第 16 章 电信核心 CNF 集群的第 2 天操作
16.1. 升级电信核心 CNF 集群
16.1.1. 升级电信核心 CNF 集群
OpenShift Container Platform 在所有发行版本以及 EUS 版本之间的更新路径中都提供长期支持或延长的更新支持 (EUS)。您可以从一个 EUS 版本升级到下一个 EUS 版本。也可以在 y-stream 和 z-stream 版本之间更新。
16.1.1.1. 电信核心 CNF 集群的集群更新
更新集群是一个关键任务,可确保修补错误和潜在的安全漏洞。通常,对云原生网络功能 (CNF) 的更新需要您更新集群版本时附带的平台的额外功能。您还必须定期更新集群,以确保支持集群平台版本。
您可以通过与 EUS 版本保持最新状态,并升级到特定的重要 z-stream 版本来最小化保持最新更新的工作量。
集群的更新路径可能会因集群的大小和拓扑而异。此处描述的更新过程对于大多数集群(从 3 个节点集群到电信扩展团队认证的最大集群)都有效。这包括混合工作负载集群的一些场景。
描述以下更新场景:
- Control Plane Only 更新
- Y-stream 更新
- z-stream 更新
Control Plane Only 更新以前被称为 EUS 到 EUS 更新。Control Plane Only 更新只能在偶数的 OpenShift Container Platform 次版本之间进行。
16.1.2. 在更新版本之间验证集群 API 版本
在组件被更新时,API 会随时间变化。验证云原生网络功能 (CNF) API 与更新的集群版本兼容非常重要。
16.1.2.1. OpenShift Container Platform API 兼容性
当考虑作为新的 y-stream 更新的一部分哪些 z-stream 版本要更新时,您必须确保您要从中迁移的 z-stream 版本中的所有补丁都位于新的 z-stream 版本中。如果您升级到的版本没有所有必需的补丁,则 Kubernetes 的内置兼容性将无法正常工作。
例如,如果集群版本是 4.15.32,则必须升级到 4.16 z-stream 版本,其所有补丁都应用到 4.15.32。
16.1.2.1.1. 关于 Kubernetes 版本偏移
每个集群 Operator 支持特定的 API 版本。Kubernetes API 随时间变化,新版本可以被弃用或更改现有的 API。这称为 "version skew"。对于每个新版本,您必须检查 API 更改。API 可能会在 Operator 的几个发行版本间兼容,但无法保证兼容性。要缓解 version skew 问题,请遵循明确的更新策略。
16.1.2.2. 确定集群版本更新路径
使用 Red Hat OpenShift Container Platform Update Graph 工具来确定路径对您要升级到的 z-stream 版本是否有效。使用您的红帽大客户经理确认更新,以确保更新路径在电信实施中有效。
您升级到的 <4.y+1.z> 或 <4.y+2.z> 版本必须与您要更新的 <4.y.z> 版本相同。
OpenShift 更新过程要求在一个特定的 <4.y.z> 版本中存在修复,那么该修复必须存在于您升级到的 <4.y+1.z> 版本中。
图 16.1. 程序错误修复向后移植和更新图表
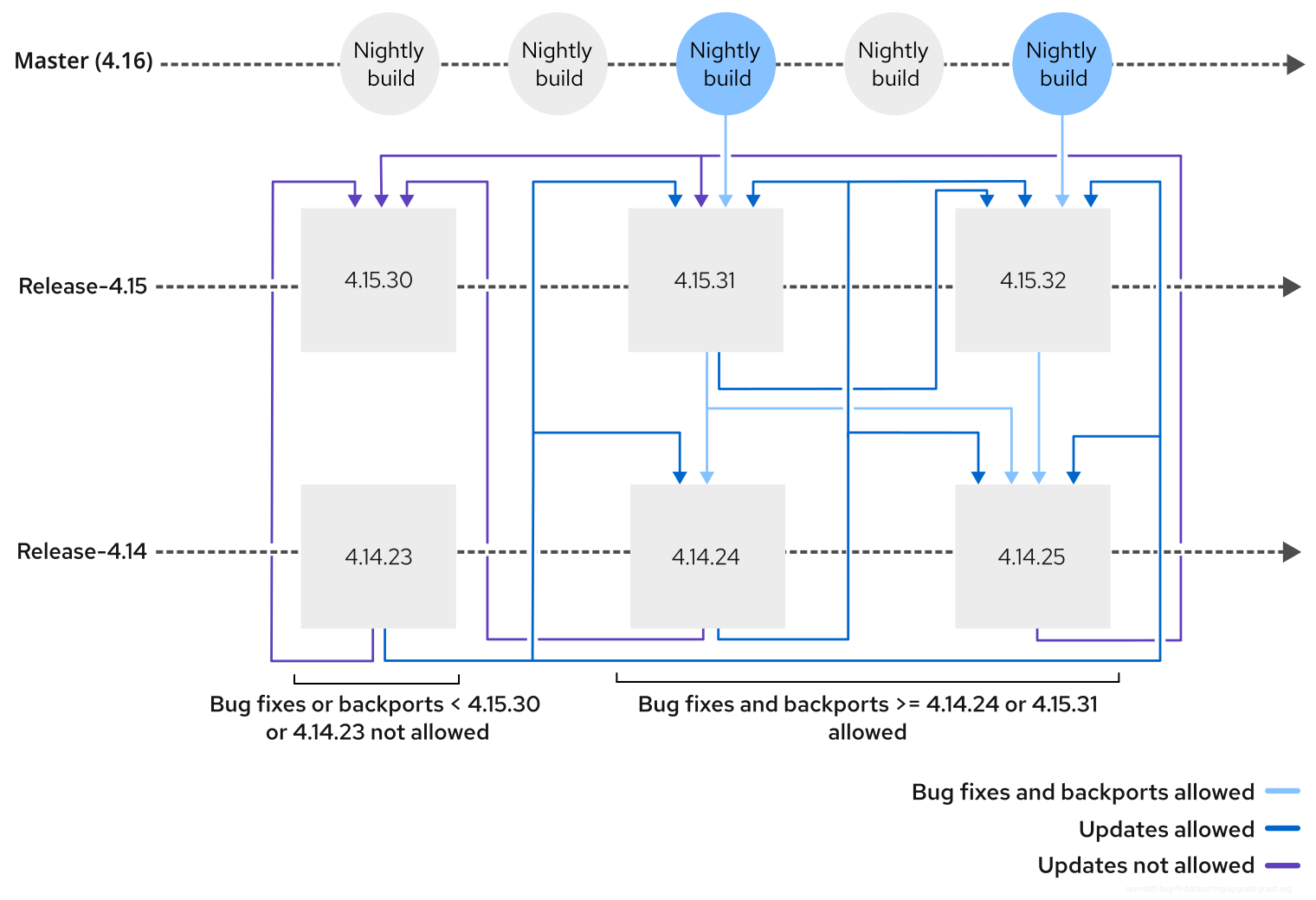
OpenShift 开发有一个严格的后向移植策略,可防止出现问题回归的问题。例如,在 4.16.z 中修复了一个程序错误,然后才能在 4.15.z 中修复。这意味着,更新图表不允许按时间更新,即使次版本更大,例如从 4.15.24 更新至 4.16.2。
16.1.2.3. 选择目标发行版本
使用 Red Hat OpenShift Container Platform Update Graph 或 cincinnati-graph-data 仓库来确定要升级到的版本。
16.1.2.3.1. 确定可用的 z-stream 更新
在升级到新的 z-stream 版本前,您需要了解可用的版本。
执行 z-stream 更新时不需要更改频道。
流程
确定哪些 z-stream 版本可用。运行以下命令:
$ oc adm upgrade输出示例
Cluster version is 4.14.34 Upstream is unset, so the cluster will use an appropriate default. Channel: stable-4.14 (available channels: candidate-4.14, candidate-4.15, eus-4.14, eus-4.16, fast-4.14, fast-4.15, stable-4.14, stable-4.15) Recommended updates: VERSION IMAGE 4.14.37 quay.io/openshift-release-dev/ocp-release@sha256:14e6ba3975e6c73b659fa55af25084b20ab38a543772ca70e184b903db73092b 4.14.36 quay.io/openshift-release-dev/ocp-release@sha256:4bc4925e8028158e3f313aa83e59e181c94d88b4aa82a3b00202d6f354e8dfed 4.14.35 quay.io/openshift-release-dev/ocp-release@sha256:883088e3e6efa7443b0ac28cd7682c2fdbda889b576edad626769bf956ac0858
16.1.2.3.2. 更改 Control Plane 更新的频道
您必须将频道改为 Control Plane Only 更新所需的版本。
执行 z-stream 更新时不需要更改频道。
流程
确定当前配置的更新频道:
$ oc get clusterversion -o=jsonpath='{.items[*].spec}' | jq输出示例
{ "channel": "stable-4.14", "clusterID": "01eb9a57-2bfb-4f50-9d37-dc04bd5bac75" }将频道更改为指向您要升级到的新频道:
$ oc adm upgrade channel eus-4.16确认更新频道:
$ oc get clusterversion -o=jsonpath='{.items[*].spec}' | jq输出示例
{ "channel": "eus-4.16", "clusterID": "01eb9a57-2bfb-4f50-9d37-dc04bd5bac75" }
16.1.2.3.2.1. 将一个早期 EUS 的频道改为 EUS 更新
到 OpenShift Container Platform 的新版本的更新路径在 EUS 频道或 stable 频道中不提供,直到次版本初始 GA 后 45 到 90 天。
要开始测试更新到新版本,您可以使用 fast 频道。
流程
将频道更改为
fast-<y+1>。例如,运行以下命令:$ oc adm upgrade channel fast-4.16检查新频道的升级路径。运行以下命令:
$ oc adm upgradeCluster version is 4.15.33 Upgradeable=False Reason: AdminAckRequired Message: Kubernetes 1.28 and therefore OpenShift 4.16 remove several APIs which require admin consideration. Please see the knowledge article https://access.redhat.com/articles/6958394 for details and instructions. Upstream is unset, so the cluster will use an appropriate default. Channel: fast-4.16 (available channels: candidate-4.15, candidate-4.16, eus-4.15, eus-4.16, fast-4.15, fast-4.16, stable-4.15, stable-4.16) Recommended updates: VERSION IMAGE 4.16.14 quay.io/openshift-release-dev/ocp-release@sha256:6618dd3c0f5 4.16.13 quay.io/openshift-release-dev/ocp-release@sha256:7a72abc3 4.16.12 quay.io/openshift-release-dev/ocp-release@sha256:1c8359fc2 4.16.11 quay.io/openshift-release-dev/ocp-release@sha256:bc9006febfe 4.16.10 quay.io/openshift-release-dev/ocp-release@sha256:dece7b61b1 4.15.36 quay.io/openshift-release-dev/ocp-release@sha256:c31a56d19 4.15.35 quay.io/openshift-release-dev/ocp-release@sha256:f21253 4.15.34 quay.io/openshift-release-dev/ocp-release@sha256:2dd69c5按照以下步骤进入 4.16 版本(<y+1> 来自版本 4.15)
注意即使使用 fast 频道,您可以在 EUS 版本之间保持 worker 节点暂停。
-
当您进入所需的 <y+1> 发行版本时,再次更改频道,这一次改为
fast-<y+2>。 - 按照 EUS 更新步骤获得所需的 <y+2> 版本。
16.1.2.3.3. 更改 y-stream 更新的频道
在 y-stream 更新中,您可以将频道改为下一个发行频道。
对于生产环境集群,请使用 stable 或 EUS 发行频道。
流程
更改更新频道:
$ oc adm upgrade channel stable-4.15检查新频道的升级路径。运行以下命令:
$ oc adm upgrade输出示例
Cluster version is 4.14.34 Upgradeable=False Reason: AdminAckRequired Message: Kubernetes 1.27 and therefore OpenShift 4.15 remove several APIs which require admin consideration. Please see the knowledge article https://access.redhat.com/articles/6958394 for details and instructions. Upstream is unset, so the cluster will use an appropriate default. Channel: stable-4.15 (available channels: candidate-4.14, candidate-4.15, eus-4.14, eus-4.15, fast-4.14, fast-4.15, stable-4.14, stable-4.15) Recommended updates: VERSION IMAGE 4.15.33 quay.io/openshift-release-dev/ocp-release@sha256:7142dd4b560 4.15.32 quay.io/openshift-release-dev/ocp-release@sha256:cda8ea5b13dc9 4.15.31 quay.io/openshift-release-dev/ocp-release@sha256:07cf61e67d3eeee 4.15.30 quay.io/openshift-release-dev/ocp-release@sha256:6618dd3c0f5 4.15.29 quay.io/openshift-release-dev/ocp-release@sha256:7a72abc3 4.15.28 quay.io/openshift-release-dev/ocp-release@sha256:1c8359fc2 4.15.27 quay.io/openshift-release-dev/ocp-release@sha256:bc9006febfe 4.15.26 quay.io/openshift-release-dev/ocp-release@sha256:dece7b61b1 4.14.38 quay.io/openshift-release-dev/ocp-release@sha256:c93914c62d7 4.14.37 quay.io/openshift-release-dev/ocp-release@sha256:c31a56d19 4.14.36 quay.io/openshift-release-dev/ocp-release@sha256:f21253 4.14.35 quay.io/openshift-release-dev/ocp-release@sha256:2dd69c5
16.1.3. 准备电信核心集群平台进行更新
通常,电信集群在裸机硬件上运行。通常,您必须更新固件以处理重要的安全修复、采用新功能或保持与 OpenShift Container Platform 的新版本的兼容性。
16.1.3.1. 确保主机固件与更新兼容
您需要在集群中运行的固件版本。更新主机固件不是 OpenShift Container Platform 更新过程的一部分。不建议将固件与 OpenShift Container Platform 版本一起更新。
硬件供应商建议最适合为您运行的特定硬件应用最新的认证固件版本。对于电信用例,请始终在测试环境中验证固件更新,然后再在生产环境中使用它们。电信 CNF 工作负载的高吞吐量性质可能会受到次优化主机固件的影响。
您应该全面测试新的固件更新,以确保它们与当前版本的 OpenShift Container Platform 正常工作。理想情况下,您可以使用目标 OpenShift Container Platform 更新版本测试最新的固件版本。
16.1.3.2. 确保分层产品与更新兼容
在开始更新前,验证所有层次产品是否在您升级到的 OpenShift Container Platform 版本上运行。这通常包括所有 Operator。
流程
验证集群中当前安装的 Operator。例如,运行以下命令:
$ oc get csv -A输出示例
NAMESPACE NAME DISPLAY VERSION REPLACES PHASE gitlab-operator-kubernetes.v0.17.2 GitLab 0.17.2 gitlab-operator-kubernetes.v0.17.1 Succeeded openshift-operator-lifecycle-manager packageserver Package Server 0.19.0 Succeeded检查您使用 OLM 安装的 Operator 是否与更新版本兼容。
使用 Operator Lifecycle Manager (OLM) 安装的 Operator 不是标准集群 Operator 集的一部分。
使用 Operator Update Information Checker 了解每个 y-stream 更新后是否需要更新 Operator,或者可以等到您完全更新至下一个 EUS 版本为止。
提示您还可以使用 Operator Update Information Checker 来查看哪些 OpenShift Container Platform 版本与 Operator 的特定发行版本兼容。
检查您在 OLM 外部安装的 Operator 是否与更新版本兼容。
对于所有不受红帽支持的 OLM 安装的 Operator,请联系 Operator 供应商以确保版本兼容性。
- 有些 Operator 与多个 OpenShift Container Platform 发行版本兼容。在完成集群更新后,您可能必须更新 Operator。如需更多信息,请参阅"更新 worker 节点"。
- 有关在执行第一个 y-stream control plane 更新后更新 Operator 的信息,请参阅"更新所有 OLM Operator"。
16.1.3.3. 在更新前将 MachineConfigPool 标签应用到节点
准备 MachineConfigPool (mcp) 节点标签,将节点分组到一组大约 8 到 10 个节点。使用 mcp 组,您可以独立于集群的其余部分重新引导一组节点。
您可以使用 mcp 节点标签在更新过程中暂停和取消暂停一组节点,以便在选择时执行更新和重新引导。
16.1.3.3.1. 交错集群更新
有时,更新过程中会出现问题。问题通常与需要重置的硬件故障或节点相关。使用 mcp 节点标签,您可以在关键时间暂停更新,在继续时跟踪暂停和取消暂停节点,以阶段更新节点。出现问题时,您可以使用处于 unpaused 状态的节点来确保有足够的节点运行,以保持所有应用 pod 都在运行。
16.1.3.3.2. 将 worker 节点划分为 MachineConfigPool 组
根据集群中多少个节点或分配给节点角色的节点数量,您可以将 worker 节点划分为 mcp 组。默认情况下,集群中的 2 个角色是 control plane 和 worker。
在运行电信工作负载的集群中,您可以在 CNF control plane 和 CNF data plane 角色之间进一步分割 worker 节点。添加将 worker 节点分成这两个组的 mcp 角色标签。
在 CNF control plane 角色中,大型集群可以有 100 个 worker 节点。无论集群中有多少个节点,请将每个 MachineConfigPool 组保留为大约 10 个节点。这可让您控制一次关闭多少个节点。使用多个 MachineConfigPool 组,您可以一次取消暂停多个组来加快更新,或者将更新与 2 个或更多维护窗口分开。
- 具有 15 个 worker 节点的集群示例
考虑有 15 个 worker 节点的集群:
- 10 个 worker 节点是 CNF control plane 节点。
- 5 个 worker 节点是 CNF data plane 节点。
将 CNF control plane 和 data plane worker 节点角色分成至少 2 个
mcp组。每个角色具有 2 个mcp组意味着您可以拥有一组不受更新影响的节点。- 带有 6 个 worker 节点的集群示例
考虑有 6 个 worker 节点的集群:
-
将 worker 节点分成 3 个
mcp组,每个节点都为 2 个。
升级其中一个
mcp组。在完成其他 4 节点上的更新前,允许更新的节点一天允许验证 CNF 兼容性。-
将 worker 节点分成 3 个
您取消暂停 mcp 组的进程和节奏由 CNF 应用程序和配置决定。
如果您的 CNF pod 可以跨集群中的节点调度,您可以一次取消暂停多个 mcp 组,并将 mcp 自定义资源 (CR) 中的 MaxUnavailable 设置为最高 50%。这允许 mcp 组中的一半节点重启和更新。
16.1.3.3.3. 查看配置的集群 MachineConfigPool 角色
查看集群中当前配置的 MachineConfigPool 角色。
流程
获取集群中当前配置的
mcp组:$ oc get mcp输出示例
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE master rendered-master-bere83 True False False 3 3 3 0 25d worker rendered-worker-245c4f True False False 2 2 2 0 25d将
mcp角色列表与集群中的节点列表进行比较:$ oc get nodes输出示例
NAME STATUS ROLES AGE VERSION ctrl-plane-0 Ready control-plane,master 39d v1.27.15+6147456 ctrl-plane-1 Ready control-plane,master 39d v1.27.15+6147456 ctrl-plane-2 Ready control-plane,master 39d v1.27.15+6147456 worker-0 Ready worker 39d v1.27.15+6147456 worker-1 Ready worker 39d v1.27.15+6147456注意当您应用
mcp组更改时,节点角色会被更新。决定如何将 worker 节点分开为
mcp组。
16.1.3.3.4. 为集群创建 MachineConfigPool 组
创建 mcp 组是一个两步的过程:
-
为集群中的节点添加一个
mcp标签 -
将
mcpCR 应用到集群,以根据其标签组织节点
流程
标记节点,以便它们可以被放入
mcp组中。运行以下命令:$ oc label node worker-0 node-role.kubernetes.io/mcp-1=$ oc label node worker-1 node-role.kubernetes.io/mcp-2=mcp-1和mcp-2标签应用到节点。例如:输出示例
NAME STATUS ROLES AGE VERSION ctrl-plane-0 Ready control-plane,master 39d v1.27.15+6147456 ctrl-plane-1 Ready control-plane,master 39d v1.27.15+6147456 ctrl-plane-2 Ready control-plane,master 39d v1.27.15+6147456 worker-0 Ready mcp-1,worker 39d v1.27.15+6147456 worker-1 Ready mcp-2,worker 39d v1.27.15+6147456创建 YAML 自定义资源 (CR),将标签作为
mcpCR 应用。将以下 YAML 保存到mcps.yaml文件中:--- apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfigPool metadata: name: mcp-2 spec: machineConfigSelector: matchExpressions: - { key: machineconfiguration.openshift.io/role, operator: In, values: [worker,mcp-2] } nodeSelector: matchLabels: node-role.kubernetes.io/mcp-2: "" --- apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfigPool metadata: name: mcp-1 spec: machineConfigSelector: matchExpressions: - { key: machineconfiguration.openshift.io/role, operator: In, values: [worker,mcp-1] } nodeSelector: matchLabels: node-role.kubernetes.io/mcp-1: ""创建
MachineConfigPool资源:$ oc apply -f mcps.yaml输出示例
machineconfigpool.machineconfiguration.openshift.io/mcp-2 created
验证
监控在集群中应用 MachineConfigPool 资源。应用 mcp 资源后,节点将添加到新机器配置池中。这需要几分钟时间。
当添加到 mcp 组时,节点不会重启。原始 worker 和 master mcp 组保持不变。
检查新
mcp资源的状态:$ oc get mcp输出示例
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE master rendered-master-be3e83 True False False 3 3 3 0 25d mcp-1 rendered-mcp-1-2f4c4f False True True 1 0 0 0 10s mcp-2 rendered-mcp-2-2r4s1f False True True 1 0 0 0 10s worker rendered-worker-23fc4f False True True 0 0 0 2 25d最终,资源会被完全应用:
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE master rendered-master-be3e83 True False False 3 3 3 0 25d mcp-1 rendered-mcp-1-2f4c4f True False False 1 1 1 0 7m33s mcp-2 rendered-mcp-2-2r4s1f True False False 1 1 1 0 51s worker rendered-worker-23fc4f True False False 0 0 0 0 25d
16.1.3.4. 电信部署环境注意事项
在电信环境中,大多数集群都处于断开连接的网络中。要在这些环境中更新集群,您必须更新离线镜像仓库。
16.1.3.5. 准备集群平台进行更新
在更新集群之前,执行一些基本检查和验证,以确保集群已准备好更新。
流程
运行以下命令,确认集群中没有失败或仍在处理中的 pod:
$ oc get pods -A | grep -E -vi 'complete|running'注意如果有处于待处理状态的 pod,您可能需要多次运行此命令。
验证集群中的所有节点是否可用:
$ oc get nodes输出示例
NAME STATUS ROLES AGE VERSION ctrl-plane-0 Ready control-plane,master 32d v1.27.15+6147456 ctrl-plane-1 Ready control-plane,master 32d v1.27.15+6147456 ctrl-plane-2 Ready control-plane,master 32d v1.27.15+6147456 worker-0 Ready mcp-1,worker 32d v1.27.15+6147456 worker-1 Ready mcp-2,worker 32d v1.27.15+6147456验证所有裸机节点是否已置备并就绪。
$ oc get bmh -n openshift-machine-api输出示例
NAME STATE CONSUMER ONLINE ERROR AGE ctrl-plane-0 unmanaged cnf-58879-master-0 true 33d ctrl-plane-1 unmanaged cnf-58879-master-1 true 33d ctrl-plane-2 unmanaged cnf-58879-master-2 true 33d worker-0 unmanaged cnf-58879-worker-0-45879 true 33d worker-1 progressing cnf-58879-worker-0-dszsh false 1d1 - 1
- 置备
worker-1节点时出错。
验证
验证所有集群 Operator 是否都已就绪:
$ oc get co输出示例
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE authentication 4.14.34 True False False 17h baremetal 4.14.34 True False False 32d ... service-ca 4.14.34 True False False 32d storage 4.14.34 True False False 32d
16.1.4. 在更新电信核心 CNF 集群前配置 CNF pod
在开发云原生网络功能 (CNF) 时,遵循红帽最佳实践 Kubernetes 的指导,以确保集群可以在更新期间调度 pod。
始终使用 Deployment 资源在组中部署 pod。部署资源将工作负载分散到所有可用的 pod 中,确保没有单点故障。当删除由 Deployment 资源管理的 pod 时,新 pod 会自动获取它。
16.1.4.1. 确保 CNF 工作负载与 pod 中断预算不间断
您可以通过在您应用的 PodDisruptionBudget 自定义资源 (CR) 中设置 pod 中断预算,在部署中配置最少的 pod 中断预算来允许 CNF 工作负载运行不间。设置此值时要小心;不当设置它可能会导致更新失败。
例如,如果您在部署中有 4 个 pod,并将 pod 中断预算设置为 4,集群调度程序会始终保持 4 个 pod 运行 - 无法缩减 pod。
相反,将 pod 中断预算设置为 2,让 2 个 pod 调度为 down。然后,可以重启这些 pod 的 worker 节点。
将 pod 中断预算设置为 2 并不意味着,您的部署在一段时间内仅在 2 个 pod 上运行,例如在更新过程中。集群调度程序创建 2 个新 pod 来替换 2 个旧的 pod。但是,新 pod 在线和旧 pod 被删除之间有短暂的时间差。
16.1.4.2. 确保 pod 不在同一集群节点上运行
Kubernetes 的高可用性要求在集群的独立节点上运行重复的进程。这样可确保即使一个节点不可用,应用程序也会继续运行。在 OpenShift Container Platform 中,进程可以在部署中的独立 pod 中自动重复。您可以在 Pod spec 中配置反关联性,以确保部署中的 pod 不在同一集群节点上运行。
在更新过程中,设置 pod 反关联性可确保在集群节点间平均分配 pod。这意味着节点在更新过程中可以更轻松地重启。例如,如果节点上的单个部署中有 4 个 pod,并且将 pod 中断预算设置为只允许 1 个 pod 一次删除,那么该节点需要 4 次才能重新引导该节点。设置 pod 反关联性将 pod 分散到集群中,以防止出现这样的发生。
16.1.4.3. 应用程序存活度、就绪度和启动探测
在调度更新前,您可以使用存活度、就绪度和启动探测来检查实时应用容器的健康状态。这些是非常有用的工具,用于依赖于为其应用程序容器保持状态的 pod。
- 存活度健康检查
- 确定容器是否在运行。如果容器的存活度探测失败,则 pod 根据重启策略进行响应。
- 就绪度探测
- 确定容器是否准备好接受服务请求。如果容器的就绪度探测失败,kubelet 会从可用服务端点列表中删除容器。
- 启动探测
-
启动探测(startup probe)指示容器内的应用程序是否启动。其它所有探测在启动成功前被禁用。如果启动探测不成功,kubelet 会终止容器,容器会受 pod
restartPolicy设置的影响。
16.1.5. 在更新电信核心 CNF 集群前
在开始集群更新前,您必须暂停 worker 节点,备份 etcd 数据库,并在继续操作前进行最终的集群健康检查。
16.1.5.1. 在更新前暂停 worker 节点
在进行更新前,您必须暂停 worker 节点。在以下示例中,有 2 个 mcp 组:mcp-1 和 mcp-2。对于每个 MachineConfigPool 组,您可以将 spec.paused 字段设置为 true。
流程
运行以下命令来修补
mcpCR,以暂停节点并排空并从这些节点中删除 pod:$ oc patch mcp/mcp-1 --type merge --patch '{"spec":{"paused":true}}'$ oc patch mcp/mcp-2 --type merge --patch '{"spec":{"paused":true}}'获取暂停的
mcp组的状态:$ oc get mcp -o json | jq -r '["MCP","Paused"], ["---","------"], (.items[] | [(.metadata.name), (.spec.paused)]) | @tsv' | grep -v worker输出示例
MCP Paused --- ------ master false mcp-1 true mcp-2 true
在更新过程中,默认的 control plane 和 worker mcp 组不会改变。
16.1.5.2. 在进行更新前备份 etcd 数据库
在进行更新前,您必须备份 etcd 数据库。
16.1.5.2.1. 备份 etcd 数据
按照以下步骤,通过创建 etcd 快照并备份静态 pod 的资源来备份 etcd 数据。这个备份可以被保存,并在以后需要时使用它来恢复 etcd 数据。
只保存单一 control plane 主机的备份。不要从集群中的每个 control plane 主机进行备份。
先决条件
-
您可以使用具有
cluster-admin角色的用户访问集群。 您已检查是否启用了集群范围代理。
提示您可以通过查看
oc get proxy cluster -o yaml的输出来检查代理是否已启用。如果httpProxy、httpsProxy和noProxy字段设置了值,则会启用代理。
流程
以 root 用户身份为 control plane 节点启动一个 debug 会话:
$ oc debug --as-root node/<node_name>在 debug shell 中将根目录改为
/host:sh-4.4# chroot /host如果启用了集群范围代理,请运行以下命令导出
NO_PROXY、HTTP_PROXY和HTTPS_PROXY环境变量:$ export HTTP_PROXY=http://<your_proxy.example.com>:8080$ export HTTPS_PROXY=https://<your_proxy.example.com>:8080$ export NO_PROXY=<example.com>在 debug shell 中运行
cluster-backup.sh脚本,并传递保存备份的位置。提示cluster-backup.sh脚本作为 etcd Cluster Operator 的一个组件被维护,它是etcdctl snapshot save命令的包装程序(wrapper)。sh-4.4# /usr/local/bin/cluster-backup.sh /home/core/assets/backup脚本输出示例
found latest kube-apiserver: /etc/kubernetes/static-pod-resources/kube-apiserver-pod-6 found latest kube-controller-manager: /etc/kubernetes/static-pod-resources/kube-controller-manager-pod-7 found latest kube-scheduler: /etc/kubernetes/static-pod-resources/kube-scheduler-pod-6 found latest etcd: /etc/kubernetes/static-pod-resources/etcd-pod-3 ede95fe6b88b87ba86a03c15e669fb4aa5bf0991c180d3c6895ce72eaade54a1 etcdctl version: 3.4.14 API version: 3.4 {"level":"info","ts":1624647639.0188997,"caller":"snapshot/v3_snapshot.go:119","msg":"created temporary db file","path":"/home/core/assets/backup/snapshot_2021-06-25_190035.db.part"} {"level":"info","ts":"2021-06-25T19:00:39.030Z","caller":"clientv3/maintenance.go:200","msg":"opened snapshot stream; downloading"} {"level":"info","ts":1624647639.0301006,"caller":"snapshot/v3_snapshot.go:127","msg":"fetching snapshot","endpoint":"https://10.0.0.5:2379"} {"level":"info","ts":"2021-06-25T19:00:40.215Z","caller":"clientv3/maintenance.go:208","msg":"completed snapshot read; closing"} {"level":"info","ts":1624647640.6032252,"caller":"snapshot/v3_snapshot.go:142","msg":"fetched snapshot","endpoint":"https://10.0.0.5:2379","size":"114 MB","took":1.584090459} {"level":"info","ts":1624647640.6047094,"caller":"snapshot/v3_snapshot.go:152","msg":"saved","path":"/home/core/assets/backup/snapshot_2021-06-25_190035.db"} Snapshot saved at /home/core/assets/backup/snapshot_2021-06-25_190035.db {"hash":3866667823,"revision":31407,"totalKey":12828,"totalSize":114446336} snapshot db and kube resources are successfully saved to /home/core/assets/backup在这个示例中,在 control plane 主机上的
/home/core/assets/backup/目录中创建了两个文件:-
snapshot_<datetimestamp>.db:这个文件是 etcd 快照。cluster-backup.sh脚本确认其有效。 static_kuberesources_<datetimestamp>.tar.gz:此文件包含静态 pod 的资源。如果启用了 etcd 加密,它也包含 etcd 快照的加密密钥。注意如果启用了 etcd 加密,建议出于安全考虑,将第二个文件与 etcd 快照分开保存。但是,需要这个文件才能从 etcd 快照中进行恢复。
请记住,etcd 仅对值进行加密,而不对键进行加密。这意味着资源类型、命名空间和对象名称是不加密的。
-
16.1.5.2.2. 创建单个 etcd 备份
按照以下步骤,通过创建并应用自定义资源 (CR) 来创建单个 etcd 备份。
先决条件
-
您可以使用具有
cluster-admin角色的用户访问集群。 -
您可以访问 OpenShift CLI(
oc)。
流程
如果动态置备的存储可用,请完成以下步骤以创建单个自动 etcd 备份:
创建名为
etcd-backup-pvc.yaml的持久性卷声明 (PVC),其内容如下:kind: PersistentVolumeClaim apiVersion: v1 metadata: name: etcd-backup-pvc namespace: openshift-etcd spec: accessModes: - ReadWriteOnce resources: requests: storage: 200Gi1 volumeMode: Filesystem- 1
- PVC 可用的存储量。根据您的要求调整这个值。
运行以下命令来应用 PVC:
$ oc apply -f etcd-backup-pvc.yaml运行以下命令验证 PVC 的创建:
$ oc get pvc输出示例
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE etcd-backup-pvc Bound 51s注意动态 PVC 处于
Pending状态,直到它们被挂载为止。创建名为
etcd-single-backup.yaml的 CR 文件,其内容如下:apiVersion: operator.openshift.io/v1alpha1 kind: EtcdBackup metadata: name: etcd-single-backup namespace: openshift-etcd spec: pvcName: etcd-backup-pvc1 - 1
- 保存备份的 PVC 名称。根据您的环境调整这个值。
应用 CR 以启动单个备份:
$ oc apply -f etcd-single-backup.yaml
如果动态置备的存储不可用,请完成以下步骤来创建单个自动 etcd 备份:
创建名为
etcd-backup-local-storage.yaml的StorageClassCR 文件,其内容如下:apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: etcd-backup-local-storage provisioner: kubernetes.io/no-provisioner volumeBindingMode: Immediate运行以下命令来应用
StorageClassCR:$ oc apply -f etcd-backup-local-storage.yaml创建名为
etcd-backup-pv-fs.yaml的 PV,其内容类似以下示例:apiVersion: v1 kind: PersistentVolume metadata: name: etcd-backup-pv-fs spec: capacity: storage: 100Gi1 volumeMode: Filesystem accessModes: - ReadWriteOnce persistentVolumeReclaimPolicy: Retain storageClassName: etcd-backup-local-storage local: path: /mnt nodeAffinity: required: nodeSelectorTerms: - matchExpressions: - key: kubernetes.io/hostname operator: In values: - <example_master_node>2 运行以下命令验证 PV 的创建:
$ oc get pv输出示例
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE etcd-backup-pv-fs 100Gi RWO Retain Available etcd-backup-local-storage 10s创建名为
etcd-backup-pvc.yaml的 PVC,其内容如下:kind: PersistentVolumeClaim apiVersion: v1 metadata: name: etcd-backup-pvc namespace: openshift-etcd spec: accessModes: - ReadWriteOnce volumeMode: Filesystem resources: requests: storage: 10Gi1 - 1
- PVC 可用的存储量。根据您的要求调整这个值。
运行以下命令来应用 PVC:
$ oc apply -f etcd-backup-pvc.yaml创建名为
etcd-single-backup.yaml的 CR 文件,其内容如下:apiVersion: operator.openshift.io/v1alpha1 kind: EtcdBackup metadata: name: etcd-single-backup namespace: openshift-etcd spec: pvcName: etcd-backup-pvc1 - 1
- 将备份保存到的持久性卷声明 (PVC) 的名称。根据您的环境调整这个值。
应用 CR 以启动单个备份:
$ oc apply -f etcd-single-backup.yaml
16.1.5.3. 检查集群健康状况
您应该在更新过程中经常检查集群健康状况。检查节点状态、集群 Operator 状态和失败的 pod。
流程
运行以下命令,检查集群 Operator 的状态:
$ oc get co输出示例
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE authentication 4.14.34 True False False 4d22h baremetal 4.14.34 True False False 4d22h cloud-controller-manager 4.14.34 True False False 4d23h cloud-credential 4.14.34 True False False 4d23h cluster-autoscaler 4.14.34 True False False 4d22h config-operator 4.14.34 True False False 4d22h console 4.14.34 True False False 4d22h ... service-ca 4.14.34 True False False 4d22h storage 4.14.34 True False False 4d22h检查集群节点的状态:
$ oc get nodes输出示例
NAME STATUS ROLES AGE VERSION ctrl-plane-0 Ready control-plane,master 4d22h v1.27.15+6147456 ctrl-plane-1 Ready control-plane,master 4d22h v1.27.15+6147456 ctrl-plane-2 Ready control-plane,master 4d22h v1.27.15+6147456 worker-0 Ready mcp-1,worker 4d22h v1.27.15+6147456 worker-1 Ready mcp-2,worker 4d22h v1.27.15+6147456检查没有处于进行中的 pod 或失败的 pod。运行以下命令时,不应返回任何 pod。
$ oc get po -A | grep -E -iv 'running|complete'
16.1.6. 完成 Control Plane Only 集群更新
按照以下步骤执行 Control Plane Only 集群更新,并监控更新完成。
Control Plane Only 更新以前被称为 EUS 到 EUS 更新。Control Plane Only 更新只能在偶数的 OpenShift Container Platform 次版本之间进行。
16.1.6.1. 确认 Control Plane Only 或 y-stream 更新
当您从 4.11 及更新版本升级到所有版本时,您必须手动确认更新可以继续。
在确认更新前,请验证您要升级到的版本中删除了使用中的 Kubernetes API。例如,在 OpenShift Container Platform 4.17 中,没有删除 API。如需更多信息,请参阅"Kubernetes API 删除"。
流程
运行以下命令:
$ oc -n openshift-config patch cm admin-acks --patch '{"data":{"ack-<update_version_from>-kube-<kube_api_version>-api-removals-in-<update_version_to>":"true"}}' --type=merge其中:
- <update_version_from>
-
是您要从中移出的集群版本,如
4.14。 - <kube_api_version>
-
是 kube API 版本,如
1.28。 - <update_version_to>
-
是您要移到的集群版本,如
4.15。
验证
验证更新。运行以下命令:
$ oc get configmap admin-acks -n openshift-config -o json | jq .data输出示例
{ "ack-4.14-kube-1.28-api-removals-in-4.15": "true", "ack-4.15-kube-1.29-api-removals-in-4.16": "true" }注意在本例中,集群从 4.14 版本更新至 4.15,然后在 Control Plane 中从 4.15 更新至 4.16。
16.1.6.2. 启动集群更新
当从一个 y-stream 版本升级到下一个版本时,您必须确保中间 z-stream 版本也兼容。
您可以通过运行 oc adm upgrade 命令来验证您要升级到一个可行的发行版本。oc adm upgrade 命令列出兼容的更新版本。
流程
启动更新:
$ oc adm upgrade --to=4.15.33重要- Control Plane Only update: 请确定您指向 interim <y+1> 发行路径
- y-stream update - 确保使用正确的 <y.z> 发行版本,遵循 Kubernetes version skew 策略。
- z-stream update - 验证没有迁移到该特定版本的问题
输出示例
Requested update to 4.15.331 - 1
Requested update值会根据您的具体更新而改变。
16.1.6.3. 监控集群更新
您应该在更新过程中经常检查集群健康状况。检查节点状态、集群 Operator 状态和失败的 pod。
流程
监控集群更新。例如,要监控从 4.14 版本到 4.15 的集群更新,请运行以下命令:
$ watch "oc get clusterversion; echo; oc get co | head -1; oc get co | grep 4.14; oc get co | grep 4.15; echo; oc get no; echo; oc get po -A | grep -E -iv 'running|complete'"输出示例
NAME VERSION AVAILABLE PROGRESSING SINCE STATUS version 4.14.34 True True 4m6s Working towards 4.15.33: 111 of 873 done (12% complete), waiting on kube-apiserver NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE authentication 4.14.34 True False False 4d22h baremetal 4.14.34 True False False 4d23h cloud-controller-manager 4.14.34 True False False 4d23h cloud-credential 4.14.34 True False False 4d23h cluster-autoscaler 4.14.34 True False False 4d23h console 4.14.34 True False False 4d22h ... storage 4.14.34 True False False 4d23h config-operator 4.15.33 True False False 4d23h etcd 4.15.33 True False False 4d23h NAME STATUS ROLES AGE VERSION ctrl-plane-0 Ready control-plane,master 4d23h v1.27.15+6147456 ctrl-plane-1 Ready control-plane,master 4d23h v1.27.15+6147456 ctrl-plane-2 Ready control-plane,master 4d23h v1.27.15+6147456 worker-0 Ready mcp-1,worker 4d23h v1.27.15+6147456 worker-1 Ready mcp-2,worker 4d23h v1.27.15+6147456 NAMESPACE NAME READY STATUS RESTARTS AGE openshift-marketplace redhat-marketplace-rf86t 0/1 ContainerCreating 0 0s
验证
在更新 watch 命令期间,一次通过一个或多个集群 Operator 周期,在 MESSAGE 列中提供 Operator 更新状态。
当集群 Operator 更新过程完成后,每个 control plane 节点都会重启,一次重启一个。
在更新过程中,会报告状态集群 Operator 被再次更新或处于降级状态的信息。这是因为 control plane 节点在重新引导节点时处于离线状态。
完成上次 control plane 节点重新引导后,将会在更新时显示集群版本。
当 control plane 更新完成后会显示如下信息。本例演示了在中间 y-stream 版本完成的更新。
NAME VERSION AVAILABLE PROGRESSING SINCE STATUS
version 4.15.33 True False 28m Cluster version is 4.15.33
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE
authentication 4.15.33 True False False 5d
baremetal 4.15.33 True False False 5d
cloud-controller-manager 4.15.33 True False False 5d1h
cloud-credential 4.15.33 True False False 5d1h
cluster-autoscaler 4.15.33 True False False 5d
config-operator 4.15.33 True False False 5d
console 4.15.33 True False False 5d
...
service-ca 4.15.33 True False False 5d
storage 4.15.33 True False False 5d
NAME STATUS ROLES AGE VERSION
ctrl-plane-0 Ready control-plane,master 5d v1.28.13+2ca1a23
ctrl-plane-1 Ready control-plane,master 5d v1.28.13+2ca1a23
ctrl-plane-2 Ready control-plane,master 5d v1.28.13+2ca1a23
worker-0 Ready mcp-1,worker 5d v1.28.13+2ca1a23
worker-1 Ready mcp-2,worker 5d v1.28.13+2ca1a2316.1.6.4. 更新 OLM Operator
在电信环境中,软件需要在加载到生产环境集群之前进行检查。生产环境集群也在断开连接的网络中配置,这意味着它们并不总是直接连接到互联网。由于集群位于断开连接的网络中,所以 OpenShift Operator 会在安装过程中进行手动更新,以便可以以集群为基础管理新版本。执行以下步骤将 Operator 移到更新的版本中。
流程
检查需要更新哪些 Operator:
$ oc get installplan -A | grep -E 'APPROVED|false'输出示例
NAMESPACE NAME CSV APPROVAL APPROVED metallb-system install-nwjnh metallb-operator.v4.16.0-202409202304 Manual false openshift-nmstate install-5r7wr kubernetes-nmstate-operator.4.16.0-202409251605 Manual false为这些 Operator 修补
InstallPlan资源:$ oc patch installplan -n metallb-system install-nwjnh --type merge --patch \ '{"spec":{"approved":true}}'输出示例
installplan.operators.coreos.com/install-nwjnh patched运行以下命令来监控命名空间:
$ oc get all -n metallb-system输出示例
NAME READY STATUS RESTARTS AGE pod/metallb-operator-controller-manager-69b5f884c-8bp22 0/1 ContainerCreating 0 4s pod/metallb-operator-controller-manager-77895bdb46-bqjdx 1/1 Running 0 4m1s pod/metallb-operator-webhook-server-5d9b968896-vnbhk 0/1 ContainerCreating 0 4s pod/metallb-operator-webhook-server-d76f9c6c8-57r4w 1/1 Running 0 4m1s ... NAME DESIRED CURRENT READY AGE replicaset.apps/metallb-operator-controller-manager-69b5f884c 1 1 0 4s replicaset.apps/metallb-operator-controller-manager-77895bdb46 1 1 1 4m1s replicaset.apps/metallb-operator-controller-manager-99b76f88 0 0 0 4m40s replicaset.apps/metallb-operator-webhook-server-5d9b968896 1 1 0 4s replicaset.apps/metallb-operator-webhook-server-6f7dbfdb88 0 0 0 4m40s replicaset.apps/metallb-operator-webhook-server-d76f9c6c8 1 1 1 4m1s更新完成后,所需的 pod 应该处于
Running状态,所需的ReplicaSet资源应就绪:NAME READY STATUS RESTARTS AGE pod/metallb-operator-controller-manager-69b5f884c-8bp22 1/1 Running 0 25s pod/metallb-operator-webhook-server-5d9b968896-vnbhk 1/1 Running 0 25s ... NAME DESIRED CURRENT READY AGE replicaset.apps/metallb-operator-controller-manager-69b5f884c 1 1 1 25s replicaset.apps/metallb-operator-controller-manager-77895bdb46 0 0 0 4m22s replicaset.apps/metallb-operator-webhook-server-5d9b968896 1 1 1 25s replicaset.apps/metallb-operator-webhook-server-d76f9c6c8 0 0 0 4m22s
验证
验证 Operator 不需要第二次更新:
$ oc get installplan -A | grep -E 'APPROVED|false'应该不会返回任何输出。
注意有时您需要批准更新两次,因为有些 Operator 在最终版本之前有需要安装的 z-stream 版本。
16.1.6.4.1. 执行第二个 y-stream 更新
完成第一个 y-stream 更新后,您必须将 y-stream control plane 版本更新至新的 EUS 版本。
流程
验证您选择的 <4.y.z> 发行版本是否仍然被列为要移至的良好频道:
$ oc adm upgrade输出示例
Cluster version is 4.15.33 Upgradeable=False Reason: AdminAckRequired Message: Kubernetes 1.29 and therefore OpenShift 4.16 remove several APIs which require admin consideration. Please see the knowledge article https://access.redhat.com/articles/7031404 for details and instructions. Upstream is unset, so the cluster will use an appropriate default. Channel: eus-4.16 (available channels: candidate-4.15, candidate-4.16, eus-4.16, fast-4.15, fast-4.16, stable-4.15, stable-4.16) Recommended updates: VERSION IMAGE 4.16.14 quay.io/openshift-release-dev/ocp-release@sha256:0521a0f1acd2d1b77f76259cb9bae9c743c60c37d9903806a3372c1414253658 4.16.13 quay.io/openshift-release-dev/ocp-release@sha256:6078cb4ae197b5b0c526910363b8aff540343bfac62ecb1ead9e068d541da27b 4.15.34 quay.io/openshift-release-dev/ocp-release@sha256:f2e0c593f6ed81250c11d0bac94dbaf63656223477b7e8693a652f933056af6e注意如果在新的 Y-stream 版本初始 GA 后马上更新,则在运行
oc adm upgrade命令时可能无法看到新的 y-stream 版本。可选:查看不推荐的、潜在的更新版本。运行以下命令:
$ oc adm upgrade --include-not-recommended输出示例
Cluster version is 4.15.33 Upgradeable=False Reason: AdminAckRequired Message: Kubernetes 1.29 and therefore OpenShift 4.16 remove several APIs which require admin consideration. Please see the knowledge article https://access.redhat.com/articles/7031404 for details and instructions. Upstream is unset, so the cluster will use an appropriate default.Channel: eus-4.16 (available channels: candidate-4.15, candidate-4.16, eus-4.16, fast-4.15, fast-4.16, stable-4.15, stable-4.16) Recommended updates: VERSION IMAGE 4.16.14 quay.io/openshift-release-dev/ocp-release@sha256:0521a0f1acd2d1b77f76259cb9bae9c743c60c37d9903806a3372c1414253658 4.16.13 quay.io/openshift-release-dev/ocp-release@sha256:6078cb4ae197b5b0c526910363b8aff540343bfac62ecb1ead9e068d541da27b 4.15.34 quay.io/openshift-release-dev/ocp-release@sha256:f2e0c593f6ed81250c11d0bac94dbaf63656223477b7e8693a652f933056af6e Supported but not recommended updates: Version: 4.16.15 Image: quay.io/openshift-release-dev/ocp-release@sha256:671bc35e Recommended: Unknown Reason: EvaluationFailed Message: Exposure to AzureRegistryImagePreservation is unknown due to an evaluation failure: invalid PromQL result length must be one, but is 0 In Azure clusters, the in-cluster image registry may fail to preserve images on update. https://issues.redhat.com/browse/IR-461注意示例显示了可能会影响 Microsoft Azure 中托管的集群的潜在错误。它不会显示裸机集群的风险。
16.1.6.4.2. 确认 y-stream 版本更新
在 y-stream 版本间进行移动时,您必须运行一个 patch 命令来明确确认更新。在 oc adm upgrade 命令的输出中,提供了一个 URL,它显示了要运行的特定命令。
在确认更新前,请验证您要升级到的版本中删除了使用中的 Kubernetes API。例如,在 OpenShift Container Platform 4.17 中,没有删除 API。如需更多信息,请参阅"Kubernetes API 删除"。
流程
通过在
openshift-config命名空间中修补admin-acks配置映射来确认 y-stream 版本升级。例如,运行以下命令:$ oc -n openshift-config patch cm admin-acks --patch '{"data":{"ack-4.15-kube-1.29-api-removals-in-4.16":"true"}}' --type=merge输出示例
configmap/admin-acks patched
16.1.6.5. 启动 y-stream control plane 更新
确定您要移至的完整新版本后,您可以运行 oc adm upgrade -to=x.y.z 命令。
流程
启动 y-stream control plane 更新。例如,运行以下命令:
$ oc adm upgrade --to=4.16.14输出示例
Requested update to 4.16.14您可能会迁移到一个 z-stream 版本,该版本可能遇到与运行平台以外的平台的潜在问题。以下示例显示了 Microsoft Azure 上集群更新的潜在问题:
$ oc adm upgrade --to=4.16.15输出示例
error: the update 4.16.15 is not one of the recommended updates, but is available as a conditional update. To accept the Recommended=Unknown risk and to proceed with update use --allow-not-recommended. Reason: EvaluationFailed Message: Exposure to AzureRegistryImagePreservation is unknown due to an evaluation failure: invalid PromQL result length must be one, but is 0 In Azure clusters, the in-cluster image registry may fail to preserve images on update. https://issues.redhat.com/browse/IR-461注意示例显示了可能会影响 Microsoft Azure 中托管的集群的潜在错误。它不会显示裸机集群的风险。
$ oc adm upgrade --to=4.16.15 --allow-not-recommended输出示例
warning: with --allow-not-recommended you have accepted the risks with 4.14.11 and bypassed Recommended=Unknown EvaluationFailed: Exposure to AzureRegistryImagePreservation is unknown due to an evaluation failure: invalid PromQL result length must be one, but is 0 In Azure clusters, the in-cluster image registry may fail to preserve images on update. https://issues.redhat.com/browse/IR-461 Requested update to 4.16.15
16.1.6.6. 监控 集群更新的第二个部分
监控集群的第二个部分更新到 <y+1> 版本。
流程
监控 <y+1> 更新的第二个部分的进度。例如,要监控从 4.15 到 4.16 的更新,请运行以下命令:
$ watch "oc get clusterversion; echo; oc get co | head -1; oc get co | grep 4.15; oc get co | grep 4.16; echo; oc get no; echo; oc get po -A | grep -E -iv 'running|complete'"输出示例
NAME VERSION AVAILABLE PROGRESSING SINCE STATUS version 4.15.33 True True 10m Working towards 4.16.14: 132 of 903 done (14% complete), waiting on kube-controller-manager, kube-scheduler NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE authentication 4.15.33 True False False 5d3h baremetal 4.15.33 True False False 5d4h cloud-controller-manager 4.15.33 True False False 5d4h cloud-credential 4.15.33 True False False 5d4h cluster-autoscaler 4.15.33 True False False 5d4h console 4.15.33 True False False 5d3h ... config-operator 4.16.14 True False False 5d4h etcd 4.16.14 True False False 5d4h kube-apiserver 4.16.14 True True False 5d4h NodeInstallerProgressing: 1 node is at revision 15; 2 nodes are at revision 17 NAME STATUS ROLES AGE VERSION ctrl-plane-0 Ready control-plane,master 5d4h v1.28.13+2ca1a23 ctrl-plane-1 Ready control-plane,master 5d4h v1.28.13+2ca1a23 ctrl-plane-2 Ready control-plane,master 5d4h v1.28.13+2ca1a23 worker-0 Ready mcp-1,worker 5d4h v1.27.15+6147456 worker-1 Ready mcp-2,worker 5d4h v1.27.15+6147456 NAMESPACE NAME READY STATUS RESTARTS AGE openshift-kube-apiserver kube-apiserver-ctrl-plane-0 0/5 Pending 0 <invalid>完成最后一个 control plane 节点后,集群版本会更新至新的 EUS 版本。例如:
NAME VERSION AVAILABLE PROGRESSING SINCE STATUS version 4.16.14 True False 123m Cluster version is 4.16.14 NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE authentication 4.16.14 True False False 5d6h baremetal 4.16.14 True False False 5d7h cloud-controller-manager 4.16.14 True False False 5d7h cloud-credential 4.16.14 True False False 5d7h cluster-autoscaler 4.16.14 True False False 5d7h config-operator 4.16.14 True False False 5d7h console 4.16.14 True False False 5d6h #... operator-lifecycle-manager-packageserver 4.16.14 True False False 5d7h service-ca 4.16.14 True False False 5d7h storage 4.16.14 True False False 5d7h NAME STATUS ROLES AGE VERSION ctrl-plane-0 Ready control-plane,master 5d7h v1.29.8+f10c92d ctrl-plane-1 Ready control-plane,master 5d7h v1.29.8+f10c92d ctrl-plane-2 Ready control-plane,master 5d7h v1.29.8+f10c92d worker-0 Ready mcp-1,worker 5d7h v1.27.15+6147456 worker-1 Ready mcp-2,worker 5d7h v1.27.15+6147456
16.1.6.7. 更新所有 OLM Operator
在多版本升级的第二阶段中,您必须批准所有 Operator,并为您要升级的任何其他 Operator 添加安装计划。
按照"更新 OLM Operator"中所述的步骤操作。确保您还根据需要更新任何非 OLM Operator。
流程
监控集群更新。例如,要监控从 4.14 版本到 4.15 的集群更新,请运行以下命令:
$ watch "oc get clusterversion; echo; oc get co | head -1; oc get co | grep 4.14; oc get co | grep 4.15; echo; oc get no; echo; oc get po -A | grep -E -iv 'running|complete'"检查需要更新哪些 Operator:
$ oc get installplan -A | grep -E 'APPROVED|false'为这些 Operator 修补
InstallPlan资源:$ oc patch installplan -n metallb-system install-nwjnh --type merge --patch \ '{"spec":{"approved":true}}'运行以下命令来监控命名空间:
$ oc get all -n metallb-system更新完成后,所需的 pod 应处于
Running状态,并且所需的ReplicaSet资源应就绪。
验证
在更新 watch 命令期间,一次通过一个或多个集群 Operator 周期,在 MESSAGE 列中提供 Operator 更新状态。
当集群 Operator 更新过程完成后,每个 control plane 节点都会重启,一次重启一个。
在更新过程中,会报告状态集群 Operator 被再次更新或处于降级状态的信息。这是因为 control plane 节点在重新引导节点时处于离线状态。
16.1.6.8. 更新 worker 节点
在更新了 control plane 后,您可以通过取消暂停您创建的相关 mcp 组来升级 worker 节点。取消暂停 mcp 组可为该组中的 worker 节点启动升级过程。集群中的每个 worker 节点都会重启,以便根据需要升级到新的 EUS y-stream 或 z-stream 版本。
对于 Control Plane Only 升级,请注意,当一个 worker 节点被更新时,只需要一个重启,并跳过 <y+2>-release 版本。这是添加的功能,以减少升级大型裸机集群所需的时间。
这是潜在的持有点。当 worker 节点处于 <y-2>-release 时,可以使用 control plane 在生产环境中运行的集群版本,该版本更新至一个新的 EUS 版本。这允许大型集群在多个维护窗口间升级。
您可以检查在
mcp组中管理多少个节点。运行以下命令来获取mcp组列表:$ oc get mcp输出示例
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE master rendered-master-c9a52144456dbff9c9af9c5a37d1b614 True False False 3 3 3 0 36d mcp-1 rendered-mcp-1-07fe50b9ad51fae43ed212e84e1dcc8e False False False 1 0 0 0 47h mcp-2 rendered-mcp-2-07fe50b9ad51fae43ed212e84e1dcc8e False False False 1 0 0 0 47h worker rendered-worker-f1ab7b9a768e1b0ac9290a18817f60f0 True False False 0 0 0 0 36d注意您决定一次要升级的
mcp组。这取决于一次可以花费多少个 CNF pod,以及如何配置 pod 中断预算和反关联性设置。获取集群中的节点列表:
$ oc get nodes输出示例
NAME STATUS ROLES AGE VERSION ctrl-plane-0 Ready control-plane,master 5d8h v1.29.8+f10c92d ctrl-plane-1 Ready control-plane,master 5d8h v1.29.8+f10c92d ctrl-plane-2 Ready control-plane,master 5d8h v1.29.8+f10c92d worker-0 Ready mcp-1,worker 5d8h v1.27.15+6147456 worker-1 Ready mcp-2,worker 5d8h v1.27.15+6147456确认已暂停的
MachineConfigPool组:$ oc get mcp -o json | jq -r '["MCP","Paused"], ["---","------"], (.items[] | [(.metadata.name), (.spec.paused)]) | @tsv' | grep -v worker输出示例
MCP Paused --- ------ master false mcp-1 true mcp-2 true注意每个
MachineConfigPool都可以独立取消暂停。因此,如果维护窗口超时其他 MCP,则不需要立即取消暂停。集群支持在 <y-2>-release 版本中使用一些 worker 节点运行。取消暂停所需的
mcp组以开始升级:$ oc patch mcp/mcp-1 --type merge --patch '{"spec":{"paused":false}}'输出示例
machineconfigpool.machineconfiguration.openshift.io/mcp-1 patched确认所需的
mcp组已被取消暂停:$ oc get mcp -o json | jq -r '["MCP","Paused"], ["---","------"], (.items[] | [(.metadata.name), (.spec.paused)]) | @tsv' | grep -v worker输出示例
MCP Paused --- ------ master false mcp-1 false mcp-2 true当每个
mcp组都已升级时,继续取消暂停并升级剩余的节点。$ oc get nodes输出示例
NAME STATUS ROLES AGE VERSION ctrl-plane-0 Ready control-plane,master 5d8h v1.29.8+f10c92d ctrl-plane-1 Ready control-plane,master 5d8h v1.29.8+f10c92d ctrl-plane-2 Ready control-plane,master 5d8h v1.29.8+f10c92d worker-0 Ready mcp-1,worker 5d8h v1.29.8+f10c92d worker-1 NotReady,SchedulingDisabled mcp-2,worker 5d8h v1.27.15+6147456
16.1.6.9. 验证新更新集群的运行状况
在更新集群后运行以下命令,以验证集群是否已备份并在运行。
流程
运行以下命令检查集群版本:
$ oc get clusterversion输出示例
NAME VERSION AVAILABLE PROGRESSING SINCE STATUS version 4.16.14 True False 4h38m Cluster version is 4.16.14这应该返回新的集群版本,
PROGRESSING列应返回False。检查所有节点是否已就绪:
$ oc get nodes输出示例
NAME STATUS ROLES AGE VERSION ctrl-plane-0 Ready control-plane,master 5d9h v1.29.8+f10c92d ctrl-plane-1 Ready control-plane,master 5d9h v1.29.8+f10c92d ctrl-plane-2 Ready control-plane,master 5d9h v1.29.8+f10c92d worker-0 Ready mcp-1,worker 5d9h v1.29.8+f10c92d worker-1 Ready mcp-2,worker 5d9h v1.29.8+f10c92d集群中的所有节点都应处于
Ready状态并运行相同的版本。检查集群中没有暂停的
mcp资源:$ oc get mcp -o json | jq -r '["MCP","Paused"], ["---","------"], (.items[] | [(.metadata.name), (.spec.paused)]) | @tsv' | grep -v worker输出示例
MCP Paused --- ------ master false mcp-1 false mcp-2 false检查所有集群 Operator 是否可用:
$ oc get co输出示例
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE authentication 4.16.14 True False False 5d9h baremetal 4.16.14 True False False 5d9h cloud-controller-manager 4.16.14 True False False 5d10h cloud-credential 4.16.14 True False False 5d10h cluster-autoscaler 4.16.14 True False False 5d9h config-operator 4.16.14 True False False 5d9h console 4.16.14 True False False 5d9h control-plane-machine-set 4.16.14 True False False 5d9h csi-snapshot-controller 4.16.14 True False False 5d9h dns 4.16.14 True False False 5d9h etcd 4.16.14 True False False 5d9h image-registry 4.16.14 True False False 85m ingress 4.16.14 True False False 5d9h insights 4.16.14 True False False 5d9h kube-apiserver 4.16.14 True False False 5d9h kube-controller-manager 4.16.14 True False False 5d9h kube-scheduler 4.16.14 True False False 5d9h kube-storage-version-migrator 4.16.14 True False False 4h48m machine-api 4.16.14 True False False 5d9h machine-approver 4.16.14 True False False 5d9h machine-config 4.16.14 True False False 5d9h marketplace 4.16.14 True False False 5d9h monitoring 4.16.14 True False False 5d9h network 4.16.14 True False False 5d9h node-tuning 4.16.14 True False False 5d7h openshift-apiserver 4.16.14 True False False 5d9h openshift-controller-manager 4.16.14 True False False 5d9h openshift-samples 4.16.14 True False False 5h24m operator-lifecycle-manager 4.16.14 True False False 5d9h operator-lifecycle-manager-catalog 4.16.14 True False False 5d9h operator-lifecycle-manager-packageserver 4.16.14 True False False 5d9h service-ca 4.16.14 True False False 5d9h storage 4.16.14 True False False 5d9h所有集群 Operator 都应该在
AVAILABLE列中报告True。检查所有 pod 是否都健康:
$ oc get po -A | grep -E -iv 'complete|running'这应该不会返回任何 pod。
注意在更新后,您可能会看到一些 pod 仍然会被移动。在等待一个时间,确保所有 pod 都已被清除。
16.1.7. 完成 y-stream 集群更新
按照以下步骤执行 y-stream 集群更新,并监控更新完成。完成 y-stream 更新比 Control Plane 只更新要简单。
16.1.7.1. 确认 Control Plane Only 或 y-stream 更新
当您从 4.11 及更新版本升级到所有版本时,您必须手动确认更新可以继续。
在确认更新前,请验证您要升级到的版本中删除了使用中的 Kubernetes API。例如,在 OpenShift Container Platform 4.17 中,没有删除 API。如需更多信息,请参阅"Kubernetes API 删除"。
流程
运行以下命令:
$ oc -n openshift-config patch cm admin-acks --patch '{"data":{"ack-<update_version_from>-kube-<kube_api_version>-api-removals-in-<update_version_to>":"true"}}' --type=merge其中:
- <update_version_from>
-
是您要从中移出的集群版本,如
4.14。 - <kube_api_version>
-
是 kube API 版本,如
1.28。 - <update_version_to>
-
是您要移到的集群版本,如
4.15。
验证
验证更新。运行以下命令:
$ oc get configmap admin-acks -n openshift-config -o json | jq .data输出示例
{ "ack-4.14-kube-1.28-api-removals-in-4.15": "true", "ack-4.15-kube-1.29-api-removals-in-4.16": "true" }注意在本例中,集群从 4.14 版本更新至 4.15,然后在 Control Plane 中从 4.15 更新至 4.16。
16.1.7.2. 启动集群更新
当从一个 y-stream 版本升级到下一个版本时,您必须确保中间 z-stream 版本也兼容。
您可以通过运行 oc adm upgrade 命令来验证您要升级到一个可行的发行版本。oc adm upgrade 命令列出兼容的更新版本。
流程
启动更新:
$ oc adm upgrade --to=4.15.33重要- Control Plane Only update: 请确定您指向 interim <y+1> 发行路径
- y-stream update - 确保使用正确的 <y.z> 发行版本,遵循 Kubernetes version skew 策略。
- z-stream update - 验证没有迁移到该特定版本的问题
输出示例
Requested update to 4.15.331 - 1
Requested update值会根据您的具体更新而改变。
16.1.7.3. 监控集群更新
您应该在更新过程中经常检查集群健康状况。检查节点状态、集群 Operator 状态和失败的 pod。
流程
监控集群更新。例如,要监控从 4.14 版本到 4.15 的集群更新,请运行以下命令:
$ watch "oc get clusterversion; echo; oc get co | head -1; oc get co | grep 4.14; oc get co | grep 4.15; echo; oc get no; echo; oc get po -A | grep -E -iv 'running|complete'"输出示例
NAME VERSION AVAILABLE PROGRESSING SINCE STATUS version 4.14.34 True True 4m6s Working towards 4.15.33: 111 of 873 done (12% complete), waiting on kube-apiserver NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE authentication 4.14.34 True False False 4d22h baremetal 4.14.34 True False False 4d23h cloud-controller-manager 4.14.34 True False False 4d23h cloud-credential 4.14.34 True False False 4d23h cluster-autoscaler 4.14.34 True False False 4d23h console 4.14.34 True False False 4d22h ... storage 4.14.34 True False False 4d23h config-operator 4.15.33 True False False 4d23h etcd 4.15.33 True False False 4d23h NAME STATUS ROLES AGE VERSION ctrl-plane-0 Ready control-plane,master 4d23h v1.27.15+6147456 ctrl-plane-1 Ready control-plane,master 4d23h v1.27.15+6147456 ctrl-plane-2 Ready control-plane,master 4d23h v1.27.15+6147456 worker-0 Ready mcp-1,worker 4d23h v1.27.15+6147456 worker-1 Ready mcp-2,worker 4d23h v1.27.15+6147456 NAMESPACE NAME READY STATUS RESTARTS AGE openshift-marketplace redhat-marketplace-rf86t 0/1 ContainerCreating 0 0s
验证
在更新 watch 命令期间,一次通过一个或多个集群 Operator 周期,在 MESSAGE 列中提供 Operator 更新状态。
当集群 Operator 更新过程完成后,每个 control plane 节点都会重启,一次重启一个。
在更新过程中,会报告状态集群 Operator 被再次更新或处于降级状态的信息。这是因为 control plane 节点在重新引导节点时处于离线状态。
完成上次 control plane 节点重新引导后,将会在更新时显示集群版本。
当 control plane 更新完成后会显示如下信息。本例演示了在中间 y-stream 版本完成的更新。
NAME VERSION AVAILABLE PROGRESSING SINCE STATUS
version 4.15.33 True False 28m Cluster version is 4.15.33
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE
authentication 4.15.33 True False False 5d
baremetal 4.15.33 True False False 5d
cloud-controller-manager 4.15.33 True False False 5d1h
cloud-credential 4.15.33 True False False 5d1h
cluster-autoscaler 4.15.33 True False False 5d
config-operator 4.15.33 True False False 5d
console 4.15.33 True False False 5d
...
service-ca 4.15.33 True False False 5d
storage 4.15.33 True False False 5d
NAME STATUS ROLES AGE VERSION
ctrl-plane-0 Ready control-plane,master 5d v1.28.13+2ca1a23
ctrl-plane-1 Ready control-plane,master 5d v1.28.13+2ca1a23
ctrl-plane-2 Ready control-plane,master 5d v1.28.13+2ca1a23
worker-0 Ready mcp-1,worker 5d v1.28.13+2ca1a23
worker-1 Ready mcp-2,worker 5d v1.28.13+2ca1a2316.1.7.4. 更新 OLM Operator
在电信环境中,软件需要在加载到生产环境集群之前进行检查。生产环境集群也在断开连接的网络中配置,这意味着它们并不总是直接连接到互联网。由于集群位于断开连接的网络中,所以 OpenShift Operator 会在安装过程中进行手动更新,以便可以以集群为基础管理新版本。执行以下步骤将 Operator 移到更新的版本中。
流程
检查需要更新哪些 Operator:
$ oc get installplan -A | grep -E 'APPROVED|false'输出示例
NAMESPACE NAME CSV APPROVAL APPROVED metallb-system install-nwjnh metallb-operator.v4.16.0-202409202304 Manual false openshift-nmstate install-5r7wr kubernetes-nmstate-operator.4.16.0-202409251605 Manual false为这些 Operator 修补
InstallPlan资源:$ oc patch installplan -n metallb-system install-nwjnh --type merge --patch \ '{"spec":{"approved":true}}'输出示例
installplan.operators.coreos.com/install-nwjnh patched运行以下命令来监控命名空间:
$ oc get all -n metallb-system输出示例
NAME READY STATUS RESTARTS AGE pod/metallb-operator-controller-manager-69b5f884c-8bp22 0/1 ContainerCreating 0 4s pod/metallb-operator-controller-manager-77895bdb46-bqjdx 1/1 Running 0 4m1s pod/metallb-operator-webhook-server-5d9b968896-vnbhk 0/1 ContainerCreating 0 4s pod/metallb-operator-webhook-server-d76f9c6c8-57r4w 1/1 Running 0 4m1s ... NAME DESIRED CURRENT READY AGE replicaset.apps/metallb-operator-controller-manager-69b5f884c 1 1 0 4s replicaset.apps/metallb-operator-controller-manager-77895bdb46 1 1 1 4m1s replicaset.apps/metallb-operator-controller-manager-99b76f88 0 0 0 4m40s replicaset.apps/metallb-operator-webhook-server-5d9b968896 1 1 0 4s replicaset.apps/metallb-operator-webhook-server-6f7dbfdb88 0 0 0 4m40s replicaset.apps/metallb-operator-webhook-server-d76f9c6c8 1 1 1 4m1s更新完成后,所需的 pod 应该处于
Running状态,所需的ReplicaSet资源应就绪:NAME READY STATUS RESTARTS AGE pod/metallb-operator-controller-manager-69b5f884c-8bp22 1/1 Running 0 25s pod/metallb-operator-webhook-server-5d9b968896-vnbhk 1/1 Running 0 25s ... NAME DESIRED CURRENT READY AGE replicaset.apps/metallb-operator-controller-manager-69b5f884c 1 1 1 25s replicaset.apps/metallb-operator-controller-manager-77895bdb46 0 0 0 4m22s replicaset.apps/metallb-operator-webhook-server-5d9b968896 1 1 1 25s replicaset.apps/metallb-operator-webhook-server-d76f9c6c8 0 0 0 4m22s
验证
验证 Operator 不需要第二次更新:
$ oc get installplan -A | grep -E 'APPROVED|false'应该不会返回任何输出。
注意有时您需要批准更新两次,因为有些 Operator 在最终版本之前有需要安装的 z-stream 版本。
16.1.7.5. 更新 worker 节点
在更新了 control plane 后,您可以通过取消暂停您创建的相关 mcp 组来升级 worker 节点。取消暂停 mcp 组可为该组中的 worker 节点启动升级过程。集群中的每个 worker 节点都会重启,以便根据需要升级到新的 EUS y-stream 或 z-stream 版本。
对于 Control Plane Only 升级,请注意,当一个 worker 节点被更新时,只需要一个重启,并跳过 <y+2>-release 版本。这是添加的功能,以减少升级大型裸机集群所需的时间。
这是潜在的持有点。当 worker 节点处于 <y-2>-release 时,可以使用 control plane 在生产环境中运行的集群版本,该版本更新至一个新的 EUS 版本。这允许大型集群在多个维护窗口间升级。
您可以检查在
mcp组中管理多少个节点。运行以下命令来获取mcp组列表:$ oc get mcp输出示例
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE master rendered-master-c9a52144456dbff9c9af9c5a37d1b614 True False False 3 3 3 0 36d mcp-1 rendered-mcp-1-07fe50b9ad51fae43ed212e84e1dcc8e False False False 1 0 0 0 47h mcp-2 rendered-mcp-2-07fe50b9ad51fae43ed212e84e1dcc8e False False False 1 0 0 0 47h worker rendered-worker-f1ab7b9a768e1b0ac9290a18817f60f0 True False False 0 0 0 0 36d注意您决定一次要升级的
mcp组。这取决于一次可以花费多少个 CNF pod,以及如何配置 pod 中断预算和反关联性设置。获取集群中的节点列表:
$ oc get nodes输出示例
NAME STATUS ROLES AGE VERSION ctrl-plane-0 Ready control-plane,master 5d8h v1.29.8+f10c92d ctrl-plane-1 Ready control-plane,master 5d8h v1.29.8+f10c92d ctrl-plane-2 Ready control-plane,master 5d8h v1.29.8+f10c92d worker-0 Ready mcp-1,worker 5d8h v1.27.15+6147456 worker-1 Ready mcp-2,worker 5d8h v1.27.15+6147456确认已暂停的
MachineConfigPool组:$ oc get mcp -o json | jq -r '["MCP","Paused"], ["---","------"], (.items[] | [(.metadata.name), (.spec.paused)]) | @tsv' | grep -v worker输出示例
MCP Paused --- ------ master false mcp-1 true mcp-2 true注意每个
MachineConfigPool都可以独立取消暂停。因此,如果维护窗口超时其他 MCP,则不需要立即取消暂停。集群支持在 <y-2>-release 版本中使用一些 worker 节点运行。取消暂停所需的
mcp组以开始升级:$ oc patch mcp/mcp-1 --type merge --patch '{"spec":{"paused":false}}'输出示例
machineconfigpool.machineconfiguration.openshift.io/mcp-1 patched确认所需的
mcp组已被取消暂停:$ oc get mcp -o json | jq -r '["MCP","Paused"], ["---","------"], (.items[] | [(.metadata.name), (.spec.paused)]) | @tsv' | grep -v worker输出示例
MCP Paused --- ------ master false mcp-1 false mcp-2 true当每个
mcp组都已升级时,继续取消暂停并升级剩余的节点。$ oc get nodes输出示例
NAME STATUS ROLES AGE VERSION ctrl-plane-0 Ready control-plane,master 5d8h v1.29.8+f10c92d ctrl-plane-1 Ready control-plane,master 5d8h v1.29.8+f10c92d ctrl-plane-2 Ready control-plane,master 5d8h v1.29.8+f10c92d worker-0 Ready mcp-1,worker 5d8h v1.29.8+f10c92d worker-1 NotReady,SchedulingDisabled mcp-2,worker 5d8h v1.27.15+6147456
16.1.7.6. 验证新更新集群的运行状况
在更新集群后运行以下命令,以验证集群是否已备份并在运行。
流程
运行以下命令检查集群版本:
$ oc get clusterversion输出示例
NAME VERSION AVAILABLE PROGRESSING SINCE STATUS version 4.16.14 True False 4h38m Cluster version is 4.16.14这应该返回新的集群版本,
PROGRESSING列应返回False。检查所有节点是否已就绪:
$ oc get nodes输出示例
NAME STATUS ROLES AGE VERSION ctrl-plane-0 Ready control-plane,master 5d9h v1.29.8+f10c92d ctrl-plane-1 Ready control-plane,master 5d9h v1.29.8+f10c92d ctrl-plane-2 Ready control-plane,master 5d9h v1.29.8+f10c92d worker-0 Ready mcp-1,worker 5d9h v1.29.8+f10c92d worker-1 Ready mcp-2,worker 5d9h v1.29.8+f10c92d集群中的所有节点都应处于
Ready状态并运行相同的版本。检查集群中没有暂停的
mcp资源:$ oc get mcp -o json | jq -r '["MCP","Paused"], ["---","------"], (.items[] | [(.metadata.name), (.spec.paused)]) | @tsv' | grep -v worker输出示例
MCP Paused --- ------ master false mcp-1 false mcp-2 false检查所有集群 Operator 是否可用:
$ oc get co输出示例
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE authentication 4.16.14 True False False 5d9h baremetal 4.16.14 True False False 5d9h cloud-controller-manager 4.16.14 True False False 5d10h cloud-credential 4.16.14 True False False 5d10h cluster-autoscaler 4.16.14 True False False 5d9h config-operator 4.16.14 True False False 5d9h console 4.16.14 True False False 5d9h control-plane-machine-set 4.16.14 True False False 5d9h csi-snapshot-controller 4.16.14 True False False 5d9h dns 4.16.14 True False False 5d9h etcd 4.16.14 True False False 5d9h image-registry 4.16.14 True False False 85m ingress 4.16.14 True False False 5d9h insights 4.16.14 True False False 5d9h kube-apiserver 4.16.14 True False False 5d9h kube-controller-manager 4.16.14 True False False 5d9h kube-scheduler 4.16.14 True False False 5d9h kube-storage-version-migrator 4.16.14 True False False 4h48m machine-api 4.16.14 True False False 5d9h machine-approver 4.16.14 True False False 5d9h machine-config 4.16.14 True False False 5d9h marketplace 4.16.14 True False False 5d9h monitoring 4.16.14 True False False 5d9h network 4.16.14 True False False 5d9h node-tuning 4.16.14 True False False 5d7h openshift-apiserver 4.16.14 True False False 5d9h openshift-controller-manager 4.16.14 True False False 5d9h openshift-samples 4.16.14 True False False 5h24m operator-lifecycle-manager 4.16.14 True False False 5d9h operator-lifecycle-manager-catalog 4.16.14 True False False 5d9h operator-lifecycle-manager-packageserver 4.16.14 True False False 5d9h service-ca 4.16.14 True False False 5d9h storage 4.16.14 True False False 5d9h所有集群 Operator 都应该在
AVAILABLE列中报告True。检查所有 pod 是否都健康:
$ oc get po -A | grep -E -iv 'complete|running'这应该不会返回任何 pod。
注意在更新后,您可能会看到一些 pod 仍然会被移动。在等待一个时间,确保所有 pod 都已被清除。
16.1.8. 完成 z-stream 集群更新
按照以下步骤执行 z-stream 集群更新,并监控更新完成。完成 z-stream 更新比 Control Plane Only 或 y-stream 更新更简单。
16.1.8.1. 启动集群更新
当从一个 y-stream 版本升级到下一个版本时,您必须确保中间 z-stream 版本也兼容。
您可以通过运行 oc adm upgrade 命令来验证您要升级到一个可行的发行版本。oc adm upgrade 命令列出兼容的更新版本。
流程
启动更新:
$ oc adm upgrade --to=4.15.33重要- Control Plane Only update: 请确定您指向 interim <y+1> 发行路径
- y-stream update - 确保使用正确的 <y.z> 发行版本,遵循 Kubernetes version skew 策略。
- z-stream update - 验证没有迁移到该特定版本的问题
输出示例
Requested update to 4.15.331 - 1
Requested update值会根据您的具体更新而改变。
16.1.8.2. 更新 worker 节点
在更新了 control plane 后,您可以通过取消暂停您创建的相关 mcp 组来升级 worker 节点。取消暂停 mcp 组可为该组中的 worker 节点启动升级过程。集群中的每个 worker 节点都会重启,以便根据需要升级到新的 EUS y-stream 或 z-stream 版本。
对于 Control Plane Only 升级,请注意,当一个 worker 节点被更新时,只需要一个重启,并跳过 <y+2>-release 版本。这是添加的功能,以减少升级大型裸机集群所需的时间。
这是潜在的持有点。当 worker 节点处于 <y-2>-release 时,可以使用 control plane 在生产环境中运行的集群版本,该版本更新至一个新的 EUS 版本。这允许大型集群在多个维护窗口间升级。
您可以检查在
mcp组中管理多少个节点。运行以下命令来获取mcp组列表:$ oc get mcp输出示例
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE master rendered-master-c9a52144456dbff9c9af9c5a37d1b614 True False False 3 3 3 0 36d mcp-1 rendered-mcp-1-07fe50b9ad51fae43ed212e84e1dcc8e False False False 1 0 0 0 47h mcp-2 rendered-mcp-2-07fe50b9ad51fae43ed212e84e1dcc8e False False False 1 0 0 0 47h worker rendered-worker-f1ab7b9a768e1b0ac9290a18817f60f0 True False False 0 0 0 0 36d注意您决定一次要升级的
mcp组。这取决于一次可以花费多少个 CNF pod,以及如何配置 pod 中断预算和反关联性设置。获取集群中的节点列表:
$ oc get nodes输出示例
NAME STATUS ROLES AGE VERSION ctrl-plane-0 Ready control-plane,master 5d8h v1.29.8+f10c92d ctrl-plane-1 Ready control-plane,master 5d8h v1.29.8+f10c92d ctrl-plane-2 Ready control-plane,master 5d8h v1.29.8+f10c92d worker-0 Ready mcp-1,worker 5d8h v1.27.15+6147456 worker-1 Ready mcp-2,worker 5d8h v1.27.15+6147456确认已暂停的
MachineConfigPool组:$ oc get mcp -o json | jq -r '["MCP","Paused"], ["---","------"], (.items[] | [(.metadata.name), (.spec.paused)]) | @tsv' | grep -v worker输出示例
MCP Paused --- ------ master false mcp-1 true mcp-2 true注意每个
MachineConfigPool都可以独立取消暂停。因此,如果维护窗口超时其他 MCP,则不需要立即取消暂停。集群支持在 <y-2>-release 版本中使用一些 worker 节点运行。取消暂停所需的
mcp组以开始升级:$ oc patch mcp/mcp-1 --type merge --patch '{"spec":{"paused":false}}'输出示例
machineconfigpool.machineconfiguration.openshift.io/mcp-1 patched确认所需的
mcp组已被取消暂停:$ oc get mcp -o json | jq -r '["MCP","Paused"], ["---","------"], (.items[] | [(.metadata.name), (.spec.paused)]) | @tsv' | grep -v worker输出示例
MCP Paused --- ------ master false mcp-1 false mcp-2 true当每个
mcp组都已升级时,继续取消暂停并升级剩余的节点。$ oc get nodes输出示例
NAME STATUS ROLES AGE VERSION ctrl-plane-0 Ready control-plane,master 5d8h v1.29.8+f10c92d ctrl-plane-1 Ready control-plane,master 5d8h v1.29.8+f10c92d ctrl-plane-2 Ready control-plane,master 5d8h v1.29.8+f10c92d worker-0 Ready mcp-1,worker 5d8h v1.29.8+f10c92d worker-1 NotReady,SchedulingDisabled mcp-2,worker 5d8h v1.27.15+6147456
16.1.8.3. 验证新更新集群的运行状况
在更新集群后运行以下命令,以验证集群是否已备份并在运行。
流程
运行以下命令检查集群版本:
$ oc get clusterversion输出示例
NAME VERSION AVAILABLE PROGRESSING SINCE STATUS version 4.16.14 True False 4h38m Cluster version is 4.16.14这应该返回新的集群版本,
PROGRESSING列应返回False。检查所有节点是否已就绪:
$ oc get nodes输出示例
NAME STATUS ROLES AGE VERSION ctrl-plane-0 Ready control-plane,master 5d9h v1.29.8+f10c92d ctrl-plane-1 Ready control-plane,master 5d9h v1.29.8+f10c92d ctrl-plane-2 Ready control-plane,master 5d9h v1.29.8+f10c92d worker-0 Ready mcp-1,worker 5d9h v1.29.8+f10c92d worker-1 Ready mcp-2,worker 5d9h v1.29.8+f10c92d集群中的所有节点都应处于
Ready状态并运行相同的版本。检查集群中没有暂停的
mcp资源:$ oc get mcp -o json | jq -r '["MCP","Paused"], ["---","------"], (.items[] | [(.metadata.name), (.spec.paused)]) | @tsv' | grep -v worker输出示例
MCP Paused --- ------ master false mcp-1 false mcp-2 false检查所有集群 Operator 是否可用:
$ oc get co输出示例
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE authentication 4.16.14 True False False 5d9h baremetal 4.16.14 True False False 5d9h cloud-controller-manager 4.16.14 True False False 5d10h cloud-credential 4.16.14 True False False 5d10h cluster-autoscaler 4.16.14 True False False 5d9h config-operator 4.16.14 True False False 5d9h console 4.16.14 True False False 5d9h control-plane-machine-set 4.16.14 True False False 5d9h csi-snapshot-controller 4.16.14 True False False 5d9h dns 4.16.14 True False False 5d9h etcd 4.16.14 True False False 5d9h image-registry 4.16.14 True False False 85m ingress 4.16.14 True False False 5d9h insights 4.16.14 True False False 5d9h kube-apiserver 4.16.14 True False False 5d9h kube-controller-manager 4.16.14 True False False 5d9h kube-scheduler 4.16.14 True False False 5d9h kube-storage-version-migrator 4.16.14 True False False 4h48m machine-api 4.16.14 True False False 5d9h machine-approver 4.16.14 True False False 5d9h machine-config 4.16.14 True False False 5d9h marketplace 4.16.14 True False False 5d9h monitoring 4.16.14 True False False 5d9h network 4.16.14 True False False 5d9h node-tuning 4.16.14 True False False 5d7h openshift-apiserver 4.16.14 True False False 5d9h openshift-controller-manager 4.16.14 True False False 5d9h openshift-samples 4.16.14 True False False 5h24m operator-lifecycle-manager 4.16.14 True False False 5d9h operator-lifecycle-manager-catalog 4.16.14 True False False 5d9h operator-lifecycle-manager-packageserver 4.16.14 True False False 5d9h service-ca 4.16.14 True False False 5d9h storage 4.16.14 True False False 5d9h所有集群 Operator 都应该在
AVAILABLE列中报告True。检查所有 pod 是否都健康:
$ oc get po -A | grep -E -iv 'complete|running'这应该不会返回任何 pod。
注意在更新后,您可能会看到一些 pod 仍然会被移动。在等待一个时间,确保所有 pod 都已被清除。