17.4. 가시성
17.4.1. 통신 핵심 CNF 클러스터의 관찰 기능
OpenShift Container Platform은 플랫폼 및 플랫폼에서 실행되는 워크로드 모두에서 성능 지표 및 로그와 같은 대량의 데이터를 생성합니다. 관리자는 다양한 도구를 사용하여 사용 가능한 모든 데이터를 수집하고 분석할 수 있습니다. 다음은 관찰 기능 스택을 구성하는 시스템 엔지니어, 아키텍트 및 관리자에 대한 모범 사례에 대한 개요입니다.
명시적으로 명시하지 않는 한 이 문서의 내용은 Edge 및 Core 배포 모두를 나타냅니다.
17.4.1.1. 모니터링 스택 이해
모니터링 스택은 다음 구성 요소를 사용합니다.
- Prometheus는 OpenShift Container Platform 구성 요소 및 워크로드에서 지표를 수집하고 분석합니다.
- Alertmanager는 Prometheus의 구성 요소로, 라우팅, 그룹화, 경고 실링을 처리합니다.
- Thanos는 메트릭의 장기 스토리지를 처리합니다.
그림 17.2. OpenShift Container Platform 모니터링 아키텍처
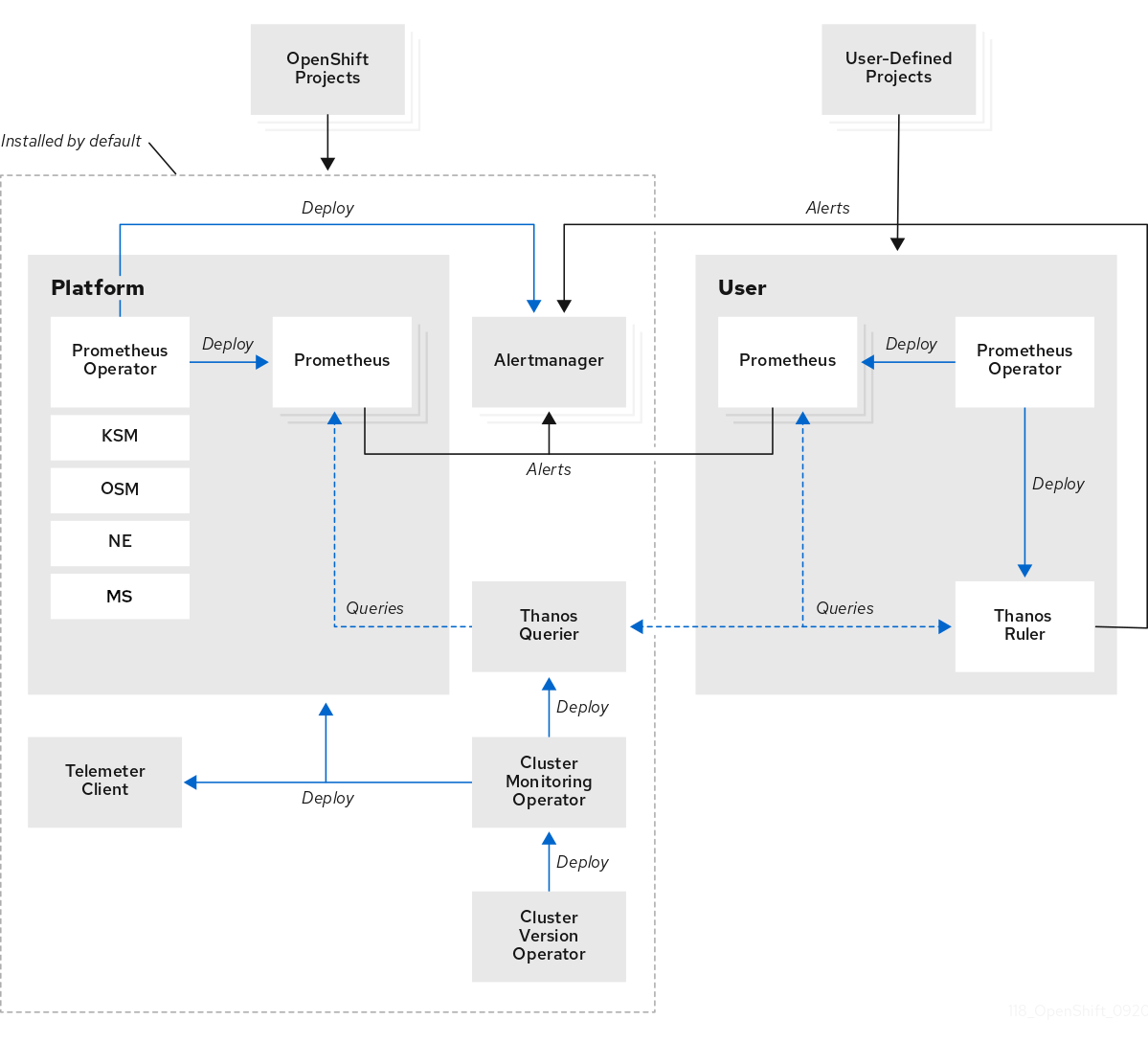
단일 노드 OpenShift 클러스터의 경우 분석 및 보존을 위해 클러스터에서 모든 메트릭을 hub 클러스터로 전송하므로 Alertmanager 및 Thanos를 비활성화해야 합니다.
17.4.1.2. 주요 성능 지표
시스템에 따라 사용 가능한 수백 개의 측정이 있을 수 있습니다.
다음은 고려해야 할 몇 가지 주요 지표입니다.
-
etcd응답 시간 - API 응답 시간
- Pod 재시작 및 예약
- 리소스 사용량
- OVN 상태
- 전체 클러스터 Operator 상태
따라야 할 좋은 규칙은 메트릭이 중요한 것으로 결정하는 경우 이에 대한 경고가 있다는 것입니다.
다음 명령을 실행하여 사용 가능한 메트릭을 확인할 수 있습니다.
$ oc -n openshift-monitoring exec -c prometheus prometheus-k8s-0 -- curl -qsk http://localhost:9090/api/v1/metadata | jq '.data17.4.1.2.1. PromQL의 쿼리 예
다음 표에는 OpenShift Container Platform 콘솔을 사용하여 메트릭 쿼리 브라우저에서 탐색할 수 있는 몇 가지 쿼리가 표시되어 있습니다.
콘솔의 URL은 https://<OpenShift Console FQDN>/monitoring/query-browser입니다. 다음 명령을 실행하여 OpenShift 콘솔 FQDN을 가져올 수 있습니다.
$ oc get routes -n openshift-console console -o jsonpath='{.status.ingress[0].host}'| 지표 | 쿼리 |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| combined |
|
| 지표 | 쿼리 |
|---|---|
|
|
|
|
|
|
| 리더 선택 |
|
| 네트워크 대기 시간 |
|
| 지표 | 쿼리 |
|---|---|
| 성능이 저하된 Operator |
|
| 클러스터당 총 성능이 저하된 Operator |
|
17.4.1.2.2. 메트릭 스토리지에 대한 권장 사항
기본적으로 Prometheus는 영구 스토리지를 사용하여 저장된 지표를 백업하지 않습니다. Prometheus Pod를 다시 시작하면 모든 지표 데이터가 손실됩니다. 플랫폼에서 사용 가능한 백엔드 스토리지를 사용하도록 모니터링 스택을 구성해야 합니다. Prometheus의 높은 IO 요구 사항을 충족하려면 로컬 스토리지를 사용해야 합니다.
Telco 코어 클러스터의 경우 Prometheus용 영구 스토리지에 Local Storage Operator를 사용할 수 있습니다.
블록, 파일 및 오브젝트 스토리지에 대한 ceph 클러스터를 배포하는 Red Hat OpenShift Data Foundation(ODF)은 Telco 코어 클러스터에도 적합한 후보입니다.
RAN 단일 노드 OpenShift 또는 far edge 클러스터에서 시스템 리소스 요구 사항을 낮게 유지하려면 모니터링 스택의 백엔드 스토리지를 프로비저닝해서는 안 됩니다. 이러한 클러스터는 타사 모니터링 플랫폼을 프로비저닝할 수 있는 허브 클러스터에 모든 메트릭을 전달합니다.
17.4.1.3. 엣지 모니터링
엣지의 단일 노드 OpenShift는 플랫폼 구성 요소의 설치 공간을 최소한으로 유지합니다. 다음 절차는 작은 모니터링 풋프린트로 단일 노드 OpenShift 노드를 구성하는 방법의 예입니다.
사전 요구 사항
- RHACM(Red Hat Advanced Cluster Management)을 사용하는 환경의 경우 Observability 서비스를 활성화했습니다.
- hub 클러스터는 Red Hat ODF(OpenShift Data Foundation)를 실행하고 있습니다.
프로세스
ConfigMapCR을 생성하고 다음 예와 같이monitoringConfigMap.yaml으로 저장합니다.apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | alertmanagerMain: enabled: false telemeterClient: enabled: false prometheusK8s: retention: 24h단일 노드 OpenShift에서 다음 명령을 실행하여
ConfigMapCR을 적용합니다.$ oc apply -f monitoringConfigMap.yamlNameSpaceCR을 생성하고 다음 예와 같이monitoringNamespace.yaml로 저장합니다.apiVersion: v1 kind: Namespace metadata: name: open-cluster-management-observabilityhub 클러스터에서 다음 명령을 실행하여 hub 클러스터에서
NamespaceCR을 적용합니다.$ oc apply -f monitoringNamespace.yamlObjectBucketClaimCR을 생성하고 다음 예와 같이monitoringObjectBucketClaim.yaml로 저장합니다.apiVersion: objectbucket.io/v1alpha1 kind: ObjectBucketClaim metadata: name: multi-cloud-observability namespace: open-cluster-management-observability spec: storageClassName: openshift-storage.noobaa.io generateBucketName: acm-multihub 클러스터에서 다음 명령을 실행하여
ObjectBucketClaimCR을 적용합니다.$ oc apply -f monitoringObjectBucketClaim.yamlSecretCR을 생성하고 다음 예와 같이monitoringSecret.yaml로 저장합니다.apiVersion: v1 kind: Secret metadata: name: multiclusterhub-operator-pull-secret namespace: open-cluster-management-observability stringData: .dockerconfigjson: 'PULL_SECRET'hub 클러스터에서 다음 명령을 실행하여
SecretCR을 적용합니다.$ oc apply -f monitoringSecret.yaml다음 명령을 실행하여 허브 클러스터에서 NooBaa 서비스의 키와 백엔드 버킷 이름을 가져옵니다.
$ NOOBAA_ACCESS_KEY=$(oc get secret noobaa-admin -n openshift-storage -o json | jq -r '.data.AWS_ACCESS_KEY_ID|@base64d')$ NOOBAA_SECRET_KEY=$(oc get secret noobaa-admin -n openshift-storage -o json | jq -r '.data.AWS_SECRET_ACCESS_KEY|@base64d')$ OBJECT_BUCKET=$(oc get objectbucketclaim -n open-cluster-management-observability multi-cloud-observability -o json | jq -r .spec.bucketName)버킷 스토리지에 대한
SecretCR을 생성하고 다음 예와 같이monitoringBucketSecret.yaml로 저장합니다.apiVersion: v1 kind: Secret metadata: name: thanos-object-storage namespace: open-cluster-management-observability type: Opaque stringData: thanos.yaml: | type: s3 config: bucket: ${OBJECT_BUCKET} endpoint: s3.openshift-storage.svc insecure: true access_key: ${NOOBAA_ACCESS_KEY} secret_key: ${NOOBAA_SECRET_KEY}hub 클러스터에서 다음 명령을 실행하여
SecretCR을 적용합니다.$ oc apply -f monitoringBucketSecret.yamlMultiClusterObservabilityCR을 생성하고 다음 예와 같이monitoringMultiClusterObservability.yaml로 저장합니다.apiVersion: observability.open-cluster-management.io/v1beta2 kind: MultiClusterObservability metadata: name: observability spec: advanced: retentionConfig: blockDuration: 2h deleteDelay: 48h retentionInLocal: 24h retentionResolutionRaw: 3d enableDownsampling: false observabilityAddonSpec: enableMetrics: true interval: 300 storageConfig: alertmanagerStorageSize: 10Gi compactStorageSize: 100Gi metricObjectStorage: key: thanos.yaml name: thanos-object-storage receiveStorageSize: 25Gi ruleStorageSize: 10Gi storeStorageSize: 25Gihub 클러스터에서 다음 명령을 실행하여
MultiClusterObservabilityCR을 적용합니다.$ oc apply -f monitoringMultiClusterObservability.yaml
검증
네임스페이스의 경로와 Pod를 확인하여 다음 명령을 실행하여 서비스가 허브 클러스터에 배포되었는지 확인합니다.
$ oc get routes,pods -n open-cluster-management-observability출력 예
NAME HOST/PORT PATH SERVICES PORT TERMINATION WILDCARD route.route.openshift.io/alertmanager alertmanager-open-cluster-management-observability.cloud.example.com /api/v2 alertmanager oauth-proxy reencrypt/Redirect None route.route.openshift.io/grafana grafana-open-cluster-management-observability.cloud.example.com grafana oauth-proxy reencrypt/Redirect None1 route.route.openshift.io/observatorium-api observatorium-api-open-cluster-management-observability.cloud.example.com observability-observatorium-api public passthrough/None None route.route.openshift.io/rbac-query-proxy rbac-query-proxy-open-cluster-management-observability.cloud.example.com rbac-query-proxy https reencrypt/Redirect None NAME READY STATUS RESTARTS AGE pod/observability-alertmanager-0 3/3 Running 0 1d pod/observability-alertmanager-1 3/3 Running 0 1d pod/observability-alertmanager-2 3/3 Running 0 1d pod/observability-grafana-685b47bb47-dq4cw 3/3 Running 0 1d <...snip…> pod/observability-thanos-store-shard-0-0 1/1 Running 0 1d pod/observability-thanos-store-shard-1-0 1/1 Running 0 1d pod/observability-thanos-store-shard-2-0 1/1 Running 0 1d- 1
- 대시보드는 나열된 grafana 경로에서 액세스할 수 있습니다. 이를 사용하여 모든 관리 클러스터의 지표를 볼 수 있습니다.
Red Hat Advanced Cluster Management의 관찰 기능에 대한 자세한 내용은 Observability 를 참조하십시오.
17.4.1.4. 경고
OpenShift Container Platform에는 많은 수의 경고 규칙이 포함되어 있으며 이는 릴리스에서 릴리스로 변경될 수 있습니다.
17.4.1.4.1. 기본 경고 보기
다음 절차에 따라 클러스터의 모든 경고 규칙을 검토합니다.
프로세스
클러스터의 모든 경고 규칙을 검토하려면 다음 명령을 실행합니다.
$ oc get cm -n openshift-monitoring prometheus-k8s-rulefiles-0 -o yaml규칙에는 설명이 포함될 수 있으며 추가 정보 및 완화 단계에 대한 링크를 제공할 수 있습니다. 예를 들어, 이는
etcdHighFsyncDurations의 규칙입니다.- alert: etcdHighFsyncDurations annotations: description: 'etcd cluster "{{ $labels.job }}": 99th percentile fsync durations are {{ $value }}s on etcd instance {{ $labels.instance }}.' runbook_url: https://github.com/openshift/runbooks/blob/master/alerts/cluster-etcd-operator/etcdHighFsyncDurations.md summary: etcd cluster 99th percentile fsync durations are too high. expr: | histogram_quantile(0.99, rate(etcd_disk_wal_fsync_duration_seconds_bucket{job=~".*etcd.*"}[5m])) > 1 for: 10m labels: severity: critical
17.4.1.4.2. 경고 알림
OpenShift Container Platform 콘솔에서 경고를 볼 수 있지만 관리자는 경고를 전달하도록 외부 수신자를 구성해야 합니다. OpenShift Container Platform에서는 다음 수신기 유형을 지원합니다.
- PagerDuty: 타사 사고 대응 플랫폼
- Webhook: POST 요청을 통해 경고를 수신하고 필요한 작업을 수행할 수 있는 임의의 API 끝점
- 이메일: 지정된 주소로 이메일을 보냅니다.
- Slack: 슬랙 채널 또는 개별 사용자에게 알림을 보냅니다.
17.4.1.5. 워크로드 모니터링
기본적으로 OpenShift Container Platform은 애플리케이션 워크로드에 대한 메트릭을 수집하지 않습니다. 워크로드 지표를 수집하도록 클러스터를 구성할 수 있습니다.
사전 요구 사항
- 클러스터에서 워크로드 지표를 수집하기 위해 끝점이 정의되어 있습니다.
프로세스
ConfigMapCR을 생성하고 다음 예와 같이monitoringConfigMap.yaml로 저장합니다.apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | enableUserWorkload: true1 - 1
- 워크로드 모니터링을 활성화하려면
true로 설정합니다.
다음 명령을 실행하여
ConfigMapCR을 적용합니다.$ oc apply -f monitoringConfigMap.yamlServiceMonitorCR을 생성하고 다음 예와 같이monitoringServiceMonitor.yaml로 저장합니다.apiVersion: monitoring.coreos.com/v1 kind: ServiceMonitor metadata: labels: app: ui name: myapp namespace: myns spec: endpoints:1 - interval: 30s port: ui-http scheme: http path: /healthz2 selector: matchLabels: app: ui다음 명령을 실행하여
ServiceMonitorCR을 적용합니다.$ oc apply -f monitoringServiceMonitor.yaml
Prometheus는 기본적으로 경로 /metrics 를 스크랩하지만 사용자 정의 경로를 정의할 수 있습니다. 스크래핑을 위해 이 끝점을 노출하는 것은 애플리케이션 벤더에게 관련이 있는 지표와 함께 노출될 수 있습니다.
17.4.1.5.1. 워크로드 경고 생성
클러스터에서 사용자 워크로드에 대한 경고를 활성화할 수 있습니다.
프로세스
ConfigMapCR을 생성하고 다음 예와 같이monitoringConfigMap.yaml으로 저장합니다.apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | enableUserWorkload: true1 # ...- 1
- 워크로드 모니터링을 활성화하려면
true로 설정합니다.
다음 명령을 실행하여
ConfigMapCR을 적용합니다.$ oc apply -f monitoringConfigMap.yaml다음 예와 같이 경고 규칙,
monitoringAlertRule.yaml에 대한 YAML 파일을 생성합니다.apiVersion: monitoring.coreos.com/v1 kind: PrometheusRule metadata: name: myapp-alert namespace: myns spec: groups: - name: example rules: - alert: InternalErrorsAlert expr: flask_http_request_total{status="500"} > 0 # ...다음 명령을 실행하여 경고 규칙을 적용합니다.
$ oc apply -f monitoringAlertRule.yaml