Dieser Inhalt ist in der von Ihnen ausgewählten Sprache nicht verfügbar.
Chapter 26. Load balancing with MetalLB
26.1. About MetalLB and the MetalLB Operator
As a cluster administrator, you can add the MetalLB Operator to your cluster so that when a service of type LoadBalancer is added to the cluster, MetalLB can add an external IP address for the service. The external IP address is added to the host network for your cluster.
You can configure MetalLB so that the IP address is advertised with layer 2 protocols. With layer 2, MetalLB provides a fault-tolerant external IP address.
You can configure MetalLB so that the IP address is advertised with the BGP protocol. With BGP, MetalLB provides fault-tolerance for the external IP address and load balancing.
MetalLB supports providing layer 2 for some IP addresses and BGP for other IP addresses.
26.1.1. When to use MetalLB
Using MetalLB is valuable when you have a bare-metal cluster, or an infrastructure that is like bare metal, and you want fault-tolerant access to an application through an external IP address.
You must configure your networking infrastructure to ensure that network traffic for the external IP address is routed from clients to the host network for the cluster.
After deploying MetalLB with the MetalLB Operator, when you add a service of type LoadBalancer, MetalLB provides a platform-native load balancer.
MetalLB operating in layer2 mode provides support for failover by utilizing a mechanism similar to IP failover. However, instead of relying on the virtual router redundancy protocol (VRRP) and keepalived, MetalLB leverages a gossip-based protocol to identify instances of node failure. When a failover is detected, another node assumes the role of the leader node, and a gratuitous ARP message is dispatched to broadcast this change.
MetalLB operating in layer3 or border gateway protocol (BGP) mode delegates failure detection to the network. The BGP router or routers that the OpenShift Container Platform nodes have established a connection with will identify any node failure and terminate the routes to that node.
Using MetalLB instead of IP failover is preferable for ensuring high availability of pods and services.
26.1.2. MetalLB Operator custom resources
The MetalLB Operator monitors its own namespace for the following custom resources:
MetalLB-
When you add a
MetalLBcustom resource to the cluster, the MetalLB Operator deploys MetalLB on the cluster. The Operator only supports a single instance of the custom resource. If the instance is deleted, the Operator removes MetalLB from the cluster. AddressPool-
MetalLB requires one or more pools of IP addresses that it can assign to a service when you add a service of type
LoadBalancer. When you add anAddressPoolcustom resource to the cluster, the MetalLB Operator configures MetalLB so that it can assign IP addresses from the pool. An address pool includes a list of IP addresses. The list can be a single IP address that is set using a range, such as 1.1.1.1-1.1.1.1, a range specified in CIDR notation, a range specified as a starting and ending address separated by a hyphen, or a combination of the three. An address pool requires a name. The documentation uses names likedoc-example,doc-example-reserved, anddoc-example-ipv6. An address pool specifies whether MetalLB can automatically assign IP addresses from the pool or whether the IP addresses are reserved for services that explicitly specify the pool by name. An address pool specifies whether MetalLB uses layer 2 protocols to advertise the IP addresses, or whether the BGP protocol is used. BGPPeer-
The BGP peer custom resource identifies the BGP router for MetalLB to communicate with, the AS number of the router, the AS number for MetalLB, and customizations for route advertisement. MetalLB advertises the routes for service load-balancer IP addresses to one or more BGP peers. The service load-balancer IP addresses are specified with
AddressPoolcustom resources that set theprotocolfield tobgp. BFDProfile- The BFD profile custom resource configures Bidirectional Forwarding Detection (BFD) for a BGP peer. BFD provides faster path failure detection than BGP alone provides.
After you add the MetalLB custom resource to the cluster and the Operator deploys MetalLB, the MetalLB software components, controller and speaker, begin running.
The Operator includes validating webhooks for the AddressPool and BGPPeer custom resources. The webhook for the address pool custom resource performs the following checks:
- Address pool names must be unique.
- IP address ranges do not overlap with an existing address pool.
-
If the address pool includes a
bgpAdvertisementfield, theprotocolfield must be set tobgp.
The webhook for the BGP peer custom resource performs the following checks:
- If the BGP peer name matches an existing peer, the IP address for the peer must be unique.
-
If the
keepaliveTimefield is specified, theholdTimefield must be specified and the keep-alive duration must be less than the hold time. -
The
myASNfield must be the same for all BGP peers.
26.1.3. MetalLB software components
When you install the MetalLB Operator, the metallb-operator-controller-manager deployment starts a pod. The pod is the implementation of the Operator. The pod monitors for changes to the MetalLB custom resource and AddressPool custom resources.
When the Operator starts an instance of MetalLB, it starts a controller deployment and a speaker daemon set.
controllerThe Operator starts the deployment and a single pod. When you add a service of type
LoadBalancer, Kubernetes uses thecontrollerto allocate an IP address from an address pool. In case of a service failure, verify you have the following entry in yourcontrollerpod logs:Example output
"event":"ipAllocated","ip":"172.22.0.201","msg":"IP address assigned by controllerspeakerThe Operator starts a daemon set for
speakerpods. By default, a pod is started on each node in your cluster. You can limit the pods to specific nodes by specifying a node selector in theMetalLBcustom resource when you start MetalLB. If thecontrollerallocated the IP address to the service and service is still unavailable, read thespeakerpod logs. If thespeakerpod is unavailable, run theoc describe pod -ncommand.For layer 2 mode, after the
controllerallocates an IP address for the service, thespeakerpods use an algorithm to determine whichspeakerpod on which node will announce the load balancer IP address. The algorithm involves hashing the node name and the load balancer IP address. For more information, see "MetalLB and external traffic policy". Thespeakeruses Address Resolution Protocol (ARP) to announce IPv4 addresses and Neighbor Discovery Protocol (NDP) to announce IPv6 addresses.
For BGP mode, after the controller allocates an IP address for the service, each speaker pod advertises the load balancer IP address with its BGP peers. You can configure which nodes start BGP sessions with BGP peers.
Requests for the load balancer IP address are routed to the node with the speaker that announces the IP address. After the node receives the packets, the service proxy routes the packets to an endpoint for the service. The endpoint can be on the same node in the optimal case, or it can be on another node. The service proxy chooses an endpoint each time a connection is established.
26.1.4. MetalLB concepts for layer 2 mode
In layer 2 mode, the speaker pod on one node announces the external IP address for a service to the host network. From a network perspective, the node appears to have multiple IP addresses assigned to a network interface.
In layer 2 mode, MetalLB relies on ARP and NDP. These protocols implement local address resolution within a specific subnet. In this context, the client must be able to reach the VIP assigned by MetalLB that exists on the same subnet as the nodes announcing the service in order for MetalLB to work.
The speaker pod responds to ARP requests for IPv4 services and NDP requests for IPv6.
In layer 2 mode, all traffic for a service IP address is routed through one node. After traffic enters the node, the service proxy for the CNI network provider distributes the traffic to all the pods for the service.
Because all traffic for a service enters through a single node in layer 2 mode, in a strict sense, MetalLB does not implement a load balancer for layer 2. Rather, MetalLB implements a failover mechanism for layer 2 so that when a speaker pod becomes unavailable, a speaker pod on a different node can announce the service IP address.
When a node becomes unavailable, failover is automatic. The speaker pods on the other nodes detect that a node is unavailable and a new speaker pod and node take ownership of the service IP address from the failed node.
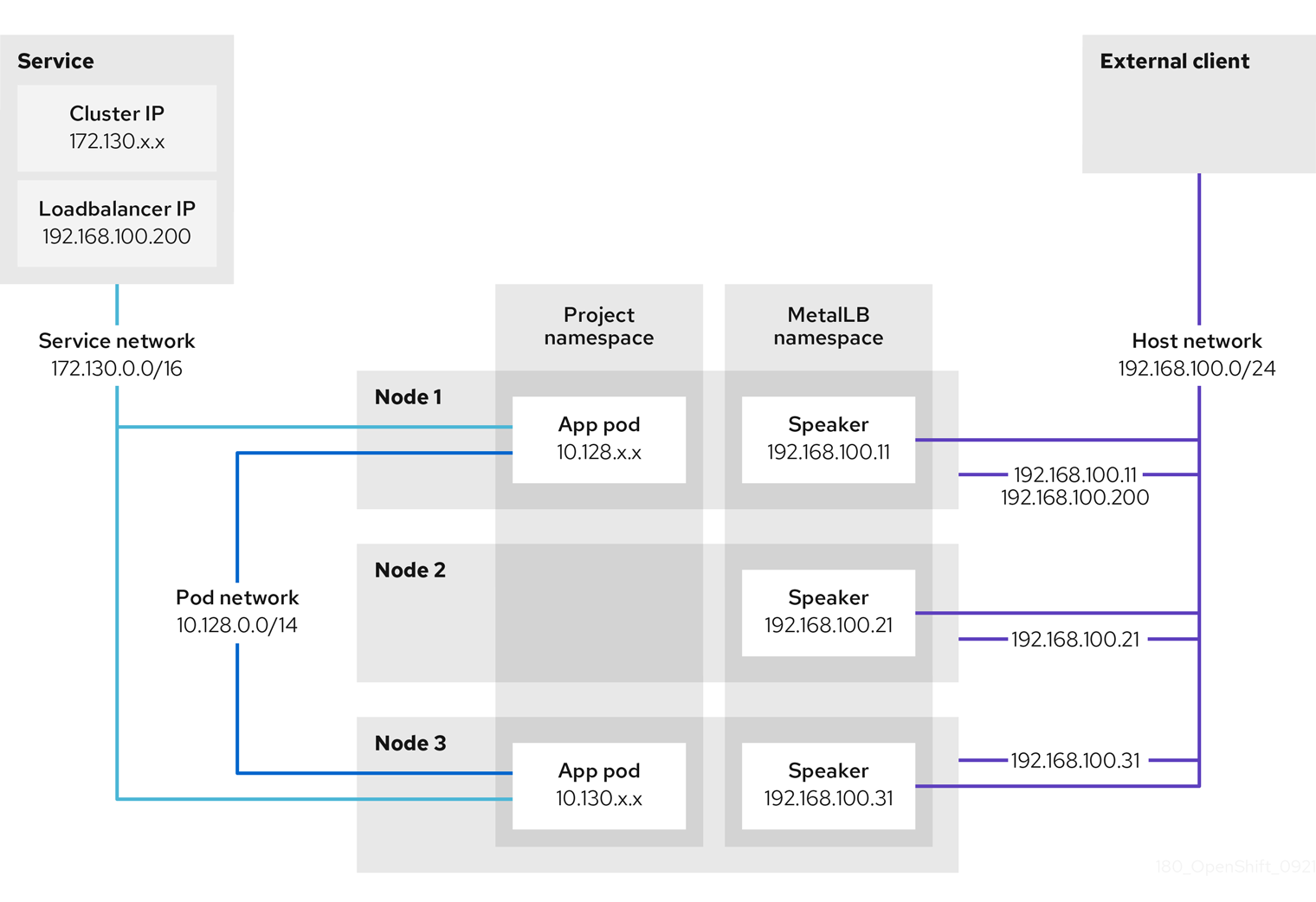
The preceding graphic shows the following concepts related to MetalLB:
-
An application is available through a service that has a cluster IP on the
172.130.0.0/16subnet. That IP address is accessible from inside the cluster. The service also has an external IP address that MetalLB assigned to the service,192.168.100.200. - Nodes 1 and 3 have a pod for the application.
-
The
speakerdaemon set runs a pod on each node. The MetalLB Operator starts these pods. -
Each
speakerpod is a host-networked pod. The IP address for the pod is identical to the IP address for the node on the host network. -
The
speakerpod on node 1 uses ARP to announce the external IP address for the service,192.168.100.200. Thespeakerpod that announces the external IP address must be on the same node as an endpoint for the service and the endpoint must be in theReadycondition. Client traffic is routed to the host network and connects to the
192.168.100.200IP address. After traffic enters the node, the service proxy sends the traffic to the application pod on the same node or another node according to the external traffic policy that you set for the service.-
If the external traffic policy for the service is set to
cluster, the node that advertises the192.168.100.200load balancer IP address is selected from the nodes where aspeakerpod is running. Only that node can receive traffic for the service. -
If the external traffic policy for the service is set to
local, the node that announces the192.168.100.200load balancer IP address is selected from the nodes where aspeakerpod is running and at least an endpoint of the service. Only that node can receive traffic for the service. In the preceding graphic, either node 1 or 3 would advertise192.168.100.200.
-
If the external traffic policy for the service is set to
-
If node 1 becomes unavailable, the external IP address fails over to another node. On another node that has an instance of the application pod and service endpoint, the
speakerpod begins to announce the external IP address,192.168.100.200and the new node receives the client traffic. In the diagram, the only candidate is node 3.
26.1.5. MetalLB concepts for BGP mode
In BGP mode, each speaker pod advertises the load balancer IP address for a service to each BGP peer. BGP peers are commonly network routers that are configured to use the BGP protocol. When a router receives traffic for the load balancer IP address, the router picks one of the nodes with a speaker pod that advertised the IP address. The router sends the traffic to that node. After traffic enters the node, the service proxy for the CNI network provider distributes the traffic to all the pods for the service.
The directly-connected router on the same layer 2 network segment as the cluster nodes can be configured as a BGP peer. If the directly-connected router is not configured as a BGP peer, you need to configure your network so that packets for load balancer IP addresses are routed between the BGP peers and the cluster nodes that run the speaker pods.
Each time a router receives new traffic for the load balancer IP address, it creates a new connection to a node. Each router manufacturer has an implementation-specific algorithm for choosing which node to initiate the connection with. However, the algorithms commonly are designed to distribute traffic across the available nodes for the purpose of balancing the network load.
If a node becomes unavailable, the router initiates a new connection with another node that has a speaker pod that advertises the load balancer IP address.
Figure 26.1. MetalLB topology diagram for BGP mode
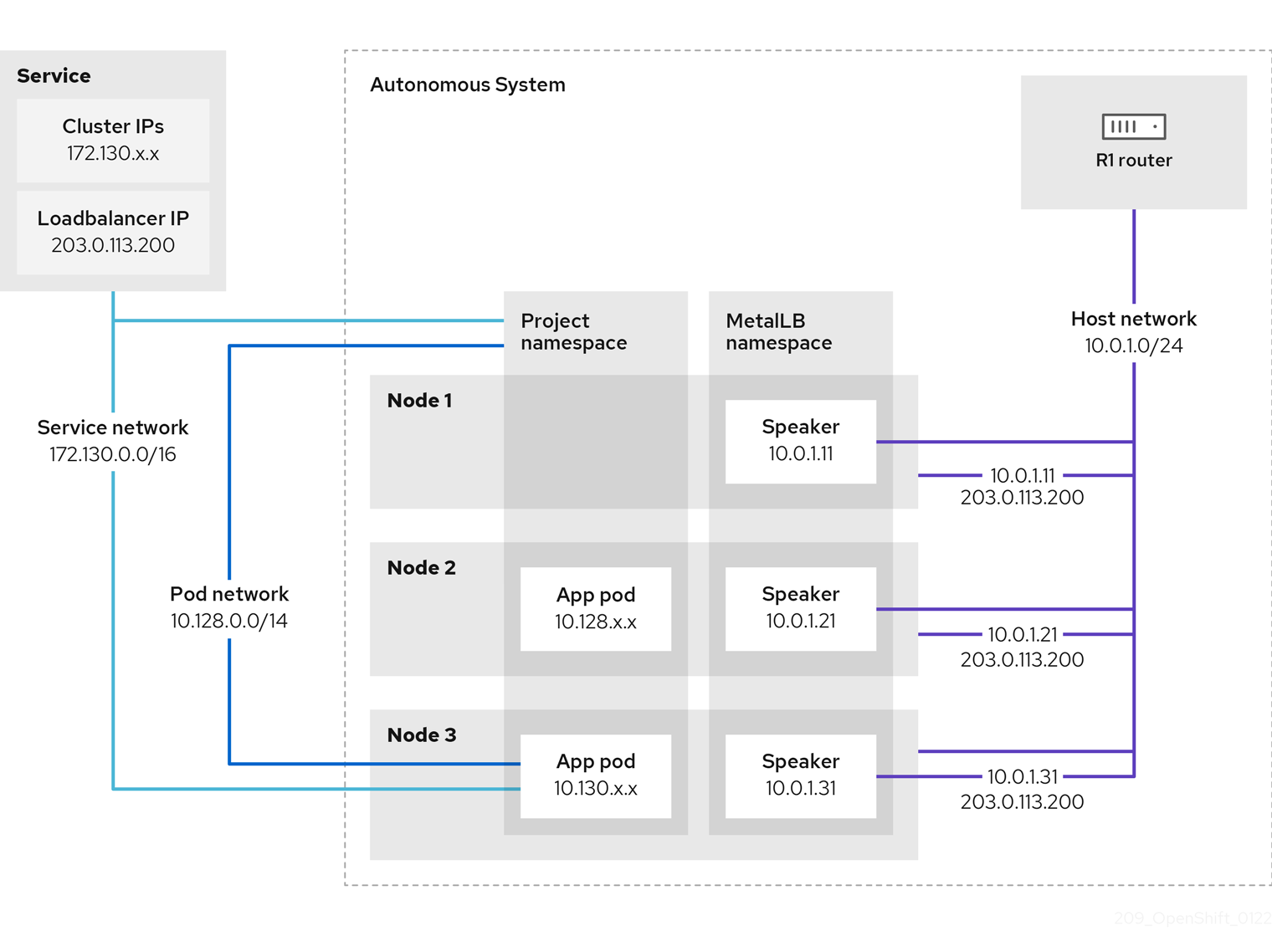
The preceding graphic shows the following concepts related to MetalLB:
-
An application is available through a service that has an IPv4 cluster IP on the
172.130.0.0/16subnet. That IP address is accessible from inside the cluster. The service also has an external IP address that MetalLB assigned to the service,203.0.113.200. - Nodes 2 and 3 have a pod for the application.
-
The
speakerdaemon set runs a pod on each node. The MetalLB Operator starts these pods. You can configure MetalLB to specify which nodes run thespeakerpods. -
Each
speakerpod is a host-networked pod. The IP address for the pod is identical to the IP address for the node on the host network. -
Each
speakerpod starts a BGP session with all BGP peers and advertises the load balancer IP addresses or aggregated routes to the BGP peers. Thespeakerpods advertise that they are part of Autonomous System 65010. The diagram shows a router, R1, as a BGP peer within the same Autonomous System. However, you can configure MetalLB to start BGP sessions with peers that belong to other Autonomous Systems. All the nodes with a
speakerpod that advertises the load balancer IP address can receive traffic for the service.-
If the external traffic policy for the service is set to
cluster, all the nodes where a speaker pod is running advertise the203.0.113.200load balancer IP address and all the nodes with aspeakerpod can receive traffic for the service. The host prefix is advertised to the router peer only if the external traffic policy is set to cluster. -
If the external traffic policy for the service is set to
local, then all the nodes where aspeakerpod is running and at least an endpoint of the service is running can advertise the203.0.113.200load balancer IP address. Only those nodes can receive traffic for the service. In the preceding graphic, nodes 2 and 3 would advertise203.0.113.200.
-
If the external traffic policy for the service is set to
-
You can configure MetalLB to control which
speakerpods start BGP sessions with specific BGP peers by specifying a node selector when you add a BGP peer custom resource. - Any routers, such as R1, that are configured to use BGP can be set as BGP peers.
- Client traffic is routed to one of the nodes on the host network. After traffic enters the node, the service proxy sends the traffic to the application pod on the same node or another node according to the external traffic policy that you set for the service.
- If a node becomes unavailable, the router detects the failure and initiates a new connection with another node. You can configure MetalLB to use a Bidirectional Forwarding Detection (BFD) profile for BGP peers. BFD provides faster link failure detection so that routers can initiate new connections earlier than without BFD.
26.1.6. MetalLB and external traffic policy
With layer 2 mode, one node in your cluster receives all the traffic for the service IP address. With BGP mode, a router on the host network opens a connection to one of the nodes in the cluster for a new client connection. How your cluster handles the traffic after it enters the node is affected by the external traffic policy.
clusterThis is the default value for
spec.externalTrafficPolicy.With the
clustertraffic policy, after the node receives the traffic, the service proxy distributes the traffic to all the pods in your service. This policy provides uniform traffic distribution across the pods, but it obscures the client IP address and it can appear to the application in your pods that the traffic originates from the node rather than the client.localWith the
localtraffic policy, after the node receives the traffic, the service proxy only sends traffic to the pods on the same node. For example, if thespeakerpod on node A announces the external service IP, then all traffic is sent to node A. After the traffic enters node A, the service proxy only sends traffic to pods for the service that are also on node A. Pods for the service that are on additional nodes do not receive any traffic from node A. Pods for the service on additional nodes act as replicas in case failover is needed.This policy does not affect the client IP address. Application pods can determine the client IP address from the incoming connections.
26.1.7. Limitations and restrictions
26.1.7.1. Infrastructure considerations for MetalLB
MetalLB is primarily useful for on-premise, bare metal installations because these installations do not include a native load-balancer capability. In addition to bare metal installations, installations of OpenShift Container Platform on some infrastructures might not include a native load-balancer capability. For example, the following infrastructures can benefit from adding the MetalLB Operator:
- Bare metal
- VMware vSphere
MetalLB Operator and MetalLB are supported with the OpenShift SDN and OVN-Kubernetes network providers.
26.1.7.2. Limitations for layer 2 mode
26.1.7.2.1. Single-node bottleneck
MetalLB routes all traffic for a service through a single node, the node can become a bottleneck and limit performance.
Layer 2 mode limits the ingress bandwidth for your service to the bandwidth of a single node. This is a fundamental limitation of using ARP and NDP to direct traffic.
26.1.7.2.2. Slow failover performance
Failover between nodes depends on cooperation from the clients. When a failover occurs, MetalLB sends gratuitous ARP packets to notify clients that the MAC address associated with the service IP has changed.
Most client operating systems handle gratuitous ARP packets correctly and update their neighbor caches promptly. When clients update their caches quickly, failover completes within a few seconds. Clients typically fail over to a new node within 10 seconds. However, some client operating systems either do not handle gratuitous ARP packets at all or have outdated implementations that delay the cache update.
Recent versions of common operating systems such as Windows, macOS, and Linux implement layer 2 failover correctly. Issues with slow failover are not expected except for older and less common client operating systems.
To minimize the impact from a planned failover on outdated clients, keep the old node running for a few minutes after flipping leadership. The old node can continue to forward traffic for outdated clients until their caches refresh.
During an unplanned failover, the service IPs are unreachable until the outdated clients refresh their cache entries.
26.1.7.3. Limitations for BGP mode
26.1.7.3.1. Node failure can break all active connections
MetalLB shares a limitation that is common to BGP-based load balancing. When a BGP session terminates, such as when a node fails or when a speaker pod restarts, the session termination might result in resetting all active connections. End users can experience a Connection reset by peer message.
The consequence of a terminated BGP session is implementation-specific for each router manufacturer. However, you can anticipate that a change in the number of speaker pods affects the number of BGP sessions and that active connections with BGP peers will break.
To avoid or reduce the likelihood of a service interruption, you can specify a node selector when you add a BGP peer. By limiting the number of nodes that start BGP sessions, a fault on a node that does not have a BGP session has no affect on connections to the service.
26.1.7.3.2. Communities are specified as 16-bit values
Communities are specified as part of an address pool custom resource and are specified as 16-bit values separated by a colon. For example, to specify that load balancer IP addresses are advertised with the well-known NO_ADVERTISE community attribute, use notation like the following:
apiVersion: metallb.io/v1beta1
kind: AddressPool
metadata:
name: doc-example-no-advertise
namespace: metallb-system
spec:
protocol: bgp
addresses:
- 192.168.1.100-192.168.1.255
bgpAdvertisements:
- communities:
- 65535:65282
The limitation that communities are only specified as 16-bit values is a difference with the community-supported implementation of MetalLB that supports a bgp-communities field and readable names for BGP communities.
26.1.7.3.3. Support for a single ASN and a single router ID only
When you add a BGP peer custom resource, you specify the spec.myASN field to identify the Autonomous System Number (ASN) that MetalLB belongs to. OpenShift Container Platform uses an implementation of BGP with MetalLB that requires MetalLB to belong to a single ASN. If you attempt to add a BGP peer and specify a different value for spec.myASN than an existing BGP peer custom resource, you receive an error.
Similarly, when you add a BGP peer custom resource, the spec.routerID field is optional. If you specify a value for this field, you must specify the same value for all other BGP peer custom resources that you add.
The limitation to support a single ASN and single router ID is a difference with the community-supported implementation of MetalLB.
26.2. Installing the MetalLB Operator
As a cluster administrator, you can add the MetallB Operator so that the Operator can manage the lifecycle for an instance of MetalLB on your cluster.
The installation procedures use the metallb-system namespace. You can install the Operator and configure custom resources in a different namespace. The Operator starts MetalLB in the same namespace that the Operator is installed in.
MetalLB and IP failover are incompatible. If you configured IP failover for your cluster, perform the steps to remove IP failover before you install the Operator.
26.2.1. Installing the MetalLB Operator from the OperatorHub using the web console
As a cluster administrator, you can install the MetalLB Operator by using the OpenShift Container Platform web console.
Procedure
- Log in to the OpenShift Container Platform web console.
Optional: Create the required namespace for the MetalLB Operator:
NoteYou can choose to create the namespace at this stage or you can create it when you start the MetalLB Operator install. From the Installed Namespace list you can create the project.
-
Navigate to Administration
Namespaces and click Create Namespace. -
Enter
metallb-systemin the Name field, and click Create.
-
Navigate to Administration
Install the MetalLB Operator:
-
In the OpenShift Container Platform web console, click Operators
OperatorHub. Type
metallbinto the Filter by keyword field to find the MetalLB Operator, and then click Install.You can also filter options by Infrastructure Features. For example, select Disconnected if you want to see Operators that work in disconnected environments, also known as restricted network environments.
-
On the Install Operator page, select a specific namespace on the cluster. Select the namespace created in the earlier section or choose to create the
metallb-systemproject, and then click Install.
-
In the OpenShift Container Platform web console, click Operators
Verification
To verify that the MetalLB Operator installed successfully:
-
Navigate to the Operators
Installed Operators page. Ensure that MetalLB Operator is listed in the metallb-system project with a Status of Succeeded.
NoteDuring installation, an Operator might display a Failed status. If the installation later succeeds with an Succeeded message, you can ignore the Failed message.
If the Operator installation does not succeed, you can troubleshoot further:
-
Navigate to the Operators
Installed Operators page and inspect the Operator Subscriptions and Install Plans tabs for any failure or errors under Status. -
Navigate to the Workloads
Pods page and check the logs for pods in the metallb-systemproject.
-
Navigate to the Operators
26.2.2. Installing from OperatorHub using the CLI
Instead of using the OpenShift Container Platform web console, you can install an Operator from OperatorHub using the CLI. Use the oc command to create or update a Subscription object.
Prerequisites
-
Install the OpenShift CLI (
oc). -
Log in as a user with
cluster-adminprivileges.
Procedure
Confirm that the MetalLB Operator is available:
$ oc get packagemanifests -n openshift-marketplace metallb-operatorExample output
NAME CATALOG AGE metallb-operator Red Hat Operators 9hCreate the
metallb-systemnamespace:$ cat << EOF | oc apply -f - apiVersion: v1 kind: Namespace metadata: name: metallb-system EOFOptional: To ensure BGP and BFD metrics appear in Prometheus, you can label the namespace as in the following command:
$ oc label ns metallb-system "openshift.io/cluster-monitoring=true"Create an Operator group custom resource in the namespace:
$ cat << EOF | oc apply -f - apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: metallb-operator namespace: metallb-system spec: targetNamespaces: - metallb-system EOFConfirm the Operator group is installed in the namespace:
$ oc get operatorgroup -n metallb-systemExample output
NAME AGE metallb-operator 14mSubscribe to the MetalLB Operator.
Run the following command to get the OpenShift Container Platform major and minor version. You use the values to set the
channelvalue in the next step.$ OC_VERSION=$(oc version -o yaml | grep openshiftVersion | \ grep -o '[0-9]*[.][0-9]*' | head -1)To create a subscription custom resource for the Operator, enter the following command:
$ cat << EOF| oc apply -f - apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: metallb-operator-sub namespace: metallb-system spec: channel: "${OC_VERSION}" name: metallb-operator source: redhat-operators sourceNamespace: openshift-marketplace EOF
Confirm the install plan is in the namespace:
$ oc get installplan -n metallb-systemExample output
NAME CSV APPROVAL APPROVED install-wzg94 metallb-operator.4.10.0-nnnnnnnnnnnn Automatic trueTo verify that the Operator is installed, enter the following command:
$ oc get clusterserviceversion -n metallb-system \ -o custom-columns=Name:.metadata.name,Phase:.status.phaseExample output
Name Phase metallb-operator.4.10.0-nnnnnnnnnnnn Succeeded
26.2.3. Starting MetalLB on your cluster
After you install the Operator, you need to configure a single instance of a MetalLB custom resource. After you configure the custom resource, the Operator starts MetalLB on your cluster.
Prerequisites
-
Install the OpenShift CLI (
oc). -
Log in as a user with
cluster-adminprivileges. - Install the MetalLB Operator.
Procedure
Create a single instance of a MetalLB custom resource:
$ cat << EOF | oc apply -f - apiVersion: metallb.io/v1beta1 kind: MetalLB metadata: name: metallb namespace: metallb-system EOF
Verification
Confirm that the deployment for the MetalLB controller and the daemon set for the MetalLB speaker are running.
Check that the deployment for the controller is running:
$ oc get deployment -n metallb-system controllerExample output
NAME READY UP-TO-DATE AVAILABLE AGE controller 1/1 1 1 11mCheck that the daemon set for the speaker is running:
$ oc get daemonset -n metallb-system speakerExample output
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE speaker 6 6 6 6 6 kubernetes.io/os=linux 18mThe example output indicates 6 speaker pods. The number of speaker pods in your cluster might differ from the example output. Make sure the output indicates one pod for each node in your cluster.
26.2.3.1. Limit speaker pods to specific nodes
By default, when you start MetalLB with the MetalLB Operator, the Operator starts an instance of a speaker pod on each node in the cluster. Only the nodes with a speaker pod can advertise a load balancer IP address. You can configure the MetalLB custom resource with a node selector to specify which nodes run the speaker pods.
The most common reason to limit the speaker pods to specific nodes is to ensure that only nodes with network interfaces on specific networks advertise load balancer IP addresses. Only the nodes with a running speaker pod are advertised as destinations of the load balancer IP address.
If you limit the speaker pods to specific nodes and specify local for the external traffic policy of a service, then you must ensure that the application pods for the service are deployed to the same nodes.
Example configuration to limit speaker pods to worker nodes
apiVersion: metallb.io/v1beta1
kind: MetalLB
metadata:
name: metallb
namespace: metallb-system
spec:
nodeSelector: <.>
node-role.kubernetes.io/worker: ""
speakerTolerations: <.>
- key: "Example"
operator: "Exists"
effect: "NoExecute"
<.> The example configuration specifies to assign the speaker pods to worker nodes, but you can specify labels that you assigned to nodes or any valid node selector. <.> In this example configuration, the pod that this toleration is attached to tolerates any taint that matches the key value and effect value using the operator.
After you apply a manifest with the spec.nodeSelector field, you can check the number of pods that the Operator deployed with the oc get daemonset -n metallb-system speaker command. Similarly, you can display the nodes that match your labels with a command like oc get nodes -l node-role.kubernetes.io/worker=.
You can optionally allow the node to control which speaker pods should, or should not, be scheduled on them by using affinity rules. You can also limit these pods by applying a list of tolerations. For more information about affinity rules, taints, and tolerations, see the additional resources.
26.2.4. Next steps
26.3. Configuring MetalLB address pools
As a cluster administrator, you can add, modify, and delete address pools. The MetalLB Operator uses the address pool custom resources to set the IP addresses that MetalLB can assign to services.
26.3.1. About the address pool custom resource
The fields for the address pool custom resource are described in the following table.
| Field | Type | Description |
|---|---|---|
|
|
|
Specifies the name for the address pool. When you add a service, you can specify this pool name in the |
|
|
| Specifies the namespace for the address pool. Specify the same namespace that the MetalLB Operator uses. |
|
|
|
Specifies the protocol for announcing the load balancer IP address to peer nodes. Specify |
|
|
|
Optional: Specifies whether MetalLB automatically assigns IP addresses from this pool. Specify |
|
|
| Specifies a list of IP addresses for MetalLB to assign to services. You can specify multiple ranges in a single pool. Specify each range in CIDR notation or as starting and ending IP addresses separated with a hyphen. |
|
|
|
Optional: By default, BGP mode advertises each allocated load-balancer IP address to the configured peers with no additional BGP attributes. The peer routers receive one |
The fields for the bgpAdvertisements object are defined in the following table:
| Field | Type | Description |
|---|---|---|
|
|
|
Optional: Specifies the number of bits to include in a 32-bit CIDR mask. To aggregate the routes that the speaker advertises to BGP peers, the mask is applied to the routes for several service IP addresses and the speaker advertises the aggregated route. For example, with an aggregation length of |
|
|
|
Optional: Specifies the number of bits to include in a 128-bit CIDR mask. For example, with an aggregation length of |
|
|
| Optional: Specifies one or more BGP communities. Each community is specified as two 16-bit values separated by the colon character. Well-known communities must be specified as 16-bit values:
|
|
|
| Optional: Specifies the local preference for this advertisement. This BGP attribute applies to BGP sessions within the Autonomous System. |
26.3.2. Configuring an address pool
As a cluster administrator, you can add address pools to your cluster to control the IP addresses that MetalLB can assign to load-balancer services.
Prerequisites
-
Install the OpenShift CLI (
oc). -
Log in as a user with
cluster-adminprivileges.
Procedure
Create a file, such as
addresspool.yaml, with content like the following example:apiVersion: metallb.io/v1alpha1 kind: AddressPool metadata: namespace: metallb-system name: doc-example spec: protocol: layer2 addresses: - 203.0.113.1-203.0.113.10 - 203.0.113.65-203.0.113.75Apply the configuration for the address pool:
$ oc apply -f addresspool.yaml
Verification
View the address pool:
$ oc describe -n metallb-system addresspool doc-exampleExample output
Name: doc-example Namespace: metallb-system Labels: <none> Annotations: <none> API Version: metallb.io/v1alpha1 Kind: AddressPool Metadata: ... Spec: Addresses: 203.0.113.1-203.0.113.10 203.0.113.65-203.0.113.75 Auto Assign: true Protocol: layer2 Events: <none>
Confirm that the address pool name, such as doc-example, and the IP address ranges appear in the output.
26.3.3. Example address pool configurations
26.3.3.1. Example: IPv4 and CIDR ranges
You can specify a range of IP addresses in CIDR notation. You can combine CIDR notation with the notation that uses a hyphen to separate lower and upper bounds.
apiVersion: metallb.io/v1beta1
kind: AddressPool
metadata:
name: doc-example-cidr
namespace: metallb-system
spec:
protocol: layer2
addresses:
- 192.168.100.0/24
- 192.168.200.0/24
- 192.168.255.1-192.168.255.526.3.3.2. Example: Reserve IP addresses
You can set the autoAssign field to false to prevent MetalLB from automatically assigning the IP addresses from the pool. When you add a service, you can request a specific IP address from the pool or you can specify the pool name in an annotation to request any IP address from the pool.
apiVersion: metallb.io/v1beta1
kind: AddressPool
metadata:
name: doc-example-reserved
namespace: metallb-system
spec:
protocol: layer2
addresses:
- 10.0.100.0/28
autoAssign: false26.3.3.3. Example: IPv4 and IPv6 addresses
You can add address pools that use IPv4 and IPv6. You can specify multiple ranges in the addresses list, just like several IPv4 examples.
Whether the service is assigned a single IPv4 address, a single IPv6 address, or both is determined by how you add the service. The spec.ipFamilies and spec.ipFamilyPolicy fields control how IP addresses are assigned to the service.
apiVersion: metallb.io/v1beta1
kind: AddressPool
metadata:
name: doc-example-combined
namespace: metallb-system
spec:
protocol: layer2
addresses:
- 10.0.100.0/28
- 2002:2:2::1-2002:2:2::10026.3.3.4. Example: Simple address pool with BGP mode
For BGP mode, you must set the protocol field set to bgp. Other address pool custom resource fields, such as autoAssign, also apply to BGP mode.
In the following example, the peer BGP routers receive one 203.0.113.200/32 route and one fc00:f853:ccd:e799::1/128 route for each load-balancer IP address that MetalLB assigns to a service. Because the localPref and communities fields are not specified, the routes are advertised with localPref set to zero and no BGP communities.
apiVersion: metallb.io/v1beta1
kind: AddressPool
metadata:
name: doc-example-bgp
namespace: metallb-system
spec:
protocol: bgp
addresses:
- 203.0.113.200/30
- fc00:f853:ccd:e799::/12426.3.3.5. Example: BGP mode with custom advertisement
You can specify sophisticated custom advertisements.
apiVersion: metallb.io/v1beta1
kind: AddressPool
metadata:
name: doc-example-bgp-adv
namespace: metallb-system
spec:
protocol: bgp
addresses:
- 203.0.113.200/30
- fc00:f853:ccd:e799::/124
bgpAdvertisements:
- communities:
- 65535:65282
aggregationLength: 32
localPref: 100
- communities:
- 8000:800
aggregationLength: 30
aggregationLengthV6: 124
In the preceding example, MetalLB assigns IP addresses to load-balancer services in the ranges between 203.0.113.200 and 203.0.113.203 and between fc00:f853:ccd:e799::0 and fc00:f853:ccd:e799::f.
To explain the two BGP advertisements, consider an instance when MetalLB assigns the IP address of 203.0.113.200 to a service. With that IP address as an example, the speaker advertises two routes to BGP peers:
-
203.0.113.200/32, withlocalPrefset to100and the community set to the numeric value of the well-knownNO_ADVERTISEcommunity. This specification indicates to the peer routers that they can use this route but they should not propagate information about this route to BGP peers. -
203.0.113.200/30, aggregates the load-balancer IP addresses assigned by MetalLB into a single route. MetalLB advertises the aggregated route to BGP peers with the community attribute set to8000:800. BGP peers propagate the203.0.113.200/30route to other BGP peers. When traffic is routed to a node with a speaker, the203.0.113.200/32route is used to forward the traffic into the cluster and to a pod that is associated with the service.
As you add more services and MetalLB assigns more load-balancer IP addresses from the pool, peer routers receive one local route, 203.0.113.20x/32, for each service, as well as the 203.0.113.200/30 aggregate route. Each service that you add generates the /30 route, but MetalLB deduplicates the routes to one BGP advertisement before communicating with peer routers.
26.3.4. Next steps
- For BGP mode, see Configuring MetalLB BGP peers.
- Configuring services to use MetalLB.
26.4. Configuring MetalLB BGP peers
As a cluster administrator, you can add, modify, and delete Border Gateway Protocol (BGP) peers. The MetalLB Operator uses the BGP peer custom resources to identify which peers that MetalLB speaker pods contact to start BGP sessions. The peers receive the route advertisements for the load-balancer IP addresses that MetalLB assigns to services.
26.4.1. About the BGP peer custom resource
The fields for the BGP peer custom resource are described in the following table.
| Field | Type | Description |
|---|---|---|
|
|
| Specifies the name for the BGP peer custom resource. |
|
|
| Specifies the namespace for the BGP peer custom resource. |
|
|
|
Specifies the Autonomous System number for the local end of the BGP session. Specify the same value in all BGP peer custom resources that you add. The range is |
|
|
|
Specifies the Autonomous System number for the remote end of the BGP session. The range is |
|
|
| Specifies the IP address of the peer to contact for establishing the BGP session. |
|
|
| Optional: Specifies the IP address to use when establishing the BGP session. The value must be an IPv4 address. |
|
|
|
Optional: Specifies the network port of the peer to contact for establishing the BGP session. The range is |
|
|
|
Optional: Specifies the duration for the hold time to propose to the BGP peer. The minimum value is 3 seconds ( |
|
|
|
Optional: Specifies the maximum interval between sending keep-alive messages to the BGP peer. If you specify this field, you must also specify a value for the |
|
|
| Optional: Specifies the router ID to advertise to the BGP peer. If you specify this field, you must specify the same value in every BGP peer custom resource that you add. |
|
|
| Optional: Specifies the MD5 password to send to the peer for routers that enforce TCP MD5 authenticated BGP sessions. |
|
|
| Optional: Specifies the name of a BFD profile. |
|
|
| Optional: Specifies a selector, using match expressions and match labels, to control which nodes can connect to the BGP peer. |
|
|
|
Optional: Specifies that the BGP peer is multiple network hops away. If the BGP peer is not directly connected to the same network, the speaker cannot establish a BGP session unless this field is set to |
26.4.2. Configuring a BGP peer
As a cluster administrator, you can add a BGP peer custom resource to exchange routing information with network routers and advertise the IP addresses for services.
Prerequisites
-
Install the OpenShift CLI (
oc). -
Log in as a user with
cluster-adminprivileges. -
Configure a MetalLB address pool that specifies
bgpfor thespec.protocolfield.
Procedure
Create a file, such as
bgppeer.yaml, with content like the following example:apiVersion: metallb.io/v1beta1 kind: BGPPeer metadata: namespace: metallb-system name: doc-example-peer spec: peerAddress: 10.0.0.1 peerASN: 64501 myASN: 64500 routerID: 10.10.10.10Apply the configuration for the BGP peer:
$ oc apply -f bgppeer.yaml
Additional resources
- Example: Simple address pool with BGP mode
-
Configure a MetalLB address pool that specifies
bgpfor thespec.protocolfield.
26.4.3. Example BGP peer configurations
26.4.3.1. Example: Limit which nodes connect to a BGP peer
You can specify the node selectors field to control which nodes can connect to a BGP peer.
apiVersion: metallb.io/v1beta1
kind: BGPPeer
metadata:
name: doc-example-nodesel
namespace: metallb-system
spec:
peerAddress: 10.0.20.1
peerASN: 64501
myASN: 64500
nodeSelectors:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values: [compute-1.example.com, compute-2.example.com]26.4.3.2. Example: Specify a BFD profile for a BGP peer
You can specify a BFD profile to associate with BGP peers. BFD compliments BGP by providing more rapid detection of communication failures between peers than BGP alone.
apiVersion: metallb.io/v1beta1
kind: BGPPeer
metadata:
name: doc-example-peer-bfd
namespace: metallb-system
spec:
peerAddress: 10.0.20.1
peerASN: 64501
myASN: 64500
holdTime: "10s"
bfdProfile: doc-example-bfd-profile-full
Deleting the bidirectional forwarding detection (BFD) profile and removing the bfdProfile added to the border gateway protocol (BGP) peer resource does not disable the BFD. Instead, the BGP peer starts using the default BFD profile. To disable BFD from a BGP peer resource, delete the BGP peer configuration and recreate it without a BFD profile. For more information, see BZ#2050824.
26.4.3.3. Example: Specify BGP peers for dual-stack networking
To support dual-stack networking, add one BGP peer custom resource for IPv4 and one BGP peer custom resource for IPv6.
apiVersion: metallb.io/v1beta1
kind: BGPPeer
metadata:
name: doc-example-dual-stack-ipv4
namespace: metallb-system
spec:
peerAddress: 10.0.20.1
peerASN: 64500
myASN: 64500
---
apiVersion: metallb.io/v1beta1
kind: BGPPeer
metadata:
name: doc-example-dual-stack-ipv6
namespace: metallb-system
spec:
peerAddress: 2620:52:0:88::104
peerASN: 64500
myASN: 6450026.5. Configuring MetalLB BFD profiles
As a cluster administrator, you can add, modify, and delete Bidirectional Forwarding Detection (BFD) profiles. The MetalLB Operator uses the BFD profile custom resources to identify which BGP sessions use BFD to provide faster path failure detection than BGP alone provides.
26.5.1. About the BFD profile custom resource
The fields for the BFD profile custom resource are described in the following table.
| Field | Type | Description |
|---|---|---|
|
|
| Specifies the name for the BFD profile custom resource. |
|
|
| Specifies the namespace for the BFD profile custom resource. |
|
|
| Specifies the detection multiplier to determine packet loss. The remote transmission interval is multiplied by this value to determine the connection loss detection timer.
For example, when the local system has the detect multiplier set to
The range is |
|
|
|
Specifies the echo transmission mode. If you are not using distributed BFD, echo transmission mode works only when the peer is also FRR. The default value is
When echo transmission mode is enabled, consider increasing the transmission interval of control packets to reduce bandwidth usage. For example, consider increasing the transmit interval to |
|
|
|
Specifies the minimum transmission interval, less jitter, that this system uses to send and receive echo packets. The range is |
|
|
| Specifies the minimum expected TTL for an incoming control packet. This field applies to multi-hop sessions only. The purpose of setting a minimum TTL is to make the packet validation requirements more stringent and avoid receiving control packets from other sessions.
The default value is |
|
|
| Specifies whether a session is marked as active or passive. A passive session does not attempt to start the connection. Instead, a passive session waits for control packets from a peer before it begins to reply. Marking a session as passive is useful when you have a router that acts as the central node of a star network and you want to avoid sending control packets that you do not need the system to send.
The default value is |
|
|
|
Specifies the minimum interval that this system is capable of receiving control packets. The range is |
|
|
|
Specifies the minimum transmission interval, less jitter, that this system uses to send control packets. The range is |
26.5.2. Configuring a BFD profile
As a cluster administrator, you can add a BFD profile and configure a BGP peer to use the profile. BFD provides faster path failure detection than BGP alone.
Prerequisites
-
Install the OpenShift CLI (
oc). -
Log in as a user with
cluster-adminprivileges.
Procedure
Create a file, such as
bfdprofile.yaml, with content like the following example:apiVersion: metallb.io/v1beta1 kind: BFDProfile metadata: name: doc-example-bfd-profile-full namespace: metallb-system spec: receiveInterval: 300 transmitInterval: 300 detectMultiplier: 3 echoMode: false passiveMode: true minimumTtl: 254Apply the configuration for the BFD profile:
$ oc apply -f bfdprofile.yaml
26.5.3. Next steps
- Configure a BGP peer to use the BFD profile.
26.6. Configuring services to use MetalLB
As a cluster administrator, when you add a service of type LoadBalancer, you can control how MetalLB assigns an IP address.
26.6.1. Request a specific IP address
Like some other load-balancer implementations, MetalLB accepts the spec.loadBalancerIP field in the service specification.
If the requested IP address is within a range from any address pool, MetalLB assigns the requested IP address. If the requested IP address is not within any range, MetalLB reports a warning.
Example service YAML for a specific IP address
apiVersion: v1
kind: Service
metadata:
name: <service_name>
annotations:
metallb.universe.tf/address-pool: <address_pool_name>
spec:
selector:
<label_key>: <label_value>
ports:
- port: 8080
targetPort: 8080
protocol: TCP
type: LoadBalancer
loadBalancerIP: <ip_address>
If MetalLB cannot assign the requested IP address, the EXTERNAL-IP for the service reports <pending> and running oc describe service <service_name> includes an event like the following example.
Example event when MetalLB cannot assign a requested IP address
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning AllocationFailed 3m16s metallb-controller Failed to allocate IP for "default/invalid-request": "4.3.2.1" is not allowed in config26.6.2. Request an IP address from a specific pool
To assign an IP address from a specific range, but you are not concerned with the specific IP address, then you can use the metallb.universe.tf/address-pool annotation to request an IP address from the specified address pool.
Example service YAML for an IP address from a specific pool
apiVersion: v1
kind: Service
metadata:
name: <service_name>
annotations:
metallb.universe.tf/address-pool: <address_pool_name>
spec:
selector:
<label_key>: <label_value>
ports:
- port: 8080
targetPort: 8080
protocol: TCP
type: LoadBalancer
If the address pool that you specify for <address_pool_name> does not exist, MetalLB attempts to assign an IP address from any pool that permits automatic assignment.
26.6.3. Accept any IP address
By default, address pools are configured to permit automatic assignment. MetalLB assigns an IP address from these address pools.
To accept any IP address from any pool that is configured for automatic assignment, no special annotation or configuration is required.
Example service YAML for accepting any IP address
apiVersion: v1
kind: Service
metadata:
name: <service_name>
spec:
selector:
<label_key>: <label_value>
ports:
- port: 8080
targetPort: 8080
protocol: TCP
type: LoadBalancer26.6.5. Configuring a service with MetalLB
You can configure a load-balancing service to use an external IP address from an address pool.
Prerequisites
-
Install the OpenShift CLI (
oc). - Install the MetalLB Operator and start MetalLB.
- Configure at least one address pool.
- Configure your network to route traffic from the clients to the host network for the cluster.
Procedure
Create a
<service_name>.yamlfile. In the file, ensure that thespec.typefield is set toLoadBalancer.Refer to the examples for information about how to request the external IP address that MetalLB assigns to the service.
Create the service:
$ oc apply -f <service_name>.yamlExample output
service/<service_name> created
Verification
Describe the service:
$ oc describe service <service_name>Example output
Name: <service_name> Namespace: default Labels: <none> Annotations: metallb.universe.tf/address-pool: doc-example <.> Selector: app=service_name Type: LoadBalancer <.> IP Family Policy: SingleStack IP Families: IPv4 IP: 10.105.237.254 IPs: 10.105.237.254 LoadBalancer Ingress: 192.168.100.5 <.> Port: <unset> 80/TCP TargetPort: 8080/TCP NodePort: <unset> 30550/TCP Endpoints: 10.244.0.50:8080 Session Affinity: None External Traffic Policy: Cluster Events: <.> Type Reason Age From Message ---- ------ ---- ---- ------- Normal nodeAssigned 32m (x2 over 32m) metallb-speaker announcing from node "<node_name>"<.> The annotation is present if you request an IP address from a specific pool. <.> The service type must indicate
LoadBalancer. <.> The load-balancer ingress field indicates the external IP address if the service is assigned correctly. <.> The events field indicates the node name that is assigned to announce the external IP address. If you experience an error, the events field indicates the reason for the error.
26.7. MetalLB logging, troubleshooting, and support
If you need to troubleshoot MetalLB configuration, see the following sections for commonly used commands.
26.7.1. Setting the MetalLB logging levels
MetalLB uses FRRouting (FRR) in a container with the default setting of info generates a lot of logging. You can control the verbosity of the logs generated by setting the logLevel as illustrated in this example.
Gain a deeper insight into MetalLB by setting the logLevel to debug as follows:
Prerequisites
-
You have access to the cluster as a user with the
cluster-adminrole. -
You have installed the OpenShift CLI (
oc).
Procedure
Create a file, such as
setdebugloglevel.yaml, with content like the following example:apiVersion: metallb.io/v1beta1 kind: MetalLB metadata: name: metallb namespace: metallb-system spec: logLevel: debug nodeSelector: node-role.kubernetes.io/worker: ""Apply the configuration:
$ oc replace -f setdebugloglevel.yamlNoteUse
oc replaceas the understanding is themetallbCR is already created and here you are changing the log level.Display the names of the
speakerpods:$ oc get -n metallb-system pods -l component=speakerExample output
NAME READY STATUS RESTARTS AGE speaker-2m9pm 4/4 Running 0 9m19s speaker-7m4qw 3/4 Running 0 19s speaker-szlmx 4/4 Running 0 9m19sNoteSpeaker and controller pods are recreated to ensure the updated logging level is applied. The logging level is modified for all the components of MetalLB.
View the
speakerlogs:$ oc logs -n metallb-system speaker-7m4qw -c speakerExample output
{"branch":"main","caller":"main.go:92","commit":"3d052535","goversion":"gc / go1.17.1 / amd64","level":"info","msg":"MetalLB speaker starting (commit 3d052535, branch main)","ts":"2022-05-17T09:55:05Z","version":""} {"caller":"announcer.go:110","event":"createARPResponder","interface":"ens4","level":"info","msg":"created ARP responder for interface","ts":"2022-05-17T09:55:05Z"} {"caller":"announcer.go:119","event":"createNDPResponder","interface":"ens4","level":"info","msg":"created NDP responder for interface","ts":"2022-05-17T09:55:05Z"} {"caller":"announcer.go:110","event":"createARPResponder","interface":"tun0","level":"info","msg":"created ARP responder for interface","ts":"2022-05-17T09:55:05Z"} {"caller":"announcer.go:119","event":"createNDPResponder","interface":"tun0","level":"info","msg":"created NDP responder for interface","ts":"2022-05-17T09:55:05Z"} I0517 09:55:06.515686 95 request.go:665] Waited for 1.026500832s due to client-side throttling, not priority and fairness, request: GET:https://172.30.0.1:443/apis/operators.coreos.com/v1alpha1?timeout=32s {"Starting Manager":"(MISSING)","caller":"k8s.go:389","level":"info","ts":"2022-05-17T09:55:08Z"} {"caller":"speakerlist.go:310","level":"info","msg":"node event - forcing sync","node addr":"10.0.128.4","node event":"NodeJoin","node name":"ci-ln-qb8t3mb-72292-7s7rh-worker-a-vvznj","ts":"2022-05-17T09:55:08Z"} {"caller":"service_controller.go:113","controller":"ServiceReconciler","enqueueing":"openshift-kube-controller-manager-operator/metrics","epslice":"{\"metadata\":{\"name\":\"metrics-xtsxr\",\"generateName\":\"metrics-\",\"namespace\":\"openshift-kube-controller-manager-operator\",\"uid\":\"ac6766d7-8504-492c-9d1e-4ae8897990ad\",\"resourceVersion\":\"9041\",\"generation\":4,\"creationTimestamp\":\"2022-05-17T07:16:53Z\",\"labels\":{\"app\":\"kube-controller-manager-operator\",\"endpointslice.kubernetes.io/managed-by\":\"endpointslice-controller.k8s.io\",\"kubernetes.io/service-name\":\"metrics\"},\"annotations\":{\"endpoints.kubernetes.io/last-change-trigger-time\":\"2022-05-17T07:21:34Z\"},\"ownerReferences\":[{\"apiVersion\":\"v1\",\"kind\":\"Service\",\"name\":\"metrics\",\"uid\":\"0518eed3-6152-42be-b566-0bd00a60faf8\",\"controller\":true,\"blockOwnerDeletion\":true}],\"managedFields\":[{\"manager\":\"kube-controller-manager\",\"operation\":\"Update\",\"apiVersion\":\"discovery.k8s.io/v1\",\"time\":\"2022-05-17T07:20:02Z\",\"fieldsType\":\"FieldsV1\",\"fieldsV1\":{\"f:addressType\":{},\"f:endpoints\":{},\"f:metadata\":{\"f:annotations\":{\".\":{},\"f:endpoints.kubernetes.io/last-change-trigger-time\":{}},\"f:generateName\":{},\"f:labels\":{\".\":{},\"f:app\":{},\"f:endpointslice.kubernetes.io/managed-by\":{},\"f:kubernetes.io/service-name\":{}},\"f:ownerReferences\":{\".\":{},\"k:{\\\"uid\\\":\\\"0518eed3-6152-42be-b566-0bd00a60faf8\\\"}\":{}}},\"f:ports\":{}}}]},\"addressType\":\"IPv4\",\"endpoints\":[{\"addresses\":[\"10.129.0.7\"],\"conditions\":{\"ready\":true,\"serving\":true,\"terminating\":false},\"targetRef\":{\"kind\":\"Pod\",\"namespace\":\"openshift-kube-controller-manager-operator\",\"name\":\"kube-controller-manager-operator-6b98b89ddd-8d4nf\",\"uid\":\"dd5139b8-e41c-4946-a31b-1a629314e844\",\"resourceVersion\":\"9038\"},\"nodeName\":\"ci-ln-qb8t3mb-72292-7s7rh-master-0\",\"zone\":\"us-central1-a\"}],\"ports\":[{\"name\":\"https\",\"protocol\":\"TCP\",\"port\":8443}]}","level":"debug","ts":"2022-05-17T09:55:08Z"}View the FRR logs:
$ oc logs -n metallb-system speaker-7m4qw -c frrExample output
Started watchfrr 2022/05/17 09:55:05 ZEBRA: client 16 says hello and bids fair to announce only bgp routes vrf=0 2022/05/17 09:55:05 ZEBRA: client 31 says hello and bids fair to announce only vnc routes vrf=0 2022/05/17 09:55:05 ZEBRA: client 38 says hello and bids fair to announce only static routes vrf=0 2022/05/17 09:55:05 ZEBRA: client 43 says hello and bids fair to announce only bfd routes vrf=0 2022/05/17 09:57:25.089 BGP: Creating Default VRF, AS 64500 2022/05/17 09:57:25.090 BGP: dup addr detect enable max_moves 5 time 180 freeze disable freeze_time 0 2022/05/17 09:57:25.090 BGP: bgp_get: Registering BGP instance (null) to zebra 2022/05/17 09:57:25.090 BGP: Registering VRF 0 2022/05/17 09:57:25.091 BGP: Rx Router Id update VRF 0 Id 10.131.0.1/32 2022/05/17 09:57:25.091 BGP: RID change : vrf VRF default(0), RTR ID 10.131.0.1 2022/05/17 09:57:25.091 BGP: Rx Intf add VRF 0 IF br0 2022/05/17 09:57:25.091 BGP: Rx Intf add VRF 0 IF ens4 2022/05/17 09:57:25.091 BGP: Rx Intf address add VRF 0 IF ens4 addr 10.0.128.4/32 2022/05/17 09:57:25.091 BGP: Rx Intf address add VRF 0 IF ens4 addr fe80::c9d:84da:4d86:5618/64 2022/05/17 09:57:25.091 BGP: Rx Intf add VRF 0 IF lo 2022/05/17 09:57:25.091 BGP: Rx Intf add VRF 0 IF ovs-system 2022/05/17 09:57:25.091 BGP: Rx Intf add VRF 0 IF tun0 2022/05/17 09:57:25.091 BGP: Rx Intf address add VRF 0 IF tun0 addr 10.131.0.1/23 2022/05/17 09:57:25.091 BGP: Rx Intf address add VRF 0 IF tun0 addr fe80::40f1:d1ff:feb6:5322/64 2022/05/17 09:57:25.091 BGP: Rx Intf add VRF 0 IF veth2da49fed 2022/05/17 09:57:25.091 BGP: Rx Intf address add VRF 0 IF veth2da49fed addr fe80::24bd:d1ff:fec1:d88/64 2022/05/17 09:57:25.091 BGP: Rx Intf add VRF 0 IF veth2fa08c8c 2022/05/17 09:57:25.091 BGP: Rx Intf address add VRF 0 IF veth2fa08c8c addr fe80::6870:ff:fe96:efc8/64 2022/05/17 09:57:25.091 BGP: Rx Intf add VRF 0 IF veth41e356b7 2022/05/17 09:57:25.091 BGP: Rx Intf address add VRF 0 IF veth41e356b7 addr fe80::48ff:37ff:fede:eb4b/64 2022/05/17 09:57:25.092 BGP: Rx Intf add VRF 0 IF veth1295c6e2 2022/05/17 09:57:25.092 BGP: Rx Intf address add VRF 0 IF veth1295c6e2 addr fe80::b827:a2ff:feed:637/64 2022/05/17 09:57:25.092 BGP: Rx Intf add VRF 0 IF veth9733c6dc 2022/05/17 09:57:25.092 BGP: Rx Intf address add VRF 0 IF veth9733c6dc addr fe80::3cf4:15ff:fe11:e541/64 2022/05/17 09:57:25.092 BGP: Rx Intf add VRF 0 IF veth336680ea 2022/05/17 09:57:25.092 BGP: Rx Intf address add VRF 0 IF veth336680ea addr fe80::94b1:8bff:fe7e:488c/64 2022/05/17 09:57:25.092 BGP: Rx Intf add VRF 0 IF vetha0a907b7 2022/05/17 09:57:25.092 BGP: Rx Intf address add VRF 0 IF vetha0a907b7 addr fe80::3855:a6ff:fe73:46c3/64 2022/05/17 09:57:25.092 BGP: Rx Intf add VRF 0 IF vethf35a4398 2022/05/17 09:57:25.092 BGP: Rx Intf address add VRF 0 IF vethf35a4398 addr fe80::40ef:2fff:fe57:4c4d/64 2022/05/17 09:57:25.092 BGP: Rx Intf add VRF 0 IF vethf831b7f4 2022/05/17 09:57:25.092 BGP: Rx Intf address add VRF 0 IF vethf831b7f4 addr fe80::f0d9:89ff:fe7c:1d32/64 2022/05/17 09:57:25.092 BGP: Rx Intf add VRF 0 IF vxlan_sys_4789 2022/05/17 09:57:25.092 BGP: Rx Intf address add VRF 0 IF vxlan_sys_4789 addr fe80::80c1:82ff:fe4b:f078/64 2022/05/17 09:57:26.094 BGP: 10.0.0.1 [FSM] Timer (start timer expire). 2022/05/17 09:57:26.094 BGP: 10.0.0.1 [FSM] BGP_Start (Idle->Connect), fd -1 2022/05/17 09:57:26.094 BGP: Allocated bnc 10.0.0.1/32(0)(VRF default) peer 0x7f807f7631a0 2022/05/17 09:57:26.094 BGP: sendmsg_zebra_rnh: sending cmd ZEBRA_NEXTHOP_REGISTER for 10.0.0.1/32 (vrf VRF default) 2022/05/17 09:57:26.094 BGP: 10.0.0.1 [FSM] Waiting for NHT 2022/05/17 09:57:26.094 BGP: bgp_fsm_change_status : vrf default(0), Status: Connect established_peers 0 2022/05/17 09:57:26.094 BGP: 10.0.0.1 went from Idle to Connect 2022/05/17 09:57:26.094 BGP: 10.0.0.1 [FSM] TCP_connection_open_failed (Connect->Active), fd -1 2022/05/17 09:57:26.094 BGP: bgp_fsm_change_status : vrf default(0), Status: Active established_peers 0 2022/05/17 09:57:26.094 BGP: 10.0.0.1 went from Connect to Active 2022/05/17 09:57:26.094 ZEBRA: rnh_register msg from client bgp: hdr->length=8, type=nexthop vrf=0 2022/05/17 09:57:26.094 ZEBRA: 0: Add RNH 10.0.0.1/32 type Nexthop 2022/05/17 09:57:26.094 ZEBRA: 0:10.0.0.1/32: Evaluate RNH, type Nexthop (force) 2022/05/17 09:57:26.094 ZEBRA: 0:10.0.0.1/32: NH has become unresolved 2022/05/17 09:57:26.094 ZEBRA: 0: Client bgp registers for RNH 10.0.0.1/32 type Nexthop 2022/05/17 09:57:26.094 BGP: VRF default(0): Rcvd NH update 10.0.0.1/32(0) - metric 0/0 #nhops 0/0 flags 0x6 2022/05/17 09:57:26.094 BGP: NH update for 10.0.0.1/32(0)(VRF default) - flags 0x6 chgflags 0x0 - evaluate paths 2022/05/17 09:57:26.094 BGP: evaluate_paths: Updating peer (10.0.0.1(VRF default)) status with NHT 2022/05/17 09:57:30.081 ZEBRA: Event driven route-map update triggered 2022/05/17 09:57:30.081 ZEBRA: Event handler for route-map: 10.0.0.1-out 2022/05/17 09:57:30.081 ZEBRA: Event handler for route-map: 10.0.0.1-in 2022/05/17 09:57:31.104 ZEBRA: netlink_parse_info: netlink-listen (NS 0) type RTM_NEWNEIGH(28), len=76, seq=0, pid=0 2022/05/17 09:57:31.104 ZEBRA: Neighbor Entry received is not on a VLAN or a BRIDGE, ignoring 2022/05/17 09:57:31.105 ZEBRA: netlink_parse_info: netlink-listen (NS 0) type RTM_NEWNEIGH(28), len=76, seq=0, pid=0 2022/05/17 09:57:31.105 ZEBRA: Neighbor Entry received is not on a VLAN or a BRIDGE, ignoring
26.7.1.1. FRRouting (FRR) log levels
The following table describes the FRR logging levels.
| Log level | Description |
|---|---|
|
| Supplies all logging information for all logging levels. |
|
|
Information that is diagnostically helpful to people. Set to |
|
| Provides information that always should be logged but under normal circumstances does not require user intervention. This is the default logging level. |
|
|
Anything that can potentially cause inconsistent |
|
|
Any error that is fatal to the functioning of |
|
| Turn off all logging. |
26.7.2. Troubleshooting BGP issues
The BGP implementation that Red Hat supports uses FRRouting (FRR) in a container in the speaker pods. As a cluster administrator, if you need to troubleshoot BGP configuration issues, you need to run commands in the FRR container.
Prerequisites
-
You have access to the cluster as a user with the
cluster-adminrole. -
You have installed the OpenShift CLI (
oc).
Procedure
Display the names of the
speakerpods:$ oc get -n metallb-system pods -l app.kubernetes.io/component=speakerExample output
NAME READY STATUS RESTARTS AGE speaker-66bth 4/4 Running 0 56m speaker-gvfnf 4/4 Running 0 56m ...Display the running configuration for FRR:
$ oc exec -n metallb-system speaker-66bth -c frr -- vtysh -c "show running-config"Example output
Building configuration... Current configuration: ! frr version 7.5.1_git frr defaults traditional hostname some-hostname log file /etc/frr/frr.log informational log timestamp precision 3 service integrated-vtysh-config ! router bgp 645001 bgp router-id 10.0.1.2 no bgp ebgp-requires-policy no bgp default ipv4-unicast no bgp network import-check neighbor 10.0.2.3 remote-as 645002 neighbor 10.0.2.3 bfd profile doc-example-bfd-profile-full3 neighbor 10.0.2.3 timers 5 15 neighbor 10.0.2.4 remote-as 645004 neighbor 10.0.2.4 bfd profile doc-example-bfd-profile-full5 neighbor 10.0.2.4 timers 5 15 ! address-family ipv4 unicast network 203.0.113.200/306 neighbor 10.0.2.3 activate neighbor 10.0.2.3 route-map 10.0.2.3-in in neighbor 10.0.2.4 activate neighbor 10.0.2.4 route-map 10.0.2.4-in in exit-address-family ! address-family ipv6 unicast network fc00:f853:ccd:e799::/1247 neighbor 10.0.2.3 activate neighbor 10.0.2.3 route-map 10.0.2.3-in in neighbor 10.0.2.4 activate neighbor 10.0.2.4 route-map 10.0.2.4-in in exit-address-family ! route-map 10.0.2.3-in deny 20 ! route-map 10.0.2.4-in deny 20 ! ip nht resolve-via-default ! ipv6 nht resolve-via-default ! line vty ! bfd profile doc-example-bfd-profile-full8 transmit-interval 35 receive-interval 35 passive-mode echo-mode echo-interval 35 minimum-ttl 10 ! ! end<.> The
router bgpsection indicates the ASN for MetalLB. <.> Confirm that aneighbor <ip-address> remote-as <peer-ASN>line exists for each BGP peer custom resource that you added. <.> If you configured BFD, confirm that the BFD profile is associated with the correct BGP peer and that the BFD profile appears in the command output. <.> Confirm that thenetwork <ip-address-range>lines match the IP address ranges that you specified in address pool custom resources that you added.Display the BGP summary:
$ oc exec -n metallb-system speaker-66bth -c frr -- vtysh -c "show bgp summary"Example output
IPv4 Unicast Summary: BGP router identifier 10.0.1.2, local AS number 64500 vrf-id 0 BGP table version 1 RIB entries 1, using 192 bytes of memory Peers 2, using 29 KiB of memory Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd PfxSnt 10.0.2.3 4 64500 387 389 0 0 0 00:32:02 0 11 10.0.2.4 4 64500 0 0 0 0 0 never Active 02 Total number of neighbors 2 IPv6 Unicast Summary: BGP router identifier 10.0.1.2, local AS number 64500 vrf-id 0 BGP table version 1 RIB entries 1, using 192 bytes of memory Peers 2, using 29 KiB of memory Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd PfxSnt 10.0.2.3 4 64500 387 389 0 0 0 00:32:02 NoNeg3 10.0.2.4 4 64500 0 0 0 0 0 never Active 04 Total number of neighbors 2Display the BGP peers that received an address pool:
$ oc exec -n metallb-system speaker-66bth -c frr -- vtysh -c "show bgp ipv4 unicast 203.0.113.200/30"Replace
ipv4withipv6to display the BGP peers that received an IPv6 address pool. Replace203.0.113.200/30with an IPv4 or IPv6 IP address range from an address pool.Example output
BGP routing table entry for 203.0.113.200/30 Paths: (1 available, best #1, table default) Advertised to non peer-group peers: 10.0.2.3 <.> Local 0.0.0.0 from 0.0.0.0 (10.0.1.2) Origin IGP, metric 0, weight 32768, valid, sourced, local, best (First path received) Last update: Mon Jan 10 19:49:07 2022<.> Confirm that the output includes an IP address for a BGP peer.
26.7.3. Troubleshooting BFD issues
The Bidirectional Forwarding Detection (BFD) implementation that Red Hat supports uses FRRouting (FRR) in a container in the speaker pods. The BFD implementation relies on BFD peers also being configured as BGP peers with an established BGP session. As a cluster administrator, if you need to troubleshoot BFD configuration issues, you need to run commands in the FRR container.
Prerequisites
-
You have access to the cluster as a user with the
cluster-adminrole. -
You have installed the OpenShift CLI (
oc).
Procedure
Display the names of the
speakerpods:$ oc get -n metallb-system pods -l app.kubernetes.io/component=speakerExample output
NAME READY STATUS RESTARTS AGE speaker-66bth 4/4 Running 0 26m speaker-gvfnf 4/4 Running 0 26m ...Display the BFD peers:
$ oc exec -n metallb-system speaker-66bth -c frr -- vtysh -c "show bfd peers brief"Example output
Session count: 2 SessionId LocalAddress PeerAddress Status ========= ============ =========== ====== 3909139637 10.0.1.2 10.0.2.3 up <.><.> Confirm that the
PeerAddresscolumn includes each BFD peer. If the output does not list a BFD peer IP address that you expected the output to include, troubleshoot BGP connectivity with the peer. If the status field indicatesdown, check for connectivity on the links and equipment between the node and the peer. You can determine the node name for the speaker pod with a command likeoc get pods -n metallb-system speaker-66bth -o jsonpath='{.spec.nodeName}'.
26.7.4. MetalLB metrics for BGP and BFD
OpenShift Container Platform captures the following metrics that are related to MetalLB and BGP peers and BFD profiles:
-
metallb_bfd_control_packet_inputcounts the number of BFD control packets received from each BFD peer. -
metallb_bfd_control_packet_outputcounts the number of BFD control packets sent to each BFD peer. -
metallb_bfd_echo_packet_inputcounts the number of BFD echo packets received from each BFD peer. -
metallb_bfd_echo_packet_outputcounts the number of BFD echo packets sent to each BFD peer. -
metallb_bfd_session_down_eventscounts the number of times the BFD session with a peer entered thedownstate. -
metallb_bfd_session_upindicates the connection state with a BFD peer.1indicates the session isupand0indicates the session isdown. -
metallb_bfd_session_up_eventscounts the number of times the BFD session with a peer entered theupstate. -
metallb_bfd_zebra_notificationscounts the number of BFD Zebra notifications for each BFD peer. -
metallb_bgp_announced_prefixes_totalcounts the number of load balancer IP address prefixes that are advertised to BGP peers. The terms prefix and aggregated route have the same meaning. -
metallb_bgp_session_upindicates the connection state with a BGP peer.1indicates the session isupand0indicates the session isdown. -
metallb_bgp_updates_totalcounts the number of BGPupdatemessages that were sent to a BGP peer.
26.7.5. About collecting MetalLB data
You can use the oc adm must-gather CLI command to collect information about your cluster, your MetalLB configuration, and the MetalLB Operator. The following features and objects are associated with MetalLB and the MetalLB Operator:
- The namespace and child objects that the MetalLB Operator is deployed in
- All MetalLB Operator custom resource definitions (CRDs)
The oc adm must-gather CLI command collects the following information from FRRouting (FRR) that Red Hat uses to implement BGP and BFD:
-
/etc/frr/frr.conf -
/etc/frr/frr.log -
/etc/frr/daemonsconfiguration file -
/etc/frr/vtysh.conf
The log and configuration files in the preceding list are collected from the frr container in each speaker pod.
In addition to the log and configuration files, the oc adm must-gather CLI command collects the output from the following vtysh commands:
-
show running-config -
show bgp ipv4 -
show bgp ipv6 -
show bgp neighbor -
show bfd peer
No additional configuration is required when you run the oc adm must-gather CLI command.