25.2. Alert Conditions
Monitoring (Chapter 19, Metrics and Measurements) is closely associated to alerting, in a larger work flow of keeping administrators aware of what is happening in their network. Alerting is based on conditions, the signal that an alert should be issued.
Conditions can be pretty straightforward — if A happens, do B — or they can be complex, with multiple conditions or combinations of readings required before an alert is initiated.
25.2.1. Reasons for Firing an Alert
Copy linkLink copied to clipboard!
The condition is any situation, event, or level on a resource that crosses a certain threshold. Basically, a condition sets parameters on what is "normal" behavior or performance for a resource. Once it crosses that boundary, JBoss ON issues an alert. This can be a metric value that has changed to an undesirable level, an event, or a recurring metric reading.
Alerts through alert definitions against are defined for individual resources or for compatible groups of resources. An alert definition specifies the conditions that trigger the alert and the type and settings of any notification that should be triggered.
When an alert is registered, the alert identifies the alert definition which was triggered (which identifies the alert condition) and the metric or event value which precipitated the alert.
An alert conditions answers four questions: what, when, who, and where. The what is the threshold or condition that triggers the alert (such as the free memory drops below a certain point). The when sets the frequency or timing for sending an alert using a defined dampening rule. And the who and where controls how administrators are notified of the alert.
A single condition can be enough to issue an alert, or an alert definition can require that an alert is issued only if multiple conditions are met simultaneously. This provides very granular control over when an alert is issued, which makes alerting information more valuable and relevant.
A condition can be based on any detectable monitoring or system metric, listed in Section 25.2.1, “Reasons for Firing an Alert”. These alert conditions correspond directly to the monitoring metrics available for that type of resource. All of the possible metrics for each resource type are listed in the Resource Monitoring Reference.
| Condition Type | Description |
|---|---|
| Metric | A specific monitoring area that is checked and the thresholds for that area which trigger a response. Metrics are usually numeric responses of some sort (e.g., percent CPU usage, number of requests, or a cache hit ratio). |
| Trait | A change in a value for a specific setting. Traits are usually string values. |
| Availability | A sudden change in whether the resource is available or unavailable. |
| Operation | A specific action or task that is performed on the resource. |
| Events | A certain type of error message, matching a given string, is recorded. Events are filtered from system or application log files, and the types of events recognized in JBoss ON depend on the event configuration for the resource. |
| Drift | A resource has changed from a predefined configuration. |
25.2.2. Detailed Discussion: Ranges, AND, and OR Operators with Conditions
Copy linkLink copied to clipboard!
Alerting is based on monitoring information. It is an extension that allows an administrator to receive a notification or define an action to take if a certain event or metrics value occurs.
The monitoring point that triggers an alert is the alert condition. At its most simplistic, an alert condition is a single event or reading. If X occurs, then that triggers an alert.
In real life, X may not be enough to warrant an alert or to adequately describe the state of a resource. Different conditions may require the same response or a situation may only be critical if multiple conditions are true. Alerting is very flexible because it allows multiple conditions to be defined with established relationships between those conditions.
The next level of complexity is to send an alert if either X or Y is true. In the alert definition, this is the ANY option, which is a logical OR. The alert definition checks for any of those conditions, but those conditions are still unrelated to each other.
The last level of complexity is when the conditions have to relate to each other for an alert to be issued. This is the ALL option, which is a logical AND. Both X and Y must occur for the alert to be issued. In this case, when one condition occurs, the server puts a lock on that definition and begins waiting for the second condition to occur. When the second condition occurs, then the alert is issued.
An AND operator is very effective on different metrics, but because the conditions do not have to occur simultaneously, using a simple AND operator does not make sense for the same metric.
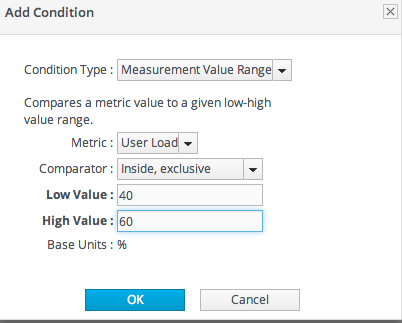
For example, Tim the IT Guy only wants an alert to be issued when the user load is between 40% to 60%, indicating slightly increased loads on his platform. Attempting to use an AND operator returns strange values when the load spikes over 70% (which trips the above 40% condition) and then falls back to 15% (which triggers the below 60% condition).
In this case, Tim uses a range condition. A range requires two values from the same metric that are within the given boundaries. A range can be inside values (40-60%) or it can be an outside range (below 40% and above 60%).
Figure 25.1. Alert Condition Range
25.2.3. Detailed Discussion: Conditions Based on Log File Messages
Copy linkLink copied to clipboard!
Events (Chapter 20, Events) are filtered log messages. Certain resource in JBoss ON maintain their own error logs, like platforms and JBoss EAP servers. JBoss ON can scan these error logs to detect events of certain severity or events matching certain patterns. This allows JBoss ON administrators to provide an easy way to identify and view important error messages.
Because JBoss ON can detect log events, JBoss ON can alert on log events. An event-based condition requires the severity of the log file message and, optionally, a pattern to use to match specific messages.
Figure 25.2. Log File Conditions
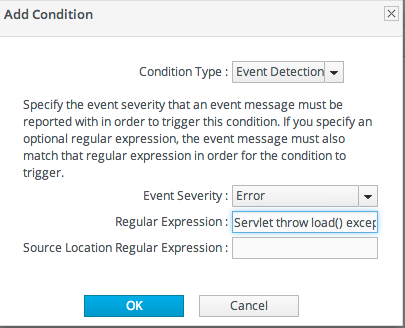
Setting only a severity alerts on any event with that severity. That is useful for severe or fatal errors, which are relatively infrequent and need immediate attention.
Note
For general error message, use a pattern to filter for a specific error type. Then, use a resource operation or CLI script to take a specific action to address that specific error, like restarting a resource or starting a new web app.
25.2.4. Detailed Discussion: Dampening
Copy linkLink copied to clipboard!
Dampening does not define an alert condition, but it tells the JBoss ON server how to handle recurring conditions.
An alert can be issued every single time a condition is met, or an alert can be issued and then disabled until an administrator acknowledges it. Dampening a condition is useful to prevent multiple alerts and notifications from being sent for a single ongoing set of circumstances.
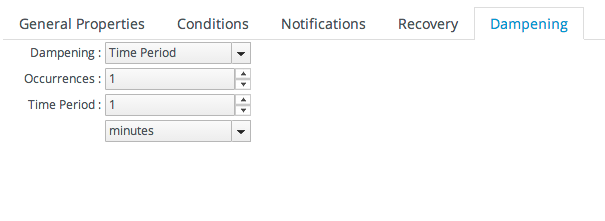
Figure 25.3. Dampening Filter
For example, Tim the IT Guy sets an alert to let him know if his platform CPU usage spikes above 80%. Every time the monitoring scan runs, the metric is again determined to be true, and is treated as a new and discrete instance. If the metric schedule is set for 10 minutes and it takes him an hour to respond to the alert, he could have six or seven alert notifications before he has a chance to respond. If the only alert response is an email, this is an annoyance, but not a problem.
If, however, Tim the IT Guy has an alert response to create a new JBoss server if his EAP connection count goes above a certain point, the same response could be taken six or seven times, when it actually should be done once and then the condition will naturally resolve itself.
Dampening is another set of instructions on how to evaluate the condition before triggering another alert. It tells JBoss ON how to interpret those monitoring data.
- JBoss ON could send an alert every time the condition is encountered. In that case, there would be multiple alerts issued if the CPU percentage bounced around, while only one alert would be sent if it hit it briefly or hit it and stayed there.
- JBoss ON could send an alert only if the condition was encountered a certain number of times consecutively or X number of times out of Y number of polls. In this case, only a recurring or sustained problem would trigger an alert. A momentary spike or trough wouldn't be enough to fire a notification.A condition may need to occur several times over a short period of time for it to be a problem, but once is not a problem. For example, a server may bounce between 78% and 80% CPU over several minutes, it could hit 80% once for only a few seconds, or it could hit 80% and stay there. The condition may only be relevant if the CPU hits 80% and stays, and the other readings can be ignored.
- A notification is sent only if the problem occurs within a set time period. This can be useful to track the frequency of recurring problems or to track how long a condition persisted.
Note
Dampening is only relevant for metrics which are variable and compared to some kind of baseline. Monitoring metrics with thresholds and value changes are dynamic, so each reading really is a new condition, even if it matches the previous reading. Dampening, then, controls those multiple similar readings.
Conditions which relate directly to a status change do not compare themselves against a baseline — they only compare against a previous state. For example, if the system configuration changes from the drift template or if the availability changes, that is a one-time change. After that, the resource has a new status and future changes would be compared against the new status — so, in a sense, it is a different condition.
Dampening does not apply conceptually for drift and availability changes.
25.2.5. Detailed Discussion: Automatically Disabling and Recovering Alerts
Copy linkLink copied to clipboard!
There are a couple of different ways to limit how often an alert notification is sent for the same observed condition. One method is a dampening rule. An alternative is to disable an alert the first time it is fired, and then only re-enabling the alert when an administrator does it manually or if the condition resets itself. This second option — disabling and then resetting itself — recovers the alert.
A recover alert is actually a pair of alerts which work in tandem to disable and enable relevant alerts as conditions change.
A couple of workflows are common with recover alerts:
- A pair of alerts work as mutual toggle switches. When one alert is active, the other is disabled. When Alert A is fired, it can be set to recover a specified Alert B — so Alert B essentially takes its place.
- Alerts work as a kind of cascade. If Alert A is fired, that enables Alert B, which then enables Alert C. In some situations, any one given condition may not be a problem, but it becomes a problem if they occur sequentially in a short amount of time.
Figure 25.4. Disable and Recover Alerts
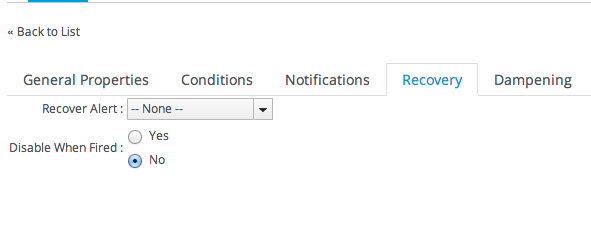
For example, Alert A triggers an alert when a resource availability goes down. When Alert A fires, it disables itself and recovers (or enables) Alert B. Alert B fires an alert when the resource's availability goes up. When Alert B fires, it likewise disables itself and recovers Alert A.
Recover alerts inform an administrator first of when an issue occurs and then second when it is resolved. In the availability examples, the first alert lets the administrator know that a resource is offline, while the second alert lets the administrator know that the resource is back online.
The Setup: Toggle Recover Alerts for Availability
Tim the IT Guy has several servers that he uses for email routing and other business operations, and then he has a couple of machines that he holds in reserve as backups.
He has mail-server-a.example.com has his primary mail server, and he only wants to bring mail-server-b.example.com online if mail-server-a goes offline, and then he wants it to go back in reserve when mail-server-a comes back.
The Plan
Tim creates a set of alert definitions to help handle the transition between his mail servers.
- The first alert definition fires when the mail-server-a platform changes availability state to goes down.The notification does a couple of things:
- Deploy a bundle with the latest mail server configuration to another platform, mail-server-b.
- Execute a command-line script on mail-server-b to start the mail service.
- Email Tim the IT Guy to let him know that mail-server-a is unavailable.
For recovery, the alert does two things:- Disable the current alert. It only needs to fire once, to get the backup server online.
- Recover (or enable) Alert B, so that JBoss ON waits for mail-server-a to come back up.
- The second alert definition, Alert B, is only in effect while mail-server-a is offline. This alert fires as soon as mail-server-b changes availability state to goes up.
- This alert definition basically waits around as long as mail-server-a is down. When mail-server-a is back online, Alert B's notification is to execute a command-line script on mail-server-b to stop the mail service.
- Alert B also sends a notification email to Tim the IT Guy to let him know that mail-server-a is available again.
For recovery, the alert does two things:- Disable the current alert. Like with Alert A, Alert B only needs to fire once, to shut off the backup as soon as the primary server is back.
- Recover (or enable) Alert A, so the JBoss ON waits again for mail-server-a to go down.