3.5. Kafka MirrorMaker 2.0 の設定
ここでは、AMQ Streams クラスターで Kafka MirrorMaker 2.0 デプロイメントを設定する方法を説明します。
MirrorMaker 2.0 は、データセンター内またはデータセンター全体の 2 台以上の Kafka クラスター間でデータを複製するために使用されます。
クラスター全体のデータレプリケーションでは、以下が必要な状況がサポートされます。
- システム障害時のデータの復旧
- 分析用のデータの集計
- 特定のクラスターへのデータアクセスの制限
- レイテンシーを改善するための特定場所でのデータのプロビジョニング
MirrorMaker 2.0 を使用している場合は、KafkaMirrorMaker2 リソースを設定します。
MirrorMaker 2.0 では、クラスターの間でデータを複製する全く新しい方法が導入されました。
その結果、リソースの設定は MirrorMaker の以前のバージョンとは異なります。MirrorMaker 2.0 の使用を選択した場合、現在、レガシーサポートがないため、リソースを手作業で新しい形式に変換する必要があります。
MirrorMaker 2.0 によってデータが複製される方法は、以下に説明されています。
以下の手順では、MirrorMaker 2.0 に対してリソースが設定される方法について取り上げます。
KafkaMirrorMaker2 リソースの完全なスキーマは、KafkaMirrorMaker2 のスキーマ参照 に記載されています。
3.5.1. MirrorMaker 2.0 のデータレプリケーション
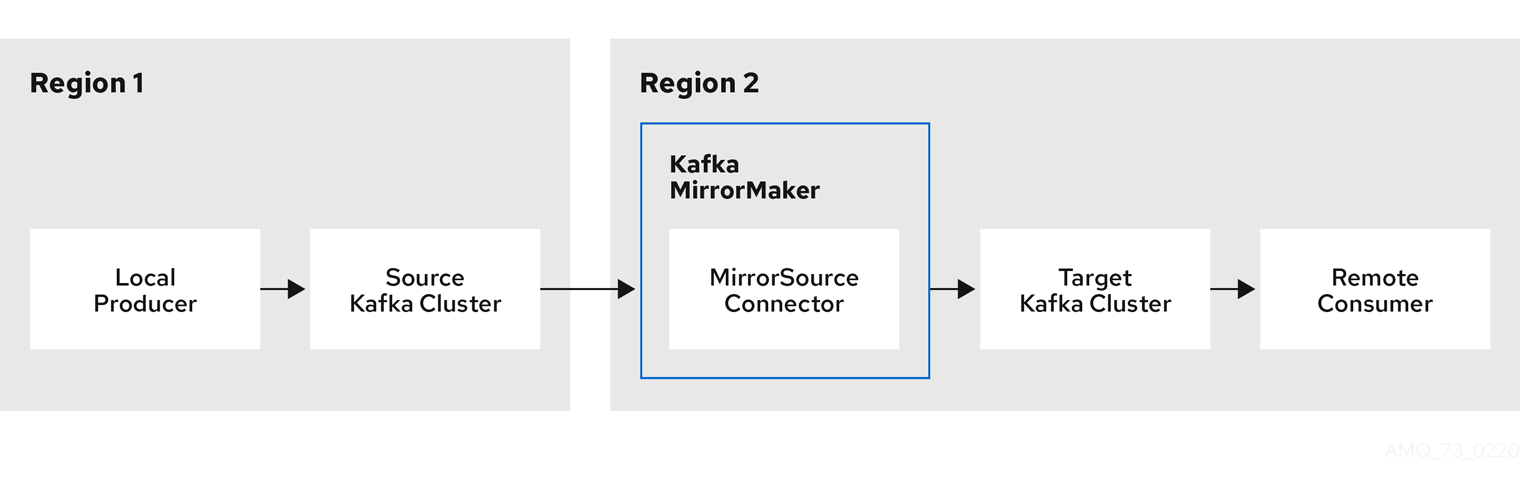
MirrorMaker 2.0 はソースの Kafka クラスターからメッセージを消費して、ターゲットの Kafka クラスターに書き込みます。
MirrorMaker 2.0 は以下を使用します。
- ソースクラスターからデータを消費するソースクラスターの設定
- データをターゲットクラスターに出力するターゲットクラスターの設定
MirrorMaker 2.0 は Kafka Connect フレームワークをベースとし、コネクター によってクラスター間のデータ転送が管理されます。MirrorMaker 2.0 の MirrorSourceConnector は、ソースクラスターからターゲットクラスターにトピックを複製します。
あるクラスターから別のクラスターにデータを ミラーリング するプロセスは非同期です。推奨されるパターンは、ソース Kafka クラスターとともにローカルでメッセージが作成され、ターゲットの Kafka クラスターの近くでリモートで消費されることです。
MirrorMaker 2.0 は、複数のソースクラスターで使用できます。
図3.1 2 つのクラスターにおけるレプリケーション