1.2. 了解监控堆栈
OpenShift Container Platform 监控堆栈基于 Prometheus 开源项目及其更广的生态系统。监控堆栈包括以下组件:
-
默认平台监控组件。在 OpenShift Container Platform 安装过程中,默认会在
openshift-monitoring项目中安装一组平台监控组件。这为包括 Kubernetes 服务在内的 OpenShift Container Platform 核心组件提供了监控。默认监控堆栈还为集群启用远程健康状态监控。下图中的默认安装部分说明了这些组件。 -
用于监控用户定义项目的组件。在选择性地为用户定义的项目启用监控后,会在
openshift-user-workload-monitoring项目中安装其他监控组件。这为用户定义的项目提供了监控。下图中的用户部分说明了这些组件。
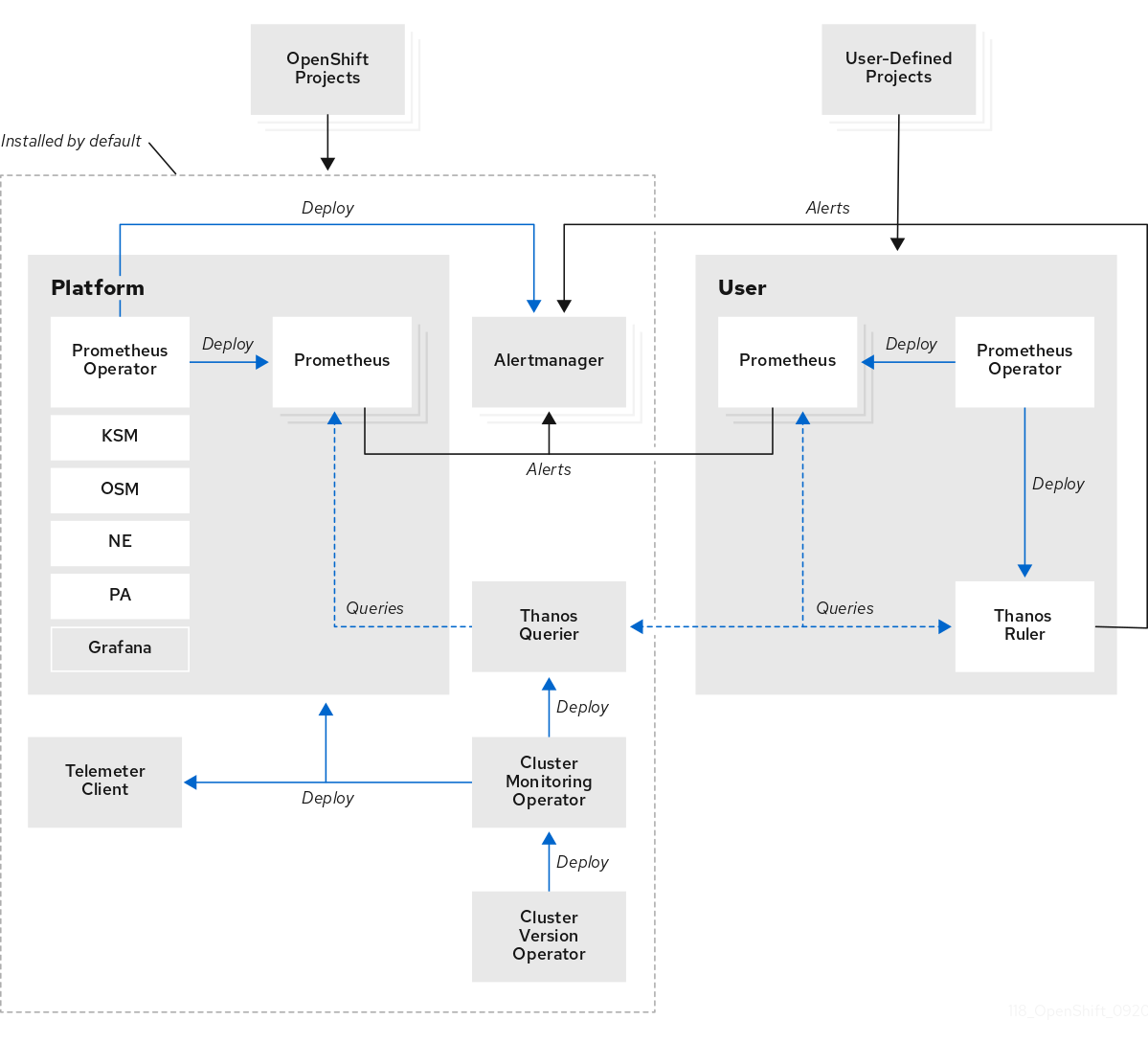
1.2.1. 默认监控组件
默认情况下,OpenShift Container Platform 4.10 监控堆栈包括以下组件:
| 组件 | 描述 |
|---|---|
| Cluster Monitoring Operator | Cluster Monitoring Operator (CMO) 是监控堆栈的核心组件。它部署、管理和自动更新 Prometheus 和 Alertmanager 实例、Thanos Querier、Teleme Client 和 metrics 目标。CMO 由 Cluster Version Operator (CVO) 部署。 |
| Prometheus Operator |
|
| Prometheus | Prometheus 是 OpenShift Container Platform 监控堆栈所依据的监控系统。Prometheus 是一个时间序列数据库和用于指标的规则评估引擎。Prometheus 将警报发送到 Alertmanager 进行处理。 |
| Prometheus Adapter |
Prometheus Adapter(上图中的 PA)负责转换 Kubernetes 节点和 Pod 查询以便在 Prometheus 中使用。转换的资源指标包括 CPU 和内存使用率指标。Prometheus Adapter 会公开用于 Pod 横向自动扩展的集群资源指标 API。Prometheus Adapter 也用于 |
| Alertmanager | Alertmanager 服务处理从 Prometheus 接收的警报。Alertmanager 还负责将警报发送到外部通知系统。 |
|
|
|
|
|
|
|
|
|
| Thanos querier | Thanos Querier 将 OpenShift Container Platform 核心指标和用于用户定义项目的指标聚合在单个多租户接口下,并选择性地进行重复数据删除。 |
| Grafana | Grafana 分析平台提供用于分析和直观呈现指标的仪表板。由监控堆栈提供的 Grafana 实例及其仪表板是只读的。 |
| Telemeter Client | Telemeter Client 将数据的子部分从平台 Prometheus 实例发送到红帽,以便为集群提供远程健康状态监控。 |
监控堆栈中的所有组件都由堆栈监控,并在 OpenShift Container Platform 更新时自动更新。
监控堆栈的所有组件都使用集群管理员集中配置的 TLS 安全配置集设置。如果您配置了使用 TLS 安全设置的监控堆栈组件,组件使用全局 OpenShift Container Platform apiservers.config.openshift.io/cluster 资源中的 tlsSecurityProfile 字段中已存在的 TLS 安全配置集设置。
1.2.2. 默认监控目标
除了堆栈本身的组件外,默认监控堆栈还监控:
- CoreDNS
- Elasticsearch(如果安装了 Logging)
- etcd
- Fluentd(如果安装了 Logging)
- HAProxy
- 镜像 registry
- Kubelets
- Kubernetes API 服务器
- Kubernetes 控制器管理器
- Kubernetes 调度程序
- OpenShift API 服务器
- OpenShift Controller Manager
- Operator Lifecycle Manager (OLM)
每个 OpenShift Container Platform 组件负责自己的监控配置。对于 OpenShift Container Platform 组件监控的问题,请针对具体组件(而非常规的监控组件)创建一个Jira 程序错误报告。
其他 OpenShift Container Platform 框架组件也可能会公开指标。如需详细信息,请参阅相应的文档。
1.2.3. 用于监控用户定义的项目的组件
OpenShift Container Platform 4.10 包括对监控堆栈的可选增强,供您用于监控用户定义的项目中的服务和 Pod。此功能包括以下组件:
| 组件 | 描述 |
|---|---|
| Prometheus Operator |
|
| Prometheus | Prometheus 是为用户定义的项目提供监控的监控系统。Prometheus 将警报发送到 Alertmanager 进行处理。 |
| Thanos Ruler | Thanos Ruler 是 Prometheus 的一个规则评估引擎,作为一个独立的进程来部署。在 OpenShift Container Platform 4.10 中,Thanos Ruler 为监控用户定义的项目提供规则和警报评估。 |
在为用户定义的项目启用监控后,会部署上表中的组件。
监控堆栈中的所有组件都由堆栈监控,并在 OpenShift Container Platform 更新时自动更新。
1.2.4. 用户定义的项目的监控目标
为用户定义的项目启用监控后,您可以监控:
- 通过用户定义的项目中的服务端点提供的指标。
- 在用户定义的项目中运行的 Pod。