5.5.2. 自定义调整规格
Operator 的自定义资源 (CR) 包含两个主要部分。第一部分是 profile:,这是 TuneD 配置集及其名称的列表。第二部分是 recommend:,用来定义配置集选择逻辑。
多个自定义调优规格可以共存,作为 Operator 命名空间中的多个 CR。Operator 会检测到是否存在新 CR 或删除了旧 CR。所有现有的自定义性能优化设置都会合并,同时更新容器化 TuneD 守护进程的适当对象。
管理状态
通过调整默认的 Tuned CR 来设置 Operator Management 状态。默认情况下,Operator 处于 Managed 状态,默认的 Tuned CR 中没有 spec.managementState 字段。Operator Management 状态的有效值如下:
- Managed: Operator 会在配置资源更新时更新其操作对象
- Unmanaged: Operator 将忽略配置资源的更改
- Removed: Operator 将移除 Operator 置备的操作对象和资源
配置集数据
profile: 部分列出了 TuneD 配置集及其名称。
profile:
- name: tuned_profile_1
data: |
# TuneD profile specification
[main]
summary=Description of tuned_profile_1 profile
[sysctl]
net.ipv4.ip_forward=1
# ... other sysctl's or other TuneD daemon plugins supported by the containerized TuneD
# ...
- name: tuned_profile_n
data: |
# TuneD profile specification
[main]
summary=Description of tuned_profile_n profile
# tuned_profile_n profile settings建议的配置集
profile: 选择逻辑通过 CR 的 recommend: 部分来定义。recommend: 部分是根据选择标准推荐配置集的项目列表。
recommend:
<recommend-item-1>
# ...
<recommend-item-n>列表中的独立项:
- machineConfigLabels:
<mcLabels>
match:
<match>
priority: <priority>
profile: <tuned_profile_name>
operand:
debug: <bool>
<match> 是一个递归定义的可选数组,如下所示:
- label: <label_name>
value: <label_value>
type: <label_type>
<match>
如果不省略 <match>,则所有嵌套的 <match> 部分也必须评估为 true。否则会假定 false,并且不会应用或建议具有对应 <match> 部分的配置集。因此,嵌套(子级 <match> 部分)会以逻辑 AND 运算来运作。反之,如果匹配 <match> 列表中任何一项,整个 <match> 列表评估为 true。因此,该列表以逻辑 OR 运算来运作。
如果定义 了 machineConfigLabels,基于机器配置池的匹配会对给定的 recommend: 列表项打开。<mcLabels> 指定机器配置标签。机器配置会自动创建,以在配置集 <tuned_profile_name> 中应用主机设置,如内核引导参数。这包括使用与 <mcLabels> 匹配的机器配置选择器查找所有机器配置池,并在分配了找到的机器配置池的所有节点上设置配置集 <tuned_profile_name>。要针对同时具有 master 和 worker 角色的节点,您必须使用 master 角色。
列表项 match 和 machineConfigLabels 由逻辑 OR 操作符连接。match 项首先以短电路方式评估。因此,如果它被评估为 true,则不考虑 MachineConfigLabels 项。
当使用基于机器配置池的匹配时,建议将具有相同硬件配置的节点分组到同一机器配置池中。不遵循这个原则可能会导致在共享同一机器配置池的两个或者多个节点中 TuneD 操作对象导致内核参数冲突。
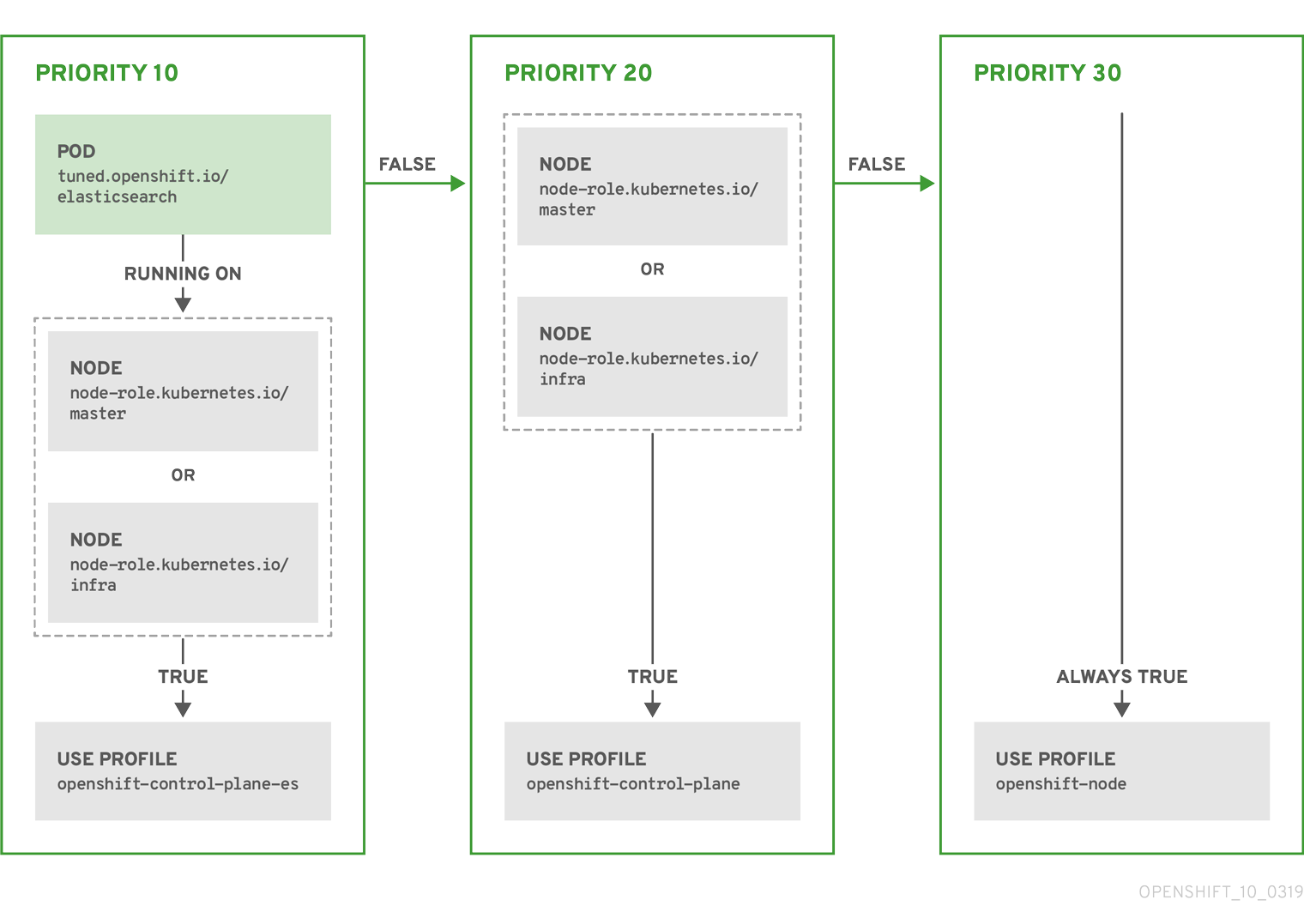
示例:基于节点或 pod 标签的匹配
- match:
- label: tuned.openshift.io/elasticsearch
match:
- label: node-role.kubernetes.io/master
- label: node-role.kubernetes.io/infra
type: pod
priority: 10
profile: openshift-control-plane-es
- match:
- label: node-role.kubernetes.io/master
- label: node-role.kubernetes.io/infra
priority: 20
profile: openshift-control-plane
- priority: 30
profile: openshift-node
根据配置集优先级,以上 CR 针对容器化 TuneD 守护进程转换为 recommend.conf 文件。优先级最高 (10) 的配置集是 openshift-control-plane-es,因此会首先考虑它。在给定节点上运行的容器化 TuneD 守护进程会查看同一节点上是否在运行设有 tuned.openshift.io/elasticsearch 标签的 pod。如果没有,则整个 <match> 部分评估为 false。如果存在具有该标签的 pod,为了让 <match> 部分评估为 true,节点标签也需要是 node-role.kubernetes.io/master 或 node-role.kubernetes.io/infra。
如果这些标签对优先级为 10 的配置集而言匹配,则应用 openshift-control-plane-es 配置集,并且不考虑其他配置集。如果节点/pod 标签组合不匹配,则考虑优先级第二高的配置集 (openshift-control-plane)。如果容器化 TuneD Pod 在具有标签 node-role.kubernetes.io/master 或 node-role.kubernetes.io/infra 的节点上运行,则应用此配置集。
最后,配置集 openshift-node 的优先级最低 (30)。它没有 <match> 部分,因此始终匹配。如果给定节点上不匹配任何优先级更高的配置集,它会作为一个适用于所有节点的配置集来设置 openshift-node 配置集。
示例:基于机器配置池的匹配
apiVersion: tuned.openshift.io/v1
kind: Tuned
metadata:
name: openshift-node-custom
namespace: openshift-cluster-node-tuning-operator
spec:
profile:
- data: |
[main]
summary=Custom OpenShift node profile with an additional kernel parameter
include=openshift-node
[bootloader]
cmdline_openshift_node_custom=+skew_tick=1
name: openshift-node-custom
recommend:
- machineConfigLabels:
machineconfiguration.openshift.io/role: "worker-custom"
priority: 20
profile: openshift-node-custom为尽量减少节点的重新引导情况,为目标节点添加机器配置池将匹配的节点选择器标签,然后创建上述 Tuned CR,最后创建自定义机器配置池。