25.2. アラート条件
監視(19章メトリックおよび測定値)はより大きなワークフローでアラートに密接に関連付けられ、管理者がネットワーク内で何が起きているかを認識させるようにします。アラートは 条件 に基づいて、アラートを発行すべきシグナルです。
条件は、非常に簡単です。A の場合、B を実行する場合や、アラートの開始前に複数の条件または読み取りの組み合わせと共に複雑になる可能性があります。
25.2.1. アラートの調整の理由
リンクのコピーリンクがクリップボードにコピーされました!
この 条件 は、特定のしきい値を超えるリソースの状況、イベント、またはレベルです。基本的に、条件はリソースの「正常な」動作またはパフォーマンスにパラメーターを設定します。この境界を超えると、JBoss ON はアラートを発行します。これは、望ましくないレベル、イベント、または繰り返し発生するメトリック読み取りに変更したメトリクスの値になります。
アラート定義を使用したアラートは、個別のリソースまたはリソースの互換性のあるグループに対して定義されます。アラート定義は、アラートをトリガーする条件と、トリガーする必要のある通知のタイプおよび設定を指定します。
アラートが登録されると、アラートはトリガーされたアラート定義(アラート状態を識別する)と、アラートの事前処理を行うメトリクスまたはイベント値を特定します。
アラート条件は、What、who 、 および where の 4 つの質問 に 回答します。アラート を トリガーするしきい値または 条件 です(たとえば、空きメモリーが特定の時点を下回る)。定義された組み込まれた ルール を使用してアラートを送信する頻度またはタイミングを設定する 場合。また、管理者にアラートの 通知 方法を制御する ユーザー および 場所。
1 つの条件でアラートを発行できる場合や、アラート定義では、複数の条件が同時に満たされる場合にのみアラートを発行する必要があります。これにより、アラートの発行時に非常に粒度の細かい制御が可能になり、アラート情報がより重要かつ適切なものになります。
条件は、に一覧表示されている検出可能な監視またはシステムメトリックを基にでき 「アラートの調整の理由」 ます。これらのアラート条件は、そのタイプのリソースで利用可能なモニタリングメトリクスに直接対応します。各リソースタイプに使用できるすべてのメトリクスは、「リソースモニタリングリファレンス」に一覧表示さ 『れます』。
| 条件のタイプ | description |
|---|---|
| メトリクス | 確認される特定の監視エリアと、応答をトリガーするその領域のしきい値。通常、メトリクスは何らかの数値の応答です(CPU の使用率、要求数、またはキャッシュヒット比率など)。 |
| trait | 特定の設定の値の変更。特性は通常文字列の値です。 |
| 可用性 | このリソースが利用できるかどうかが突然変更されています。 |
| operation | リソースで実行される特定のアクションまたはタスク。 |
| イベント | 特定のタイプのエラーメッセージが記録されます。イベントはシステムまたはアプリケーションのログファイルからフィルターされ、JBoss ON で認識されるイベントのタイプは、リソースのイベント設定によって異なります。 |
| drift | 事前定義された設定からリソースが変更されました。 |
25.2.2. 詳細なディスカッション: 条件のある Ranges、AND、および OR 演算子
リンクのコピーリンクがクリップボードにコピーされました!
アラートは、監視情報に基づきます。これは、管理者が通知を受け取るか、特定のイベントまたはメトリクスの値が発生した場合に実行するアクションを定義するエクステンションです。
アラートをトリガーするモニタリングポイントはアラート状態です。最も分かりやすく、アラート状態は単一のイベントまたは読み取りです。X が発生した場合は、アラートがトリガーされます。
実際、X はアラートを保証するほど不十分な場合や、リソースの状態を適切に記述できない場合があります。異なる条件で同じ応答が必要となる場合や、複数の条件が true の場合のみ重要となる場合があります。アラートは、これらの条件間で確立された関係で複数の条件を定義できるため、柔軟性が非常に高くなります。
次のレベルの複雑さは、X または Y のいずれかが true の場合にアラートを送信することです。アラート定義では、これは論理 OR の ANY オプションです。アラート定義はこれらの条件のいずれかをチェックしますが、それらの条件は相互に関連しません。
最後の複雑さのレベルは、アラートの発行のために条件が相互に関連する必要がある場合です。これは、論理 AND である ALL オプションです。アラートを発行するには、X と Y の両方が必要です。この場合、ある条件が発生すると、サーバーはその定義をロックし、2 つ目の条件が発生するまで待機を開始します。2 つ目の条件が発生すると、アラートが発行されます。
AND 演算子は異なるメトリクスに対して非常に有効ですが、条件が同時に発生する必要がないため、単純な AND 演算子は 同じ メトリクスに意味を持ちません。
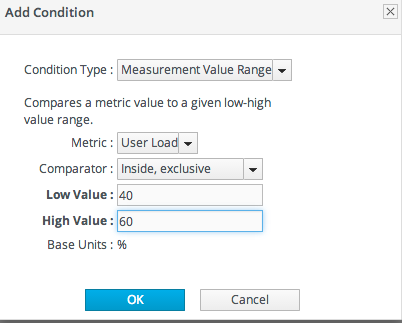
たとえば、Tim(IT 管理者)では、ユーザーの負荷が │ から 60% の間にある場合に限りアラートの発行を希望します。これは、プラットフォームの負荷をわずかに増やすことを示します。AND 演算子の使用を試みると、負荷が │(上記の │ 条件を 3 回)上で増加し、15% にフォールバックすると、(以下の 60% 条件未満の 60% 条件がトリガー)にフォールバックすると、異常値が返されます。
この場合、Tim は range 条件を使用します。範囲には、指定された境界内にある同じメトリクスの 2 つの値が必要です。範囲には、内部の値(40 ~ 60%)を指定するか、または外部範囲(low └ および 60%)を指定できます。
図25.1 アラート条件の範囲
25.2.3. 詳細なディスカッション: ログファイルメッセージに基づく条件
リンクのコピーリンクがクリップボードにコピーされました!
イベント(20章イベント)はフィルターされたログメッセージです。JBoss ON の特定のリソースは、プラットフォームや JBoss EAP サーバーなどのエラーログを維持します。JBoss ON では、これらのエラーログをスキャンして、特定のパターンに一致する特定の重大度またはイベントのイベントを検出できます。これにより、JBoss ON の管理者は、重要なエラーメッセージを特定し、表示できます。
JBoss ON はログイベントを検出できるため、JBoss ON はログイベントをアラートできます。イベントベースの状況には、ログファイルメッセージの重大度と、オプションで特定のメッセージと照合するために使用するパターンが必要です。
図25.2 ログファイルの条件
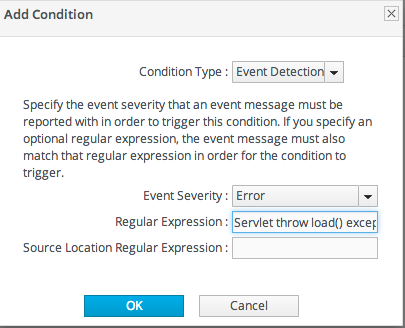
重大度が「重大」のイベントに重大度を設定するアラートのみを設定します。これは、致命的なエラーや致命的なエラーに役に立ち、これは比較的頻度がないため、すぐに注意を促す必要があります。
注記
一般的なエラーメッセージでは、パターンを使用して特定のエラータイプをフィルターします。次に、リソース操作または CLI スクリプトを使用して、リソースの再起動や新しい Web アプリケーションの起動など、特定のエラーに対応するための特定のアクションを実行します。
25.2.4. 詳細ディスカッション: フレームワーク
リンクのコピーリンクがクリップボードにコピーされました!
依存関係はアラート状態を定義しませんが、JBoss ON サーバーに対して定期的な条件の処理方法を指示します。
アラートは、条件が満たされるたびにアラートを発行するか、管理者が承認するまでアラートを発行して無効にすることができます。状態 を破損させると、継続中の単一の状況に対して、複数のアラートおよび通知が送信されるのを防ぐのに役立ちます。
図25.3 Dampening Filter
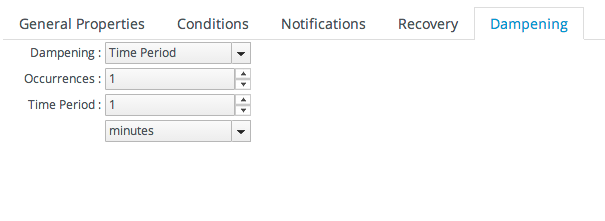
たとえば、Tim(IT Guy)は、プラットフォーム CPU の使用率が 50% を超えるかどうかをユーザーに通知するためにアラートを設定します。監視スキャンが実行されるたびに、メトリクスは再び true と判断され、新規インスタンスおよび個別インスタンスとして処理されます。メトリクススケジュールが 10 分間設定され、アラートに応答するのに 1 時間かかる場合、応答する前に 6 つまたは 7 つのアラート通知がある可能性があります。アラート応答のみがメールである場合、これは問題ではありません。
しかし、Tim(Tim)の IT Guy に、EAP 接続数が特定の時点よりも大きい場合に新しい JBoss サーバーを作成するアラート応答がある場合に、実際に 1 回実行すべき場合は、同じ応答が 6 回または 7 回取得され、条件が実際に解決されます。
依存関係は、別のアラートをトリガーする前に条件を評価する方法についてのもう 1 つの命令セットです。これは、これらのモニタリングデータを解釈する方法を JBoss ON に指示します。
- JBoss ON は、条件が発生するたびにアラートを送信できます。この場合、CPU のパーセンテージがバウンスした場合に複数のアラートが発行されますが、これに一時的にヒットまたはヒットした場合にアラートが送信されるのは 1 つのアラートだけです。
- JBoss ON は、条件が連続して、または Y 回のポーリング数の X 回数で発生した場合にのみアラートを送信できます。この場合、繰り返しまたは持続された問題のみがアラートをトリガーします。通知を出力するには不十分です。状態は、問題になるために短期間に複数回発生する必要がある場合がありますが、一度は問題ではありません。たとえば、サーバーが数分で 7 つの CPU から 80% までの CPU をバウンスする可能性があり、数秒で 1 分の 1 に達する可能性があります。あるいは、8 分の 1 に達する可能性があり、そこに留まる可能性があります。この条件は、CPU のヒット率 20% が残り、他の読み取りは無視されます。
- 設定した期間内に問題が発生した場合にのみ通知が送信されます。これは、繰り返し発生する問題の頻度を追跡したり、状態が持続する期間を追跡するのに便利です。
注記
ハイフンは、変数で何らかの基準と比較されるメトリクスにのみ関係します。しきい値および値の変更のあるメトリクスの監視は動的であるため、各読み取りは以前の読み取りと一致しても実際の状態になります。次に、複数の同様の読み取りを制御します。
ステータス変更と直接関係する条件は、自身をベースラインと比較するのではなく、以前の状態としか比較しません。たとえば、ドリフトテンプレートからシステム設定を変更した場合や、可用性が変更した場合は 1 回限りの変更になります。その後、リソースのステータスは新しい状態になり、今後の変更が新しいステータスと比較されるため、ある意味が異なる条件となります。
ハイフンは、ドリフトと可用性の変更に概念的には適用されません。
25.2.5. 詳細なディスカッション: アラートの自動無効化およびリカバリー
リンクのコピーリンクがクリップボードにコピーされました!
同じ確認された状態に対してアラート通知が送信される頻度を制限するには、いくつかの方法があります。1 つの方法では、破損したルールがあります。別の方法として、アラートの初回起動時にアラートを無効にし、管理者が手動で実行するか、または 条件自体がリセットされた場合にのみアラートを再度有効にします。2 番目のオプション - 無効にしてからリセットする - アラートを回復します。
リカバリーアラートは 、実際には、条件の変更時に関連するアラートを無効にし、有効にするために調整を行うアラートのペアです。
いくつかのワークフローは、復旧アラートで一般的に使用されます。
- アラートのペアは、相互トグルスイッチとして機能します。あるアラートがアクティブな場合、もう 1 つは無効になります。Alert A が起動すると、指定した Alert B をリカバリーするように設定できます。したがって、Alert B は基本的にその代わりに使用されます。
- アラートは CAScade の種類として機能します。Alert A が起動すると、Alert B が有効になり、Alert C が有効になります。場合によっては、特定の状態が問題にならない可能性がありますが、短期間に連続して発生すると問題になります。
図25.4 アラートの無効化およびリカバリー

たとえば、Alert A は、リソースの可用性がダウンするとアラートをトリガーします。Alert A が発生すると、それ自体が無効(または有効化)されます。Alert B は、リソースの可用性が起動するとアラートを出力します。Alert B も実行すると、それ自体を無効にし、A を復旧します。
リカバリーアラートは、問題が発生してから、解決時に管理者に通知します。可用性の例では、最初のアラートにより、管理者はリソースがオフラインであることを確認できますが、2 つ目のアラートにより、そのリソースがオンラインに戻ることを管理者が通知します。
Setup: Toggle Recover Alerts for Availability
Tim(IT 管理者)には、電子メールのルーティングやその他のオペレーションに使用する複数のサーバーがあり、バックアップとして予約している複数のマシンがあります。
プライマリーメールサーバー mail-server-a.example.com があり、オフライン時のみ mail-server-b.example.com オンラインにしたいだけです。その後、戻るときには予約の mail-server-a 状態に戻したいと考え mail-server-a ます。
The Plan
Tim は、メールサーバー間の移行を処理するため、アラート定義のセットを作成します。
- mail-server-a プラットフォームの可用性の状態が ダウンすると、最初のアラート定義が 実行されます。この通知は、以下の点をいくつか行います。
- 最新のメールサーバー設定でバンドルを別のプラットフォームにデプロイする mail-server-b。
- コマンドラインスクリプトを実行し、メールサービス mail-server-b を起動します。
- Email Tim the IT Guy to know that mail-server-a is unavailable.
リカバリーでは、アラートは以下の 2 つの処理を行います。- 現在のアラートを無効にします。バックアップサーバーをオンラインにするには、一度だけ起動する必要があります。
- JBoss ON がバックアップを待機するよう mail-server-a に、アラート B を回復(または有効化)します。
- 2 つ目のアラート定義 Alert B は、mail-server-a がオフライン時 にのみ有効です。このアラートは、可用性の状態 が mail-server-b 変更されるとすぐに実行されます。
- このアラート定義は、基本的にダウンして mail-server-a いる限り待機します。オンラインに mail-server-a 戻ると、Alert B の通知は、メールサービスを停止する mail-server-b ためのコマンドラインスクリプトの実行です。
- アラート B は、Tim the IT Guy に通知メールを送信し、再び mail-server-a 利用できることを通知します。
リカバリーでは、アラートは以下の 2 つの処理を行います。- 現在のアラートを無効にします。Alert A と同様に、Alert B は、プライマリーサーバーが復元するとすぐにバックアップを停止する必要があります。
- アラート A をリカバリー(または有効化)するので、JBoss ON は再びダウン mail-server-a するまで待機します。