9.2. 关于 NUMA 感知调度
NUMA 感知调度会调整同一 NUMA 区域中请求的集群计算资源(CPU、内存、设备),以有效地处理对延迟敏感的工作负责或高性能工作负载。NUMA 感知调度还提高了每个计算节点的 pod 密度,以提高资源效率。
9.2.1. 与 Node Tuning Operator 集成
通过将 Node Tuning Operator 的性能配置集与 NUMA 感知调度集成,您可以进一步配置 CPU 关联性来优化对延迟敏感的工作负载的性能。
9.2.2. 默认调度逻辑
默认的 OpenShift Container Platform pod 调度程序调度逻辑考虑整个计算节点的可用资源,而不是单个 NUMA 区域。如果在 kubelet 拓扑管理器中请求最严格的资源协调,则会在将 pod 传递给节点时出现错误条件。相反,如果没有请求限制性最严格的资源协调,则 pod 可以在没有正确的资源协调的情况下被节点接受,从而导致性能更差或无法达到预期。例如,当 pod 调度程序通过不知道 pod 请求的资源可用而导致做出非最佳的调度决定时,pod 创建可能会出现 Topology Affinity Error 状态。调度不匹配决策可能会导致 pod 启动延迟。另外,根据集群状态和资源分配,pod 调度决策可能会因为启动失败而对集群造成额外的负载。
9.2.3. NUMA 感知 pod 调度图
NUMA Resources Operator 部署了一个自定义 NUMA 资源辅助调度程序和其他资源,以缓解默认 OpenShift Container Platform pod 调度程序的缩写。下图显示了 NUMA 感知 pod 调度的高级概述。
图 9.1. NUMA 感知调度概述
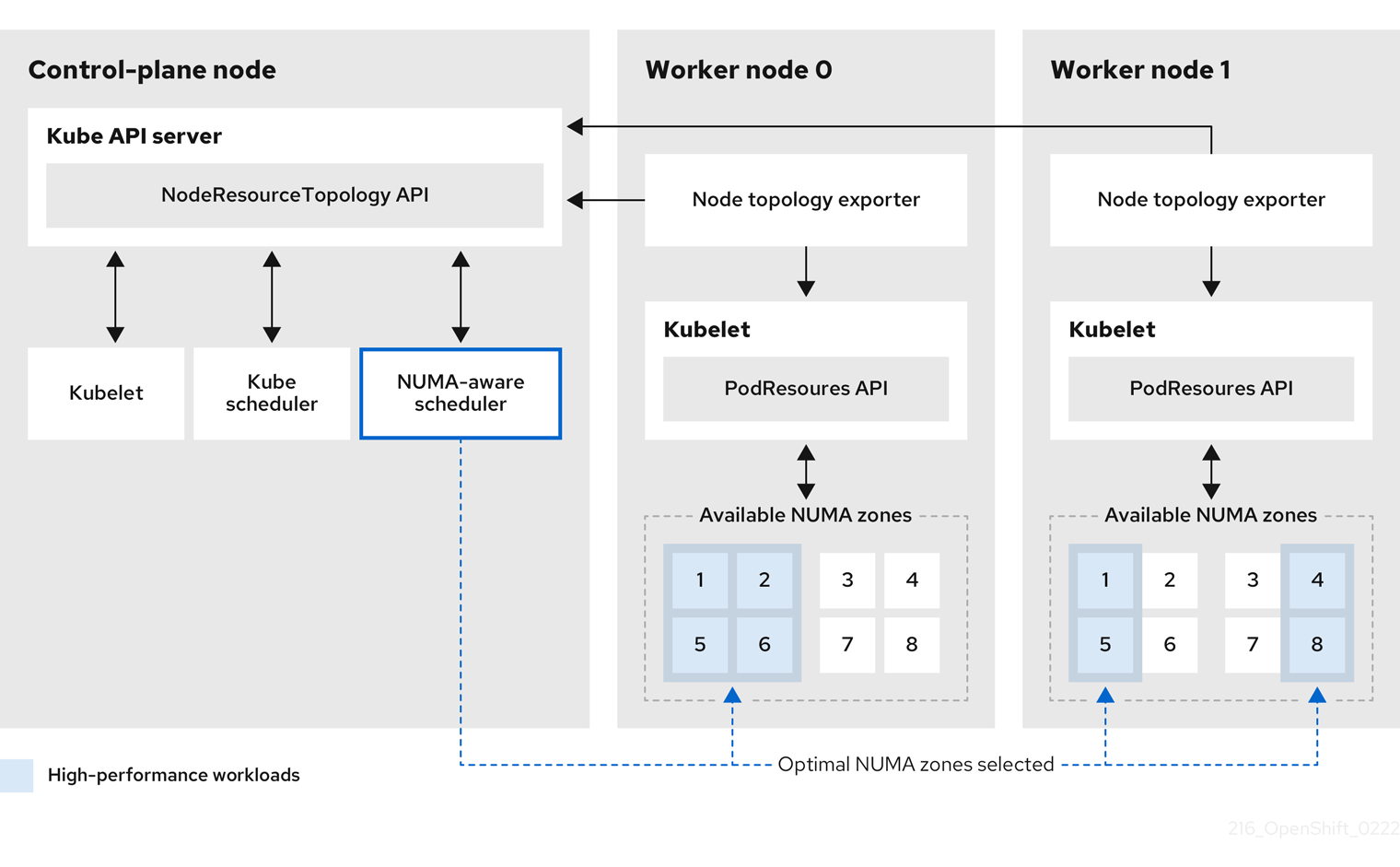
- NodeResourceTopology API
-
NodeResourceTopologyAPI 描述了每个计算节点上可用的 NUMA 区资源。 - NUMA 感知调度程序
-
NUMA 感知辅助调度程序从
NodeResourceTopologyAPI 接收有关可用 NUMA 区域的信息,并在可以最佳处理的节点上调度高性能工作负载。 - 节点拓扑 exporter
-
节点拓扑 exporter 会公开每个计算节点的可用 NUMA 区资源到
NodeResourceTopologyAPI。节点拓扑 exporter 守护进程使用PodResourcesAPI 跟踪来自 kubelet 的资源分配。 - PodResources API
对于每个节点,
PodResourcesAPI 是本地的,并向 kubelet 公开资源拓扑和可用资源。注意PodResourcesAPI 的List端点公开分配给特定容器的专用 CPU。API 不会公开属于共享池的 CPU。GetAllocatableResources端点公开节点上可用的可分配资源。