18.3. 詳細なディスカッション: 可用性の期間とパフォーマンス
監視メカニズムとしての可用性には、2 つの重要なファセットがあります。変更時の影響と、可用性の変更がリソースパフォーマンスを反映している状況の観点です。
履歴的な観点では、可用性の期間 が紹介されます。特定の状態のリソース期間。どの頻度が変更するか?
図18.4 可用性数
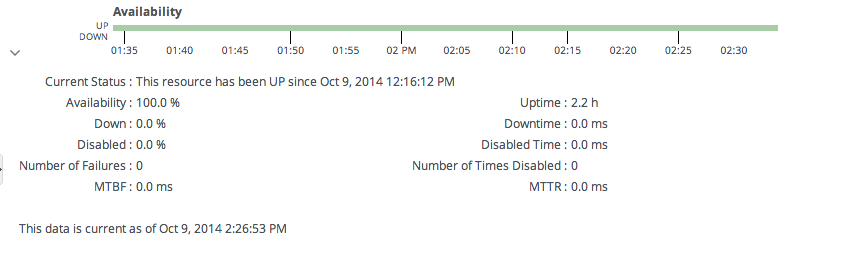
リソースの実行方法を正確に把握するには、可用性期間の概念が重要です。この情報を JBoss ON が破損する方法は複数あります。
- up、down、および disabled 状態の合計時間
- 稼働時間、ダウン状態、および無効な状態の時間の割合
- リソースがダウン状態または無効状態にある回数
- 障害(MTBF)と平均リカバリー時間(MTTR)の平均時間。
注記
未知の状態は、リソースの全体的な可用性履歴の計算には含まれません。
最後の要素は、可用性を考慮してリソースのパフォーマンスを評価する上で特に重要になります。障害間の平均期間 は、リソースが起動し、次に停止するまでの時間です。これは、平均です。 [4] すべてのアップ期間。これにより、システムがどの程度安定しているかがわかります。リカバリーの平均時間は、耐障害性または耐障害性を示すリソースがどの程度停止する かを把握します。MTBF および高 MTTR の低い場合は、メンテナンスの問題や、リソースに対するアプリケーションの不安定性を示します。
図18.5 アップアンドダウンの監視
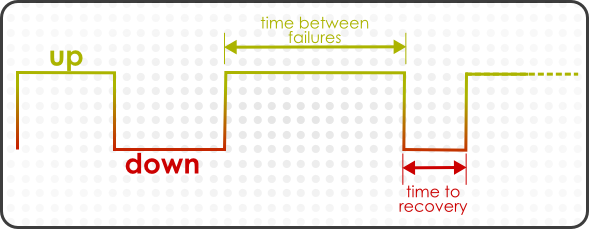
監視パースペクティブでは、特に機器の置き換えやアップグレードの計画時に、履歴の観点が重要です。
即時応答の観点から、アラートの観点から、可用性の変更のみを行います。
first および最も明確なアラート状態は、状態の変更のみに基づいてアラートを発行します。
ただし、リソースは、リソースの全体的なパフォーマンスや、実行している機能に影響を及ぼすことはありませんが、リソースにアクセスできない数秒または数分かかる場合があります。リソースは特定の状態に達し、状態が重要になる前に一定期間そこに留まる必要があります。
図18.6 可用性の期間アラート
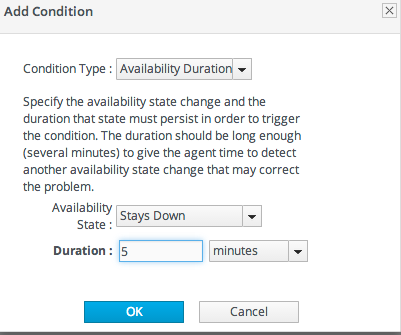
注記
可用性アラートは、リソースが down 状態に切り替わった際に発生する可用性アラートなどの状態が変更し続け、その後も引き続き利用できるため、可用性アラート自体は輻輳状態になります。リソースが循環している場合は、そのリソースで数回停止して稼働し、毎回新しいアラートをトリガーする場合がありますが、リソースで同じパフォーマンスの問題に関連する可能性があります。
輻輳の代わりに、アラートで無効を設定すると、で説明されているように管理者が承認するまでアラートの定義が 1 度実行され、そのアラート定義が無効になり 「詳細なディスカッション: アラートの自動無効化およびリカバリー」 ます。(この場合、対応するリカバリー設定を設定しないでください。リソースがサイクリングの場合は、すべての UP 読み込みによってアラートがリセットされ、次の DOWN レポートが別の通知を発生させます。基本的に、警告が承認されるまで無効にする不利な影響が取り消されます。)