3.3. Using deployment strategies
A deployment strategy is a way to change or upgrade an application. The aim is to make the change without downtime in a way that the user barely notices the improvements.
Because the end user usually accesses the application through a route handled by a router, the deployment strategy can focus on DeploymentConfig object features or routing features. Strategies that focus on the deployment impact all routes that use the application. Strategies that use router features target individual routes.
Many deployment strategies are supported through the DeploymentConfig object, and some additional strategies are supported through router features. Deployment strategies are discussed in this section.
Choosing a deployment strategy
Consider the following when choosing a deployment strategy:
- Long-running connections must be handled gracefully.
- Database conversions can be complex and must be done and rolled back along with the application.
- If the application is a hybrid of microservices and traditional components, downtime might be required to complete the transition.
- You must have the infrastructure to do this.
- If you have a non-isolated test environment, you can break both new and old versions.
A deployment strategy uses readiness checks to determine if a new pod is ready for use. If a readiness check fails, the DeploymentConfig object retries to run the pod until it times out. The default timeout is 10m, a value set in TimeoutSeconds in dc.spec.strategy.*params.
3.3.1. Rolling strategy
A rolling deployment slowly replaces instances of the previous version of an application with instances of the new version of the application. The rolling strategy is the default deployment strategy used if no strategy is specified on a DeploymentConfig object.
A rolling deployment typically waits for new pods to become ready via a readiness check before scaling down the old components. If a significant issue occurs, the rolling deployment can be aborted.
When to use a rolling deployment:
- When you want to take no downtime during an application update.
- When your application supports having old code and new code running at the same time.
A rolling deployment means you to have both old and new versions of your code running at the same time. This typically requires that your application handle N-1 compatibility.
Example rolling strategy definition
strategy:
type: Rolling
rollingParams:
updatePeriodSeconds: 1
intervalSeconds: 1
timeoutSeconds: 120
maxSurge: "20%"
maxUnavailable: "10%"
pre: {}
post: {}- 1
- The time to wait between individual pod updates. If unspecified, this value defaults to
1. - 2
- The time to wait between polling the deployment status after update. If unspecified, this value defaults to
1. - 3
- The time to wait for a scaling event before giving up. Optional; the default is
600. Here, giving up means automatically rolling back to the previous complete deployment. - 4
maxSurgeis optional and defaults to25%if not specified. See the information below the following procedure.- 5
maxUnavailableis optional and defaults to25%if not specified. See the information below the following procedure.- 6
preandpostare both lifecycle hooks.
The rolling strategy:
-
Executes any
prelifecycle hook. - Scales up the new replication controller based on the surge count.
- Scales down the old replication controller based on the max unavailable count.
- Repeats this scaling until the new replication controller has reached the desired replica count and the old replication controller has been scaled to zero.
-
Executes any
postlifecycle hook.
When scaling down, the rolling strategy waits for pods to become ready so it can decide whether further scaling would affect availability. If scaled up pods never become ready, the deployment process will eventually time out and result in a deployment failure.
The maxUnavailable parameter is the maximum number of pods that can be unavailable during the update. The maxSurge parameter is the maximum number of pods that can be scheduled above the original number of pods. Both parameters can be set to either a percentage (e.g., 10%) or an absolute value (e.g., 2). The default value for both is 25%.
These parameters allow the deployment to be tuned for availability and speed. For example:
-
maxUnavailable*=0andmaxSurge*=20%ensures full capacity is maintained during the update and rapid scale up. -
maxUnavailable*=10%andmaxSurge*=0performs an update using no extra capacity (an in-place update). -
maxUnavailable*=10%andmaxSurge*=10%scales up and down quickly with some potential for capacity loss.
Generally, if you want fast rollouts, use maxSurge. If you have to take into account resource quota and can accept partial unavailability, use maxUnavailable.
3.3.1.1. Canary deployments
All rolling deployments in OpenShift Container Platform are canary deployments; a new version (the canary) is tested before all of the old instances are replaced. If the readiness check never succeeds, the canary instance is removed and the DeploymentConfig object will be automatically rolled back.
The readiness check is part of the application code and can be as sophisticated as necessary to ensure the new instance is ready to be used. If you must implement more complex checks of the application (such as sending real user workloads to the new instance), consider implementing a custom deployment or using a blue-green deployment strategy.
3.3.1.2. Creating a rolling deployment
Rolling deployments are the default type in OpenShift Container Platform. You can create a rolling deployment using the CLI.
Procedure
Create an application based on the example deployment images found in Docker Hub:
$ oc new-app openshift/deployment-exampleIf you have the router installed, make the application available via a route or use the service IP directly.
$ oc expose svc/deployment-example-
Browse to the application at
deployment-example.<project>.<router_domain>to verify you see thev1image. Scale the
DeploymentConfigobject up to three replicas:$ oc scale dc/deployment-example --replicas=3Trigger a new deployment automatically by tagging a new version of the example as the
latesttag:$ oc tag deployment-example:v2 deployment-example:latest-
In your browser, refresh the page until you see the
v2image. When using the CLI, the following command shows how many pods are on version 1 and how many are on version 2. In the web console, the pods are progressively added to v2 and removed from v1:
$ oc describe dc deployment-example
During the deployment process, the new replication controller is incrementally scaled up. After the new pods are marked as ready (by passing their readiness check), the deployment process continues.
If the pods do not become ready, the process aborts, and the deployment rolls back to its previous version.
Prerequisites
- Ensure that you are in the Developer perspective of the web console.
- Ensure that you have created an application using the Add view and see it deployed in the Topology view.
Procedure
To start a rolling deployment to upgrade an application:
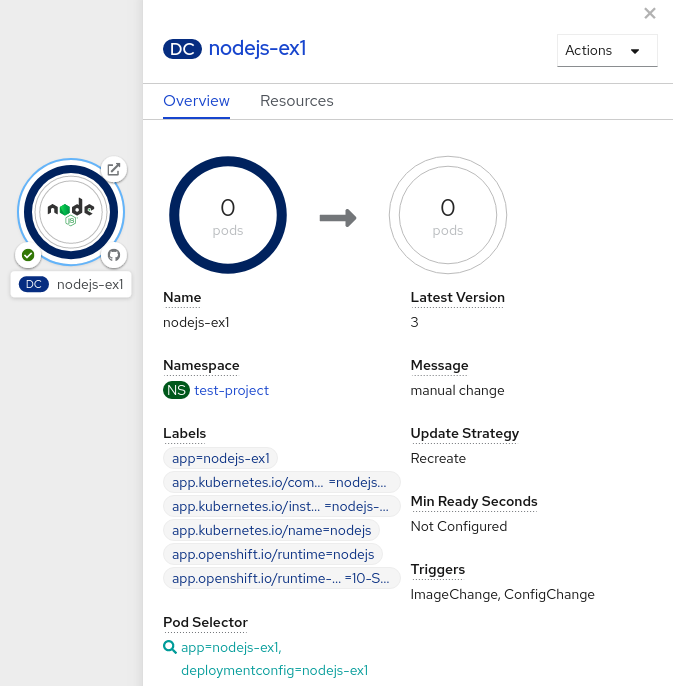
- In the Topology view of the Developer perspective, click on the application node to see the Overview tab in the side panel. Note that the Update Strategy is set to the default Rolling strategy.
In the Actions drop-down menu, select Start Rollout to start a rolling update. The rolling deployment spins up the new version of the application and then terminates the old one.
图 3.1. Rolling update

3.3.2. Recreate strategy
The recreate strategy has basic rollout behavior and supports lifecycle hooks for injecting code into the deployment process.
Example recreate strategy definition
strategy:
type: Recreate
recreateParams:
pre: {}
mid: {}
post: {}The recreate strategy:
-
Executes any
prelifecycle hook. - Scales down the previous deployment to zero.
-
Executes any
midlifecycle hook. - Scales up the new deployment.
-
Executes any
postlifecycle hook.
During scale up, if the replica count of the deployment is greater than one, the first replica of the deployment will be validated for readiness before fully scaling up the deployment. If the validation of the first replica fails, the deployment will be considered a failure.
When to use a recreate deployment:
- When you must run migrations or other data transformations before your new code starts.
- When you do not support having new and old versions of your application code running at the same time.
- When you want to use a RWO volume, which is not supported being shared between multiple replicas.
A recreate deployment incurs downtime because, for a brief period, no instances of your application are running. However, your old code and new code do not run at the same time.
You can switch the deployment strategy from the default rolling update to a recreate update using the Developer perspective in the web console.
Prerequisites
- Ensure that you are in the Developer perspective of the web console.
- Ensure that you have created an application using the Add view and see it deployed in the Topology view.
Procedure
To switch to a recreate update strategy and to upgrade an application:
- In the Actions drop-down menu, select Edit Deployment Config to see the deployment configuration details of the application.
-
In the YAML editor, change the
spec.strategy.typetoRecreateand click Save. - In the Topology view, select the node to see the Overview tab in the side panel. The Update Strategy is now set to Recreate.
Use the Actions drop-down menu to select Start Rollout to start an update using the recreate strategy. The recreate strategy first terminates pods for the older version of the application and then spins up pods for the new version.
图 3.2. Recreate update
3.3.4. Custom strategy
The custom strategy allows you to provide your own deployment behavior.
Example custom strategy definition
strategy:
type: Custom
customParams:
image: organization/strategy
command: [ "command", "arg1" ]
environment:
- name: ENV_1
value: VALUE_1
In the above example, the organization/strategy container image provides the deployment behavior. The optional command array overrides any CMD directive specified in the image’s Dockerfile. The optional environment variables provided are added to the execution environment of the strategy process.
Additionally, OpenShift Container Platform provides the following environment variables to the deployment process:
| Environment variable | Description |
|---|---|
|
| The name of the new deployment, a replication controller. |
|
| The name space of the new deployment. |
The replica count of the new deployment will initially be zero. The responsibility of the strategy is to make the new deployment active using the logic that best serves the needs of the user.
Alternatively, use the customParams object to inject the custom deployment logic into the existing deployment strategies. Provide a custom shell script logic and call the openshift-deploy binary. Users do not have to supply their custom deployer container image; in this case, the default OpenShift Container Platform deployer image is used instead:
strategy:
type: Rolling
customParams:
command:
- /bin/sh
- -c
- |
set -e
openshift-deploy --until=50%
echo Halfway there
openshift-deploy
echo CompleteThis results in following deployment:
Started deployment #2
--> Scaling up custom-deployment-2 from 0 to 2, scaling down custom-deployment-1 from 2 to 0 (keep 2 pods available, don't exceed 3 pods)
Scaling custom-deployment-2 up to 1
--> Reached 50% (currently 50%)
Halfway there
--> Scaling up custom-deployment-2 from 1 to 2, scaling down custom-deployment-1 from 2 to 0 (keep 2 pods available, don't exceed 3 pods)
Scaling custom-deployment-1 down to 1
Scaling custom-deployment-2 up to 2
Scaling custom-deployment-1 down to 0
--> Success
CompleteIf the custom deployment strategy process requires access to the OpenShift Container Platform API or the Kubernetes API the container that executes the strategy can use the service account token available inside the container for authentication.
3.3.5. Lifecycle hooks
The rolling and recreate strategies support lifecycle hooks, or deployment hooks, which allow behavior to be injected into the deployment process at predefined points within the strategy:
Example pre lifecycle hook
pre:
failurePolicy: Abort
execNewPod: {} - 1
execNewPodis a pod-based lifecycle hook.
Every hook has a failure policy, which defines the action the strategy should take when a hook failure is encountered:
|
| The deployment process will be considered a failure if the hook fails. |
|
| The hook execution should be retried until it succeeds. |
|
| Any hook failure should be ignored and the deployment should proceed. |
Hooks have a type-specific field that describes how to execute the hook. Currently, pod-based hooks are the only supported hook type, specified by the execNewPod field.
Pod-based lifecycle hook
Pod-based lifecycle hooks execute hook code in a new pod derived from the template in a DeploymentConfig object.
The following simplified example deployment uses the rolling strategy. Triggers and some other minor details are omitted for brevity:
kind: DeploymentConfig
apiVersion: v1
metadata:
name: frontend
spec:
template:
metadata:
labels:
name: frontend
spec:
containers:
- name: helloworld
image: openshift/origin-ruby-sample
replicas: 5
selector:
name: frontend
strategy:
type: Rolling
rollingParams:
pre:
failurePolicy: Abort
execNewPod:
containerName: helloworld
command: [ "/usr/bin/command", "arg1", "arg2" ]
env:
- name: CUSTOM_VAR1
value: custom_value1
volumes:
- data - 1
- The
helloworldname refers tospec.template.spec.containers[0].name. - 2
- This
commandoverrides anyENTRYPOINTdefined by theopenshift/origin-ruby-sampleimage. - 3
envis an optional set of environment variables for the hook container.- 4
volumesis an optional set of volume references for the hook container.
In this example, the pre hook will be executed in a new pod using the openshift/origin-ruby-sample image from the helloworld container. The hook pod has the following properties:
-
The hook command is
/usr/bin/command arg1 arg2. -
The hook container has the
CUSTOM_VAR1=custom_value1environment variable. -
The hook failure policy is
Abort, meaning the deployment process fails if the hook fails. -
The hook pod inherits the
datavolume from theDeploymentConfigobject pod.
3.3.5.1. Setting lifecycle hooks
You can set lifecycle hooks, or deployment hooks, for a deployment using the CLI.
Procedure
Use the
oc set deployment-hookcommand to set the type of hook you want:--pre,--mid, or--post. For example, to set a pre-deployment hook:$ oc set deployment-hook dc/frontend \ --pre -c helloworld -e CUSTOM_VAR1=custom_value1 \ --volumes data --failure-policy=abort -- /usr/bin/command arg1 arg2