Much of the JBoss ON configuration management is designed around implementing changes for resources by editing configuration files or updating files and packages. But another aspect of managing configuration is detecting changes.
IT administrators must invest a significant amount of time planning the optimum configuration for systems in every type of environment, from production systems to internal resources. This ideal configuration includes file settings, software versions, and system settings. Resource configuration is going to change naturally over time, but administrators need to be able to track those changes to make sure that no unplanned or undesirable changes impact the resource. Defining a baseline configuration and tracking changes helps systems remain resilient during both maintenance and failures.
The unplanned changes that occur to a resource's configuration is called drift, as the configuration moves away from the designed baseline. Drift is common because of frequent software and hardware updates, particularly in a colocation facility or using virtual machines.
Production, staging, development, and recovery configurations are designed to have identical or near-identical configuration to maintain consistency. As the configurations within the different environments change, there emerges a configuration gap. Ultimately, this configuration gap can lead to disaster recovery failures or high availability failures because the configuration of the production system and the backup system are too different.
Drift monitoring provides a very general, freewheeling content-based monitoring. Rather than structured configuration management, drift monitoring tracks changes to content on the local filesystem. This means any changes in any files — even binary files [3].
Of course, drift monitoring isn't as simple as checking for changes. One of the core questions is what changes matter? There are two conceptual parts to that question:
What directories (and files within those directories) matter for drift monitoring? Even though a drift definition is defined for a resource, the actual drift detection is performed at the directory level. Drift monitoring, then, can hit anywhere on a platform — even outside resources managed by JBoss ON.
How do you identify a change? Do you compare it to the version immediately before it or to an established baseline?
Once you identify what changes you want to monitor for drift, then you can use JBoss ON to set up monitoring and alerting effectively.
The first part of drift detection is identifying what you are monitoring.
JBoss ON defines a drift definition that sets the target location for drift monitoring. The target can be identified from some configuration element for the resource — it can be a directory or file on the filesystem, a resource configuration property, a resource plug-in parameter, or a monitoring trait. This target is the base directory. There are several different configuration areas within each resource that (potentially) define a filesystem location. The base directory is identified by determing what configuration type contains that information; that information area is the value context. A value context can be any one of four different areas:
From the plug-in configuration (pluginConfiguration). This means, it can be taken from any of the connection properties for the resource. Connection properties can include log files, deployment directories, and installation directories, depending on the resource type.
From the resource configuration (resourceConfiguration). This means, it can be taken from any of the configurable properties for the resource.
From a trait (measurementTrait). Traits are informational measurement properties for the resource.
An explicit filesystem location. If none of the resource properties have the proper location or if a different location should be used for drift, then the directory can be specified in the fileSystem property.
The actual value is the value name.
Note
Plug-in configuration (connection properties), resource configuration properties, and traits for each resource are listed in the Resource Reference.
For example, for a base directory of /etc/ that only includes changes to *.conf files, the elements in the drift definition are:
Value context: fileSystem
Value name: /etc
Includes: **/*.conf
Note
Drift detection is performed at the filesystem level. This means that drift detection is not bound or restricted to a resource managed by JBoss ON. You can create a drift definition for a platform and set it to monitor any file or directory on that platform, even if it is outside the JBoss ON inventory, as long as that directory is accessible to the system user that the JBoss ON agent runs as.
By default, every subdirectory and file underneath the base directory is monitored for drift. The includes/excludes options define subdirectories or files that are explicitly included or explicitly excluded from drift monitoring. If includes is used, then only the specified directories or files are monitored and everything else is implicitly excluded, and vice versa for excludes. Included/excluded directories and files are identified by a path and a pattern. The path is the starting point beneath the base directory, and the pattern matches the file to monitor.
Expand
Table 15.1. Combinations to Include Specific Files
For *.conf files only in the /etc directory, with no subdirectories (/etc/*.conf)
.
*.conf
For *.conf files only in a subdirectory one level below /etc (/etc/*/*.conf)
Not possible
Not possible
For any file in a specific subdirectory (yum.repos.d/) below /etc
yum.repos.d (subdirectory name)
Blank
[a]
This must have a double asterisk for the directory part. It will not work with a single asterisk.
The drift definition also sets an interval, or frequency, for how often the agent checks for drift. This is a very important setting for performance, both for JBoss ON and for data management. Setting a frequency that is too high risks missing changes or lumping changes together into large (and therefore difficult to manage) snapshots. However, setting the interval too low can impact JBoss ON agent and server performance.
The key thing about the drift definition is that it sets what to look at and how often to look.
Note
All drift detection runs are performed outside the agent plug-in and independent of the resource state. A drift detection scan can be run even if the resource is not running.
The second part of drift detection is identifying how you want to define a change. Change is comparative. It takes the current version of a file and compares it to some previous version. The question for drift management is what previous version to compare to.
When a drift definition is first created, the agent collects all of the files in that base directory and subdirectories and sends information about them to the server. This collection is the initial file set.
From that point onward, the agent only sends change information about the files. Each set of changes is a snapshot. For text files, the change information includes the content of the file and diffs (both constructed on the JBoss ON server based on patches sent by the agent). For binary files, drift only records that the file change and displays a SHA and timestamp. A snapshot is always based on real files from a real resource.
Note
The agent does not send the actual files to the JBoss ON server. The agent sends information about file changes back to the server. These updates only contain the deltas between versions; they're not full files. This minimizes the network I/O.
The actual diffs are generated on the server from the content that the server stores.
The way that a snapshot is created is by comparing the current files against the agent's version. There are two ways that this comparison can be made:
It can compare against the next-most recent version of the files.
It can compare against a defined, stable baseline.
The first option is a rolling snapshot. This is the simplest setting, because it just keeps a running tally of changes.
Figure 15.1. Rolling Snapshots
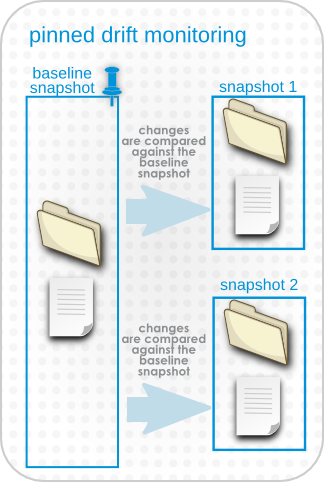
The second option is a pinned snapshot, and this is the method that gives administrators the most insight and control over drift. A pinned snapshot means that some image of the base directory has the optimal, approved configuration and this snapshot is selected as the baseline. It is in essence pinned in place, and every subsequent change is compared against that pinned snapshot, rather than being compared against each other.
Figure 15.2. Pinned Snapshots
Snapshots exist at the resource-level, because they are based on the real files that exist on a system. When a snapshot is pinned to a resource-level definition, then any changes made on that system are compared to that snapshot. When the current file version matches the pinned snapshot, the resource is compliant.
A snapshot for a resource can also be pinned to a drift template — then, it is applied to every definition attached to that template. This is really powerful for administrators. For example, you can use a staging or development server to create the best system configuration for EAP performance, and then apply that EAP baseline snapshot to every EAP server in the production environment by pinning it to a drift template. You can see immediately all the EAP configuration relative to your defined ideal.
Drift looks at both files and directories on the local system to generate snapshots and identify changes. The majority of these files and directories are going to be real files, but Unix does have some special file types, and the drift operation may encounter those files as part of processing the destination directory. There are some behavior implications, particularly with symbolic links and named pipes.
With symbolic links, drift detection follows any links back to the original file or directory, and includes those files in the snapshot. For example, if a symlink is set up for some library:
If drift is configured on the libs/ directory in the JBoss Enterprise Application Platform home directory, it will follow the symlink back to /home/dev/libs, and include all of those files in the drift snapshot.
Important
Be careful when configuring drift against a directory which contains symlinks. All of the linked files will be included as part of the drift target.
If the linked directory has a large number of files, then drift detection runs may take longer than expected. Additionally, changes in that symlinked directory may have an unexpected impact on drift detection by recording many changes as drift when they weren't intended to be.
If you do not want to include the symlinked directory in the drift definition, use the excludes parameter in the drift definition to exclude the symlink.
The other special file type that is common on Unix systems is a pipe. As with a symlink, drift detection runs can detect a fifo file within the target directory. However, unlike symlinks, drift cannot process the fifo file, which causes drift detection to hang.
Note
Use the excludes parameter in the drift definition to exclude any named pipes in the target directory.
Whether drift is supported is defined in the resource type (which is discussed in Section 15.3.1, “About Resources and Drift Definition Templates”). If a drift template is defined in the resource type's rhq-plugin.xml descriptor, then that resource type supports drift. The template is a starting point (not an enforced configuration, like alert or metric collection templates).
Three JBoss ON standard resource types support drift:
All platforms
JBoss EAP 6 (AS 7), and all resources which use the JBoss AS 5 plug-in
JBoss AS/EAP 5, and all resources which use the JBoss AS 5 plug-in
JBoss AS/EAP 4 (deprecated)
Because drift support is defined in the plug-in descriptor, custom plug-ins can be created that add drift support for those resource types. For examples of writing agent plug-ins with drift support, see "Writing Custom JBoss ON Plug-ins."
Note
Drift is not supported on embedded web applications, such as an embedded WAR under an EAR application.
Drift detection is performed at the directory level. It is not tied to a specific resource. This means that drift detection can be run even when a resource is not running. It also means that drift detection can occur for an application, service, or file that is not managed by JBoss ON or for a resource type that does not otherwise support drift.
To monitor an entity outside the three supported resources, just configure drift detection on the platform resource and define the base directory as whatever directory path is used by the application or service you want to monitor.
Configuring drift monitoring can have a significant impact on disk space requirements.
JBoss ON stores multiple snapshots. This is part of versioning control, allowing changes to monitored directories to be reverted and managed.
Therefore, the system which hosts the backend database (Oracle or PostgreSQL) must have enough disk space to store all versions of all bundles. Additionally, the database itself must have adequate tablespace for the content.
Size considerations can also affect how drift monitoring is configured, in several ways:
The size of the directory being monitored. In some cases, it may be better to monitor multiple smaller subdirectories rather than one large, high-level directory.
The frequency of drift detection runs, balancing the need to capture changes versus the number of backup copies.
How long drift snapshots are stored. By default, unused snapshots (meaning, unpinned snapshots) are stored for 31 days and then deleted. Changing how long snapshots are stored can help manage the database size.
When calculating the required amount of space, estimate the size the targeted directories, and then the frequency that snapshots are taken to get an idea of how many snapshots will be stored. At a minimum, have twice that amount of space available; both PostgreSQL and Oracle require twice the database size to perform cleanup operations like vacuum, compression, and backup and recovery.
The goal of setting up drift detection is to provide clarity into how systems and application servers are being modified. JBoss ON provides two ways to manage drift.
Drift Monitoring
Drift monitoring is the ability to track changes to target locations. The JBoss ON GUI allows you to view snapshots all together, compare changes for individual files between snapshots, view the current configuration, and view change details. It also provides inventory and drift reports and indicates, at a glance, whether a resource is compliant with an associated pinned snapshot.
Drift Alerting
A specific alert condition exists that will trigger an alert whenever there is drift. For rolling snapshots, this will send an alert once (and only once) for each drift snapshot. For pinned snapshots, the drift alert is fired for every detection run for as long as the resource is out of compliance, even if there are no subsequent changes.
Note
There is no direct way to remedy drift through the JBoss ON GUI. However, it is possible to launch a JBoss ON CLI script in response to a drift alert. For example, you can create a patch of your ideal EAP configuration. If an EAP server drifts from that configuration, then you can use a JBoss ON CLI script to deploy that EAP patch bundle to the drifting EAP server.
[3]
JBoss ON detects that changes have been made to a binary file. It does not display binary files or compare or diff changes between versions for binary files, only text files.
We deliver hardened solutions that make it easier for enterprises to work across platforms and environments, from the core datacenter to the network edge.
Making open source more inclusive
Red Hat is committed to replacing problematic language in our code, documentation, and web properties. For more details, see the Red Hat Blog.
About Red Hat Documentation
We help Red Hat users innovate and achieve their goals with our products and services with content they can trust. Explore our recent updates.