster with Google Cloud Workload Identity enabled is not supported. For more information about the Google Cloud Workload Identity, see Google Cloud Workload Identity.
5.3.7.1. Creating DNS records on a public managed zone for Google Cloud
To create DNS records on Google Cloud, use the External DNS Operator. The DNS Operator manages external name resolution for your cluster services.
Prerequisites
- You must have administrator privileges.
Procedure
Copy the
gcp-credentialssecret in theencoded-gcloud.jsonfile by running the following command:$ oc get secret gcp-credentials -n kube-system --template='{{$v := index .data "service_account.json"}}{{$v}}' | base64 -d - > decoded-gcloud.jsonExport your Google credentials by running the following command:
$ export GOOGLE_CREDENTIALS=decoded-gcloud.jsonActivate your account by using the following command:
$ gcloud auth activate-service-account <client_email as per decoded-gcloud.json> --key-file=decoded-gcloud.jsonSet your project by running the following command:
$ gcloud config set project <project_id as per decoded-gcloud.json>Get a list of routes by running the following command:
$ oc get routes --all-namespaces | grep consoleExample output
openshift-console console console-openshift-console.apps.test.gcp.example.com console https reencrypt/Redirect None openshift-console downloads downloads-openshift-console.apps.test.gcp.example.com downloads http edge/Redirect NoneGet a list of managed zones, such as
qe-cvs4g-private-zone test.gcp.example.com, by running the following command:$ gcloud dns managed-zones list | grep test.gcp.example.comCreate a YAML file, for example,
external-dns-sample-gcp.yaml, that defines theExternalDNSobject:Example
external-dns-sample-gcp.yamlfileapiVersion: externaldns.olm.openshift.io/v1beta1 kind: ExternalDNS metadata: name: sample-gcp spec: domains: - filterType: Include matchType: Exact name: test.gcp.example.com provider: type: GCP source: openshiftRouteOptions: routerName: default type: OpenShiftRoute # ...where:
metadata.name- Specifies the External DNS name.
spec.domains.filterType- By default, all hosted zones are selected as potential targets. You can include your hosted zone.
spec.domains.matchType-
Specifies the domain of the target that must match the string defined by the
namekey. spec.domains.name- Specifies the exact domain of the zone you want to update. The hostname of the routes must be subdomains of the specified domain.
spec.provider.type- Specifies the provider type.
source.openshiftRouteOptions- Specifies options for the source of DNS records.
openshiftRouteOptions.routerName-
If the source type is
OpenShiftRoute, you can pass the OpenShift Ingress Controller name. External DNS selects the canonical hostname of that router as the target while creating a CNAME record. type-
Specifies the
routeresource as the source for Google Cloud DNS records.
Check the DNS records created for OpenShift Container Platform routes by running the following command:
$ gcloud dns record-sets list --zone=qe-cvs4g-private-zone | grep console
5.3.8. Creating DNS records on Infoblox
To create DNS records on Infoblox, use the External DNS Operator. The Operator manages external name resolution for your cluster services.
5.3.8.1. Creating DNS records on a public DNS zone on Infoblox
To create DNS records on Infoblox, use the External DNS Operator. The Operator manages external name resolution for your cluster services.
Prerequisites
-
You have access to the OpenShift CLI (
oc). - You have access to the Infoblox UI.
Procedure
Create a
secretobject with Infoblox credentials by running the following command:$ oc -n external-dns-operator create secret generic infoblox-credentials --from-literal=EXTERNAL_DNS_INFOBLOX_WAPI_USERNAME=<infoblox_username> --from-literal=EXTERNAL_DNS_INFOBLOX_WAPI_PASSWORD=<infoblox_password>Get a list of routes by running the following command:
$ oc get routes --all-namespaces | grep consoleExample output
openshift-console console console-openshift-console.apps.test.example.com console https reencrypt/Redirect None openshift-console downloads downloads-openshift-console.apps.test.example.com downloads http edge/Redirect NoneCreate a YAML file, for example,
external-dns-sample-infoblox.yaml, that defines theExternalDNSobject:Example
external-dns-sample-infoblox.yamlfileapiVersion: externaldns.olm.openshift.io/v1beta1 kind: ExternalDNS metadata: name: sample-infoblox spec: provider: type: Infoblox infoblox: credentials: name: infoblox-credentials gridHost: ${INFOBLOX_GRID_PUBLIC_IP} wapiPort: 443 wapiVersion: "2.3.1" domains: - filterType: Include matchType: Exact name: test.example.com source: type: OpenShiftRoute openshiftRouteOptions: routerName: defaultwhere:
metadata.name- Specifies the External DNS name.
provider.type- Specifies the provider type.
source.type- Specifies options for the source of DNS records.
routerName-
If the source type is
OpenShiftRoute, you can pass the OpenShift Ingress Controller name. External DNS selects the canonical hostname of that router as the target while creating a CNAME record.
Create the
ExternalDNSresource on Infoblox by running the following command:$ oc create -f external-dns-sample-infoblox.yamlFrom the Infoblox UI, check the DNS records created for
consoleroutes:-
Click Data Management
DNS Zones. - Select the zone name.
-
Click Data Management
5.3.9. Configuring the cluster-wide proxy on the External DNS Operator
To propagate proxy settings to your deployed Operators, configure the cluster-wide proxy. The Operator Lifecycle Manager (OLM) automatically updates these Operators with the new HTTP_PROXY, HTTPS_PROXY, and NO_PROXY environment variables.
5.3.9.1. Trusting the certificate authority of the cluster-wide proxy
To enable the External DNS Operator to authenticate with the cluster-wide proxy, configure the Operator to trust the certificate authority (CA) of the proxy. This ensures secure communication when routing DNS traffic through the proxy.
Procedure
Create the config map to contain the CA bundle in the
external-dns-operatornamespace by running the following command:$ oc -n external-dns-operator create configmap trusted-caTo inject the trusted CA bundle into the config map, add the
config.openshift.io/inject-trusted-cabundle=truelabel to the config map by running the following command:$ oc -n external-dns-operator label cm trusted-ca config.openshift.io/inject-trusted-cabundle=trueUpdate the subscription of the External DNS Operator by running the following command:
$ oc -n external-dns-operator patch subscription external-dns-operator --type='json' -p='[{"op": "add", "path": "/spec/config", "value":{"env":[{"name":"TRUSTED_CA_CONFIGMAP_NAME","value":"trusted-ca"}]}}]'
Verification
After deploying the External DNS Operator, verify that the trusted CA environment variable is added by running the following command. The output must show
trusted-cafor theexternal-dns-operatordeployment.$ oc -n external-dns-operator exec deploy/external-dns-operator -c external-dns-operator -- printenv TRUSTED_CA_CONFIGMAP_NAME
5.4. MetalLB Operator
5.4.1. About MetalLB and the MetalLB Operator
In OpenShift Container Platform clusters running on bare metal or without a cloud load balancer, you can use the MetalLB Operator to assign external IP addresses to LoadBalancer services. These services receive external IPs on the host network.
5.4.1.1. When to use MetalLB
To get fault-tolerant access to applications through an external IP on bare metal in OpenShift Container Platform, you can use MetalLB.
MetalLB is useful when you have a bare-metal cluster, or an on-premise infrastructure without a native load balancer, and you need to expose services through external IP addresses.
You must configure your networking infrastructure to route network traffic for the external IP address from clients to the host network for the cluster.
When you deploy MetalLB with the MetalLB Operator, and add a service of type LoadBalancer, MetalLB provides a platform-native load balancer.
When external traffic enters your OpenShift Container Platform cluster through a MetalLB LoadBalancer service, the return traffic to the client has the external IP address of the load balancer as the source IP.
MetalLB operating in layer2 mode provides support for failover by utilizing a mechanism similar to IP failover. However, instead of relying on the virtual router redundancy protocol (VRRP) and keepalived, MetalLB leverages a gossip-based protocol to identify instances of node failure. When a failover is detected, another node assumes the role of the leader node, and a gratuitous ARP message is dispatched to broadcast this change.
MetalLB operating in layer3 or border gateway protocol (BGP) mode delegates failure detection to the network. The BGP router or routers that the OpenShift Container Platform nodes have established a connection with will identify any node failure and terminate the routes to that node.
Using MetalLB instead of IP failover is preferable for ensuring high availability of pods and services.
5.4.1.2. MetalLB Operator custom resources
In OpenShift Container Platform, you configure MetalLB deployment and IP advertisement through custom resources that the MetalLB Operator monitors. The resources include MetalLB, IPAddressPool, L2Advertisement, BGPAdvertisement, BGPPeer, and BFDProfile.
MetalLB-
When you add a
MetalLBcustom resource to the cluster, the MetalLB Operator deploys MetalLB on the cluster. The Operator only supports a single instance of the custom resource. If the instance is deleted, the Operator removes MetalLB from the cluster. IPAddressPoolMetalLB requires one or more pools of IP addresses that it can assign to a service when you add a service of type
LoadBalancer. AnIPAddressPoolincludes a list of IP addresses. The list can be a single IP address that is set using a range, such as 1.1.1.1-1.1.1.1, a range specified in CIDR notation, a range specified as a starting and ending address separated by a hyphen, or a combination of the three. AnIPAddressPoolrequires a name. The documentation uses names likedoc-example,doc-example-reserved, anddoc-example-ipv6. The MetalLBcontrollerassigns IP addresses from a pool of addresses in anIPAddressPool.L2AdvertisementandBGPAdvertisementcustom resources enable the advertisement of a given IP from a given pool. You can assign IP addresses from anIPAddressPoolto services and namespaces by using thespec.serviceAllocationspecification in theIPAddressPoolcustom resource.NoteA single
IPAddressPoolcan be referenced by a L2 advertisement and a BGP advertisement.BGPPeer- The BGP peer custom resource identifies the BGP router for MetalLB to communicate with, the AS number of the router, the AS number for MetalLB, and customizations for route advertisement. MetalLB advertises the routes for service load-balancer IP addresses to one or more BGP peers.
BFDProfile- The BFD profile custom resource configures Bidirectional Forwarding Detection (BFD) for a BGP peer. BFD provides faster path failure detection than BGP alone provides.
L2Advertisement-
The L2Advertisement custom resource advertises an IP coming from an
IPAddressPoolusing the L2 protocol. BGPAdvertisement-
The BGPAdvertisement custom resource advertises an IP coming from an
IPAddressPoolusing the BGP protocol.
After you add the MetalLB custom resource to the cluster and the Operator deploys MetalLB, the controller and speaker MetalLB software components begin running.
MetalLB validates all relevant custom resources.
5.4.1.3. MetalLB software components
In OpenShift Container Platform, you get external IPs for LoadBalancer services from two MetalLB components. The controller assigns IPs from address pools, and the speaker advertises them via layer 2 or BGP.
When you install the MetalLB Operator, the metallb-operator-controller-manager deployment starts a pod. The pod is the implementation of the Operator. The pod monitors for changes to all the relevant resources.
When the Operator starts an instance of MetalLB, it starts a controller deployment and a speaker daemon set.
You can configure deployment specifications in the MetalLB custom resource to manage how controller and speaker pods deploy and run in your cluster. For more information about these deployment specifications, see the Additional resources section.
controllerThe Operator starts the deployment and a single pod. When you add a service of type
LoadBalancer, Kubernetes uses thecontrollerto allocate an IP address from an address pool. In case of a service failure, verify you have the following entry in yourcontrollerpod logs:Example output
"event":"ipAllocated","ip":"172.22.0.201","msg":"IP address assigned by controllerspeakerThe Operator starts a daemon set for
speakerpods. By default, a pod is started on each node in your cluster. You can limit the pods to specific nodes by specifying a node selector in theMetalLBcustom resource when you start MetalLB. If thecontrollerallocated the IP address to the service and service is still unavailable, read thespeakerpod logs. If thespeakerpod is unavailable, run theoc describe pod -ncommand.For layer 2 mode, after the
controllerallocates an IP address for the service, thespeakerpods use an algorithm to determine whichspeakerpod on which node will announce the load balancer IP address. The algorithm involves hashing the node name and the load balancer IP address. For more information, see "MetalLB and external traffic policy". Thespeakeruses Address Resolution Protocol (ARP) to announce IPv4 addresses and Neighbor Discovery Protocol (NDP) to announce IPv6 addresses.
For Border Gateway Protocol (BGP) mode, after the controller allocates an IP address for the service, each speaker pod advertises the load balancer IP address with its BGP peers. You can configure which nodes start BGP sessions with BGP peers.
Requests for the load balancer IP address are routed to the node with the speaker that announces the IP address. After the node receives the packets, the service proxy routes the packets to an endpoint for the service. The endpoint can be on the same node in the optimal case, or it can be on another node. The service proxy chooses an endpoint each time a connection is established.
5.4.1.4. MetalLB and external traffic policy
External traffic policy for MetalLB LoadBalancer services determines how the service proxy distributes traffic to pods. Set the policy to cluster for uniform distribution or to local to preserve client IP addresses.
With layer 2 mode, one node in your cluster receives all the traffic for the service IP address.
With BGP mode, a router on the host network opens a connection to one of the nodes in the cluster for a new client connection.
How your cluster handles the traffic after it enters the node is affected by the external traffic policy.
clusterThis is the default value for
spec.externalTrafficPolicy.With the
clustertraffic policy, after the node receives the traffic, the service proxy distributes the traffic to all the pods in your service. This policy provides uniform traffic distribution across the pods, but it obscures the client IP address and it can appear to the application in your pods that the traffic originates from the node rather than the client.localWith the
localtraffic policy, after the node receives the traffic, the service proxy only sends traffic to the pods on the same node. For example, if thespeakerpod on node A announces the external service IP, then all traffic is sent to node A. After the traffic enters node A, the service proxy only sends traffic to pods for the service that are also on node A. Pods for the service that are on additional nodes do not receive any traffic from node A. Pods for the service on additional nodes act as replicas in case failover is needed.This policy does not affect the client IP address. Application pods can determine the client IP address from the incoming connections.
The following information is important when configuring the external traffic policy in BGP mode.
Although MetalLB advertises the load balancer IP address from all the eligible nodes, the number of nodes loadbalancing the service can be limited by the capacity of the router to establish equal-cost multipath (ECMP) routes. If the number of nodes advertising the IP is greater than the ECMP group limit of the router, the router will use less nodes than the ones advertising the IP.
For example, if the external traffic policy is set to local and the router has an ECMP group limit set to 16 and the pods implementing a LoadBalancer service are deployed on 30 nodes, this would result in pods deployed on 14 nodes not receiving any traffic. In this situation, it would be preferable to set the external traffic policy for the service to cluster.
5.4.1.5. MetalLB concepts for layer 2 mode
MetalLB in layer 2 mode announces the external IP for a LoadBalancer service from one node via ARP or NDP. All traffic for the service goes through that node, and failover to another node is automatic when the node becomes unavailable.
In layer 2 mode, MetalLB relies on ARP and NDP. These protocols implement local address resolution within a specific subnet. In this context, the client must be able to reach the VIP assigned by MetalLB that exists on the same subnet as the nodes announcing the service in order for MetalLB to work.
The speaker pod responds to ARP requests for IPv4 services and NDP requests for IPv6.
In layer 2 mode, all traffic for a service IP address is routed through one node. After traffic enters the node, the service proxy for the CNI network provider distributes the traffic to all the pods for the service.
Because all traffic for a service enters through a single node in layer 2 mode, in a strict sense, MetalLB does not implement a load balancer for layer 2. Rather, MetalLB implements a failover mechanism for layer 2 so that when a speaker pod becomes unavailable, a speaker pod on a different node can announce the service IP address.
When a node becomes unavailable, failover is automatic. The speaker pods on the other nodes detect that a node is unavailable and a new speaker pod and node take ownership of the service IP address from the failed node.
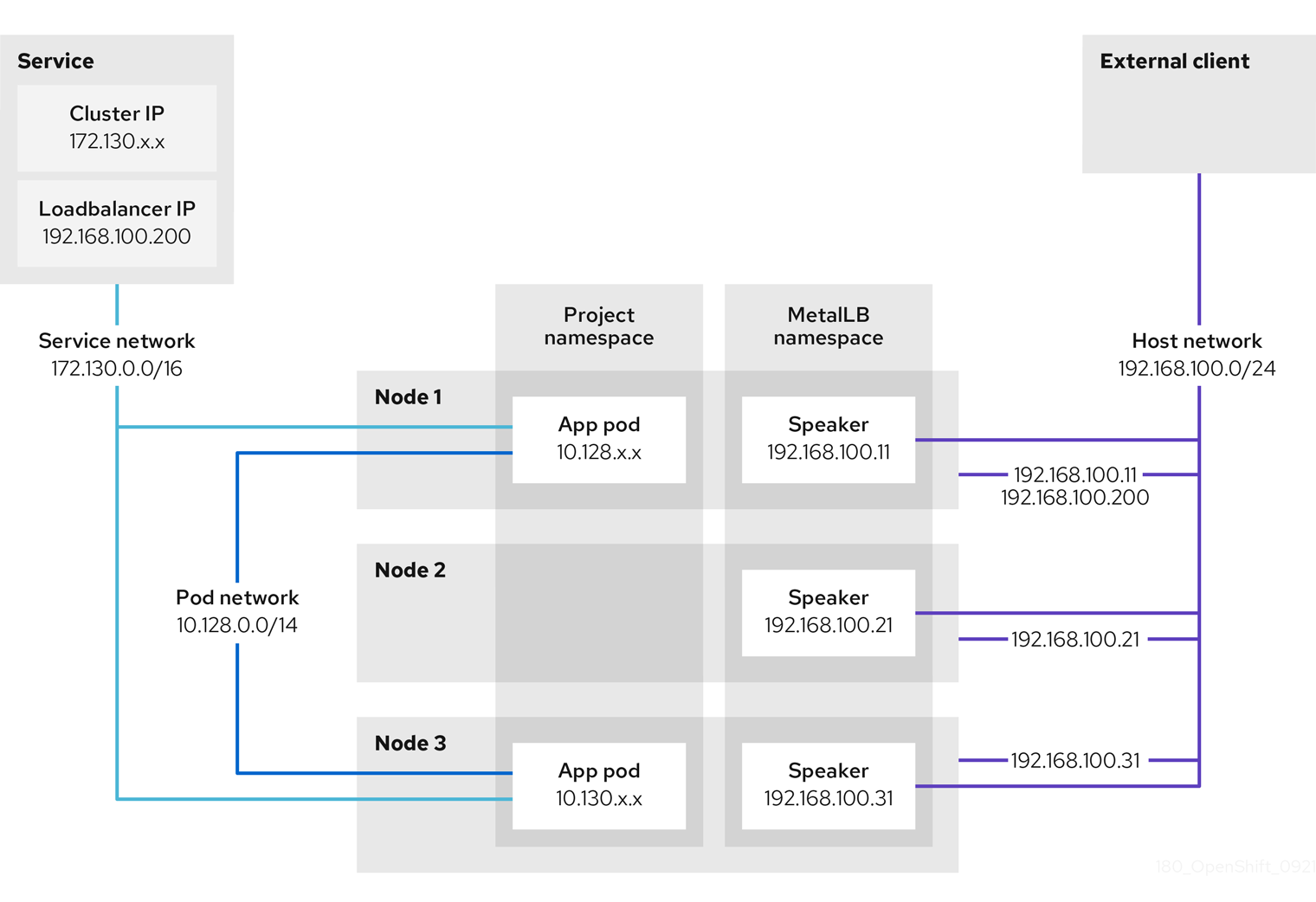
The preceding graphic shows the following concepts related to MetalLB:
-
An application is available through a service that has a cluster IP on the
172.130.0.0/16subnet. That IP address is accessible from inside the cluster. The service also has an external IP address that MetalLB assigned to the service,192.168.100.200. - Nodes 1 and 3 have a pod for the application.
-
The
speakerdaemon set runs a pod on each node. The MetalLB Operator starts these pods. -
Each
speakerpod is a host-networked pod. The IP address for the pod is identical to the IP address for the node on the host network. -
The
speakerpod on node 1 uses ARP to announce the external IP address for the service,192.168.100.200. Thespeakerpod that announces the external IP address must be on the same node as an endpoint for the service and the endpoint must be in theReadycondition. Client traffic is routed to the host network and connects to the
192.168.100.200IP address. After traffic enters the node, the service proxy sends the traffic to the application pod on the same node or another node according to the external traffic policy that you set for the service.-
If the external traffic policy for the service is set to
cluster, the node that advertises the192.168.100.200load balancer IP address is selected from the nodes where aspeakerpod is running. Only that node can receive traffic for the service. -
If the external traffic policy for the service is set to
local, the node that advertises the192.168.100.200load balancer IP address is selected from the nodes where aspeakerpod is running and at least an endpoint of the service. Only that node can receive traffic for the service. In the preceding graphic, either node 1 or 3 would advertise192.168.100.200.
-
If the external traffic policy for the service is set to
-
If node 1 becomes unavailable, the external IP address fails over to another node. On another node that has an instance of the application pod and service endpoint, the
speakerpod begins to announce the external IP address,192.168.100.200and the new node receives the client traffic. In the diagram, the only candidate is node 3.
5.4.1.6. MetalLB concepts for BGP mode
MetalLB in border gateway protocol (BGP) mode advertises load balancer IP addresses to BGP peers from each speaker pod. The router sends traffic to one of the nodes, so load is distributed across nodes and the router switches to another node when one becomes unavailable.
It is also possible to advertise the IPs coming from a given pool to a specific set of peers by adding an optional list of BGP peers.
BGP peers are commonly network routers that are configured to use the BGP protocol. When a router receives traffic for the load balancer IP address, the router picks one of the nodes with a speaker pod that advertised the IP address. The router sends the traffic to that node. After traffic enters the node, the service proxy for the CNI network plugin distributes the traffic to all the pods for the service.
The directly-connected router on the same layer 2 network segment as the cluster nodes can be configured as a BGP peer. If the directly-connected router is not configured as a BGP peer, you need to configure your network so that packets for load balancer IP addresses are routed between the BGP peers and the cluster nodes that run the speaker pods.
Each time a router receives new traffic for the load balancer IP address, it creates a new connection to a node. Each router manufacturer has an implementation-specific algorithm for choosing which node to initiate the connection with. However, the algorithms commonly are designed to distribute traffic across the available nodes for the purpose of balancing the network load.
If a node becomes unavailable, the router initiates a new connection with another node that has a speaker pod that advertises the load balancer IP address.
Figure 5.1. MetalLB topology diagram for BGP mode
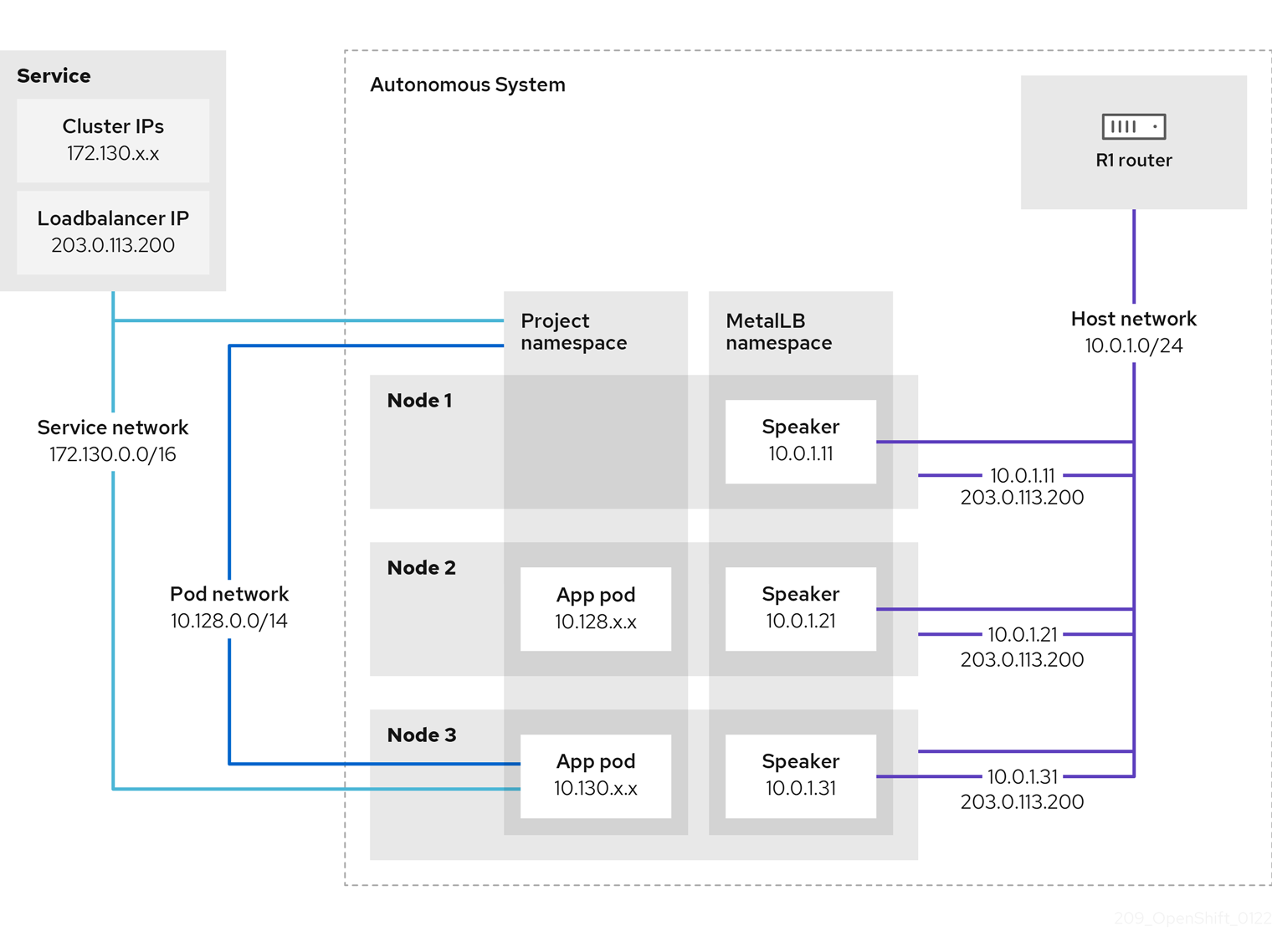
The preceding graphic shows the following concepts related to MetalLB:
-
An application is available through a service that has an IPv4 cluster IP on the
172.130.0.0/16subnet. That IP address is accessible from inside the cluster. The service also has an external IP address that MetalLB assigned to the service,203.0.113.200. - Nodes 2 and 3 have a pod for the application.
-
The
speakerdaemon set runs a pod on each node. The MetalLB Operator starts these pods. You can configure MetalLB to specify which nodes run thespeakerpods. -
Each
speakerpod is a host-networked pod. The IP address for the pod is identical to the IP address for the node on the host network. -
Each
speakerpod starts a BGP session with all BGP peers and advertises the load balancer IP addresses or aggregated routes to the BGP peers. Thespeakerpods advertise that they are part of Autonomous System 65010. The diagram shows a router, R1, as a BGP peer within the same Autonomous System. However, you can configure MetalLB to start BGP sessions with peers that belong to other Autonomous Systems. All the nodes with a
speakerpod that advertises the load balancer IP address can receive traffic for the service.-
If the external traffic policy for the service is set to
cluster, all the nodes where a speaker pod is running advertise the203.0.113.200load balancer IP address and all the nodes with aspeakerpod can receive traffic for the service. The host prefix is advertised to the router peer only if the external traffic policy is set to cluster. -
If the external traffic policy for the service is set to
local, then all the nodes where aspeakerpod is running and at least an endpoint of the service is running can advertise the203.0.113.200load balancer IP address. Only those nodes can receive traffic for the service. In the preceding graphic, nodes 2 and 3 would advertise203.0.113.200.
-
If the external traffic policy for the service is set to
-
You can configure MetalLB to control which
speakerpods start BGP sessions with specific BGP peers by specifying a node selector when you add a BGP peer custom resource. - Any routers, such as R1, that are configured to use BGP can be set as BGP peers.
- Client traffic is routed to one of the nodes on the host network. After traffic enters the node, the service proxy sends the traffic to the application pod on the same node or another node according to the external traffic policy that you set for the service.
- If a node becomes unavailable, the router detects the failure and initiates a new connection with another node. You can configure MetalLB to use a Bidirectional Forwarding Detection (BFD) profile for BGP peers. BFD provides faster link failure detection so that routers can initiate new connections earlier than without BFD.
5.4.1.7. Limitations and restrictions
MetalLB has limitations for infrastructure, layer 2 mode, and BGP mode in OpenShift Container Platform. Consider infrastructure fit, layer 2 single-node bandwidth and failover, and BGP connection resets and single ASN when you plan your deployment.
5.4.1.7.1. Infrastructure considerations for MetalLB
MetalLB is designed for bare metal and on-premise environments where no native cloud load balancer is available. Before you deploy MetalLB, verify that your infrastructure meets the networking requirements for your chosen mode.
MetalLB is not supported on cloud provider platforms such as AWS, Azure, or Google Cloud. Cloud platforms virtualize the network layer and expose proprietary APIs instead of standard network protocols. As a result, MetalLB cannot function correctly on these platforms.
Use the load balancing service that the platform provides if your cluster runs on a cloud platform.
5.4.1.7.1.1. Supported platforms
The following infrastructure platforms support MetalLB:
- Bare metal
- VMware vSphere
- IBM Z® and IBM® LinuxONE
- IBM Z® and IBM® LinuxONE for Red Hat Enterprise Linux (RHEL) KVM
- IBM Power®
MetalLB Operator and MetalLB are supported with the OpenShift SDN and OVN-Kubernetes network providers.
5.4.1.7.1.2. Network prerequisites
MetalLB requires the following network capabilities, depending on the operating mode:
- For Layer 2 mode
- Standard ARP (IPv4) or NDP (IPv6) must function on the network. The network must not block or emulate ARP/NDP traffic.
- Anti-ARP-spoofing protections, if present, must be disabled on nodes running MetalLB speakers. Some virtualization platforms, such as Red Hat OpenStack Platform (RHOSP), enable this protection by default.
- For BGP mode
- An external BGP-capable router must be available and reachable from the cluster nodes.
- The network must allow BGP sessions (TCP port 179) between the cluster nodes and the upstream router.
- For both modes
- Configure external network infrastructure to route traffic destined for the external IP addresses to the cluster nodes.
5.4.1.7.2. Limitations for layer 2 mode
In OpenShift Container Platform, MetalLB layer 2 mode is limited to single-node bandwidth and failover depends on client ARP handling. Avoid using the same VLAN for MetalLB and an additional network to prevent connection failures.
5.4.1.7.2.1. Single-node bottleneck
MetalLB routes all traffic for a service through a single node, the node can become a bottleneck and limit performance.
Layer 2 mode limits the ingress bandwidth for your service to the bandwidth of a single node. This is a fundamental limitation of using ARP and NDP to direct traffic.
5.4.1.7.2.2. Slow failover performance
Failover between nodes depends on cooperation from the clients. When a failover occurs, MetalLB sends gratuitous ARP packets to notify clients that the MAC address associated with the service IP has changed.
Most client operating systems handle gratuitous ARP packets correctly and update their neighbor caches promptly. When clients update their caches quickly, failover completes within a few seconds. Clients typically fail over to a new node within 10 seconds. However, some client operating systems either do not handle gratuitous ARP packets at all or have outdated implementations that delay the cache update.
Recent versions of common operating systems such as Windows, macOS, and Linux implement layer 2 failover correctly. Issues with slow failover are not expected except for older and less common client operating systems.
To minimize the impact from a planned failover on outdated clients, keep the old node running for a few minutes after flipping leadership. The old node can continue to forward traffic for outdated clients until their caches refresh.
During an unplanned failover, the service IPs are unreachable until the outdated clients refresh their cache entries.
5.4.1.7.2.3. Additional Network and MetalLB cannot use same network
Using the same VLAN for both MetalLB and an additional network interface set up on a source pod might result in a connection failure. This occurs when both the MetalLB IP and the source pod reside on the same node.
To avoid connection failures, place the MetalLB IP in a different subnet from the one where the source pod resides. This configuration ensures that traffic from the source pod will take the default gateway. Consequently, the traffic can effectively reach its destination by using the OVN overlay network, ensuring that the connection functions as intended.
5.4.1.7.3. Limitations for BGP mode
In OpenShift Container Platform, MetalLB border gateway protocol (BGP) mode can reset active connections when a BGP session terminates and requires a single ASN and router ID for all BGP peers. Use a node selector when adding a BGP peer to limit which nodes run BGP sessions and reduce the impact of node faults.
5.4.1.7.3.1. Node failure can break all active connections
MetalLB shares a limitation that is common to BGP-based load balancing. When a BGP session terminates, such as when a node fails or when a speaker pod restarts, the session termination might result in resetting all active connections. End users can experience a Connection reset by peer message.
The consequence of a terminated BGP session is implementation-specific for each router manufacturer. However, you can anticipate that a change in the number of speaker pods affects the number of BGP sessions and that active connections with BGP peers will break.
To avoid or reduce the likelihood of a service interruption, you can specify a node selector when you add a BGP peer. By limiting the number of nodes that start BGP sessions, a fault on a node that does not have a BGP session has no affect on connections to the service.
5.4.1.7.3.2. Support for a single ASN and a single router ID only
When you add a BGP peer custom resource, you specify the spec.myASN field to identify the Autonomous System Number (ASN) that MetalLB belongs to. OpenShift Container Platform uses an implementation of BGP with MetalLB that requires MetalLB to belong to a single ASN. If you attempt to add a BGP peer and specify a different value for spec.myASN than an existing BGP peer custom resource, you receive an error.
Similarly, when you add a BGP peer custom resource, the spec.routerID field is optional. If you specify a value for this field, you must specify the same value for all other BGP peer custom resources that you add.
The limitation to support a single ASN and single router ID is a difference with the community-supported implementation of MetalLB.
5.4.2. Installing the MetalLB Operator
As a cluster administrator, you can add the MetalLB Operator so that the Operator can manage the lifecycle for an instance of MetalLB on your cluster.
MetalLB and IP failover are incompatible. If you configured IP failover for your cluster, perform the steps to remove IP failover before you install the Operator.
5.4.2.1. Installing the MetalLB Operator from the OperatorHub by using the web console
As a cluster administrator, you can install the MetalLB Operator by using the OpenShift Container Platform web console.
Prerequisites
-
Log in as a user with
cluster-adminprivileges.
Procedure
-
In the OpenShift Container Platform web console, navigate to Operators
OperatorHub. Type a keyword into the Filter by keyword box or scroll to find the Operator you want. For example, type
metallbto find the MetalLB Operator.You can also filter options by Infrastructure Features. For example, select Disconnected if you want to see Operators that work in disconnected environments, also known as restricted network environments.
- On the Install Operator page, accept the defaults and click Install.
Verification
To confirm that the installation is successful:
-
Navigate to the Operators
Installed Operators page. -
Check that the Operator is installed in the
openshift-operatorsnamespace and that its status isSucceeded.
-
Navigate to the Operators
If the Operator is not installed successfully, check the status of the Operator and review the logs:
-
Navigate to the Operators
Installed Operators page and inspect the Statuscolumn for any errors or failures. -
Navigate to the Workloads
Pods page and check the logs in any pods in the openshift-operatorsproject that are reporting issues.
-
Navigate to the Operators
5.4.2.2. Installing from OperatorHub using the CLI
To install the MetalLB Operator from the software catalog in OpenShift Container Platform without using the web console, you can use the OpenShift CLI (oc).
It is recommended that when using the CLI you install the Operator in the metallb-system namespace.
Prerequisites
- A cluster installed on bare-metal hardware.
-
Install the OpenShift CLI (
oc). -
Log in as a user with
cluster-adminprivileges.
Procedure
Create a namespace for the MetalLB Operator by entering the following command:
$ cat << EOF | oc apply -f - apiVersion: v1 kind: Namespace metadata: name: metallb-system EOFCreate an Operator group custom resource (CR) in the namespace:
$ cat << EOF | oc apply -f - apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: metallb-operator namespace: metallb-system EOFConfirm the Operator group is installed in the namespace:
$ oc get operatorgroup -n metallb-systemExample output
NAME AGE metallb-operator 14mCreate a
SubscriptionCR:Define the
SubscriptionCR and save the YAML file, for example,metallb-sub.yaml:apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: metallb-operator-sub namespace: metallb-system spec: channel: stable name: metallb-operator source: redhat-operators sourceNamespace: openshift-marketplace-
For the
spec.sourceparameter, must specify theredhat-operatorsvalue.
-
For the
To create the
SubscriptionCR, run the following command:$ oc create -f metallb-sub.yaml
Optional: To ensure BGP and BFD metrics appear in Prometheus, you can label the namespace as in the following command:
$ oc label ns metallb-system "openshift.io/cluster-monitoring=true"
Verification
The verification steps assume the MetalLB Operator is installed in the metallb-system namespace.
Confirm the install plan is in the namespace:
$ oc get installplan -n metallb-systemExample output
NAME CSV APPROVAL APPROVED install-wzg94 metallb-operator.4.16.0-nnnnnnnnnnnn Automatic trueNoteInstallation of the Operator might take a few seconds.
To verify that the Operator is installed, enter the following command and then check that output shows
Succeededfor the Operator:$ oc get clusterserviceversion -n metallb-system \ -o custom-columns=Name:.metadata.name,Phase:.status.phase
5.4.2.3. Starting MetalLB on your cluster
To start MetalLB on your cluster after installing the MetalLB Operator in OpenShift Container Platform, you create a single MetalLB custom resource.
Prerequisites
-
Install the OpenShift CLI (
oc). -
Log in as a user with
cluster-adminprivileges. - Install the MetalLB Operator.
Procedure
Create a single instance of a MetalLB custom resource:
$ cat << EOF | oc apply -f - apiVersion: metallb.io/v1beta1 kind: MetalLB metadata: name: metallb namespace: metallb-system EOF-
For the
metdata.namespaceparameter, substitutemetallb-systemwithopenshift-operatorsif you installed the MetalLB Operator using the web console.
-
For the
Verification
Confirm that the deployment for the MetalLB controller and the daemon set for the MetalLB speaker are running.
Verify that the deployment for the controller is running:
$ oc get deployment -n metallb-system controllerExample output
NAME READY UP-TO-DATE AVAILABLE AGE controller 1/1 1 1 11mVerify that the daemon set for the speaker is running:
$ oc get daemonset -n metallb-system speakerExample output
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE speaker 6 6 6 6 6 kubernetes.io/os=linux 18mThe example output indicates 6 speaker pods. The number of speaker pods in your cluster might differ from the example output. Make sure the output indicates one pod for each node in your cluster.
5.4.2.4. Deployment specifications for MetalLB
Deployment specifications in the MetalLB custom resource control how the MetalLB controller and speaker pods deploy and run in OpenShift Container Platform.
Use deployment specifications to manage the following tasks:
- Select nodes for MetalLB pod deployment.
- Manage scheduling by using pod priority and pod affinity.
- Assign CPU limits for MetalLB pods.
- Assign a container RuntimeClass for MetalLB pods.
- Assign metadata for MetalLB pods.
5.4.2.4.1. Limit speaker pods to specific nodes
You can limit MetalLB speaker pods to specific nodes in OpenShift Container Platform by configuring a node selector in the MetalLB custom resource. Only nodes that run a speaker pod advertise load balancer IP addresses, so you control which nodes serve MetalLB traffic.
The most common reason to limit the speaker pods to specific nodes is to ensure that only nodes with network interfaces on specific networks advertise load balancer IP addresses.
If you limit the speaker pods to specific nodes and specify local for the external traffic policy of a service, then you must ensure that the application pods for the service are deployed to the same nodes.
Example configuration to limit speaker pods to worker nodes
apiVersion: metallb.io/v1beta1
kind: MetalLB
metadata:
name: metallb
namespace: metallb-system
spec:
nodeSelector:
node-role.kubernetes.io/worker: ""
speakerTolerations:
- key: "Example"
operator: "Exists"
effect: "NoExecute"-
In this example configuration, the
spec.nodeSelectorfield assigns thespeakerpods to worker nodes. You can specify labels that you assigned to nodes or any valid node selector. -
In this example configuration,
spec.speakerToTolerationspod that this toleration is attached to tolerates any taint that matches thekeyandeffectvalues by using theoperatorvalue.
After you apply a manifest with the spec.nodeSelector field, you can check the number of pods that the Operator deployed with the oc get daemonset -n metallb-system speaker command. Similarly, you can display the nodes that match your labels with a command like oc get nodes -l node-role.kubernetes.io/worker=.
You can optionally allow the node to control which speaker pods should, or should not, be scheduled on them by using affinity rules. You can also limit these pods by applying a list of tolerations. For more information about affinity rules, taints, and tolerations, see the additional resources.
5.4.2.4.2. Configuring pod priority and pod affinity in a MetalLB deployment
To control scheduling of MetalLB controller and speaker pods in OpenShift Container Platform, you can assign pod priority and pod affinity in the MetalLB custom resource. You create a PriorityClass and set priorityClassName and affinity in the MetalLB spec, then apply the configuration.
The pod priority indicates the relative importance of a pod on a node and schedules the pod based on this priority. Set a high priority on your controller or speaker pod to ensure scheduling priority over other pods on the node.
Pod affinity manages relationships among pods. Assign pod affinity to the controller or speaker pods to control on what node the scheduler places the pod in the context of pod relationships. For example, you can use pod affinity rules to ensure that certain pods are located on the same node or nodes, which can help improve network communication and reduce latency between those components.
Prerequisites
-
You are logged in as a user with
cluster-adminprivileges. - You have installed the MetalLB Operator.
- You have started the MetalLB Operator on your cluster.
Procedure
Create a
PriorityClasscustom resource, such asmyPriorityClass.yaml, to configure the priority level. This example defines aPriorityClassnamedhigh-prioritywith a value of1000000. Pods that are assigned this priority class are considered higher priority during scheduling compared to pods with lower priority classes:apiVersion: scheduling.k8s.io/v1 kind: PriorityClass metadata: name: high-priority value: 1000000Apply the
PriorityClasscustom resource configuration:$ oc apply -f myPriorityClass.yamlCreate a
MetalLBcustom resource, such asMetalLBPodConfig.yaml, to specify thepriorityClassNameandpodAffinityvalues:apiVersion: metallb.io/v1beta1 kind: MetalLB metadata: name: metallb namespace: metallb-system spec: logLevel: debug controllerConfig: priorityClassName: high-priority affinity: podAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchLabels: app: metallb topologyKey: kubernetes.io/hostname speakerConfig: priorityClassName: high-priority affinity: podAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchLabels: app: metallb topologyKey: kubernetes.io/hostnamewhere:
spec.controllerConfig.priorityClassName-
Specifies the priority class for the MetalLB controller pods. In this case, it is set to
high-priority. spec.controllerConfig.affinity.podAffinity-
Specifies that you are configuring pod affinity rules. These rules dictate how pods are scheduled in relation to other pods or nodes. This configuration instructs the scheduler to schedule pods that have the label
app: metallbonto nodes that share the same hostname. This helps to co-locate MetalLB-related pods on the same nodes, potentially optimizing network communication, latency, and resource usage between these pods.
Apply the
MetalLBcustom resource configuration by running the following command:$ oc apply -f MetalLBPodConfig.yaml
Verification
To view the priority class that you assigned to pods in the
metallb-systemnamespace, run the following command:$ oc get pods -n metallb-system -o custom-columns=NAME:.metadata.name,PRIORITY:.spec.priorityClassNameExample output
NAME PRIORITY controller-584f5c8cd8-5zbvg high-priority metallb-operator-controller-manager-9c8d9985-szkqg <none> metallb-operator-webhook-server-c895594d4-shjgx <none> speaker-dddf7 high-priorityVerify that the scheduler placed pods according to pod affinity rules by viewing the metadata for the node of the pod. For example:
$ oc get pod -o=custom-columns=NODE:.spec.nodeName,NAME:.metadata.name -n metallb-system
5.4.2.4.3. Configuring pod CPU limits in a MetalLB deployment
To manage compute resources on nodes running MetalLB in OpenShift Container Platform, you can assign CPU limits to the controller and speaker pods in the MetalLB custom resource. This ensures that all pods on the node have the necessary compute resources to manage workloads and cluster housekeeping.
Prerequisites
-
You are logged in as a user with
cluster-adminprivileges. - You have installed the MetalLB Operator.
Procedure
Create a
MetalLBcustom resource file, such asCPULimits.yaml, to specify thecpuvalue for thecontrollerandspeakerpods:apiVersion: metallb.io/v1beta1 kind: MetalLB metadata: name: metallb namespace: metallb-system spec: logLevel: debug controllerConfig: resources: limits: cpu: "200m" speakerConfig: resources: limits: cpu: "300m"Apply the
MetalLBcustom resource configuration:$ oc apply -f CPULimits.yaml
Verification
To view compute resources for a pod, run the following command, replacing
<pod_name>with your target pod:$ oc describe pod <pod_name>
5.4.3. Upgrading the MetalLB Operator
The Subscription custom resource (CR) for the MetalLB Operator is used to manage whether the Operator is upgraded automatically or manually.
By default, the Subscription CR assigns the namespace to metallb-system and automatically sets the installPlanApproval parameter to Automatic. This means that when Red Hat-provided Operator catalogs include a newer version of the MetalLB Operator, the MetalLB Operator is automatically upgraded.
If you need to manually control upgrading the MetalLB Operator, set the installPlanApproval parameter to Manual.
5.4.3.1. Manually upgrading the MetalLB Operator
To manually control when the MetalLB Operator upgrades in OpenShift Container Platform, you set installPlanApproval to Manual in the Subscription custom resource and approve the install plan. You then verify the upgrade by using the ClusterServiceVersion status.
Prerequisites
- You updated your cluster to the latest z-stream release.
- You used OperatorHub to install the MetalLB Operator.
-
Access the cluster as a user with the
cluster-adminrole.
Procedure
Get the YAML definition of the
metallb-operatorsubscription in themetallb-systemnamespace by entering the following command:$ oc -n metallb-system get subscription metallb-operator -o yamlEdit the
SubscriptionCR by setting theinstallPlanApprovalparameter toManual:apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: metallb-operator namespace: metallb-system # ... spec: channel: stable installPlanApproval: Manual name: metallb-operator source: redhat-operators sourceNamespace: openshift-marketplace # ...Find the latest OpenShift Container Platform 4.16 version of the MetalLB Operator by entering the following command:
$ oc -n metallb-system get csvCheck the install plan that exists in the namespace by entering the following command.
$ oc -n metallb-system get installplanExample output that shows install-tsz2g as a manual install plan
NAME CSV APPROVAL APPROVED install-shpmd metallb-operator.v4.16.0-202502261233 Automatic true install-tsz2g metallb-operator.v4.16.0-202503102139 Manual falseEdit the install plan that exists in the namespace by entering the following command. Ensure that you replace
<name_of_installplan>with the name of the install plan, such asinstall-tsz2g.$ oc edit installplan <name_of_installplan> -n metallb-systemWith the install plan open in your editor, set the
spec.approvalparameter toManualand set thespec.approvedparameter totrue.NoteAfter you edit the install plan, the upgrade operation starts. If you enter the
oc -n metallb-system get csvcommand during the upgrade operation, the output might show theReplacingor thePendingstatus.
Verification
To verify that the Operator is upgraded, enter the following command and then check that output shows
Succeededfor the Operator:$ oc -n metallb-system get csv
5.4.3.2. Additional resources
5.5. Cluster Network Operator in OpenShift Container Platform
With the Cluster Network Operator, you can manage networking in OpenShift Container Platform, including how to view status, enable IP forwarding, and collect logs.
You can use the Cluster Network Operator (CNO) to deploy and manage cluster network components on an OpenShift Container Platform cluster, including the Container Network Interface (CNI) network plugin selected for the cluster during installation.
5.5.1. Cluster Network Operator
The Cluster Network Operator implements the network API from the operator.openshift.io API group. The Operator deploys the OVN-Kubernetes network plugin, or the network provider plugin that you selected during cluster installation, by using a daemon set.
The Cluster Network Operator is deployed during installation as a Kubernetes Deployment.
Procedure
Run the following command to view the Deployment status:
$ oc get -n openshift-network-operator deployment/network-operatorExample output
NAME READY UP-TO-DATE AVAILABLE AGE network-operator 1/1 1 1 56mRun the following command to view the state of the Cluster Network Operator:
$ oc get clusteroperator/networkExample output
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE network 4.16.1 True False False 50mThe following fields provide information about the status of the operator:
AVAILABLE,PROGRESSING, andDEGRADED. TheAVAILABLEfield isTruewhen the Cluster Network Operator reports an available status condition.
5.5.2. Viewing the cluster network configuration
You can view your OpenShift Container Platform cluster network configuration by using the oc describe command for the network.config/cluster resource.
Procedure
Use the
oc describecommand to view the cluster network configuration:$ oc describe network.config/clusterExample output
Name: cluster Namespace: Labels: <none> Annotations: <none> API Version: config.openshift.io/v1 Kind: Network Metadata: Creation Timestamp: 2024-08-08T11:25:56Z Generation: 3 Resource Version: 29821 UID: 808dd2be-5077-4ff7-b6bb-21b7110126c7 Spec: Cluster Network: Cidr: 10.128.0.0/14 Host Prefix: 23 Network Type: OVNKubernetes Service Network: 172.30.0.0/16 Status Cluster Network: Cidr: 10.128.0.0/14 Host Prefix: 23 Cluster Network MTU: 8951 Network Type: OVNKubernetes Service Network: 172.30.0.0/16 Events: <none>where:
spec- Specifies the field that displays the configured state of the cluster network.
Status- Displays the current state of the cluster network configuration.
5.5.3. Viewing Cluster Network Operator status
You can inspect the status and view the details of the Cluster Network Operator by using the oc describe command.
Procedure
Run the following command to view the status of the Cluster Network Operator:
$ oc describe clusteroperators/network
5.5.4. Enabling IP forwarding globally
From OpenShift Container Platform 4.14 onward, OVN-Kubernetes disables global IP forwarding by default. By setting the Cluster Network Operator gatewayConfig.ipForwarding spec to Global, you can enable cluster-wide forwarding.
Procedure
Backup the existing network configuration by running the following command:
$ oc get network.operator cluster -o yaml > network-config-backup.yamlRun the following command to modify the existing network configuration:
$ oc edit network.operator clusterAdd or update the following block under
specas illustrated in the following example:spec: clusterNetwork: - cidr: 10.128.0.0/14 hostPrefix: 23 serviceNetwork: - 172.30.0.0/16 networkType: OVNKubernetes clusterNetworkMTU: 8900 defaultNetwork: ovnKubernetesConfig: gatewayConfig: ipForwarding: Global- Save and close the file.
After applying the changes, the OpenShift Cluster Network Operator (CNO) applies the update across the cluster. You can monitor the progress by using the following command:
$ oc get clusteroperators networkThe status should eventually report as
Available,Progressing=False, andDegraded=False.Alternatively, you can enable IP forwarding globally by running the following command:
$ oc patch network.operator cluster -p '{"spec":{"defaultNetwork":{"ovnKubernetesConfig":{"gatewayConfig":{"ipForwarding": "Global"}}}}}' --type=mergeNoteThe other valid option for this parameter is
Restrictedin case you want to revert this change.Restrictedis the default and with that setting global IP address forwarding is disabled.
5.5.5. Viewing Cluster Network Operator logs
You can view Cluster Network Operator logs by using the oc logs command.
Procedure
Run the following command to view the logs of the Cluster Network Operator:
$ oc logs --namespace=openshift-network-operator deployment/network-operator
5.5.6. Cluster Network Operator configuration
To manage cluster networking, configure the Cluster Network Operator (CNO) Network custom resource (CR) named cluster so the cluster uses the correct IP ranges and network plugin settings for reliable pod and service connectivity. Some settings and fields are inherited at the time of install.
The CNO configuration inherits the following fields during cluster installation from the Network API in the Network.config.openshift.io API group:
clusterNetwork- IP address pools from which pod IP addresses are allocated.
serviceNetwork- IP address pool for services.
defaultNetwork.type-
Cluster network plugin.
OVNKubernetesis the only supported plugin during installation.
After cluster installation, you can only modify the clusterNetwork IP address range. The default network type can only be changed from OpenShift SDN to OVN-Kubernetes through migration.
You can specify the cluster network plugin configuration for your cluster by setting the fields for the defaultNetwork object in the CNO object named cluster.
5.5.6.1. Cluster Network Operator configuration object
The fields for the Cluster Network Operator (CNO) are described in the following table:
| Field | Type | Description |
|---|---|---|
|
|
|
The name of the CNO object. This name is always |
|
|
| A list specifying the blocks of IP addresses from which pod IP addresses are allocated and the subnet prefix length assigned to each individual node in the cluster. For example: |
|
|
| A block of IP addresses for services. The OpenShift SDN and OVN-Kubernetes network plugins support only a single IP address block for the service network. For example:
This value is ready-only and inherited from the |
|
|
| Configures the network plugin for the cluster network. |
|
|
| The fields for this object specify the kube-proxy configuration. If you are using the OVN-Kubernetes cluster network plugin, the kube-proxy configuration has no effect. |
For a cluster that needs to deploy objects across multiple networks, ensure that you specify the same value for the clusterNetwork.hostPrefix parameter for each network type that is defined in the install-config.yaml file. Setting a different value for each clusterNetwork.hostPrefix parameter can impact the OVN-Kubernetes network plugin, where the plugin cannot effectively route object traffic among different nodes.
5.5.6.2. defaultNetwork object configuration
The values for the defaultNetwork object are defined in the following table:
| Field | Type | Description |
|---|---|---|
|
|
|
Note OpenShift Container Platform uses the OVN-Kubernetes network plugin by default. OpenShift SDN is no longer available as an installation choice for new clusters. |
|
|
| This object is only valid for the OVN-Kubernetes network plugin. |
5.5.6.3. Configuration for the OpenShift SDN network plugin
The following table describes the configuration fields for the OpenShift SDN network plugin:
| Field | Type | Description |
|---|---|---|
|
|
| The network isolation mode for OpenShift SDN. |
|
|
| The maximum transmission unit (MTU) for the VXLAN overlay network. This value is normally configured automatically. |
|
|
|
The port to use for all VXLAN packets. The default value is |
Example OpenShift SDN configuration
defaultNetwork:
type: OpenShiftSDN
openshiftSDNConfig:
mode: NetworkPolicy
mtu: 1450
vxlanPort: 47895.5.6.4. Configuration for the OVN-Kubernetes network plugin
The following table describes the configuration fields for the OVN-Kubernetes network plugin:
| Field | Type | Description |
|---|---|---|
|
|
| The maximum transmission unit (MTU) for the Geneve (Generic Network Virtualization Encapsulation) overlay network. This value is normally configured automatically. |
|
|
| The UDP port for the Geneve overlay network. |
|
|
| An object describing the IPsec mode for the cluster. |
|
|
| Specifies a configuration object for IPv4 settings. |
|
|
| Specifies a configuration object for IPv6 settings. |
|
|
| Specify a configuration object for customizing network policy audit logging. If unset, the defaults audit log settings are used. |
|
|
|
Optional: Specify a configuration object for customizing how egress traffic is sent to the node gateway. Valid values are Note While migrating egress traffic, you can expect some disruption to workloads and service traffic until the Cluster Network Operator (CNO) successfully rolls out the changes. |
| Field | Type | Description |
|---|---|---|
|
| string |
If your existing network infrastructure overlaps with the
The default value is |
|
| string |
If your existing network infrastructure overlaps with the
The default value is |
| Field | Type | Description |
|---|---|---|
|
| string |
If your existing network infrastructure overlaps with the
The default value is |
|
| string |
If your existing network infrastructure overlaps with the
The default value is |
| Field | Type | Description |
|---|---|---|
|
| integer |
The maximum number of messages to generate every second per node. The default value is |
|
| integer |
The maximum size for the audit log in bytes. The default value is |
|
| integer | The maximum number of log files that are retained. |
|
| string | One of the following additional audit log targets:
|
|
| string |
The syslog facility, such as |
| Field | Type | Description |
|---|---|---|
|
|
|
Set this field to
This field has an interaction with the Open vSwitch hardware offloading feature. If you set this field to |
|
|
|
You can control IP forwarding for all traffic on OVN-Kubernetes managed interfaces by using the |
|
|
| Optional: Specify an object to configure the internal OVN-Kubernetes masquerade address for host to service traffic for IPv4 addresses. |
|
|
| Optional: Specify an object to configure the internal OVN-Kubernetes masquerade address for host to service traffic for IPv6 addresses. |
| Field | Type | Description |
|---|---|---|
|
|
|
The masquerade IPv4 addresses that are used internally to enable host to service traffic. The host is configured with these IP addresses as well as the shared gateway bridge interface. The default value is |
| Field | Type | Description |
|---|---|---|
|
|
|
The masquerade IPv6 addresses that are used internally to enable host to service traffic. The host is configured with these IP addresses as well as the shared gateway bridge interface. The default value is |
| Field | Type | Description |
|---|---|---|
|
|
| Specifies the behavior of the IPsec implementation. Must be one of the following values:
|
You can only change the configuration for your cluster network plugin during cluster installation, except for the gatewayConfig field that can be changed at runtime as a postinstallation activity.
Example OVN-Kubernetes configuration with IPSec enabled
defaultNetwork:
type: OVNKubernetes
ovnKubernetesConfig:
mtu: 1400
genevePort: 6081
ipsecConfig:
mode: FullUsing OVNKubernetes can lead to a stack exhaustion problem on IBM Power®.
5.5.6.5. kubeProxyConfig object configuration (OpenShiftSDN container network interface only)
The values for the kubeProxyConfig object are defined in the following table:
| Field | Type | Description |
|---|---|---|
|
|
|
The refresh period for Note
Because of performance improvements introduced in OpenShift Container Platform 4.3 and greater, adjusting the |
|
|
|
The minimum duration before refreshing |
5.5.6.6. Cluster Network Operator example configuration
A complete CNO configuration is specified in the following example:
Example Cluster Network Operator object
apiVersion: operator.openshift.io/v1
kind: Network
metadata:
name: cluster
spec:
clusterNetwork:
- cidr: 10.128.0.0/14
hostPrefix: 23
serviceNetwork:
- 172.30.0.0/16
networkType: OVNKubernetes5.6. DNS Operator in OpenShift Container Platform
In OpenShift Container Platform, the DNS Operator deploys and manages a CoreDNS instance to provide a name resolution service to pods inside the cluster, enables DNS-based Kubernetes Service discovery, and resolves internal cluster.local names.
5.6.1. Checking the status of the DNS Operator
You can check the DNS Operator deployment and Cluster Operator status. The DNS Operator is deployed during installation with a Deployment object.
The DNS Operator implements the dns API from the operator.openshift.io API group. The Operator deploys CoreDNS using a daemon set, creates a service for the daemon set, and configures the kubelet to instruct pods to use the CoreDNS service IP address for name resolution.
Procedure
Use the
oc getcommand to view the deployment status:$ oc get -n openshift-dns-operator deployment/dns-operatorExample output
NAME READY UP-TO-DATE AVAILABLE AGE dns-operator 1/1 1 1 23hUse the
oc getcommand to view the state of the DNS Operator:$ oc get clusteroperator/dnsExample output
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE dns 4.1.15-0.11 True False False 92mAVAILABLE,PROGRESSING, andDEGRADEDprovide information about the status of the Operator.AVAILABLEisTruewhen at least 1 pod from the CoreDNS daemon set reports anAvailablestatus condition, and the DNS service has a cluster IP address.
5.6.2. View the default DNS
View the default DNS resource and cluster DNS settings to verify the DNS configuration or troubleshoot DNS issues.
Every new OpenShift Container Platform installation has a dns.operator named default.
Procedure
Use the
oc describecommand to view the defaultdns:$ oc describe dns.operator/defaultExample output
Name: default Namespace: Labels: <none> Annotations: <none> API Version: operator.openshift.io/v1 Kind: DNS ... Status: Cluster Domain: cluster.local Cluster IP: 172.30.0.10 ...where:
Status.Cluster Domain- Specifiecs the base DNS domain used to construct fully qualified pod and service domain names.
Status.Cluster IP- Specifies the address that pods query for name resolution. The IP is defined as the 10th address in the service CIDR range.
To find the service CIDR range, such as
172.30.0.0/16, of your cluster, use theoc getcommand:$ oc get networks.config/cluster -o jsonpath='{$.status.serviceNetwork}'
5.6.3. Using DNS forwarding
Configure DNS forwarding servers and upstream resolvers for the cluster.
You can use DNS forwarding to override the default forwarding configuration in the /etc/resolv.conf file in the following ways:
-
Specify name servers (
spec.servers) for every zone. If the forwarded zone is the ingress domain managed by OpenShift Container Platform, then the upstream name server must be authorized for the domain. -
Provide a list of upstream DNS servers (
spec.upstreamResolvers). - Change the default forwarding policy.
A DNS forwarding configuration for the default domain can have both the default servers specified in the /etc/resolv.conf file and the upstream DNS servers.
Procedure
Modify the DNS Operator object named
default:$ oc edit dns.operator/defaultAfter you issue the previous command, the Operator creates and updates the config map named
dns-defaultwith additional server configuration blocks based onspec.servers. If none of the servers have a zone that matches the query, then name resolution falls back to the upstream DNS servers.Configuring DNS forwarding
apiVersion: operator.openshift.io/v1 kind: DNS metadata: name: default spec: cache: negativeTTL: 0s positiveTTL: 0s logLevel: Normal nodePlacement: {} operatorLogLevel: Normal servers: - name: example-server zones: - example.com forwardPlugin: policy: Random upstreams: - 1.1.1.1 - 2.2.2.2:5353 upstreamResolvers: policy: Random protocolStrategy: "" transportConfig: {} upstreams: - type: SystemResolvConf - type: Network address: 1.2.3.4 port: 53 status: clusterDomain: cluster.local clusterIP: x.y.z.10 conditions: ...where:
spec.servers.name-
Must comply with the
rfc6335service name syntax. spec.servers.zones-
Must conform to the
rfc1123subdomain syntax. The cluster domaincluster.localis invalid forzones. spec.servers.forwardPlugin.policy-
Specifies the upstream selection policy. Defaults to
Random; allowed values areRoundRobinandSequential. spec.servers.forwardPlugin.upstreams-
Must provide no more than 15
upstreamsentries perforwardPlugin. spec.upstreamResolvers.upstreams-
Specifies an
upstreamResolversto override the default forwarding policy and forward DNS resolution to the specified DNS resolvers (upstream resolvers) for the default domain. You can use this field when you need custom upstream resolvers; otherwise queries use the servers declared in/etc/resolv.conf. spec.upstreamResolvers.policy-
Specifies the upstream selection order. Defaults to
Sequential; allowed values areRandom,RoundRobin, andSequential. spec.upstreamResolvers.protocolStrategy-
Specify
TCPto force the protocol to use for upstream DNS requests, even if the request uses UDP. Valid values areTCPand omitted. When omitted, the platform chooses a default, normally the protocol of the original client request. spec.upstreamResolvers.transportConfig- Specifies the transport type, server name, and optional custom CA or CA bundle to use when forwarding DNS requests to an upstream resolver.
spec.upstreamResolvers.upstreams.type-
Specifies two types of
upstreams:SystemResolvConforNetwork.SystemResolvConfconfigures the upstream to use/etc/resolv.confandNetworkdefines aNetworkresolver. You can specify one or both. spec.upstreamResolvers.upstreams.address-
Specifies a valid IPv4 or IPv6 address when type is
Network. spec.upstreamResolvers.upstreams.port-
Specifies an optional field to provide a port number. Valid values are between
1and65535; defaults to 853 when omitted.
5.6.4. Checking DNS Operator status
You can inspect the status and view the details of the DNS Operator by using the oc describe command.
Procedure
View the status of the DNS Operator:
$ oc describe clusteroperators/dnsThough the messages and spelling might vary in a specific release, the expected status output looks like:
Status: Conditions: Last Transition Time: <date> Message: DNS "default" is available. Reason: AsExpected Status: True Type: Available Last Transition Time: <date> Message: Desired and current number of DNSes are equal Reason: AsExpected Status: False Type: Progressing Last Transition Time: <date> Reason: DNSNotDegraded Status: False Type: Degraded Last Transition Time: <date> Message: DNS default is upgradeable: DNS Operator can be upgraded Reason: DNSUpgradeable Status: True Type: Upgradeable
5.6.5. Viewing DNS Operator logs
You can view DNS Operator logs to troubleshoot DNS issues, verify configuration changes, and monitor activity by using the by using the oc logs command.
Procedure
View the logs of the DNS Operator by running the following command:
$ oc logs -n openshift-dns-operator deployment/dns-operator -c dns-operator
5.6.6. Setting the CoreDNS log level
Set CoreDNS log levels to control the detail of DNS error logging.
Log levels for CoreDNS and the CoreDNS Operator are set by using different methods. You can configure the CoreDNS log level to determine the amount of detail in logged error messages. The valid values for CoreDNS log level are Normal, Debug, and Trace. The default logLevel is Normal.
The CoreDNS error log level is always enabled. The following log level settings report different error responses:
-
logLevel:Normalenables the "errors" class:log . { class error }. -
logLevel:Debugenables the "denial" class:log . { class denial error }. -
logLevel:Traceenables the "all" class:log . { class all }.
Procedure
To set
logLeveltoDebug, enter the following command:$ oc patch dnses.operator.openshift.io/default -p '{"spec":{"logLevel":"Debug"}}' --type=mergeTo set
logLeveltoTrace, enter the following command:$ oc patch dnses.operator.openshift.io/default -p '{"spec":{"logLevel":"Trace"}}' --type=merge
Verification
To ensure the desired log level was set, check the config map:
$ oc get configmap/dns-default -n openshift-dns -o yamlFor example, after setting the
logLeveltoTrace, you should see this stanza in each server block:errors log . { class all }
5.6.7. Viewing the CoreDNS logs
You can view CoreDNS pod logs to troubleshoot DNS issues by using the oc logs command.
Procedure
View the logs of a specific CoreDNS pod by entering the following command:
$ oc -n openshift-dns logs -c dns <core_dns_pod_name>Follow the logs of all CoreDNS pods by entering the following command:
$ oc -n openshift-dns logs -c dns -l dns.operator.openshift.io/daemonset-dns=default -f --max-log-requests=<number>1 -
<number>: Specifies the number of DNS pods to stream logs from. The maximum is 6.
-
5.6.8. Setting the CoreDNS Operator log level
You can configure the Operator log level to quickly track down OpenShift DNS issues.
The valid values for operatorLogLevel are Normal, Debug, and Trace. Trace has the most detailed information. The default operatorlogLevel is Normal. There are seven logging levels for Operator issues: Trace, Debug, Info, Warning, Error, Unrecoverable, and Panic. After the logging level is set, log entries with that severity or anything above it will be logged.
-
operatorLogLevel: "Normal"setslogrus.SetLogLevel("Info"). -
operatorLogLevel: "Debug"setslogrus.SetLogLevel("Debug"). -
operatorLogLevel: "Trace"setslogrus.SetLogLevel("Trace").
Procedure
To set
operatorLogLeveltoDebug, enter the following command:$ oc patch dnses.operator.openshift.io/default -p '{"spec":{"operatorLogLevel":"Debug"}}' --type=mergeTo set
operatorLogLeveltoTrace, enter the following command:$ oc patch dnses.operator.openshift.io/default -p '{"spec":{"operatorLogLevel":"Trace"}}' --type=merge
Verification
To review the resulting change, enter the following command:
$ oc get dnses.operator -A -oyamlYou should see two log level entries. The
operatorLogLevelapplies to OpenShift DNS Operator issues, and thelogLevelapplies to the daemonset of CoreDNS pods:logLevel: Trace operatorLogLevel: DebugTo review the logs for the daemonset, enter the following command:
$ oc logs -n openshift-dns ds/dns-default
5.6.9. Tuning the CoreDNS cache
For CoreDNS, you can configure the maximum duration of both successful or unsuccessful caching, also known respectively as positive or negative caching. Tuning the cache duration of DNS query responses can reduce the load for any upstream DNS resolvers.
Setting TTL fields to low values could lead to an increased load on the cluster, any upstream resolvers, or both.
Procedure
Edit the DNS Operator object named
defaultby running the following command:$ oc edit dns.operator.openshift.io/defaultModify the time-to-live (TTL) caching values:
Configuring DNS caching
apiVersion: operator.openshift.io/v1 kind: DNS metadata: name: default spec: cache: positiveTTL: 1h negativeTTL: 0.5h10mwhere:
spec.cache.positiveTTL-
Specifies a string value that is converted to its respective number of seconds by CoreDNS. If this field is omitted, the value is assumed to be
0sand the cluster uses the internal default value of900sas a fallback. spec.cache.negativeTTL-
Specifies a string value that is converted to its respective number of seconds by CoreDNS. If this field is omitted, the value is assumed to be
0sand the cluster uses the internal default value of30sas a fallback.
Verification
To review the change, look at the config map again by running the following command:
$ oc get configmap/dns-default -n openshift-dns -o yamlVerify that you see entries that look like the following example:
cache 3600 { denial 9984 2400 }
5.6.9.1. Changing the DNS Operator managementState
You can change from the default Managed state to Unmanaged to stop the DNS Operator from managing its resources in order to apply a workaround or test a configuration change.
The DNS Operator manages the CoreDNS component to provide a name resolution service for pods and services in the cluster. The managementState of the DNS Operator is set to Managed by default, which means that the DNS Operator is actively managing its resources. You can change it to Unmanaged, which means the DNS Operator is not managing its resources.
The following are use cases for changing the DNS Operator managementState:
-
You are a developer and want to test a configuration change to see if it fixes an issue in CoreDNS. You can stop the DNS Operator from overwriting the configuration change by setting the
managementStatetoUnmanaged. -
You are a cluster administrator and have reported an issue with CoreDNS, but need to apply a workaround until the issue is fixed. You can set the
managementStatefield of the DNS Operator toUnmanagedto apply the workaround.
You cannot upgrade while the managementState is set to Unmanaged.
Procedure
Change
managementStatetoUnmanagedin the DNS Operator by running the following command:oc patch dns.operator.openshift.io default --type merge --patch '{"spec":{"managementState":"Unmanaged"}}'Review
managementStateof the DNS Operator by using thejsonpathcommand-line JSON parser:$ oc get dns.operator.openshift.io default -ojsonpath='{.spec.managementState}'
5.6.9.2. Controlling DNS pod placement
Control where CoreDNS and node-resolver pods run by using taints, tolerations, and selectors.
The DNS Operator has two daemon sets: one for CoreDNS called dns-default and one for managing the /etc/hosts file called node-resolver.
You can assign and run CoreDNS pods on specified nodes. For example, if the cluster administrator has configured security policies that prohibit communication between pairs of nodes, you can configure CoreDNS pods to run on a restricted set of nodes.
DNS service is available to all pods if the following circumstances are true:
- DNS pods are running on some nodes in the cluster.
- The nodes on which DNS pods are not running have network connectivity to nodes on which DNS pods are running,
The node-resolver daemon set must run on every node host because it adds an entry for the cluster image registry to support pulling images. The node-resolver pods have only one job: to look up the image-registry.openshift-image-registry.svc service’s cluster IP address and add it to /etc/hosts on the node host so that the container runtime can resolve the service name.
As a cluster administrator, you can use a custom node selector to configure the daemon set for CoreDNS to run or not run on certain nodes.
Prerequisites
-
You installed the
ocCLI. -
You are logged in to the cluster as a user with
cluster-adminprivileges. -
Your DNS Operator
managementStateis set toManaged.
Procedure
To allow the daemon set for CoreDNS to run on certain nodes, configure a taint and toleration:
$ oc adm taint nodes <node_name> dns-only=abc:NoExecuteReplace
<node_name>with the actual name of the node.Modify the DNS Operator object named
defaultto include the corresponding toleration by entering the following command:$ oc edit dns.operator/defaultSpecify a taint key and a toleration for the taint:
apiVersion: operator.openshift.io/v1 kind: DNS metadata: name: default spec: nodePlacement: tolerations: - effect: NoExecute key: "dns-only" operator: Equal value: abc tolerationSeconds: 3600
-
If the
keyfield is set todns-only, it can be tolerated indefinitely. The
tolerationSecondsfield is optional.Optional: To specify node placement using a node selector, modify the default DNS Operator:
Edit the DNS Operator object named
defaultto include a node selector:apiVersion: operator.openshift.io/v1 kind: DNS metadata: name: default spec: nodePlacement: nodeSelector: node-role.kubernetes.io/control-plane: ""
-
The
spec.nodePlacement.nodeSelectorfield in the example ensures that the CoreDNS pods run only on control plane nodes.
5.6.9.3. Configuring DNS forwarding with TLS
Configure DNS forwarding with TLS to secure queries to upstream resolvers.
When working in a highly regulated environment, you might need the ability to secure DNS traffic when forwarding requests to upstream resolvers so that you can ensure additional DNS traffic and data privacy.
Be aware that CoreDNS caches forwarded connections for 10 seconds. CoreDNS will hold a TCP connection open for those 10 seconds if no request is issued.
With large clusters, ensure that your DNS server is aware that it might get many new connections to hold open because you can initiate a connection per node. Set up your DNS hierarchy accordingly to avoid performance issues.
Procedure
Modify the DNS Operator object named
default:$ oc edit dns.operator/defaultCluster administrators can configure transport layer security (TLS) for forwarded DNS queries.
Configuring DNS forwarding with TLS
apiVersion: operator.openshift.io/v1 kind: DNS metadata: name: default spec: servers: - name: example_server zones: - example.com forwardPlugin: transportConfig: transport: TLS tls: caBundle: name: mycacert serverName: dnstls.example.com policy: Random upstreams: - 1.1.1.1 - 2.2.2.2:5353 upstreamResolvers: transportConfig: transport: TLS tls: caBundle: name: mycacert serverName: dnstls.example.com upstreams: - type: Network address: 1.2.3.4 port: 53where:
spec.servers.name-
Must comply with the
rfc6335service name syntax. spec.servers.zones-
Must conform to the
rfc1123subdomain syntax. The cluster domain,cluster.local, is invalid forzones. spec.servers.forwardPlugin.transportConfig.transport-
Must be set to
TLSwhen configuring TLS forwarding. spec.servers.forwardPlugin.transportConfig.tls.serverName- Must be set to the server name indication (SNI) server name used to validate the upstream TLS certificate.
spec.servers.forwardPlugin.policy-
Specifies the upstream selection policy. Defaults to
Random; valid values areRoundRobinandSequential. spec.servers.forwardPlugin.upstreams-
Must provide upstream resolvers; maximum 15 entries per
forwardPlugin. spec.upstreamResolvers.upstreams-
Specifies an optional field to override the default policy for the default domain. Use the
Networktype only when TLS is enabled and provide an IP address. If omitted, queries use/etc/resolv.conf. spec.upstreamResolvers.upstreams.address- Must be a valid IPv4 or IPv6 address.
spec.upstreamResolvers.upstreams.portSpecifies an optional field to provide a port number. Valid values are between
1and65535; defaults to 853 when omitted.NoteIf
serversis undefined or invalid, the config map only contains the default server.
Verification
View the config map:
$ oc get configmap/dns-default -n openshift-dns -o yamlSample DNS ConfigMap based on TLS forwarding example
apiVersion: v1 data: Corefile: | example.com:5353 { forward . 1.1.1.1 2.2.2.2:5353 } bar.com:5353 example.com:5353 { forward . 3.3.3.3 4.4.4.4:5454 } .:5353 { errors health kubernetes cluster.local in-addr.arpa ip6.arpa { pods insecure upstream fallthrough in-addr.arpa ip6.arpa } prometheus :9153 forward . /etc/resolv.conf 1.2.3.4:53 { policy Random } cache 30 reload } kind: ConfigMap metadata: labels: dns.operator.openshift.io/owning-dns: default name: dns-default namespace: openshift-dns-
The
data.Corefilekey contains the Corefile configuration for the DNS server. Changes to theforwardPlugintriggers a rolling update of the CoreDNS daemon set.
-
The
5.7. Ingress Operator in OpenShift Container Platform
The Ingress Operator implements the IngressController API and is the component responsible for enabling external access to OpenShift Container Platform cluster services.
5.7.1. OpenShift Container Platform Ingress Operator
When you create your OpenShift Container Platform cluster, pods and services running on the cluster are each allocated their own IP addresses. The IP addresses are accessible to other pods and services running nearby but are not accessible to outside clients.
The Ingress Operator makes it possible for external clients to access your service by deploying and managing one or more HAProxy-based Ingress Controllers to handle routing. You can use the Ingress Operator to route traffic by specifying OpenShift Container Platform Route and Kubernetes Ingress resources. Configurations within the Ingress Controller, such as the ability to define endpointPublishingStrategy type and internal load balancing, provide ways to publish Ingress Controller endpoints.
5.7.2. The Ingress configuration asset
The installation program generates an asset with an Ingress resource in the config.openshift.io API group, cluster-ingress-02-config.yml.
YAML Definition of the Ingress resource
apiVersion: config.openshift.io/v1
kind: Ingress
metadata:
name: cluster
spec:
domain: apps.openshiftdemos.com
The installation program stores this asset in the cluster-ingress-02-config.yml file in the manifests/ directory. This Ingress resource defines the cluster-wide configuration for Ingress. This Ingress configuration is used as follows:
- The Ingress Operator uses the domain from the cluster Ingress configuration as the domain for the default Ingress Controller.
-
The OpenShift API Server Operator uses the domain from the cluster Ingress configuration. This domain is also used when generating a default host for a
Routeresource that does not specify an explicit host.
5.7.3. Ingress Controller configuration parameters
The IngressController custom resource (CR) includes optional configuration parameters that you can configure to meet specific needs for your organization.
| Parameter | Description |
|---|---|
|
|
The
If empty, the default value is |
|
|
|
|
|
For cloud environments, use the
On Google Cloud, AWS, and Azure you can configure the following
If not set, the default value is based on
For most platforms, the
For non-cloud environments, such as a bare-metal platform, use the
If you do not set a value in one of these fields, the default value is based on binding ports specified in the
If you need to update the
|
|
|
The
The secret must contain the following keys and data: *
If not set, a wildcard certificate is automatically generated and used. The certificate is valid for the Ingress Controller The in-use certificate, whether generated or user-specified, is automatically integrated with OpenShift Container Platform built-in OAuth server. |
|
|
|
|
|
|
|
|
If not set, the defaults values are used. Note
The |
|
|
If not set, the default value is based on the
When using the
The minimum TLS version for Ingress Controllers is Note
Ciphers and the minimum TLS version of the configured security profile are reflected in the Important
The Ingress Operator converts the TLS |
|
|
The
The |
|
|
|
|
|
|
|
|
By setting the
By default, the policy is set to
By setting These adjustments are only applied to cleartext, edge-terminated, and re-encrypt routes, and only when using HTTP/1.
For request headers, these adjustments are applied only for routes that have the
|
|
|
|
|
|
|
|
|
For any cookie that you want to capture, the following parameters must be in your
For example: |
|
|
|
|
|
|
|
|
The
|
|
|
The
These connections come from load balancer health probes or web browser speculative connections (preconnect) and can be safely ignored. However, these requests can be caused by network errors, so setting this field to |
5.7.3.1. Ingress Controller TLS security profiles
TLS security profiles provide a way for servers to regulate which ciphers a connecting client can use when connecting to the server.
5.7.3.1.1. Understanding TLS security profiles
You can use a TLS (Transport Layer Security) security profile, as described in this section, to define which TLS ciphers are required by various OpenShift Container Platform components.
The OpenShift Container Platform TLS security profiles are based on Mozilla recommended configurations.
You can specify one of the following TLS security profiles for each component:
| Profile | Description |
|---|---|
|
| This profile is intended for use with legacy clients or libraries. The profile is based on the Old backward compatibility recommended configuration.
The Note For the Ingress Controller, the minimum TLS version is converted from 1.0 to 1.1. |
|
| This profile is the default TLS security profile for the Ingress Controller, kubelet, and control plane. The profile is based on the Intermediate compatibility recommended configuration.
The Note This profile is the recommended configuration for the majority of clients. |
|
| This profile is intended for use with modern clients that have no need for backwards compatibility. This profile is based on the Modern compatibility recommended configuration.
The |
|
| This profile allows you to define the TLS version and ciphers to use. Warning
Use caution when using a |
When using one of the predefined profile types, the effective profile configuration is subject to change between releases. For example, given a specification to use the Intermediate profile deployed on release X.Y.Z, an upgrade to release X.Y.Z+1 might cause a new profile configuration to be applied, resulting in a rollout.
5.7.3.1.2. Configuring the TLS security profile for the Ingress Controller
To configure a TLS security profile for an Ingress Controller, edit the IngressController custom resource (CR) to specify a predefined or custom TLS security profile. If a TLS security profile is not configured, the default value is based on the TLS security profile set for the API server.
Sample IngressController CR that configures the Old TLS security profile
apiVersion: operator.openshift.io/v1
kind: IngressController
...
spec:
tlsSecurityProfile:
old: {}
type: Old
...The TLS security profile defines the minimum TLS version and the TLS ciphers for TLS connections for Ingress Controllers.
You can see the ciphers and the minimum TLS version of the configured TLS security profile in the IngressController custom resource (CR) under Status.Tls Profile and the configured TLS security profile under Spec.Tls Security Profile. For the Custom TLS security profile, the specific ciphers and minimum TLS version are listed under both parameters.
The HAProxy Ingress Controller image supports TLS 1.3 and the Modern profile.
The Ingress Operator also converts the TLS 1.0 of an Old or Custom profile to 1.1.
Prerequisites
-
You have access to the cluster as a user with the
cluster-adminrole.
Procedure
Edit the
IngressControllerCR in theopenshift-ingress-operatorproject to configure the TLS security profile:$ oc edit IngressController default -n openshift-ingress-operatorAdd the
spec.tlsSecurityProfilefield:Sample
IngressControllerCR for aCustomprofileapiVersion: operator.openshift.io/v1 kind: IngressController ... spec: tlsSecurityProfile: type: Custom1 custom:2 ciphers:3 - ECDHE-ECDSA-CHACHA20-POLY1305 - ECDHE-RSA-CHACHA20-POLY1305 - ECDHE-RSA-AES128-GCM-SHA256 - ECDHE-ECDSA-AES128-GCM-SHA256 minTLSVersion: VersionTLS11 ...- Save the file to apply the changes.
Verification
Verify that the profile is set in the
IngressControllerCR:$ oc describe IngressController default -n openshift-ingress-operatorExample output
Name: default Namespace: openshift-ingress-operator Labels: <none> Annotations: <none> API Version: operator.openshift.io/v1 Kind: IngressController ... Spec: ... Tls Security Profile: Custom: Ciphers: ECDHE-ECDSA-CHACHA20-POLY1305 ECDHE-RSA-CHACHA20-POLY1305 ECDHE-RSA-AES128-GCM-SHA256 ECDHE-ECDSA-AES128-GCM-SHA256 Min TLS Version: VersionTLS11 Type: Custom ...
5.7.3.1.3. Configuring mutual TLS authentication
You can configure the Ingress Controller to enable mutual TLS (mTLS) authentication by setting a spec.clientTLS value. The clientTLS value configures the Ingress Controller to verify client certificates. This configuration includes setting a clientCA value, which is a reference to a config map. The config map contains the PEM-encoded CA certificate bundle that is used to verify a client’s certificate. Optionally, you can also configure a list of certificate subject filters.
If the clientCA value specifies an X509v3 certificate revocation list (CRL) distribution point, the Ingress Operator downloads and manages a CRL config map based on the HTTP URI X509v3 CRL Distribution Point specified in each provided certificate. The Ingress Controller uses this config map during mTLS/TLS negotiation. Requests that do not provide valid certificates are rejected.
Prerequisites
-
You have access to the cluster as a user with the
cluster-adminrole. - You have a PEM-encoded CA certificate bundle.
If your CA bundle references a CRL distribution point, you must have also included the end-entity or leaf certificate to the client CA bundle. This certificate must have included an HTTP URI under
CRL Distribution Points, as described in RFC 5280. For example:Issuer: C=US, O=Example Inc, CN=Example Global G2 TLS RSA SHA256 2020 CA1 Subject: SOME SIGNED CERT X509v3 CRL Distribution Points: Full Name: URI:http://crl.example.com/example.crl
Procedure
In the
openshift-confignamespace, create a config map from your CA bundle:$ oc create configmap \ router-ca-certs-default \ --from-file=ca-bundle.pem=client-ca.crt \1 -n openshift-config- 1
- The config map data key must be
ca-bundle.pem, and the data value must be a CA certificate in PEM format.
Edit the
IngressControllerresource in theopenshift-ingress-operatorproject:$ oc edit IngressController default -n openshift-ingress-operatorAdd the
spec.clientTLSfield and subfields to configure mutual TLS:Sample
IngressControllerCR for aclientTLSprofile that specifies filtering patternsapiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: clientTLS: clientCertificatePolicy: Required clientCA: name: router-ca-certs-default allowedSubjectPatterns: - "^/CN=example.com/ST=NC/C=US/O=Security/OU=OpenShift$"Optional, get the Distinguished Name (DN) for
allowedSubjectPatternsby entering the following command.$ openssl x509 -in custom-cert.pem -noout -subjectExample output
subject=C=US, ST=NC, O=Security, OU=OpenShift, CN=example.com
5.7.4. View the default Ingress Controller
The Ingress Operator is a core feature of OpenShift Container Platform and is enabled out of the box.
Every new OpenShift Container Platform installation has an ingresscontroller named default. It can be supplemented with additional Ingress Controllers. If the default ingresscontroller is deleted, the Ingress Operator will automatically recreate it within a minute.
Procedure
View the default Ingress Controller:
$ oc describe --namespace=openshift-ingress-operator ingresscontroller/default
5.7.5. View Ingress Operator status
You can view and inspect the status of your Ingress Operator.
Procedure
View your Ingress Operator status:
$ oc describe clusteroperators/ingress
5.7.6. View Ingress Controller logs
You can view your Ingress Controller logs.
Procedure
View your Ingress Controller logs:
$ oc logs --namespace=openshift-ingress-operator deployments/ingress-operator -c <container_name>
5.7.7. View Ingress Controller status
Your can view the status of a particular Ingress Controller.
Procedure
View the status of an Ingress Controller:
$ oc describe --namespace=openshift-ingress-operator ingresscontroller/<name>
5.7.8. Creating a custom Ingress Controller
As a cluster administrator, you can create a new custom Ingress Controller. Because the default Ingress Controller might change during OpenShift Container Platform updates, creating a custom Ingress Controller can be helpful when maintaining a configuration manually that persists across cluster updates.
This example provides a minimal spec for a custom Ingress Controller. To further customize your custom Ingress Controller, see "Configuring the Ingress Controller".
Prerequisites
-
Install the OpenShift CLI (
oc). -
Log in as a user with
cluster-adminprivileges.
Procedure
Create a YAML file that defines the custom
IngressControllerobject:Example
custom-ingress-controller.yamlfileapiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: <custom_name>1 namespace: openshift-ingress-operator spec: defaultCertificate: name: <custom-ingress-custom-certs>2 replicas: 13 domain: <custom_domain>4 - 1
- Specify the a custom
namefor theIngressControllerobject. - 2
- Specify the name of the secret with the custom wildcard certificate.
- 3
- Minimum replica needs to be ONE
- 4
- Specify the domain to your domain name. The domain specified on the IngressController object and the domain used for the certificate must match. For example, if the domain value is "custom_domain.mycompany.com", then the certificate must have SAN *.custom_domain.mycompany.com (with the
*.added to the domain).
Create the object by running the following command:
$ oc create -f custom-ingress-controller.yaml
5.7.9. Configuring the Ingress Controller
5.7.9.1. Setting a custom default certificate
As an administrator, you can configure an Ingress Controller to use a custom certificate by creating a Secret resource and editing the IngressController custom resource (CR).
Prerequisites
- You must have a certificate/key pair in PEM-encoded files, where the certificate is signed by a trusted certificate authority or by a private trusted certificate authority that you configured in a custom PKI.
Your certificate meets the following requirements:
- The certificate is valid for the ingress domain.
-
The certificate uses the
subjectAltNameextension to specify a wildcard domain, such as*.apps.ocp4.example.com.
You must have an
IngressControllerCR, which includes just having thedefaultIngressControllerCR. You can run the following command to check that you have anIngressControllerCR:$ oc --namespace openshift-ingress-operator get ingresscontrollers
If you have intermediate certificates, they must be included in the tls.crt file of the secret containing a custom default certificate. Order matters when specifying a certificate; list your intermediate certificate(s) after any server certificate(s).
Procedure
The following assumes that the custom certificate and key pair are in the tls.crt and tls.key files in the current working directory. Substitute the actual path names for tls.crt and tls.key. You also may substitute another name for custom-certs-default when creating the Secret resource and referencing it in the IngressController CR.
This action will cause the Ingress Controller to be redeployed, using a rolling deployment strategy.
Create a Secret resource containing the custom certificate in the
openshift-ingressnamespace using thetls.crtandtls.keyfiles.$ oc --namespace openshift-ingress create secret tls custom-certs-default --cert=tls.crt --key=tls.keyUpdate the IngressController CR to reference the new certificate secret:
$ oc patch --type=merge --namespace openshift-ingress-operator ingresscontrollers/default \ --patch '{"spec":{"defaultCertificate":{"name":"custom-certs-default"}}}'Verify the update was effective:
$ echo Q |\ openssl s_client -connect console-openshift-console.apps.<domain>:443 -showcerts 2>/dev/null |\ openssl x509 -noout -subject -issuer -enddatewhere:
<domain>- Specifies the base domain name for your cluster.
Example output
subject=C = US, ST = NC, L = Raleigh, O = RH, OU = OCP4, CN = *.apps.example.com issuer=C = US, ST = NC, L = Raleigh, O = RH, OU = OCP4, CN = example.com notAfter=May 10 08:32:45 2022 GMTipYou can alternatively apply the following YAML to set a custom default certificate:
apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: defaultCertificate: name: custom-certs-defaultThe certificate secret name should match the value used to update the CR.
Once the IngressController CR has been modified, the Ingress Operator updates the Ingress Controller’s deployment to use the custom certificate.
5.7.9.2. Removing a custom default certificate
As an administrator, you can remove a custom certificate that you configured an Ingress Controller to use.
Prerequisites
-
You have access to the cluster as a user with the
cluster-adminrole. -
You have installed the OpenShift CLI (
oc). - You previously configured a custom default certificate for the Ingress Controller.
Procedure
To remove the custom certificate and restore the certificate that ships with OpenShift Container Platform, enter the following command:
$ oc patch -n openshift-ingress-operator ingresscontrollers/default \ --type json -p $'- op: remove\n path: /spec/defaultCertificate'There can be a delay while the cluster reconciles the new certificate configuration.
Verification
To confirm that the original cluster certificate is restored, enter the following command:
$ echo Q | \ openssl s_client -connect console-openshift-console.apps.<domain>:443 -showcerts 2>/dev/null | \ openssl x509 -noout -subject -issuer -enddatewhere:
<domain>- Specifies the base domain name for your cluster.
Example output
subject=CN = *.apps.<domain> issuer=CN = ingress-operator@1620633373 notAfter=May 10 10:44:36 2023 GMT
5.7.9.3. Autoscaling an Ingress Controller
You can automatically scale an Ingress Controller to dynamically meet routing performance or availability requirements. For example, the requirement to increase throughput.
The following procedure provides an example for scaling up the default Ingress Controller.
Prerequisites
-
You have the OpenShift CLI (
oc) installed. -
You have access to an OpenShift Container Platform cluster as a user with the
cluster-adminrole. On VMware vSphere, bare-metal, and Nutanix installer-provisioned infrastructure, scaling up Ingress Controller pods does not improve external traffic performance. To improve performance, ensure that you complete the following prerequisites:
- You manually configured a user-managed load balancer for your cluster.
- You ensured that the load balancer was configured for the cluster nodes that handle incoming traffic from the Ingress Controller.
You installed the Custom Metrics Autoscaler Operator and an associated KEDA Controller.
-
You can install the Operator by using OperatorHub on the web console. After you install the Operator, you can create an instance of
KedaController.
-
You can install the Operator by using OperatorHub on the web console. After you install the Operator, you can create an instance of
Procedure
Create a service account to authenticate with Thanos by running the following command:
$ oc create -n openshift-ingress-operator serviceaccount thanos && oc describe -n openshift-ingress-operator serviceaccount thanosExample output
Name: thanos Namespace: openshift-ingress-operator Labels: <none> Annotations: <none> Image pull secrets: thanos-dockercfg-kfvf2 Mountable secrets: thanos-dockercfg-kfvf2 Tokens: <none> Events: <none>Manually create the service account secret token with the following command:
$ oc apply -f - <<EOF apiVersion: v1 kind: Secret metadata: name: thanos-token namespace: openshift-ingress-operator annotations: kubernetes.io/service-account.name: thanos type: kubernetes.io/service-account-token EOFDefine a
TriggerAuthenticationobject within theopenshift-ingress-operatornamespace by using the service account’s token.Create the
TriggerAuthenticationobject and pass the value of thesecretvariable to theTOKENparameter:$ oc apply -f - <<EOF apiVersion: keda.sh/v1alpha1 kind: TriggerAuthentication metadata: name: keda-trigger-auth-prometheus namespace: openshift-ingress-operator spec: secretTargetRef: - parameter: bearerToken name: thanos-token key: token - parameter: ca name: thanos-token key: ca.crt EOF
Create and apply a role for reading metrics from Thanos:
Create a new role,
thanos-metrics-reader.yaml, that reads metrics from pods and nodes:thanos-metrics-reader.yaml
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: thanos-metrics-reader namespace: openshift-ingress-operator rules: - apiGroups: - "" resources: - pods - nodes verbs: - get - apiGroups: - metrics.k8s.io resources: - pods - nodes verbs: - get - list - watch - apiGroups: - "" resources: - namespaces verbs: - getApply the new role by running the following command:
$ oc apply -f thanos-metrics-reader.yaml
Add the new role to the service account by entering the following commands:
$ oc adm policy -n openshift-ingress-operator add-role-to-user thanos-metrics-reader -z thanos --role-namespace=openshift-ingress-operator$ oc adm policy -n openshift-ingress-operator add-cluster-role-to-user cluster-monitoring-view -z thanosNoteThe argument
add-cluster-role-to-useris only required if you use cross-namespace queries. The following step uses a query from thekube-metricsnamespace which requires this argument.Create a new
ScaledObjectYAML file,ingress-autoscaler.yaml, that targets the default Ingress Controller deployment:Example
ScaledObjectdefinitionapiVersion: keda.sh/v1alpha1 kind: ScaledObject metadata: name: ingress-scaler namespace: openshift-ingress-operator spec: scaleTargetRef:1 apiVersion: operator.openshift.io/v1 kind: IngressController name: default envSourceContainerName: ingress-operator minReplicaCount: 1 maxReplicaCount: 202 cooldownPeriod: 1 pollingInterval: 1 triggers: - type: prometheus metricType: AverageValue metadata: serverAddress: https://thanos-querier.openshift-monitoring.svc.cluster.local:90913 namespace: openshift-ingress-operator4 metricName: 'kube-node-role' threshold: '1' query: 'sum(kube_node_role{role="worker",service="kube-state-metrics"})'5 authModes: "bearer" authenticationRef: name: keda-trigger-auth-prometheus- 1
- The custom resource that you are targeting. In this case, the Ingress Controller.
- 2
- Optional: The maximum number of replicas. If you omit this field, the default maximum is set to 100 replicas.
- 3
- The Thanos service endpoint in the
openshift-monitoringnamespace. - 4
- The Ingress Operator namespace.
- 5
- This expression evaluates to however many worker nodes are present in the deployed cluster.
ImportantIf you are using cross-namespace queries, you must target port 9091 and not port 9092 in the
serverAddressfield. You also must have elevated privileges to read metrics from this port.Apply the custom resource definition by running the following command:
$ oc apply -f ingress-autoscaler.yaml
Verification
Verify that the default Ingress Controller is scaled out to match the value returned by the
kube-state-metricsquery by running the following commands:Use the
grepcommand to search the Ingress Controller YAML file for the number of replicas:$ oc get -n openshift-ingress-operator ingresscontroller/default -o yaml | grep replicas:Get the pods in the
openshift-ingressproject:$ oc get pods -n openshift-ingressExample output
NAME READY STATUS RESTARTS AGE router-default-7b5df44ff-l9pmm 2/2 Running 0 17h router-default-7b5df44ff-s5sl5 2/2 Running 0 3d22h router-default-7b5df44ff-wwsth 2/2 Running 0 66s
5.7.9.4. Scaling an Ingress Controller
Manually scale an Ingress Controller to meeting routing performance or availability requirements such as the requirement to increase throughput. oc commands are used to scale the IngressController resource. The following procedure provides an example for scaling up the default IngressController.
Scaling is not an immediate action, as it takes time to create the desired number of replicas.
Prerequisites
On VMware vSphere, bare-metal, and Nutanix installer-provisioned infrastructure, scaling up Ingress Controller pods does not improve external traffic performance. To improve performance, ensure that you complete the following prerequisites:
- You manually configured a user-managed load balancer for your cluster.
- You ensured that the load balancer was configured for the cluster nodes that handle incoming traffic from the Ingress Controller.
Procedure
View the current number of available replicas for the default
IngressController:$ oc get -n openshift-ingress-operator ingresscontrollers/default -o jsonpath='{$.status.availableReplicas}'Scale the default
IngressControllerto the desired number of replicas by using theoc patchcommand. The following example scales the defaultIngressControllerto 3 replicas.$ oc patch -n openshift-ingress-operator ingresscontroller/default --patch '{"spec":{"replicas": 3}}' --type=mergeVerify that the default
IngressControllerscaled to the number of replicas that you specified:$ oc get -n openshift-ingress-operator ingresscontrollers/default -o jsonpath='{$.status.availableReplicas}'TipYou can alternatively apply the following YAML to scale an Ingress Controller to three replicas:
apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: replicas: 31 - 1
- If you need a different amount of replicas, change the
replicasvalue.
5.7.9.5. Configuring Ingress access logging
You can configure the Ingress Controller to enable access logs. If you have clusters that do not receive much traffic, then you can log to a sidecar. If you have high traffic clusters, to avoid exceeding the capacity of the logging stack or to integrate with a logging infrastructure outside of OpenShift Container Platform, you can forward logs to a custom syslog endpoint. You can also specify the format for access logs.
Container logging is useful to enable access logs on low-traffic clusters when there is no existing Syslog logging infrastructure, or for short-term use while diagnosing problems with the Ingress Controller.
Syslog is needed for high-traffic clusters where access logs could exceed the OpenShift Logging stack’s capacity, or for environments where any logging solution needs to integrate with an existing Syslog logging infrastructure. The Syslog use-cases can overlap.
Prerequisites
-
Log in as a user with
cluster-adminprivileges.
Procedure
For Ingress access logging to a sidecar, complete the following commands:
To enable Ingress access logging to a sidecar, enter the following command:
$ oc patch ingresscontroller default -n openshift-ingress-operator --type=merge \ -p '{"spec":{"logging":{"access":{"destination":{"type":"Container"}}}}}'After you configure the Ingress Controller to log to a sidecar, the Operator creates a container named
logsinside a router pod that exists in theopenshift-ingressnamespace.If you need to disable Ingress access logging, enter the following command that does not specify any values for
spec.logging:$ oc patch ingresscontroller default -n openshift-ingress-operator --type=json \ -p='[{"op": "remove", "path": "/spec/logging"}]'To stream the access logs and system events from the OpenShift Container Platform Ingress Controller, enter the following command:
$ oc -n openshift-ingress logs deployment.apps/router-default -c logsExample output
2020-05-11T19:11:50.135710+00:00 router-default-57dfc6cd95-bpmk6 router-default-57dfc6cd95-bpmk6 haproxy[108]: 174.19.21.82:39654 [11/May/2020:19:11:50.133] public be_http:hello-openshift:hello-openshift/pod:hello-openshift:hello-openshift:10.128.2.12:8080 0/0/1/0/1 200 142 - - --NI 1/1/0/0/0 0/0 "GET / HTTP/1.1"
To enable logging to an external Syslog server, enter the following command. Use this option if you need to forward logs to a centralized logging solution such as Splunk, Rsyslog, or Logstash.
$ oc patch ingresscontroller default -n openshift-ingress-operator --type=merge \ -p '{"spec":{"logging":{"access":{"destination":{"type":"Syslog","syslog":{"address":"1.2.3.4","port":514,"maxLenght":1024}}}}}}'-
Replace
1.2.3.4with the destination IP address of your logging server. Syslog does not support a DNS hostname value. -
Replace
514with the UDP destination port of your logging server. -
Replace
1024with the maximum length of a log message in bytes that you want to set for log messages.
-
Replace
To customize the log format, append an HAProxy-compatible log string to the following command. The string determines what information gets captured in the log format, such as a client IP address.
$ oc patch ingresscontroller default -n openshift-ingress-operator --type=merge \ -p '{"spec":{"logging":{"access":{"httpLogFormat":"%ci:%cp [%t] %ft %b/%s %B %bq %HM %HU %HV"}}}}'NoteFor a list of HAProxy log variable descriptions, see Custom log format in the upstream HAProxy documentation.
To capture custom HTTP headers or response headers in your logs, enter the following command. Consider this option if you need to track an
X-Forwarded-Forheader or custom application IDs in the Ingress and application logs.$ oc patch ingresscontroller default -n openshift-ingress-operator --type=merge -p '{"spec":{"logging":{"access":{"httpCaptureHeaders":{"request":[{"name":"User-Agent","maxLength": 1024}],"response":[{"name":"Content-Type","maxLength": 1024}]}}}}}'To configure a log empty requests policy, enter the following command and set the
logEmptyRequestsparameter toLog. By default, HAProxy might not log empty requests or health checks, so you must manually enable this feature. To disable the feature, set thelogEmptyRequestsparameter toIgnore.$ oc patch ingresscontroller default -n openshift-ingress-operator --type=merge -p '{"spec":{"logging":{"access":{"logEmptyRequests":"Ignore"}}}}'
5.7.9.6. Setting Ingress Controller thread count
A cluster administrator can set the thread count to increase the amount of incoming connections a cluster can handle. You can patch an existing Ingress Controller to increase the amount of threads.
Prerequisites
- The following assumes that you already created an Ingress Controller.
Procedure
Update the Ingress Controller to increase the number of threads:
$ oc -n openshift-ingress-operator patch ingresscontroller/default --type=merge -p '{"spec":{"tuningOptions": {"threadCount": 8}}}'NoteIf you have a node that is capable of running large amounts of resources, you can configure
spec.nodePlacement.nodeSelectorwith labels that match the capacity of the intended node, and configurespec.tuningOptions.threadCountto an appropriately high value.
5.7.9.7. Configuring an Ingress Controller to use an internal load balancer
When creating an Ingress Controller on cloud platforms, the Ingress Controller is published by a public cloud load balancer by default. As an administrator, you can create an Ingress Controller that uses an internal cloud load balancer.
If your cloud provider is Microsoft Azure, you must have at least one public load balancer that points to your nodes. If you do not, all of your nodes will lose egress connectivity to the internet.
If you want to change the scope for an IngressController, you can change the .spec.endpointPublishingStrategy.loadBalancer.scope parameter after the custom resource (CR) is created.
Figure 5.2. Diagram of LoadBalancer
The preceding graphic shows the following concepts pertaining to OpenShift Container Platform Ingress LoadBalancerService endpoint publishing strategy:
- You can load balance externally, using the cloud provider load balancer, or internally, using the OpenShift Ingress Controller Load Balancer.
- You can use the single IP address of the load balancer and more familiar ports, such as 8080 and 4200 as shown on the cluster depicted in the graphic.
- Traffic from the external load balancer is directed at the pods, and managed by the load balancer, as depicted in the instance of a down node. See the Kubernetes Services documentation for implementation details.
Prerequisites
-
Install the OpenShift CLI (
oc). -
Log in as a user with
cluster-adminprivileges.
Procedure
Create an
IngressControllercustom resource (CR) in a file named<name>-ingress-controller.yaml, such as in the following example:apiVersion: operator.openshift.io/v1 kind: IngressController metadata: namespace: openshift-ingress-operator name: <name>1 spec: domain: <domain>2 endpointPublishingStrategy: type: LoadBalancerService loadBalancer: scope: Internal3 Create the Ingress Controller defined in the previous step by running the following command:
$ oc create -f <name>-ingress-controller.yaml1 - 1
- Replace
<name>with the name of theIngressControllerobject.
Optional: Confirm that the Ingress Controller was created by running the following command:
$ oc --all-namespaces=true get ingresscontrollers
5.7.9.8. Configuring global access for an Ingress Controller on Google Cloud
An Ingress Controller created on Google Cloud with an internal load balancer generates an internal IP address for the service. A cluster administrator can specify the global access option, which enables clients in any region within the same VPC network and compute region as the load balancer, to reach the workloads running on your cluster.
For more information, see the Google Cloud documentation for global access.
Prerequisites
- You deployed an OpenShift Container Platform cluster on Google Cloud infrastructure.
- You configured an Ingress Controller to use an internal load balancer.
-
You installed the OpenShift CLI (
oc).
Procedure
Configure the Ingress Controller resource to allow global access.
NoteYou can also create an Ingress Controller and specify the global access option.
Configure the Ingress Controller resource:
$ oc -n openshift-ingress-operator edit ingresscontroller/defaultEdit the YAML file:
Sample
clientAccessconfiguration toGlobalspec: endpointPublishingStrategy: loadBalancer: providerParameters: gcp: clientAccess: Global1 type: GCP scope: Internal type: LoadBalancerService- 1
- Set
gcp.clientAccesstoGlobal.
- Save the file to apply the changes.
Run the following command to verify that the service allows global access:
$ oc -n openshift-ingress edit svc/router-default -o yamlThe output shows that global access is enabled for Google Cloud with the annotation,
networking.gke.io/internal-load-balancer-allow-global-access.
5.7.9.9. Setting the Ingress Controller health check interval
A cluster administrator can set the health check interval to define how long the router waits between two consecutive health checks. This value is applied globally as a default for all routes. The default value is 5 seconds.
Prerequisites
- The following assumes that you already created an Ingress Controller.
Procedure
Update the Ingress Controller to change the interval between back end health checks:
$ oc -n openshift-ingress-operator patch ingresscontroller/default --type=merge -p '{"spec":{"tuningOptions": {"healthCheckInterval": "8s"}}}'NoteTo override the
healthCheckIntervalfor a single route, use the route annotationrouter.openshift.io/haproxy.health.check.interval
5.7.9.10. Configuring the default Ingress Controller for your cluster to be internal
You can configure the default Ingress Controller for your cluster to be internal by deleting and recreating it.
If your cloud provider is Microsoft Azure, you must have at least one public load balancer that points to your nodes. If you do not, all of your nodes will lose egress connectivity to the internet.
If you want to change the scope for an IngressController, you can change the .spec.endpointPublishingStrategy.loadBalancer.scope parameter after the custom resource (CR) is created.
Prerequisites
-
Install the OpenShift CLI (
oc). -
Log in as a user with
cluster-adminprivileges.
Procedure
Configure the
defaultIngress Controller for your cluster to be internal by deleting and recreating it.$ oc replace --force --wait --filename - <<EOF apiVersion: operator.openshift.io/v1 kind: IngressController metadata: namespace: openshift-ingress-operator name: default spec: endpointPublishingStrategy: type: LoadBalancerService loadBalancer: scope: Internal EOF
5.7.9.11. Configuring the route admission policy
Administrators and application developers can run applications in multiple namespaces with the same domain name. This is for organizations where multiple teams develop microservices that are exposed on the same hostname.
Allowing claims across namespaces should only be enabled for clusters with trust between namespaces, otherwise a malicious user could take over a hostname. For this reason, the default admission policy disallows hostname claims across namespaces.
Prerequisites
- Cluster administrator privileges.
Procedure
Edit the
.spec.routeAdmissionfield of theingresscontrollerresource variable using the following command:$ oc -n openshift-ingress-operator patch ingresscontroller/default --patch '{"spec":{"routeAdmission":{"namespaceOwnership":"InterNamespaceAllowed"}}}' --type=mergeSample Ingress Controller configuration
spec: routeAdmission: namespaceOwnership: InterNamespaceAllowed ...TipYou can alternatively apply the following YAML to configure the route admission policy:
apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: routeAdmission: namespaceOwnership: InterNamespaceAllowed
5.7.9.12. Using wildcard routes
The HAProxy Ingress Controller has support for wildcard routes. The Ingress Operator uses wildcardPolicy to configure the ROUTER_ALLOW_WILDCARD_ROUTES environment variable of the Ingress Controller.
The default behavior of the Ingress Controller is to admit routes with a wildcard policy of None, which is backwards compatible with existing IngressController resources.
Procedure
Configure the wildcard policy.
Use the following command to edit the
IngressControllerresource:$ oc edit IngressControllerUnder
spec, set thewildcardPolicyfield toWildcardsDisallowedorWildcardsAllowed:spec: routeAdmission: wildcardPolicy: WildcardsDisallowed # or WildcardsAllowed
5.7.9.13. HTTP header configuration
OpenShift Container Platform provides different methods for working with HTTP headers. When setting or deleting headers, you can use specific fields in the Ingress Controller or an individual route to modify request and response headers. You can also set certain headers by using route annotations. The various ways of configuring headers can present challenges when working together.
You can only set or delete headers within an IngressController or Route CR, you cannot append them. If an HTTP header is set with a value, that value must be complete and not require appending in the future. In situations where it makes sense to append a header, such as the X-Forwarded-For header, use the spec.httpHeaders.forwardedHeaderPolicy field, instead of spec.httpHeaders.actions.
5.7.9.13.1. Order of precedence
When the same HTTP header is modified both in the Ingress Controller and in a route, HAProxy prioritizes the actions in certain ways depending on whether it is a request or response header.
- For HTTP response headers, actions specified in the Ingress Controller are executed after the actions specified in a route. This means that the actions specified in the Ingress Controller take precedence.
- For HTTP request headers, actions specified in a route are executed after the actions specified in the Ingress Controller. This means that the actions specified in the route take precedence.
For example, a cluster administrator sets the X-Frame-Options response header with the value DENY in the Ingress Controller using the following configuration:
Example IngressController spec
apiVersion: operator.openshift.io/v1
kind: IngressController
# ...
spec:
httpHeaders:
actions:
response:
- name: X-Frame-Options
action:
type: Set
set:
value: DENY
A route owner sets the same response header that the cluster administrator set in the Ingress Controller, but with the value SAMEORIGIN using the following configuration:
Example Route spec
apiVersion: route.openshift.io/v1
kind: Route
# ...
spec:
httpHeaders:
actions:
response:
- name: X-Frame-Options
action:
type: Set
set:
value: SAMEORIGIN
When both the IngressController spec and Route spec are configuring the X-Frame-Options response header, then the value set for this header at the global level in the Ingress Controller takes precedence, even if a specific route allows frames. For a request header, the Route spec value overrides the IngressController spec value.
This prioritization occurs because the haproxy.config file uses the following logic, where the Ingress Controller is considered the front end and individual routes are considered the back end. The header value DENY applied to the front end configurations overrides the same header with the value SAMEORIGIN that is set in the back end:
frontend public
http-response set-header X-Frame-Options 'DENY'
frontend fe_sni
http-response set-header X-Frame-Options 'DENY'
frontend fe_no_sni
http-response set-header X-Frame-Options 'DENY'
backend be_secure:openshift-monitoring:alertmanager-main
http-response set-header X-Frame-Options 'SAMEORIGIN'Additionally, any actions defined in either the Ingress Controller or a route override values set using route annotations.
5.7.9.13.2. Special case headers
The following headers are either prevented entirely from being set or deleted, or allowed under specific circumstances:
| Header name | Configurable using IngressController spec | Configurable using Route spec | Reason for disallowment | Configurable using another method |
|---|---|---|---|---|
|
| No | No |
The | No |
|
| No | Yes |
When the | No |
|
| No | No |
The |
Yes: the |
|
| No | No | The cookies that HAProxy sets are used for session tracking to map client connections to particular back-end servers. Allowing these headers to be set could interfere with HAProxy’s session affinity and restrict HAProxy’s ownership of a cookie. | Yes:
|
5.7.9.14. Setting or deleting HTTP request and response headers in an Ingress Controller
You can set or delete certain HTTP request and response headers for compliance purposes or other reasons. You can set or delete these headers either for all routes served by an Ingress Controller or for specific routes.
For example, you might want to migrate an application running on your cluster to use mutual TLS, which requires that your application checks for an X-Forwarded-Client-Cert request header, but the OpenShift Container Platform default Ingress Controller provides an X-SSL-Client-Der request header.
The following procedure modifies the Ingress Controller to set the X-Forwarded-Client-Cert request header, and delete the X-SSL-Client-Der request header.
Prerequisites
-
You have installed the OpenShift CLI (
oc). -
You have access to an OpenShift Container Platform cluster as a user with the
cluster-adminrole.
Procedure
Edit the Ingress Controller resource:
$ oc -n openshift-ingress-operator edit ingresscontroller/defaultReplace the X-SSL-Client-Der HTTP request header with the X-Forwarded-Client-Cert HTTP request header:
apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: httpHeaders: actions:1 request:2 - name: X-Forwarded-Client-Cert3 action: type: Set4 set: value: "%{+Q}[ssl_c_der,base64]"5 - name: X-SSL-Client-Der action: type: Delete- 1
- The list of actions you want to perform on the HTTP headers.
- 2
- The type of header you want to change. In this case, a request header.
- 3
- The name of the header you want to change. For a list of available headers you can set or delete, see HTTP header configuration.
- 4
- The type of action being taken on the header. This field can have the value
SetorDelete. - 5
- When setting HTTP headers, you must provide a
value. The value can be a string from a list of available directives for that header, for exampleDENY, or it can be a dynamic value that will be interpreted using HAProxy’s dynamic value syntax. In this case, a dynamic value is added.
NoteFor setting dynamic header values for HTTP responses, allowed sample fetchers are
res.hdrandssl_c_der. For setting dynamic header values for HTTP requests, allowed sample fetchers arereq.hdrandssl_c_der. Both request and response dynamic values can use thelowerandbase64converters.- Save the file to apply the changes.
5.7.9.15. Using X-Forwarded headers
You configure the HAProxy Ingress Controller to specify a policy for how to handle HTTP headers including Forwarded and X-Forwarded-For. The Ingress Operator uses the HTTPHeaders field to configure the ROUTER_SET_FORWARDED_HEADERS environment variable of the Ingress Controller.
Procedure
Configure the
HTTPHeadersfield for the Ingress Controller.Use the following command to edit the
IngressControllerresource:$ oc edit IngressControllerUnder
spec, set theHTTPHeaderspolicy field toAppend,Replace,IfNone, orNever:apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: httpHeaders: forwardedHeaderPolicy: Append
5.7.9.15.1. Example use cases
As a cluster administrator, you can:
Configure an external proxy that injects the
X-Forwarded-Forheader into each request before forwarding it to an Ingress Controller.To configure the Ingress Controller to pass the header through unmodified, you specify the
neverpolicy. The Ingress Controller then never sets the headers, and applications receive only the headers that the external proxy provides.Configure the Ingress Controller to pass the
X-Forwarded-Forheader that your external proxy sets on external cluster requests through unmodified.To configure the Ingress Controller to set the
X-Forwarded-Forheader on internal cluster requests, which do not go through the external proxy, specify theif-nonepolicy. If an HTTP request already has the header set through the external proxy, then the Ingress Controller preserves it. If the header is absent because the request did not come through the proxy, then the Ingress Controller adds the header.
As an application developer, you can:
Configure an application-specific external proxy that injects the
X-Forwarded-Forheader.To configure an Ingress Controller to pass the header through unmodified for an application’s Route, without affecting the policy for other Routes, add an annotation
haproxy.router.openshift.io/set-forwarded-headers: if-noneorhaproxy.router.openshift.io/set-forwarded-headers: neveron the Route for the application.NoteYou can set the
haproxy.router.openshift.io/set-forwarded-headersannotation on a per route basis, independent from the globally set value for the Ingress Controller.
5.7.9.16. Enabling and disabling HTTP/2 on Ingress Controllers
You can enable or disable transparent end-to-end HTTP/2 connectivity in HAProxy. This allows application owners to make use of HTTP/2 protocol capabilities, including single connection, header compression, binary streams, and more.
You can enable or disable HTTP/2 connectivity for an individual Ingress Controller or for the entire cluster.
To enable the use of HTTP/2 for the connection from the client to HAProxy, a route must specify a custom certificate. A route that uses the default certificate cannot use HTTP/2. This restriction is necessary to avoid problems from connection coalescing, where the client re-uses a connection for different routes that use the same certificate.
The connection from HAProxy to the application pod can use HTTP/2 only for re-encrypt routes and not for edge-terminated or insecure routes. This restriction is because HAProxy uses Application-Level Protocol Negotiation (ALPN), which is a TLS extension, to negotiate the use of HTTP/2 with the back-end. The implication is that end-to-end HTTP/2 is possible with passthrough and re-encrypt and not with edge-terminated routes.
You can use HTTP/2 with an insecure route whether the Ingress Controller has HTTP/2 enabled or disabled.
For non-passthrough routes, the Ingress Controller negotiates its connection to the application independently of the connection from the client. This means a client may connect to the Ingress Controller and negotiate HTTP/1.1, and the Ingress Controller might then connect to the application, negotiate HTTP/2, and forward the request from the client HTTP/1.1 connection using the HTTP/2 connection to the application. This poses a problem if the client subsequently tries to upgrade its connection from HTTP/1.1 to the WebSocket protocol, because the Ingress Controller cannot forward WebSocket to HTTP/2 and cannot upgrade its HTTP/2 connection to WebSocket. Consequently, if you have an application that is intended to accept WebSocket connections, it must not allow negotiating the HTTP/2 protocol or else clients will fail to upgrade to the WebSocket protocol.
5.7.9.16.1. Enabling HTTP/2
You can enable HTTP/2 on a specific Ingress Controller, or you can enable HTTP/2 for the entire cluster.
Procedure
To enable HTTP/2 on a specific Ingress Controller, enter the
oc annotatecommand:$ oc -n openshift-ingress-operator annotate ingresscontrollers/<ingresscontroller_name> ingress.operator.openshift.io/default-enable-http2=true1 - 1
- Replace
<ingresscontroller_name>with the name of an Ingress Controller to enable HTTP/2.
To enable HTTP/2 for the entire cluster, enter the
oc annotatecommand:$ oc annotate ingresses.config/cluster ingress.operator.openshift.io/default-enable-http2=true
Alternatively, you can apply the following YAML code to enable HTTP/2:
apiVersion: config.openshift.io/v1
kind: Ingress
metadata:
name: cluster
annotations:
ingress.operator.openshift.io/default-enable-http2: "true"5.7.9.16.2. Disabling HTTP/2
You can disable HTTP/2 on a specific Ingress Controller, or you can disable HTTP/2 for the entire cluster.
Procedure
To disable HTTP/2 on a specific Ingress Controller, enter the
oc annotatecommand:$ oc -n openshift-ingress-operator annotate ingresscontrollers/<ingresscontroller_name> ingress.operator.openshift.io/default-enable-http2=false1 - 1
- Replace
<ingresscontroller_name>with the name of an Ingress Controller to disable HTTP/2.
To disable HTTP/2 for the entire cluster, enter the
oc annotatecommand:$ oc annotate ingresses.config/cluster ingress.operator.openshift.io/default-enable-http2=false
Alternatively, you can apply the following YAML code to disable HTTP/2:
apiVersion: config.openshift.io/v1
kind: Ingress
metadata:
name: cluster
annotations:
ingress.operator.openshift.io/default-enable-http2: "false"5.7.9.17. Configuring the PROXY protocol for an Ingress Controller
A cluster administrator can configure the PROXY protocol when an Ingress Controller uses either the HostNetwork, NodePortService, or Private endpoint publishing strategy types. The PROXY protocol enables the load balancer to preserve the original client addresses for connections that the Ingress Controller receives. The original client addresses are useful for logging, filtering, and injecting HTTP headers. In the default configuration, the connections that the Ingress Controller receives only contain the source address that is associated with the load balancer.
The default Ingress Controller with installer-provisioned clusters on non-cloud platforms that use a Keepalived Ingress Virtual IP (VIP) do not support the PROXY protocol.
The PROXY protocol enables the load balancer to preserve the original client addresses for connections that the Ingress Controller receives. The original client addresses are useful for logging, filtering, and injecting HTTP headers. In the default configuration, the connections that the Ingress Controller receives contain only the source IP address that is associated with the load balancer.
For a passthrough route configuration, servers in OpenShift Container Platform clusters cannot observe the original client source IP address. If you need to know the original client source IP address, configure Ingress access logging for your Ingress Controller so that you can view the client source IP addresses.
For re-encrypt and edge routes, the OpenShift Container Platform router sets the Forwarded and X-Forwarded-For headers so that application workloads check the client source IP address.
For more information about Ingress access logging, see "Configuring Ingress access logging".
Configuring the PROXY protocol for an Ingress Controller is not supported when using the LoadBalancerService endpoint publishing strategy type. This restriction is because when OpenShift Container Platform runs in a cloud platform, and an Ingress Controller specifies that a service load balancer should be used, the Ingress Operator configures the load balancer service and enables the PROXY protocol based on the platform requirement for preserving source addresses.
You must configure both OpenShift Container Platform and the external load balancer to use either the PROXY protocol or TCP.
This feature is not supported in cloud deployments. This restriction is because when OpenShift Container Platform runs in a cloud platform, and an Ingress Controller specifies that a service load balancer should be used, the Ingress Operator configures the load balancer service and enables the PROXY protocol based on the platform requirement for preserving source addresses.
You must configure both OpenShift Container Platform and the external load balancer to either use the PROXY protocol or to use Transmission Control Protocol (TCP).
Prerequisites
- You created an Ingress Controller.
Procedure
Edit the Ingress Controller resource by entering the following command in your CLI:
$ oc -n openshift-ingress-operator edit ingresscontroller/defaultSet the PROXY configuration:
If your Ingress Controller uses the
HostNetworkendpoint publishing strategy type, set thespec.endpointPublishingStrategy.hostNetwork.protocolsubfield toPROXY:Sample
hostNetworkconfiguration toPROXY# ... spec: endpointPublishingStrategy: hostNetwork: protocol: PROXY type: HostNetwork # ...If your Ingress Controller uses the
NodePortServiceendpoint publishing strategy type, set thespec.endpointPublishingStrategy.nodePort.protocolsubfield toPROXY:Sample
nodePortconfiguration toPROXY# ... spec: endpointPublishingStrategy: nodePort: protocol: PROXY type: NodePortService # ...If your Ingress Controller uses the
Privateendpoint publishing strategy type, set thespec.endpointPublishingStrategy.private.protocolsubfield toPROXY:Sample
privateconfiguration toPROXY# ... spec: endpointPublishingStrategy: private: protocol: PROXY type: Private # ...
5.7.9.18. Specifying an alternative cluster domain using the appsDomain option
As a cluster administrator, you can specify an alternative to the default cluster domain for user-created routes by configuring the appsDomain field. The appsDomain field is an optional domain for OpenShift Container Platform to use instead of the default, which is specified in the domain field. If you specify an alternative domain, it overrides the default cluster domain for the purpose of determining the default host for a new route.
For example, you can use the DNS domain for your company as the default domain for routes and ingresses for applications running on your cluster.
Prerequisites
- You deployed an OpenShift Container Platform cluster.
-
You installed the
occommand-line interface.
Procedure
Configure the
appsDomainfield by specifying an alternative default domain for user-created routes.Edit the ingress
clusterresource:$ oc edit ingresses.config/cluster -o yamlEdit the YAML file:
Sample
appsDomainconfiguration totest.example.comapiVersion: config.openshift.io/v1 kind: Ingress metadata: name: cluster spec: domain: apps.example.com1 appsDomain: <test.example.com>2
Verify that an existing route contains the domain name specified in the
appsDomainfield by exposing the route and verifying the route domain change:NoteWait for the
openshift-apiserverfinish rolling updates before exposing the route.Expose the route by entering the following command. The command outputs
route.route.openshift.io/hello-openshift exposedto designate exposure of the route.$ oc expose service hello-openshiftGet a list of routes by running the following command:
$ oc get routesExample output
NAME HOST/PORT PATH SERVICES PORT TERMINATION WILDCARD hello-openshift hello_openshift-<my_project>.test.example.com hello-openshift 8080-tcp None
5.7.9.19. Converting HTTP header case
HAProxy lowercases HTTP header names by default; for example, changing Host: xyz.com to host: xyz.com. If legacy applications are sensitive to the capitalization of HTTP header names, use the Ingress Controller spec.httpHeaders.headerNameCaseAdjustments API field for a solution to accommodate legacy applications until they can be fixed.
OpenShift Container Platform includes HAProxy 2.8. If you want to update to this version of the web-based load balancer, ensure that you add the spec.httpHeaders.headerNameCaseAdjustments section to your cluster’s configuration file.
As a cluster administrator, you can convert the HTTP header case by entering the oc patch command or by setting the HeaderNameCaseAdjustments field in the Ingress Controller YAML file.
Prerequisites
-
You have installed the OpenShift CLI (
oc). -
You have access to the cluster as a user with the
cluster-adminrole.
Procedure
Capitalize an HTTP header by using the
oc patchcommand.Change the HTTP header from
hosttoHostby running the following command:$ oc -n openshift-ingress-operator patch ingresscontrollers/default --type=merge --patch='{"spec":{"httpHeaders":{"headerNameCaseAdjustments":["Host"]}}}'Create a
Routeresource YAML file so that the annotation can be applied to the application.Example of a route named
my-applicationapiVersion: route.openshift.io/v1 kind: Route metadata: annotations: haproxy.router.openshift.io/h1-adjust-case: true1 name: <application_name> namespace: <application_name> # ...- 1
- Set
haproxy.router.openshift.io/h1-adjust-caseso that the Ingress Controller can adjust thehostrequest header as specified.
Specify adjustments by configuring the
HeaderNameCaseAdjustmentsfield in the Ingress Controller YAML configuration file.The following example Ingress Controller YAML file adjusts the
hostheader toHostfor HTTP/1 requests to appropriately annotated routes:Example Ingress Controller YAML
apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: httpHeaders: headerNameCaseAdjustments: - HostThe following example route enables HTTP response header name case adjustments by using the
haproxy.router.openshift.io/h1-adjust-caseannotation:Example route YAML
apiVersion: route.openshift.io/v1 kind: Route metadata: annotations: haproxy.router.openshift.io/h1-adjust-case: true1 name: my-application namespace: my-application spec: to: kind: Service name: my-application- 1
- Set
haproxy.router.openshift.io/h1-adjust-caseto true.
5.7.9.20. Using router compression
You configure the HAProxy Ingress Controller to specify router compression globally for specific MIME types. You can use the mimeTypes variable to define the formats of MIME types to which compression is applied. The types are: application, image, message, multipart, text, video, or a custom type prefaced by "X-". To see the full notation for MIME types and subtypes, see RFC1341.
Memory allocated for compression can affect the max connections. Additionally, compression of large buffers can cause latency, like heavy regex or long lists of regex.
Not all MIME types benefit from compression, but HAProxy still uses resources to try to compress if instructed to. Generally, text formats, such as html, css, and js, formats benefit from compression, but formats that are already compressed, such as image, audio, and video, benefit little in exchange for the time and resources spent on compression.
Procedure
Configure the
httpCompressionfield for the Ingress Controller.Use the following command to edit the
IngressControllerresource:$ oc edit -n openshift-ingress-operator ingresscontrollers/defaultUnder
spec, set thehttpCompressionpolicy field tomimeTypesand specify a list of MIME types that should have compression applied:apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: httpCompression: mimeTypes: - "text/html" - "text/css; charset=utf-8" - "application/json" ...
5.7.9.21. Exposing router metrics
You can expose the HAProxy router metrics by default in Prometheus format on the default stats port, 1936. The external metrics collection and aggregation systems such as Prometheus can access the HAProxy router metrics. You can view the HAProxy router metrics in a browser in the HTML and comma separated values (CSV) format.
Prerequisites
- You configured your firewall to access the default stats port, 1936.
Procedure
Get the router pod name by running the following command:
$ oc get pods -n openshift-ingressExample output
NAME READY STATUS RESTARTS AGE router-default-76bfffb66c-46qwp 1/1 Running 0 11hGet the router’s username and password, which the router pod stores in the
/var/lib/haproxy/conf/metrics-auth/statsUsernameand/var/lib/haproxy/conf/metrics-auth/statsPasswordfiles:Get the username by running the following command:
$ oc rsh <router_pod_name> cat metrics-auth/statsUsernameGet the password by running the following command:
$ oc rsh <router_pod_name> cat metrics-auth/statsPassword
Get the router IP and metrics certificates by running the following command:
$ oc describe pod <router_pod>Get the raw statistics in Prometheus format by running the following command:
$ curl -u <user>:<password> http://<router_IP>:<stats_port>/metricsAccess the metrics securely by running the following command:
$ curl -u user:password https://<router_IP>:<stats_port>/metrics -kAccess the default stats port, 1936, by running the following command:
$ curl -u <user>:<password> http://<router_IP>:<stats_port>/metricsExample 5.1. Example output
... # HELP haproxy_backend_connections_total Total number of connections. # TYPE haproxy_backend_connections_total gauge haproxy_backend_connections_total{backend="http",namespace="default",route="hello-route"} 0 haproxy_backend_connections_total{backend="http",namespace="default",route="hello-route-alt"} 0 haproxy_backend_connections_total{backend="http",namespace="default",route="hello-route01"} 0 ... # HELP haproxy_exporter_server_threshold Number of servers tracked and the current threshold value. # TYPE haproxy_exporter_server_threshold gauge haproxy_exporter_server_threshold{type="current"} 11 haproxy_exporter_server_threshold{type="limit"} 500 ... # HELP haproxy_frontend_bytes_in_total Current total of incoming bytes. # TYPE haproxy_frontend_bytes_in_total gauge haproxy_frontend_bytes_in_total{frontend="fe_no_sni"} 0 haproxy_frontend_bytes_in_total{frontend="fe_sni"} 0 haproxy_frontend_bytes_in_total{frontend="public"} 119070 ... # HELP haproxy_server_bytes_in_total Current total of incoming bytes. # TYPE haproxy_server_bytes_in_total gauge haproxy_server_bytes_in_total{namespace="",pod="",route="",server="fe_no_sni",service=""} 0 haproxy_server_bytes_in_total{namespace="",pod="",route="",server="fe_sni",service=""} 0 haproxy_server_bytes_in_total{namespace="default",pod="docker-registry-5-nk5fz",route="docker-registry",server="10.130.0.89:5000",service="docker-registry"} 0 haproxy_server_bytes_in_total{namespace="default",pod="hello-rc-vkjqx",route="hello-route",server="10.130.0.90:8080",service="hello-svc-1"} 0 ...Launch the stats window by entering the following URL in a browser:
http://<user>:<password>@<router_IP>:<stats_port>Optional: Get the stats in CSV format by entering the following URL in a browser:
http://<user>:<password>@<router_ip>:1936/metrics;csv
5.7.9.22. Customizing HAProxy error code response pages
As a cluster administrator, you can specify a custom error code response page for either 503, 404, or both error pages. The HAProxy router serves a 503 error page when the application pod is not running or a 404 error page when the requested URL does not exist. For example, if you customize the 503 error code response page, then the page is served when the application pod is not running, and the default 404 error code HTTP response page is served by the HAProxy router for an incorrect route or a non-existing route.
Custom error code response pages are specified in a config map then patched to the Ingress Controller. The config map keys have two available file names as follows: error-page-503.http and error-page-404.http.
Custom HTTP error code response pages must follow the HAProxy HTTP error page configuration guidelines. Here is an example of the default OpenShift Container Platform HAProxy router http 503 error code response page. You can use the default content as a template for creating your own custom page.
By default, the HAProxy router serves only a 503 error page when the application is not running or when the route is incorrect or non-existent. This default behavior is the same as the behavior on OpenShift Container Platform 4.8 and earlier. If a config map for the customization of an HTTP error code response is not provided, and you are using a custom HTTP error code response page, the router serves a default 404 or 503 error code response page.
If you use the OpenShift Container Platform default 503 error code page as a template for your customizations, the headers in the file require an editor that can use CRLF line endings.
Procedure
Create a config map named
my-custom-error-code-pagesin theopenshift-confignamespace:$ oc -n openshift-config create configmap my-custom-error-code-pages \ --from-file=error-page-503.http \ --from-file=error-page-404.httpImportantIf you do not specify the correct format for the custom error code response page, a router pod outage occurs. To resolve this outage, you must delete or correct the config map and delete the affected router pods so they can be recreated with the correct information.
Patch the Ingress Controller to reference the
my-custom-error-code-pagesconfig map by name:$ oc patch -n openshift-ingress-operator ingresscontroller/default --patch '{"spec":{"httpErrorCodePages":{"name":"my-custom-error-code-pages"}}}' --type=mergeThe Ingress Operator copies the
my-custom-error-code-pagesconfig map from theopenshift-confignamespace to theopenshift-ingressnamespace. The Operator names the config map according to the pattern,<your_ingresscontroller_name>-errorpages, in theopenshift-ingressnamespace.Display the copy:
$ oc get cm default-errorpages -n openshift-ingressExample output
NAME DATA AGE default-errorpages 2 25s1 - 1
- The example config map name is
default-errorpagesbecause thedefaultIngress Controller custom resource (CR) was patched.
Confirm that the config map containing the custom error response page mounts on the router volume where the config map key is the filename that has the custom HTTP error code response:
For 503 custom HTTP custom error code response:
$ oc -n openshift-ingress rsh <router_pod> cat /var/lib/haproxy/conf/error_code_pages/error-page-503.httpFor 404 custom HTTP custom error code response:
$ oc -n openshift-ingress rsh <router_pod> cat /var/lib/haproxy/conf/error_code_pages/error-page-404.http
Verification
Verify your custom error code HTTP response:
Create a test project and application:
$ oc new-project test-ingress$ oc new-app django-psql-exampleFor 503 custom http error code response:
- Stop all the pods for the application.
Run the following curl command or visit the route hostname in the browser:
$ curl -vk <route_hostname>
For 404 custom http error code response:
- Visit a non-existent route or an incorrect route.
Run the following curl command or visit the route hostname in the browser:
$ curl -vk <route_hostname>
Check if the
errorfileattribute is properly in thehaproxy.configfile:$ oc -n openshift-ingress rsh <router> cat /var/lib/haproxy/conf/haproxy.config | grep errorfile
5.7.9.23. Setting the Ingress Controller maximum connections
A cluster administrator can set the maximum number of simultaneous connections for OpenShift router deployments. You can patch an existing Ingress Controller to increase the maximum number of connections.
Prerequisites
- The following assumes that you already created an Ingress Controller
Procedure
Update the Ingress Controller to change the maximum number of connections for HAProxy:
$ oc -n openshift-ingress-operator patch ingresscontroller/default --type=merge -p '{"spec":{"tuningOptions": {"maxConnections": 7500}}}'WarningIf you set the
spec.tuningOptions.maxConnectionsvalue greater than the current operating system limit, the HAProxy process will not start. See the table in the "Ingress Controller configuration parameters" section for more information about this parameter.
5.8. Ingress Node Firewall Operator in OpenShift Container Platform
The Ingress Node Firewall Operator provides a stateless, eBPF-based firewall for managing node-level ingress traffic in OpenShift Container Platform.
5.8.1. Ingress Node Firewall Operator
The Ingress Node Firewall Operator provides ingress firewall rules at a node level that you can specify and manage in the firewall configurations.
To deploy the daemon set created by the Operator, you create an IngressNodeFirewallConfig custom resource (CR). The Operator applies the IngressNodeFirewallConfig CR to create ingress node firewall daemon set daemon, which run on all nodes that match the nodeSelector.
You configure rules of the IngressNodeFirewall CR and apply them to clusters using the nodeSelector and setting values to "true".
The Ingress Node Firewall Operator supports only stateless firewall rules.
Network interface controllers (NICs) that do not support native XDP drivers will run at a lower performance.
For OpenShift Container Platform 4.14 or later, you must run Ingress Node Firewall Operator on RHEL 9.0 or later.
5.8.2. Installing the Ingress Node Firewall Operator
As a cluster administrator, you can install the Ingress Node Firewall Operator to enable node-level ingress firewalling by using the OpenShift Container Platform CLI.
Prerequisites
-
You have installed the OpenShift CLI (
oc). - You have an account with administrator privileges.
Procedure
To create the
openshift-ingress-node-firewallnamespace, enter the following command:$ cat << EOF| oc create -f - apiVersion: v1 kind: Namespace metadata: labels: pod-security.kubernetes.io/enforce: privileged pod-security.kubernetes.io/enforce-version: v1.24 name: openshift-ingress-node-firewall EOFTo create an
OperatorGroupCR, enter the following command:$ cat << EOF| oc create -f - apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: ingress-node-firewall-operators namespace: openshift-ingress-node-firewall EOFSubscribe to the Ingress Node Firewall Operator.
To create a
SubscriptionCR for the Ingress Node Firewall Operator, enter the following command:$ cat << EOF| oc create -f - apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: ingress-node-firewall-sub namespace: openshift-ingress-node-firewall spec: name: ingress-node-firewall channel: stable source: redhat-operators sourceNamespace: openshift-marketplace EOF
To verify that the Operator is installed, enter the following command:
$ oc get ip -n openshift-ingress-node-firewallExample output
NAME CSV APPROVAL APPROVED install-5cvnz ingress-node-firewall.4.16.0-202211122336 Automatic trueTo verify the version of the Operator, enter the following command:
$ oc get csv -n openshift-ingress-node-firewallExample output
NAME DISPLAY VERSION REPLACES PHASE ingress-node-firewall.4.16.0-202211122336 Ingress Node Firewall Operator 4.16.0-202211122336 ingress-node-firewall.4.16.0-202211102047 Succeeded
5.8.3. Installing the Ingress Node Firewall Operator using the web console
As a cluster administrator, you can install the Ingress Node Firewall Operator to enable node-level ingress firewalling by using the web console.
Prerequisites
-
You have installed the OpenShift CLI (
oc). - You have an account with administrator privileges.
Procedure
Install the Ingress Node Firewall Operator:
-
In the OpenShift Container Platform web console, click Operators
OperatorHub. - Select Ingress Node Firewall Operator from the list of available Operators, and then click Install.
- On the Install Operator page, under Installed Namespace, select Operator recommended Namespace.
- Click Install.
-
In the OpenShift Container Platform web console, click Operators
Verify that the Ingress Node Firewall Operator is installed successfully:
-
Navigate to the Operators
Installed Operators page. Ensure that Ingress Node Firewall Operator is listed in the openshift-ingress-node-firewall project with a Status of InstallSucceeded.
NoteDuring installation an Operator might display a Failed status. If the installation later succeeds with an InstallSucceeded message, you can ignore the Failed message.
If the Operator does not have a Status of InstallSucceeded, troubleshoot using the following steps:
- Inspect the Operator Subscriptions and Install Plans tabs for any failures or errors under Status.
-
Navigate to the Workloads
Pods page and check the logs for pods in the openshift-ingress-node-firewallproject. Check the namespace of the YAML file. If the annotation is missing, you can add the annotation
workload.openshift.io/allowed=managementto the Operator namespace with the following command:$ oc annotate ns/openshift-ingress-node-firewall workload.openshift.io/allowed=managementNoteFor single-node OpenShift clusters, the
openshift-ingress-node-firewallnamespace requires theworkload.openshift.io/allowed=managementannotation.
-
Navigate to the Operators
5.8.4. Deploying Ingress Node Firewall Operator
To deploy the Ingress Node Firewall Operator, create a IngressNodeFirewallConfig custom resource that will deploy the Operator’s daemon set. You can deploy one or multiple IngressNodeFirewall CRDs to nodes by applying firewall rules.
Prerequisite
- The Ingress Node Firewall Operator is installed.
Procedure
-
Create the
IngressNodeFirewallConfiginside theopenshift-ingress-node-firewallnamespace namedingressnodefirewallconfig. Run the following command to deploy Ingress Node Firewall Operator rules:
$ oc apply -f rule.yaml
5.8.5. Ingress Node Firewall configuration object
Review configuration fields so you can define how the Operator deploys the firewall.
The fields for the Ingress Node Firewall configuration object are described in the following table:
| Field | Type | Description |
|---|---|---|
|
|
|
The name of the CR object. The name of the firewall rules object must be |
|
|
|
Namespace for the Ingress Firewall Operator CR object. The |
|
|
| A node selection constraint used to target nodes through specified node labels. For example: Note
One label used in |
The Operator consumes the CR and creates an ingress node firewall daemon set on all the nodes that match the nodeSelector.
5.8.5.1. Ingress Node Firewall Operator example configuration
A complete Ingress Node Firewall Configuration is specified in the following example:
Example Ingress Node Firewall Configuration object
apiVersion: ingressnodefirewall.openshift.io/v1alpha1
kind: IngressNodeFirewallConfig
metadata:
name: ingressnodefirewallconfig
namespace: openshift-ingress-node-firewall
spec:
nodeSelector:
node-role.kubernetes.io/worker: ""
The Operator consumes the CR and creates an ingress node firewall daemon set on all the nodes that match the nodeSelector.
5.8.5.2. Ingress Node Firewall rules object
You can review rule fields and examples to define which ingress traffic is allowed or denied by using the Ingress Node Firewall rules object.
The fields for the Ingress Node Firewall rules object are described in the following table:
| Field | Type | Description |
|---|---|---|
|
|
| The name of the CR object. |
|
|
|
The fields for this object specify the interfaces to apply the firewall rules to. For example, |
|
|
|
You can use |
|
|
|
|
5.8.5.2.1. Ingress object configuration
The values for the ingress object are defined in the following table:
| Field | Type | Description |
|---|---|---|
|
|
| Allows you to set the CIDR block. You can configure multiple CIDRs from different address families. Note
Different CIDRs allow you to use the same order rule. In the case that there are multiple |
|
|
|
Ingress firewall
Set Note Ingress firewall rules are verified using a verification webhook that blocks any invalid configuration. The verification webhook prevents you from blocking any critical cluster services such as the API server. |
5.8.5.2.2. Ingress Node Firewall rules object example
A complete Ingress Node Firewall configuration is specified in the following example:
Example Ingress Node Firewall configuration
apiVersion: ingressnodefirewall.openshift.io/v1alpha1
kind: IngressNodeFirewall
metadata:
name: ingressnodefirewall
spec:
interfaces:
- eth0
nodeSelector:
matchLabels:
<label_name>: <label_value>
ingress:
- sourceCIDRs:
- 172.16.0.0/12
rules:
- order: 10
protocolConfig:
protocol: ICMP
icmp:
icmpType: 8 #ICMP Echo request
action: Deny
- order: 20
protocolConfig:
protocol: TCP
tcp:
ports: "8000-9000"
action: Deny
- sourceCIDRs:
- fc00:f853:ccd:e793::0/64
rules:
- order: 10
protocolConfig:
protocol: ICMPv6
icmpv6:
icmpType: 128 #ICMPV6 Echo request
action: Deny
+ A <label_name> and a <label_value> must exist on the node and must match the nodeselector label and value applied to the nodes you want the ingressfirewallconfig CR to run on. The <label_value> can be true or false. By using nodeSelector labels, you can target separate groups of nodes to apply different rules to using the ingressfirewallconfig CR.
5.8.5.2.3. Zero trust Ingress Node Firewall rules object example
Zero trust Ingress Node Firewall rules can provide additional security to multi-interface clusters. For example, you can use zero trust Ingress Node Firewall rules to drop all traffic on a specific interface except for SSH.
A complete configuration of a zero trust Ingress Node Firewall rule for a network-interface cluster is specified in the following example:
Users need to add all ports their application will use to their allowlist in the following case to ensure proper functionality.
Example zero trust Ingress Node Firewall rules
apiVersion: ingressnodefirewall.openshift.io/v1alpha1
kind: IngressNodeFirewall
metadata:
name: ingressnodefirewall-zero-trust
spec:
interfaces:
- eth1
nodeSelector:
matchLabels:
<ingress_firewall_label_name>: <label_value>
ingress:
- sourceCIDRs:
- 0.0.0.0/0
rules:
- order: 10
protocolConfig:
protocol: TCP
tcp:
ports: 22
action: Allow
- order: 20
action: Deny5.8.6. Viewing Ingress Node Firewall Operator rules
Inspect existing rules and configs to confirm the firewall is applied as intended.
Procedure
Run the following command to view all current rules :
$ oc get ingressnodefirewallChoose one of the returned
<resource>names and run the following command to view the rules or configs:$ oc get <resource> <name> -o yaml
5.8.7. Troubleshooting the Ingress Node Firewall Operator
You can verify the status and view the logs to diagnose ingress firewall deployment or rule issues.
Procedure
Run the following command to list installed Ingress Node Firewall custom resource definitions (CRD):
$ oc get crds | grep ingressnodefirewallExample output
NAME READY UP-TO-DATE AVAILABLE AGE ingressnodefirewallconfigs.ingressnodefirewall.openshift.io 2022-08-25T10:03:01Z ingressnodefirewallnodestates.ingressnodefirewall.openshift.io 2022-08-25T10:03:00Z ingressnodefirewalls.ingressnodefirewall.openshift.io 2022-08-25T10:03:00ZRun the following command to view the state of the Ingress Node Firewall Operator:
$ oc get pods -n openshift-ingress-node-firewallExample output
NAME READY STATUS RESTARTS AGE ingress-node-firewall-controller-manager 2/2 Running 0 5d21h ingress-node-firewall-daemon-pqx56 3/3 Running 0 5d21hThe following fields provide information about the status of the Operator:
READY,STATUS,AGE, andRESTARTS. TheSTATUSfield isRunningwhen the Ingress Node Firewall Operator is deploying a daemon set to the assigned nodes.Run the following command to collect all ingress firewall node pods' logs:
$ oc adm must-gather – gather_ingress_node_firewallThe logs are available in the sos node’s report containing eBPF
bpftooloutputs at/sos_commands/ebpf. These reports include lookup tables used or updated as the ingress firewall XDP handles packet processing, updates statistics, and emits events.
5.9. SR-IOV Operator
5.9.1. Installing the SR-IOV Network Operator
To manage SR-IOV network devices and network attachments on your cluster, install the Single Root I/O Virtualization (SR-IOV) Network Operator. By using this Operator, you can centralize the configuration and lifecycle management of your SR-IOV resources.
As a cluster administrator, you can install the Single Root I/O Virtualization (SR-IOV) Network Operator by using the OpenShift Container Platform CLI or the web console.
5.9.1.1. Using the CLI to install the SR-IOV Network Operator
You can use the CLI to install the SR-IOV Network Operator. By using the CLI, you can deploy the Operator directly from your terminal to manage SR-IOV network devices and attachments without navigating the web console.
Prerequisites
-
You installed the OpenShift CLI (
oc). -
You have an account with
cluster-adminprivileges. - You installed a cluster on bare-metal hardware, and you ensured that cluster nodes have hardware that supports SR-IOV.
Procedure
Create the
openshift-sriov-network-operatornamespace by entering the following command:$ cat << EOF| oc create -f - apiVersion: v1 kind: Namespace metadata: name: openshift-sriov-network-operator annotations: workload.openshift.io/allowed: management EOFCreate an
OperatorGroupcustom resource (CR) by entering the following command:$ cat << EOF| oc create -f - apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: sriov-network-operators namespace: openshift-sriov-network-operator spec: targetNamespaces: - openshift-sriov-network-operator EOFCreate a
SubscriptionCR for the SR-IOV Network Operator by entering the following command:$ cat << EOF| oc create -f - apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: sriov-network-operator-subscription namespace: openshift-sriov-network-operator spec: channel: stable name: sriov-network-operator source: redhat-operators sourceNamespace: openshift-marketplace EOFCreate an
SriovoperatorConfigresource by entering the following command:$ cat <<EOF | oc create -f - apiVersion: sriovnetwork.openshift.io/v1 kind: SriovOperatorConfig metadata: name: default namespace: openshift-sriov-network-operator spec: enableInjector: true enableOperatorWebhook: true logLevel: 2 disableDrain: false EOF
Verification
To verify that the Operator is installed, enter the following command and then check that the output shows
Succeededfor the Operator:$ oc get csv -n openshift-sriov-network-operator \ -o custom-columns=Name:.metadata.name,Phase:.status.phase
5.9.1.2. Using the web console to install the SR-IOV Network Operator
You can use the web console to install the SR-IOV Network Operator. By using the web console, you can deploy the Operator and manage SR-IOV network devices and attachments directly from a graphical interface without having to the CLI.
Prerequisites
-
You have an account with
cluster-adminprivileges. - You installed a cluster on bare-metal hardware, and you ensured that cluster nodes have hardware that supports SR-IOV.
Procedure
Install the SR-IOV Network Operator:
-
In the OpenShift Container Platform web console, click Operators
OperatorHub. - Select SR-IOV Network Operator from the list of available Operators, and then click Install.
- On the Install Operator page, under Installed Namespace, select Operator recommended Namespace.
- Click Install.
-
In the OpenShift Container Platform web console, click Operators
Verification
-
Navigate to the Operators
Installed Operators page. Ensure that SR-IOV Network Operator is listed in the openshift-sriov-network-operator project with a Status of InstallSucceeded.
NoteDuring installation an Operator might display a Failed status. If the installation later succeeds with an InstallSucceeded message, you can ignore the Failed message.
If the Operator does not show as installed, complete any of the following steps to troubleshoot the issue:
- Inspect the Operator Subscriptions and Install Plans tabs for any failure or errors under Status.
-
Navigate to the Workloads
Pods page and check the logs for pods in the openshift-sriov-network-operatorproject. Check the namespace of the YAML file. If the annotation is missing, you can add the annotation
workload.openshift.io/allowed=managementto the Operator namespace with the following command:$ oc annotate ns/openshift-sriov-network-operator workload.openshift.io/allowed=managementNoteFor single-node OpenShift clusters, the annotation
workload.openshift.io/allowed=managementis required for the namespace.
5.9.2. Configuring the SR-IOV Network Operator
To manage SR-IOV network devices and network attachments in your cluster, use the Single Root I/O Virtualization (SR-IOV) Network Operator.
5.9.2.1. Configuring the SR-IOV Network Operator
To manage SR-IOV network devices and network attachments in your cluster, configure the Single Root I/O Virtualization (SR-IOV) Network Operator. You can then deploy the Operator components to your cluster.
Procedure
Create a
SriovOperatorConfigcustom resource (CR). The following example creates a file namedsriovOperatorConfig.yaml:apiVersion: sriovnetwork.openshift.io/v1 kind: SriovOperatorConfig metadata: name: default namespace: openshift-sriov-network-operator spec: disableDrain: false enableInjector: true enableOperatorWebhook: true logLevel: 2 featureGates: metricsExporter: false # ...where:
metadata.name-
Specifies the name of the SR-IOV Network Operator instance. The only valid name for the
SriovOperatorConfigresource isdefaultand the name must be in the namespace where the Operator is deployed. spec.enableInjector-
Specifies if any
network-resources-injectorpod can run in the namespace. If not specified in the CR or explicitly set totrue, defaults tofalseor<none>, preventing anynetwork-resources-injectorpod from running in the namespace. The recommended setting istrue. spec.enableOperatorWebhook-
Specifies if any
operator-webhookpods can run in the namespace. TheenableOperatorWebhookfield, if not specified in the CR or explicitly set to true, defaults tofalseor<none>, preventing anyoperator-webhookpod from running in the namespace. The recommended setting istrue.
Apply the resource to your cluster by running the following command:
$ oc apply -f sriovOperatorConfig.yaml
5.9.2.2. SR-IOV Network Operator config custom resource
To customize the SR-IOV Network Operator, configure the sriovoperatorconfig custom resource. The reference lists the parameters available for controlling the global settings and deployment behavior of the Operator.
The following table describes the sriovoperatorconfig CR fields:
| Field | Type | Description |
|---|---|---|
|
|
|
Specifies the name of the SR-IOV Network Operator instance. The default value is |
|
|
|
Specifies the namespace of the SR-IOV Network Operator instance. The default value is |
|
|
| Specifies the node selection to control scheduling the SR-IOV Network Config Daemon on selected nodes. By default, this field is not set and the Operator deploys the SR-IOV Network Config daemon set on compute nodes. |
|
|
|
Specifies whether to disable the node draining process or enable the node draining process when you apply a new policy to configure the NIC on a node. Setting this field to |
|
|
| Specifies whether to enable or disable the Network Resources Injector daemon set. |
|
|
| Specifies whether to enable or disable the Operator Admission Controller webhook daemon set. |
|
|
|
Specifies the log verbosity level of the Operator. By default, this field is set to |
|
|
|
Specifies whether to enable or disable the optional features. For example, |
|
|
|
Specifies whether to enable or disable the SR-IOV Network Operator metrics. By default, this field is set to |
5.9.2.3. About the Network Resources Injector
To automate network configuration for your workloads, use the Network Resources Injector. This Kubernetes Dynamic Admission Controller intercepts pod creation requests to automatically inject the necessary network resources and parameters defined for your cluster.
The Network Resources Injector provides the following capabilities:
- Mutation of resource requests and limits in a pod specification to add an SR-IOV resource name according to an SR-IOV network attachment definition annotation.
-
Mutation of a pod specification with a Downward API volume to expose pod annotations, labels, and huge pages requests and limits. Containers that run in the pod can access the exposed information as files under the
/etc/podnetinfopath.
The SR-IOV Network Operator enables the Network Resources Injector when the enableInjector is set to true in the SriovOperatorConfig CR. The network-resources-injector pod runs as a daemon set on all control plane nodes. The following is an example of Network Resources Injector pods running in a cluster with three control plane nodes:
$ oc get pods -n openshift-sriov-network-operatorExample output
NAME READY STATUS RESTARTS AGE
network-resources-injector-5cz5p 1/1 Running 0 10m
network-resources-injector-dwqpx 1/1 Running 0 10m
network-resources-injector-lktz5 1/1 Running 0 10m5.9.2.4. Disabling or enabling the Network Resources Injector
To control the automatic configuration of your cluster workloads, enable or disable the Network Resources Injector. By adjusting these settings you can better manage whether the Kubernetes Dynamic Admission Controller automatically injects network resources and parameters into pods during their creation.
Prerequisites
-
Install the OpenShift CLI (
oc). -
Log in as a user with
cluster-adminprivileges. - You must have installed the SR-IOV Network Operator.
Procedure
Set the
enableInjectorfield. Replace<value>withfalseto disable the feature ortrueto enable the feature.$ oc patch sriovoperatorconfig default \ --type=merge -n openshift-sriov-network-operator \ --patch '{ "spec": { "enableInjector": <value> } }'TipYou can alternatively apply the following YAML to update the Operator:
apiVersion: sriovnetwork.openshift.io/v1 kind: SriovOperatorConfig metadata: name: default namespace: openshift-sriov-network-operator spec: enableInjector: <value> # ...
5.9.2.5. About the SR-IOV Network Operator admission controller webhook
To validate network configurations and prevent errors, rely on the SR-IOV Network Operator admission controller webhook. This Kubernetes Dynamic Admission Controller intercepts API requests to ensure that your SR-IOV resource definitions and pod specifications comply with cluster policies.
The SR-IOV Network Operator Admission Controller webhook provides the following capabilities:
-
Validation of the
SriovNetworkNodePolicyCR when it is created or updated. -
Mutation of the
SriovNetworkNodePolicyCR by setting the default value for thepriorityanddeviceTypefields when the CR is created or updated.
The SR-IOV Network Operator Admission Controller webhook is enabled by the Operator when the enableOperatorWebhook is set to true in the SriovOperatorConfig CR. The operator-webhook pod runs as a daemon set on all control plane nodes.
Use caution when disabling the SR-IOV Network Operator Admission Controller webhook. You can disable the webhook under specific circumstances, such as troubleshooting, or if you want to use unsupported devices. For information about configuring unsupported devices, see "Configuring the SR-IOV Network Operator to use an unsupported NIC".
The following is an example of the Operator Admission Controller webhook pods running in a cluster with three control plane nodes:
$ oc get pods -n openshift-sriov-network-operatorExample output
NAME READY STATUS RESTARTS AGE
operator-webhook-9jkw6 1/1 Running 0 16m
operator-webhook-kbr5p 1/1 Running 0 16m
operator-webhook-rpfrl 1/1 Running 0 16m5.9.2.6. Disabling or enabling the SR-IOV Network Operator admission controller webhook
To manage validation of your network configurations, enable or disable the SR-IOV Network Operator admission controller webhook. When enabled, the Operator automatically verifies SR-IOV resource definitions and pod specifications against cluster policies.
Prerequisites
-
Install the OpenShift CLI (
oc). -
Log in as a user with
cluster-adminprivileges. - You must have installed the SR-IOV Network Operator.
Procedure
Set the
enableOperatorWebhookfield. Replace<value>withfalseto disable the feature ortrueto enable it:$ oc patch sriovoperatorconfig default --type=merge \ -n openshift-sriov-network-operator \ --patch '{ "spec": { "enableOperatorWebhook": <value> } }'TipYou can alternatively apply the following YAML to update the Operator:
apiVersion: sriovnetwork.openshift.io/v1 kind: SriovOperatorConfig metadata: name: default namespace: openshift-sriov-network-operator spec: enableOperatorWebhook: <value> # ...
5.9.2.7. Configuring a custom NodeSelector for the SR-IOV Network Config daemon
To specify which nodes host the SR-IOV Network Config daemon, configure a custom node selector by using node labels. By completing this task, you can restrict deployment to specific nodes instead of the default compute nodes.
The SR-IOV Network Config daemon discovers and configures the SR-IOV network devices on cluster nodes. By default, the daemon is deployed to all the compute nodes in the cluster.
When you update the configDaemonNodeSelector field, the SR-IOV Network Config daemon is recreated on each selected node. While the daemon is recreated, cluster users are unable to apply any new SR-IOV Network node policy or create new SR-IOV pods.
Procedure
To update the node selector for the Operator, enter the following command:
$ oc patch sriovoperatorconfig default --type=json \ -n openshift-sriov-network-operator \ --patch '[{ "op": "replace", "path": "/spec/configDaemonNodeSelector", "value": {<node_label>} }]'Replace
<node_label>with a label to apply as in the following example:"node-role.kubernetes.io/worker": "".TipYou can alternatively apply the following YAML to update the Operator:
apiVersion: sriovnetwork.openshift.io/v1 kind: SriovOperatorConfig metadata: name: default namespace: openshift-sriov-network-operator spec: configDaemonNodeSelector: <node_label> # ...
5.9.2.8. Configuring the SR-IOV Network Operator for single node installations
By default, the SR-IOV Network Operator drains workloads from a node before every policy change. The Operator performs this action to ensure that no workloads are using the virtual functions before the reconfiguration. As a result, you must configure the Operator to not drain workloads from the single node.
For installations on a single node, other nodes do not receive the workloads.
After performing the following procedure to disable draining workloads, you must remove any workload that uses an SR-IOV network interface before you change any SR-IOV network node policy.
Prerequisites
-
Install the OpenShift CLI (
oc). -
Log in as a user with
cluster-adminprivileges. - You must have installed the SR-IOV Network Operator.
Procedure
To set the
disableDrainfield totrueand theconfigDaemonNodeSelectorfield tonode-role.kubernetes.io/master: "", enter the following command:$ oc patch sriovoperatorconfig default --type=merge -n openshift-sriov-network-operator --patch '{ "spec": { "disableDrain": true, "configDaemonNodeSelector": { "node-role.kubernetes.io/master": "" } } }'TipYou can alternatively apply the following YAML to update the Operator:
apiVersion: sriovnetwork.openshift.io/v1 kind: SriovOperatorConfig metadata: name: default namespace: openshift-sriov-network-operator spec: disableDrain: true configDaemonNodeSelector: node-role.kubernetes.io/master: "" # ...
5.9.2.8.1. Deploying the SR-IOV Operator for hosted control planes
Hosted control planes on the AWS platform is a Technology Preview feature only. Technology Preview features are not supported with Red Hat production service level agreements (SLAs) and might not be functionally complete. Red Hat does not recommend using them in production. These features provide early access to upcoming product features, enabling customers to test functionality and provide feedback during the development process.
For more information about the support scope of Red Hat Technology Preview features, see Technology Preview Features Support Scope.
After you configure and deploy your hosting service cluster, you can create a subscription to the SR-IOV Operator on a hosted cluster. The SR-IOV pod runs on worker machines rather than the control plane.
Prerequisites
You must configure and deploy the hosted cluster on AWS. For more information, see Configuring the hosting cluster on AWS (Technology Preview).
Procedure
Create a namespace and an Operator group:
apiVersion: v1 kind: Namespace metadata: name: openshift-sriov-network-operator --- apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: sriov-network-operators namespace: openshift-sriov-network-operator spec: targetNamespaces: - openshift-sriov-network-operatorCreate a subscription to the SR-IOV Operator:
apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: sriov-network-operator-subsription namespace: openshift-sriov-network-operator spec: channel: stable name: sriov-network-operator config: nodeSelector: node-role.kubernetes.io/worker: "" source: redhat-operators sourceNamespace: openshift-marketplace
Verification
To verify that the SR-IOV Operator is ready, run the following command and view the resulting output:
$ oc get csv -n openshift-sriov-network-operatorExample output
NAME DISPLAY VERSION REPLACES PHASE sriov-network-operator.4.16.0-202211021237 SR-IOV Network Operator 4.16.0-202211021237 sriov-network-operator.4.16.0-202210290517 SucceededTo verify that the SR-IOV pods are deployed, run the following command:
$ oc get pods -n openshift-sriov-network-operator
5.9.2.9. About the SR-IOV network metrics exporter
To monitor the networking activity of SR-IOV pods, enable the SR-IOV network metrics exporter. This tool exposes metrics for SR-IOV virtual functions (VFs) in Prometheus format, so that you can query and visualize data through the OpenShift Container Platform web console.
When you query the SR-IOV VF metrics by using the web console, the SR-IOV network metrics exporter fetches and returns the VF network statistics along with the name and namespace of the pod that the VF is attached to.
The following table describes the SR-IOV VF metrics that the metrics exporter reads and exposes in Prometheus format:
| Metric | Description | Example PromQL query to examine the VF metric |
|---|---|---|
|
| Received bytes per virtual function. |
|
|
| Transmitted bytes per virtual function. |
|
|
| Received packets per virtual function. |
|
|
| Transmitted packets per virtual function. |
|
|
| Dropped packets upon receipt per virtual function. |
|
|
| Dropped packets during transmission per virtual function. |
|
|
| Received multicast packets per virtual function. |
|
|
| Received broadcast packets per virtual function. |
|
|
| Virtual functions linked to active pods. | - |
You can also combine these queries by using the kube-state-metrics tool to get more information about the SR-IOV pods. For example, you can use the following query to get the VF network statistics along with the application name from the standard Kubernetes pod label:
(sriov_vf_tx_packets * on (pciAddr,node) group_left(pod,namespace) sriov_kubepoddevice) * on (pod,namespace) group_left (label_app_kubernetes_io_name) kube_pod_labels5.9.2.9.1. Enabling the SR-IOV network metrics exporter
To enable the SR-IOV network metrics exporter, set the spec.featureGates.metricsExporter field to true. Because the exporter is disabled by default, you must explicitly activate this feature gate to start exposing metrics for your SR-IOV devices.
When the metrics exporter is enabled, the SR-IOV Network Operator deploys the metrics exporter only on nodes with SR-IOV capabilities.
Prerequisites
-
You have installed the OpenShift CLI (
oc). -
You have logged in as a user with
cluster-adminprivileges. - You have installed the SR-IOV Network Operator.
Procedure
Enable cluster monitoring by running the following command:
$ oc label ns/openshift-sriov-network-operator openshift.io/cluster-monitoring=trueTo enable cluster monitoring, you must add the
openshift.io/cluster-monitoring=truelabel in the namespace where you have installed the SR-IOV Network Operator.Set the
spec.featureGates.metricsExporterfield totrueby running the following command:$ oc patch -n openshift-sriov-network-operator sriovoperatorconfig/default \ --type='merge' -p='{"spec": {"featureGates": {"metricsExporter": true}}}'
Verification
Check that the SR-IOV network metrics exporter is enabled by running the following command:
$ oc get pods -n openshift-sriov-network-operatorExample output
NAME READY STATUS RESTARTS AGE operator-webhook-hzfg4 1/1 Running 0 5d22h sriov-network-config-daemon-tr54m 1/1 Running 0 5d22h sriov-network-metrics-exporter-z5d7t 1/1 Running 0 10s sriov-network-operator-cc6fd88bc-9bsmt 1/1 Running 0 5d22hEnsure that
sriov-network-metrics-exporterpod is in theREADYstate.- Optional: Examine the SR-IOV virtual function (VF) metrics by using the OpenShift Container Platform web console. For more information, see "Querying metrics".
5.9.3. Uninstalling the SR-IOV Network Operator
To uninstall the SR-IOV Network Operator, you must delete any running SR-IOV workloads, uninstall the Operator, and delete the webhooks that the Operator used.
5.9.3.1. Uninstalling the SR-IOV Network Operator
You can remove the SR-IOV Network Operator from your cluster by uninstalling the Operator. This ensures that the Operator and its associated resources are deleted when you no longer need to manage SR-IOV network devices.
Prerequisites
-
You have access to an OpenShift Container Platform cluster using an account with
cluster-adminpermissions. - You have the SR-IOV Network Operator installed.
Procedure
Delete all SR-IOV custom resources (CRs):
$ oc delete sriovnetwork -n openshift-sriov-network-operator --all$ oc delete sriovnetworknodepolicy -n openshift-sriov-network-operator --all$ oc delete sriovibnetwork -n openshift-sriov-network-operator --all- Follow the instructions in the "Deleting Operators from a cluster" section to remove the SR-IOV Network Operator from your cluster.
Delete the SR-IOV custom resource definitions that remain in the cluster after the SR-IOV Network Operator is uninstalled:
$ oc delete crd sriovibnetworks.sriovnetwork.openshift.io$ oc delete crd sriovnetworknodepolicies.sriovnetwork.openshift.io$ oc delete crd sriovnetworknodestates.sriovnetwork.openshift.io$ oc delete crd sriovnetworkpoolconfigs.sriovnetwork.openshift.io$ oc delete crd sriovnetworks.sriovnetwork.openshift.io$ oc delete crd sriovoperatorconfigs.sriovnetwork.openshift.ioDelete the SR-IOV webhooks:
$ oc delete mutatingwebhookconfigurations network-resources-injector-config$ oc delete MutatingWebhookConfiguration sriov-operator-webhook-config$ oc delete ValidatingWebhookConfiguration sriov-operator-webhook-configDelete the SR-IOV Network Operator namespace:
$ oc delete namespace openshift-sriov-network-operator