第3章 Blue-Green デプロイメント
3.1. 概要
このトピックでは、インプレースアップグレード方法に代わるノードホストのアップグレード方法について説明します。
Blue-Green デプロイメント のアップグレード方式はインプレース方式と同様のフローに基づいて実行されます。この場合もマスターおよび etcd サーバーが最初にアップグレードされます。ただし、インプレースアップグレードを実行する代わりに、新規ノードホストの並列環境が作成されます。
この方式では、管理者は新規デプロイメントの検証後、古いノードホストセット (例: 「Blue」デプロイメント) から新規セット (例: 「Green デプロイメント) にトラフィックを切り換えることができます。問題が検出される場合も、古いデプロイメントへのロールバックを簡単かつすぐに実行できます。
Blue-Green がソフトウェアについてのデプロイの証明済みの有効なストラテジーであるものの、トレードオフも常にあります。すべての環境が Blue-Green デプロイメントの適切な実行に必要な同じアップタイム要件を満たしている訳でもなく、これに必要なリソースがある訳でもありません。
OpenShift Container Platform 環境では、Blue-Green デプロイメントに最も適した候補はノードホストです。すべてのユーザープロセスはこれらのシステムで実行され、OpenShift Container Platform インフラストラクチャーの重要な部分もこれらのリソースで自己ホストされます。アップタイムはこれらのワークロードで最も重要であり、Blue-Green デプロイメントによって複雑性が増すとしてもこれを確保できる場合には問題になりません。
この方法の実際の実装は要件に応じて異なります。通常、主な課題は、この方法を容易に実行するための追加の容量を確保することにあります。
図3.1 Blue-Green デプロイメント
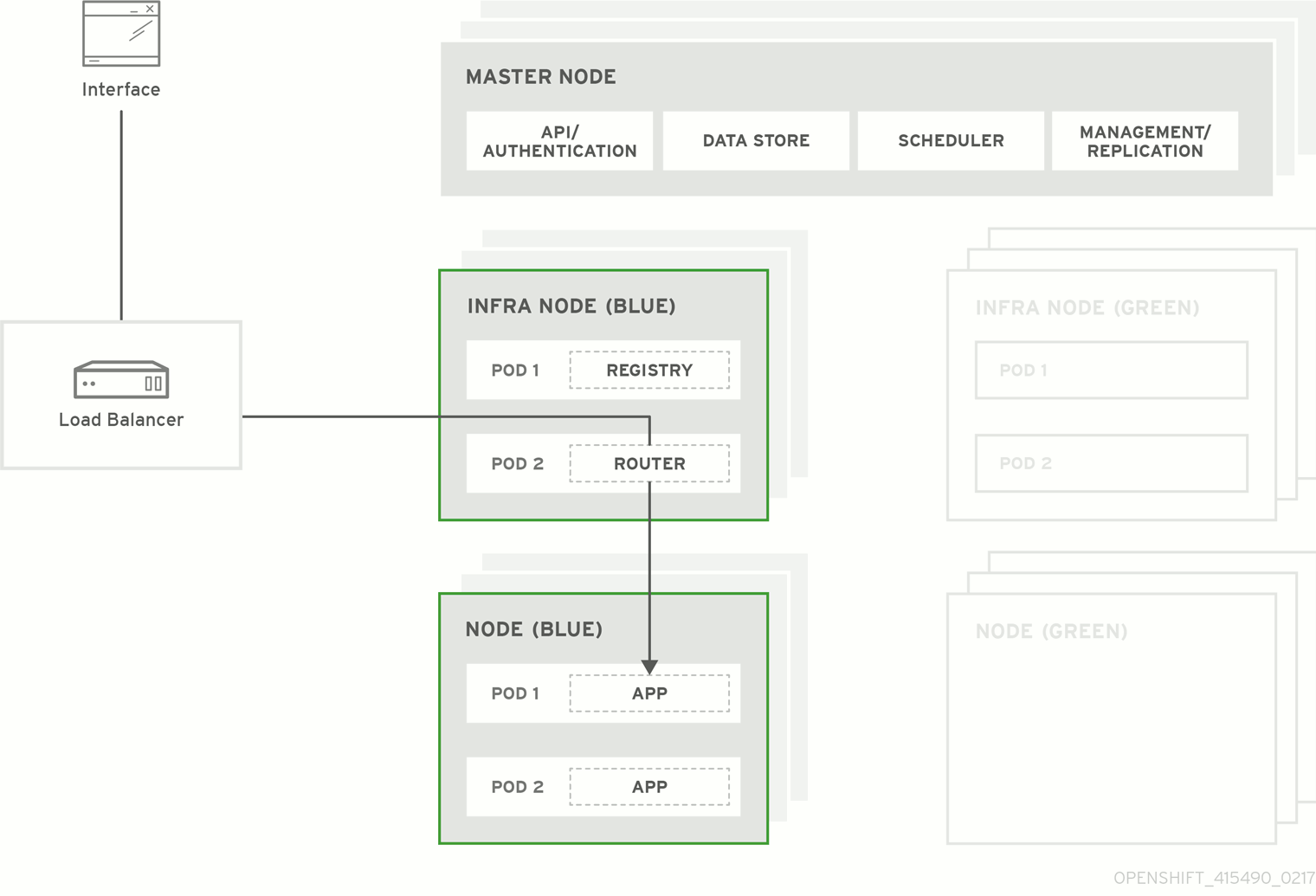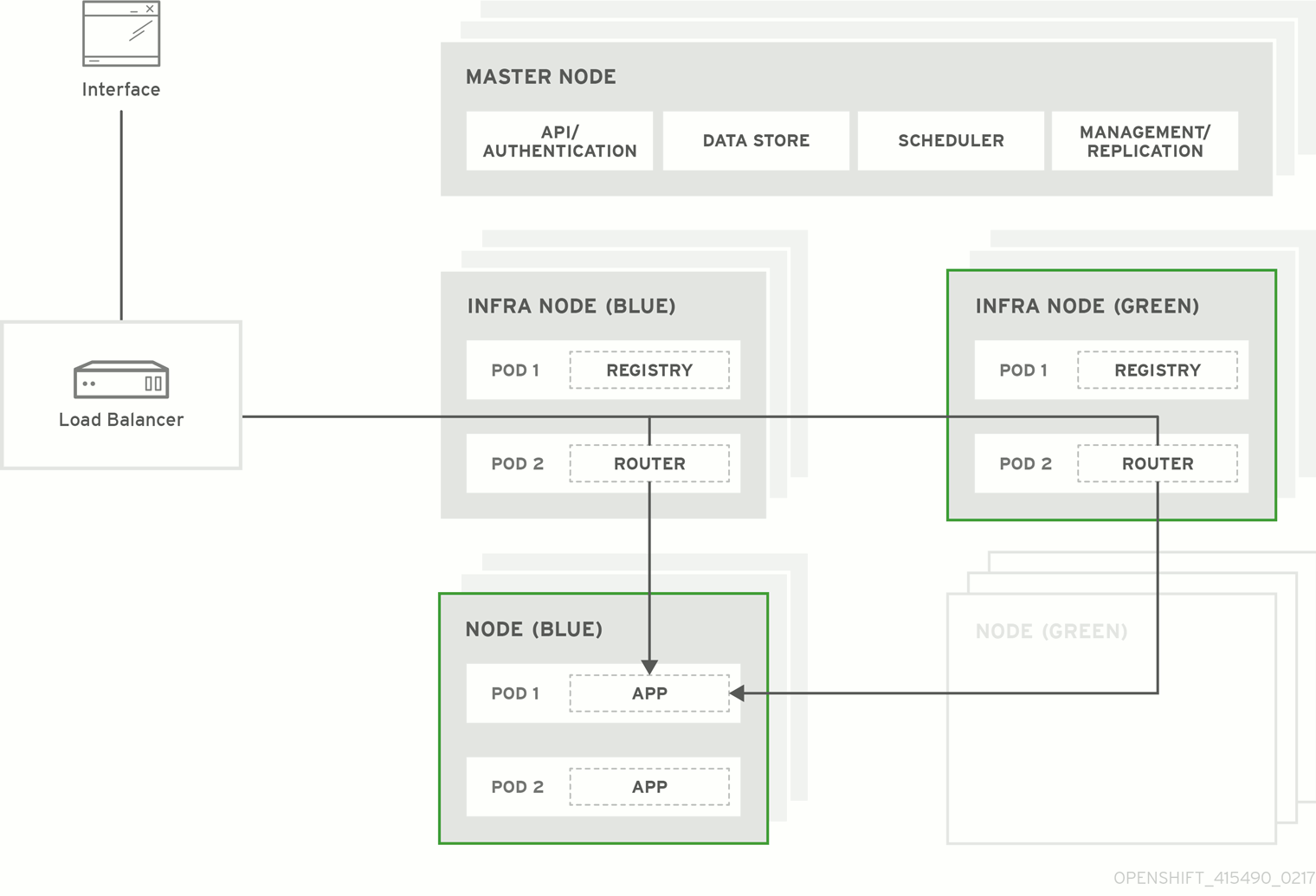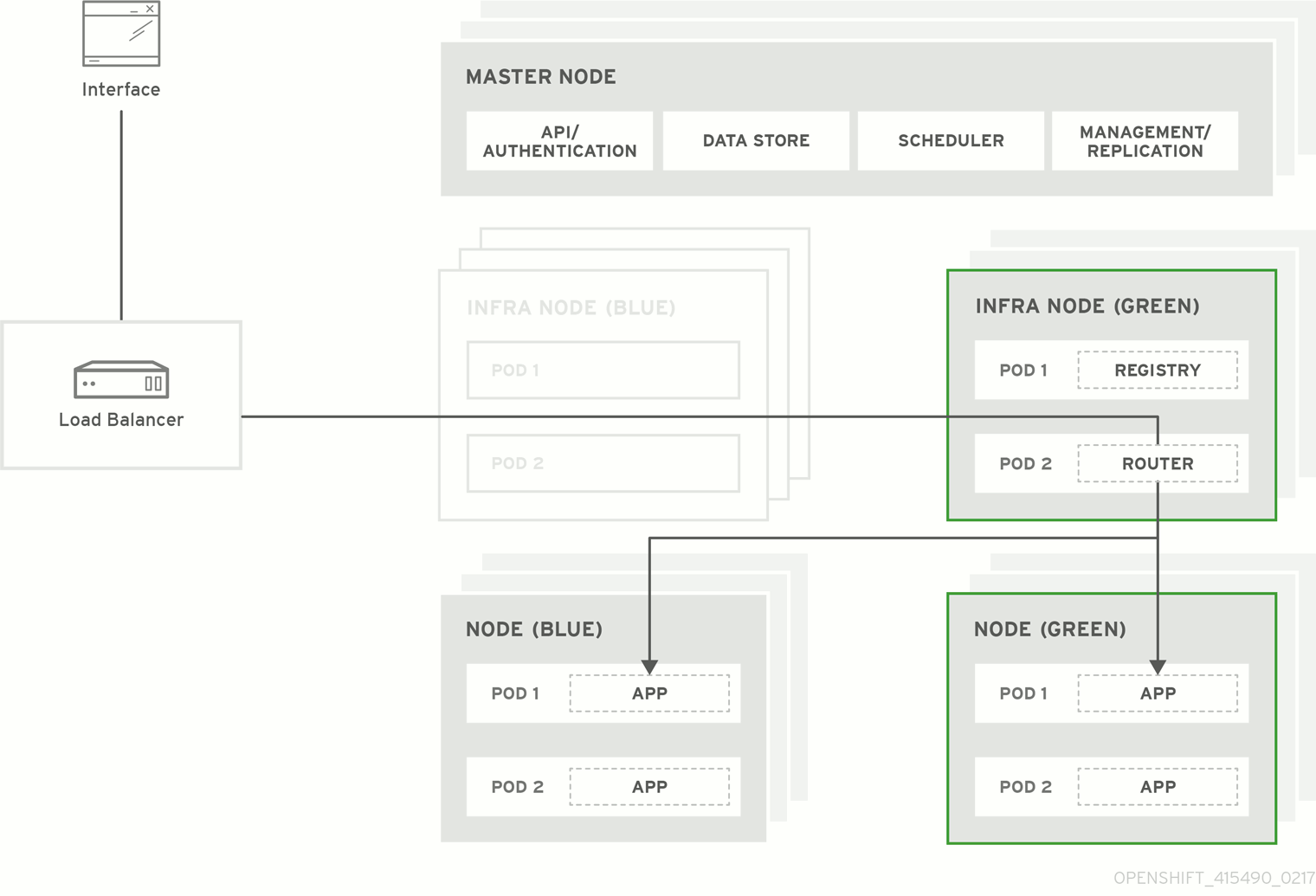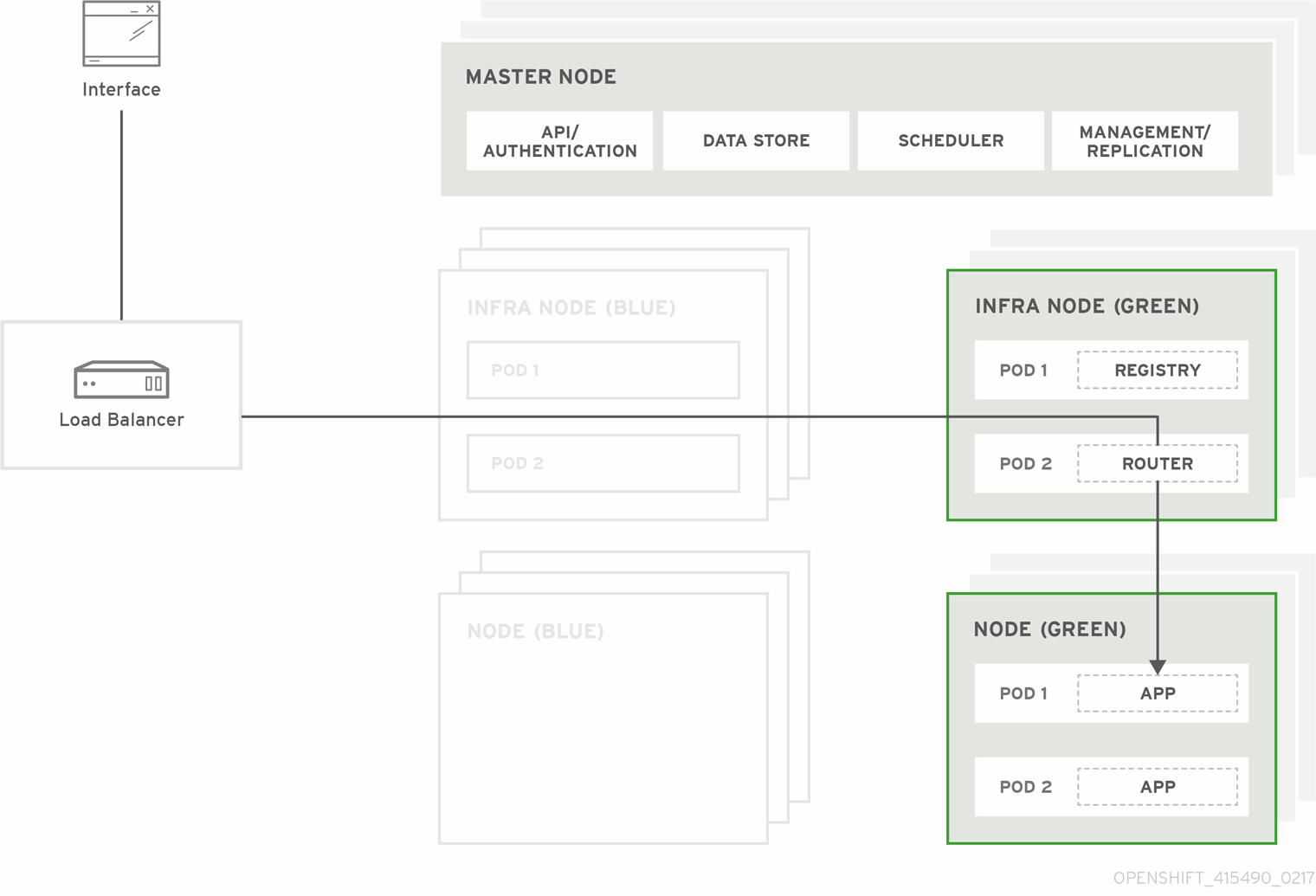
3.2. Blue-Green アップグレードの準備
「インプレースアップグレード」で説明されている方法を使用してマスターと etcd ホストをアップグレードした後に、以下のセクションを参照して残りのノードホストの Blue-Green アップグレードの環境を準備します。
3.2.1. ソフトウェアエンタイトルメントの共有
管理者は Blue-Green デプロイメント間で Red Hat ソフトウェアエンタイトルメントを一時的に共有するか、または Red Hat Satellite などのシステムでインストールコンテンツへのアクセスを提供する必要があります。これは、以前のノードホストからのコンシューマー ID を共有して実行できます。
アップグレードされるそれぞれの古いノードホストで、コンシューマー ID であるその
system identity値を書き留めておいてください。# subscription-manager identity | grep system system identity: 6699375b-06db-48c4-941e-689efd6ce3aa古いノードホストに置き換わるそれぞれの新規 RHEL 7 または RHEL Atomic Host 7 システムで、直前の手順のそれぞれのコンシューマー ID を使用して登録します。
# subscription-manager register --consumerid=6699375b-06db-48c4-941e-689efd6ce3aa
正常なデプロイメントの後に、subscription-manager clean で古いホストを登録解除し、環境が非コンプライアンスの状態にならないようにします。
3.2.2. Blue ノードのラベリング
実稼働の現在のノードホストに blue または green のいずれかのラベルが付けられていることを確認する必要があります。以下の例では、現在の実稼働環境は blue となり、新規の環境は green になります。
クラスターに認識されるノード名の現在の一覧を取得します。
$ oc get nodes現在の実稼働環境内にあるマスター以外のノードホスト (コンピュートノード) および専用のインフラストラクチャーノードに、
color=blueのラベルを付けます。$ oc label node --selector=node-role.kubernetes.io/compute=true,node-role.kubernetes.io/infra=true color=blue上記のコマンドでは、
--selectorフラグを使用して、関連のノードラベルでクラスターのサブセットと一致し、照合したすべての項目にcolor=blueのラベルを付けます。
3.2.3. Green ノードの作成およびラベリング
新規ノードホストと同じ数を、既存のクラスターに追加して、置き換えるノードホストに対する Green 環境を新たに作成します。
「既存のクラスターへのホストの追加」に記載の手順を使用して、新規ノードホストを追加します。この手順にある
[new_nodes]グループで、インベントリーファイルを更新するときにこれらの変数が設定されているようにしてください。-
ノードが「健全」であるとみなされるまで、ワークロードのスケジューリングを遅らせるには (健全性については後の手順で検証します)、新規ノードホストごとに
openshift_schedulable=false変数を設定し、これらが初期の時点でスケジュール対象外となるようにします。 -
新規ホストが OpenShift Container Platform 3.10 に配置されるので、
openshift_node_group_name変数を使用して、ホストエントリーごとにノードグループを設定する必要があります。詳細は、もう一度「ノードグループおよびホストマッピングの定義」を参照してください。
たとえば、以下の新しいノードホストが既存のインベントリーに追加されます。以前のインベントリーに含まれていた項目はすべて残して置く必要があります。
例 [new_nodes] ホストグループ
[new_nodes] node4.example.com openshift_node_group_name='node-config-compute' openshift_schedulable=false node5.example.com openshift_node_group_name='node-config-compute' openshift_schedulable=false node6.example.com openshift_node_group_name='node-config-compute' openshift_schedulable=false infra-node3.example.com openshift_node_group_name='node-config-infra' openshift_schedulable=false infra-node4.example.com openshift_node_group_name='node-config-infra' openshift_schedulable=false-
ノードが「健全」であるとみなされるまで、ワークロードのスケジューリングを遅らせるには (健全性については後の手順で検証します)、新規ノードホストごとに
新規ノードをデプロイしてから、
oc label nodeコマンドを使用して、ノードごとにcolor=greenラベルを適用します。$ oc label node <node_name> color=green
3.2.4. Green ノードの検証
新規 Green ノードが健全な状態にあることを確認します。以下のチェックリストを実行します。
新規ノードがクラスター内で検出され、Ready,SchedulingDisabled 状態にあることを確認します。
$ oc get nodes NAME STATUS ROLES AGE node4.example.com Ready,SchedulingDisabled compute 1dGreen ノードに適切なラベルがあることを確認します。
$ oc get nodes --show-labels NAME STATUS ROLES AGE LABELS node4.example.com Ready,SchedulingDisabled compute 1d beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,color=green,kubernetes.io/hostname=m01.example.com,node-role.kubernetes.io/compute=trueクラスターの診断チェックを実行します。
$ oc adm diagnostics [Note] Determining if client configuration exists for client/cluster diagnostics Info: Successfully read a client config file at '/root/.kube/config' Info: Using context for cluster-admin access: 'default/m01-example-com:8443/system:admin' [Note] Performing systemd discovery [Note] Running diagnostic: ConfigContexts[default/m01-example-com:8443/system:admin] Description: Validate client config context is complete and has connectivity ... [Note] Running diagnostic: CheckExternalNetwork Description: Check that external network is accessible within a pod [Note] Running diagnostic: CheckNodeNetwork Description: Check that pods in the cluster can access its own node. [Note] Running diagnostic: CheckPodNetwork Description: Check pod to pod communication in the cluster. In case of ovs-subnet network plugin, all pods should be able to communicate with each other and in case of multitenant network plugin, pods in non-global projects should be isolated and pods in global projects should be able to access any pod in the cluster and vice versa. [Note] Running diagnostic: CheckServiceNetwork Description: Check pod to service communication in the cluster. In case of ovs-subnet network plugin, all pods should be able to communicate with all services and in case of multitenant network plugin, services in non-global projects should be isolated and pods in global projects should be able to access any service in the cluster. ...
3.3. Green ノードの準備
Pod を Blue 環境から Green に移行するために、必要なコンテナーイメージをプルする必要があります。レジストリーについてのネットワークの待機時間およびロードにより、環境に十分な容量が組み込まれていない場合は遅延が生じる可能性があります。
多くの場合、実行中のシステムへの影響を最小限に抑えるための最良の方法として、新規ノードに到達する新規 Pod デプロイメントをトリガーすることができます。これは、新規イメージストリームをインポートして実行できます。
メジャーリリースの OpenShift Container Platform (および一部の非同期エラータ更新) では、Source-to-Image (S2I) のユーザーのビルダーイメージについての新規イメージストリームを導入しています。インポート時に、「イメージ変更トリガー」で設定されるビルドおよびデプロイメントが自動的に作成されます。
ビルドをトリガーする別の利点として、各種のビルダーイメージ、Pod インフラストラクチャーイメージおよびデプロイヤーなどの多数の補助イメージをすべてのノードホストに効果的に取り込める点があります。Green ノードは 準備完了 (予想される負荷の増加に対応できる状態にある) とみなされると、他のすべてのものが後の手順のノードの退避で移行するため、結果として処理がより迅速になります。
アップグレードプロセスに進む準備ができたら、以下の手順に従って Green ノードを準備します。
Green ノードをスケジュール対象 (Schedulable) に設定し、新規 Pod がそれらのノードにのみ到達するようにします。
$ oc adm manage-node --schedulable=true --selector=color=greenBlue ノードを無効にし、それらをスケジュール対象外 (Unschedulable) に設定して新規 Pod がそれらのノードで実行されないようにします。
$ oc adm manage-node --schedulable=false --selector=color=bluenode-role.kubernetes.io/infra=trueラベルを使用するように、レジストリーのノードセレクターとルーターデプロイメント設定を更新します。これにより、新規の Pod が新しいインフラストラクチャーノードに配置されるように、新しいデプロイメントがトリガーされます。docker-registry デプロイメント設定を編集します。
$ oc edit -n default dc/docker-registrynodeSelectorフィールドを以下のように更新して (引用を含めた"true"と全く同じ形式を使用)、変更を保存します。nodeSelector: node-role.kubernetes.io/infra: "true"router デプロイメント設定を編集します。
$ oc edit -n default dc/routernodeSelectorフィールドを以下のように更新して (引用を含めた"true"と全く同じ形式を使用)、変更を保存します。nodeSelector: node-role.kubernetes.io/infra: "true"新規インフラストラクチャーノードで docker-registry および router Pod が実行中で、Ready の状態であることを確認します。
$ oc get pods -n default -o wide NAME READY STATUS RESTARTS AGE IP NODE docker-registry-2-b7xbn 1/1 Running 0 18m 10.128.0.188 infra-node3.example.com router-2-mvq6p 1/1 Running 0 6m 192.168.122.184 infra-node4.example.com
- デフォルトのイメージストリームとテンプレートを更新します。
- 最新のイメージをインポートします。このプロセスで多数のビルドがトリガーされる点を理解することが重要です。ただし、ビルドは Green ノードで実行されるため、これが Blue デプロイメントのトラフィックに影響を与えることはありません。
クラスター内のすべての namespace (プロジェクト) でのビルドプロセスをモニターするには、以下を実行します。
$ oc get events -w --all-namespaces大規模な環境では、ビルドはほとんど停止することがありません。しかしながら、管理上のイメージのインポートによって大きな増減が生じます。
3.4. Blue ノードの退避および使用停止
大規模デプロイメントでは、退避の調整方法を定めるのに役立つ他のラベルを使用できます。ダウンタイムを防ぐための最も保守的な方法として、一度に 1 つのノードホストを退避する方法があります。
サービスがゾーンの非アフィニティーを使用して複数の Pod で構成されている場合、ゾーン全体を一度に退避できます。使用されるストレージボリュームが新規ゾーンで利用可能であることを確認することは重要です。これについての詳細はクラウドプロバイダーごとに異なる場合があるためです。
OpenShift Container Platform 3.2 以降では、ノードホストの退避はノードサービスの停止時に常にトリガーされます。ノードのラベリングは非常に重要であり、ノードに誤ったラベルが付けられていたり、コマンドが汎用化されたラベルの付いたノードで実行されたりする場合は問題が生じる可能性があります。マスターホストにも color=blue のラベルが付けられている場合には注意が必要です。
アップグレードプロセスに進む準備ができたら、以下の手順に従います。
以下のコマンドで、Blue ノードをすべて退避して削除します。
$ oc adm manage-node --selector=color=blue --evacuate $ oc delete node --selector=color=blue- Blue ノードホストから Pod がなくなり、Blue ノードホストが OpenShift Container Platform から削除されたら、電源をオフにしても問題がありません。安全上の措置として、アップグレードに問題がある場合には、ホストを短時間そのままにしておくと良いでしょう。
- これらのホストを停止する前に、すべての必要なスクリプトまたはファイルが取得されていることを確認します。指定した期間と容量に問題がないことを確認した後に、これらのホストを削除します。