第9章 デプロイメント
9.1. デプロイメントの仕組み
9.1.1. デプロイメントの概要
OpenShift Container Platform デプロイメントでは、一般的なユーザーアプリケーションに対して詳細にわたる管理ができます。デプロイメントは、3 つの異なる API オブジェクトを使用して記述します。
- デプロイメント設定。Pod テンプレートとして、アプリケーションの特定のコンポーネントに対する任意の状態を記述します。
- 1 つまたは複数のレプリケーションコントローラー。このコントローラーには、Pod テンプレートとしてデプロイメント設定のある時点の状態が含まれます。
- 1 つまたは複数の Pod。特定バージョンのアプリケーションのインスタンスを表します。
デプロイメント設定が所有するレプリケーションコントローラーまたは Pod を操作する必要はありません。デプロイメントシステムにより、デプロイメント設定への変更は適切に伝搬されます。既存のデプロイメントストラテジーがユースケースに適さない場合や、デプロイメントのライフサイクルで手動の手順を実行する必要がある場合には、「カスタムストラテジー」の作成を検討してください。
デプロイメント設定を作成すると、レプリケーションコントローラーが、デプロイメント設定の Pod テンプレートとして作成されます。デプロイメント設定が変更されると、最新の Pod テンプレートで新しいレプリケーションコントローラーが作成され、デプロイメントプロセスが実行され、以前のレプリケーションコントローラーにスケールダウンされるか、新しいレプリケーションコントローラーにスケールアップされます。
アプリケーションのインスタンスは、作成時に、サービスローダーバランサーやルーターに対して自動的に追加/削除されます。アプリケーションが 正常なシャットダウン機能 をサポートしている限り、アプリケーションが TERM シグナルを受け取ると、実行中のユーザー接続が通常通り完了できるようにすることができます。
デプロイメントシステムで提供される機能:
- 実行中のアプリケーションのテンプレートとなる デプロイメント設定。
- イベントに対応するために自動デプロイメントを駆動するトリガー。
- 以前のバージョンから新しいバージョンに移行するための、ユーザーによるカスタマイズが可能な ストラテジー。ストラテジーは、デプロイメントプロセスと一般的に呼ばれる Pod 内で実行されます。
- デプロイメントのライフサイクル中のさまざまなポイントで、カスタムの動作を実行するための フック セット。
- デプロイメントが失敗した場合に手動または自動で ロールバック ができるようにするためのアプリケーションのバージョン。
- 手動のレプリケーションのスケーリング および 自動スケーリング。
9.1.2. デプロイメント設定の作成
デプロイメント設定は、OpenShift Container Platform API リソースの deploymentConfig で、他のリソースのように oc コマンドで管理できます。以下は、deploymentConfig リソースの例です。
kind: "DeploymentConfig"
apiVersion: "v1"
metadata:
name: "frontend"
spec:
template:
metadata:
labels:
name: "frontend"
spec:
containers:
- name: "helloworld"
image: "openshift/origin-ruby-sample"
ports:
- containerPort: 8080
protocol: "TCP"
replicas: 5
triggers:
- type: "ConfigChange"
- type: "ImageChange"
imageChangeParams:
automatic: true
containerNames:
- "helloworld"
from:
kind: "ImageStreamTag"
name: "origin-ruby-sample:latest"
strategy:
type: "Rolling"
paused: false
revisionHistoryLimit: 2
minReadySeconds: 0 - 1
- 単純な Ruby アプリケーションを記述する
frontendデプロイメント設定 - 2
frontendのレプリカは 5 つとなります。- 3
- pod テンプレートが変更されるたびに、新規レプリケーションコントローラーが作成されるようにする 設定変更トリガー
- 4
origin-ruby-sample:latestイメージストリームタグの新規バージョンが利用できるようになると、新しいレプリケーションコントローラーが作成されるようにする イメージ変更トリガー- 5
- ローリングストラテジー。このストラテジーは、pod をデプロイするデフォルトの方法で、省略可能です。
- 6
- デプロイメント設定を一時停止します。これにより、すべてのトリガー機能が無効になり、実際にロールアウトされる前に pod テンプレートに複数の変更を加えることができます。
- 7
- 改訂履歴の制限。ロールバック用に保持する、以前のレプリケーションコントローラー数の上限で、省略可能です。省略した場合には、以前のレプリケーションコントローラーは消去されません。
- 8
- (Readiness チェックにパスした後) pod が利用可能とみなされるまでに待機する最低期間 (秒)。デフォルト値は 0 です。
9.2. 基本のデプロイメント操作
9.2.1. デプロイメントの開始
Web コンソールまたは CLI を使用して手動で新規デプロイメントプロセスを開始できます。
$ oc rollout latest dc/<name>デプロイメントプロセスが進行中の場合には、このコマンドを実行すると、メッセージが表示され、新規レプリケーションコントローラーがデプロイされません。
9.2.2. デプロイメントの表示
アプリケーションで利用可能な全リビジョンの基本情報を取得します。
$ oc rollout history dc/<name>このコマンドでは、現在実行中のデプロイメントプロセスなど、指定したデプロイメント設定用に、最近作成されたすべてのレプリケーションコントローラーの詳細を表示します。
--revision フラグを使用すると、リビジョン固有の詳細情報が表示されます。
$ oc rollout history dc/<name> --revision=1デプロイメント設定および最新のリビジョンに関する詳細情報は、以下を実行してください。
$ oc describe dc <name>「Web コンソール」では、Browse タブにデプロイメントが表示されます。
9.2.3. デプロイメントのロールバック
ロールバックすると、アプリケーションを以前のリビジョンに戻します。この操作は、REST API、CLI または Web コンソールで実行できます。
最後にデプロイして成功した設定のリビジョンにロールバックするには以下を実行します。
$ oc rollout undo dc/<name>
デプロイして設定にテンプレートは、undo コマンドで指定してデプロイメントのリビジョンと一致するように元に戻され、新しいレプリケーションコントローラーが起動します。--to-revision でリビジョンが指定されていない場合には、最後に成功したデプロイメントのバージョンが使用されます。
ロールバックの完了直後に新規デプロイメントプロセスが誤って開始されないように、ロールバックの一部として、デプロイメント設定のイメージ変更トリガーは無効になります。イメージ変更トリガーをもう一度有効にするには、以下を実行します。
$ oc set triggers dc/<name> --auto最新のデプロイメントプロセスに失敗した場合に、デプロイメント設定は、最後に成功したリビジョンの設定に自動的にロールバックする機能をサポートします。この場合に、デプロイに失敗した最新のテンプレートはシステムで修正されないので、設定の修正はユーザーが行う必要があります。
9.2.4. コンテナー内でのコマンドの実行
コンテナーにコマンドを追加して、イメージの ENTRYPOINT を却下して、コンテナーの起動動作を変更することができます。これは、指定したタイミングでデプロイメントごとに 1 回実行できる ライフサイクルフック とは異なります。
command パラメーターを、デプロイメントの spec フィールドを追加します。commandコマンドを変更する args フィールドも追加できます (または command コマンドが存在しない場合には、ENTRYPOINT)。
...
spec:
containers:
-
name: <container_name>
image: 'image'
command:
- '<command>'
args:
- '<argument_1>'
- '<argument_2>'
- '<argument_3>'
...
たとえば、-jar および /opt/app-root/springboots2idemo.jar 引数を指定して、java コマンドを実行します。
...
spec:
containers:
-
name: example-spring-boot
image: 'image'
command:
- java
args:
- '-jar'
- /opt/app-root/springboots2idemo.jar
...9.2.5. デプロイメントログの表示
指定のデプロイメント設定に関する最新リビジョンのログをストリームします。
$ oc logs -f dc/<name>
最新のリビジョンが実行中または失敗した場合には、oc logs は、pod のデプロイを行うプロセスのログが返されます。成功した場合には、oc logs は、アプリケーションの pod からのログを返します。
以前に失敗したデプロイメントプロセスからのログを表示することも可能です。ただし、これらのプロセス (以前のレプリケーションコントローラーおよびデプロイヤーの Pod) が存在し、手動でプルーニングまたは削除されていない場合に限ります。
$ oc logs --version=1 dc/<name>ログの取得に関する他のオプションについては、以下を参照してください。
$ oc logs --help9.2.6. デプロイメントトリガーの設定
デプロイメント設定には、クラスター内のイベントに対応する新規デプロイメントプロセスの作成を駆動するトリガーを含めることができます。
トリガーがデプロイメント設定に定義されていない場合は、ConfigChange トリガーがデフォルトで追加されます。トリガーが空のフィールドとして定義されている場合には、デプロイメントは 手動で起動 する必要があります。
9.2.6.1. 設定変更トリガー
ConfigChange トリガーにより、デプロイメント設定の Pod テンプレートに変更があると検出されるたびに、新規のレプリケーションコントローラーが作成されます。
ConfigChange トリガーがデプロイメント設定に定義されている場合は、デプロイメント設定自体が作成された直後に、最初のレプリケーションコントローラーは自動的に作成され、一時停止されません。
例9.1 ConfigChange トリガー
triggers:
- type: "ConfigChange"9.2.6.2. ImageChange トリガー
ImageChange トリガーにより、「イメージストリームタグ」の内容が変更されるたびに、(イメージの新規バージョンがプッシュされるタイミングで) 新規レプリケーションコントローラーが作成されます。
例9.2 ImageChange トリガー
triggers:
- type: "ImageChange"
imageChangeParams:
automatic: true
from:
kind: "ImageStreamTag"
name: "origin-ruby-sample:latest"
namespace: "myproject"
containerNames:
- "helloworld"- 1
imageChangeParams.automaticフィールドがfalseに設定されると、トリガーが無効になります。
上記の例では、origin-ruby-sample イメージストリームの latest タグの値が変更され、新しいイメージの値がデプロイメント設定の helloworld コンテナーに指定されている現在のイメージと異なる場合に、helloworld コンテナーの新規イメージを使用して、新しいレプリケーションコントローラーが 作成されます。
ImageChange とライガーがデプロイメント設定 (ConfigChange トリガーと automatic=false、または automatic=true) で定義されていて、ImageChange トリガーで参照されている ImageStreamTag がまだ存在していない場合には、ビルドにより、イメージが、ImageStreamTag にインポートまたはプッシュされた直後に初回のデプロイメントプロセスが自動的に開始されます。
9.2.6.2.1. コマンドラインの使用
oc set triggers コマンドでは、デプロイメント設定にデプロイメントトリガーを設定するために使用できます。上記の例では、次のコマンドを使用して ImageChangeTrigger を設定できます。
$ oc set triggers dc/frontend --from-image=myproject/origin-ruby-sample:latest -c helloworld詳細は、以下を参照してください。
$ oc set triggers --help9.2.7. デプロイメントリソースの設定
このリソースは管理者が OpenShift Container Platform 3.10 でテクノロジープレビューとして提供されている一時ストレージを有効化した場合にのみ利用できます。この機能はデフォルトでは無効になっています。
デプロイメントは、ノードでリソース (メモリーおよび一時ストレージ) を消費する Pod を使用して完了します。デフォルトでは、Pod はバインドされていないノードのリソースを消費しますが、プロジェクトにデフォルトでコンテナー制限が指定されている場合には、Pod はその上限分までリソースを消費します。
デプロイメント設定の一部にリソース制限を指定して、リソースの使用を制限することも可能です。デプロイメントリソースは、Recreate (再作成)、Rolling (ローリング) または Custom (カスタム) のデプロイメントストラテジーで使用できます。
以下の例では、resources、cpu、memory および ephemeral-storage はそれぞれオプションです。
type: "Recreate"
resources:
limits:
cpu: "100m"
memory: "256Mi"
ephemeral-storage: "1Gi" ただし、クォータがプロジェクトに定義されている場合には、以下の 2 つの項目のいずれかが必要です。
明示的な
requestsで設定したresourcesセクション :type: "Recreate" resources: requests:1 cpu: "100m" memory: "256Mi" ephemeral-storage: "1Gi"- 1
requestsオブジェクトは、クォータ内のリソース一覧に対応するリソース一覧を含みます。
コンピュートリソースや、要求と制限の相違点についての詳しい情報は、「クォータと制限の範囲」を参照してください。
-
プロジェクトに定義されている「制限の範囲」。
LimitRangeオブジェクトからのデフォルト値がデプロイメントプロセス中に作成される Pod に適用されます。
適用されない場合は、クォータ基準を満たさないために失敗したというメッセージを表示し、デプロイメントの Pod 作成は失敗します。
9.2.8. 手動のスケーリング
ロールバック以外に、Web コンソールまたは oc scale コマンドを使用して、レプリカの数を細かく管理できます。たとえば、以下のコマンドは、デプロイメント設定の frontend を 3 に設定します。
$ oc scale dc frontend --replicas=3
レプリカの数は最終的に、デプロイメント設定の frontend で設定した希望のデプロイメントの状態と現在のデプロイメントの状態に伝搬されます。
Pod は oc autoscale コマンドを使用して自動スケーリングすることも可能です。詳細は「Pod の自動スケーリング」を参照してください。
9.2.9. 特定のノードへの Pod の割り当て
ラベル付きのノードと合わせてノードセレクターを使用し、Pod の割当を制御することができます。
OpenShift Container Platform 管理者は、「クラスターをインストールする時」 または 「インストール後にノードを追加する時」にラベルを割り当てることができます。
クラスターの管理者は、プロジェクトに対して「デフォルトのノードセレクターを設定して」、特定のノードに Pod の配置を制限できます。OpenShift Container Platform の開発者は、Pod 設定にノードセレクターを設定して、ノードをさらに制限することができます。
Pod の作成時にノードセレクターを追加するには、Pod の設定を編集し、nodeSelector の値を追加します。以下の内容は、単一の Pod 設定や、Pod テンプレートに追加できます。
apiVersion: v1
kind: Pod
spec:
nodeSelector:
disktype: ssd
...ノードセレクターの割当時に作成された Pod は、指定したラベルのノードに割り当てられます。
ここで指定したラベルは、「クラスター管理者が追加した」ラベルと併用されます。
たとえば、プロジェクトに type=user-node と region=east のラベルがクラスター管理者により追加され、上記の disktype: ssd ラベルを Pod に追加した場合に、Pod は 3 つのラベルすべてが含まれるノードにのみスケジュールされます。
ラベルには値を 1 つしか設定できないので、region=east が管理者によりデフォルト設定されている Pod 設定に region=west のノードセレクターを設定すると、Pod が全くスケジュールされなくなります。
9.2.10. 異なるサービスアカウントでの Pod の実行
デフォルト以外のサービスアカウントで Pod を実行できます。
デプロイメント設定を編集します。
$ oc edit dc/<deployment_config>serviceAccountとserviceAccountNameパラメーターをspecフィールドに追加し、使用するサービスアカウントを指定します。spec: securityContext: {} serviceAccount: <service_account> serviceAccountName: <service_account>
9.2.11. Web コンソールを使用してデプロイメント設定にシークレットを追加する手順
プライベートリポジトリーにアクセスできるように、デプロイメント設定にシークレットを追加します。
- 新規の OpenShift Container Platform プロジェクトを作成します。
- プライベートのイメージリポジトリーにアクセスするための認証情報が含まれる シークレットを作成 します。
- デプロイメント設定を作成します。
- デプロイメント設定のエディターページまたは、「web コンソール」の fromimage ページで、プルシークレット を設定します。
- Save ボタンをクリックします。
9.3. デプロイメントストラテジー
9.3.1. デプロイメントストラテジーの概要
アプリケーションを変更またはアップグレードする手段として、デプロイメントストラテジーを使用します。デプロイメントストラテジーの目的は、ユーザーには改善が加えられていることが分からないように、ダウンタイムなしに変更を加えることです。
最も一般的なストラテジーとして blue-green デプロイメント を使用します。新規バージョン (blue バージョン) を、テストと評価用に起動しつつ、安定版 (green バージョン) をユーザーが継続して使用します。準備が整ったら、Blue バージョンに切り替えられます。問題が発生した場合には、Green バージョンに戻すことができます。
一般的な別のストラテジーとして、A/B バージョンがいずれも、同時にアクティブな状態で、A バージョンを使用するユーザーも、B ユーザーを使用するユーザーもいるという方法です。これは、ユーザーインターフェースや他の機能の変更をテストして、ユーザーのフィードバックを取得するために使用できます。また、ユーザーに対する問題の影響が限られている場合に、実稼働のコンテキストで操作が正しく行われていることを検証するのに使用することもできます。
カナリアリリースデプロイメントでは、新規バージョンをテストしますが、問題が検出されると、すぐに以前のバージョンにフォールバックされます。これは、上記のストラテジーどちらでも実行できます。
ルートベースのデプロイメントストラテジーでは、サービス内の Pod 数はスケーリングされません。希望とするパフォーマンスの特徴を維持するには、デプロイメント設定をスケーリングする必要があります。
デプロイメントストラテジーを選択する場合に、考慮するべき事項があります。
- 長期間実行される接続は正しく処理される必要があります。
- データベースの変換は複雑になる可能性があり、アプリケーションと共に変換し、ロールバックする必要があります。
- アプリケーションがマイクロサービスと従来のコンポーネントを使用するハイブリッドの場合には、移行の完了時にダウンタイムが必要になる場合があります。
- これを実行するためのインフラストラクチャーが必要です。
- テスト環境が分離されていない場合は、新規バージョンと以前のバージョン両方が破損してしまう可能性があります。
通常、エンドユーザーはルーターが取り扱うルート経由でアプリケーションにアクセスするので、デプロイメントストラテジーは、デプロイメント設定機能またはルーティング機能にフォーカスできます。
デプロイメント設定にフォーカスするストラテジーは、アプリケーションを使用するすべてのルートに影響を与えます。ルーター機能を使用するストラテジーは個別のルートをターゲットに設定します。
デプロイメントストラテジーの多くは、デプロイメント設定でサポートされ、追加のストラテジーはルーター機能でサポートされます。このセクションでは、デプロイメント設定をベースにするストラテジーについて説明します。
- ローリングストラテジー およびカナリアリリースデプロイメント
- 再作成ストラテジー
- カスタムストラテジー
- ルートを使用した Blue-Green デプロイメント
- ルートを使用した A/B デプロイメント およびカナリアリリースデプロイメント
- 1 サービス、複数デプロイメント設定
ローリングストラテジー は、ストラテジーがデプロイメント設定に指定されていない場合にデフォルトで使用するストラテジーです。
デプロイメントストラテジーは、Readiness チェック を使用して、新しい Pod の使用準備ができているかを判断します。Readiness チェックに失敗すると、デプロイメント設定は、タイムアウトするまで pod の実行を再試行します。デフォルトのタイムアウトは、10m で、値は dc.spec.strategy.*params の TimeoutSeconds で設定します。
9.3.2. ローリングストラテジー
ローリングデプロイメントは、以前のバージョンのアプリケーションインスタンスを、新しいバージョンのアプリケーションインスタンスに徐々に置き換えます。ローリングデプロイメントは、新規 Pod がreadiness チェック で ready になるまで待機してから、以前のコンポーネントをスケールダウンします。大きな問題が発生した場合には、ローリングデプロイメントは中断される可能性があります。
9.3.2.1. カナリアリリースデプロイメント
OpenShift Container Platform のローリングデプロイメントは、カナリアリリース デプロイメントで、新規バージョン (カナリアリリース) をテストしてから、以前の全インスタンスを置き換えます。Readiness チェックに成功しない場合には、カナリアリリースのインスタンスが削除され、デプロイメント設定は自動的にロールバックされます。Readiness チェックはアプリケーションコードの一部で、新規インスタンスの使用準備が確実に整うように、必要に応じて改善されます。より複雑なアプリケーションチェックを実装する必要がある場合には (新規インスタンスに実際のユーザーワークロードを送信するなど)、カスタムデプロイメントの実装や、blue-green デプロイメントストラテジーの使用を検討してください。
9.3.2.2. ローリングデプロイメントの使用のタイミング
- ダウンタイムを発生させずに、アプリケーションの更新を行う場合
- 以前のコードと新しいコードの同時実行がアプリケーションでサポートされている場合
ローリングデプロイメントとは、以前のバージョンと新しいバージョンのコードを同時に実行するという意味です。これは通常、アプリケーションで「N-1 互換性」に対応する必要があります。
以下は、ローリングストラテジーの例です。
strategy:
type: Rolling
rollingParams:
updatePeriodSeconds: 1
intervalSeconds: 1
timeoutSeconds: 120
maxSurge: "20%"
maxUnavailable: "10%"
pre: {}
post: {}- 1
- 各 Pod が次に更新されるまで待機する時間。指定されていない場合、デフォルト値は
1となります。 - 2
- 更新してからデプロイメントステータスをポーリングするまでの間待機する時間。指定されていない場合、デフォルト値は
1となります。 - 3
- イベントのスケーリングを中断するまでの待機時間。この値はオプションです。デフォルトは
600です。ここでの 中断 とは、自動的に以前の完全なデプロイメントにロールバックされるという意味です。 - 4
maxSurgeはオプションで、指定されていない場合には、デフォルト値は25%となります。以下の手順の次にある情報を参照してください。- 5
maxUnavailableはオプションで、指定されていない場合には、デフォルト値は25%となります。以下の手順の次にある情報を参照してください。- 6
ローリングストラテジーは以下を行います。
-
preライフサイクルフックを実行します。 - サージ数に基づいて新しいレプリケーションコントローラーをスケールアップします。
- 最大利用不可数に基づいて以前のレプリケーションコントローラーをスケールダウンします。
- 新しいレプリケーションコントローラーが希望のレプリカ数に到達して、以前のレプリケーションコントローラーの数がゼロになるまで、このスケーリングを繰り返します。
-
postライフサイクルフックを実行します。
スケールダウン時には、ローリングストラテジーは Pod の準備ができるまで待機し、スケーリングを行うことで可用性に影響が出るかどうかを判断します。Pod をスケールアップしたにもかかわらず、準備が整わない場合には、デプロイメントプロセスは最終的にタイムアウトして、デプロイメントに失敗します。
maxUnavailable パラメーターは、更新時に利用できない Pod 最大数で、maxSurge パラメーターは、元の pod 数を超えてスケジュールできる最大数のことです。いずれのパラメーターも、パーセント (例: 10%) または絶対値 (例: 2) を指定できます。これらのパラメーターのデフォルト値はいずれも、25% です。
以下のパラメーターを使用して、デプロイメントの可用性やスピードを調整できます。以下に例を示します。
-
maxUnavailable=0およびmaxSurge=20%が指定されていると、更新時および急速なスケールアップ時に完全なキャパシティーが維持されるようになります。 -
maxUnavailable=10%およびmaxSurge=0が指定されていると、追加のキャパシティーを使用せずに更新が実行されます (インプレース更新)。 -
maxUnavailable=10%およびmaxSurge=10%が指定されている場合には、キャパシティーが一部失われる可能性がありますが、迅速にスケールアップおよびスケールダウンを行います。
一般的に、迅速にロールアウトする場合は maxSurge を使用します。リソースのクォータを考慮して、一部に利用不可の状態が発生してもかまわない場合には、maxUnavailable を使用します。
9.3.2.3. ローリングの例
OpenShift Container Platform では、ローリングデプロイメントはデフォルト設定です。ローリングアップデートを行うには、以下の手順に従います。
DockerHub にあるデプロイメントイメージの例を基にアプリケーションを作成します。
$ oc new-app openshift/deployment-exampleルーターをインストールしている場合は、ルートを使用してアプリケーションを利用できるようにしてください (または、サービス IP を直接使用してください)。
$ oc expose svc/deployment-exampledeployment-example.<project>.<router_domain>でアプリケーションを参照し、v1 イメージが表示されることを確認します。レプリカが最大 3 つになるまで、デプロイメント設定をスケーリングします。
$ oc scale dc/deployment-example --replicas=3新しいバージョンの例を
latestとタグ付けして、新規デプロイメントを自動的にトリガーします。$ oc tag deployment-example:v2 deployment-example:latest- ブラウザーで、v2 イメージが表示されるまでページを更新します。
CLI を使用している場合は、以下のコマンドで、バージョン 1 に Pod がいくつあるか、バージョン 2 にはいくつあるかを表示します。Web コンソールでは、徐々に v2 に追加される Pod、v1 から削除される Pod が確認できるはずです。
$ oc describe dc deployment-example
デプロイメントプロセスで、新しいレプリケーションコントローラーが漸増的にスケールアップします。新しい Pod が (readiness チェックをパスして) ready とマークされたら、デプロイメントプロセスが継続されます。Pod の準備が整わない場合には、プロセスが中断され、デプロイメント設定が以前のバージョンにロールバックされます。
9.3.3. 再作成ストラテジー
再作成ストラテジーは、基本的なロールアウト動作で、デプロイメントプロセスにコードを挿入する ライフサイクルフック をサポートします。
以下は、再作成ストラテジーの例です。
strategy:
type: Recreate
recreateParams:
pre: {}
mid: {}
post: {}再作成ストラテジーは以下を行います。
-
preライフサイクルフックを実行します。 - 以前のデプロイメントをゼロにスケールダウンします。
-
midライフサイクルフックを実行します。 - 新規デプロイメントをスケールアップします。
-
postライフサイクルフックを実行します。
スケールアップ中に、デプロイメントのレプリカ数が複数ある場合は、デプロイメントの最初のレプリカが準備できているかどうかが検証されてから、デプロイメントが完全にスケールアップされます。最初のレプリカの検証に失敗した場合には、デプロイメントは失敗とみなされます。
9.3.3.1. 再作成デプロイメントの使用のタイミング
- 新規コードを起動する前に、移行または他のデータの変換を行う必要がある場合
- 以前のバージョンと新しいバージョンのアプリケーションコードの同時使用をサポートしていない場合
- 複数のレプリカ間での共有がサポートされていない、RWO ボリュームを使用する場合
再作成デプロイメントでは、短い期間にアプリケーションのインスタンスが実行されなくなるので、ダウンタイムが発生します。ただし、以前のコードと新しいコードは同時には実行されません。
9.3.4. カスタムストラテジー
カスタムストラテジーでは、独自のデプロイメントの動作を提供できるようになります。
以下は、カスタムストラテジーの例です。
strategy:
type: Custom
customParams:
image: organization/strategy
command: [ "command", "arg1" ]
environment:
- name: ENV_1
value: VALUE_1
上記の例では、organization/strategy コンテナーイメージにより、デプロイメントの動作が提供されます。オプションの command 配列は、イメージの Dockerfile で指定した CMD ディレクティブを上書きします。指定したオプションの環境変数は、ストラテジープロセスの実行環境に追加されます。
さらに、OpenShift Container Platform は以下の環境変数もデプロイメントプロセスに提供します。
| 環境変数 | 説明 |
|---|---|
|
|
新規デプロイメント名 (レプリケーションコントローラー) |
|
|
新規デプロイメントの namespace |
新規デプロイメントのレプリカ数は最初はゼロです。ストラテジーの目的は、ユーザーのニーズに最適な仕方で対応するロジックを使用して新規デプロイメントをアクティブにすることにあります。
詳細は、高度なデプロイメントストラテジーを参照してください。
または customParams を使用して、カスタムのデプロイメントロジックを、既存のデプロイメントストラテジーに挿入します。カスタムのシェルロジックを指定して、openshift-deploy バイナリーを呼び出します。カスタムのデプロイヤーコンテナーイメージを用意する必要はありません。ここでは、代わりにデフォルトの OpenShift Container Platform デプロイヤーイメージが使用されます。
strategy:
type: Rolling
customParams:
command:
- /bin/sh
- -c
- |
set -e
openshift-deploy --until=50%
echo Halfway there
openshift-deploy
echo Completeこのストラテジーの設定では、以下のようなデプロイメントになります。
Started deployment #2
--> Scaling up custom-deployment-2 from 0 to 2, scaling down custom-deployment-1 from 2 to 0 (keep 2 pods available, don't exceed 3 pods)
Scaling custom-deployment-2 up to 1
--> Reached 50% (currently 50%)
Halfway there
--> Scaling up custom-deployment-2 from 1 to 2, scaling down custom-deployment-1 from 2 to 0 (keep 2 pods available, don't exceed 3 pods)
Scaling custom-deployment-1 down to 1
Scaling custom-deployment-2 up to 2
Scaling custom-deployment-1 down to 0
--> Success
Completeカスタムデプロイメントストラテジーのプロセスでは、OpenShift Container Platform API または Kubernetes API へのアクセスが必要な場合には、ストラテジーを実行するコンテナーは、認証用のコンテナーで利用可能なサービスアカウントのトークンを使用できます。
9.3.5. ライフサイクルフック
再作成 および ローリング ストラテジーは、ストラテジーで事前に定義したポイントでデプロイメントプロセスに動作を挿入できるようにするライフサイクルフックをサポートします。
以下は pre ライフサイクルフックの例です。
pre:
failurePolicy: Abort
execNewPod: {} - 1
execNewPodは Pod ベースのライフサイクルフック です。
フックにはすべて、フックに問題が発生した場合にストラテジーが取るべきアクションを定義する failurePolicy が含まれます。
|
|
フックに失敗すると、デプロイメントプロセスも失敗とみなされます。 |
|
|
フックの実行は、成功するまで再試行されます。 |
|
|
フックの失敗は無視され、デプロイメントは続行されます。 |
フックには、フックの実行方法を記述するタイプ固有のフィールドがあります。現在、フックタイプとしてサポートされているのは Pod ベースのフック のみで、このフックは execNewPod フィールドで指定します。
9.3.5.1. Pod ベースのライフサイクルフック
Pod ベースのライフサイクルフックは、デプロイメント設定のテンプレートをベースとする新しい Pod でフックコードを実行します。
以下のデプロイメント設定例は簡素化されており、この例では「ローリングストラテジー」を使用します。トリガーおよびその他の詳細は省略し、簡潔化しています。
kind: DeploymentConfig
apiVersion: v1
metadata:
name: frontend
spec:
template:
metadata:
labels:
name: frontend
spec:
containers:
- name: helloworld
image: openshift/origin-ruby-sample
replicas: 5
selector:
name: frontend
strategy:
type: Rolling
rollingParams:
pre:
failurePolicy: Abort
execNewPod:
containerName: helloworld
command: [ "/usr/bin/command", "arg1", "arg2" ]
env:
- name: CUSTOM_VAR1
value: custom_value1
volumes:
- data
この例では pre フックは、helloworld からの openshift/origin-ruby-sample イメージを使用して新規 Pod で実行されます。フック Pod には以下のプロパティーが設定されます。
-
フックコマンドは
/usr/bin/command arg1 arg2となります。 -
フックコンテナーには
CUSTOM_VAR1=custom_value1環境変数が含まれます。 -
フックの失敗ポリシーは
Abortで、フックが失敗するとデプロイメントプロセスも失敗します。 -
フック Pod は、設定 Pod から
dataボリュームを継承します。
9.3.5.2. コマンドラインの使用
oc set deployment-hook コマンドは、デプロイメント構成にデプロイメントフックを設定するのに使用できます。上記の例では、以下のコマンドでプリデプロイメントフックを設定できます。
$ oc set deployment-hook dc/frontend --pre -c helloworld -e CUSTOM_VAR1=custom_value1 \
-v data --failure-policy=abort -- /usr/bin/command arg1 arg29.4. 高度なデプロイメントストラテジー
9.4.1. 高度なデプロイメントストラテジー
デプロイメントストラテジー は、アプリケーションを進化させる手段として使用します。一部のストラテジーは デプロイメント設定 を使用して変更を加えます。これらの変更は、アプリケーションを解決する全ルートのユーザーに表示されます。ここで説明している他のストラテジーは、ルート機能を使用して固有のルートに影響を与えます。
9.4.2. Blue-Green デプロイメント
Blue-green デプロイメントでは、同時に 2 つのバージョンを実行し、実稼働版 (green バージョン) からより新しいバージョン (blue バージョン) にトラフィックを移動します。ルートで ローリングストラテジー または切り替えサービスを使用できます。
多くのアプリケーションは永続データに依存するので、N-1 互換性 をサポートするアプリケーションが必要です。つまり、データを共有して、データ層を 2 つ作成し、データベース、ストアまたはディスク間のライブマイグレーションを実装します。
新規バージョンのテストに使用するデータについて考えてみてください。実稼働データの場合には、新規バージョンのバグにより、実稼働版を破損してしまう可能性があります。
9.4.2.1. Blue-Green デプロイメントの使用
Blue-Green デプロイメントは 2 つのデプロイメント設定を使用します。いずれも実行され、実稼働のデプロイメントはルートが指定するルートによって変わります。この際、各デプロイメント設定は異なるサービスに公開されます。新しいバージョンに新規ルートを作成して、これをテストすることができます。準備が整うと、実稼働ルートのサービスを新規サービスを参照するように変更し、新しい blue バージョンがライブになります。
必要に応じて以前のバージョンにサービスを切り替えて、以前の green バージョンにロールバックすることができます。
ルートと 2 つのサービスの使用
以下の例は、2 つのデプロイメント設定を行います。1 つは、安定版 (green バージョン) で、もう 1 つは新規バージョン (blue バージョン) です。
ルートは、サービスを参照し、いつでも別のサービスを参照するように変更できます。開発者は、実稼働トラフィックが新規サービスにルーティングされる前に、新規サービスに接続して、コードの新規バージョンをテストできます。
ルートは、web (HTTP および HTTPS) トラフィックを対象としているので、この手法は Web アプリケーションに最適です。
アプリケーションサンプルを 2 つ作成します。
$ oc new-app openshift/deployment-example:v1 --name=example-green $ oc new-app openshift/deployment-example:v2 --name=example-blue上記のコマンドにより、独立したアプリケーションコンポーネントが 2 つ作成されます。1 つは、
example-greenサービスで v1 イメージを実行するコンポーネントと、もう 1 つはexample-blueサービスで v2 イメージを実行するコンポーネントです。以前のサービスを参照するルートを作成します。
$ oc expose svc/example-green --name=bluegreen-examplebluegreen-example.<project>.<router_domain>で、アプリケーションを参照して v1 イメージが表示されることを確認します。注記OpenShift Container Platform v3.0.1 以前のバージョンでは、このコマンドは、上記の場所ではなく
example-green.<project>.<router_domain>にルートを生成します。ルートを編集して、サービス名を
example-blueに変更します。$ oc patch route/bluegreen-example -p '{"spec":{"to":{"name":"example-blue"}}}'- ルートが変更されたことを確認するには、v2 イメージが表示されるまで、ブラウザーを更新します。
9.4.3. A/B デプロイメント
A/B デプロイメントストラテジー では、新しいバージョンのアプリケーションを実稼働環境での制限された方法で試すことができます。実稼働バージョンは、ユーザーの要求の大半に対応し、要求の一部が新しいバージョンに移動されるように指定できます。各バージョンへの要求の部分を制御できるので、テストが進むにつれ、新しいバージョンへの要求を増やし、最終的に以前のバージョンの使用を停止することができます。各バージョン要求負荷を調整するにつれ、期待どおりのパフォーマンスを出せるように、各サービスの Pod 数もスケーリングする必要があります。
ソフトウェアのアップグレードに加え、この機能を使用してユーザーインターフェースのバージョンを検証することができます。以前のバージョンを使用するユーザーと、新しいバージョンを使用するユーザーが出てくるので、異なるバージョンに対するユーザーの反応を評価して、デザインの意思決定を行うことができます。
このデプロイメントの効果を発揮するには、以前のバージョンと新しいバージョンは同時に実行できるほど類似している必要があります。これは、バグ修正リリースや新機能が以前の機能と干渉しないようにする場合の一般的なポイントになります。これらのバージョンが正しく連携するには N-1 互換性 が必要です。
OpenShift Container Platform は、Web コンソールとコマンドラインインターフェースで N-1 互換性をサポートします。
9.4.3.1. A/B テスト用の負荷分散
「複数のサービスでルート」を設定します。各サービスは、アプリケーションの 1 つのバージョンを処理します。
各サービスには weight が割り当てられ、各サービスへの要求の部分については service_weight を sum_of_weights で除算します。エンドポイントの weights の合計がサービスの weight になるように、サービスごとの weight がサービスのエンドポイントに分散されます。
ルートにはサービスを 4 つ含めることができます。サービスの weight は、0 から 256 で指定してください。weight が 0 の場合は、新しい要求はサービスに移動せずに、既存の接続がアクティブのままになります。サービスの weight が 0 でない場合は、エンドポイントの最小 weight は 1 となります。これにより、エンドポイントが多数含まれるサービスは、最終的に希望の weight よりも多くなってしまう可能性があります。このような場合は、希望とする負荷分散の weight になるように、Pod の数を減らしてください。詳しい情報は、「別のバックエンドおよび Weight」のセクションを参照してください。
Web コンソールでは、重みを設定したり、各サービス間の重みの分散を表示したりできます。
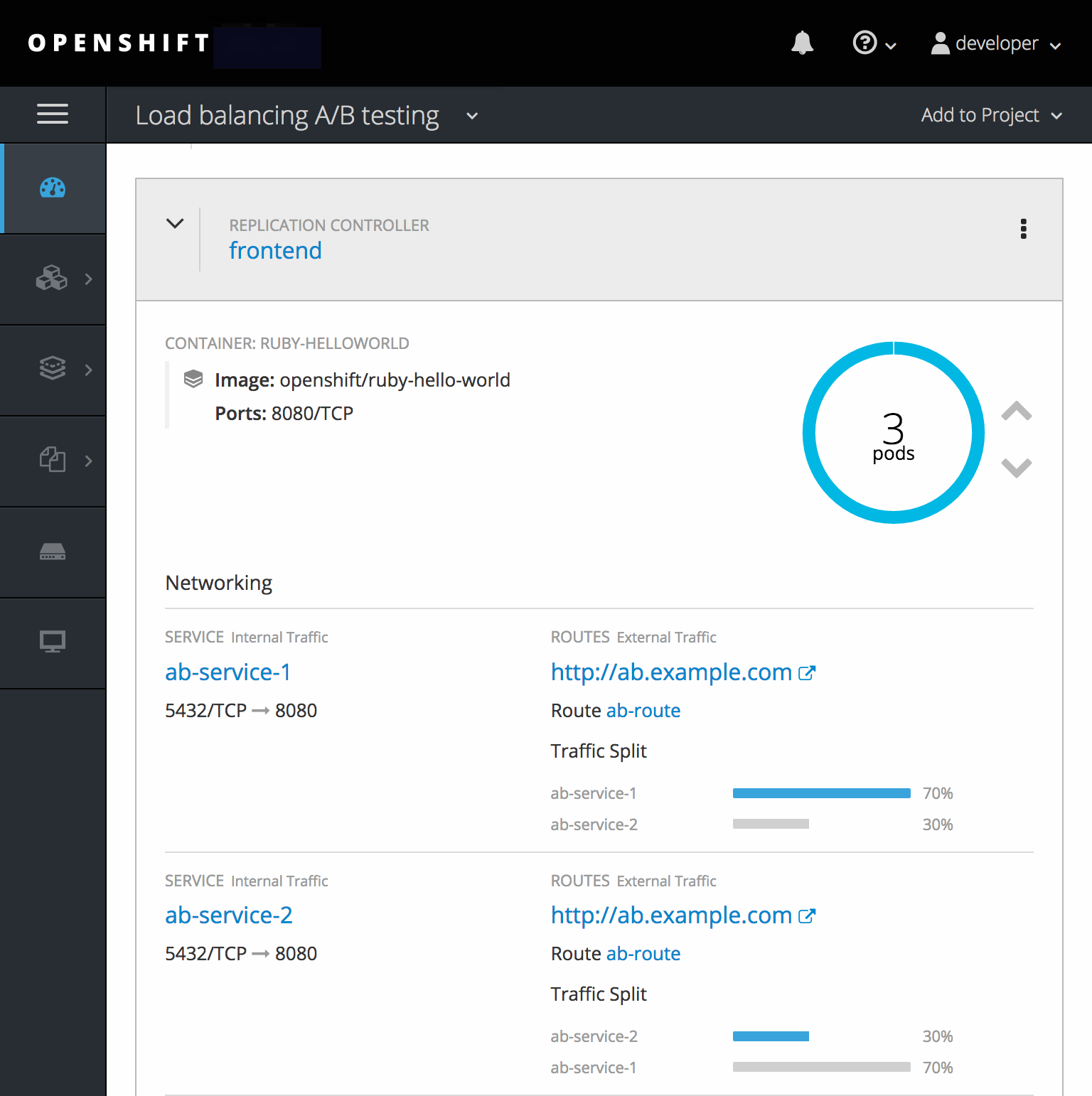
A/B 環境を設定するには以下を行います。
2 つのアプリケーションを作成して、異なる名前を指定します。それぞがデプロイメント設定を作成します。これらのアプリケーションは同じアプリケーションのバージョンであり、通常 1 つは現在の実稼働バージョンで、もう 1 つは提案される新規バージョンとなります。
$ oc new-app openshift/deployment-example1 --name=ab-example-a $ oc new-app openshift/deployment-example2 --name=ab-example-bデプロイメント設定を公開してサービスを作成します。
$ oc expose dc/ab-example-a --name=ab-example-A $ oc expose dc/ab-example-b --name=ab-example-Bこの時点で、いずれのアプリケーションもデプロイ、実行され、サービスが追加されています。
ルート経由でアプリケーションを外部から利用できるようにします。この時点でサービスを公開できます。現在の実稼働バージョンを公開してから、後でルートを編集して新規バージョンを追加すると便利です。
$ oc expose svc/ab-example-Aab-example.<project>.<router_domain>でアプリケーションを参照して、希望とするバージョンが表示されていることを確認します。ルートをデプロイする場合には、ルーターはサービスに指定した
weightsに従って「トラフィックを分散します」。この時点では、デフォルトのweight=1と指定されたサービスが 1 つ存在するので、すべての要求がこのサービスに送られます。他のサービスをalternateBackendsとして追加し、weightsを調整すると、A/B 設定が機能するようになります。これは、oc set route-backendsコマンドを実行するか、ルートを編集して実行できます。注記ルートに変更を加えると、さまざまなサービスへのトラフィックの部分だけが変更されます。デプロイメント設定をスケーリングして、必要な負荷を処理できるように Pod 数を調整する必要がある場合があります。
ルートを編集するには、以下を実行します。
$ oc edit route <route-name> ... metadata: name: route-alternate-service annotations: haproxy.router.openshift.io/balance: roundrobin spec: host: ab-example.my-project.my-domain to: kind: Service name: ab-example-A weight: 10 alternateBackends: - kind: Service name: ab-example-B weight: 15 ...
9.4.3.1.1. Web コンソールを使用した重みの管理
- Route の詳細ページ (アプリケーション/ルート) に移動します。
- アクションメニューから Edit を選択します。
- Split traffic across multiple services にチェックを入れます。
Service Weights スライダーで、各サービスに送信するトラフィックの割合を設定します。

2 つ以上のサービスにトラフィックを分割する場合には、各サービスに 0 から 256 の整数を使用して、相対的な重みを指定します。
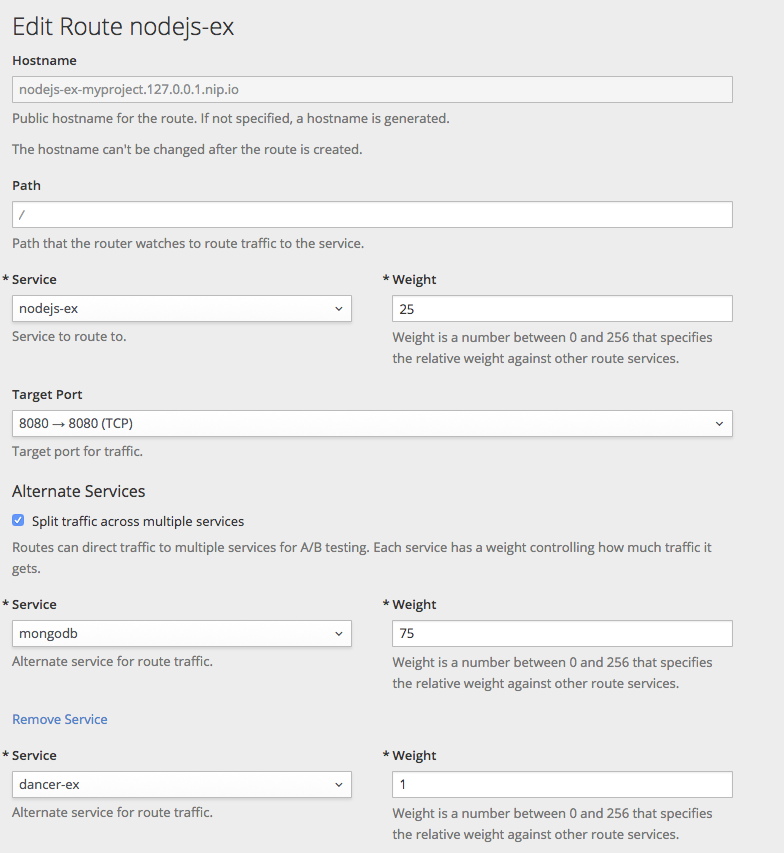
トラフィックの重みは、トラフィックを分割したアプリケーションの行を展開すると Overview に表示されます。
9.4.3.1.2. CLI を使用した重みの管理
このコマンドは、ルートでサービスと対応する重みの「負荷分散」を管理します。
$ oc set route-backends ROUTENAME [--zero|--equal] [--adjust] SERVICE=WEIGHT[%] [...] [options]
たとえば、以下のコマンドは ab-example-A に weight=198 を指定して主要なサービスとし、ab-example-B に weight=2 を指定して 1 番目の代用サービスとして設定します。
$ oc set route-backends web ab-example-A=198 ab-example-B=2
つまり、99% のトラフィックはサービス ab-example-A に、1% はサービス ab-example-B に送信されます。
このコマンドでは、デプロイメント設定はスケーリングされません。要求の負荷を処理するのに十分な pod がある状態でこれを実行する必要があります。
フラグなしのコマンドでは、現在の設定が表示されます。
$ oc set route-backends web
NAME KIND TO WEIGHT
routes/web Service ab-example-A 198 (99%)
routes/web Service ab-example-B 2 (1%)
--adjust フラグを使用すると、個別のサービスの重みを、それ自体に対して、または主要なサービスに対して相対的に変更できます。割合を指定すると、主要サービスまたは 1 番目の代用サービス (主要サービスを設定している場合) に対して相対的にサービスを調整できます。他にバックエンドがある場合には、重みは変更に比例した状態になります。
$ oc set route-backends web --adjust ab-example-A=200 ab-example-B=10
$ oc set route-backends web --adjust ab-example-B=5%
$ oc set route-backends web --adjust ab-example-B=+15%
--equal フラグでは、全サービスの weight が 100 になるように設定します。
$ oc set route-backends web --equal
--zero フラグは、全サービスの weight を 0 に設定します。すべての要求に対して 503 エラーが返されます。
ルートによっては、複数のバックエンドたは重みが設定されたバックエンドをサポートしないものがあります。
9.4.3.1.3. 1 サービス、複数のデプロイメント設定
ルーターをインストールしている場合は、ルートを使用してアプリケーションを利用できるようにしてください (または、サービス IP を直接使用してください)。
$ oc expose svc/ab-example
ab-example.<project>.<router_domain> でアプリケーションを参照し、v1 イメージが表示されることを確認します。
1 つ目のシャードと同じだが別のバージョンがタグ付けされたソースイメージを基に 2 つ目のシャードを作成して、一意の値を設定します。
$ oc new-app openshift/deployment-example:v2 --name=ab-example-b --labels=ab-example=true SUBTITLE="shard B" COLOR="red"新たに作成したシャードを編集して、全シャードに共通の
ab-example=trueラベルを設定します。$ oc edit dc/ab-example-bエディターで、
spec.selectorとspec.template.metadata.labelsの下に、既存のdeploymentconfig=ab-example-bラベルと一緒にab-example: "true"の行を追加して保存し、エディターを終了します。2 番目のシャードの再デプロイメントをトリガーして、新規ラベルを取得します。
$ oc rollout latest dc/ab-example-bこの時点で、いずれの Pod もルートでサービスが提供されますが、両ブラウザー (接続を開放) とルート (デフォルトでは cookie を使用) で、バックエンドサーバーへの接続を保存するように試行するので、シャードが両方返されない可能性があります。ブラウザーからいずれかのシャードを表示させるようにするには、scale コマンドを使用します。
$ oc scale dc/ab-example-a --replicas=0ブラウザーを更新すると、 v2 および shard B (赤字) が表示されているはずです。
$ oc scale dc/ab-example-a --replicas=1; oc scale dc/ab-example-b --replicas=0ブラウザーを更新すると、v1 と shard A (青字) が表示されているはずです。
いずれかのシャードでデプロイメントをトリガーした場合には、そのシャード内の Pod のみが影響を受けます。いずれかのデプロイメント設定で
SUBTITLE環境変数を変更して (oc edit dc/ab-example-aまたはoc edit dc/ab-example-b)、デプロイメントを簡単にトリガーできます。ステップ 5-7 を繰り返すと、別のシャードを追加できます。注記これらの手順は、今後の OpenShift Container Platform バージョンでは簡素化される予定です。
9.4.4. プロキシーシャード/トラフィックスプリッター
実稼働環境で、特定のシャードに到達するトラフィックの分散を正確に制御できます。多くのインスタンスを扱う場合は、各シャードに相対的なスケールを使用して、割合ベースのトラフィックを実装できます。これは、他の場所で実行中の別のサービスやアプリケーションに転送または分割する プロキシーシャード とも適切に統合されます。
最も単純な設定では、プロキシーは要求を変更せずに転送します。より複雑な設定では、受信要求を複製して、別のクラスターだけでなく、アプリケーションのローカルインスタンスにも送信して、結果を比較することができます。他のパターンとしては、DR のインストールのキャッシュを保持したり、分析目的で受信トラフィックをサンプリングすることができます。
実装がこの例のスコープ外の場合でも、TCP (または UDP) のプロキシーは必要なシャードで実行できます。oc scale コマンドを使用して、プロキシーシャードで要求に対応するインスタンスの相対数を変更してください。より複雑なトラフィックを管理する場合には、OpenShift Container Platform ルーターを比例分散機能でカスタマイズすることを検討してください。
9.4.5. N-1 互換性
新規コードと以前のコードが同時に実行されるアプリケーションの場合は、新規コードで記述されたデータが、以前のコードで読み込みや処理 (または正常に無視) できるように注意する必要があります。これは、スキーマの進化 と呼ばれ、複雑な問題です。
これは、ディスクに保存したデータ、データベース、一時的なキャッシュ、ユーザーのブラウザーセッションの一部など、多数の形式を取ることができます。多くの Web アプリケーションはローリングデプロイメントをサポートできますが、アプリケーションをテストし、設計してこれに対応させることが重要です。
アプリケーションによっては、新規と旧コードが並行的に実行されている期間が短いため、バグやユーザーのトランザクションに失敗しても許容範囲である場合があります。別のアプリケーションでは失敗したパターンが原因で、アプリケーション全体が機能しなくなる場合もあります。
N-1 互換性を検証する 1 つの方法として、A/B デプロイメント があります。制御されたテスト環境で、以前のコードと新しいコードを同時に実行して、新規デプロイメントに流れるトラフィックが以前のデプロイメントで問題を発生させないかを確認します。
9.4.6. 正常な終了
OpenShift Container Platform および Kubernetes は、負荷分散のローテーションから削除する前にアプリケーションインスタンスがシャットダウンする時間を設定します。ただし、アプリケーションでは、終了前にユーザー接続が正常に中断されていることを確認する必要があります。
シャットダウン時に、OpenShift Container Platform はコンテナーのプロセスに TERM シグナルを送信します。SIGTERM を受信すると、アプリケーションコードは、新規接続の受け入れを停止する必要があります。こうすることで、ロードバランサーにより、他のアクティブなインスタンスにトラフィックをルーティングされるようになります。アプリケーションコードは、開放されている接続がすべて終了する (または、次の機会に個別接続が正常に終了される) まで待機してから終了します。
正常に終了する期間が終わると、終了されていないプロセスに KILL シグナルが送信され、プロセスが即座に終了されます。Pod の terminationGracePeriodSeconds 属性または Pod テンプレートが正常に終了する期間 (デフォルト 30 秒) を制御し、必要に応じてアプリケーションごとにカスタマイズすることができます。
9.5. Kubernetes デプロイメントサポート
9.5.1. デプロイメントオブジェクトタイプ
Kubernetes には、OpenShift Container Platform では デプロイメント と呼ばれるファーストクラスのオブジェクトタイプがあります。このオブジェクトタイプ (ここでは区別するために Kubernetes デプロイメント と呼びます) は、デプロイメント設定オブジェクトタイプの派生タイプとして機能します。
デプロイメント設定と同様に、Kubernetes デプロイメントは Pod テンプレートとして、アプリケーションの特定のコンポーネントの必要とされる状態を記述します。Kubernetes デプロイメントは レプリカセット (「レプリケーションコントローラー」の反復) を作成して、Pod ライフサイクルをオーケストレーションします。
たとえば、Kubernetes デプロイメントのこの定義は、レプリカセットを作成して hello-openshift pod を 1 つ起動します。
例: Kubernetes デプロイメント定義 hello-openshift-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: hello-openshift
spec:
replicas: 1
selector:
matchLabels:
app: hello-openshift
template:
metadata:
labels:
app: hello-openshift
spec:
containers:
- name: hello-openshift
image: openshift/hello-openshift:latest
ports:
- containerPort: 80ローカルファイルに定義を保存した後に、Kubernetes デプロイメントの作成にこのファイルを使用できます。
$ oc create -f hello-openshift-deployment.yaml
CLI を使用して、get や describe などの「一般的な操作」で記載されているように、Kubernetes デプロイメントと、他のオブジェクトタイプなどのレプリカセットを検証して、操作します。オブジェクトタイプの場合、Kubernetes デプロイメントには deployments または deploy を、レプリカセットには replicasets または rs を使用します。
デプロイメント および レプリカセット に関する詳細は、Kubernetes のドキュメントを参照してください。CLI の使用方法の例で、oc を kubectl に置き換えてください。
9.5.2. Kubernetes デプロイメント 対 デプロイメント設定
デプロイメントが Kurbernetes 1.2 に追加される前にデプロイメント設定が OpenShift Container Platform に存在していたために、Kurbenetes のオブジェクトタイプは OpenShift Container Platform の設定とは若干異なっています。OpenShift Container Platform の長期的な目標は、Kubernetes デプロイメントと全く同等な機能を実現し、アプリケーションの詳細な管理を可能にする単一オブジェクトタイプとしてそれらのデプロイメントを使用する方法に切り替えることにあります。
新規オブジェクトタイプを使用するアップストリームのプロジェクトや例が OpenShift Container Platform でスムーズに実行できるように、Kubernetes デプロイメントはサポートされます。Kubernetes デプロイメントの現在の機能を考慮すると、特に以下のいずれかを使用する予定がない場合には、OpenShift Container Platform のデプロイメント設定の代わりに、Kubernetes デプロイメントを使用すると良いでしょう。
以下のセクションでは、2 つのオブジェクトタイプの相違点に関してさらに扱います。これは、デプロイメント設定ではなく、Kubernetes デプロイメントを使用する場合を判別するのに役立ちます。
9.5.2.1. デプロイメント設定固有の機能
9.5.2.1.1. 自動ロールバック
Kubernetes デプロイメントは、問題が発生した場合に、最後に正常にデプロイされたレプリカセットに自動的にロールバックされません。この機能は近日追加される予定です。
9.5.2.1.2. トリガー
Kubernetes デプロイメントには、デプロイメントの Pod テンプレートに変更があるたびに、新しいロールアウトが自動的にトリガーされるので、暗黙的な ConfigChange トリガーが含まれています。Pod テンプレートの変更時に新たにロールアウトしない場合には、デプロイメントを以下のように停止します。
$ oc rollout pause deployments/<name>
現在、Kubernetes デプロイメントでは ImageChange トリガーはサポートされません。汎用的なトリガーの仕組みがアップストリームでは提案されていますが、この提案が受け入れられるのか、また受け入れられるタイミングは不明です。最終的には、OpenShift Container Platform 固有の仕組みが、Kubernetes デプロイメントの階層の上に実装される可能性がありますが、Kubernetes コアの一部として存在させる方が適しています。
9.5.2.1.3. ライフサイクルフック
Kubernetes デプロイメントではライフサイクルフックがサポートされません。
9.5.2.1.4. カスタムストラテジー
Kubernetes デプロイメントでは、ユーザーが指定するカスタムデプロイメントストラテジーはまだサポートされていません。
9.5.2.1.5. カナリアリリースデプロイメント
Kubernetes デプロイメントでは、新規ロールアウトの一部としてカナリアリリースは実行されません。
9.5.2.1.6. テストデプロイメント
Kubernetes デプロイメントでは、実行中のテストトラックはサポートされません。
9.5.2.2. Kubernetes デプロイメント固有の機能
9.5.2.2.1. ロールオーバー
Kubernetes デプロイメントのデプロイメントプロセスは、コントローラーループで駆動されますが、デプロイメント設定は、新しいロールアウトごとにデプロイヤー Pod を使用します。つまり、Kubernetes デプロイメントはできるだけアクティブなレプリカセットを指定することができ、最終的にデプロイメントコントローラーが以前のレプリカセットをスケールダウンし、最新のものをスケールアップします。
デプロイメント設定で、実行できるデプロイヤー Pod は最大 1 つとなっています。デプロイヤーが 2 つある場合は、他のデプロイヤーと競合して、それぞれが最新のレプリケーションコントローラーであると考えるコントローラーをスケールアップしようとします。これにより、一度にアクティブにできるのは、レプリケーションコントローラー 2 つだけで、最終的に、Kubernetes デプロイヤーのロールアウトが加速します。
9.5.2.2.2. 比例スケーリング
Kubernetes デプロイメントコントローラーのみがデプロイメントが所有する新旧レプリカセットのサイズについての信頼できる情報源であるため、継続中のロールアウトのスケーリングできます。追加のレプリカはレプリカセットのサイズに比例して分散されます。
デプロイメント設定は、デプロイメント設定コントローラーが新規レプリケーションコントローラーのサイズに関してデプロイヤープロセスと競合するためにロールアウトが続行されている場合はスケーリングできません。
9.5.2.2.3. ロールアウト中の一時停止
Kubernetes デプロイメントはいつでも一時停止できます。つまり、継続中のロールアウトも一時停止できます。反対に、デプロイヤー Pod は現時点で一時停止できないので、ロールアウト時にデプロイメント設定を一時停止しようとしても、デプロイヤープロセスはこの影響を受けず、完了するまで続行されます。