2.4. 使用 pod 横向自动扩展自动扩展 pod
作为开发人员,您可以使用 pod 横向自动扩展 (HPA) 来指定 OpenShift Container Platform 如何根据从属于某复制控制器或部署配置的 pod 收集的指标来自动增加或缩小该复制控制器或部署配置的规模。您可以为部署、部署配置、副本集、复制控制器或有状态集创建 HPA。
有关根据自定义指标缩放 pod 的信息,请参阅基于自定义指标自动扩展 pod。
除非需要特定功能或由其他对象提供的行为,否则建议使用 Deployment 对象或 ReplicaSet 对象。如需有关这些对象的更多信息,请参阅了解部署。
2.4.1. 了解 pod 横向自动扩展
您可以创建一个 pod 横向自动扩展来指定您要运行的 pod 的最小和最大数量,以及 pod 的目标 CPU 用量或内存用量。
创建 pod 横向自动扩展后,OpenShift Container Platform 开始查询 pod 上的 CPU、内存或两个资源指标。当这些指标可用时,pod 横向自动扩展会计算当前指标用于预期指标使用的比率,并根据需要扩展或缩减。查询和缩放是定期进行的,但可能需要一到两分钟时间才会有可用指标。
对于复制控制器,这种缩放直接与复制控制器的副本对应。对于部署,缩放直接与部署的副本数对应。注意,自动缩放仅应用到 Complete 阶段的最新部署。
OpenShift Container Platform 会自动考虑资源情况,并防止在资源激增期间进行不必要的自动缩放,比如在启动过程中。处于 unready 状态的 pod 在扩展时具有 0 CPU 用量,自动扩展在缩减时会忽略这些 pod。没有已知指标的 Pod 在扩展时具有 0% CPU 用量,在缩减时具有 100% CPU 用量。这在 HPA 决策过程中提供更高的稳定性。要使用这个功能,您必须配置就绪度检查来确定新 pod 是否准备就绪。
要使用 pod 横向自动扩展,您的集群管理员必须已经正确配置了集群指标。
pod 横向自动扩展支持以下指标:
| 指标 | 描述 | API 版本 |
|---|---|---|
| CPU 使用率 | 已用的 CPU 内核数。您可以使用它来计算 pod 的已请求 CPU 的百分比。 |
|
| 内存使用率 | 已用内存量。您可以使用它来计算 pod 请求的内存百分比。 |
|
对于基于内存的自动缩放,内存用量必须与副本数呈正比增大和减小。平均而言:
- 增加副本数一定会导致每个 pod 的内存(工作集)用量总体降低。
- 减少副本数一定会导致每个 pod 的内存用量总体增高。
使用 OpenShift Container Platform Web 控制台检查应用程序的内存行为,并确保应用程序在使用基于内存的自动缩放前满足这些要求。
以下示例显示了对 hello-node Deployment 对象的自动扩展。初始部署需要 3 个 pod。HPA 对象将最小值增加到 5。如果 pod 的 CPU 用量达到 75%,pod 会增加到 7:
$ oc autoscale deployment/hello-node --min=5 --max=7 --cpu-percent=75输出示例
horizontalpodautoscaler.autoscaling/hello-node autoscaled为 hello-node 部署对象创建一个 HPA,并将 minReplicas 设置为 3 的 YAML 示例
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: hello-node
namespace: default
spec:
maxReplicas: 7
minReplicas: 3
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: hello-node
targetCPUUtilizationPercentage: 75
status:
currentReplicas: 5
desiredReplicas: 0在创建 HPA 后,您可以通过运行以下命令来查看部署的新状态:
$ oc get deployment hello-node部署中现在有 5 个 pod:
输出示例
NAME REVISION DESIRED CURRENT TRIGGERED BY
hello-node 1 5 5 config2.4.2. HPA 的工作原理?
pod 横向自动扩展(HPA)扩展了 pod 自动扩展的概念。HPA 允许您创建和管理一组负载均衡的节点。当给定的 CPU 或内存阈值被超过时,HPA 会自动增加或减少 pod 数量。
图 2.1. HPA 的高级别工作流

HPA 是 Kubernetes 自动扩展 API 组中的 API 资源。自动扩展器充当控制循环,在同步周期内默认为 15 秒。在此期间,控制器管理器会根据 HPA 的 YAML 文件中定义的 CPU、内存使用率或两者查询 CPU、内存使用或两者。控制器管理器为 HPA 为目标的每个 pod 来获取来自每个 pod 资源指标(如 CPU 或内存)的资源指标的利用率指标。
如果设置了使用值目标,控制器会将利用率值视为各个 pod 中容器对等资源请求的百分比。然后,控制器需要所有目标 pod 的平均利用率,并生成一个用于缩放所需副本数的比率。HPA 配置为从 metrics.k8s.io 获取指标(由 metrics 服务器提供)。由于指标评估的动态性质,副本的数量在扩展一组副本期间会波动。
要实现 HPA,所有目标 pod 都必须在其容器上设置了一个资源请求。
2.4.3. 关于请求和限制
调度程序使用您为 pod 中容器指定的资源请求,来确定要将 pod 放置到哪个节点。kubelet 强制执行您为容器指定的资源限值,以确保容器不允许使用超过指定的限制。kubelet 还保留针对该容器使用的系统资源的请求数量。
如何使用资源指标?
在 pod 规格中,您必须指定资源请求,如 CPU 和内存。HPA 使用此规范来确定资源利用率,然后扩展目标或缩减。
例如,HPA 对象使用以下指标源:
type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 60在本例中,HPA 将 pod 的平均利用率保持在 scale 目标为 60%。使用率是当前资源使用量与 pod 请求的资源之间的比率。
2.4.4. 最佳实践
为获得最佳性能,请为所有 pod 配置资源请求。要防止频繁的副本波动,请配置 cooldown 周期。
- 所有 pod 都必须配置资源请求
- HPA 根据 OpenShift Container Platform 集群中观察的 pod 或内存用量值做出缩放决定。利用率值计算为各个容器集的资源请求的百分比。缺少资源请求值可能会影响 HPA 的最佳性能。
如需更多信息,请参阅"了解资源请求和限值"。
- 配置冷却期
-
在横向 pod 自动扩展过程中,可能会快速扩展事件,而不会造成时间差。配置 cool down 周期,以防止频繁的副本波动。您可以通过配置
stabilizationWindowSeconds字段指定 cool down period。当用于扩展的指标保持波动时,stabilization 窗口用于限制副本数的波动。自动扩展算法使用此窗口来推断以前的必要状态,并避免对工作负载扩展不需要的更改。
例如,为 scaleDown 字段指定了 stabilization 窗口:
behavior:
scaleDown:
stabilizationWindowSeconds: 300在上例中,过去 5 分钟的所有预期状态都会被考虑。这个大约滚动的最大值,避免出现扩展算法通常只删除 pod,以便以后触发相等的 pod 重新创建。
如需更多信息,请参阅"扩展策略"。
2.4.4.1. 扩展策略
使用 autoscaling/v2 API 为 pod 横向自动扩展添加 扩展策略。扩展策略用于控制 OpenShift Container Platform 横向自动扩展(HPA)如何扩展 pod。使用扩展策略,通过设置在指定时间段内扩展的特定数量或特定百分比来限制 HPA 扩展或缩减的速率。您还可以定义 一个稳定窗口,它使用之前计算的所需状态来控制扩展(如果指标波动)。您可以为同一扩展方向创建多个策略,并根据更改的数量决定要使用的策略。您还可以通过计时的迭代限制缩放。HPA 在迭代过程中扩展 pod,然后在以后的迭代中执行扩展(如果需要)。
带有扩展策略的 HPA 对象示例
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: hpa-resource-metrics-memory
namespace: default
spec:
behavior:
scaleDown:
policies:
- type: Pods
value: 4
periodSeconds: 60
- type: Percent
value: 10
periodSeconds: 60
selectPolicy: Min
stabilizationWindowSeconds: 300
scaleUp:
policies:
- type: Pods
value: 5
periodSeconds: 70
- type: Percent
value: 12
periodSeconds: 80
selectPolicy: Max
stabilizationWindowSeconds: 0
...- 1
- 指定扩展策略的方向,可以是
scaleDown或scaleUp。本例为缩减创建一个策略。 - 2
- 定义扩展策略。
- 3
- 决定策略是否在每次迭代过程中根据特定的 pod 数量或 pod 百分比进行扩展。默认值为
pod。 - 4
- 在每次迭代过程中缩放数量(pod 数量或 pod 的百分比)的限制。在按 pod 数量进行缩减时没有默认的值。
- 5
- 决定扩展迭代的长度。默认值为
15秒。 - 6
- 按百分比缩减的默认值为 100%。
- 7
- 如果定义了多个策略,则决定首先使用的策略。指定
Max使用允许最多更改的策略,Min使用允许最小更改的策略,或者Disabled阻止 HPA 在策略方向进行扩展。默认值为Max。 - 8
- 决定 HPA 检查所需状态的时间周期。默认值为
0。 - 9
- 本例为扩展创建了策略。
- 10
- 扩展数量的限制(按 pod 的数量)。扩展 pod 数量的默认值为 4%。
- 11
- 扩展数量的限制(按 pod 的百分比)。按百分比扩展的默认值为 100%。
缩减策略示例
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: hpa-resource-metrics-memory
namespace: default
spec:
...
minReplicas: 20
...
behavior:
scaleDown:
stabilizationWindowSeconds: 300
policies:
- type: Pods
value: 4
periodSeconds: 30
- type: Percent
value: 10
periodSeconds: 60
selectPolicy: Max
scaleUp:
selectPolicy: Disabled
在本例中,当 pod 的数量大于 40 时,则使用基于百分比的策略进行缩减。这个策略会产生较大变化,这是 selectPolicy 需要的。
如果有 80 个 pod 副本,在第一次迭代时 HPA 会将 pod 减少 8 个,即 80 个 pod 的 10%(根据 type: Percent 和 value: 10 参数),持续一分钟(periodSeconds: 60)。对于下一个迭代,pod 的数量为 72。HPA 计算剩余 pod 的 10% 为 7.2,这个数值被舍入到 8,这会缩减 8 个 pod。在每一后续迭代中,将根据剩余的 pod 数量重新计算要缩放的 pod 数量。当 pod 的数量小于 40 时,会应用基于 pod 的策略,因为基于 pod 的数值大于基于百分比的数量。HPA 每次减少 4 个 pod(type: Pod 和 value: 4),持续 30 秒(periodSeconds: 30),直到剩余 20 个副本(minReplicas)。
selectPolicy: Disabled 参数可防止 HPA 扩展 pod。如果需要,可以通过调整副本集或部署集中的副本数来手动扩展。
如果设置,您可以使用 oc edit 命令查看扩展策略:
$ oc edit hpa hpa-resource-metrics-memory输出示例
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
annotations:
autoscaling.alpha.kubernetes.io/behavior:\
'{"ScaleUp":{"StabilizationWindowSeconds":0,"SelectPolicy":"Max","Policies":[{"Type":"Pods","Value":4,"PeriodSeconds":15},{"Type":"Percent","Value":100,"PeriodSeconds":15}]},\
"ScaleDown":{"StabilizationWindowSeconds":300,"SelectPolicy":"Min","Policies":[{"Type":"Pods","Value":4,"PeriodSeconds":60},{"Type":"Percent","Value":10,"PeriodSeconds":60}]}}'
...2.4.5. 使用 Web 控制台创建 pod 横向自动扩展
在 web 控制台中,您可以创建一个 pod 横向自动扩展(HPA),用于指定要在 Deployment 或 DeploymentConfig 对象上运行的 pod 的最小和最大数量。您还可以定义 pod 的目标 CPU 或内存用量。
HPA 不能添加到作为 Operator 支持服务、Knative 服务或 Helm chart 一部分的部署中。
流程
在 web 控制台中创建 HPA:
- 在 Topology 视图中,点击节点公开侧面板。
在 Actions 下拉列表中,选择 Add HorizontalPodAutoscaler 来打开 Add HorizontalPodAutoscaler 表单。
图 2.2. 添加 HorizontalPodAutoscaler
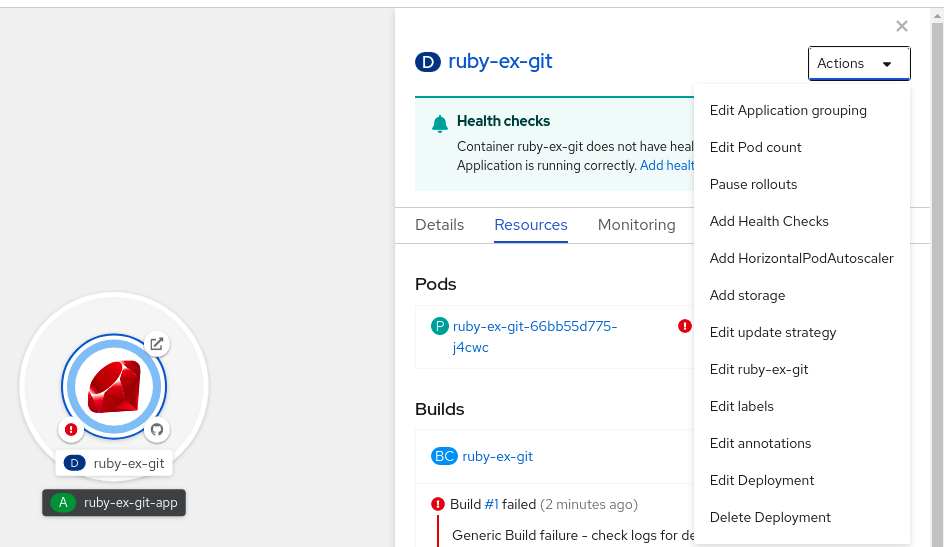
在 Add HorizontalPodAutoscaler 表单中,定义名称、最小和最大 pod 限值、CPU 和内存用量,并点 Save。
注意如果缺少 CPU 和内存用量的值,则会显示警告。
2.4.5.1. 使用 Web 控制台编辑 pod 横向自动扩展
在 web 控制台中,您可以修改 pod 横向自动扩展(HPA),用于指定要在 Deployment 或 DeploymentConfig 对象上运行的 pod 的最小和最大数量。您还可以定义 pod 的目标 CPU 或内存用量。
流程
- 在 Topology 视图中,点击节点公开侧面板。
- 在 Actions 下拉列表中,选择 Edit HorizontalPodAutoscaler 来打开 Edit Horizontal Pod Autoscaler 表单。
- 在 Edit Horizontal Pod Autoscaler 表单中,编辑最小和最大 pod 限值以及 CPU 和内存用量,然后点 Save。
在 web 控制台中创建或编辑 pod 横向自动扩展时,您可以从 Form 视图切换到 YAML 视图。
2.4.5.2. 使用 Web 控制台删除 pod 横向自动扩展
您可以在 web 控制台中删除 pod 横向自动扩展(HPA)。
流程
- 在 Topology 视图中,点击节点公开侧面板。
- 在 Actions 下拉列表中,选择 Remove HorizontalPodAutoscaler。
- 在确认窗口中,点击 Remove 删除 HPA。
2.4.6. 使用 CLI 创建 pod 横向自动扩展
使用 OpenShift Container Platform CLI,您可以创建一个 pod 横向自动扩展(HPA)来自动扩展现有的 Deployment、DeploymentConfig、ReplicaSet、ReplicationController 或 StatefulSet 对象。HPA 扩展与该对象关联的 pod,以维护您指定的 CPU 或内存资源。
您可以通过指定资源使用情况或特定值百分比来根据 CPU 或内存使用自动扩展,如以下部分所述。
HPA 增加和减少最小和最大数量之间的副本数量,以维护所有 pod 的指定资源使用。
2.4.6.1. 为 CPU 的使用率创建 pod 横向自动扩展
使用 OpenShift Container Platform CLI,您可以创建一个 pod 横向自动扩展(HPA)根据 CPU 使用百分比自动扩展现有对象。HPA 扩展与该对象关联的 pod,以维护您指定的 CPU 使用。
当为 CPU 使用百分比自动扩展时,您可以使用 oc autoscale 命令来指定要在任意给定时间运行的 pod 的最小和最大数量,以及 pod 的目标平均 CPU 数量。如果未指定最小值,则 OpenShift Container Platform 服务器会为 pod 赋予一个默认值。
使用 Deployment 对象或 ReplicaSet 对象,除非您需要由其他对象提供的特定功能或行为。
先决条件
要使用 pod 横向自动扩展,您的集群管理员必须已经正确配置了集群指标。您可以使用 oc describe PodMetrics <pod-name> 命令来判断是否已配置了指标。如果配置了指标,输出类似于以下示例,其中 Usage 下列出了 Cpu 和 Memory。
$ oc describe PodMetrics openshift-kube-scheduler-ip-10-0-135-131.ec2.internal输出示例
Name: openshift-kube-scheduler-ip-10-0-135-131.ec2.internal
Namespace: openshift-kube-scheduler
Labels: <none>
Annotations: <none>
API Version: metrics.k8s.io/v1beta1
Containers:
Name: wait-for-host-port
Usage:
Memory: 0
Name: scheduler
Usage:
Cpu: 8m
Memory: 45440Ki
Kind: PodMetrics
Metadata:
Creation Timestamp: 2019-05-23T18:47:56Z
Self Link: /apis/metrics.k8s.io/v1beta1/namespaces/openshift-kube-scheduler/pods/openshift-kube-scheduler-ip-10-0-135-131.ec2.internal
Timestamp: 2019-05-23T18:47:56Z
Window: 1m0s
Events: <none>流程
为现有对象创建
HorizontalPodAutoscaler对象:$ oc autoscale <object_type>/<name> \1 --min <number> \2 --max <number> \3 --cpu-percent=<percent>4 例如,以下命令显示
hello-node部署对象的自动扩展:初始部署需要 3 个 pod。HPA 对象将最小值增加到 5。如果 pod 的 CPU 用量达到 75%,pod 将增加到 7:$ oc autoscale deployment/hello-node --min=5 --max=7 --cpu-percent=75创建 Pod 横向自动扩展:
$ oc create -f <file-name>.yaml
验证
确保创建了 pod 横向自动扩展:
$ oc get hpa cpu-autoscale输出示例
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE cpu-autoscale Deployment/example 173m/500m 1 10 1 20m
2.4.6.2. 为特定 CPU 值创建 pod 横向自动扩展
使用 OpenShift Container Platform CLI,您可以创建一个 pod 横向自动扩展(HPA),通过创建带有目标 CPU 和 pod 限制的 HorizontalPodAutoscaler 对象来根据特定 CPU 值自动扩展现有对象。HPA 扩展与该对象关联的 pod,以维护您指定的 CPU 使用。
使用 Deployment 对象或 ReplicaSet 对象,除非您需要由其他对象提供的特定功能或行为。
先决条件
要使用 pod 横向自动扩展,您的集群管理员必须已经正确配置了集群指标。您可以使用 oc describe PodMetrics <pod-name> 命令来判断是否已配置了指标。如果配置了指标,输出类似于以下示例,其中 Usage 下列出了 Cpu 和 Memory。
$ oc describe PodMetrics openshift-kube-scheduler-ip-10-0-135-131.ec2.internal输出示例
Name: openshift-kube-scheduler-ip-10-0-135-131.ec2.internal
Namespace: openshift-kube-scheduler
Labels: <none>
Annotations: <none>
API Version: metrics.k8s.io/v1beta1
Containers:
Name: wait-for-host-port
Usage:
Memory: 0
Name: scheduler
Usage:
Cpu: 8m
Memory: 45440Ki
Kind: PodMetrics
Metadata:
Creation Timestamp: 2019-05-23T18:47:56Z
Self Link: /apis/metrics.k8s.io/v1beta1/namespaces/openshift-kube-scheduler/pods/openshift-kube-scheduler-ip-10-0-135-131.ec2.internal
Timestamp: 2019-05-23T18:47:56Z
Window: 1m0s
Events: <none>流程
为现有对象创建类似如下的 YAML 文件:
apiVersion: autoscaling/v21 kind: HorizontalPodAutoscaler metadata: name: cpu-autoscale2 namespace: default spec: scaleTargetRef: apiVersion: apps/v13 kind: Deployment4 name: example5 minReplicas: 16 maxReplicas: 107 metrics:8 - type: Resource resource: name: cpu9 target: type: AverageValue10 averageValue: 500m11 - 1
- 使用
autoscaling/v2API。 - 2
- 指定此 pod 横向自动扩展对象的名称。
- 3
- 指定要缩放对象的 API 版本:
-
对于
Deployment,ReplicaSet、Statefulset对象,使用apps/v1。 -
对于
ReplicationController,使用v1。 -
对于
DeploymentConfig,使用apps.openshift.io/v1。
-
对于
- 4
- 指定对象类型。对象需要是
Deployment,DeploymentConfig/dc,ReplicaSet/rs,ReplicationController/rc, 或StatefulSet. - 5
- 指定要缩放的对象名称。对象必须存在。
- 6
- 指定缩减时的最小副本数量。
- 7
- 指定扩展时的最大副本数量。
- 8
- 使用
metrics参数供内存使用。 - 9
- 为 CPU 用量指定
cpu。 - 10
- 设置为
AverageValue。 - 11
- 使用目标 CPU 值设置为
averageValue。
创建 Pod 横向自动扩展:
$ oc create -f <file-name>.yaml
验证
检查是否已创建 pod 横向自动扩展:
$ oc get hpa cpu-autoscale输出示例
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE cpu-autoscale Deployment/example 173m/500m 1 10 1 20m
2.4.6.3. 为内存百分比创建 pod 横向自动扩展对象
使用 OpenShift Container Platform CLI,您可以创建一个 pod 横向自动扩展(HPA)根据内存使用百分比来自动扩展现有对象。HPA 扩展与该对象关联的 pod,以维护您指定的内存使用。
使用 Deployment 对象或 ReplicaSet 对象,除非您需要由其他对象提供的特定功能或行为。
您可以指定 pod 的最小和最大数量,以及 pod 应该针对的平均内存使用。如果未指定最小值,则 OpenShift Container Platform 服务器会为 pod 赋予一个默认值。
先决条件
要使用 pod 横向自动扩展,您的集群管理员必须已经正确配置了集群指标。您可以使用 oc describe PodMetrics <pod-name> 命令来判断是否已配置了指标。如果配置了指标,输出类似于以下示例,其中 Usage 下列出了 Cpu 和 Memory。
$ oc describe PodMetrics openshift-kube-scheduler-ip-10-0-135-131.ec2.internal输出示例
Name: openshift-kube-scheduler-ip-10-0-135-131.ec2.internal
Namespace: openshift-kube-scheduler
Labels: <none>
Annotations: <none>
API Version: metrics.k8s.io/v1beta1
Containers:
Name: wait-for-host-port
Usage:
Memory: 0
Name: scheduler
Usage:
Cpu: 8m
Memory: 45440Ki
Kind: PodMetrics
Metadata:
Creation Timestamp: 2019-05-23T18:47:56Z
Self Link: /apis/metrics.k8s.io/v1beta1/namespaces/openshift-kube-scheduler/pods/openshift-kube-scheduler-ip-10-0-135-131.ec2.internal
Timestamp: 2019-05-23T18:47:56Z
Window: 1m0s
Events: <none>流程
为现有对象创建类似如下的
HorizontalPodAutoscaler对象:apiVersion: autoscaling/v21 kind: HorizontalPodAutoscaler metadata: name: memory-autoscale2 namespace: default spec: scaleTargetRef: apiVersion: apps/v13 kind: Deployment4 name: example5 minReplicas: 16 maxReplicas: 107 metrics:8 - type: Resource resource: name: memory9 target: type: Utilization10 averageUtilization: 5011 behavior:12 scaleUp: stabilizationWindowSeconds: 180 policies: - type: Pods value: 6 periodSeconds: 120 - type: Percent value: 10 periodSeconds: 120 selectPolicy: Max- 1
- 使用
autoscaling/v2API。 - 2
- 指定此 pod 横向自动扩展对象的名称。
- 3
- 指定要缩放对象的 API 版本:
-
对于 ReplicationController,使用
v1。 -
对于 DeploymentConfig,使用
apps.openshift.io/v1。 -
对于 Deployment、ReplicaSet 和 Statefulset 对象,使用
apps/v1。
-
对于 ReplicationController,使用
- 4
- 指定对象类型。对象必须是
Deployment、DeploymentConfig、ReplicaSet、ReplicationController或StatefulSet。 - 5
- 指定要缩放的对象名称。对象必须存在。
- 6
- 指定缩减时的最小副本数量。
- 7
- 指定扩展时的最大副本数量。
- 8
- 使用
metrics参数进行内存用量。 - 9
- 为内存用量指定内存。
- 10
- 设置
Utilization。 - 11
- 指定
averageUtilization和所有 pod 的目标平均内存使用量,以请求的内存百分比表示。目标 pod 必须配置内存请求。 - 12
- 可选:指定一个扩展策略来控制扩展或缩减率。
使用类似如下的命令创建 pod 横向自动扩展:
$ oc create -f <file-name>.yaml例如:
$ oc create -f hpa.yaml输出示例
horizontalpodautoscaler.autoscaling/hpa-resource-metrics-memory created
验证
使用类似如下的命令检查 pod 横向自动扩展是否已创建:
$ oc get hpa hpa-resource-metrics-memory输出示例
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE hpa-resource-metrics-memory Deployment/example 2441216/500Mi 1 10 1 20m使用类似如下的命令检查 pod 横向自动扩展的详情:
$ oc describe hpa hpa-resource-metrics-memory输出示例
Name: hpa-resource-metrics-memory Namespace: default Labels: <none> Annotations: <none> CreationTimestamp: Wed, 04 Mar 2020 16:31:37 +0530 Reference: Deployment/example Metrics: ( current / target ) resource memory on pods: 2441216 / 500Mi Min replicas: 1 Max replicas: 10 ReplicationController pods: 1 current / 1 desired Conditions: Type Status Reason Message ---- ------ ------ ------- AbleToScale True ReadyForNewScale recommended size matches current size ScalingActive True ValidMetricFound the HPA was able to successfully calculate a replica count from memory resource ScalingLimited False DesiredWithinRange the desired count is within the acceptable range Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal SuccessfulRescale 6m34s horizontal-pod-autoscaler New size: 1; reason: All metrics below target
2.4.6.4. 为特定内存使用创建 pod 横向自动扩展对象
使用 OpenShift Container Platform CLI,您可以创建一个 pod 横向自动扩展(HPA)来自动扩展现有对象。HPA 扩展与该对象关联的 pod,以维护您指定的平均内存使用。
使用 Deployment 对象或 ReplicaSet 对象,除非您需要由其他对象提供的特定功能或行为。
您可以指定 pod 的最小和最大数量,以及 pod 应该针对的平均内存使用。如果未指定最小值,则 OpenShift Container Platform 服务器会为 pod 赋予一个默认值。
先决条件
要使用 pod 横向自动扩展,您的集群管理员必须已经正确配置了集群指标。您可以使用 oc describe PodMetrics <pod-name> 命令来判断是否已配置了指标。如果配置了指标,输出类似于以下示例,其中 Usage 下列出了 Cpu 和 Memory。
$ oc describe PodMetrics openshift-kube-scheduler-ip-10-0-135-131.ec2.internal输出示例
Name: openshift-kube-scheduler-ip-10-0-135-131.ec2.internal
Namespace: openshift-kube-scheduler
Labels: <none>
Annotations: <none>
API Version: metrics.k8s.io/v1beta1
Containers:
Name: wait-for-host-port
Usage:
Memory: 0
Name: scheduler
Usage:
Cpu: 8m
Memory: 45440Ki
Kind: PodMetrics
Metadata:
Creation Timestamp: 2019-05-23T18:47:56Z
Self Link: /apis/metrics.k8s.io/v1beta1/namespaces/openshift-kube-scheduler/pods/openshift-kube-scheduler-ip-10-0-135-131.ec2.internal
Timestamp: 2019-05-23T18:47:56Z
Window: 1m0s
Events: <none>流程
为现有对象创建类似如下的
HorizontalPodAutoscaler对象:apiVersion: autoscaling/v21 kind: HorizontalPodAutoscaler metadata: name: hpa-resource-metrics-memory2 namespace: default spec: scaleTargetRef: apiVersion: apps/v13 kind: Deployment4 name: example5 minReplicas: 16 maxReplicas: 107 metrics:8 - type: Resource resource: name: memory9 target: type: AverageValue10 averageValue: 500Mi11 behavior:12 scaleDown: stabilizationWindowSeconds: 300 policies: - type: Pods value: 4 periodSeconds: 60 - type: Percent value: 10 periodSeconds: 60 selectPolicy: Max- 1
- 使用
autoscaling/v2API。 - 2
- 指定此 pod 横向自动扩展对象的名称。
- 3
- 指定要缩放对象的 API 版本:
-
对于
Deployment、ReplicaSet或Statefulset对象,请使用apps/v1。 -
对于
ReplicationController,使用v1。 -
对于
DeploymentConfig,使用apps.openshift.io/v1。
-
对于
- 4
- 指定对象类型。对象必须是
Deployment、DeploymentConfig、ReplicaSet、ReplicationController或StatefulSet。 - 5
- 指定要缩放的对象名称。对象必须存在。
- 6
- 指定缩减时的最小副本数量。
- 7
- 指定扩展时的最大副本数量。
- 8
- 使用
metrics参数进行内存用量。 - 9
- 为内存用量指定内存。
- 10
- 将类型设置为
AverageValue。 - 11
- 指定
averageValue和一个特定的内存值。 - 12
- 可选:指定一个扩展策略来控制扩展或缩减率。
使用类似如下的命令创建 pod 横向自动扩展:
$ oc create -f <file-name>.yaml例如:
$ oc create -f hpa.yaml输出示例
horizontalpodautoscaler.autoscaling/hpa-resource-metrics-memory created
验证
使用类似如下的命令检查 pod 横向自动扩展是否已创建:
$ oc get hpa hpa-resource-metrics-memory输出示例
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE hpa-resource-metrics-memory Deployment/example 2441216/500Mi 1 10 1 20m使用类似如下的命令检查 pod 横向自动扩展的详情:
$ oc describe hpa hpa-resource-metrics-memory输出示例
Name: hpa-resource-metrics-memory Namespace: default Labels: <none> Annotations: <none> CreationTimestamp: Wed, 04 Mar 2020 16:31:37 +0530 Reference: Deployment/example Metrics: ( current / target ) resource memory on pods: 2441216 / 500Mi Min replicas: 1 Max replicas: 10 ReplicationController pods: 1 current / 1 desired Conditions: Type Status Reason Message ---- ------ ------ ------- AbleToScale True ReadyForNewScale recommended size matches current size ScalingActive True ValidMetricFound the HPA was able to successfully calculate a replica count from memory resource ScalingLimited False DesiredWithinRange the desired count is within the acceptable range Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal SuccessfulRescale 6m34s horizontal-pod-autoscaler New size: 1; reason: All metrics below target
2.4.7. 使用 CLI 了解 pod 横向自动扩展状态条件
您可以使用设置的状态条件来判断 pod 横向自动扩展 (HPA) 是否能够缩放,以及目前是否受到某种方式的限制。
HPA 状态条件可通过 v2 版的自动扩展 API 使用。
HPA 可以通过下列状态条件给予响应:
AbleToScale条件指示 HPA 是否能够获取和更新指标,以及是否有任何与退避相关的条件阻碍了缩放。-
True条件表示允许缩放。 -
False条件表示因为指定原因不允许缩放。
-
ScalingActive条件指示 HPA 是否已启用(例如,目标的副本数不为零),并且可以计算所需的指标。-
True条件表示指标工作正常。 -
False条件通常表示获取指标时出现问题。
-
ScalingLimited条件表示所需的规模由 pod 横向自动扩展限定最大或最小限制。-
True条件表示您需要提高或降低最小或最大副本数才能进行缩放。 False条件表示允许请求的缩放。$ oc describe hpa cm-test输出示例
Name: cm-test Namespace: prom Labels: <none> Annotations: <none> CreationTimestamp: Fri, 16 Jun 2017 18:09:22 +0000 Reference: ReplicationController/cm-test Metrics: ( current / target ) "http_requests" on pods: 66m / 500m Min replicas: 1 Max replicas: 4 ReplicationController pods: 1 current / 1 desired Conditions:1 Type Status Reason Message ---- ------ ------ ------- AbleToScale True ReadyForNewScale the last scale time was sufficiently old as to warrant a new scale ScalingActive True ValidMetricFound the HPA was able to successfully calculate a replica count from pods metric http_request ScalingLimited False DesiredWithinRange the desired replica count is within the acceptable range Events:- 1
- pod 横向自动扩展状态消息。
-
下例中是一个无法缩放的 pod:
输出示例
Conditions:
Type Status Reason Message
---- ------ ------ -------
AbleToScale False FailedGetScale the HPA controller was unable to get the target's current scale: no matches for kind "ReplicationController" in group "apps"
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedGetScale 6s (x3 over 36s) horizontal-pod-autoscaler no matches for kind "ReplicationController" in group "apps"下例中是一个无法获得缩放所需指标的 pod:
输出示例
Conditions:
Type Status Reason Message
---- ------ ------ -------
AbleToScale True SucceededGetScale the HPA controller was able to get the target's current scale
ScalingActive False FailedGetResourceMetric the HPA was unable to compute the replica count: failed to get cpu utilization: unable to get metrics for resource cpu: no metrics returned from resource metrics API下例中是一个请求的自动缩放低于所需下限的 pod:
输出示例
Conditions:
Type Status Reason Message
---- ------ ------ -------
AbleToScale True ReadyForNewScale the last scale time was sufficiently old as to warrant a new scale
ScalingActive True ValidMetricFound the HPA was able to successfully calculate a replica count from pods metric http_request
ScalingLimited False DesiredWithinRange the desired replica count is within the acceptable range2.4.7.1. 使用 CLI 查看 pod 横向自动扩展状态条件
您可以查看 pod 横向自动扩展 (HPA) 对 pod 设置的状态条件。
pod 横向自动扩展状态条件可通过 v2 版本的自动扩展 API 使用。
先决条件
要使用 pod 横向自动扩展,您的集群管理员必须已经正确配置了集群指标。您可以使用 oc describe PodMetrics <pod-name> 命令来判断是否已配置了指标。如果配置了指标,输出类似于以下示例,其中 Usage 下列出了 Cpu 和 Memory。
$ oc describe PodMetrics openshift-kube-scheduler-ip-10-0-135-131.ec2.internal输出示例
Name: openshift-kube-scheduler-ip-10-0-135-131.ec2.internal
Namespace: openshift-kube-scheduler
Labels: <none>
Annotations: <none>
API Version: metrics.k8s.io/v1beta1
Containers:
Name: wait-for-host-port
Usage:
Memory: 0
Name: scheduler
Usage:
Cpu: 8m
Memory: 45440Ki
Kind: PodMetrics
Metadata:
Creation Timestamp: 2019-05-23T18:47:56Z
Self Link: /apis/metrics.k8s.io/v1beta1/namespaces/openshift-kube-scheduler/pods/openshift-kube-scheduler-ip-10-0-135-131.ec2.internal
Timestamp: 2019-05-23T18:47:56Z
Window: 1m0s
Events: <none>流程
要查看 pod 上的状态条件,请使用以下命令并提供 pod 的名称:
$ oc describe hpa <pod-name>例如:
$ oc describe hpa cm-test
这些条件会出现在输出中的 Conditions 字段里。
输出示例
Name: cm-test
Namespace: prom
Labels: <none>
Annotations: <none>
CreationTimestamp: Fri, 16 Jun 2017 18:09:22 +0000
Reference: ReplicationController/cm-test
Metrics: ( current / target )
"http_requests" on pods: 66m / 500m
Min replicas: 1
Max replicas: 4
ReplicationController pods: 1 current / 1 desired
Conditions:
Type Status Reason Message
---- ------ ------ -------
AbleToScale True ReadyForNewScale the last scale time was sufficiently old as to warrant a new scale
ScalingActive True ValidMetricFound the HPA was able to successfully calculate a replica count from pods metric http_request
ScalingLimited False DesiredWithinRange the desired replica count is within the acceptable range