3.5. AWS에서 Red Hat OpenShift Service의 프로세스 및 보안 이해
이 문서에서는 ROSA(Red Hat OpenShift Service on AWS)를 관리하는 Red Hat의 역할에 대해 자세히 설명합니다.
약어 및 용어
- AWS - Amazon Web Services
- CEE - 고객 경험 및 참여 (Red Hat 지원)
- CI/CD - 지속적 통합/지속적인 제공
- CVE - Common Vulnerabilities and Exposures
- PV - 영구 볼륨
- ROSA - Red Hat OpenShift Service on AWS
- SRE - Red Hat 사이트 안정성 엔지니어링
- VPC - 가상 프라이빗 클라우드
3.5.1. 사고 및 운영 관리
이 문서에서는 ROSA(Red Hat OpenShift Service on AWS) 관리 서비스에 대한 Red Hat 책임이 자세히 설명되어 있습니다.
3.5.1.1. 플랫폼 모니터링
Red Hat 사이트 안정성 엔지니어(SRE)는 모든 ROSA 클러스터 구성 요소, SRE 서비스 및 기본 AWS 계정에 대한 중앙 집중식 모니터링 및 경고 시스템을 유지합니다. 플랫폼 감사 로그는 중앙 집중식 보안 정보 및 이벤트 모니터링(SIEM) 시스템으로 안전하게 전달되며, 여기서 SRE 팀에 구성된 경고를 트리거할 수 있으며 수동 검토도 받습니다. 감사 로그는 SIEM 시스템에 1년 동안 유지됩니다. 지정된 클러스터에 대한 감사 로그는 클러스터를 삭제할 때 삭제되지 않습니다.
3.5.1.2. 사고 관리
사고는 하나 이상의 Red Hat 서비스의 성능 저하 또는 중단을 초래하는 이벤트입니다. 기술 지원 케이스를 통해 고객 또는 고객 경험 및 참여(CEE)의 사고는 중앙 집중식 모니터링 및 경고 시스템에 의해 직접 발생하거나 SRE 팀의 구성원에 의해 발생할 수 있습니다.
서비스 및 고객에 미치는 영향에 따라 보안 사고는 심각도 별로 분류됩니다.
Red Hat은 새로운 사고를 관리할 때 다음과 같은 일반 워크플로를 사용합니다.
- SRE 첫 번째 대응자는 새로운 사고에 대한 경고를 받고 있으며 초기 조사를 시작합니다.
- 초기 조사 후 사고의 선두주자가 할당되며, 이는 복구 노력을 조정합니다.
- 사고 대응자는 관련 알림 및 지원 케이스 업데이트를 포함하여 모든 통신을 관리하고 복구에 대한 조정을 관리합니다.
- 이 사고는 복구되었습니다.
- 이 사고는 문서화되어 있으며 근본적인 원인 분석 (RCA)은 사고 후 5 일 이내에 수행됩니다.
- RCA 초안 문서는 사고 후 7일 이내에 고객과 공유됩니다.
3.5.1.3. 알림
플랫폼 알림은 이메일을 사용하여 구성됩니다. 일부 고객 알림은 필요한 경우 기술 계정 관리자를 포함하여 계정의 해당 Red Hat 계정 팀으로 전송됩니다.
다음 활동을 통해 알림을 트리거할 수 있습니다.
- 플랫폼 사고
- 성능 저하
- 클러스터 용량 경고
- 심각한 취약점 및 해결 방법
- 업그레이드 스케줄링
3.5.1.4. 인프라 및 데이터 복원력
고객은 데이터의 정기적인 백업을 수행해야 하며 Kubernetes 모범 사례를 따르는 워크로드가 포함된 다중 AZ 클러스터를 배포하여 한 리전 내에서 고가용성을 보장해야 합니다. 전체 클라우드 리전을 사용할 수 없는 경우 고객은 다른 지역에 새 클러스터를 설치하고 백업 데이터를 사용하여 앱을 복원해야 합니다.
STS를 사용하는 ROSA 클러스터에 사용할 수 있는 Red Hat 제공 백업 방법은 없습니다. Red Hat은 PREO (Resupation Point Objective) 또는 RTO (RTO)에 커밋하지 않습니다.
3.5.1.5. 클러스터 용량
클러스터 용량을 평가하고 관리하는 것은 Red Hat과 고객 간에 공유됩니다. Red Hat SRE는 클러스터의 모든 컨트롤 플레인 및 인프라 노드의 용량을 담당합니다.
Red Hat SRE는 업그레이드 중 및 클러스터 경고에 대한 응답으로 클러스터 용량도 평가합니다. 용량에 대한 클러스터 업그레이드의 영향은 업그레이드 테스트 프로세스의 일부로 평가되어 클러스터에 새로 추가된 용량의 부정적인 영향을 받지 않도록 합니다. 클러스터 업그레이드 중에 업그레이드 프로세스 중에 총 클러스터 용량을 유지하도록 추가 작업자 노드가 추가됩니다.
Red Hat SRE 직원의 용량 평가는 특정 기간 동안 사용량 임계값을 초과한 후 클러스터의 경고에 대한 응답으로도 수행됩니다. 이러한 경고는 고객에게 통지가 발생할 수도 있습니다.
3.5.2. 변경 관리
이 섹션에서는 클러스터 및 구성 변경, 패치 및 릴리스를 관리하는 방법에 대한 정책에 대해 설명합니다.
3.5.2.1. 고객 시작 변경
클러스터 배포, 작업자 노드 확장 또는 클러스터 삭제와 같은 셀프 서비스 기능을 사용하여 변경 사항을 시작할 수 있습니다.
변경 내역은 OpenShift Cluster Manager 개요 탭 의 클러스터 기록 섹션에서 캡처되며 사용자가 확인할 수 있습니다. 변경 내역에는 다음이 포함되지만 이에 국한되지는 않으며 다음 변경 사항의 로그가 포함됩니다.
- ID 공급자 추가 또는 제거
-
dedicated-admins그룹에 사용자 추가 또는 제거 - 클러스터 컴퓨팅 노드 확장
- 클러스터 로드 밸런서 스케일링
- 클러스터 영구 스토리지 스케일링
- 클러스터 업그레이드
다음 구성 요소에 대해 OpenShift Cluster Manager의 변경 사항을 방지하여 유지 관리 제외를 구현할 수 있습니다.
- 클러스터 삭제
- ID 공급자 추가, 수정 또는 제거
- 승격된 그룹에서 사용자 추가, 수정 또는 제거
- 애드온 설치 또는 제거
- 클러스터 네트워킹 구성 수정
- 머신 풀 추가, 수정 또는 제거
- 사용자 워크로드 모니터링 활성화 또는 비활성화
- 업그레이드 시작
유지 관리 제외를 적용하려면 머신 풀 자동 스케일링 또는 자동 업그레이드 정책을 비활성화해야 합니다. 유지 관리 제외가 해제된 후 필요에 따라 머신 풀 자동 스케일링 또는 자동 업그레이드 정책 활성화를 진행합니다.
3.5.2.2. Red Hat 시작 변경
Red Hat 사이트 안정성 엔지니어링(SRE)은 GitOps 워크플로 및 완전 자동화된 CI/CD 파이프라인을 사용하여 AWS에서 Red Hat OpenShift Service의 인프라, 코드 및 구성을 관리합니다. 이 프로세스를 통해 Red Hat은 고객에게 부정적인 영향을 미치지 않고 지속적으로 서비스 개선을 지속적으로 개선할 수 있습니다.
제안된 모든 변경 사항은 점검 즉시 일련의 자동 검증을 거칩니다. 그런 다음 변경 사항이 자동화된 통합 테스트를 받는 스테이징 환경에 배포됩니다. 마지막으로 변경 사항이 프로덕션 환경에 배포됩니다. 각 단계는 완전히 자동화됩니다.
승인된 SRE 검토자는 각 단계에 대한 진행을 승인해야 합니다. 검토자는 변경 사항을 제안한 동일한 개인일 수 없습니다. 모든 변경 사항 및 승인은 GitOps 워크플로우의 일부로 완전히 감사할 수 있습니다.
기능 플래그를 사용하여 지정된 클러스터 또는 고객에 대한 새 기능의 가용성을 제어하는 일부 변경 사항이 증분적으로 릴리스됩니다.
3.5.2.3. 패치 관리
OpenShift Container Platform 소프트웨어 및 기본 변경 불가능한 RHCOS (Red Hat CoreOS) 운영 체제 이미지는 일반 z-stream 업그레이드의 버그 및 취약점에 대해 패치됩니다. OpenShift Container Platform 설명서에서 RHCOS 아키텍처에 대해 자세히 알아보십시오.
3.5.2.4. 릴리스 관리
Red Hat은 클러스터를 자동으로 업그레이드하지 않습니다. OpenShift Cluster Manager 웹 콘솔을 사용하여 클러스터를 정기적인 간격으로 업그레이드하거나 (개인 업그레이드) 한 번만 예약할 수 있습니다. Red Hat은 클러스터가 심각한 영향 CVE의 영향을 받는 경우에만 클러스터를 새 z-stream 버전으로 강제로 업그레이드할 수 있습니다.
필요한 권한이 y-stream 릴리스 간에 변경될 수 있으므로 업그레이드를 수행하기 전에 정책을 업데이트해야 할 수 있습니다. 따라서 STS를 사용하여 ROSA 클러스터에서 반복 업그레이드를 예약할 수 없습니다.
OpenShift Cluster Manager 웹 콘솔에서 모든 클러스터 업그레이드 이벤트 기록을 검토할 수 있습니다. 릴리스에 대한 자세한 내용은 라이프 사이클 정책을 참조하십시오.
3.5.3. ID 및 액세스 관리
대부분의 SRE(사이트 안정성 엔지니어링) 팀은 자동화된 구성 관리를 통해 클러스터 Operator를 사용하여 수행됩니다.
3.5.3.1. 하위 프로세서
사용 가능한 하위 프로세서 목록은 Red Hat 고객 포털의 Red Hat 하위 프로세서 목록을 참조하십시오.
3.5.3.2. AWS 클러스터의 모든 Red Hat OpenShift Service에 대한 SRE 액세스
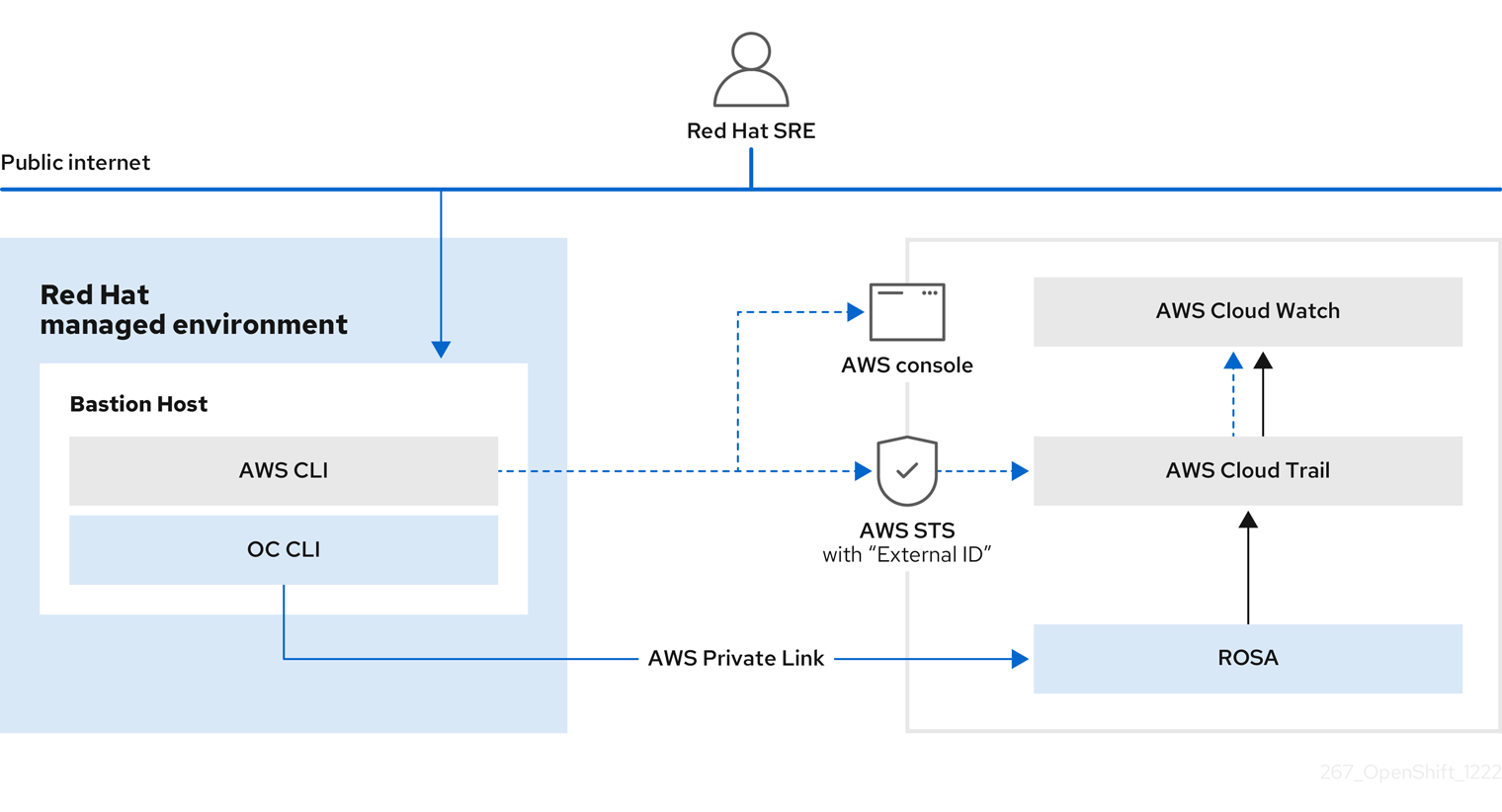
SRES는 웹 콘솔 또는 명령줄 툴을 통해 AWS 클러스터의 Red Hat OpenShift Service에 액세스합니다. 인증에는 암호 복잡성 및 계정 잠금에 대한 업계 표준 요구 사항이 있는 MFA(다중 인증)가 필요합니다. SRES는 감사성을 보장하기 위해 개인으로 인증해야 합니다. 모든 인증 시도가 SIEM(Security Information and Event Management) 시스템에 기록됩니다.
SRES는 암호화된 HTTP 연결을 사용하여 프라이빗 클러스터에 액세스합니다. 연결은 IP 허용 목록 또는 프라이빗 클라우드 공급자 링크를 사용하는 Red Hat 네트워크에서만 허용됩니다.
그림 3.1. ROSA 클러스터에 대한 SRE 액세스
3.5.3.3. AWS의 Red Hat OpenShift Service에서 권한 있는 액세스 제어
SRE는 AWS 및 AWS 구성 요소에서 Red Hat OpenShift Service에 액세스할 때 최소 권한 원칙을 준수합니다. 수동 SRE 액세스의 네 가지 기본 카테고리가 있습니다.
- 일반적인 2 단계 인증 및 권한 없는 고도와 함께 Red Hat 포털을 통해 SRE 관리자 액세스.
- 정상적인 2 단계 인증으로 Red Hat 기업 SSO를 통한 SRE 관리자 액세스 및 권한 없는 고도.
- Red Hat SSO를 사용한 수동 승격인 OpenShift 승격. 액세스는 2시간으로 제한되며 완전히 감사되며 관리 승인이 필요합니다.
- AWS 콘솔 또는 CLI 액세스에 대한 수동 승격인 AWS 액세스 또는 승격. 액세스는 60분으로 제한되며 완전히 감사됩니다.
이러한 액세스 유형에는 각각 다른 수준의 구성 요소에 대한 액세스 수준이 있습니다.
| 구성 요소 | 일반적인 SRE 관리자 액세스 (Red Hat Portal) | 일반적인 SRE 관리자 액세스(Red Hat SSO) | OpenShift 고도 | 클라우드 공급자 액세스 또는 승격 |
|---|---|---|---|---|
| OpenShift Cluster Manager | R/W | 액세스 권한 없음 | 액세스 권한 없음 | 액세스 권한 없음 |
| OpenShift 콘솔 | 액세스 권한 없음 | R/W | R/W | 액세스 권한 없음 |
| 노드 운영 체제 | 액세스 권한 없음 | 승격된 OS 및 네트워크 권한의 특정 목록입니다. | 승격된 OS 및 네트워크 권한의 특정 목록입니다. | 액세스 권한 없음 |
| AWS Console | 액세스 권한 없음 | 액세스 권한은 없지만 클라우드 공급자 액세스를 요청하는 데 사용되는 계정입니다. | 액세스 권한 없음 | SRE ID를 사용하는 모든 클라우드 공급자 권한. |
3.5.3.4. AWS 계정에 대한 SRE 액세스
Red Hat 인력은 일상적인 Red Hat OpenShift Service 과정에서 AWS 작업에 대한 AWS 계정에 액세스하지 않습니다. 긴급 문제 해결을 위해 SRE는 클라우드 인프라 계정에 액세스하기 위한 잘 정의되고 감사 가능한 절차가 있습니다.
SRES는 AWS STS(보안 토큰 서비스)를 사용하여 예약된 역할에 대한 단기 AWS 액세스 토큰을 생성합니다. STS 토큰에 대한 액세스는 감사로 기록되고 개별 사용자로 추적할 수 있습니다. STS 및 비STS 클러스터 모두 SRE 액세스에 AWS STS 서비스를 사용합니다. STS가 아닌 클러스터의 경우 BYOCAdminAccess 역할에 AdministratorAccess IAM 정책이 연결되어 있으며 이 역할은 관리에 사용됩니다. STS 클러스터의 경우 ManagedOpenShift-Support-Role 에 ManagedOpenShift-Support-Access 정책이 연결되었으며 이 역할은 관리에 사용됩니다.
3.5.3.5. Red Hat 지원 액세스
Red Hat CEE(Customer Experience and Engagement) 팀의 구성원은 일반적으로 클러스터의 일부에 대한 읽기 전용 권한을 갖습니다. 특히 CEE는 핵심 및 제품 네임스페이스에 대한 액세스를 제한하고 고객 네임스페이스에 대한 액세스 권한이 없습니다.
| Role | 코어 네임스페이스 | 계층화된 제품 네임스페이스 | 고객 네임스페이스 | AWS 계정* |
|---|---|---|---|---|
| OpenShift SRE | 읽기: 모두 쓰기: Very 제한된 [1] | 읽기: 모두 쓰기: 없음 | 읽기: None[2] 쓰기: 없음 | 읽기: 모두 [3] 모두 쓰기 [3] |
| CEE | 읽기: 모두 쓰기: 없음 | 읽기: 모두 쓰기: 없음 | 읽기: None[2] 쓰기: 없음 | 읽기: 없음 쓰기: 없음 |
| 고객 관리자 | 읽기: 없음 쓰기: 없음 | 읽기: 없음 쓰기: 없음 | 읽기: 모두 쓰기: 모두 | 읽기: 모두 쓰기: 모두 |
| 고객 사용자 | 읽기: 없음 쓰기: 없음 | 읽기: 없음 쓰기: 없음 | 읽기: Limited[4] 쓰기: 제한됨[4] | 읽기: 없음 쓰기: 없음 |
| 다른 모든 사람 | 읽기: 없음 쓰기: 없음 | 읽기: 없음 쓰기: 없음 | 읽기: 없음 쓰기: 없음 | 읽기: 없음 쓰기: 없음 |
- 실패한 배포, 클러스터 업그레이드, 잘못된 작업자 노드 교체와 같은 일반적인 사용 사례 처리로 제한됩니다.
- Red Hat 직원은 기본적으로 고객 데이터에 액세스할 수 없습니다.
- AWS 계정에 대한 SRE 액세스는 문서화된 사고 중에 예외적인 문제 해결을 위한 긴급 절차입니다.
- 고객 관리자가 RBAC를 통해 부여한 항목 및 사용자가 생성한 네임스페이스로 제한됩니다.
3.5.3.6. 고객 액세스
고객 액세스는 고객이 생성한 네임스페이스 및 고객 관리자 역할에서 RBAC를 사용하여 부여하는 권한으로 제한됩니다. 기본 인프라 또는 제품 네임스페이스에 대한 액세스는 일반적으로 cluster-admin 액세스없이 허용되지 않습니다. 고객 액세스 및 인증에 대한 자세한 내용은 문서의 "기술 이해" 섹션에서 확인할 수 있습니다.
3.5.3.7. 액세스 승인 및 검토
새로운 SRE 사용자 액세스에는 관리 승인이 필요합니다. 분리되거나 전송된 SRE 계정은 자동화된 프로세스를 통해 권한 있는 사용자로 제거됩니다. 또한 SRE는 권한 있는 사용자 목록의 관리 서명을 포함하여 정기적인 액세스 검토를 수행합니다.
3.5.4. 보안 및 규정 준수
보안 및 규정 준수에는 보안 제어 및 컴플라이언스 인증 구현과 같은 작업이 포함됩니다.
3.5.4.1. 데이터 분류
Red Hat은 데이터 분류 표준을 정의하고 준수하여 데이터의 민감도를 결정하고 수집, 사용, 전송, 저장 및 처리되는 데이터의 기밀성 및 무결성에 대한 내재적인 위험을 강조합니다. 고객 소유 데이터는 최고 수준의 민감도 및 처리 요구 사항으로 분류됩니다.
3.5.4.2. 데이터 관리
Red Hat OpenShift Service on AWS (ROSA)는 AWS KMS(Key Management Service)를 사용하여 암호화된 데이터의 키를 안전하게 관리합니다. 이러한 키는 기본적으로 암호화된 컨트롤 플레인, 인프라 및 작업자 데이터 볼륨에 사용됩니다. 고객 애플리케이션의 PV(영구 볼륨)도 키 관리를 위해 AWS KMS를 사용합니다.
고객이 ROSA 클러스터를 삭제하면 컨트롤 플레인 데이터 볼륨 및 PV(영구 볼륨)와 같은 고객 애플리케이션 데이터 볼륨을 포함하여 모든 클러스터 데이터가 영구적으로 삭제됩니다.
3.5.4.3. 취약점 관리
Red Hat은 산업 표준 툴을 사용하여 ROSA의 정기적인 취약점 검사를 수행합니다. 확인된 취약점은 심각도에 따라 타임라인에 따라 수정에 추적됩니다. 취약점 스캔 및 수정 활동에는 규정 준수 인증 감사 과정에서 타사 평가자가 확인할 수 있도록 문서화되어 있습니다.
3.5.4.4. 네트워크 보안
3.5.4.4.1. 방화벽 및 CloudEvent 보호
각 ROSA 클러스터는 AWS 보안 그룹에 대한 방화벽 규칙을 사용하여 보안 네트워크 구성으로 보호됩니다. ROSA 고객은 AWS Shield Standard 를 사용하여 CloudEvent 보안 공격을 방지할 수 있습니다.
3.5.4.4.2. 프라이빗 클러스터 및 네트워크 연결
고객은 선택적으로 웹 콘솔, API 및 애플리케이션 라우터와 같은 ROSA 클러스터 끝점을 구성하여 비공개로 설정하여 클러스터 컨트롤 플레인 및 애플리케이션에 액세스할 수 없습니다. Red Hat SRE는 여전히 IP 허용 목록으로 보호되는 인터넷 액세스 가능한 엔드 포인트가 필요합니다.
AWS 고객은 AWS VPC 피어링, AWS VPN 또는 AWS Direct Connect와 같은 기술을 통해 ROSA 클러스터에 대한 프라이빗 네트워크 연결을 구성할 수 있습니다.
3.5.4.4.3. 클러스터 네트워크 액세스 제어
고객이 NetworkPolicy 오브젝트 및 OpenShift SDN을 사용하여 세분화된 네트워크 액세스 제어 규칙을 프로젝트별로 구성할 수 있습니다.
3.5.4.5. Penetration 테스트
Red Hat은 ROSA에 대해 정기적인 검사 테스트를 수행합니다. 테스트는 산업 표준 툴과 모범 사례를 사용하여 독립적인 내부 팀에서 수행합니다.
발견된 문제는 심각도에 따라 우선 순위가 지정됩니다. 오픈 소스 프로젝트에 속하는 모든 문제는 해결을 위해 커뮤니티와 공유됩니다.
3.5.4.6. 컴플라이언스
AWS 기반의 Red Hat OpenShift Service는 보안 및 제어를 위한 일반적인 업계 모범 사례를 따릅니다. 인증은 다음 표에 설명되어 있습니다.
| 인증 | Red Hat Openshift Service on AWS |
|---|---|
| HIPAA | 제공됨 |
| ISO 27001 | 제공됨 |
| ISO 27017 | 제공됨 |
| ISO 27018 | 제공됨 |
| PCI DSS | 제공됨 |
| SOC 2 Type 2 | 제공됨 |
3.5.5. 재해 복구
Red Hat OpenShift Service on AWS(ROSA)는 Pod, 작업자 노드, 인프라 노드, 컨트롤 플레인 노드 및 가용 영역 수준에서 발생하는 장애 발생을 위한 재해 복구 기능을 제공합니다.
모든 재해 복구를 위해서는 고객이 원하는 가용성 수준을 고려하여 고가용성 애플리케이션, 스토리지 및 클러스터 아키텍처(예: 단일 영역 배포 또는 다중 영역 배포)를 배포하는 모범 사례를 사용해야 합니다.
하나의 단일 영역 클러스터는 가용성 영역 또는 지역 중단 시 재해 방지 또는 복구를 제공하지 않습니다. 고객이 유지보수하는 장애 조치가 있는 여러 단일 영역 클러스터에서는 해당 영역 또는 지역 수준에서의 중단을 설명할 수 있습니다.
하나의 다중 영역 클러스터는 전체 리전 중단 시 재해 방지 또는 복구를 제공하지 않습니다. 고객이 유지보수하는 장애 조치가 있는 여러 다중 영역 클러스터는 지역 수준에서의 중단을 설명할 수 있습니다.