第41章 OpenShift SDN のトラブルシューティング
41.1. 概要
SDN のドキュメントで説明されているように、あるコンテナーから別のコンテナーへのトラフィックを適切に渡すために作成されるインターフェースには複数のレイヤーがあります。接続の問題をデバッグするには、スタックの複数のレイヤーをテストして問題の原因を判別する必要があります。本書は複数のレイヤーを調べて問題を特定し、解決するのに役立ちます。
問題の原因の一部は OpenShift Container Platform が複数の方法で設定でき、ネットワークが複数の異なる場所で正しく設定されない可能性がある点にあります。本書では、いくつかのシナリオを使用しますが、これらのシナリオは大半のケースに対応していることが予想されます。実際に生じている問題がこれらのシナリオで扱われていない場合には、導入されている各種のツールおよび概念を使用してデバッグ作業を行うことができます。
41.2. 用語
- クラスター
- クラスター内の一連のマシンです。例: マスターおよびノード。
- マスター
- OpenShift Container Platform クラスターのコントローラーです。マスターはクラスター内のノードではない場合があり、そのため Pod への IP 接続がない場合があることに注意してください。
- ノード
- Pod をホストできる OpenShift Container Platform を実行するクラスター内のホストです。
- Pod
- OpenShift Container Platform によって管理される、ノード上で実行されるコンテナーのグループです。
- サービス
- 1 つ以上の Pod でサポートされる、統一ネットワークインターフェースを表す抽象化です。
- ルーター
- 複数の URL とパスを OpenShift Container Platform サービスにマップし、外部トラフィックがクラスターに到達できるようにする web プロキシーです。
- ノードアドレス
- ノードの IP アドレスです。これはノードが割り当てられるネットワークの所有者によって割り当てられ、管理されます。クラスター内の任意のノード (マスターおよびクライアント) からアクセスできる必要があります。
- Pod アドレス
- Pod の IP アドレスです。これらは OpenShift Container Platform によって割り当てられ、管理されます。デフォルトで、これらは 10.128.0.0/14 ネットワーク (または古いバージョンでは 10.1.0.0/16) から割り当てられます。クライアントノードからのみアクセスできます。
- サービスアドレス
- サービスを表す IP アドレスで、内部で Pod アドレスにマップされます。これらは OpenShift Container Platform によって割り当てられ、管理されます。デフォルトで、これらは 172.30.0.0/16 ネットワークから割り当てられます。クライアントノードからのみアクセスできます。
以下の図は、外部アクセスに関係するすべての構成部分を示しています。
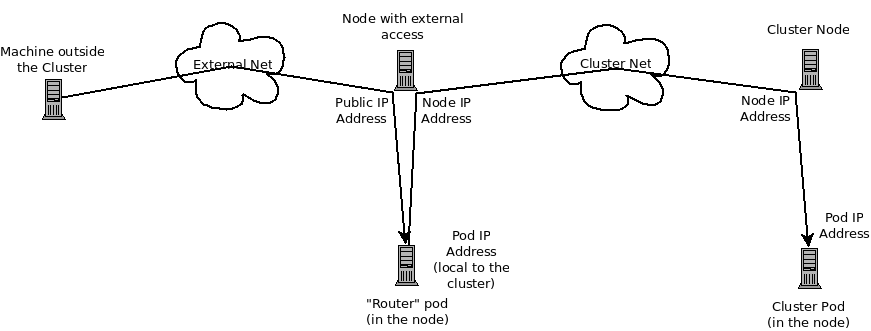
41.3. HTTP サービスへの外部アクセスのデバッグ
クラスター外のマシンを使用している場合で、クラスターで提供されるリソースにアクセスしようとしている場合、パブリック IP アドレスでリッスンし、クラスター内のトラフィックを「ルーティング」する Pod でプロセスが実行されている必要があります。この場合、OpenShift Container Platform ルーターは、HTTP、HTTPS (SNI を使用)、WebSockets または TLS (SNI を使用) について使用できます。
クラスター外より HTTP サービスにアクセスできないことを想定し、障害が発生しているマシンのコマンドラインを使って問題を再現します。以下を実行します。
curl -kv http://foo.example.com:8000/bar # But replace the argument with your URL成功する場合は、正しい場所からバグを再現しているかどうかを確認します。サービスに機能する Pod と機能しない Pod が含まれる可能性もあります。したがって、「ルーターのデバッグ」 セクションを参照してください。
失敗した場合は、IP アドレスに対して DNS 名を解決します (ないことを想定します)。
dig +short foo.example.com # But replace the hostname with yoursIP アドレスが返されない場合は、DNS をトラブルシューティングする必要がありますが、これについては本書では扱いません。
返される IP アドレスがルーターを実行するルーターであることを確認します。そうでない場合は、DNS を修正します。
次に ping -c address および tracepath address を使用して、ルーターホストに到達できることを確認します。それらが ICMP パケットに応答しない場合もあり、この場合はそれらのテストは失敗しますが、ルーターマシンにはアクセスできる場合があります。この場合、コマンドを使ってルーターのポートに直接アクセスしてみます。
telnet 1.2.3.4 8000以下が表示される場合があります。
Trying 1.2.3.4...
Connected to 1.2.3.4.
Escape character is '^]'.
この場合、IP アドレスのポートでリッスンしているものがあることを示しています。ctrl-] を押してから enter キーを押し、close を入力して telnet を終了します。「ルーターのデバッグ」 セクションに移行してルーターの他のものを確認します。
または、以下が表示される可能性があります。
Trying 1.2.3.4...
telnet: connect to address 1.2.3.4: Connection refusedこれは、ルーターがそのポートでリッスンしていないことを示します。ルーターの設定方法における追加のポイントについては、「ルーターのデバッグ」セクションを参照してください。
または、以下が表示される場合があります。
Trying 1.2.3.4...
telnet: connect to address 1.2.3.4: Connection timed outこれは、IP アドレス上のいずれとも通信できないことを示します。ルーティング、ファイアウォールを確認し、IP アドレスでリッスンしているルーターがあることを確認します。ルーターをデバッグするには、「ルーターのデバッグ」セクションを参照してください。IP ルーティングおよびファイアウォールの問題については、本書では扱いません。
41.4. ルーターのデバッグ
IP アドレスを使用し、そのマシンに対して ssh を実行してルーターソフトウェアがそのマシン上で実行されており、正しく設定されていることを確認する必要があります。ここで ssh を実行し、管理者の OpenShift Container Platform 認証情報を取得します。
管理者認証情報を利用できるがデフォルトシステムユーザーの system:admin としてログインしていない場合、認証情報が CLI 設定ファイルにある限りはこのユーザーとしていつでもログインし直すことができます。以下のコマンドはログインを実行し、デフォルト プロジェクトへの切り替えを実行します。
$ oc login -u system:admin -n defaultルーターが実行されていることを確認します。
# oc get endpoints --namespace=default --selector=router
NAMESPACE NAME ENDPOINTS
default router 10.128.0.4:80このコマンドが失敗する場合、OpenShift Container Platform 設定は破損しています。この設定の修正については、本書では扱われません。
1 つ以上のルーターエンドポイントが一覧表示されますが、エンドポイント IP アドレスはクラスター内の Pod アドレスの 1 つであるため、それらが指定の外部 IP アドレスでマシン上で実行されているかどうかを識別することはできません。ルーターホスト IP アドレスの一覧を取得するには、以下を実行します。
# oc get pods --all-namespaces --selector=router --template='{{range .items}}HostIP: {{.status.hostIP}} PodIP: {{.status.podIP}}{{end}}{{"\n"}}'
HostIP: 192.168.122.202 PodIP: 10.128.0.4外部アドレスに対応するホスト IP が表示されるはずです。表示されない場合は、ルーターのドキュメントを参照して、適切なノードで実行されるようにルーター Podを設定するか (アフィニティーを適切に設定する)、またはルーターが実行されている IP アドレスに一致するよう DNS を更新します。
(本書の) この時点では、ノードでルーター Pod を実行しても HTTP 要求を機能させることはできません。まず、ルーターが外部 URL を正しいサービスにマップしていること、またそれが機能している場合は、そのサービスの詳細を調べてすべてのエンドポイントがアクセス可能であることを確認する必要があります。
OpenShift Container Platform が認識するすべてのルートを一覧表示します。
# oc get route --all-namespaces
NAME HOST/PORT PATH SERVICE LABELS TLS TERMINATION
route-unsecured www.example.com /test service-nameURL のホスト名およびパスが返されるルートの一覧のいずれにも一致しない場合はルートを追加する必要があります。ルーターのドキュメントを参照してください。
ルートが存在する場合、エンドポイントへのアクセスをデバッグする必要があります。これはサービスに関する問題をデバッグしている場合と同様のプロセスです。そのため、次の 「サービスのデバッグ」 セクションに進んでください。
41.5. サービスのデバッグ
クラスター内からサービスと通信できない場合 (サービスが直接通信できないか、またはルーターを使用していてクラスターに入るまですべてが正常に機能している場合)、サービスに関連付けられているエンドポイントを判別し、それらをデバッグする必要があります。
最初にサービスを取得します。
# oc get services --all-namespaces
NAMESPACE NAME LABELS SELECTOR IP(S) PORT(S)
default docker-registry docker-registry=default docker-registry=default 172.30.243.225 5000/TCP
default kubernetes component=apiserver,provider=kubernetes <none> 172.30.0.1 443/TCP
default router router=router router=router 172.30.213.8 80/TCPサービスが一覧に表示されます。表示されない場合は、サービスを定義する必要があります。
サービス出力に一覧表示される IP アドレスは Kubernetes サービス IP アドレスであり、これは Kubernetes がサービスをサポートする Pod のいずれかにマップするものです。このの IP アドレスと通信できるはずですが、通信できたとしても、すべての Pod にアクセスできる訳ではありません。また、通信できない場合もすべての Pod がアクセスできない訳ではありません。これは kubeproxy が接続している 1 つ の IP アドレスのステータスのみを示しています。
サービスをテストします。ノードのいずれかより以下を実行します。
curl -kv http://172.30.243.225:5000/bar # Replace the argument with your service IP address and port
次にサービスをサポートしている Pod を見つけます (docker-registry を破損したサービスの名前に置き換えます)。
# oc get endpoints --selector=docker-registry
NAME ENDPOINTS
docker-registry 10.128.2.2:5000ここではエンドポイントは 1 つだけであることを確認できます。そのため、サービステストが成功し、ルーターテストに成功した場合には、極めて稀なことが生じている可能性があります。ただし、複数のエンドポイントがあるか、またはサービステストが失敗した場合には、それぞれの エンドポイントについて以下を試行します。機能していないエンドポイントを特定できたら、次のセクションに進みます。
最初に、それぞれのエンドポイントをテストします (適切なエンドポイント IP、ポートおよびパスを持つように URL を変更します)。
curl -kv http://10.128.2.2:5000/barこれが機能する場合は、次のエンドポイントをテストします。失敗した場合はその情報をメモしておきます。次のセクションでその原因を判別します。
すべてが失敗した場合は、ローカルノードが機能していない可能があります。その場合は、「ローカルネットワークのデバッグ」 セクションに移行してください。
すべてが機能する場合は、「Kubernetes のデバッグ」 セクションに移行してサービス IP アドレスが機能しない理由を判別します。
41.6. ノード間通信のデバッグ
機能していないエンドポイントの一覧を使用して、ノードに対する接続をテストする必要があります。
すべてのノードに予想される IP アドレスがあることを確認します。
# oc get hostsubnet NAME HOST HOST IP SUBNET rh71-os1.example.com rh71-os1.example.com 192.168.122.46 10.1.1.0/24 rh71-os2.example.com rh71-os2.example.com 192.168.122.18 10.1.2.0/24 rh71-os3.example.com rh71-os3.example.com 192.168.122.202 10.1.0.0/24DHCP を使用している場合はそれらが変更されている可能性があります。ホスト名、IP アドレス、およびサブネットが予想される内容に一致していることを確認します。ノードの詳細が変更されている場合は、
oc edit hostsubnetを使用してエントリーを訂正します。ノードアドレスおよびホスト名が正しいことを確認した後に、エンドポイント IP およびノード IP を一覧表示します。
# oc get pods --selector=docker-registry \ --template='{{range .items}}HostIP: {{.status.hostIP}} PodIP: {{.status.podIP}}{{end}}{{"\n"}}' HostIP: 192.168.122.202 PodIP: 10.128.0.4事前にメモしたエンドポイント IP アドレスを見つけ、これを
PodIPエントリーを検索し、対応するHostIPアドレスを見つけます。次に、HostIPからのアドレスを使用してノードホストレベルで接続をテストします。-
ping -c 3 <IP_address>: 応答がないことは、中間ルーターが ICMP トラフィックを消費している可能性があることを意味しています。 tracepath <IP_address>: ICMP パケットがすべてのホップによって返される場合、ターゲットにつながる IP ルートを表示します。tracepathとpingの両方が失敗する場合、ローカルまたは仮想ネットワークの接続の問題を探します。
-
ローカルネットワークの場合は、以下を確認します。
追加設定なしの状態のパケットのターゲットアドレスへのルートを確認します。
# ip route get 192.168.122.202 192.168.122.202 dev ens3 src 192.168.122.46 cache上記の例では、ソースアドレスが
192.168.122.46のens3という名前のインターフェースからターゲットに直接つながります。これが予想される結果である場合はip a show dev ens3を使用してインターフェースの詳細を取得し、このインターフェースが予想されるインターフェースであることを確認します。または、結果が以下になる可能性もあります。
# ip route get 192.168.122.202 1.2.3.4 via 192.168.122.1 dev ens3 src 192.168.122.46これは、正しくルーティングされるために
via値をパススルーします。トラフィックが正しくルーティングされていることを確認します。ルートトラフィックのデバッグについては、本書では扱われません。
ノード間ネットワークの他のデバッグオプションについては、以下を確認して解決できます。
-
どちらの側にもイーサネットリンクがあるか?
ethtool <network_interface>でLink detected: yesを検索します。 -
デュプレックス設定とイーサネット速度はどちらの側でも適切に設定されているか?
ethtool <network_interface>情報の残りの部分を確認します。 - ケーブルは適切にプラグインされているか? 正しいポートに接続されているか?
- スイッチは適切に設定されているか?
ノード間設定が適切であることを確認した後は、両サイドで SDN 設定を確認する必要があります。
41.7. ローカルネットワークのデバッグ
ここで通信できないものの、ノード間通信が設定された 1 つ以上のエンドポイントの一覧が表示されます。それぞれのエンドポイントについて問題点を特定する必要がありますが、まずは SDN が複数の異なる Pod についてノードでネットワークをどのように設定しているかについて理解する必要があります。
41.7.1. ノードのインターフェース
以下は OpenShift SDN が作成するインターフェースです。
-
br0: コンテナーが割り当てられる OVS ブリッジデバイスです。OpenShift SDN はこのブリッジにサブネットに固有ではないフロールールのセットも設定します。 -
tun0: OVS 内部ポート (br0のポート 2) です。これにはクラスターサブネットゲートウェイアドレスが割り当てられ、外部ネットワークアクセスに使用されます。OpenShift SDN はクラスターサブネットから NAT 経由で外部ネットワークにアクセスできるようにnetfilterおよびルートルールを設定します。 -
vxlan_sys_4789: OVS VXLAN デバイス (br0のポート 1) です。これはリモートノードのコンテナーへのアクセスを提供します。OVS ルールではvxlan0として参照されます。 -
vethX(メイン netns 内): Docker netns におけるeth0の Linux 仮想イーサネットのピアです。これは他のポートのいずれかの OVS ブリッジに割り当てられます。
41.7.2. ノード内の SDN フロー
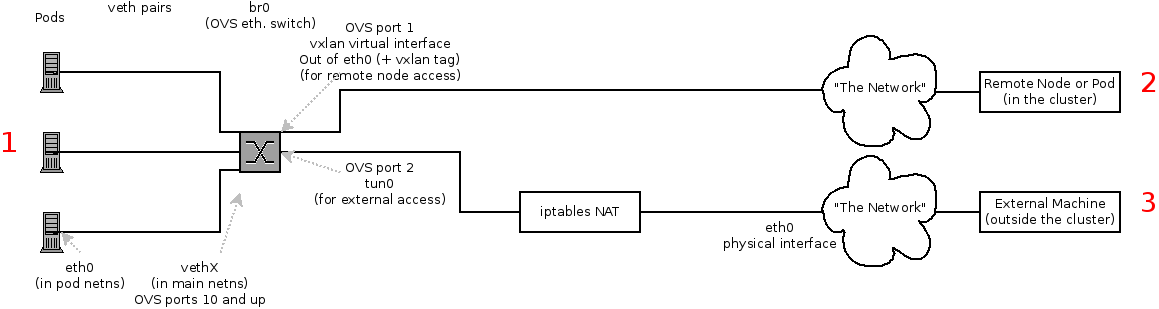
アクセスしようとしているもの (またはアクセスされるもの) によってパスは異なります。SDN が (ノード内に) で接続する場所は 4 カ所あります。それらには上記の図で赤のラベルが付けられています。
- Pod: トラフィックは同じマシンのある Pod から別の Pod に移動します (1 から他の 1 へ)。
- リモートノード (または Pod): トラフィックは同じクラスター内のローカル Pod からリモートノードまたは Pod に移動します (1 から 2 へ)。
- 外部マシン: トラフィックはローカル Pod からクラスター外に移動します (1 から 3 へ)。
当然のこととして、トラフィックはこれらと反対方向でも移動します。
41.7.3. デバッグ手順
41.7.3.1. IP 転送は有効にされているか?
sysctl net.ipv4.ip_forward が 1 に設定されていること (およびホストが仮想マシンであるかどうか) を確認します。
41.7.3.2. ルートは正しく設定されているか?
ip route でルートテーブルを確認します。
# ip route
default via 192.168.122.1 dev ens3
10.128.0.0/14 dev tun0 proto kernel scope link # This sends all pod traffic into OVS
10.128.2.0/23 dev tun0 proto kernel scope link src 10.128.2.1 # This is traffic going to local pods, overriding the above
169.254.0.0/16 dev ens3 scope link metric 1002 # This is for Zeroconf (may not be present)
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.42.1 # Docker's private IPs... used only by things directly configured by docker; not OpenShift
192.168.122.0/24 dev ens3 proto kernel scope link src 192.168.122.46 # The physical interface on the local subnet10.128.x.x 行が表示されるはずです (Pod ネットワークが設定内でデフォルト範囲に設定されていることを前提とします)。これが表示されない場合は、OpenShift Container Platform ログを確認します (「ログの読み取り」 セクションを参照してください)。
41.7.4. Open vSwitch は正しく設定されているか?
両サイドで Open vSwitch ブリッジを確認します。
# ovs-vsctl list-br
br0
これは br0 である必要があります。
ovs が認識するすべてのポートを一覧表示できます。
# ovs-ofctl -O OpenFlow13 dump-ports-desc br0
OFPST_PORT_DESC reply (OF1.3) (xid=0x2):
1(vxlan0): addr:9e:f1:7d:4d:19:4f
config: 0
state: 0
speed: 0 Mbps now, 0 Mbps max
2(tun0): addr:6a:ef:90:24:a3:11
config: 0
state: 0
speed: 0 Mbps now, 0 Mbps max
8(vethe19c6ea): addr:1e:79:f3:a0:e8:8c
config: 0
state: 0
current: 10GB-FD COPPER
speed: 10000 Mbps now, 0 Mbps max
LOCAL(br0): addr:0a:7f:b4:33:c2:43
config: PORT_DOWN
state: LINK_DOWN
speed: 0 Mbps now, 0 Mbps max
とくにアクティブなすべての Pod の vethX デバイスがポートとして表示されるはずです。
次に、そのブリッジに設定されているフローを一覧表示します。
# ovs-ofctl -O OpenFlow13 dump-flows br0ovs-subnet または ovs-multitenant プラグインのどちらを使用しているかに応じて結果は若干異なりますが、以下のような一般的な設定を確認することができます。
-
すべてのリモートノードには
tun_src=<node_IP_address>に一致するフロー (ノードからの着信 VXLAN トラフィック) およびアクションset_field:<node_IP_address>->tun_dstを含む別のフロー(ノードへの発信 VXLAN トラフィック) が設定されている必要があります。 -
すべてのローカル Pod には
arp_spa=<pod_IP_address>およびarp_tpa=<pod_IP_address>に一致するフロー (Pod の着信および発信 ARP トラフィック) と、nw_src=<pod_IP_address>およびnw_dst=<pod_IP_address>に一致するフロー (Pod の着信および発信 IP トラフィック) が設定されている必要があります。
フローがない場合は、「ログの読み取り」 セクションを参照してください。
41.7.4.1. iptables 設定に誤りがないか?
iptables-save の出力をチェックし、トラフィックにフィルターを掛けていないことを確認します。OpenShift Container Platform は通常の操作時に iptables ルールを設定するため、ここにエントリーが表示されていても不思議なことではありません。
41.7.4.2. 外部ネットワークは正しく設定されているか?
外部ファイアウォール (ある場合) を確認し、ターゲットアドレスへのトラフィックを許可するかどうかを確認します (これはサイトごとに異なるため、本書では扱われません)。
41.8. 仮想ネットワークのデバッグ
41.8.1. 仮想ネットワークのビルドに障害が発生している
仮想ネットワーク (例: OpeStack) を使用して OpenShift Container Platform をインストールしている場合で、ビルドに障害が発生している場合、ターゲットノードホストの最大伝送単位 (MTU: maximum transmission unit) はプライマリーネットワークインターフェース (例: eth0) の MTU との互換性がない可能性があります。
ビルドが正常に完了するには、データをノードホスト間で渡すために SDN の MTU が eth0 ネットワークの MTU よりも小さくなければなりません。
ip addrコマンドを実行してネットワークの MTU を確認します。# ip addr --- 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000 link/ether fa:16:3e:56:4c:11 brd ff:ff:ff:ff:ff:ff inet 172.16.0.0/24 brd 172.16.0.0 scope global dynamic eth0 valid_lft 168sec preferred_lft 168sec inet6 fe80::f816:3eff:fe56:4c11/64 scope link valid_lft forever preferred_lft forever ---上記のネットワークの MTU は 1500 です。
ノード設定の MTU はネットワーク値よりも小さくなければなりません。ターゲットに設定されたノードホストの
mtuを確認します。# $ oc describe configmaps node-config-infra ... networkConfig: mtu: 1450 networkPluginName: company/openshift-ovs-subnet ...上記のノード設定ファイルでは、
mtu値はネットワーク MTU よりも低くなるため、設定は不要になります。mtu値がこれより高くなる場合はファイルを編集して、値をプライマリーネットワークインターフェースの MTU よりも少なくとも 50 単位分下げてノードサービスを再起動します。これにより、より大きなパケットのデータをノード間で渡すことが可能になります。注記クラスターのノードを変更するには、ノード設定マップを必要に応じて更新します。
node-config.yamlファイルは手動で変更しないようにしてください。
41.9. Pod の Egress のデバッグ
Pod から外部サービスへのアクセスを試行する場合、以下の例のようになります。
curl -kv github.comDNS が適切に解決されていることを確認します。
dig +search +noall +answer github.comこれにより、github サーバーの IP アドレスが返されるはずですが、正しいアドレスが返されていることを確認します。アドレスが返されない場合やお使いのマシンのいずれかのアドレスが返される場合、ローカル DNS サーバーのワイルドカードエントリーに一致している可能性があります。
これを修正するには、ワイルドカードエントリーを持つ DNS サーバーが /etc/resolv.conf の nameserver として一覧表示されていないことを確認するか、または ワイルドカードドメインが search 一覧に一覧表示されていないことを確認する必要があります。
正しい IP アドレスが返される場合、「ローカルネットワークのデバッグ」 の前述のデバッグに関するアドバイスに従ってください。通常、トラフィックはポート 2 の Open vSwitch から iptables ルールおよびルートテーブルを通過するはずです。
41.10. ログの読み取り
次を実行します: journalctl -u atomic-openshift-node.service --boot | less
Output of setup script: 行を検索します。'+' で始まるすべての行については、その下にスクリプト手順が記述されます。この部分で明らかなエラーがあるかどうかを調べます。
スクリプトを追ってみると、Output of adding table=0 という行を見つけることができるはずです。これは OVS ルールであり、エラーは存在しないはずです。
41.11. Kubernetes のデバッグ
iptables -t nat -L を確認して、サービスがローカルマシンでkubeproxy の適切なポートに NAT されていることを確認します。
上記についてはまもなく全面的に変更されます… Kubeproxy は除去され、iptables のみのソリューションに置き換わります。
41.12. 診断ツールを使用したネットワークの問題の検出
クラスター管理者として診断ツールを実行し、共通するネットワークの問題を診断します。
# oc adm diagnostics NetworkCheck診断ツールは、指定したコンポーネントのエラー状態をチェックする一連のチェックを実行します。詳細は、「診断ツール」のセクションを参照してください。
現時点で、診断ツールでは IP フェイルオーバーの問題を診断できません。回避策として、スクリプトをマスターの https://raw.githubusercontent.com/openshift/openshift-sdn/master/hack/ipf-debug.sh で (またはマスターへのアクセスのある別のマシンから) 実行して役に立つデバッグ情報を生成できます。ただし、このスクリプトはサポート対象外です。
デフォルトで、 oc adm diagnostics NetworkCheck はエラーのログを /tmp/openshift/ に記録します。これは --network-logdir オプションで設定できます。
# oc adm diagnostics NetworkCheck --network-logdir=<path/to/directory>41.13. その他の注意点
41.13.1. ingress についての追加情報
- Kube: サービスを NodePort として宣言し、クラスター内のすべてのマシンでそのポートを要求し、kube-proxy およびサポートする Pod にルーティングします。https://kubernetes.io/docs/concepts/services-networking/service/#type-nodeport を参照してください (一部のノードは外部からアクセスできる必要があります)。
- Kube: LoadBalancer として宣言し、独自に 判別したオブジェクトが残りを実行します。
- OS/AE: いずれもルーターを使用します。
41.13.2. TLS ハンドシェイクのタイムアウト
Pod がデプロイに失敗する場合、docker ログで TLS ハンドシェイクのタイムアウトを確認します。
$ docker log <container_id>
...
[...] couldn't get deployment [...] TLS handshake timeout
...この状態は通常はセキュアな接続を確立する際のエラーであり、このエラーは tun0 とプライマリーインターフェース (例: eth0) 間の MTU 値の大きな違い (例: tun0 MTU が 1500 に対し eth0 MTU が 9000 (ジャンボフレーム) である場合) によって引き起こされる可能性があります。
41.13.3. デバッグについての他の注意点
-
(Linux 仮想イーサネットペア) のピアインターフェースは
ethtool -S ifnameで判別できます。 -
ドライバータイプ:
ethtool -i ifname